Neural Network学习笔记2
torch.nn:
Containers: 神经网络骨架
Convolution Layers 卷积层
Pooling Layers 池化层
Normalization Layers 正则化层
Non-linear Activations (weighted sum, nonlinearity) 非线性激活
Convolution Layers
Conv2d
torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode='zeros', device=None, dtype=None)
in_channels= : 输入图像的通道数
out_channels= : 输出图象的通道数
kernel_size=3: 3x3的卷积核,会在训练过程中不断调整
stride: 卷积核滑动的步长
padding: 在图像的纵向和横向填充 ,填充的地方一般默认为0,这样卷积核可以划过更多地方
padding_mode=zeros: padding时的填充值
dilation: 卷积核的对应位
groups
bias:偏置
卷积过程:

经典vgg16的卷积过程:

推导padding等参数的公式:

import torch
import torchvision
from torch import nn
from torch.nn import Conv2dfrom torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriterdataset = torchvision.datasets.CIFAR10("../dataset_transform",train=False, transform=torchvision.transforms.ToTensor(), download=True)
dataloader = DataLoader(dataset, batch_size=64)class Zrf(nn.Module):def __init__(self):super(Zrf, self).__init__()self.conv1 = Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=0)def forward(self, x):x = self.conv1(x)return x# 初始化网络
zrf = Zrf()
print(zrf)writer = SummaryWriter("conv2d")
step = 0
for data in dataloader:imgs, targets = dataoutput = zrf(imgs)print(imgs.shape)print(output.shape)# torch.Size([64, 3, 32, 32])writer.add_images("input_imgs", imgs, step)# torch.Size([64, 6, 30, 30]) ---> [xxx, 3, 30, 30]output = torch.reshape(output, (-1, 3, 30, 30))writer.add_images("output_imgs", output, step)step = step + 1
writer.close()
Pooling Layers
MaxPool2d
最大池化--->下采样(别称)
(池化层没有要优化的参数,只是形式上的卷积核)
kernel_size=3: 3x3的窗口,用来取最大值
stride: 窗口滑动的步长,默认值是kernel_size的大小
padding: 在图像的纵向和横向填充 ,填充的地方一般默认为0
dilation: 空洞卷积
return_indices: 通常来说不会用到
ceil_mode: 设置为True时,会使用ceil模式(不满3x3也取一个最大值)而不是floor模式(不满3x3就不取值 )
一般理解------ceil:向上取整,floor模式:向下取整
为什么要进行最大池化? 在保持数据特征的同时,减小数据量
import torch
import torchvision
from torch import nn
from torch.nn import MaxPool2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriterdataset = torchvision.datasets.CIFAR10(root="../dataset_transform", download=True, train=False, transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset, batch_size=64)# input = torch.tensor([[1, 2, 0, 3, 1],
# [0, 1, 2, 3, 1],
# [1, 2, 1, 0, 0],
# [5, 2, 3, 1, 1],
# [2, 1, 0, 1, 1]], dtype=torch.float32)
# input = torch.reshape(input, (-1, 1, 5, 5))
# print(input.shape)class Zrf(nn.Module):def __init__(self):super(Zrf, self).__init__()self.maxpool1 = MaxPool2d(kernel_size=3)def forward(self, x):output = self.maxpool1(x)return outputzrf = Zrf()
# output = zrf(input)
# print(output)
writer = SummaryWriter("log_maxpol")
step = 0
for data in dataloader:imgs, targets = datawriter.add_images("max_before", imgs, step)output = zrf(imgs)writer.add_images("max_afteer", output, step)step = step + 1
writer.close()Non-linear Activations
Relu:大于0取原值,小于0取0

Sigmoid:常用激活函数
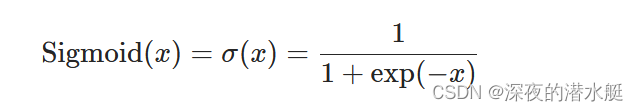
inplace参数
input = -1
Relu(input, inplace = True)
# 结果:input = 0input = -1
output = Relu(input, inplace = False)
# 结果:input = -1, output = 0import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriterinput = torch.tensor([[1, -0.5],[-1, 3]])
input = torch.reshape(input, (-1, 1, 2, 2))# print(input.shape)dataset = torchvision.datasets.CIFAR10(root="../dataset_transform", download=True, train=False, transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset, batch_size=64)class Zrf(nn.Module):def __init__(self):super(Zrf, self).__init__()# self.relu1 = nn.ReLU()self.sigmoid1 = nn.Sigmoid()def forward(self, input):# output = self.relu1(input)output = self.sigmoid1(input)return output# zrf = Zrf()
# output = zrf(input)
# print(output)zrf = Zrf()writer = SummaryWriter("log_sigmoid")
step = 0
for data in dataloader:imgs, targets = datawriter.add_images("before_sigmoid", imgs, step)output = zrf(imgs)writer.add_images("after_sigmoid", output, step)step = step + 1writer.close()线性层以及其他层介绍
Linear Layers
线性层,目的是变换特征维度,参数:in_features, out_features, bias (bool)
in_features:
out_features:
bias (bool):偏置
计算过程中的权重k和偏置b要按照一定条件进行调整和优化
Normalization Layers
正则化层:对输入进行正则化(注意:正则化不是归一化),有助于梯度下降,解决过拟合

num_feature(int): 输入图像的通道数层
affine(bool): 当设置为True时,该模块具有可学习的仿射参数,一般默认为True
Recurrent Layers
循环网络,多用于文字处理中
Transformers Layers
。。。21年大火
Dropout Layers
在训练过程中,会随机的把输入图像(tensor数据类型)中的元素以p的概率变成0
主要是为了防止过拟合
Sparse Layers
主要用于自然语言处理
Distance Functions
计算两个值之间的误差
Loss Functions
计算损失
相关文章:
Neural Network学习笔记2
torch.nn: Containers: 神经网络骨架 Convolution Layers 卷积层 Pooling Layers 池化层 Normalization Layers 正则化层 Non-linear Activations (weighted sum, nonlinearity) 非线性激活 Convolution Layers Conv2d torch.nn.Conv2d(in_channels, out_channels, ke…...

用@Value注解为bean的属性赋值
1.Value注解 Value注解的源码,如下所示 Target({ElementType.FIELD, ElementType.METHOD, ElementType.PARAMETER, ElementType.ANNOTATION_TYPE}) Retention(RetentionPolicy.RUNTIME) Documented public interface Value {String value(); }从Value注解的源码中…...

拨云见日:深入理解 HTML 解析器与有限状态机
文章目录 参考描述状态机状态机有限状态机与无限状态机有限状态机与自动售货机无限状态机与计算器 HTML 解析器HTML 解析器HTML 与有限状态机 HTML 解析器的常见状态初始状态DOCTYPE 状态注释状态标签状态开始标签状态属性状态属性名状态属性值状态 结束标签状态自闭和标签状态…...
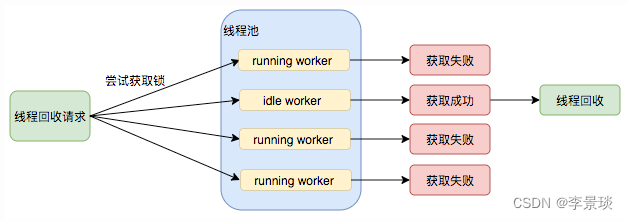
Java线程池及其实现原理
线程池概述 线程池(Thread Pool)是一种基于池化思想管理线程的工具,经常出现在多线程服务器中,如MySQL。 线程过多会带来额外的开销,其中包括创建销毁线程的开销、调度线程的开销等等,同时也降低了计算机…...
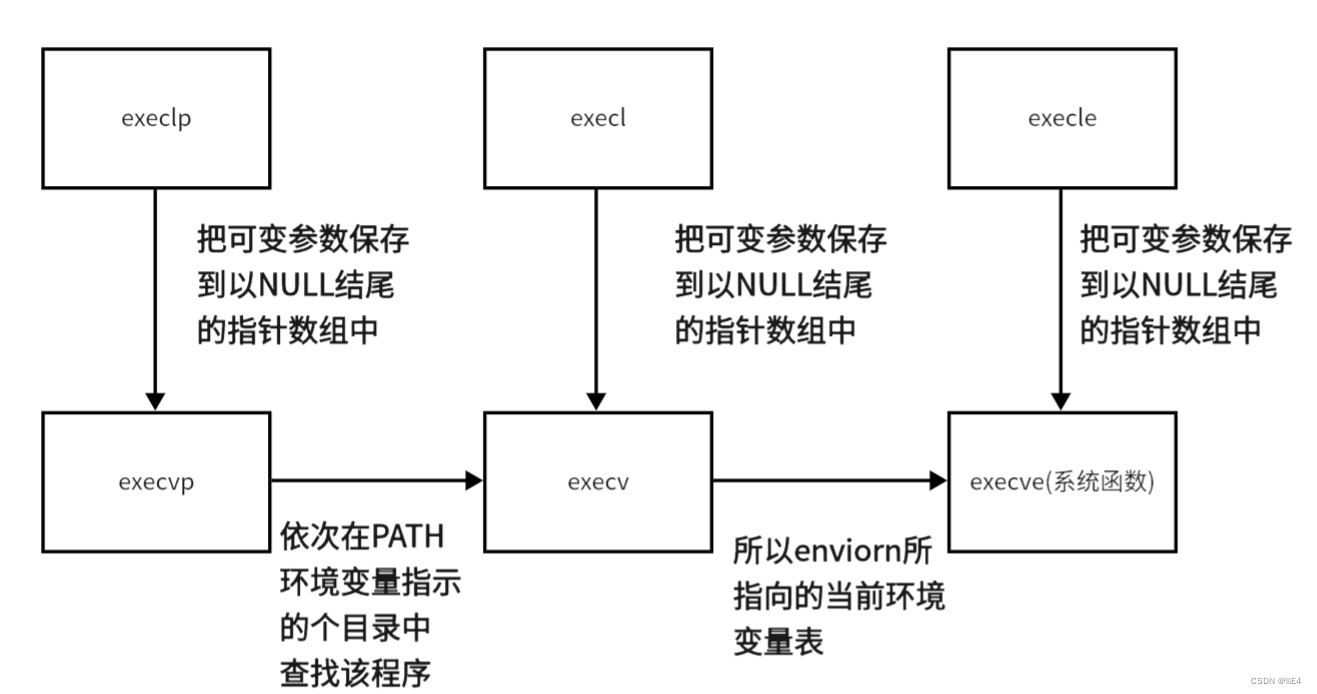
进程替换函数组介绍exec*
目录 前述 execl execlp execle execv execvp execvpe 前述 介绍后缀的意义: l (list):表示参数采用列表。 v(vector):参数同数组表示。 p(path):自…...
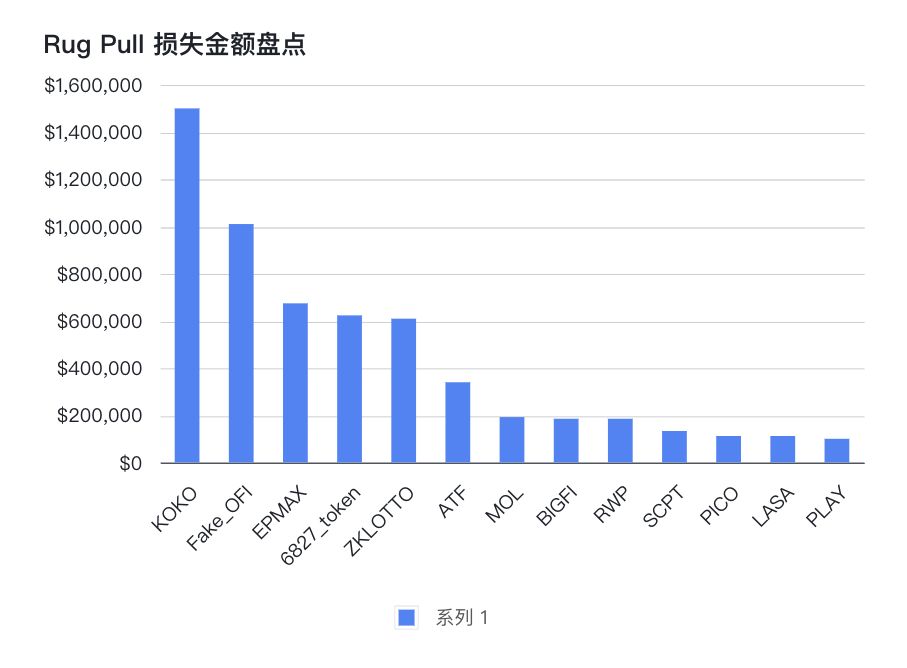
欧科云链OKLink:2023年4月安全事件盘点
一、基本信息 2023年4月安全事件共造约6000万美金的损失,与上个月相比,损失金额有所降落,但安全事件数量依旧不减。其中,Yearn Finance因参数配置错误,导致了1000多万美金的损失。同时,有一些已经出现过的…...

KubeVirt备份与还原方案【翻译】
KubeVirt备份与还原方案【翻译】 ref:https://github.com/kubevirt/kubevirt/blob/main/docs/backup-restore-integration.md 备份 为所有必需的k8s资源构建依赖关系图冻结应用程序pvc数据快照解冻应用程序将所有必需的k8s资源定义拷贝到一个共享的存储位置(可选…...
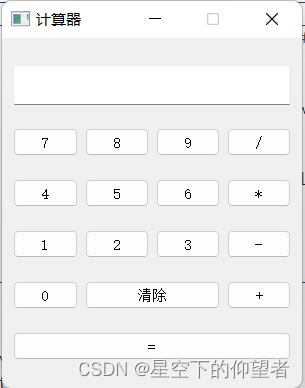
使用PyQt5设计一款简单的计算器
目录 一、环境配置: 二、代码实现 三、主程序 四、总结 本文使用PyQt5设计一款简单的计算器,可以通过界面交互实现加减乘除的功能,希望能够给初学者一些帮助。主要涉及的知识点有类的定义与初始化、类的成员函数、pyqt5的信号与槽函数等。…...

Htop使用说明
目录 引言 什么是htop htop安装 htop界面介绍 htop功能介绍 引言 我们使用服务器的时候常常需要关注下自己的程序资源占用情况,htop就是一种互动式的进程查查看器,整齐用下来感觉比top的逼格高,造作可视化都更方便些,我觉得还…...

PostgreSQL Linux安装
安装依赖: sudo yum -y install readline-devel zlib-devel 安装Postgres: ssh hadoophadoop001 #下载Postgres wget https://ftp.postgresql.org/pub/source/v14.2/postgresql-14.2.tar.gz tar -zxvf postgresql-14.2.tar.gz -C /data #编译前准备 /dat…...

亚商投资顾问 早餐FM/0509车辆电动化
01/亚商投资顾问 早间导读 1.上交所拟于5月11日举办“发现央企投资价值,促进央企估值回归”交流会 2.监管部门十方面举措加强房地产经纪行业管理 3.广东:推动城市公共服务及货运配送车辆电动化替代 4.昆山两楼盘因大幅降价被暂停网签:降幅…...

AI绘画天花板——Midjourney注册使用保姆级教程(5月5日验证有效)
大家好,我是可夫小子,关注AIGC、读书和自媒体。解锁更多ChatGPT、AI绘画玩法。加我,备注:aigc,拉你进群。 现在市面上AI绘图大概有三大阵营:Midjourney、Stable Diffusion,还有一个就是OpenAI实…...
项目结构描述 - manifest.json和pages.json)
学习笔记(2)项目结构描述 - manifest.json和pages.json
目录 1,manifest.json2,pages.json2.1,pages2.2,globalStyle2.3,tabBar 1,manifest.json 官方详情 uni-app 的 appid 由 DCloud 云端分配,主要用于 DCloud 相关的云服务,请勿自行修…...

vector、deque、list相关知识点
vector erase返回迭代器指向删除元素后的元素insert返回迭代器指插入的元素reserve只给容器底层开指定大小内存空间,并不添加新元素 deque 底层数据结构 动态开辟的二维数组,一维数组从2开始,以2倍方式扩容,每次扩容和&#x…...
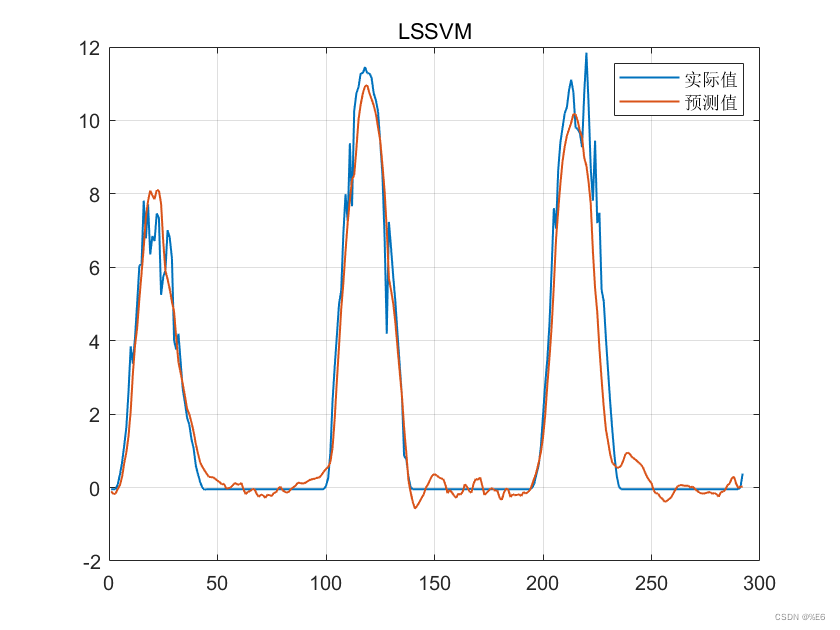
多维时序 | MATLAB实现基于VMD-SSA-LSSVM、SSA-LSSVM、VMD-LSSVM、LSSVM的多变量时间序列预测对比
多维时序 | MATLAB实现基于VMD-SSA-LSSVM、SSA-LSSVM、VMD-LSSVM、LSSVM的多变量时间序列预测对比 目录 多维时序 | MATLAB实现基于VMD-SSA-LSSVM、SSA-LSSVM、VMD-LSSVM、LSSVM的多变量时间序列预测对比预测效果基本介绍程序设计学习总结参考资料 预测效果 基本介绍 多维时序 …...
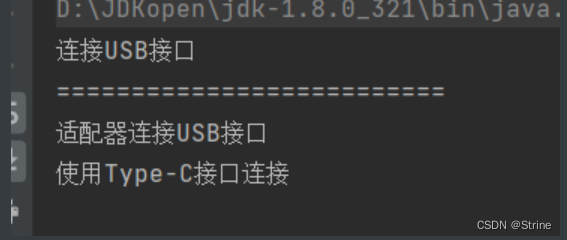
设计模式——适配器模式(类适配器、对象适配器)
是什么? 我们平时的有线耳机接口分为USB的和Type-C的接口,但是手机的耳机插口却只有一个,像华为的耳机插口现在基本都是Type-c的,那如果我们现在只有USB接口的耳机怎么办呢,这个时候就需要使用到一个转换器,…...

iOS开发多target
场景 背景:设想一下有一个场景,一个业务分为多种身份,他们大部分功能是相同的,但是也有自己的差异性。这种情况,想要构建出不同身份的APP。你会怎么做??? 当然,你可以拷贝一份代码出来,给项目重新命名。这样做的好处是,他们互相不会冲突,不用去关心是否有逻辑的冲…...

100种思维模型之每日评估思维模型-58
曾子曰:吾日三省吾省,为人谋而不忠乎?与朋友交不信乎?传不习乎? 曾国藩,坚持每日写复盘日记,最后他用自己的实践经历向我们证明:一个智商很平庸、出身很普通且有着各种毛病的人&…...

libreoffice api
libreOffice API是用于访问libreOffice的编程接口。可以使用libreOffice API创建、打开、修改和打印libreOffice文档。 LibreOffice API支持Basic、Java、C/C、Javascript、Python语言。 这是通过一种称为通用网络对象 (Universal Network Objects, UNO) 的技术实现的ÿ…...
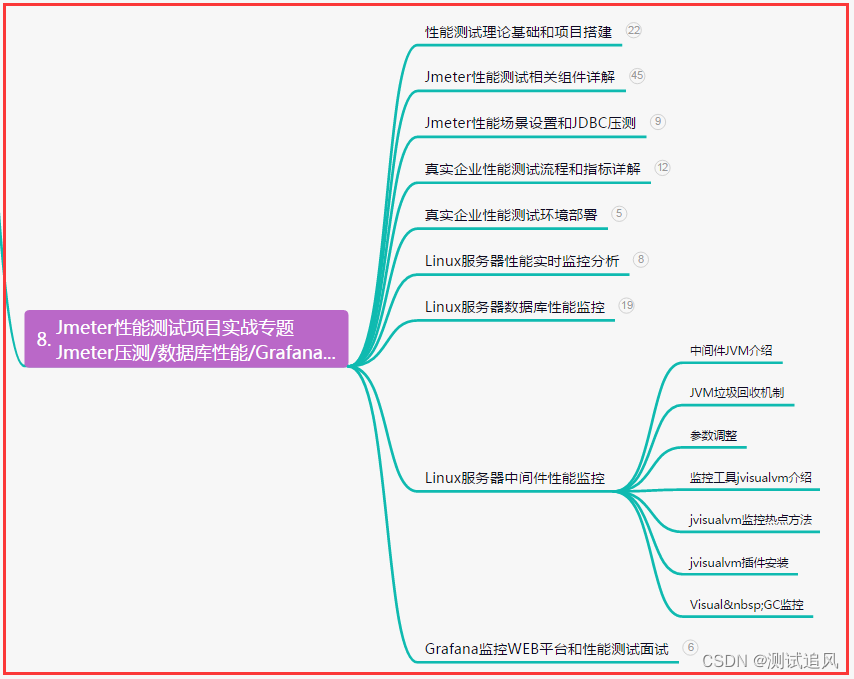
全网最火,Web自动化测试驱动模型详全,一语点通超实用...
目录:导读 前言一、Python编程入门到精通二、接口自动化项目实战三、Web自动化项目实战四、App自动化项目实战五、一线大厂简历六、测试开发DevOps体系七、常用自动化测试工具八、JMeter性能测试九、总结(尾部小惊喜) 前言 自动化测试模型&a…...

经典的网格寻路问题实例分析
经典的网格寻路问题消除墙砖 这一设置会导致地形发生变化,增加问题处理的难度。让我们先去掉这一要求,这样题目就简化成了经典的 网格寻路问题:给你一个 的网格,其中每个单元格不是 (空)就是 (障…...

SQL server 2017镜像库主从同步架构部署
SQL server 2017镜像库主从同步架构部署 目录: 1.主库配置 2.镜像库配置 3.检查状态 4.手工故障转移测试-主备切换 5.添加见证服务器实现自动主备切换 6.自动故障切换测试-主备切换角色 IP 状态 主机名 主库 192.168.56.120 可读写 sqldb2 镜像库(从库&a…...

手把手改造libmad:将一次性加载改为流式解码,拯救你的内存不足嵌入式系统
嵌入式音频革命:libmad流式解码改造实战指南 在资源受限的嵌入式环境中处理MP3音频,就像试图用吸管喝光整个游泳池的水——传统的一次性加载方式会让你的系统瞬间窒息。当树莓派Pico这类微控制器只有264KB的RAM时,一个5MB的MP3文件就能让内存…...

论文查重会查表格么?
会,但不是所有表格都按同一种方式查。先说结论:论文里的表格,学校查重一般是会处理的。只是“查到什么程度”,看系统。分几种情况说。1. Word里的可编辑表格:会查如果你的表格是这种:Word 直接插入的表格单…...
 全解析|运输包装容器振动测试标准完整版)
ASTM D999-08 (2015) 全解析|运输包装容器振动测试标准完整版
前言ASTM D999-08 (2015)《运输集装箱的振动测试》是全球运输包装领域最经典的正弦振动与往复冲击测试标准,覆盖往复冲击振动、单件共振、托盘 / 集合包装共振三大类测试场景,广泛用于评估包装在运输振动环境下的强度与防护能力,同时等效满足…...

Excel数据导入实战:为缺失ID列批量生成标准UUID
1. 为什么需要为Excel数据批量生成UUID? 最近在处理一个数据迁移项目时,遇到了一个典型问题:从Navicat导出的Excel表格缺少主键列,导致后续数据导入时频频报错。这种情况在数据迁移、系统对接时特别常见。UUID(通用唯…...
)
Perplexity环境新闻检索失效真相(2024最新API响应延迟根因分析)
更多请点击: https://kaifayun.com 第一章:Perplexity环境新闻搜索 Perplexity 是一款基于大语言模型的实时信息检索工具,其核心优势在于融合权威信源与上下文感知能力,特别适用于需要高时效性与高可信度的新闻类查询场景。在该环…...

废水污染源在线监测管理平台方案
某企业从事染整加工生产,属于环境监管重点单位,安装有废水自动处理系统,监控因子包括PH值、化学需氧量、氨氮、总氮等。但在某次巡查工作时发现,化学需氧量远远超过排放标准,但涉事企业却未上报排放超标的情况。因此要…...
)
嵌入式网络硬件设计避坑指南:如何为你的SOC选配合适的PHY芯片与接口(MII/RMII实战解析)
嵌入式网络硬件设计避坑指南:如何为你的SOC选配合适的PHY芯片与接口(MII/RMII实战解析) 在嵌入式系统设计中,网络功能已成为现代智能设备的标配需求。无论是工业控制、物联网终端还是消费电子产品,稳定可靠的网络连接往…...

学习规划需要定期调整吗?
在当今竞争激烈的教育环境中,学习规划对于学生的成长和发展起着至关重要的作用。作为一名在学习规划领域深耕十年的专家,我见证了无数学生在学习规划的指引下取得优异成绩,也看到了一些学生因为规划不合理而走了不少弯路。那么,学…...