【消息中间件】kafka高性能设计之内存池
文章目录
- 前言
- 实现
- 创建内存池
- 分配内存
- 释放内存
- 总结
前言
Kafka的内存池是一个用于管理内存分配的缓存区域。它通过在内存上保留一块固定大小的内存池,用于分配消息缓存、批处理缓存等对象,以减少频繁调用内存分配函数的开销。
Kafka内存池的实现利用了Java NIO中的 ByteBuffer。当需要创建一个新的缓存对象时,内存池会取出一块固定大小的内存块,并在存储内存池对象的池中保存该内存块的引用。当该内存块不再被使用时,内存池将把它收回,以供下一次使用。
使用内存池可以提高Kafka生产者的性能,因为对象kafka这样的消息中间件,需要频繁地创建对象,我们知道频繁地创建对象很消耗内存,使用内存池可以减少内存的消耗,此外,内存池还可以减少内存碎片的产生,提高内存使用效率。
实现
下面我们从几个方面来对象内存池的实现进行详细介绍。
创建内存池
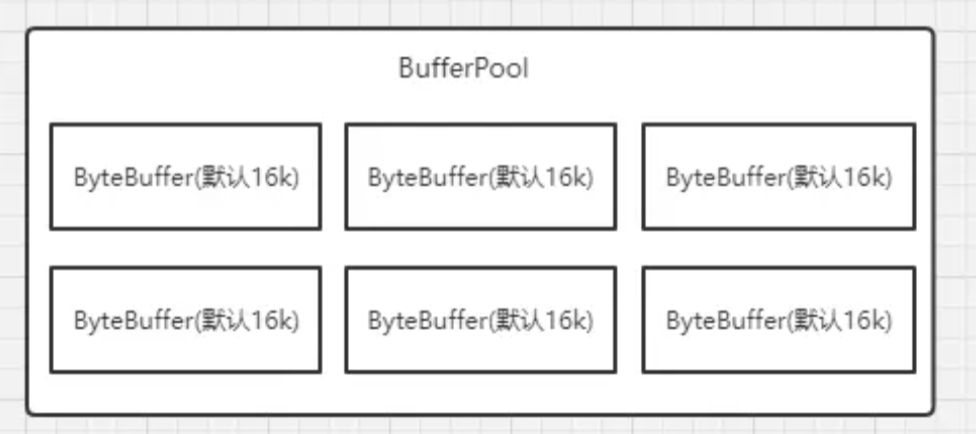
在kafka初始化的时候,会对内存池进行初始化,在Kafka Producer端,有一个BufferPool,与它相关的配置参数是buffer.memory和batch.size,buffer.memory它代表缓冲区内存的大小,默认为32M,batch.size代表消息批次的大小,默认为16kb,在BufferPool中,batch.size其实就是代表一个ByteBuffer的大小,因为BufferPool只管理batch.size大小的ByteBuffer,在kafka初始化的时候,就会创建缓冲区(new BufferPool),如下,在创建消息收集器RecordAccumulator的时候,就创建了BufferPool。
this.accumulator = new RecordAccumulator(logContext,batchSize,this.compressionType,lingerMs(config),retryBackoffMs,deliveryTimeoutMs,partitionerConfig,metrics,PRODUCER_METRIC_GROUP_NAME,time,apiVersions,transactionManager,new BufferPool(this.totalMemorySize, batchSize, metrics, time, PRODUCER_METRIC_GROUP_NAME));
分配内存
我们知道kafka的消息不是直接发送到broker,而是先发送到消息收集器RecordAccumulator,而消息发送到RecordAccumulator,是需要先申请内存的,如果消息的大小大于内存池BufferPool的大小,那么这是不允许的,会抛出异常,比如我的消息的大小时40M,但是内存池的大小是32M,那么显然BufferPool装不下消息,就会报错。
我们说了消息是被存储在队列中,以ProducerBatch的形式,当发送消息时,获取分区对应的队列,入队队列不存在,就创一个队列,这个队列就是装ProducerBatch的队列,为Deque,然后从队列中取出一个ProducerBatch,如果存在ProducerBatch,那么
就判断这个ProducerBatch是否足够装得下消息,如果能够装得下,那么就将消息装入,如果装不下,那么就重新创建一个ProducerBatch,然后将消息加入新创建的这个ProducerBatch,最后将这个ProducerBatch加入队列中,然后释放掉ProducerBatch,其实就是释放掉ByteBuffer中的ProducerBatch,因为ProducerBatch本身就是由ByteBuffer来进行承载。
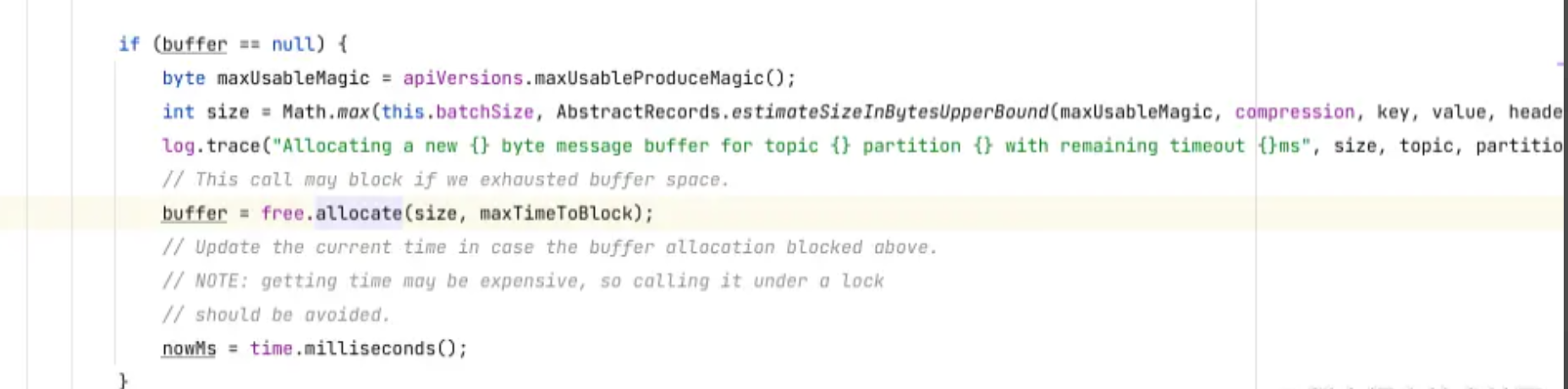
如果消息的长度大于16kb(注意,这个16kb是batch.size参数的默认值,如果我们对batch.size进行设置,那么就按照我们设置的值来算),那么就按消息的实际大小来进行创建,如果小于或等于16kb,那么就按照16kb来进行创建,如下代码所示,会将batchSize和我们消息的大小进行比较,选出最大的,然后去分配Buffer。
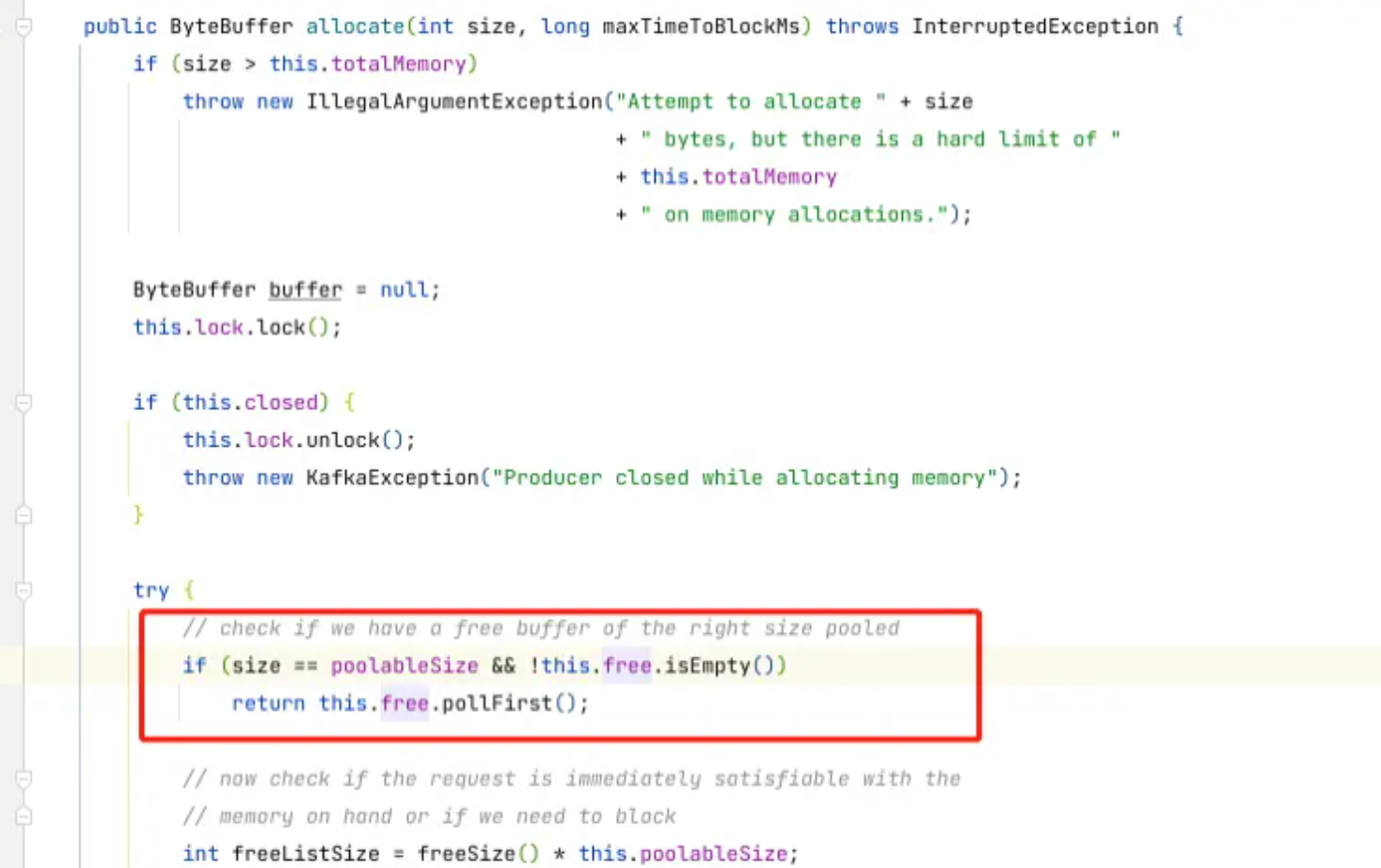
我们知道ProducerBatch是放在ByteBuffer中,所以在创建ProducerBatch的时候,会去申请一个ByteBuffer,如果我们的消息小于或者等于batch.size(默认为16kb),那么就会去缓冲池BufferPool中取一块ByteBuffer来给ProducerBatch使用,如上图所示,这些ByteBuffer都被缓冲池BufferPool管理起来,如果我们的消息大于batch.size,那么就无法使用缓冲池中的ByteBuffer了。如下,在allocate方法中,如果我们消息所需要的ByteBuffer的大小等于poolableSize并且BufferPool中存在ByteBuffer,那么久直接从BufferPool的队列中获取一个ByteBuffer,poolableSize其实就是batch.size。
释放内存
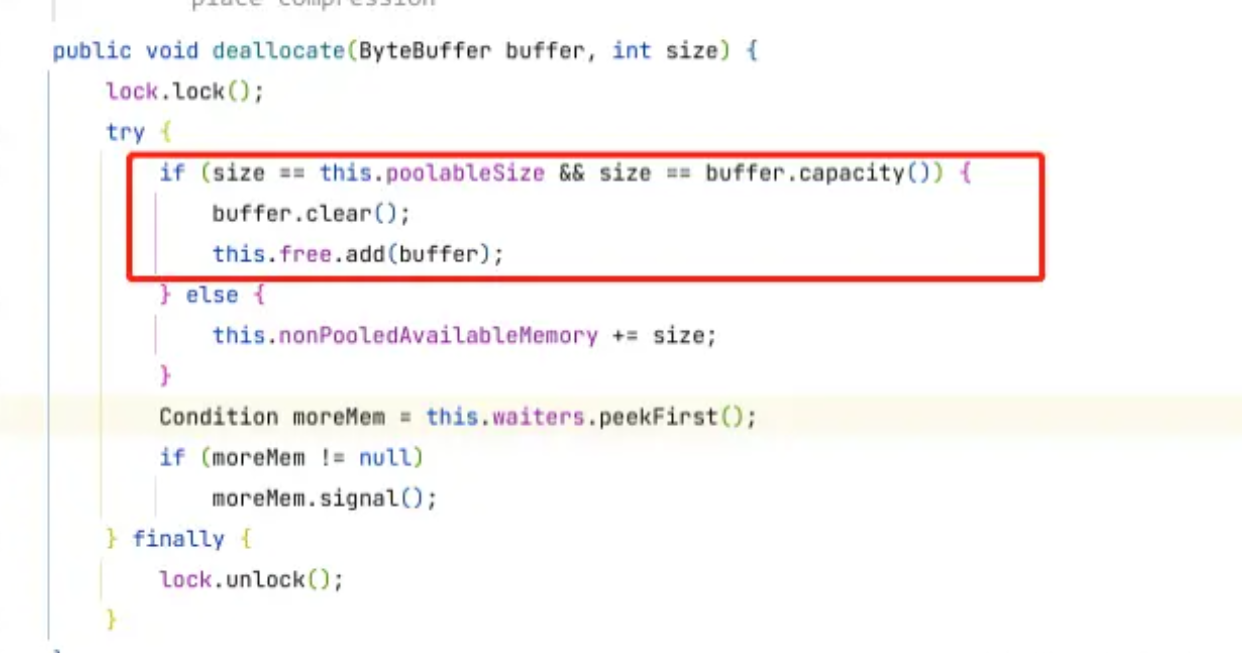
当我们消息发送完以后,就需要释放ByteBuffer,然后再将ByteBuffer加入到BufferPool中,以供后面使用,注意,只有batch.size大小的ByteBuffer才能加入BufferPool中,后面才能复用,大于batch.size的ByteBuffer不能加入BufferPool中,大于batch.size的则和非缓冲池的内存有关,和nonPooledAvailableMemory这个值有关,就不去详细说它,如下,通过buffer.clear()清空ByteBuffer,然后将清空后的buffer加入队列中。
总结
上面我们对kafka的为什么使用内存池,使用内存池的好处进行了分析,然后对它怎么实现进行了分析,分别从创建,使用和释放去进行详细说明,不过我们应该记住的是,kafka使用内存池的条件是我们的消息的大小必须小于等于batch.size的值,这样内存池才能发挥它的作用,如果我们的消息很大,然而也没对batch.size进行设置,使用的是默认值,那么将不能使用内存池,不能发挥它的性能。
相关文章:
【消息中间件】kafka高性能设计之内存池
文章目录 前言实现创建内存池分配内存释放内存 总结 前言 Kafka的内存池是一个用于管理内存分配的缓存区域。它通过在内存上保留一块固定大小的内存池,用于分配消息缓存、批处理缓存等对象,以减少频繁调用内存分配函数的开销。 Kafka内存池的实现利用了…...
)
创建型模式——单例(singleton)
1. 模式说明 单例模式保证类只有一个实例;创建一个对象,当你创建第二个对象的时候,此时你获取到的是已经创建过的对象,而不是一个新的对象; 1.1 使用场景 共享资源的访问权限;任务的管理类;数…...

算法:迷宫问题
描述 定义一个二维数组 N*M ,如 5 5 数组下所示: int maze[5][5] { 0, 1, 0, 0, 0, 0, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 0, 0, 0, 0, 1, 0, }; 它表示一个迷宫,其中的1表示墙壁,0表示可以走的路,只能横着走或…...
聊聊并发编程的12种业务场景
前言 并发编程是一项非常重要的技术,无论在面试,还是工作中出现的频率非常高。 并发编程说白了就是多线程编程,但多线程一定比单线程效率更高? 答:不一定,要看具体业务场景。 毕竟如果使用了多线程&…...

MySQL执行顺序
MySQL执行顺序 MySQL语句的执行顺序也是在面试过程中经常问到的问题,并且熟悉执行顺序也有助于SQL语句的编写。 SELECT FROM JOIN ON WHERE GROUP BY HAVING ORDER BY LIMIT执行顺序如下: FROM ON JOIN WHERE GROUP BY # (开始使用别名) SUM # SUM等…...

引领真无线耳机未来趋势,NANK南卡OE骨传导真无线耳机惊艳亮相
传统的蓝牙耳机存在很多问题,例如续航时间短、长期佩戴耳朵会不舒服,甚至影响听力等等。为了解决这些问题,在骨传导领域深耕十多年的南卡品牌推出了这款真无线骨传导耳机——NANK南卡 OE。 NANK南卡OE即将正式上线,这一消息一经宣…...

5款写作神器,帮助你写出5w+爆款文案,好用到哭
我不允许还有文案小白、新手博主不知道这5款写作利器! 每次一写文案就头秃的新媒体工作者,赶紧看过来吧!这5款好用到爆的写作神器,喝一杯咖啡的时间就能完成写作。 我和同事都是用它们,出了很多的爆款,现…...
相交链表问题
给你两个单链表的头节点 headA 和 headB ,请你找出并返回两个单链表相交的起始节点。如果两个链表不存在相交节点,返回 null 。 图示两个链表在节点 c1 开始相交: 题目数据 保证 整个链式结构中不存在环。 注意,函数返回结果后&…...

[ubuntu] ax200网卡虚接,导致系统根目录占满而无法进入系统的奇葩问题
20230508,我像往常一样,打开电脑发现根目录满了,报警了,所以按照网上的教程,清理了一下根目录的文件,没想到背后是网卡问题… 文章目录 1.进入终端模式2.查看占用情况3.清理系统log文件3.1 清理/var/log/syslog3.2 清…...

本地字体库的引入方法
本地字体库是指在计算机系统中存储的一组字体文件,通常包含多种字体格式,如TTF、OTF、WOFF等。引入本地字体库可以让用户在使用计算机时可以选择不同的字体,从而提高用户的使用体验。 本地字体库的引入方式有多种,其中比较常用的是…...

7种优秀的导航菜单设计总结
导航是应用程序界面中最常见的模块之一,在链接应用程序中起着每个页面的作用。 不同的设计需求和业务目标决定了导航的设计因品而异,移动设备的尺寸远小于计算机。因此,在设计移动终端导航时,应考虑更全面,以确保简单…...
)
Problem E. 矩阵游戏 (2023年ccpc河南省赛)
原题链接: https://codeforces.com/gym/104354 题意: 有一个n*m的矩阵,只有三种字符:0,1和?。从[1,1]走到[n,m],每次只能向下走或者向下走。当走到1的时候得一分,走到0的时候不得分,走到?的时候可以将他…...
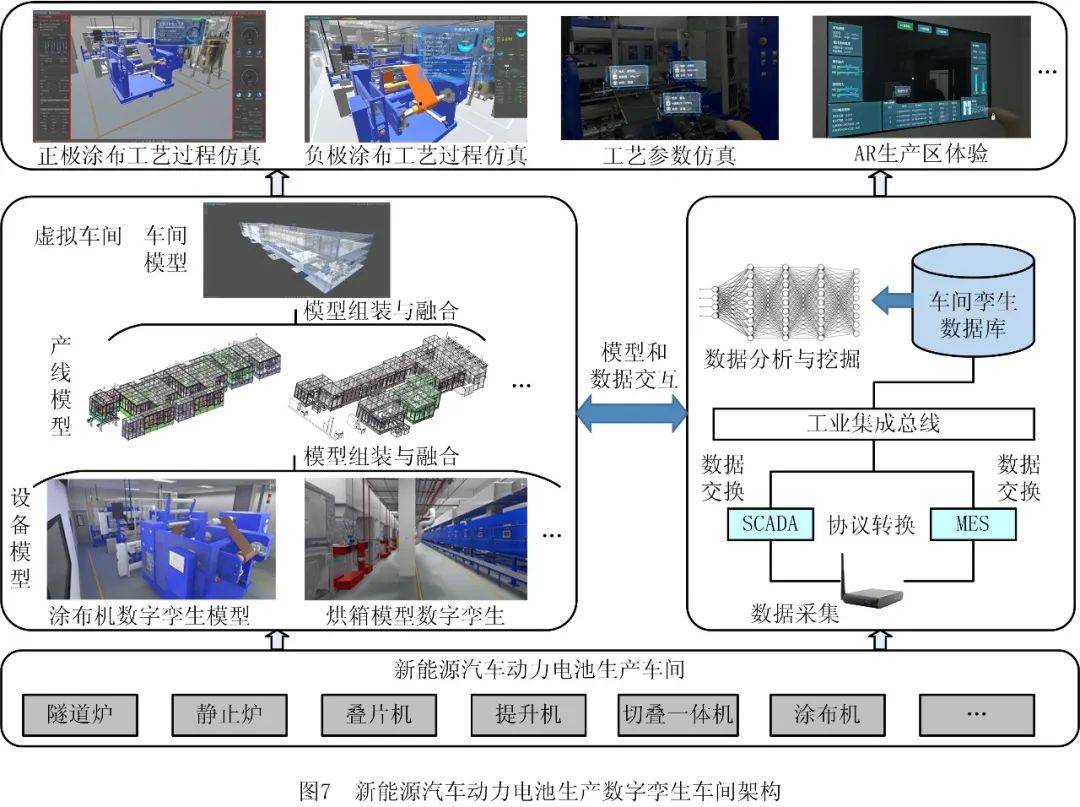
数字孪生模型构建理论及应用
源自:计算机集成制造系统 作者:陶飞 张贺 戚庆林 徐 俊 孙铮 胡天亮 刘晓军 刘庭煜 关俊涛 陈畅宇 孟凡伟 张辰源 李志远 魏永利 朱铭浩 肖斌 摘 要 数字孪生作为实现数字化转型和促进智能化升级的重要使能途径,一直备受各…...

Vue面试题:30道含答案和代码示例的练习题
Vue中的双向数据绑定是怎么实现的? 双向数据绑定通过使用v-model指令实现。v-model指令会在表单元素上创建一个监听器,在用户输入时实时更新Vue实例的数据,并且在Vue实例数据变化时更新表单元素的值。 如何在Vue中定义一个方法?…...
)
2023-05-09 LeetCode每日一题(有效时间的数目)
2023-05-09每日一题 一、题目编号 2437. 有效时间的数目二、题目链接 点击跳转到题目位置 三、题目描述 给你一个长度为 5 的字符串 time ,表示一个电子时钟当前的时间,格式为 “hh:mm” 。最早 可能的时间是 “00:00” ,最晚 可能的时间…...
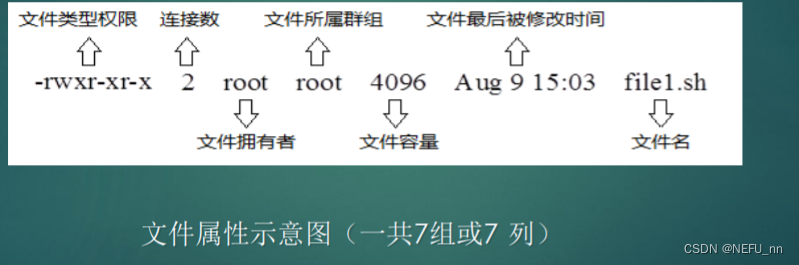
第三节课 Linux文件权限
目录 文件属性详解 权限修改 文件所有者与属组修改 文件默认权限修改 Linux是多人多任务的操作系统,因此可能常常会有多人使用一台机器, 为了考虑每个人的隐私、方便用户合作,每个文件都有三类用户,权限是基于这三类用户设定的…...

开发STC89C51系列单片机需要的单片机技术
端口操作:控制单片机的输入输出端口,与外界进行通信。中断优先级:当多个中断同时发生时,确定哪个中断优先级更高,优先响应。时钟模块:控制单片机的时钟,可以精确计时。PWM技术:实现模…...
)
分布式键值存储是什么?(分布式键值存储大值)
文章目录 什么是分布式键值存储?分布式键值存储“大值”指什么? 什么是分布式键值存储? 分布式键值存储是一种分布式数据存储系统,它将数据存储为键值对的形式,并将这些键值对分散在多个节点上。每个节点都可以独立地…...
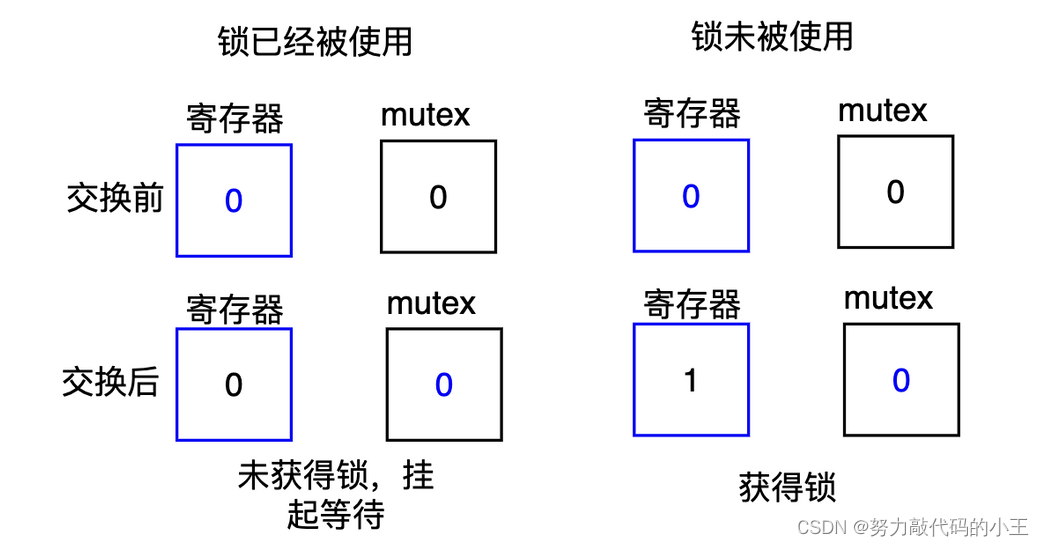
多线程(线程同步和互斥+线程安全+条件变量)
线程互斥 线程互斥: 任何时刻,保证只有一个执行流进入临界区访问临界资源,通常对临界资源起到保护作用 相关概念 临界资源: 一次仅允许一个进程使用的共享资源临界区: 每个线程内部,访问临界资源的代码&am…...

Flutter学习——开发Flutter需要的技能
第二章 Flutter开发所需要掌握的知识 文章目录 第二章 Flutter开发所需要掌握的知识前言一、开发语言Dart语言Android/Ios知识 二、组件学习三、调试与性能优化总结 前言 上一章,介绍了Flutter的来源和平台支持及特点,这一章,来梳理一下学习…...

Simulink 模型注释实战指南:从静态标注到动态交互
1. Simulink注释的进阶价值:从说明书到智能助手 第一次打开Simulink模型时,我常被密密麻麻的连线图吓到——就像面对一本没有目录的教科书。直到学会用注释做"书签",才发现原来模型可以像交互式电子书一样友好。注释不只是写备注的…...

法律AI实战:基于OpenCLAW构建破产法智能辅助系统
1. 项目概述与核心价值最近在整理一些法律实务相关的工具和资源,发现了一个挺有意思的项目,叫“zhang-bankruptcy-law”。虽然项目描述和正文信息不多,但从项目名称和关键词来看,这应该是一个聚焦于中国破产法领域的知识库或技能工…...
)
SAP S/4HANA数据迁移,别再死磕LSMW了!手把手教你激活Migration Cockpit (LTMC/LTMOM)
SAP S/4HANA数据迁移:从LSMW到Migration Cockpit的技术跃迁 当SAP ECC用户首次接触S/4HANA时,数据迁移工具的选择往往成为第一个认知断层。那些在ECC时代熟练使用LSMW(Legacy System Migration Workbench)的顾问们,突然…...

实战AI智能体技能库:设计、Telegram连接、多智能体协同与知识库部署
1. 项目概述:一个实战派AI智能体技能库如果你正在寻找一套能直接部署、经过生产环境验证的AI智能体技能,那么你找对地方了。今天要聊的这个项目,是我在运行一个多智能体系统近一年后,沉淀下来的核心资产。它不是实验室里的玩具&am…...

douyin-downloader抖音下载器:如何高效批量下载去水印视频的完整指南
douyin-downloader抖音下载器:如何高效批量下载去水印视频的完整指南 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser …...

像素级实景映射,构建实景孪生底层新范式
副标题:自研硬核引擎矩阵,铸就镜像视界行业标杆内核前言数字经济深度赋能实体经济,数字孪生与视频孪生技术已成为智慧城市、工业管控、智慧安防等全域场景升级的核心支撑。当前行业多数方案仍沿用人工建模、静态渲染、视频贴图叠加的传统路径…...

基于API网关构建技能管理平台:架构设计与工程实践
1. 项目概述:一个面向技能管理的API网关最近在梳理团队内部的技术资产和成员技能图谱时,我一直在寻找一个轻量、灵活且能快速部署的解决方案。传统的技能管理要么依赖笨重的商业软件,要么就是散落在各种Excel表格和即时通讯工具的聊天记录里&…...

基于大语言模型的自我提升智能体:从执行-评估-学习闭环到工程实践
1. 项目概述与核心价值最近在GitHub上看到一个挺有意思的项目,叫“self-improving”,作者是Cat-tj。光看这个名字,你可能觉得有点抽象,但点进去之后,我发现它触及了一个非常核心且前沿的议题:如何让一个AI系…...

2026届学术党必备的五大降AI率神器解析与推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek DeepSeek系列论文展现出大规模语言模型的技术突破,其创新架构运用混合专家模型跟…...

Windows PDF处理工具:3分钟掌握Poppler预编译包全攻略
Windows PDF处理工具:3分钟掌握Poppler预编译包全攻略 【免费下载链接】poppler-windows Download Poppler binaries packaged for Windows with dependencies 项目地址: https://gitcode.com/gh_mirrors/po/poppler-windows 还在为Windows系统上的PDF处理烦…...