ElasticSearch 7.6.1
疑问
- ES为什么这么快?
全文检索
- 听过一个程序扫描文本的每一个单词,针对单词建立索引,并保存该单词在文本中的位置,以及出现的次数。
- 在检索查询时候,通过建立好的索引进行查询,将索引中单词对应的文本位置,出现的此处返回给用户,有了具体文本的位置,就可以将具体内容读取出来。
分词原理、倒排索引
- 例如我要存储三个数据:“hello speeder”、“hello world”、“Im speeder”,那么存储的过程会经历什么?
- 分词和去重,将上述三个数据分成四个单词:hello speeder world Im
- 建立倒排索引:
| ID | word | index |
|---|---|---|
| 1 | hello | 1,2 |
| 2 | speeder | 1,3 |
| 3 | world | 2 |
| 4 | Im | 3 |
- 正排索引:根据index查询数据信息,例如根据ID查询name
- 倒排索引:根据数据信息查询对应的index,也叫反向索引,上述根据word查询index就是倒排索引
- 在用户检索查询时,流程如下:
- 先根据关键词查word查询到index。
- 再根据index查询到对应的整条数据记录,包含其他所有的field。(我认为这一步类似于关系型数据库中聚集索引的回表操作)
- 展示信息。
ES、Lucene、Solr
- lucene只能用在java项目中,需要引入jar包
- lucene不支持集群环境
- Solr实时建立索引时,Solr会产生IO阻塞,查询性能较差,Solr用的是Zookeeper进行分布式管理,而ES自带有分布式协调管理功能。
- Solr支持JSON/XML/CSV,但是ES只支持json文件,但是ES实时搜索应用效率高于Solr
- ES是基于Lucene的搜索框架
ES、kibana、logstash
- ES搜索引擎
- kibana可视化管理界面
- logstash存储库
ES和关系型数据库比较
| ES | 关系型数据库 |
|---|---|
| Index(索引) | Database(数据库) |
| Type或者_Doc(类型) | Table(表) |
| Document(文档) | Row(行) |
| Field(字段) | Column(列) |
ES中的重要概念
- Index
- Mapping
- Type
- Document
- Field
- Cluster
- node
- 分片和副本
文档映射
查看映射关系:get /index_name/_mapping,加上_下划线表示查看ES内置对象
- 动态映射,自动映射字段类型
- 静态映射,自己指定字段映射类型
- text类型中,会有type为keyword的类型字段,因为text默认是要拆分分词进行检索,keyword是为了保留原文本的不拆分而存在的,keyword也算一种类型,例如人员表中的name就可以设置为keyword,不必设置成text进行分词拆分。
IK分词器
- ES中默认的分词器是单字分词器,会把一句汉字中的所有字都拆开,所以默认的在中文环境下十分不好用,所以要用第三方分词器。
- IK直接放在ES安装目录下的plugins,重启ES后即可生效。
- IK分词器两种模式:
- ik_smart,粗粒度拆分,运用比较少。
- ik_max_word,最细粒度拆分,常用。
- ES中指定IK分词器作为默认分词器
put /index_name
{"settings" : {"index": {"analysis.analyzer.default.type" : "ik_max_word"}}
}
基本操作
- 创建索引库:
put /index_name - 查询索引库:
get /inex_name - 删除索引库:
delete /index_name - 添加一条记录:
put /index_name/_doc/id,例如put /test/user/1 - 条件查询
- 范围查询
- 批量查询
- 分页查询
DSL语言高级查询(ES中最核心的查询语法)
- match,拆分查询
- term,不拆分查询
- multi_match,多词查询
ES-Header集群管理可视化界面
待更新。。
相关文章:

ElasticSearch 7.6.1
疑问 ES为什么这么快? 全文检索 听过一个程序扫描文本的每一个单词,针对单词建立索引,并保存该单词在文本中的位置,以及出现的次数。在检索查询时候,通过建立好的索引进行查询,将索引中单词对应的文本位…...
Linux系列 操作系统安装及服务控制(笔记)
作者简介:一名在校云计算网络运维学生、每天分享网络运维的学习经验、和学习笔记。 座右铭:低头赶路,敬事如仪 个人主页:网络豆的主页 目录 前言 一.操作系统 1.Linux系统三大类 (1)ubu…...
Linux基础 - NTP时间同步
🏡博客主页: Passerby_Wang的博客_CSDN博客-系统运维,云计算,Linux基础领域博主 🌐所属专栏:『Linux基础』 🌌上期文章: Linux基础 - DNS服务进阶 📰如觉得博主文章写的不错或对你有所帮助…...

golang 入门教程:迷你 Twitter 后端
请记住,这个项目主要是为了稍微熟悉下Golang,您可以复制架构,但该项目缺少适当的 ORM,没有适当的身份验证或授权,我完全无视中间件,也没有测试。 我将在其自己的部分中讨论所有这些问题,但重要的…...

CPP2022-30-期末模拟测试03
6-1 引用作函数形参交换两个整数 分数 5 全屏浏览题目 切换布局 作者 李廷元 单位 中国民用航空飞行学院 设计一个void类型的函数Swap,该函数有两个引用类型的参数,函数功能为实现两个整数交换的操作。 裁判测试程序样例: #include <…...
)
华为OD机试真题Python实现【最多等和不相交连续子序列】真题+解题思路+代码(20222023)
🔥系列专栏 华为OD机试(Python)真题目录汇总华为OD机试(JAVA)真题目录汇总华为OD机试(C++)真题目录汇总华为OD机试(JavaScript)真题目录汇总文章目录 🔥系列专栏题目输入输出示例一输入输出说明示例二输入输出说明...

二叉搜索树
1.二叉搜索树 1.1.二叉搜索树概念 二叉搜索树又称二叉排序树,它或者是一颗空树,或者是具有一下性质的二叉树。 若它的左子树不为空,则左子树上的所有节点的值都小于根节点的值。若它的右子树不为空,则右子树上的所有节点的值都…...
数据结构(三):集合、字典、哈希表
数据结构(三)一、集合(Set)1.封装一个集合类2.集合常见的操作(1)并集(2)交集(3)差集(4)子集二、字典(Map)三、…...

Linux内核驱动开发(一)
Linux内核初探 linux操作系统历史 开发模式 git 分布式管理git clone 获取git push 提交git pull 更新 邮件组 mailing list patch 内核代码组成 Makfile arch 体系系统架构相关 block 块设备 crypto 加密算法 drivers 驱动(85%) atm 通信bluet…...

TCP/IP协议二十问
TCP/IP协议二十问 1. 什么是TCP网络分层? TCP网络分层一般分为五层: 应用层(HTTP):组装数据包传输层(TCP):增加TCP头部,包含端口号等信息网络互联层(IP&am…...

常用Array数组操作方法
定义一个测试数组constplayers[{name:科比,num:24},{name:詹姆斯,num:23},{name:保罗,num:3},{name:威少,num:0},{name:杜兰特,num:35}]复制代码1、forEach参数代表含义item:遍历项index:遍历项的索引arr:数组本身Array.prototype.sx_forEach…...
【C++】set/multiset、map/multimap的使用
目录 一、关联式容器 二、set的介绍 1、接口count与容器multiset 2、接口lower_bound和upper_bound 三、map的介绍 1、接口insert 2、接口insert和operator[]和at 3、容器multimap 四、map和set相关OJ 1、前K个高频单词 2、两个数组的交集 一、关联式容器 vector、…...
vue3语法
vue3教程 //ps 这里是基本写法 一般项目不需要ref 因为需要一直return 这里是根据在不使用ts后缀 来在.vue里面写setup 如下图所示:setup setup是启动页面会自动执行的一个函数 项目里定义的所有变量,都要在setup当中 在setup定义的变量和方法,都需要r…...
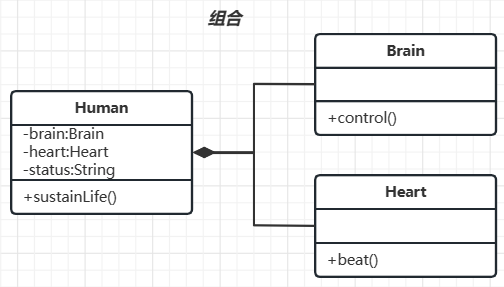
对象之间的关系
目录1. 依赖2. 关联3. 聚合4. 组合Java的对象/类之间有四种关系:依赖、关联、组合、聚合。 1. 依赖 依赖(Dependency): 一个对象的功能依赖于另一个对象。 类比:人类生存依赖食物和空气 体现:被依赖者体…...
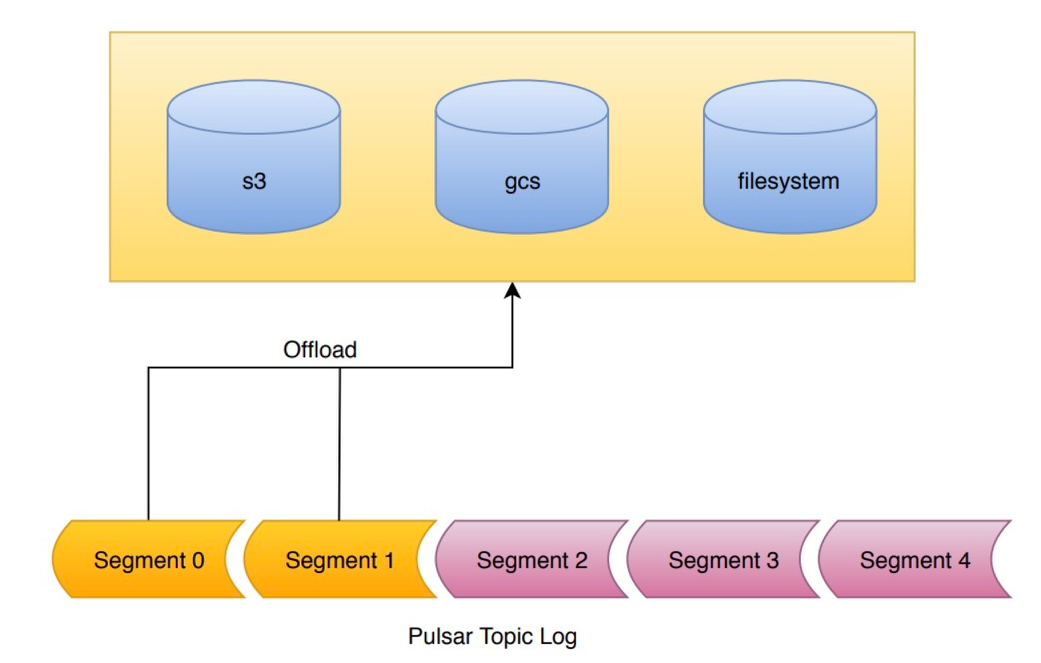
云原生时代顶流消息中间件Apache Pulsar部署实操-上
文章目录安装运行时Java版本推荐Locally Standalone集群启动验证部署分布式集群部署说明初始化集群元数据部署BookKeeper部署BrokerAdmin客户端和验证Tiered Storage(层级存储)概述支持分级存储何时使用工作原理安装 运行时Java版本推荐 Locally Standalone集群 启动 # 下载…...

Python实现基于openCV+百度智能云平台实现《1:N人脸考勤机》文章最后附带源码!
目录 一、 项目介绍 1.1 项目名称 1.2 项目简介 1.3 项目物料 1.4 技术栈 二、 项目架构 三、项目细节 3.1 环境搭建 3.2 利用opencv实现摄像头调取及相关图像的采集 3.3 利用aips上传图像和结果返回 3.4 结果优化和处理 3.5 可扩展性 3.6 遗留问题和…...

因为锁的问题,我们被扣了1万
前言 春节放假期间,一个项目上的积分接口被刷,而且不止一个人在刷,并且东西也被兑走,放假晚上被人叫起来排查问题,通过这个人的积分明细观察,基本一秒就能获取一次,远远超过了积分规则限定的次…...
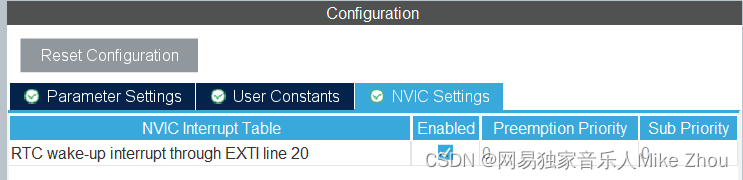
【STM32笔记】低功耗模式下的RTC唤醒(非闹钟唤醒,而是采用RTC_WAKEUPTIMER)
【STM32笔记】低功耗模式下的RTC唤醒(非闹钟唤醒,而是采用RTC_WAKEUPTIMER) 前文: blog.csdn.net/weixin_53403301/article/details/128216064 【STM32笔记】HAL库低功耗模式配置(ADC唤醒无法使用、低功耗模式无法烧录…...

浏览器渲染中的相关概念
渲染 渲染流水线 构建 DOM 树 输入:HTML 文档;处理:HTML 解析器解析;输出:DOM 数据解构。 样式计算 输入:CSS 文本;处理:属性值标准化,每个节点具体样式(…...

【MySQL】数据类型
1、数据类型描述 类型类型举例整数类型TINYINT、SMALLINT、MEDIUMINT、INT(或INTEGER)、BIGINT浮点类型FLOAT、DOUBLE定点数类型DECIMAL位类型BIT日期时间类型YEAR、TIME、DATE、DATETIME、TIMESTAMP文本字符串类型CHAR、VARCHAR、TINYTEXT、TEXT、MEDIUMTEXT、LONGTEXT枚举类…...

AI代理自动化发币:SolPaw Skill在Solana上的集成与实战
1. 项目概述:当AI代理学会在Solana上发币如果你正在研究如何让一个AI代理(比如OpenClaw)在Solana区块链上自动创建和发行代币,特别是通过Pump.fun这个平台,那么你找对地方了。SolPaw Skill这个项目,本质上是…...

AI原生安全CLI实战指南:Zypheron安装、配置与攻防工作流解析
1. 项目概述:一个为实战而生的AI原生安全CLI如果你和我一样,常年泡在终端里,每天和各种扫描器、漏洞库、报告打交道,那你肯定也烦透了那种“脚本小子”式的工作流:一个工具输出一堆原始日志,再手动扔给另一…...

别再只盯着机械雷达了!聊聊MEMS、相控阵这些固态激光雷达到底强在哪
固态激光雷达技术革命:MEMS与相控阵如何重塑自动驾驶感知格局 当Waymo第五代自动驾驶系统将MEMS激光雷达成本压缩至7500美元时,行业终于意识到固态化浪潮已不可逆转。传统机械式激光雷达的旋转部件正如内燃机之于电动车,正在经历一场静默但彻…...
)
从克拉坡振荡器到丙类功放:深入拆解一个调频发射机的每个模块(含原理、选型与实测分析)
从克拉坡振荡器到丙类功放:深入拆解一个调频发射机的每个模块(含原理、选型与实测分析) 在射频电路设计的进阶领域,调频发射机是一个兼具经典理论和工程实践价值的项目。不同于基础教程中简单的电路搭建,本文将带您深入…...

用Python实战SCAN算法:15分钟搞定社交网络中的“关键人物”与“边缘人”识别
用Python实战SCAN算法:15分钟搞定社交网络中的"关键人物"与"边缘人"识别 社交网络分析中,识别关键节点和边缘用户是理解群体结构的重要突破口。想象一下,当你面对公司内部通讯记录或产品用户互动数据时,如何快…...

基于Coolify与OpenClaw部署自托管AI智能体网关的完整实践指南
1. 项目概述:在Coolify上部署你的专属AI智能体网关 如果你对AI智能体(Agent)感兴趣,想拥有一个能帮你处理信息、自动执行任务的私人助手,但又觉得从零搭建环境、配置模型、管理服务太麻烦,那么今天分享的这…...

神经网络训练绝对值函数的奥秘
在机器学习和深度学习的世界里,神经网络的训练过程充满了各种有趣的现象和挑战。本文将详细讨论如何使用神经网络来拟合一个看似简单的函数——绝对值函数(|x|),并探讨为何在某些情况下需要增加网络的层数来获得更好的拟合效果。 问题背景 假设我们想用神经网络来学习函数…...

构建全球AI治理框架:跨国法律协调与监管机构设计
1. 项目概述:为什么我们需要一个全球性的AI治理框架?最近几年,AI技术的爆炸式发展,尤其是大语言模型和生成式AI的快速迭代,让我这个在科技与政策交叉领域摸爬滚打了十几年的人,感受到了一种前所未有的紧迫感…...

易语言大漠模块实战:BindWindow后台绑定模式选择与避坑指南
1. 大漠模块后台绑定的核心价值 后台绑定技术对于自动化操作来说就像给机器人装上了眼睛和手指。想象一下,你正在玩一款需要重复刷副本的游戏,每次都要机械地点鼠标、按键盘,不仅累还容易出错。而大漠模块的BindWindow函数就是帮你解决这个痛…...

百度网盘提取码获取神器:3步解决资源下载难题
百度网盘提取码获取神器:3步解决资源下载难题 【免费下载链接】baidupankey 项目地址: https://gitcode.com/gh_mirrors/ba/baidupankey 你是否经常遇到这样的情况:好不容易找到心仪的百度网盘资源,却因为不知道提取码而无法下载&…...