HashMap底层实现原理概述
原文https://blog.csdn.net/fedorafrog/article/details/115478407
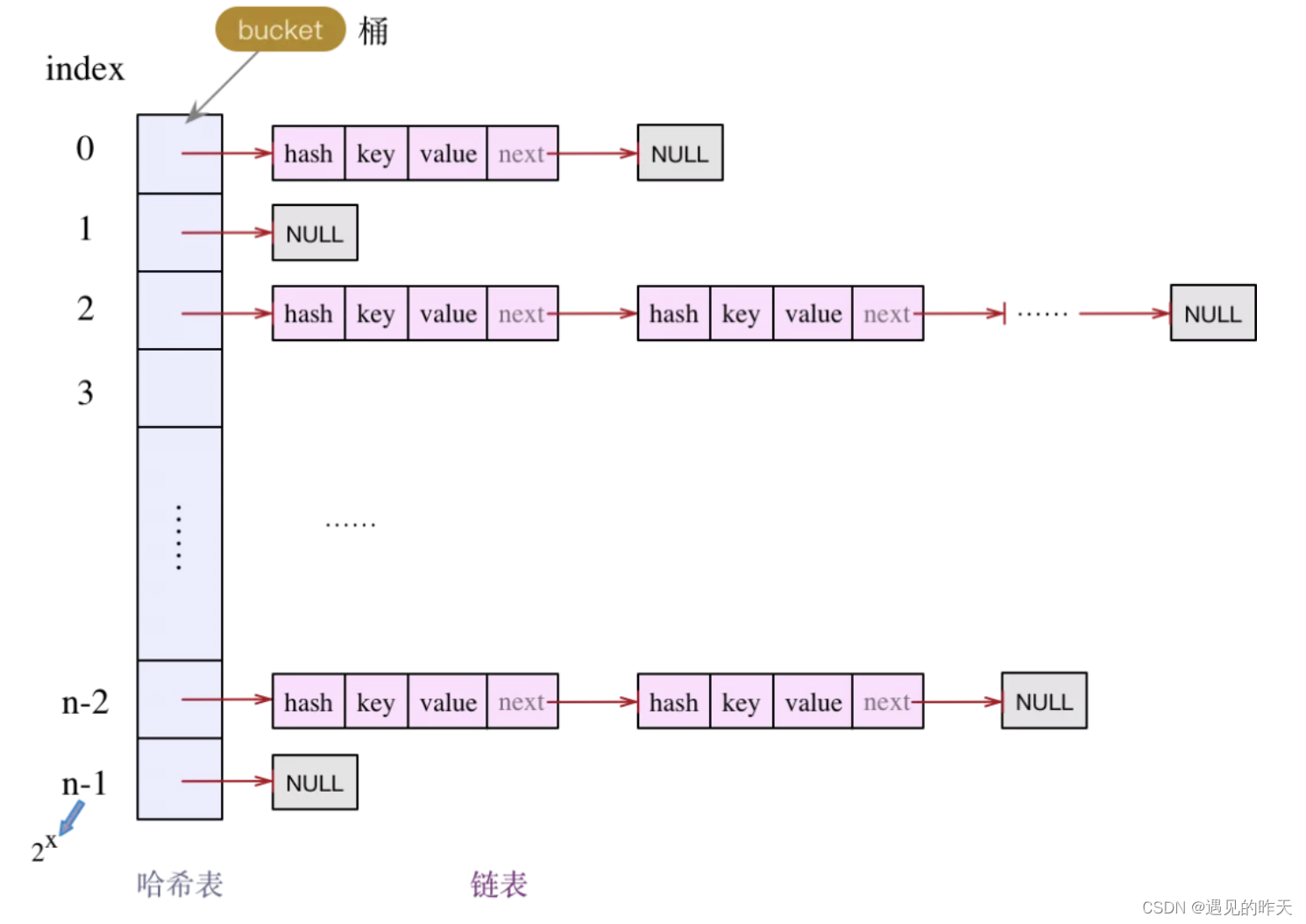
hashMap结构
常见问题
在理解了HashMap的整体架构的基础上,我们可以试着回答一下下面的几个问题,如果对其中的某几个问题还有疑惑,那就说明我们还需要深入代码,把书读厚。
- HashMap内部的bucket数组长度为什么一直都是2的整数次幂
- HashMap默认的bucket数组是多大
- HashMap什么时候开辟bucket数组占用内存
- HashMap何时扩容?
- 桶中的元素链表何时转换为红黑树,什么时候转回链表,为什么要这么设计?
- Java 8中为什么要引进红黑树,是为了解决什么场景的问题?
- HashMap如何处理key为null的键值对?
new HashMap()
在JDK 8中,在调用new HashMap()的时候并没有分配数组堆内存,只是做了一些参数校验,初始化了一些常量
public HashMap(int initialCapacity, float loadFactor) {if (initialCapacity < 0)throw new IllegalArgumentException("Illegal initial capacity: " +initialCapacity);if (initialCapacity > MAXIMUM_CAPACITY)initialCapacity = MAXIMUM_CAPACITY;if (loadFactor <= 0 || Float.isNaN(loadFactor))throw new IllegalArgumentException("Illegal load factor: " +loadFactor);this.loadFactor = loadFactor;this.threshold = tableSizeFor(initialCapacity);
}static final int tableSizeFor(int cap) {int n = cap - 1;n |= n >>> 1;n |= n >>> 2;n |= n >>> 4;n |= n >>> 8;n |= n >>> 16;return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
tableSizeFor的作用是找到大于cap的最小的2的整数幂,我们假设n(注意是n,不是cap哈)对应的二进制为000001xxxxxx,其中x代表的二进制位是0是1我们不关心,
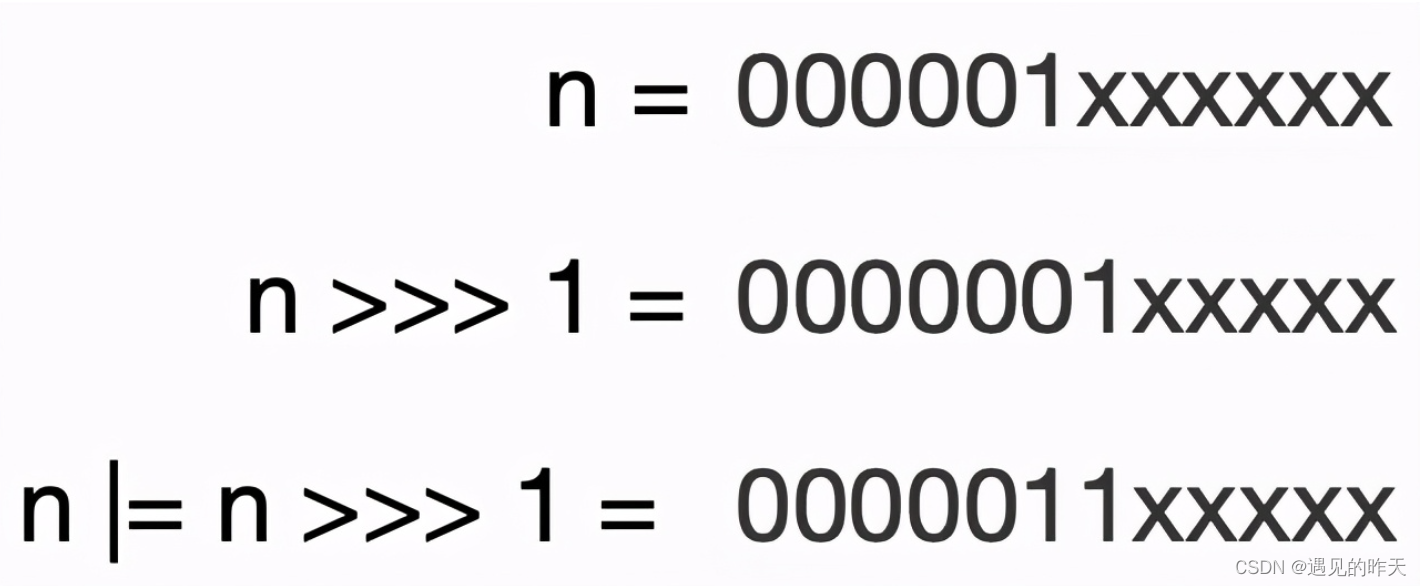
可以看到此时n的二进制最高两位已经变成了1(1和0或1异或都是1),再接着执行第二行代码:
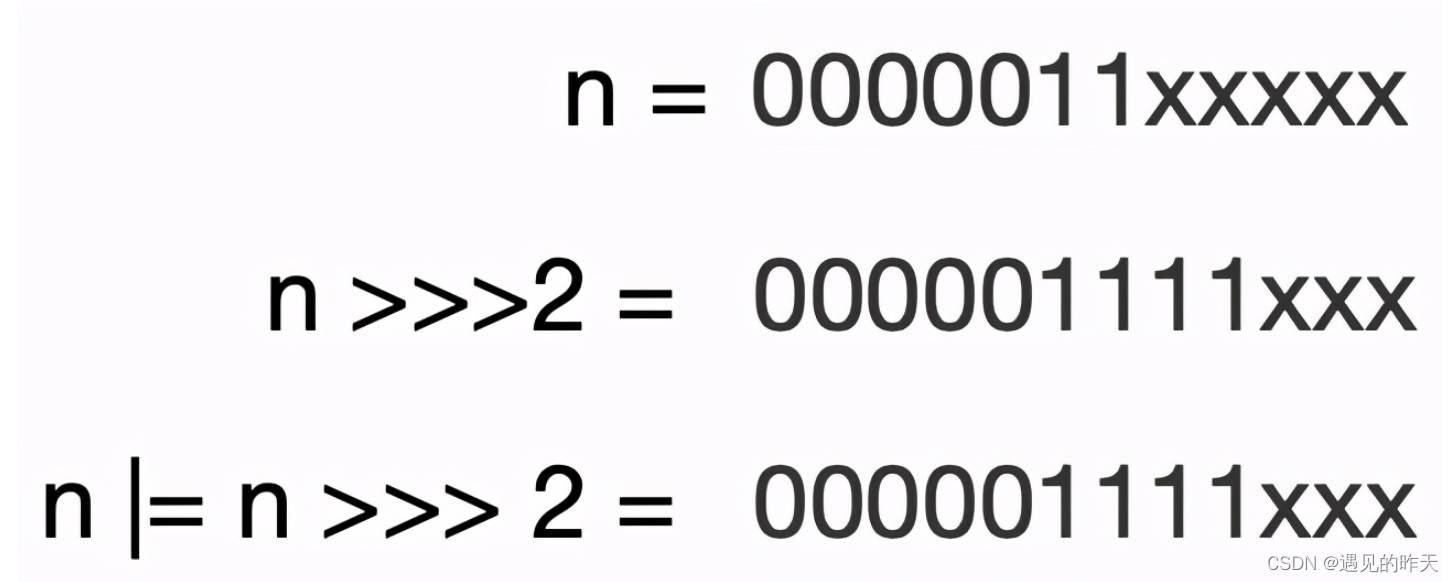
可见n的二进制最高四位已经变成了1,等到执行完代码n |= n >>> 16;之后,n的二进制最低位全都变成了1,也就是n = 2^x - 1其中x和n的值有关,如果没有超过MAXIMUM_CAPACITY,最后会返回一个2的正整数次幂,因此tableSizeFor的作用就是保证返回一个比入参大的最小的2的正整数次幂。
这里我们也回答了开头提出来的问题:
HashMap什么时候开辟bucket数组占用内存?答案是在HashMap第一次put的时候,无论Java 8还是Java 7都是这样实现的。
为什么桶数组的大小都是2的正整数幂?
Hash
在HashMap这个特殊的数据结构中,hash函数承担着寻址定址的作用,其性能对整个HashMap的性能影响巨大,那什么才是一个好的hash函数呢?
- 计算出来的哈希值足够散列,能够有效减少哈希碰撞
- 本身能够快速计算得出,因为HashMap每次调用get和put的时候都会调用hash方法
static final int hash(Object key) {int h;return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
异或是相加
这里比较重要的是(h = key.hashCode()) ^ (h >>> 16),这个位运算其实是将key.hashCode()计算出来的hash值的高16位与低16位继续异或,为什么要这么做呢?
我们知道hash函数的作用是用来确定key在桶数组中的位置的,在JDK中为了更好的性能,通常会这样写:
index =(table.length - 1) & key.hash();
& 运算是相乘
回忆前文中的内容,table.length是一个2的正整数次幂,类似于000100000,这样的值减一就成了000011111,通过位运算可以高效寻址,
这也回答了前文中提到的一个问题,HashMap内部的bucket数组长度为什么一直都是2的整数次幂?好处之一就是可以通过构造位运算快速寻址定址。
回到本小节的议题,既然计算出来的哈希值都要与table.length - 1做与运算,那就意味着计算出来的hash值只有低位有效,这样会加大碰撞几率,因此让高16位与低16位做异或,让低位保留部分高位信息,减少哈希碰撞。
Put
在Java 8中put这个方法的思路分为以下几步:
1、调用key的hashCode方法计算哈希值,并据此计算出数组下标index
2、如果发现当前的桶数组为null,则调用resize()方法进行初始化
3、如果没有发生哈希碰撞,则直接放到对应的桶中
4、如果发生哈希碰撞,且节点已经存在,就替换掉相应的value
5、如果发生哈希碰撞,且桶中存放的是树状结构,则挂载到树上
6、如果碰撞后为链表,添加到链表尾,如果链表长度超过TREEIFY_THRESHOLD默认是8,则将链表转换为树结构
7、数据put完成后,如果HashMap的总数超过threshold就要resize
public V put(K key, V value) {// 调用上文我们已经分析过的hash方法return putVal(hash(key), key, value, false, true);
}final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {Node<K,V>[] tab; Node<K,V> p; int n, i;if ((tab = table) == null || (n = tab.length) == 0)// 第一次put时,会调用resize进行桶数组初始化n = (tab = resize()).length;// 根据数组长度和哈希值相与来寻址,原理上文也分析过if ((p = tab[i = (n - 1) & hash]) == null)// 如果没有哈希碰撞,直接放到桶中tab[i] = newNode(hash, key, value, null);else {Node<K,V> e; K k;if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k))))// 哈希碰撞,且节点已存在,直接替换e = p;else if (p instanceof TreeNode)// 哈希碰撞,树结构e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);else {// 哈希碰撞,链表结构for (int binCount = 0; ; ++binCount) {if ((e = p.next) == null) {p.next = newNode(hash, key, value, null);// 链表过长,转换为树结构if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1sttreeifyBin(tab, hash);break;}if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))// 如果节点已存在,则跳出循环break;// 否则,指针后移,继续后循环p = e;}}if (e != null) { // existing mapping for key// 对应着上文中节点已存在,跳出循环的分支// 直接替换V oldValue = e.value;if (!onlyIfAbsent || oldValue == null)e.value = value;afterNodeAccess(e);return oldValue;}}++modCount;if (++size > threshold)// 如果超过阈值,还需要扩容resize();afterNodeInsertion(evict);return null;
}
resize()
resize是整个HashMap中最复杂的一个模块,如果在put数据之后超过了threshold的值,则需要扩容,扩容意味着桶数组大小变化,我们在前文中分析过,HashMap寻址是通过index =(table.length - 1) & key.hash();来计算的,现在table.length发生了变化,势必会导致部分key的位置也发生了变化,HashMap是如何设计的呢?
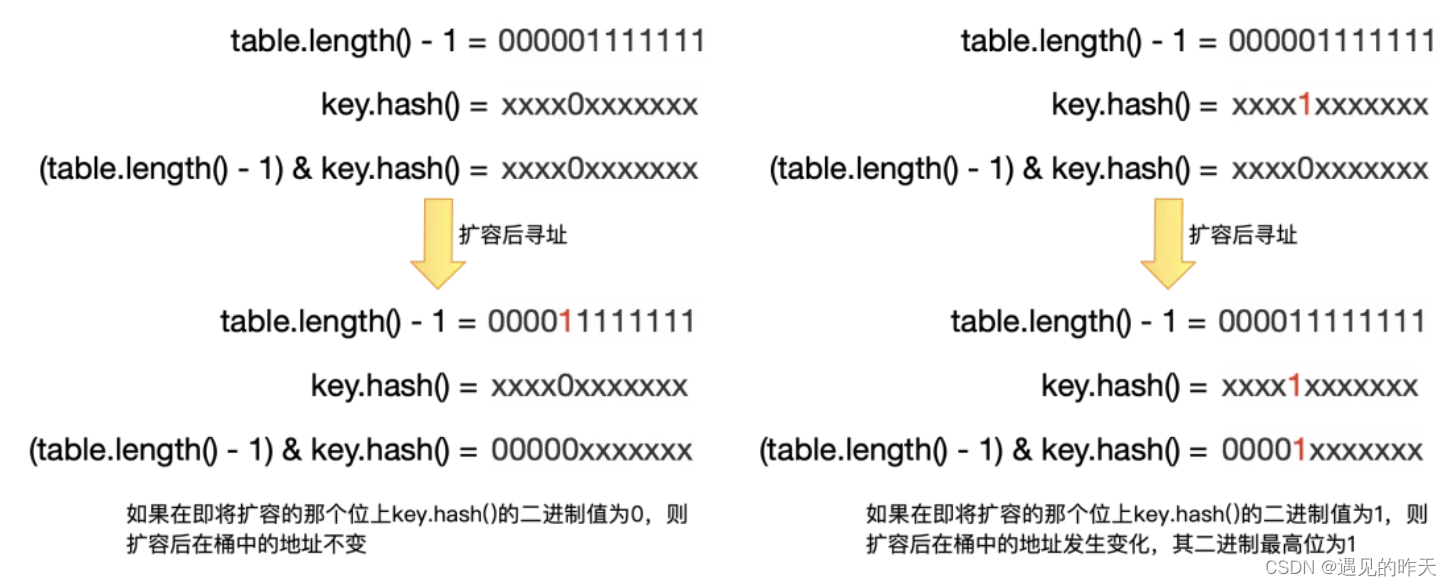
通过这个分析可以看到如果在即将扩容的那个位上key.hash()的二进制值为0,则扩容后在桶中的地址不变,否则,扩容后的最高位变为了1,新的地址也可以快速计算出来newIndex = oldCap + oldIndex;
final Node<K,V>[] resize() {Node<K,V>[] oldTab = table;int oldCap = (oldTab == null) ? 0 : oldTab.length;int oldThr = threshold;int newCap, newThr = 0;if (oldCap > 0) {// 如果oldCap > 0则对应的是扩容而不是初始化if (oldCap >= MAXIMUM_CAPACITY) {threshold = Integer.MAX_VALUE;return oldTab;}// 没有超过最大值,就扩大为原先的2倍else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&oldCap >= DEFAULT_INITIAL_CAPACITY)newThr = oldThr << 1; // double threshold}else if (oldThr > 0) // initial capacity was placed in threshold// 如果oldCap为0, 但是oldThr不为0,则代表的是table还未进行过初始化newCap = oldThr;else { // zero initial threshold signifies using defaultsnewCap = DEFAULT_INITIAL_CAPACITY;newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);}if (newThr == 0) {// 如果到这里newThr还未计算,比如初始化时,则根据容量计算出新的阈值float ft = (float)newCap * loadFactor;newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?(int)ft : Integer.MAX_VALUE);}threshold = newThr;@SuppressWarnings({"rawtypes","unchecked"})Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];table = newTab;if (oldTab != null) {for (int j = 0; j < oldCap; ++j) {// 遍历之前的桶数组,对其值重新散列Node<K,V> e;if ((e = oldTab[j]) != null) {oldTab[j] = null;if (e.next == null)// 如果原先的桶中只有一个元素,则直接放置到新的桶中newTab[e.hash & (newCap - 1)] = e;else if (e instanceof TreeNode)((TreeNode<K,V>)e).split(this, newTab, j, oldCap);else { // preserve order// 如果原先的桶中是链表Node<K,V> loHead = null, loTail = null;// hiHead和hiTail代表元素在新的桶中和旧的桶中的位置不一致Node<K,V> hiHead = null, hiTail = null;Node<K,V> next;do {next = e.next;if ((e.hash & oldCap) == 0) {if (loTail == null)loHead = e;elseloTail.next = e;loTail = e;}else {if (hiTail == null)hiHead = e;elsehiTail.next = e;hiTail = e;}} while ((e = next) != null);if (loTail != null) {loTail.next = null;// loHead和loTail代表元素在新的桶中和旧的桶中的位置一致newTab[j] = loHead;}if (hiTail != null) {hiTail.next = null;// 新的桶中的位置 = 旧的桶中的位置 + oldCap, 详细分析见前文newTab[j + oldCap] = hiHead;}}}}}return newTab;
}
总结
HashMap什么时候开辟bucket数组占用内存?
答案是在HashMap第一次put的时候,无论Java 8还是Java 7都是这样实现的。
为什么hashMap大小必须是2的次幂?
好处1:
那得从她的结构说起,当put,get的时候,内部会通过对key进行hash运算,运算结果是二进制低位有效,然后对 (数组大小-1 )(低位有效)进行& 运算(相乘)实际上得到的结果就会映射到 数组大小之内,因此数组大小定义为2的次幂,能够快速的定位寻址,除此之外,其中的位运算也是为了加快处理速度。
好处2
在HashMap扩容的时候可以保证同一个桶中的元素均匀地散列到新的桶中,具体一点就是同一个桶中的元素在扩容后一般留在原先的桶中,一般放到了新的桶中。
HashMap默认的bucket数组是多大?
默认是16,即时指定的大小不是2的整数次幂,HashMap也会找到一个最近的2的整数次幂来初始化桶数组。
HashMap何时扩容?
答:当HashMap中的元素熟练超过阈值时,阈值计算方式是capacity * loadFactor,在HashMap中loadFactor是0.75
桶中的元素链表何时转换为红黑树,什么时候转回链表,为什么要这么设计?
答:当同一个桶中的元素数量大于等于8的时候元素中的链表转换为红黑树,反之,当桶中的元素数量小于等于6的时候又会转为链表,这样做的原因是避免红黑树和链表之间频繁转换,引起性能损耗
Java 8中为什么要引进红黑树,是为了解决什么场景的问题?
答:引入红黑树是为了避免hash性能急剧下降,引起HashMap的读写性能急剧下降的场景,正常情况下,一般是不会用到红黑树的,在一些极端场景下,假如客户端实现了一个性能拙劣的hashCode方法,可以保证HashMap的读写复杂度不会低于O(lgN)
public int hashCode() {
return 1;
}
HashMap如何处理key为null的键值对?
答:放置在桶数组中下标为0的位置
在Java 8中put这个方法的思路分为以下几步:
1、调用key的hashCode方法计算哈希值,并据此计算出数组下标index
2、如果发现当前的桶数组为null,则调用resize()方法进行初始化
3、如果没有发生哈希碰撞,则直接放到对应的桶中
4、如果发生哈希碰撞,且节点已经存在,就替换掉相应的value
5、如果发生哈希碰撞,且桶中存放的是树状结构,则挂载到树上
6、如果碰撞后为链表,添加到链表尾,如果链表长度超过TREEIFY_THRESHOLD默认是8,则将链表转换为树结构
7、数据put完成后,如果HashMap的总数超过threshold就要resize
相关文章:
HashMap底层实现原理概述
原文https://blog.csdn.net/fedorafrog/article/details/115478407 hashMap结构 常见问题 在理解了HashMap的整体架构的基础上,我们可以试着回答一下下面的几个问题,如果对其中的某几个问题还有疑惑,那就说明我们还需要深入代码,…...
Linux驱动学习环境搭建
背景常识 一、程序分类 程序按其运行环境分为: 1. 裸机程序:直接运行在对应硬件上的程序 2. 应用程序:只能运行在对应操作系统上的程序 二、计算机系统的层次结构 所有智能设备其实都是计算机,机顶盒、路由器、冰箱、洗衣机、汽…...

Java基础之异常
目录1 异常1.1 异常的概述1.2 常见异常类型1.3 JVM的默认处理方案1.4 编译时异常的处理方式1.4.1 异常处理之 try ... catch ... [ktʃ](捕获异常)1.4.2 异常处理之 throws(抛出异常)1.5 Throwable 的成员方法1.6 编译时异常和运行…...

感慨:大三了,未来该何去何从呢
笔者曾在十一月份通过了字节跳动的三次面试, 但是最终因为疫情原因不能满足公司的入职时间要求, 没有拿到offer。近期也是投递了大量大厂的实习岗, 但是要么已读不回, 要么明确告诉我学历至少要985硕士(天天被阿里cpu)。 说实话一…...
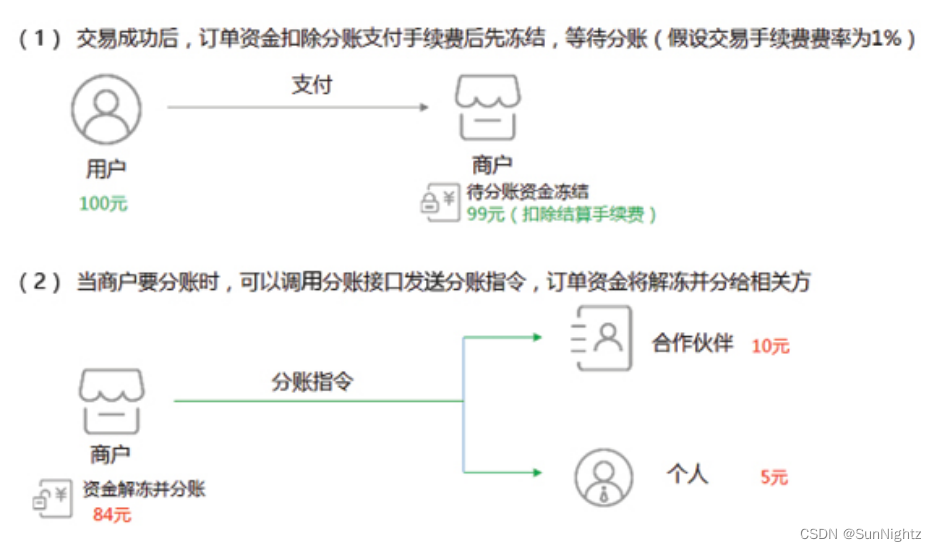
分账系统逻辑
一、说明 主体与业务关系方进行相关利益和支出的分配过程 使用场景: 在分销业务中,主营商户收到用户购买分销商品所支付的款项后,可以通过分账逻辑,与分销商进行佣金结算。在零售、餐饮等行业中,当销售人员完零售等…...

SpringCloud篇——什么是SpringCloud、有什么优缺点、学习顺序是什么
文章目录一、首先看官方解释二、Spring Cloud 的项目的位置三、Spring Cloud的子项目四、Spring Cloud 现状五、spring cloud 优缺点六、Spring Cloud 和 Dubbo 对比七、Spring Cloud 学习路线一、首先看官方解释 Spring Cloud为开发人员提供了快速构建分布式系统中一些常见模式…...

TCP核心机制之连接管理详解(三次握手,四次挥手)
目录 前言: 建立连接 建立连接主要两个TCP状态: 断开连接 断开连接的两个重要状态 小结: 前言: TCP是如何建立对端连接,如何断开连接,这篇文章会详细介绍。 建立连接 首先明确连接的概念:…...

前端—环境配置
前端开发建议用 Google Chrome 浏览器 vscode https://code.visualstudio.com 1、open in browser 插件:可以在 vscode 中直接运行查看浏览器效果 2、Live Server 插件:可以使代码修改浏览器页面实时刷新。 用户代码片段 … JavaScript 与 TypeScri…...
大学生常用python变量和简单的数据类型、可迭代对象、for循环的3用法
文章目录变量和简单的数据类型下划线开头的对象删除内存中的对象列表与元组debug三酷猫钓鱼记录实际POS机小条打印使用循环找乌龟可迭代对象📗理解一📘理解二2️⃣什么是迭代器✔️注意3️⃣迭代器对象4️⃣有关迭代的函数for循环的3用法🌸I …...

Java集合:Map的使用
1.Map框架l----Map:双列数据,存储key-value对的数据 ---类似于高中的函数: y f(x)|----HashMap:作为Map的主要实现类, 线程不安全的,效率高;可以存储null的key和value|----LinkedHashMap:保证在遍历map元素时,可以按照…...

【Datawhale图机器学习】第一章图机器学习导论
图机器学习导论 学习路径与必读论文清单 斯坦福CS224W(子豪兄中文精讲)知识图谱实战DeepwalkNode2vecPageRankGNNGCNGragh-SAGEGINGATTrans-ETrans-R 图无处不在 图是描述关联数据的通用语言 举例 计算机网络新冠肺炎流行病学调查传播链食物链地铁图…...

window 配置深度学习环境GPU
CUDA 11.6 CUDNN Anaconda pytorch 参考网址:https://zhuanlan.zhihu.com/p/460806048 阿里巴巴开源镜像站-OPSX镜像站-阿里云开发者社区 (aliyun.com) 电脑信息 RTX 2060 GPU0 1. CUDA 11.6 1.1 确认信息 C:\Users\thzn>nvidia-smi (CUDA Versi…...

VS Code 用作嵌入式开发编辑器
使用 Keil MDK 进行嵌入式开发时,Keil 的编辑器相对于主流编辑器而言有些不方便,比如缺少暗色主题、缺少智能悬停感知(鼠标停在一个宏上,能自动展开最终的宏结果)、代码补全不好用等等,所以推荐使用 VS Cod…...

【Python】网络爬虫经验之谈
爬虫经验之谈对爬虫的认识网站分析技术选型JS逆向反爬机制结语近段时间,因为工作需要做一些爬虫的开发,分享一下走过的坑和实战的经验吧!对爬虫的认识 F12查看的网络请求,找到相应的接口查看一下json数据来源和构造。我爬取的网站…...
数学建模美赛【LaTeX】公式、表格、图片
数学建模美赛【LaTeX】公式、表格、图片 1 宏包 \package{ } 就是在调用宏包,对计算机实在外行的同学姑且可以理解为工具箱。 每一个宏包里都定义了一些专门的命令,通过这些命令可以实现对于一类对象(如数学公式等)的统一排版&a…...
【大数据】YARN节点标签Node Label特性
简介 YARN 的 Node-label 特性能够将不同的机器类型进行分组调度,也可以根据不同的资源要求进行分区调度。运维人员可以根据节点的特性将其分为不同的分区来满足业务多维度的使用需求。YARN的Node-label功能将很好的试用于异构集群中,可以更好地管理和调…...
C# SolidWorks二次开发 API-命令标签页的切换与按钮错乱问题
这是一个网友咨询的问题,说他想控制默认打开文件之后solidworks上方工具栏的当前激活标签页。 之前我们提到过,制作Solidworks的插件也会在上面增加一个标签页,用来放自己开发的命令,经常开发的人肯定会遇到有时候更新版本,或者标…...

ElasticSearch 7.6.1
疑问 ES为什么这么快? 全文检索 听过一个程序扫描文本的每一个单词,针对单词建立索引,并保存该单词在文本中的位置,以及出现的次数。在检索查询时候,通过建立好的索引进行查询,将索引中单词对应的文本位…...
Linux系列 操作系统安装及服务控制(笔记)
作者简介:一名在校云计算网络运维学生、每天分享网络运维的学习经验、和学习笔记。 座右铭:低头赶路,敬事如仪 个人主页:网络豆的主页 目录 前言 一.操作系统 1.Linux系统三大类 (1)ubu…...
Linux基础 - NTP时间同步
🏡博客主页: Passerby_Wang的博客_CSDN博客-系统运维,云计算,Linux基础领域博主 🌐所属专栏:『Linux基础』 🌌上期文章: Linux基础 - DNS服务进阶 📰如觉得博主文章写的不错或对你有所帮助…...

5分钟掌握ComfyUI_essentials:解锁AI绘画的终极创作工具箱
5分钟掌握ComfyUI_essentials:解锁AI绘画的终极创作工具箱 【免费下载链接】ComfyUI_essentials 项目地址: https://gitcode.com/gh_mirrors/co/ComfyUI_essentials 还在为ComfyUI中缺少关键功能而烦恼吗?ComfyUI_essentials就是你的终极解决方案…...

Nuendo实战排障——从无声到有声的驱动与连接设置指南
1. 无声问题的常见根源排查 当你第一次打开Nuendo准备大展身手时,最令人崩溃的莫过于导入音频后点击播放却一片寂静。这种情况我遇到过太多次了,记得刚开始用Nuendo时,整整两天都在和无声问题作斗争。经过这些年的摸索,我总结出几…...

技术深度解析:NxNandManager——Nintendo Switch存储管理核心功能与加密架构价值主张
技术深度解析:NxNandManager——Nintendo Switch存储管理核心功能与加密架构价值主张 【免费下载链接】NxNandManager Nintendo Switch NAND management tool : explore, backup, restore, mount, resize, create emunand, etc. (Windows) 项目地址: https://gitc…...

基于RAG的本地知识库构建:从Lorex项目看检索增强生成技术实践
1. 项目概述:一个被低估的本地知识库构建利器如果你正在寻找一个能够轻松将本地文档、笔记、甚至网页内容转化为可交互、可查询的智能知识库的方案,那么alirezanet/Lorex这个开源项目绝对值得你花时间深入研究。它不是一个简单的文档管理系统,…...

第四次工业革命:AI驱动的社会变革、就业重塑与伦理挑战
1. 项目概述:我们正在谈论什么?最近几年,无论是行业峰会还是日常的技术讨论,一个词被反复提及,频率之高几乎让人有些“麻木”——“第四次工业革命”。但当我们真正停下来,试图去理解它究竟意味着什么时&am…...

如何突破百度网盘限速?3分钟掌握直链解析终极指南
如何突破百度网盘限速?3分钟掌握直链解析终极指南 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 还在为百度网盘的龟速下载而烦恼吗?当你急需下载重要…...

阿里AgentEvolver框架解析:让AI智能体实现自我进化的三大核心机制
1. 项目概述:AgentEvolver,一个让智能体学会“自我进化”的框架如果你和我一样,长期在AI智能体(Agent)这个领域里摸爬滚打,那你一定对一个问题深有感触:训练一个真正能打、能适应复杂任务的智能…...

3步实现高效B站视频转文字的智能解决方案
3步实现高效B站视频转文字的智能解决方案 【免费下载链接】bili2text Bilibili视频转文字,一步到位,输入链接即可使用 项目地址: https://gitcode.com/gh_mirrors/bi/bili2text 在信息爆炸的时代,视频已成为知识传播的主流媒介。B站作…...

命令行办公自动化:officecli-skills技能库实战指南
1. 项目概述:一个为命令行注入办公能力的技能库如果你和我一样,每天的工作流都离不开终端,同时又需要频繁处理文档、表格和演示文稿,那么你肯定也经历过那种在图形界面和命令行之间反复横跳的割裂感。officecli/officecli-skills这…...

Haft:AI辅助开发中的工程治理与决策可追溯性实践
1. 项目概述:Haft——AI辅助软件交付的工程治理层在AI编码助手(如Claude Code、Cursor)日益普及的今天,我们正面临一个全新的工程挑战:代码生成的速度前所未有,但生成代码背后的决策质量、长期可维护性以及…...