【Flink】DataStream API使用之源算子(Source)
源算子

创建环境之后,就可以构建数据的业务处理逻辑了,Flink可以从各种来源获取数据,然后构建DataStream进项转换。一般将数据的输入来源称为数据源(data source),而读取数据的算子就叫做源算子(source operator)。所以,Source就是整个程序的输入端。
Flink中添加source的方式,是调用执行环境的 addSource()方法:
DataStreamSource<String> stringDataStreamSource = env.addSource(...);
DataStreamSource<String> stringDataStreamSource = env.fromSource(...);
参数是一个泛型接口SourceFunction<OUT>,需要实现 SourceFunction 接口;返回 DataStreamSource。这里的
DataStreamSource 类继承自 SingleOutputStreamOperator 类,又进一步继承自 DataStream。所以
很明显,读取数据的 source 操作是一个算子,得到的是一个数据流(DataStream)。
Flink提供了很多种已经实现好的source function,一般情况下我们只需要找到对应的实现类就可以了。
以下介绍5种读取数据的源算子示例。
1. 从集合中读取
最简单的读取数据的方式,就是在代码创建一个集合通过调用执行环境的fromCollection 或者其他方法进行读取。这相当于将数据读取到内存中,形成特殊的数据结构后,作为数据源使用,一般用于测试。
1.1 fromCollection
基于集合构建输入数据,集合中的所有元素必须是同一种类型。
| 方法名 | 示例 |
|---|---|
public <OUT> DataStreamSource<OUT> fromCollection(Collection<OUT> data) | env.fromCollection(list) |
public <OUT> DataStreamSource<OUT> fromCollection(Collection<OUT> data, TypeInformation<OUT> typeInfo) | env.fromCollection(list, BasicTypeInfo.STRING_TYPE_INFO) |
public <OUT> DataStreamSource<OUT> fromCollection(Iterator<OUT> data, Class<OUT> type) | env.fromCollection(new CustomIterator(), String.class) |
public <OUT> DataStreamSource<OUT> fromCollection(Iterator<OUT> data, TypeInformation<OUT> typeInfo) | env.fromCollection(new CustomIterator(), BasicTypeInfo.STRING_TYPE_INFO) |
参数说明:
Collection<OUT> data集合对象,例如List,SetIterator<OUT> data迭代器对象或者自定义迭代器,CustomIteratorClass<OUT> type type集合数据元素类型 ,例如:BasicTypeInfo.STRING_TYPE_INFO.getTypeClass()TypeInformation<OUT> typeInfo集合数据类型对象,例如:BasicTypeInfo.STRING_TYPE_INFO
其中 CustomIterator 为自定义的迭代器,自定义迭代器除了要实现 Iterator 接口外,还必须实现序列化接口 Serializable ,否则会抛出序列化失败的异常,示例代码如下:
public class CustomIterator implements Iterator<Integer>, Serializable {private int i = 0;@Overridepublic boolean hasNext() {return i < 100;}@Overridepublic Integer next() {i++;return i;}
}
1.2 fromElements
基于元素创建,所有元素必须是同一种类型。
| 方法名 | 示例 |
|---|---|
public final <OUT> DataStreamSource<OUT> fromElements(OUT... data) | env.fromElements("one1", "two2", "three3"); |
public final <OUT> DataStreamSource<OUT> fromElements(Class<OUT> type, OUT... data) | env.fromElements(String.class, "one1", "two2", "three3"); |
参数说明:
OUT... data多参数元素Class<OUT> type元素类型 例如:BasicTypeInfo.STRING_TYPE_INFO.getTypeClass()
1.3 fromSequence
基于给定的序列区间进行构建。
| 方法名 | 示例 |
|---|---|
public DataStreamSource<Long> fromSequence(long from, long to) | env.fromSequence(1, 10); |
| 返回1-10之间的所有数字。 |
1.4 fromParallelCollection
从一个迭代器中创建并行数据流。Class 指定了该迭代器返回元素的类型。
| 方法名 | 示例 |
|---|---|
public <OUT> DataStreamSource<OUT> fromParallelCollection(SplittableIterator<OUT> iterator, Class<OUT> type) | env.fromParallelCollection(new NumberSequenceIterator(1, 10), BasicTypeInfo.LONG_TYPE_INFO.getTypeClass()); |
public <OUT> DataStreamSource<OUT> fromParallelCollection(SplittableIterator<OUT> iterator, TypeInformation<OUT> typeInfo) | env.fromParallelCollection(new NumberSequenceIterator(1, 10), BasicTypeInfo.LONG_TYPE_INFO); |
参数说明:
SplittableIterator<OUT> iterator是迭代器的抽象基类,它用于将原始迭代器的值拆分到多个不相交的迭代器中。Class<OUT> type type集合数据元素类型 ,例如:BasicTypeInfo.STRING_TYPE_INFO.getTypeClass()TypeInformation<OUT> typeInfo集合数据类型对象,例如:BasicTypeInfo.STRING_TYPE_INFO
2. 从文件读取数据
真正业务场景中,不会让我们直接把数据写在代码里,通长情况下可能会从存储介质中获取数据,本地文件或者HDFS文件以及OBS存储中等等。
- 参数可以是目录,也可以是文件;
- 路径可以是相对路径,也可以是绝对路径;相对路径是从系统属性 user.dir 获取路径: idea 下是 project 的根目录, standalone 模式下是集群节点根目录;
- 也可以从 hdfs 目录下读取, 使用路径 hdfs://…, 由于 Flink 没有提供 hadoop 相关依赖, 需要 pom 中添加相关依赖:
2.1 readTextFile
按照 TextInputFormat 格式读取文本文件,并将其内容以字符串的形式返回。
| 方法名 | 示例 |
|---|---|
public DataStreamSource<String> readTextFile(String filePath) | env.readTextFile("doc/demo.txt"); |
public DataStreamSource<String> readTextFile(String filePath, String charsetName) | env.readTextFile("doc/demo.txt", "UTF-8"); |
参数说明:
filePath文件路径,可以是绝对路径也可以是相对路径charsetName文件字符串格式,UTF-8或者GBK等
2.2 readFile
根据给定的FileInputFormat读取用户指定的filePath的内容,文本类型的数据通用型方法
| 方法名 | 示例 |
|---|---|
public <OUT> DataStreamSource<OUT> readFile(FileInputFormat<OUT> inputFormat, String filePath) | env.readFile(new TextInputFormat(new Path("doc/demo.txt")), "doc/demo.txt"); |
public <OUT> DataStreamSource<OUT> readFile(FileInputFormat<OUT> inputFormat,String filePath,FileProcessingMode watchType, long interval) | env.readFile(new TextInputFormat(new Path("doc/demo.txt")), "doc/demo.txt", FileProcessingMode.PROCESS_ONCE , 10); |
public <OUT> DataStreamSource<OUT> readFile(FileInputFormat<OUT> inputFormat,String filePath, FileProcessingMode watchType,long interval,TypeInformation<OUT> typeInformation) | env.readFile(new TextInputFormat(new Path("doc/demo.txt")), "doc/demo.txt", FileProcessingMode.PROCESS_ONCE , 10, BasicTypeInfo.STRING_TYPE_INFO); |
参数说明:
FileInputFormat<OUT> inputFormat数据流的输入格式String filePath文件路径,可以是本地文件系统上的路径,也可以是 HDFS 上的文件路径FileProcessingMode watchType读取方式,它有两个可选值,分别是 FileProcessingMode.PROCESS_ONCE 和 FileProcessingMode.PROCESS_CONTINUOUSLY:前者表示对指定路径上的数据只读取一次,然后退出;后者表示对路径进行定期地扫描和读取。需要注意的是如果 watchType 被设置为 PROCESS_CONTINUOUSLY,那么当文件被修改时,其所有的内容 (包含原有的内容和新增的内容) 都将被重新处理,因此这会打破 Flink 的 exactly-once 语义。long interval定期扫描的时间间隔。TypeInformation<OUT> typeInformation输入流中元素的类型
注意!FileInputFormat是一个抽象类,他的实现类有很多,对应了不同文件类型。
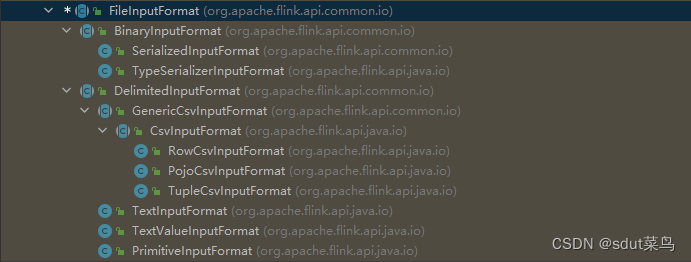
2.3 createInput
使用InputFormat创建输入数据流的通用方法。
| 方法名 | 示例 |
|---|---|
public <OUT> DataStreamSource<OUT> createInput(InputFormat<OUT, ?> inputFormat) | env.readFile(new TextInputFormat(new Path("doc/demo.txt")), "doc/demo.txt"); |
public <OUT> DataStreamSource<OUT> createInput(InputFormat<OUT, ?> inputFormat, TypeInformation<OUT> typeInfo) | env.readFile(new TextInputFormat(new Path("doc/demo.txt")), "doc/demo.txt", FileProcessingMode.PROCESS_ONCE , 10); |
参数说明:
InputFormat<OUT, ?> inputFormat接受通用输入格式读取数据
实际上FileInputFormat就继承自InputFormat,所以使用readFile就可以了

3. 从 Socket 读取数据
不论从集合还是文件,我们读取的其实都是有界数据。在流处理的场景中,数据往往是无
界的。Flink 提供了 socketTextStream 方法用于构建基于 Socket 的数据流。
3.1 socketTextStream
| 方法名 | 示例 |
|---|---|
public DataStreamSource<String> socketTextStream(String hostname, int port, String delimiter, long maxRetry) | env.socketTextStream("127.0.0.1", 9999, "\n", 3); |
public DataStreamSource<String> socketTextStream(String hostname, int port, String delimiter) | env.socketTextStream("127.0.0.1", 9999, "\n"); |
public DataStreamSource<String> socketTextStream(String hostname, int port) | env.socketTextStream("127.0.0.1", 9999); |
参数说明:
String hostnameIP地址或者域名地址int port端口号,设置为0表示端口号自动分配String delimiter定界符long maxRetry最大重试次数, 当 Socket 临时关闭时,程序的最大重试间隔,单位为秒。设置为 0 时表示不进行重试;设置为负值则表示一直重试。
创建一个新的数据流,其中包含从套接字无限接收的字符串。接收到的字符串由系统的默认字符集解码,使用“\n”作为分隔符。当套接字关闭时,读取器将立即终止。
4. 从 Kafka 读取数据
一些比较基本的 Source 和 Sink 已经内置在 Flink 里。 预定义 data sources 支持从文件、目录、socket,以及 collections 和 iterators 中读取数据。 预定义 data sinks 支持把数据写入文件、标准输出(stdout)、标准错误输出(stderr)和 socket。
Flink1.17版本已经集成了非常多的连接器,我这里使用的1.12版本。

Flink 还有些一些额外的连接器通过 Apache Bahir 发布, 包括:

具体详细的连接器信息,可以看官方文档DataStream Connectors
这里主要介绍下使用Flink读取Kafka数据的连接方式
4.1 导入外部依赖
Flink自身是没有Kafka的连接器的,不过Flink提供了Kafka的连接器的依赖包,
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka_${scala.binary.version}</artifactId><version>${flink.version}</version>
</dependency>
只需要注意相对应的版本就可以了,我这里用的
<flink.version>1.13.0</flink.version>
<scala.binary.version>2.12</scala.binary.version>
然后使用FlinkKafkaConsumer就可以了
4.2 使用FlinkKafkaConsumer开发
在1.17版本,Flink已经推荐使用KafkaSource来构建Kafka的连接器,示例:
KafkaSource<String> source = KafkaSource.<String>builder().setBootstrapServers(brokers).setTopics("input-topic").setGroupId("my-group").setStartingOffsets(OffsetsInitializer.earliest()).setValueOnlyDeserializer(new SimpleStringSchema()).build();env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source");
FlinkKafkaConsumer测试代码示例:
public class GetDataSourceFromKafka {public static void main(String[] args) throws Exception {// 1. 直接调用getExecutionEnvironment 方法,底层源码可以自由判断是本地执行环境还是集群的执行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);// 2. 从Kafka中读取数据Properties properties = new Properties();// 3. 设置Kafka消费者配置参数properties.setProperty("bootstrap.servers", "hadoop102:9092");properties.setProperty("group.id", "consumer-group");properties.setProperty("key.deserializer","org.apache.kafka.common.serialization.StringDeserializer");properties.setProperty("value.deserializer","org.apache.kafka.common.serialization.StringDeserializer");properties.setProperty("auto.offset.reset", "latest");// 4. 指定监听topic, 并定义Flink和Kafka之间对象的转换规则DataStreamSource<String> KafkaSource = env.addSource(new FlinkKafkaConsumer<>("topic", new SimpleStringSchema(), properties));KafkaSource.print("dd");// 5. 执行程序env.execute();}
}
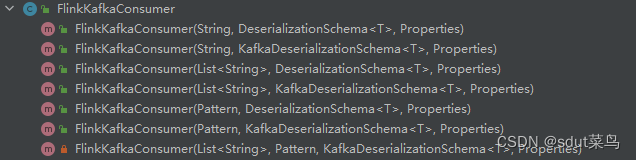
创建FlinkKafkaConsumer对象需要至少三个参数,这三个参数的说明如下:
public FlinkKafkaConsumer(String topic, DeserializationSchema<T> valueDeserializer, Properties props)
- topic:定义了从哪些主题中读取数据。
- valueDeserializer: 是一个 DeserializationSchema 或者 KafkaDeserializationSchema。Kafka 消
息被存储为原始的字节数据,所以需要反序列化成 Java 或者 Scala 对象。上面代码中
使用的 SimpleStringSchema,是一个内置的 DeserializationSchema,它只是将字节数
组简单地反序列化成字符串。DeserializationSchema 和 KafkaDeserializationSchema是
公共接口,所以我们也可以自定义反序列化逻辑。 - props: 是一个 Properties 对象,设置了 Kafka 客户端的一些属性。
FlinkKafkaConsumer有很多的构造方法,对应不同场景,你可以使用一个 topic,也可以是 topic
列表,还可以是匹配所有想要读取的 topic 的正则表达式。
KeyedDeserializationSchema 过期了,所以这里使用的是KafkaDeserializationSchema。当然读取kafka的数据还有更多配置,这里不再详细描写,可以看官网的文档Apache Kafka 连接器
5. 自定义 Source读取数据
除了Flink提供的数据源连接器外,你还可以通过自定义实现 SourceFunction创建数据源连接器,自定义SourceFunction必须要实现重写两个关键方法:run()和 cancel()。
run()方法:使用运行时上下文对象(SourceContext)向下游发送数据。cancel()方法:通过标识位控制退出循环,来达到中断数据源的效果。
以下是自定义SourceFunction代码实例:
public class CustomSource implements SourceFunction<Event> {// 声明一个布尔变量,作为控制数据生成的标识位private Boolean running = true;@Overridepublic void run(SourceContext<Event> ctx) throws Exception {Random random = new Random(); // 在指定的数据集中随机选取数据String[] users = {"Mary", "Alice", "Bob", "Cary"};String[] urls = {"./home", "./cart", "./fav", "./prod?id=1", "./prod?id=2"};while (running) {ctx.collect(new Event(users[random.nextInt(users.length)],urls[random.nextInt(urls.length)],Calendar.getInstance().getTimeInMillis()));// 隔 1 秒生成一个点击事件,方便观测Thread.sleep(1000);}}@Overridepublic void cancel() {running = false;}
}
使用方式就是直接通过addSource()调用就可以了
DataStreamSource<Event> customSource = env.addSource(new CustomSource());
注意我们实现的SourceFunction并行度只有1,如果数据源设置大于1的并行度,就会抛出异常
Exception in thread "main" java.lang.IllegalArgumentException: The parallelism
of non parallel operator must be 1.
所以如果我们想要自定义并行的数据源的话,需要使用·ParallelSourceFunction,示例代码如下:
public class CustomSource implements ParallelSourceFunction<Event> {// 声明一个布尔变量,作为控制数据生成的标识位private Boolean running = true;@Overridepublic void run(SourceContext<Event> ctx) throws Exception {Random random = new Random(); // 在指定的数据集中随机选取数据String[] users = {"Mary", "Alice", "Bob", "Cary"};String[] urls = {"./home", "./cart", "./fav", "./prod?id=1", "./prod?id=2"};while (running) {ctx.collect(new Event(users[random.nextInt(users.length)],urls[random.nextInt(urls.length)],Calendar.getInstance().getTimeInMillis()));// 隔 1 秒生成一个点击事件,方便观测Thread.sleep(1000);}}@Overridepublic void cancel() {running = false;}
}
使用方式就是直接通过addSource()调用就可以了
DataStreamSource<Event> customSource = env.addSource(new CustomSource()).setParallelism(2);
相关文章:
【Flink】DataStream API使用之源算子(Source)
源算子 创建环境之后,就可以构建数据的业务处理逻辑了,Flink可以从各种来源获取数据,然后构建DataStream进项转换。一般将数据的输入来源称为数据源(data source),而读取数据的算子就叫做源算子(…...
树莓派硬件介绍及配件选择
目录 树莓派Datasheet下载地址: Raspberry 4B 外观图: 技术规格书: 性能介绍: 树莓派配件选用 电源的选用: 树莓派外壳选用: 内存卡/U盘选用 树莓派Datasheet下载地址: Raspberry Pi …...
O2OA (翱途) 平台 V8.0 发布新增数据台账能力
亲爱的小伙伴们,O2OA (翱途) 平台开发团队经过几个月的持续努力,实现功能的新增、优化以及问题的修复。2023 年度 V8.0 版本已正式发布。欢迎大家到 O2OA 的官网上下载进行体验,也希望大家在藕粉社区里多提宝贵建议。本篇我们先为大家介绍应用…...

数控解锁怎么解 数控系统解锁解密
Amazon Fargate 在中国区正式落地,因 数控解锁使用 Serverless 架构,更加适合对性能要求不敏感的服务使用,Pyroscope 是一款基于 Golang 开发的应用程序性能分析工具,Pyroscope 的服务端为无状态服务且性能要求不敏感,…...
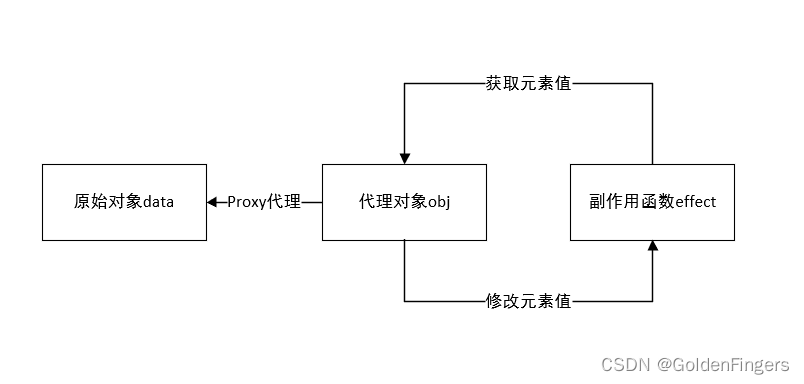
3.0 响应式系统的设计与实现
1、Proxy代理对象 Proxy用于对一个普通对象代理,实现对象的拦截和自定义,如拦截其赋值、枚举、函数调用等。里面包含了很多组捕获器(trap),在代理对象执行相应的操作时捕获,然后在内部实现自定义。 const…...
Rust 快速入门60分① 看完这篇就能写代码了
Rust 一门赋予每个人构建可靠且高效软件能力的语言https://hannyang.blog.csdn.net/article/details/130467813?spm1001.2014.3001.5502关于Rust安装等内容请参考上文链接,写完上文就在考虑写点关于Rust的入门文章,本专辑将直接从Rust基础入门内容开始讲…...

【5.JS基础-JavaScript的DOM操作】
1 认识DOM和BOM 所以我们学习DOM,就是在学习如何通过JavaScript对文档进行操作的; DOM Tree的理解 DOM的学习顺序 DOM的继承关系图 2 document对象 3 节点(Node)之间的导航(navigator) 4 元素࿰…...

【大数据之Hadoop】二十九、HDFS存储优化
纠删码和异构存储测试需要5台虚拟机。准备另外一套5台服务器集群。 环境准备: (1)克隆hadoop105为hadoop106,修改ip地址和hostname,然后重启。 vim /etc/sysconfig/network-scripts/ifcfg-ens33 vim /etc/hostname r…...
SuperMap GIS基础产品组件GIS FAQ集锦(2)
SuperMap GIS基础产品组件GIS FAQ集锦(2) 【iObjects for Spark】读取GDB参数该如何填写? 【解决办法】可参考以下示例: val GDB_params new util.HashMapString, java.io.Serializable GDB_params.put(FeatureRDDProviderParam…...
函数中整型格式说明符详解)
C语言printf()函数中整型格式说明符详解
每个整型在printf()函数中对应不同的格式说明符,以实现该整型的打印输出。格式说明符必须使用小写。现在让我们看看各个整型及其格式说明符: 短整型(short) 10进制:%hd16进制:无负数格式,正数使用%hx8进制:无负数格式,正数使用%ho c short s 34; printf("%hd", s…...
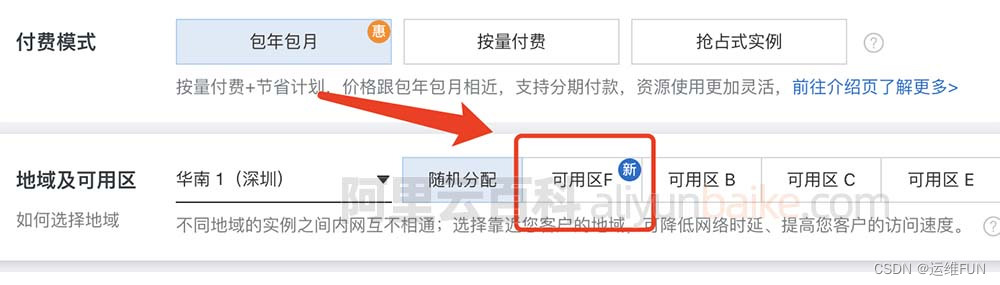
阿里云服务器地域和可用区怎么选择合适?
阿里云服务器地域和可用区怎么选择?地域是指云服务器所在物理数据中心的位置,地域选择就近选择,访客距离地域所在城市越近网络延迟越低,速度就越快;可用区是指同一个地域下,网络和电力相互独立的区域&#…...
Java序列化引发的血案
1、引言 阿里巴巴Java开发手册在第一章节,编程规约中OOP规约的第15条提到: **【强制】**序列化类新增属性时,请不要修改serialVersionUID字段,避免反序列失败;如果完全不兼容升级,避免反序列化混乱&#x…...

为Linux系统添加一块新硬盘,并扩展根目录容量
我的原来ubuntu20.04系统装的时候不是LVM格式的分区, 所以先将新硬盘转成LVM,再将原来的系统dd到新硬盘,从新硬盘的分区启动,之后再将原来的分区转成LVM,在融入进来 1:将新硬盘制作成 LVM分区 我的新硬盘…...

树莓派Opencv调用摄像头(Raspberry Pi 11)
前言:本人初玩树莓派opencv,使用的是树莓派Raspberry Pi OS 11,系统若不一致请慎用,本文主要记录在树莓派上通过Opencv打开摄像头的经验。 1、系统版本 进入树莓派,打开终端输入以下代码(查看系统的版本&…...

国产ChatGPT命名图鉴
很久不见这般热闹的春天。 随着ChatGPT的威名席卷全球,大洋对岸的中国厂商也纷纷亮剑,各式本土大模型你方唱罢我登场,声势浩大的发布会排满日程表。 有趣的是,在这些大模型产品初入历史舞台之时,带给世人的第一印象其…...

操作系统——进程管理
0.关注博主有更多知识 操作系统入门知识合集 目录 0.关注博主有更多知识 4.1进程概念 4.1.1进程基本概念 思考题: 4.1.2进程状态 思考题: 4.1.3进程控制块PCB 4.2进程控制 思考题: 4.3线程 思考题: 4.4临界资源与临…...

第四十一章 Unity 输入框 (Input Field) UI
本章节我们学习输入框 (Input Field),它可以帮助我们获取用户的输入。我们点击菜单栏“GameObject”->“UI”->“Input Field”,我们调整一下它的位置,效果如下 我们在层次面板中发现,这个InputField UI元素包含两个子元素&…...

10.集合
1.泛型 1.1泛型概述 泛型的介绍 泛型是JDK5中引入的特性,它提供了编译时类型安全检测机制 泛型的好处 把运行时期的问题提前到了编译期间避免了强制类型转换 泛型的定义格式 <类型>: 指定一种类型的格式.尖括号里面可以任意书写,一般只写一个字母.例如:…...

强化学习p3-策略学习
Policy Network (策略网络) 我们无法知道策略函数 π \pi π所以要做函数近似,求一个近似的策略函数 使用策略网络 π ( a ∣ s ; θ ) \pi(a|s;\theta) π(a∣s;θ) 去近似策略函数 π ( a ∣ s ) \pi(a|s) π(a∣s) ∑ a ∈ A π ( a ∣ s ; θ ) 1 \sum_{a\in …...

初学Verilog语言基础笔记整理(实例点灯代码分析)持续更新~
实例:点灯学习 一、Verilog语法学习 1. 参考文章 刚接触Verilog,作为一个硬件小白,只能尝试着去理解,文章未完…持续更新。 参考博客文章: Verilog语言入门学习(1)Verilog语法【Verilog】一文…...

AI智能体架构设计:从成本黑洞到价值引擎的解耦之道
1. 从成本黑洞到价值引擎:为什么你的AI智能体架构正在吞噬预算又到了季度技术复盘会,财务那边递过来的云账单和工程人力成本,是不是又让你倒吸一口凉气?你看着报表上那个名为“AI智能体平台”的项目,它的资源消耗曲线几…...
)
Goframe项目实战:从数据库表到API接口的全链路开发指南(含避坑点)
Goframe项目实战:从数据库表到API接口的全链路开发指南(含避坑点)在当今微服务架构盛行的时代,Go语言因其高性能和并发优势成为后端开发的热门选择。而Goframe作为一款企业级的Go应用开发框架,提供了从数据库操作到API…...

百考通智能任务书:贴合你的选题,拒绝空话假大空
毕业设计任务书是高校教学管理中的关键环节,它不仅标志着研究工作的正式启动,更是后续开题、实施、论文撰写和答辩全过程的行动依据。然而,许多学生在撰写时常常因不熟悉本专业写作规范、技术表达能力有限,或缺乏权威模板参考而陷…...

Office RibbonX Editor:让Office界面定制变得像搭积木一样简单
Office RibbonX Editor:让Office界面定制变得像搭积木一样简单 【免费下载链接】office-ribbonx-editor An overhauled fork of the original Custom UI Editor for Microsoft Office, built with WPF 项目地址: https://gitcode.com/gh_mirrors/of/office-ribbon…...

三步实现跨架构程序兼容:Box64高效架构转换指南
三步实现跨架构程序兼容:Box64高效架构转换指南 【免费下载链接】box64 Box64 - Linux Userspace x86_64 Emulator with a twist, targeted at ARM64, RV64 and LoongArch Linux devices 项目地址: https://gitcode.com/gh_mirrors/bo/box64 你是否曾在ARM64…...

【DeepSeek架构评审功能深度解密】:20年架构师亲授3大避坑指南与5步落地 checklist
更多请点击: https://kaifayun.com 第一章:DeepSeek架构评审功能全景概览 DeepSeek架构评审功能是一套面向大模型系统设计与工程落地的自动化分析框架,聚焦于模型结构合理性、计算图优化潜力、内存访问模式、算子兼容性及部署约束等多维度评…...

从安装到排错:手把手解决Linux服务器上Nacos启动失败的十大常见问题
从安装到排错:手把手解决Linux服务器上Nacos启动失败的十大常见问题当你在Linux服务器上部署Nacos时,是否遇到过启动失败却无从下手的困境?作为阿里巴巴开源的服务发现和配置管理平台,Nacos在微服务架构中扮演着重要角色。然而&am…...

uWSGI目录穿越漏洞CVE-2018-7490深度利用与防御实战
1. 这不是“读文件”那么简单:uWSGI目录穿越在真实攻防链中的定位与误判代价你刚在Vulfocus靶场里跑通了CVE-2018-7490的PoC,用curl "http://target:8080/?p../../../../etc/passwd"成功读出了root:x:0:0:root:/root:/bin/bash,截…...

基于Cynthion逆向USB协议,为DP100电源开发Linux控制软件
1. 项目概述:用Cynthion嗅探USB,为DP100电源打造Linux软件作为一名长期在Linux环境下折腾硬件和嵌入式开发的爱好者,我经常遇到一个头疼的问题:很多不错的桌面小设备,比如电源、示波器、逻辑分析仪,它们的官…...
)
【C++】零基础入门 · 第 4 节:循环结构(while、for、do-while)
上一节我们学习了条件判断,这一节来学习循环结构。循环让程序能够重复执行某段代码,直到满足特定条件为止。C 提供了三种循环语句:while、for 和 do-while。 1. while 循环:先判断后执行 while 循环在每次执行前先检查条件&#x…...