LeetCode 1206. 实现跳表
不使用任何库函数,设计一个跳表。
跳表是在 O(log(n)) 时间内完成增加、删除、搜索操作的数据结构。跳表相比于树堆与红黑树,其功能与性能相当,并且跳表的代码长度相较下更短,其设计思想与链表相似。
例如,一个跳表包含 [30, 40, 50, 60, 70, 90],然后增加 80、45 到跳表中,以下图的方式操作:
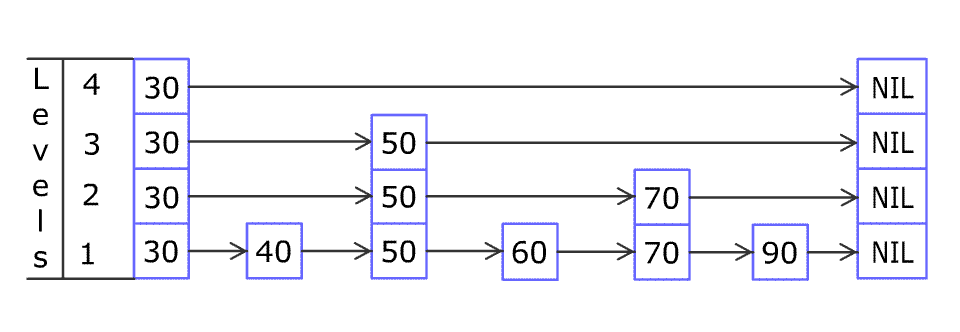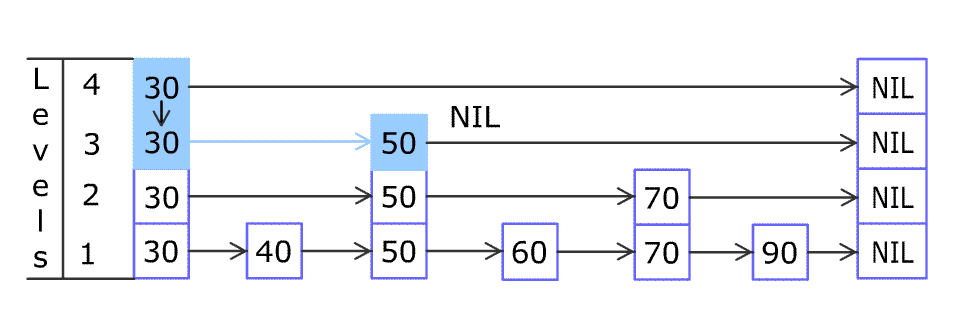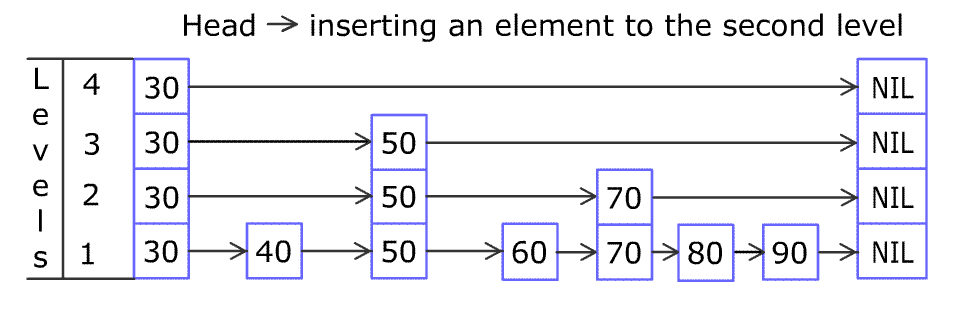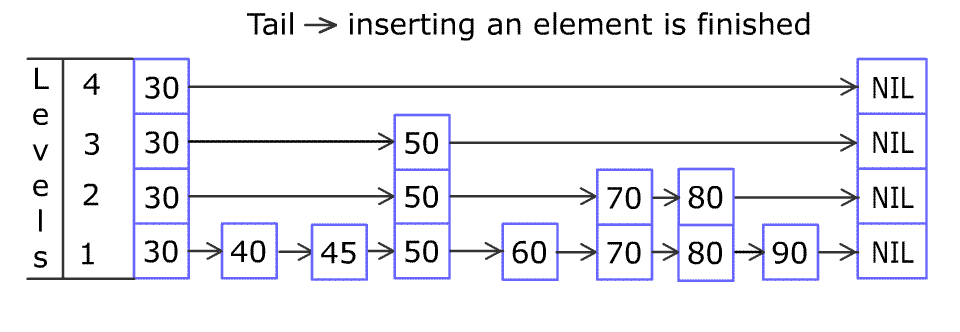
跳表中有很多层,每一层是一个短的链表。在第一层的作用下,增加、删除和搜索操作的时间复杂度不超过 O(n)。跳表的每一个操作的平均时间复杂度是 O(log(n)),空间复杂度是 O(n)。
注意,跳表中可能存在多个相同的值,你的代码需要处理这种情况。
题目分析
跳表其实就是加了几层索引的链表,一共有 N 层,以 0 ~ N-1 层表示,设第 0 层是原链表,抽取其中部分元素,在第 1 层形成新的链表,上下层的相同元素之间连起来;再抽取第 1 层部分元素,构成第 2 层,以此类推。
为什么需要random函数呢?
需要某种手段来维护索引与原始链表大小之间的平衡,也就是说,如果链表中结点多了,索引结点就相应地增加一些,避免复杂度退化,以及查找、插入、删除操作性能下降。
如果你了解红黑树、AVL 树这样平衡二叉树,你就知道它们是通过左右旋的方式保持左右子树的大小平衡,而跳表是通过随机函数来维护前面提到的“平衡性”。
【查找】
跳表其实就是加了几层索引的链表,一共有 N 层,以 0 ~ N-1 层表示,设第 0 层是原链表,抽取其中部分元素,在第 1 层形成新的链表,上下层的相同元素之间连起来;再抽取第 1 层部分元素,构成第 2 层,以此类推。
具体选哪些元素呢?题目给的是coinFlip,也就是每次插入元素的时候,都进行一次 50% 概率的判断,如果 true 则向上层添加一个索引,如果 false 就不加了。
【添加和删除】
添加和删除的时候,存在数据重复的问题,经过我的测试,发现题目要求的是,将重复的数据当做不同的值来对待,即存了一个元素 9 ,再存一个 9 ,此时表里有俩 9 ,相互独立,删除一个 9 ,表里应该还剩余有一个9。
由于添加和删除元素都是从底层开始,而在查找的时候是从顶层开始查找的,因此可以使用一个数组记录每层的“跳跃节点”的位置,就不必反复的从顶层开始查找每层的位置了。
在添加的时候,首先是查找到添加位置,过程与查找类似,首先找到表中 >= 插入元素 的最小节点位置,然后插入节点, 50% 概率判别,如果需要添加索引,就添加索引,继续 50% 概率判别,直到结束。
在删除的时候,首先也是查找,找到表中所有 = 插入元素的节点位置(每层只找一个,找到直接跳层即可),然后挨个删除。
代码实现
class Skiplist {class SkipListNode {int val;int cnt; // 当前val出现的次数SkipListNode[] levels; // start from 0SkipListNode() {levels = new SkipListNode[MAX_LEVEL];}}private double p = 0.5;private int MAX_LEVEL = 16;private SkipListNode head; // 头结点private int level; // private Random random;public Skiplist() {// 保存此level有利于查询(以及其他操作)level = 0; // 当前 skiplist的高度(所有数字 level数最大的)head = new SkipListNode();random = new Random();}// 返回target是否存在于跳表中public boolean search(int target) {SkipListNode curNode = head;for (int i = level-1; i >= 0; i--) {while (curNode.levels[i] != null && curNode.levels[i].val < target) {curNode = curNode.levels[i];}}curNode = curNode.levels[0];return (curNode != null && curNode.val == target);}// 插入一个元素到跳表。public void add(int num) {SkipListNode curNode = head;// 记录每层能访问的最右节点SkipListNode[] levelTails = new SkipListNode[MAX_LEVEL];for (int i = level-1; i >= 0; i--) {while (curNode.levels[i] != null && curNode.levels[i].val < num) {curNode = curNode.levels[i];}levelTails[i] = curNode;}curNode = curNode.levels[0];if (curNode != null && curNode.val == num) {// 已存在,cnt 加1curNode.cnt++;} else {// 插入int newLevel = randomLevel();if (newLevel > level) {for (int i = level; i < newLevel; i++) {levelTails[i] = head;}level = newLevel;}SkipListNode newNode = new SkipListNode();newNode.val = num;newNode.cnt = 1;for (int i = 0; i < level; i++) {newNode.levels[i] = levelTails[i].levels[i];levelTails[i].levels[i] = newNode;}}}private int randomLevel() {int level = 1; // 注意思考此处为什么是 1 ?while (random.nextDouble() < p && level < MAX_LEVEL) {level++;}return level > MAX_LEVEL ? MAX_LEVEL : level;}// 在跳表中删除一个值,如果 num 不存在,直接返回false. 如果存在多个 num ,删除其中任意一个即可。public boolean erase(int num) {SkipListNode curNode = head;// 记录每层能访问的最右节点SkipListNode[] levelTails = new SkipListNode[MAX_LEVEL];for (int i = level-1; i >= 0; i--) {while (curNode.levels[i] != null && curNode.levels[i].val < num) {curNode = curNode.levels[i];}levelTails[i] = curNode;}curNode = curNode.levels[0];if (curNode != null && curNode.val == num) {if (curNode.cnt > 1) {curNode.cnt--;return true;}// 存在,删除for (int i = 0; i < level; i++) {if (levelTails[i].levels[i] != curNode) {break;}levelTails[i].levels[i] = curNode.levels[i];}while (level > 0 && head.levels[level-1] == null) {level--;}return true;} return false;}
}代码实现二
class Skiplist {int MAX_LEVEL = 16;int curLevel;Node head;public Skiplist() {curLevel = 1;head = new Node(-1);head.next_point = new Node[MAX_LEVEL];}public boolean search(int target) {Node temp = head;//从最顶层索引找for (int i = MAX_LEVEL - 1; i >=0; i--) {while (temp.next_point[i] != null && temp.next_point[i].val <= target) {if (temp.next_point[i].val == target)return true;elsetemp = temp.next_point[i];}}// 判断temp的下个节点是否满足条件if (temp.next_point[0] != null && temp.next_point[0].val == target)return true;return false;}public void add(int num) {int level = randomLevel(0.5);if (level > curLevel)curLevel = level;Node node = new Node(num);node.next_point = new Node[level];Node[] forward = new Node[level];Arrays.fill(forward, head);Node temp = head;// 找到前驱节点for (int i = level - 1; i >= 0; i--) {while (temp.next_point[i] != null && temp.next_point[i].val < num)temp = temp.next_point[i];forward[i] = temp;}// 更新连接for (int i = 0; i < level; i++) {node.next_point[i] = forward[i].next_point[i];forward[i].next_point[i] = node;}}public boolean erase(int num) {Node[] forward = new Node[curLevel];Node temp = head;for (int i = curLevel - 1; i >= 0; i--) {while (temp.next_point[i] != null && temp.next_point[i].val < num)temp = temp.next_point[i];forward[i] = temp;}boolean res = false;if (temp.next_point[0] != null && temp.next_point[0].val == num) {res = true;// 更新连接for (int i = curLevel - 1; i >= 0; i--)if (forward[i].next_point[i] != null && forward[i].next_point[i].val == num)forward[i].next_point[i] = forward[i].next_point[i].next_point[i];}// 删除孤立节点层while (curLevel > 1 && head.next_point[curLevel - 1] == null)curLevel -= 1;return res;}public int randomLevel(double p) {int level = 1;while (Math.random() < p && level < MAX_LEVEL)level++;return level;}
}class Node {int val;Node[] next_point;public Node(int val) {this.val = val;}
}相关文章:
LeetCode 1206. 实现跳表
不使用任何库函数,设计一个跳表。 跳表是在 O(log(n)) 时间内完成增加、删除、搜索操作的数据结构。跳表相比于树堆与红黑树,其功能与性能相当,并且跳表的代码长度相较下更短,其设计思想与链表相似。 例如,一个跳表包…...
离散数学_九章:关系(2)
9.2 n元关系及其应用 1、n元关系,关系的域,关系的阶2、数据库和关系 1. 数据库 2. 主键 3. 复合主键 3、n元关系的运算 1. 选择运算 (Select) 2. 投影运算 (Project) 3. 连接运算 (Join) n元关系:两个以上集合的元素间的关系 1、n元关系…...

[ubuntu][原创]通过apt方式去安装libnccl库
ubuntu18.04版本安装流程: wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64/cuda-ubuntu1804.pin sudo mv cuda-ubuntu1804.pin /etc/apt/preferences.d/cuda-repository-pin-600 sudo apt-key adv --fetch-keys https://develo…...

YonLinker连接集成平台构建新一代产业互联根基
近日,由用友公司主办的“2023用友BIP技术大会“在用友产业园(北京)盛大召开,用友介绍了更懂企业业务的用友BIP-iuap平台,并发布了全面数智化能力体系,助力企业升级数智化底座,加强加速数智化推进…...

泛型的详解
泛型的理解和好处 首先我们先来看看泛型的好处 1)编译时,检查添加元素的类型,提高了安全性 2)减少了类型转换的次数,提高效率[说明] 不使用泛型 Dog -> Object -> Dog//放入到ArrayList 会先转成Object,在取出时&#x…...

用科技创造未来!流辰信息技术助您实现高效办公
随着社会的迅猛发展,科技的力量无处不见。它正在悄悄地改变整个社会,让人类变得进步和文明,让生活变得便捷和高效。在办公自动化强劲发展的今天,流辰信息技术让通信业、电网、汽车、物流等领域的企业实现了高效办公,数…...

基于R语言APSIM模型
随着数字农业和智慧农业的发展,基于过程的农业生产系统模型在模拟作物对气候变化的响应与适应、农田管理优化、作物品种和株型筛选、农田固碳和温室气体排放等领域扮演着越来越重要的作用。 APSIM (Agricultural Production Systems sIMulator)模型是世界知名的作物…...

块状链表实现BigString大字符串操作(golang)
前言 块状链表是介于链表和数组之间的数据结构,能够在 O ( n ) O(\sqrt{n}) O(n )时间内完成插入、删除、访问操作。 数据结构如图所示。假设最大容量为 n n n, 则它有一个长度为 s n s\sqrt{n} sn 的链表。链表中每个结点是一个长度为 2 n 2 \times \sqrt{…...
)
项目问题记录(持续更新)
1.在 yarn install的时候报 error achrinza/node-ipc9.2.2: The engine "node" is incompatible with this module. Expected version "8 || 10 || 12 || 14 || 16 || 17". Got "20.1.0" error Found incompatible module.需要执行 yarn config…...
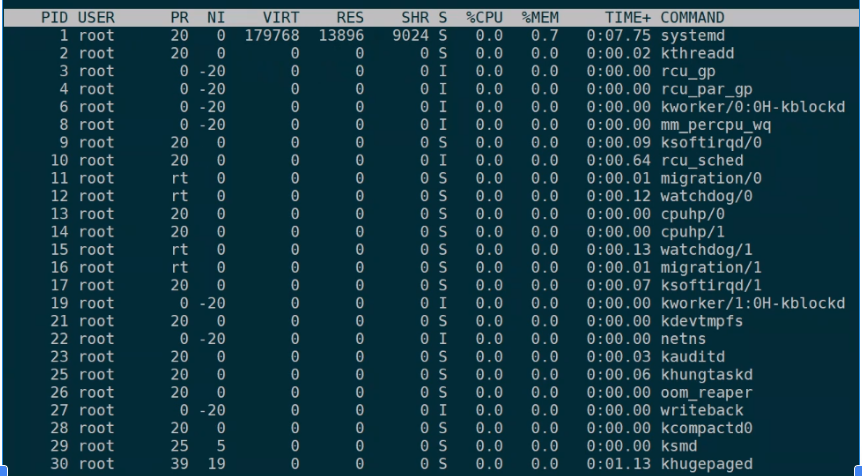
Linux的进程
目录 一、进程占用的内存资源 二、进程的系统环境 三、进程一直在切换 四、父进程和子进程 五、进程状态 六、查看进程 1.ps -ef 列出所有进程 2.ps -lax 列出所有进程 3.ps aux列出所有进程 4.树形列出所有进程 七、作业(用来查看管理进程) …...

与其焦虑被 AI 取代或猜测前端是否已死, 不如看看 vertical-align 扎实你的基础!!!
与其焦虑被 AI 取代或猜测前端是否已死, 不如看看 vertical-align 扎实你的基础!!! vertical-align 设置 display 值为 inline, inline-block 和 table-cell 的元素竖直对齐方式. 从 line-height: normal 究竟是多高说起 我们先来看一段代码, 分析一下为什么第二行的行高, 也就…...

路由、交换机、集线器、DNS服务器、广域网/局域网、端口、MTU
前言:网络名词术语解析(自行阅读扫盲),推荐大家去读户根勤的《网络是怎样连接的》 路由(route): 数据包从源地址到目的地址所经过的路径,由一系列路由节点组成。某个路由节点为数据包选择投递方向的选路过程。 路由器工作原理 路…...

在全志V851S开发板上进行屏幕触摸适配
1.修改屏幕驱动 从ft6236 (删掉,不要保留),改为下面的 路径:/home/wells/tina-v853-open/tina-v853-open/device/config/chips/v851s/configs/lizard/board.dts(注意路径,要设置为自己的实际路…...

字符串拷贝时的内存重叠问题
字符串拷贝时的内存重叠问题 1.什么是内存重叠 拷贝的目的地址在源地址的范围内,有重叠。 如在写程序的过程中,我们用到的strcpy这个拷贝函数,在这个函数中我们定义一个目的地址,一个源地址,在拷贝的过程中如果内存重…...
告别PPT手残党!这6款AI神器,让你秒变PPT王者!
如果你是一个PPT手残党,每每制作PPT总是让你焦头烂额,那么你一定需要这篇幽默拉风的推广文案! 我向你保证,这篇文案将帮助你发现6款AI自动生成PPT的神器,让你告别PPT手残党的身份,成为一名PPT王者。 无论…...

JVM配置与优化
参考: JVM内存分区及作用(JDK8) https://blog.csdn.net/BigBug_500/article/details/104734957 java 进程占用系统内存过高分析 https://blog.csdn.net/fxh13579/article/details/104754340 Java之jvm和线程的内存 https://blog.csdn.ne…...

电力系统储能调峰、调频模型研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

C++基础之类、对象一(类的定义,作用域、this指针)
目录 面向对象的编程 类的引入 简介 类的定义 简介 访问限定符 命名规则 封装 简介 类的作用域 类的大小及存储模型 this指针 简介 面向对象的编程 C与C语言不同,C是面向对象的编程,那么什么是面向对象的编程呢? C语言编程,规定…...

javaScript---设计模式-封装与对象
目录 1、封装对象时的设计模式 2、基本结构与应用示例 2.1 工厂模式 2.2 建造者模式 2.3 单例模式 封装的目的:①定义变量不会污染外部;②能作为一个模块调用;③遵循开闭原则。 好的封装(不可见、留接口):①…...
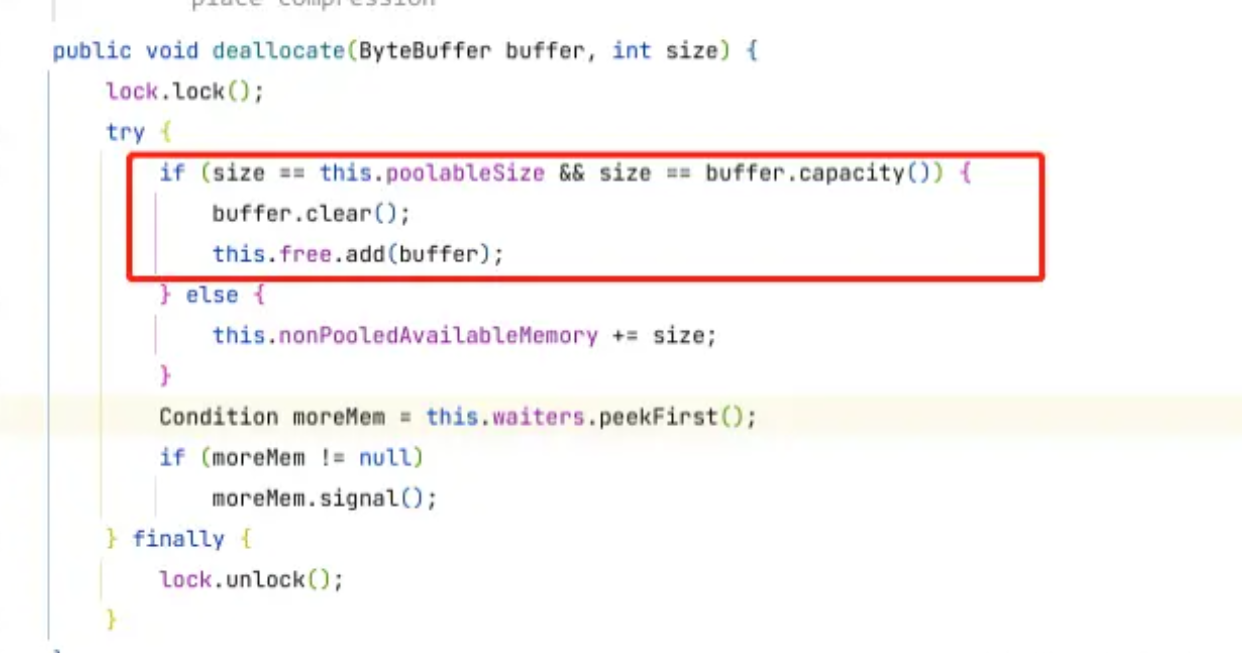
【消息中间件】kafka高性能设计之内存池
文章目录 前言实现创建内存池分配内存释放内存 总结 前言 Kafka的内存池是一个用于管理内存分配的缓存区域。它通过在内存上保留一块固定大小的内存池,用于分配消息缓存、批处理缓存等对象,以减少频繁调用内存分配函数的开销。 Kafka内存池的实现利用了…...

AI助手开发实战:从资源索引到生产级系统搭建指南
1. 项目概述:一个为AI助手开发者准备的“藏宝图” 如果你正在开发一个AI助手应用,或者正打算将大语言模型的能力集成到你的产品里,那你大概率会遇到一个经典难题:面对市面上眼花缭乱的模型、API和工具,我到底该怎么选&…...
实战:从零部署企业级WEB前后端项目)
TongWEB(东方通)实战:从零部署企业级WEB前后端项目
1. 环境准备:银河麒麟系统下的基础搭建 在银河麒麟桌面系统V10(SP1)兆芯版上部署企业级WEB项目,环境准备是第一步。我遇到过不少开发者直接跳过环境检查就急着部署,结果浪费大量时间排查兼容性问题。这里分享几个关键点: 首先是系…...

3DS游戏格式转换神器:5分钟让.3ds文件变身为可安装的CIA
3DS游戏格式转换神器:5分钟让.3ds文件变身为可安装的CIA 【免费下载链接】3dsconv Python script to convert Nintendo 3DS CCI (".cci", ".3ds") files to the CIA format 项目地址: https://gitcode.com/gh_mirrors/3d/3dsconv 还在为…...

【HarmonyOS 6.1 全场景实战】《灵犀厨房》之【营养分析引擎】计算个性化卡路里建议:给《灵犀厨房》装上“营养大脑”
【营养分析引擎】计算个性化卡路里建议:给《灵犀厨房》装上“营养大脑” 摘要:从“爱吃什么”到“该吃什么”,是《灵犀厨房》进化的关键一步。上一篇我们刚打通了 Health Kit 数据,今天,我们就要基于 Mifflin-St Jeor …...

跨越平台限制:如何用WorkshopDL免费获取Steam创意工坊模组
跨越平台限制:如何用WorkshopDL免费获取Steam创意工坊模组 【免费下载链接】WorkshopDL WorkshopDL - The Best Steam Workshop Downloader 项目地址: https://gitcode.com/gh_mirrors/wo/WorkshopDL 还在为Epic Games或GOG平台无法访问Steam创意工坊而烦恼吗…...

Steam成就管理器终极指南:3步修复错失的游戏成就
Steam成就管理器终极指南:3步修复错失的游戏成就 【免费下载链接】SteamAchievementManager A manager for game achievements in Steam. 项目地址: https://gitcode.com/gh_mirrors/st/SteamAchievementManager Steam Achievement Manager(SAM&a…...

从零构建可定制对话系统:模块化架构与RAG实战指南
1. 项目概述:从零构建一个可定制的对话系统最近在折腾一个挺有意思的东西,我把它叫做“定制化聊天系统”。起因很简单,市面上现成的聊天机器人,无论是开源的还是商业的,总感觉差了那么点意思。要么是功能太臃肿&#x…...
用户指引自助教学源码—东方仙盟)
未来之窗昭和仙君(九十三)用户指引自助教学源码—东方仙盟
代码<!DOCTYPE html> <html lang"zh-CN"> <head> <meta charset"UTF-8"> <meta http-equiv"X-UA-Compatible" content"IEedge,chrome1"> <title>你的导师-未来之窗</title> <style>*…...

蜘蛛池技术解析:网站收录提速的关键工具与运营策略
在搜索引擎优化领域,蜘蛛池是助力网站收录提速的重要辅助工具,尤其适配新站、低权重站或海量内容站,能有效破解收录慢、收录少、深层页面难抓取等痛点。本文从技术原理、核心价值、搭建要点及合规运营策略四方面,全面解析蜘蛛池的…...

开源婚礼技能库:用项目管理思维破解备婚焦虑,打造个性化高性价比婚礼
1. 项目概述:婚礼技能库的诞生与价值最近在GitHub上看到一个挺有意思的项目,叫“awesome-wedding-skills”。光看名字,你可能会觉得这又是一个普通的“awesome”系列资源列表,无非是收集一些婚礼策划、摄影、化妆的链接。但当我点…...