PyTorch深度学习实战 | 基于线性回归、决策树和SVM进行鸢尾花分类

鸢尾花数据集是机器学习领域非常经典的一个分类任务数据集。它的英文名称为Iris Data Set,使用sklearn库可以直接下载并导入该数据集。数据集总共包含150行数据,每一行数据由4个特征值及一个标签组成。标签为三种不同类别的鸢尾花,分别为:Iris Setosa,Iris Versicolour,Iris Virginica。
对于多分类任务,有较多机器学习的算法可以支持。本文将使用决策树、线性回归、SVM等多种算法来完成这一任务,并对不同方法进行比较。
01、使用Logistic实现鸢尾花分类
在前面介绍过Logistic用于二分类任务,对其进行扩展也用于多分类任务。下面将使用sklearn库完成一个基于Logistic的鸢尾花分类任务。如代码清单1所示,首先是导入sklearn.datasets包从而加载数据集,并将数据集按照测试集占比0.2随机分为训练集和测试集。
代码清单1 导入包以及加载数据集
rom sklearn.datasets import load_iris
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
import numpy as np
from sklearn.preprocessing import label_binarize
from sklearn.metrics import confusion_matrix, precision_score, accuracy_score,recall_score, f1_score, roc_auc_score, \roc_curve
import matplotlib.pyplot as plt# 加载数据集
def loadDataSet():iris_dataset = load_iris()X = iris_dataset.datay = iris_dataset.target# 将数据划分为训练集和测试集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)return X_train, X_test, y_train, y_test如代码清单2所示,编写函数训练Logistic模型。
代码清单2 训练Logistic模型
# 训练Logistic模性
def trainLS(x_train, y_train):# Logistic生成和训练clf = LogisticRegression()clf.fit(x_train, y_train)return clfLogistic模型较为简单,不需要额外设置超参数即可开始训练。如代码清单3所示,初始化Logistic模型并将模型在训练集上训练,返回训练好的模型。
代码清单3 测试模型及打印各种评价指标
# 测试模型
def test(model, x_test, y_test):# 将标签转换为one-hot形式y_one_hot = label_binarize(y_test, np.arange(3))# 预测结果y_pre = model.predict(x_test)# 预测结果的概率y_pre_pro = model.predict_proba(x_test)# 混淆矩阵con_matrix = confusion_matrix(y_test, y_pre)print('confusion_matrix:\n', con_matrix)print('accuracy:{}'.format(accuracy_score(y_test, y_pre)))print('precision:{}'.format(precision_score(y_test, y_pre, average='micro')))print('recall:{}'.format(recall_score(y_test, y_pre, average='micro')))print('f1-score:{}'.format(f1_score(y_test, y_pre, average='micro')))# 绘制ROC曲线drawROC(y_one_hot, y_pre_pro)在预测结果时,为了方便后面绘制ROC曲线,需要首先将测试集的标签转化为one-hot的形式,并得到模型在测试集上预测结果的概率值即y_pre_pro,从而传入drawROC函数完成ROC曲线的绘制。除此外,该函数实现了输出混淆矩阵以及计算准确率、精确率、查全率以及f1-score的功能。
代码清单4 绘制ROC曲线
def drawROC(y_one_hot, y_pre_pro):# AUC值auc = roc_auc_score(y_one_hot, y_pre_pro, average='micro')# 绘制ROC曲线fpr, tpr, thresholds = roc_curve(y_one_hot.ravel(), y_pre_pro.ravel())plt.plot(fpr, tpr, linewidth=2, label='AUC=%.3f' % auc)plt.plot([0, 1], [0, 1], 'k--')plt.axis([0, 1.1, 0, 1.1])plt.xlabel('False Postivie Rate')plt.ylabel('True Positive Rate')plt.legend()plt.show()如代码清单4所示为绘制ROC曲线的代码实现。最后将加载数据集,训练模型,以及模型验证的整个流程连接起来从而实现main函数,如代码清单5所示。
代码清单5 main函数设置
if __name__ == '__main__':X_train, X_test, y_train, y_test = loadDataSet()model = trainLS(X_train, y_train)test(model, X_test, y_test)将上述所有代码放在同一py脚本文件中,如图1所示可得最终的输出结果为

图1 命令行打印的测试结果
绘制得到的ROC曲线如图2所示。

图2 ROC曲线
Logistic是一个较为简单的模型,参数量较少,一般也用于较为简单的分类任务中,当任务更为复杂时,可以选取更为复杂的模型获得更好的效果,下面将使用不同的模型从而验证同一任务在不同模型下的表现。
02、使用决策树实现鸢尾花分类
由于只改动了模型,加载数据集、模型评价等其他部分的代码不需要改动,如代码清单6所示,增加新的函数用于训练决策树模型。
代码清单6 使用决策树模型进行训练
from sklearn import tree
# 训练决策树模性
def trainDT(x_train, y_train):# DT生成和训练clf = tree.DecisionTreeClassifier(criterion="entropy")clf.fit(x_train, y_train)return clf同时修改main函数中调用的训练函数如代码清单7所示。
代码清单7 修改main函数内容
if __name__ == '__main__':X_train, X_test, y_train, y_test = loadDataSet()model = trainDT(X_train, y_train)test(model, X_test, y_test)最后运行可得命令行输出如图3所示。
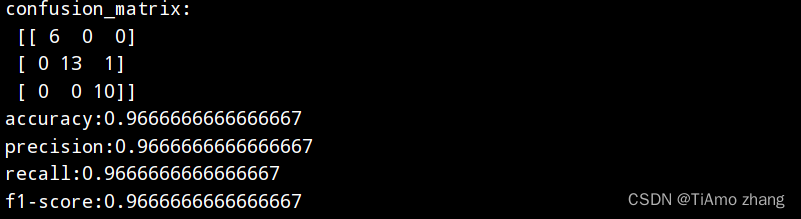
图3 决策树模型预测结果
以及ROC曲线如图4所示。
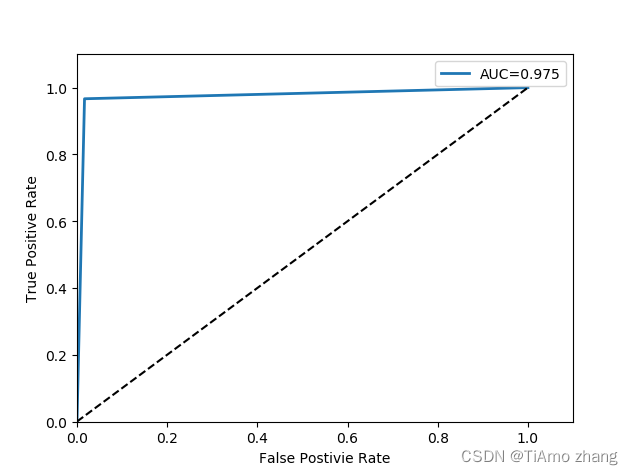
图4 决策树模型绘制ROC曲线
相比Logistic模型,决策树模型无论在哪一项指标上都得到了更高的评分,且决策树模型不会像Logistic模型一样受初始化的影响,多次运行程序均可获得相同的输出模型,而Logistic模型运行多次会发现评价指标会在某个范围内上下抖动。
03、使用SVM实现鸢尾花分类
到现在相信大家都已经非常熟悉如何继续修改代码从而实现SVM模型的预测,实现SVM模型的训练代码如代码清单8所示
代码清单8 使用SVM模型进行训练
# 训练SVM模性
from sklearn import svm
def trainSVM(x_train, y_train):# SVM生成和训练clf = svm.SVC(kernel='rbf', probability=True)clf.fit(x_train, y_train)return clf同时修改main函数,如代码清单9所示。
代码清单9 修改main函数内容
if __name__ == '__main__':X_train, X_test, y_train, y_test = loadDataSet()model = trainSVM(X_train, y_train)test(model, X_test, y_test)程序运行输出如图5所示。

图5 使用SVM模型预测结果
绘制得到的ROC曲线如图6所示。
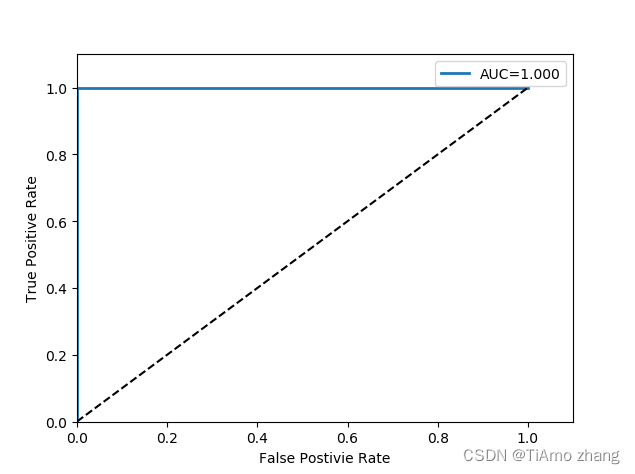
图6 使用SVM模型绘制的ROC曲线
可以发现,随着模型进一步变得复杂,最终预测的各项指标进一步上升,在三个模型中SVM模型的高斯核最终结果在测试集中表现得最好且没有发生过拟合的现象,因此可以选用SVM模型来完成鸢尾花分类这一任务。
相关文章:
PyTorch深度学习实战 | 基于线性回归、决策树和SVM进行鸢尾花分类
鸢尾花数据集是机器学习领域非常经典的一个分类任务数据集。它的英文名称为Iris Data Set,使用sklearn库可以直接下载并导入该数据集。数据集总共包含150行数据,每一行数据由4个特征值及一个标签组成。标签为三种不同类别的鸢尾花,分别为&…...
服务端接口优化方案
一、背景 针对老项目,去年做了许多降本增效的事情,其中发现最多的就是接口耗时过长的问题,就集中搞了一次接口性能优化。本文将给小伙伴们分享一下接口优化的通用方案。 二、接口优化方案总结 1. 批处理 批量思想:批量操作数据…...

【并发基础】Happens-Before模型详解
目录 一、Happens-Before模型简介 二、组成Happens-Before模型的八种规则 2.1 程序顺序规则(as-if-serial语义) 2.2 传递性规则 2.3 volatile变量规则 2.4 监视器锁规则 2.5 start规则 2.6 Join规则 一、Happens-Before模型简介 除了显示引用vo…...

Kubernetes系列---Kubernetes 理论知识 | 初识
Kubernetes系列---Kubernetes 理论知识 | 初识 1.K8s 是什么?2.K8s 特性3.小拓展(业务升级)4.K8s 集群架构与组件①架构拓扑图:②Master 组件③Node 组件 五 K8s 核心概念六 官方提供的三种部署方式总结 1.K8s 是什么?…...

KingbaseES 原生XML系列三--XML数据查询函数
KingbaseES 原生XML系列三--XML数据查询函数(EXTRACT,EXTRACTVALUE,EXISTSNODE,XPATH,XPATH_EXISTS,XMLEXISTS) XML的简单使其易于在任何应用程序中读写数据,这使XML很快成为数据交换的一种公共语言。在不同平台下产生的信息,可以很容易加载XML数据到程序…...
【51单片机】点亮一个LED灯(看开发板原理图十分重要)
🎊专栏【51单片机】 🍔喜欢的诗句:更喜岷山千里雪 三军过后尽开颜。 🎆音乐分享【The Right Path】 🥰大一同学小吉,欢迎并且感谢大家指出我的问题🥰 目录 🍔基础内容 🏳…...
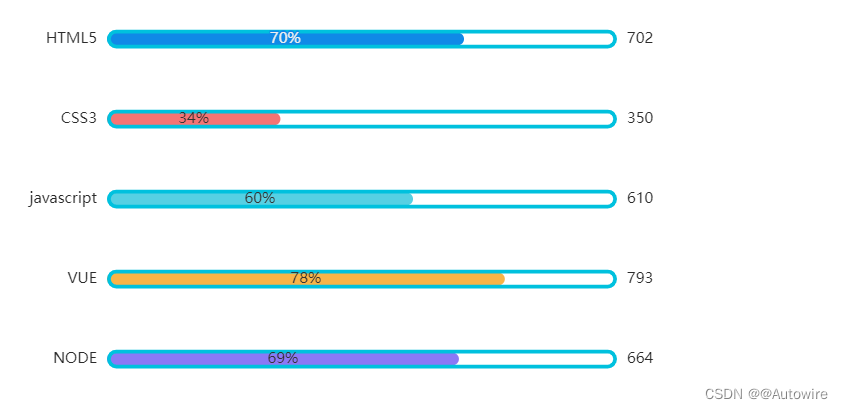
数据可视化工具 - ECharts以及柱状图的编写
1 快速上手 引入echarts 插件文件到html页面中 <head><meta charset"utf-8"/><title>ECharts</title><!-- step1 引入刚刚下载的 ECharts 文件 --><script src"./echarts.js"></script> </head>准备一个…...
【AI绘画】——Midjourney关键词格式解析(常用参数分享)
目前在AI绘画模型中,Midjourney的效果是公认的top级别,但同时也是相对较难使用的,对小白来说比较难上手,主要就在于Mj没有webui,不能选择参数,怎么找到这些隐藏参数并且触发它是用好Mj的第一步。 今天就来…...

操作符知识点大全(简洁,全面,含使用场景,演示,代码)
目录 一.算术操作符 1.要点: 二.负数原码,反码,补码的互推 1.按位取反操作符:~(二进制位) 2.原反补互推演示 三.进制位的表示 1.不同进制位的特征: 2.二进制位表示 3.整型的二进制表…...

华工研究生语音课
这门课讲啥 语音蕴含的信息、语音识别的目的 语音的准平稳性、分帧、预加重、时域特征分析(能量和过零率)、端点检测(双门限法) 语音的基频及检测(主要是自相关法、野点的处理) 声音的产生过程…...

KingbaseES 原生XML系列二 -- XML数据操作函数
KingbaseES 原生XML系列二--XML数据操作函数(DELETEXML,APPENDCHILDXML,INSERTCHILDXML,INSERTCHILDXMLAFTER,INSERTCHILDXMLBEFORE,INSERTXMLAFTER,INSERTXMLBEFORE,UPDATEXML) XML的简单使其易于在任何应用程序中读写数据,这使XML很快成为数据交换的一种公共语言。…...
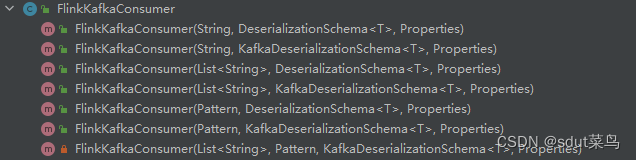
【Flink】DataStream API使用之源算子(Source)
源算子 创建环境之后,就可以构建数据的业务处理逻辑了,Flink可以从各种来源获取数据,然后构建DataStream进项转换。一般将数据的输入来源称为数据源(data source),而读取数据的算子就叫做源算子(…...
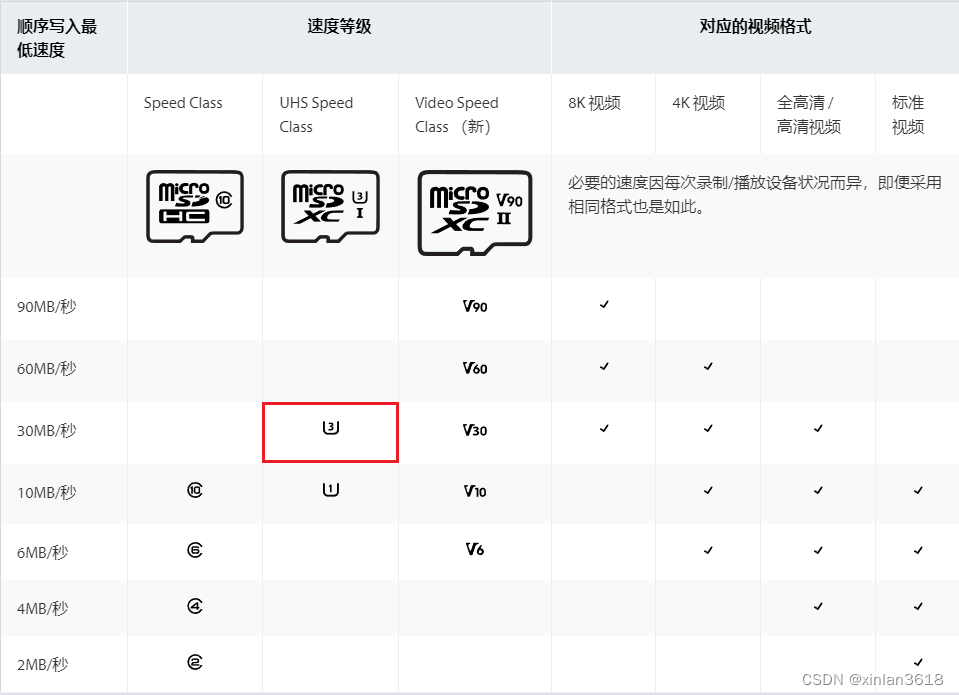
树莓派硬件介绍及配件选择
目录 树莓派Datasheet下载地址: Raspberry 4B 外观图: 技术规格书: 性能介绍: 树莓派配件选用 电源的选用: 树莓派外壳选用: 内存卡/U盘选用 树莓派Datasheet下载地址: Raspberry Pi …...
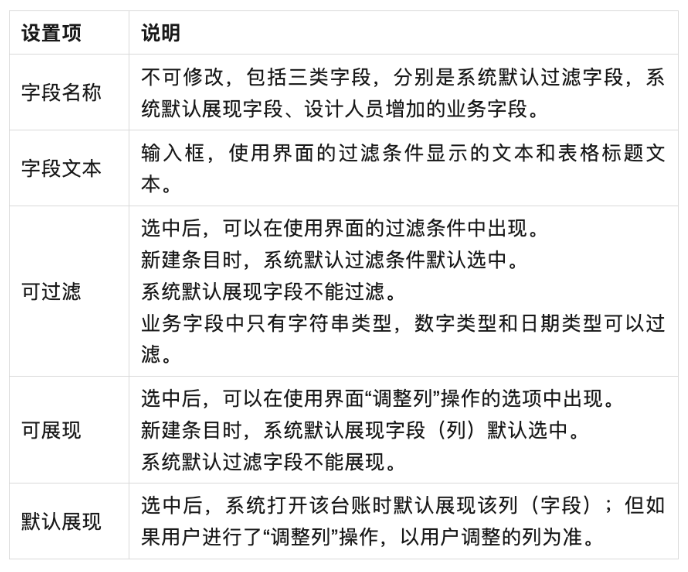
O2OA (翱途) 平台 V8.0 发布新增数据台账能力
亲爱的小伙伴们,O2OA (翱途) 平台开发团队经过几个月的持续努力,实现功能的新增、优化以及问题的修复。2023 年度 V8.0 版本已正式发布。欢迎大家到 O2OA 的官网上下载进行体验,也希望大家在藕粉社区里多提宝贵建议。本篇我们先为大家介绍应用…...

数控解锁怎么解 数控系统解锁解密
Amazon Fargate 在中国区正式落地,因 数控解锁使用 Serverless 架构,更加适合对性能要求不敏感的服务使用,Pyroscope 是一款基于 Golang 开发的应用程序性能分析工具,Pyroscope 的服务端为无状态服务且性能要求不敏感,…...
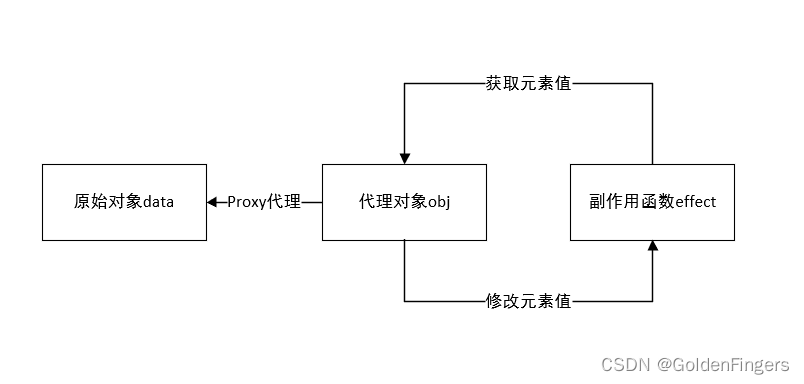
3.0 响应式系统的设计与实现
1、Proxy代理对象 Proxy用于对一个普通对象代理,实现对象的拦截和自定义,如拦截其赋值、枚举、函数调用等。里面包含了很多组捕获器(trap),在代理对象执行相应的操作时捕获,然后在内部实现自定义。 const…...
Rust 快速入门60分① 看完这篇就能写代码了
Rust 一门赋予每个人构建可靠且高效软件能力的语言https://hannyang.blog.csdn.net/article/details/130467813?spm1001.2014.3001.5502关于Rust安装等内容请参考上文链接,写完上文就在考虑写点关于Rust的入门文章,本专辑将直接从Rust基础入门内容开始讲…...

【5.JS基础-JavaScript的DOM操作】
1 认识DOM和BOM 所以我们学习DOM,就是在学习如何通过JavaScript对文档进行操作的; DOM Tree的理解 DOM的学习顺序 DOM的继承关系图 2 document对象 3 节点(Node)之间的导航(navigator) 4 元素࿰…...

【大数据之Hadoop】二十九、HDFS存储优化
纠删码和异构存储测试需要5台虚拟机。准备另外一套5台服务器集群。 环境准备: (1)克隆hadoop105为hadoop106,修改ip地址和hostname,然后重启。 vim /etc/sysconfig/network-scripts/ifcfg-ens33 vim /etc/hostname r…...
SuperMap GIS基础产品组件GIS FAQ集锦(2)
SuperMap GIS基础产品组件GIS FAQ集锦(2) 【iObjects for Spark】读取GDB参数该如何填写? 【解决办法】可参考以下示例: val GDB_params new util.HashMapString, java.io.Serializable GDB_params.put(FeatureRDDProviderParam…...

Buzz音频转录完全指南:3大核心功能+5个实战场景,快速掌握本地语音转文字技术
Buzz音频转录完全指南:3大核心功能5个实战场景,快速掌握本地语音转文字技术 【免费下载链接】buzz Buzz transcribes and translates audio offline on your personal computer. Powered by OpenAIs Whisper. 项目地址: https://gitcode.com/GitHub_Tr…...

Unity安卓构建72小时实战指南:从零到真机运行
1. 这不是“又一本Unity教程”,而是我带三个新人从零上线第一款安卓游戏的真实路径你点开这个标题,大概率正站在两个路口之间:一边是满屏“30天速成Unity”“零基础做爆款”的短视频封面,一边是你刚下载完Unity Hub、卡在Android …...

Hirschmann RS20-0800M4M4SDAE工业以太网交换机
Hirschmann RS20-0800M4M4SDAE 工业以太网交换机产品特点:端口配置:共8个端口,含6个RJ45电口和2个ST光纤接口。端口速率:所有端口均为100Mbps快速以太网。光纤类型:2个光纤端口为多模、ST接头。管理类型:二…...

金融合规审核为何人力堆积却仍漏洞百出?2026年RegTech演进与Agent全链路闭环解决方案
在2026年的金融监管环境下,合规审核已不再是简单的“查漏补缺”,而是演变为一场高强度的算力与逻辑博弈。尽管金融机构在合规成本上的投入逐年攀升,甚至不惜以“人海战术”填补流程断点,但监管罚单的数额与频率却并未显著下降。这…...

Taotoken如何帮助教育科技产品实现个性化学习辅导
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken如何帮助教育科技产品实现个性化学习辅导 1. 场景与挑战 教育科技公司在开发个性化学习助手时,常常面临一个核…...

十年以上经验的建站公司推荐|策划强、落地稳的网站制作公司盘点
互联网时代,企业官网已从单纯的信息展示窗口升级为集品牌价值传递、用户体验连接与业务高效转化于一体的核心数字阵地。行业报告显示,优质官网可帮助企业线上转化率提升35%-60%,而低效官网则可能导致潜在客户大量流失。面对市场上众多的网站建…...

uWSGI目录穿越漏洞CVE-2018-7490深度利用与防御实战
1. 这不是“读文件”那么简单:uWSGI目录穿越在真实攻防链中的定位与误判代价你刚在Vulfocus靶场里跑通了CVE-2018-7490的PoC,用curl "http://target:8080/?p../../../../etc/passwd"成功读出了root:x:0:0:root:/root:/bin/bash,截…...
与 NOT EXISTS 优化)
PostgreSQL Join 执行策略(Nested Loop、Hash Join、Merge Join)与 NOT EXISTS 优化
以集成数据压缩 SQL 优化为例,用大白话讲清楚 Nested Loop、Hash Join、Merge Join 三种执行策略。一、背景:一条慢 SQL 引发的思考 在对上游下发数据做压缩时,有这样一条 UPDATE SQL: -- ❌ 原始写法 UPDATE magellan_nk_order_i…...
)
【独家首发】Sora 2 AVI支持并非“开箱即用”:3层封装校验机制详解(RIFF→AVI→OpenCV Mat内存映射链路图解)
更多请点击: https://codechina.net 第一章:Sora 2 AVI支持并非“开箱即用”:核心矛盾与技术定位 Sora 2 的官方文档与发布说明中明确将 AVI 视为“实验性容器支持”,而非默认启用的输入格式。其底层解码栈基于 FFmpeg 5.1 构建&…...

Unity Spine换装系统:骨骼映射与Skin动态管理实战
1. 为什么Spine换装不能只靠“替换贴图”——一个被低估的骨骼绑定难题 在Unity里做Spine换装,很多人第一反应是:把新衣服的Atlas和SkeletonData拖进去,用 SkeletonRenderer 的 skeletonDataAsset 字段一换,完事。我去年接手一…...