强化学习p3-策略学习
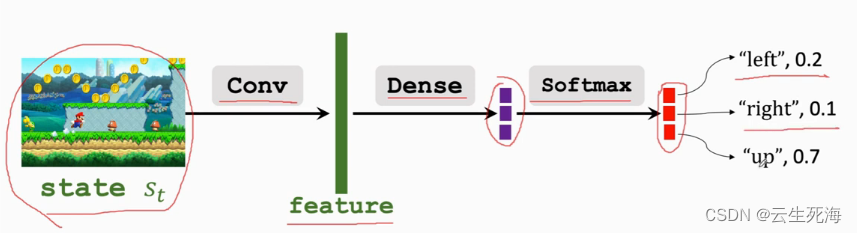
Policy Network (策略网络)
我们无法知道策略函数 π \pi π所以要做函数近似,求一个近似的策略函数
使用策略网络 π ( a ∣ s ; θ ) \pi(a|s;\theta) π(a∣s;θ) 去近似策略函数 π ( a ∣ s ) \pi(a|s) π(a∣s)
∑ a ∈ A π ( a ∣ s ; θ ) = 1 \sum_{a\in A} \pi(a|s;\theta) = 1 ∑a∈Aπ(a∣s;θ)=1
动作空间A的大小是多少,输出向量的维度就是多少。
策略学习的目标函数
状态价值函数(State-value function)
V π ( s t ) = E A [ Q π ( s t , A ) ] = ∑ a π ( a ∣ s t ) ⋅ Q π ( s t , a ) V_\pi(s_t)=E_A[Q_\pi(s_t,A)] = \sum_a\pi(a|s_t)\cdot Q_\pi(s_t,a) Vπ(st)=EA[Qπ(st,A)]=∑aπ(a∣st)⋅Qπ(st,a)
对A求期望,去掉A的影响
用策略网络 π ( a ∣ s t ; θ ) \pi(a|s_t;\theta) π(a∣st;θ) 去近似策略函数 π ( a ∣ s t ) \pi(a|s_t) π(a∣st)
V π ( s t ; θ ) = E A [ Q π ( s t , A ) ] = ∑ a π ( a ∣ s t ; θ ) ⋅ Q π ( s t , a ) V_\pi(s_t;\theta)=E_A[Q_\pi(s_t,A)] = \sum_a\pi(a|s_t;\theta)\cdot Q_\pi(s_t,a) Vπ(st;θ)=EA[Qπ(st,A)]=∑aπ(a∣st;θ)⋅Qπ(st,a)
近似状态价值既依赖于当前状态 s t s_t st,也依赖于策略网络 π \pi π的参数 θ \theta θ
如果一个策略很好,那么状态价值函数的近似 V π ( s ; θ ) V_\pi(s;\theta) Vπ(s;θ)的均值应当很大。因此我们定义目标函数:
J ( θ ) = E S [ V π ( s ; θ ) ] J(\theta)=E_S[V_\pi(s;\theta)] J(θ)=ES[Vπ(s;θ)]
目标函数 J ( θ ) J(\theta) J(θ) 排除了状态 S S S的因素,只依赖于策略网络 π \pi π的参数 θ \theta θ。策略越好,则 J ( θ ) J(\theta) J(θ) 越大,所以策略学习可以被看作是这样一个优化问题:
m a x θ J ( θ ) \mathop{max}_{\theta}J(\theta) maxθJ(θ)
通过学习参数 θ \theta θ ,使得目标函数 J ( θ ) J(\theta) J(θ)
越来越大,也就意味着策略网络越来越好。
使用策略梯度上升更新 θ \theta θ ,使得 J ( θ ) J(\theta) J(θ)增大。
设当前策略网络的参数为 θ \theta θ,做梯度上升更新参数,得到新的参数 θ ′ \theta' θ′, β \beta β为学习率
θ ′ = θ + β ⋅ ∂ V ( s ; θ ) ∂ θ \theta' =\theta+\beta \cdot \frac{\mathrm{\partial}V(s;\theta)}{\mathrm{\partial}\theta} θ′=θ+β⋅∂θ∂V(s;θ)
策略梯度(Policy Gradient)
∂ V ( s ; θ ) ∂ θ \frac{\mathrm{\partial}V(s;\theta)}{\mathrm{\partial}\theta} ∂θ∂V(s;θ)大概推导 不严谨 实际上 Q π Q_\pi Qπ中也有 θ \theta θ要求导

使用策略梯度更新策略网络
算法:
1、在 t t t时刻观测到状态 s t s_t st
2、根据策略网络 π ( . ∣ s t ; θ ) \pi(.|s_t;\theta) π(.∣st;θ)随机抽样一个动作 a t a_t at
3、计算动作价值 q t ≈ Q π ( s t , a t ) q_t \approx Q_\pi(s_t,a_t) qt≈Qπ(st,at)
4、计算策略网络关于参数 θ \theta θ的微分 d θ = ∂ l n π ( a ∣ s ; θ ) ∂ θ ∣ θ = θ t d\theta = \frac{\mathrm{\partial}ln\pi(a|s;\theta)}{\mathrm{\partial}\theta}|_{\theta=\theta_t} dθ=∂θ∂lnπ(a∣s;θ)∣θ=θt
5、计算近似策略梯度 g ( a t , θ t ) = q t , d θ g(a_t,\theta_t)=q_t,d\theta g(at,θt)=qt,dθ
6、更新策略网络: θ t + 1 = θ t + β ⋅ g ( a t , θ t ) \theta_{t+1}=\theta_t+\beta \cdot g(a_t,\theta_t) θt+1=θt+β⋅g(at,θt)
在第 3 步中,怎么计算 q t q_t qt?
在后面章节中,我们用两种方法对 Q π ( s , a ) Q_\pi(s,a) Qπ(s,a) 做近似。
1、REINFORCE 算法
用实际观测的回报 u u u近似 Q π ( s , a ) Q_\pi(s,a) Qπ(s,a)。
2、actor-critic 算法
用神经网络 q ( s , a ; w ) q(s,a;w) q(s,a;w)近似 Q π ( s , a ) Q_\pi(s,a) Qπ(s,a)。
所以想要近似求得 π \pi π函数 还要近似求得 Q π Q_\pi Qπ函数
相关文章:
强化学习p3-策略学习
Policy Network (策略网络) 我们无法知道策略函数 π \pi π所以要做函数近似,求一个近似的策略函数 使用策略网络 π ( a ∣ s ; θ ) \pi(a|s;\theta) π(a∣s;θ) 去近似策略函数 π ( a ∣ s ) \pi(a|s) π(a∣s) ∑ a ∈ A π ( a ∣ s ; θ ) 1 \sum_{a\in …...

初学Verilog语言基础笔记整理(实例点灯代码分析)持续更新~
实例:点灯学习 一、Verilog语法学习 1. 参考文章 刚接触Verilog,作为一个硬件小白,只能尝试着去理解,文章未完…持续更新。 参考博客文章: Verilog语言入门学习(1)Verilog语法【Verilog】一文…...
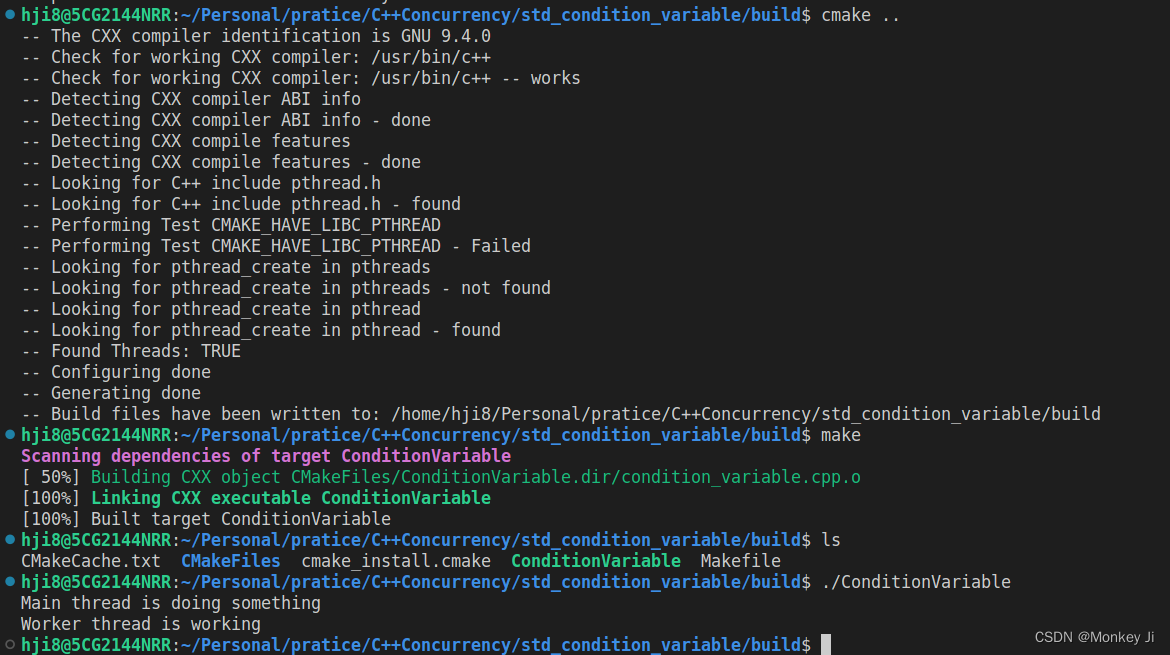
关于 std::condition_variable
一. std::condition_variable是什么? std::condition_variable 是 C 标准库提供的一个线程同步的工具,用于实现线程间的条件变量等待和通知机制。 条件变量的发生通常与某个共享变量的状态改变相关。 在多线程编程中,条件变量通常和互斥锁…...
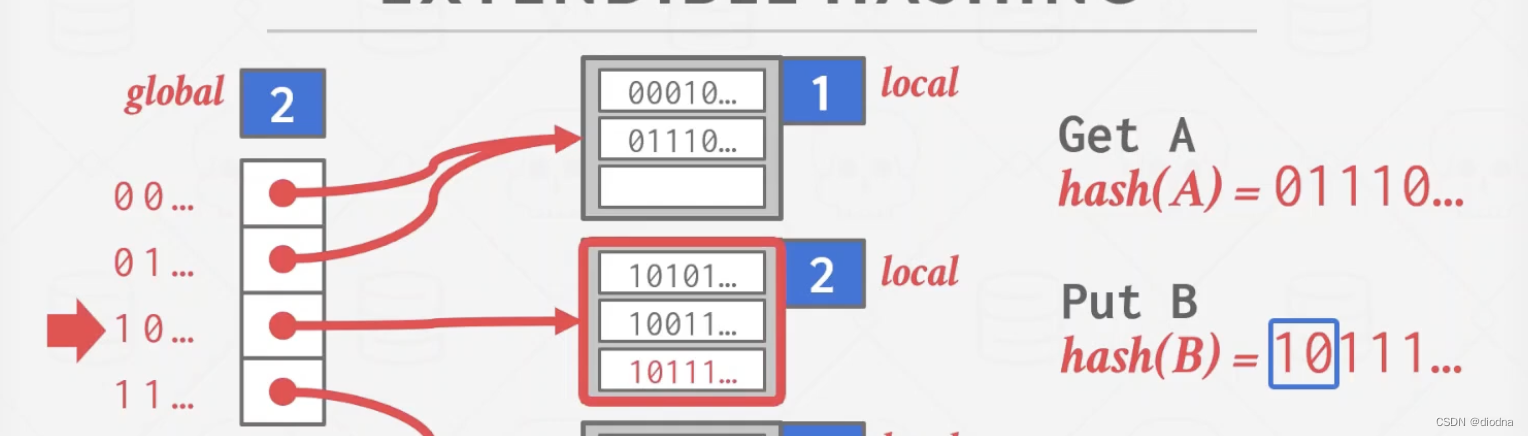
可拓展哈希
可拓展哈希 借CMU 15445的ppt截图来说明问题。 我们传统静态hash的过程是hash函数后直接将值存入对应的bucket,但是在可扩展hash中,得查询Directory(左),存入directory指向的bucket(右)。 下面…...

Java 版 spring cloud 工程系统管理 +二次开发 工程项目管理系统源码
工程项目各模块及其功能点清单 一、系统管理 1、数据字典:实现对数据字典标签的增删改查操作 2、编码管理:实现对系统编码的增删改查操作 3、用户管理:管理和查看用户角色 4、菜单管理:实现对系统菜单的增删改查操…...

通过伴随矩阵怎么求逆矩阵
设矩阵A为n阶方阵,其伴随矩阵为Adj(A),则A的逆矩阵为: A⁻ (1/|A|) Adj(A) |A|为A的行列式 Adj(A)为A的伴随矩阵 具体步骤如下: 求出A的行列式|A| 求出A的伴随矩阵 Adj(A) 。伴随矩阵的定义为:对于A的第i行第j列…...

巡检机器人之仪表识别系统
作者主页:爱笑的男孩。 博客简介:分享机器学习、深度学习、python相关内容、日常BUG解决方法及Windows&Linux实践小技巧。 如发现文章有误,麻烦请指出,我会及时去纠正。有其他需要可以私信我或者发我邮箱:zhilong666foxmail.c…...
)
面试官反感的求职者(下)
上期给大家总结了面试中常见的一些问题,今天就接着上次的话题再给大家说说HR反感的求职者,希望同学们可以自省,避免踩雷。小编从如信银行考试中心了解到的有: 第一、缺乏个性者 这种考生在答题中往往表现得千篇一律,从…...
-生存曲线(LM曲线)(补充篇))
可视化绘图技巧100篇分析篇(二)-生存曲线(LM曲线)(补充篇)
目录 前言 知识储备 生存分析中的基本概念 生存分析 (survival analysis) 事件 (event)...

【100%通过率 】【华为OD机试python】钟表重合时刻【 2023 Q1考试题 A卷|100分】
华为OD机试- 题目列表 2023Q1 点这里!! 2023华为OD机试-刷题指南 点这里!! ■ 题目描述 钟表是日常生活中不可缺少的时间度量计, 其时针、分针、秒针三者的转动速度满足特定规律(见备注)。 现在输入时刻 time ,请计算出时刻 time 小时和 time+1 小时之间, 时针和分针…...

Java线程池编码示例
第1步:自定义线程实现类 Java中多线程编码时,定义线程类有两种方式: 继承Thread类实现Runnable接口(由于Java的单继承特性,一般推荐使用此方式) public class BizThread implements Runnable {private int …...

如何优化Android 4.x系统设置字体大小
android4.x系统设置字体大小导致应用布局混乱的解决方案 在前几年,Android系统的设置界面还是相对简单的,用户可以通过设置菜单进行各种系统设置,如字体大小、壁纸、铃声等。但是随着用户对系统功能的需求越来越多,Android系统也在…...
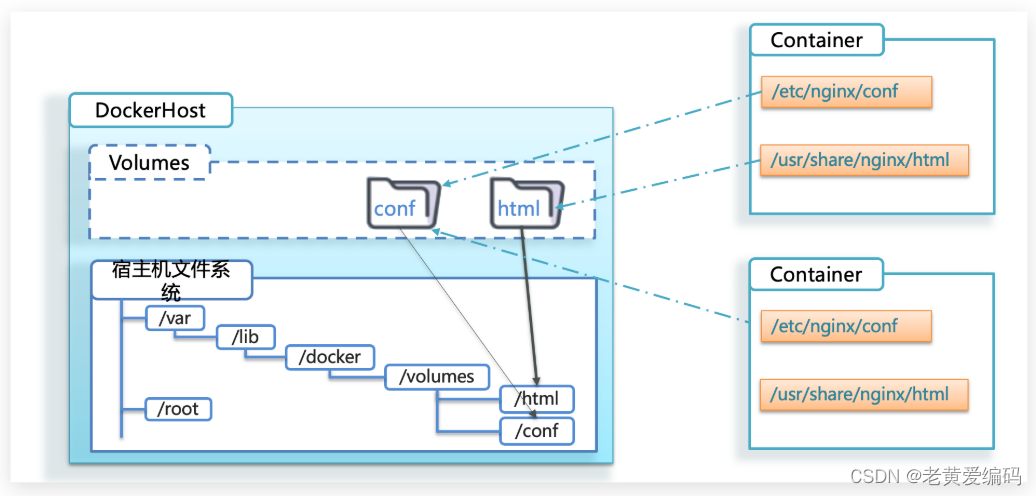
Docker安装、Docker基本操作
一、Dokcer安装 1.安装 # 1、yum 包更新到最新,需要几分钟时间(注意:也可以直接跨过) sudo yum update # 2、作用:安装需要的软件包, yum-util 提供yum-config-manager功能,另外两个是devicemapper驱动依赖的 sudo yum install -y yum-util…...

系统集成项目管理工程师知识点总结
项目经理的五种权利: 职位权力: 来源于管理者在组织中的职位和职权。罚权力: 使用降职、扣薪、惩罚、批评、威胁等负面手段的能力。奖励权力: 给予下属奖励的能力专家权力: 来源于个人的专业技能。参照(号…...

【游戏里的网络同步分析】马里奥制造2 多人模式
前置知识 先说几个游戏设计的术语。 PlayerAgent是玩家控制的网络游戏中的角色形象,也是代表在游戏空间中的玩家,被唯一PlayerController所拥有,被所有用户可观测到。 在马里奥制造2中,PlayerAgent一共有四种:马里奥 …...

SSM框架学习-注解开发第三方bean管理
1. 复习xml配置文件管理第三方bean 在Spring中,可以使用依赖注入(Dependency Injection)来管理和使用第三方Bean。Spring提供了多种方式来进行依赖注入,比如构造函数注入、Setter方法注入、字段注入等。下面以Setter方法注入为例&…...
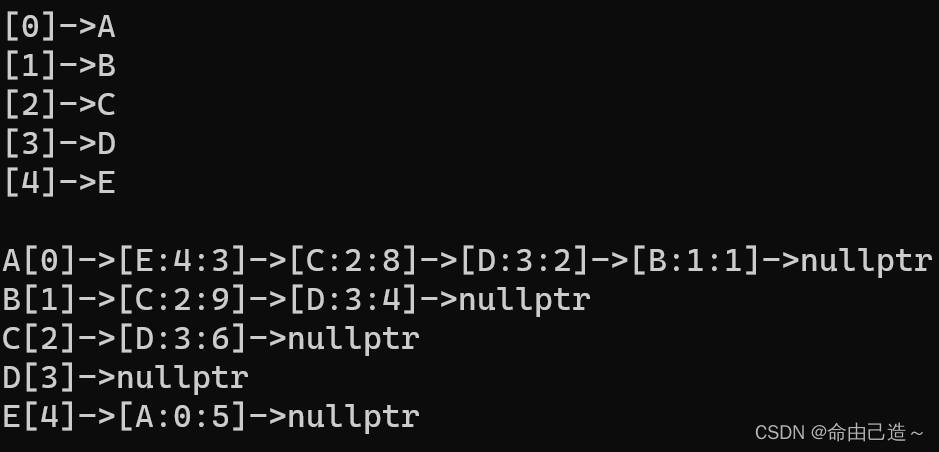
【数据结构与算法】图——邻接表与邻接矩阵
文章目录 一、图的基本概念二、图的存储结构2.1 邻接矩阵2.2 邻接表2.3 邻接矩阵的实现2.4 邻接表的实现 三、总结 一、图的基本概念 图(Graph)是由顶点的有穷非空集合和顶点之间边的集合组成,通常表示为:G(V,E&#…...

网安笔记02 密码学基础
密码学概述 • 1.1、密码学的基本概念 密码编码学 : 密码编制 密码分析学 : 密码破译 密码学 : 研究密码保护 通信手段的科学, 密码编码学密码分析学 密码技术: 把可理解的消息伪装为不可理解的消息,再复原成原消息的科学 概…...

open3d io操作
目录 1. read_image, write_image 2. read_point_cloud, write_point_cloud 3. 深度相机IO操作 4. Mesh文件读取 1. read_image, write_image 读取jpg. png. bmp等文件 image_io.py import open3d as o3dif __name__ "__main__":img_data o3d.data.JuneauIma…...
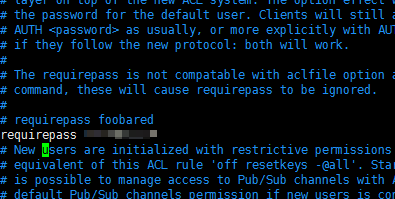
【Linux】Linux安装Redis(图文解说详细版)
文章目录 前言第一步,下载安装包第二步,上传安装包到/opt下(老规矩了,安装包在opt下)第三步,解压安装包第四步,编译第五步,安装第六步,配置redis第七步,设置开…...

Unity UGUI轻量UI框架:200行代码实现零GC界面管理
1. 为什么还要自己手写UI框架?——当UGUI原生方案开始“卡脖子”很多人看到这个标题第一反应是:“都2024年了,还手写UI框架?Asset Store里几十个成熟方案,NGUI、FairyGUI、TextMeshPro配套的UI系统一抓一大把ÿ…...

DMA-330地址空间限制与扩展方案解析
1. DMA-330地址空间限制解析DMA-330作为Arm CoreLink系列中的直接内存访问控制器,其物理寻址能力直接由AxADDR信号宽度决定。这个32位地址总线宽度意味着它原生仅支持4GB(2^32字节)的物理地址空间访问。在实际嵌入式系统设计中,这…...

DeepSeek基准测试避坑手册:92%开发者忽略的4大陷阱——硬件配置偏差、tokenizer不一致、batch size幻觉、温度值污染
更多请点击: https://codechina.net 第一章:DeepSeek基准测试避坑手册:92%开发者忽略的4大陷阱——硬件配置偏差、tokenizer不一致、batch size幻觉、温度值污染 硬件配置偏差:GPU显存与计算精度的隐性干扰 在A100(8…...

政企数据安全:危机与出路
随着数字化转型的浪潮席卷全球,公共部门积累的数据量呈爆炸式增长。从公民个人信息到公共服务记录,从财政预算到基础设施管理数据——这些宝贵资源在提升政府治理效率的同时,也悄然成为网络犯罪分子的“新猎物”。当公共数据逐渐成为数字时代…...

新能源车轻量化为什么开始盯上高强镁合金?
续航,是悬在每一台纯电动汽车头上的达摩克利斯之剑。多充一度电、多堆一些正极材料,是一条路;但还有另一条路——把车造得更轻。 SAE(美国汽车工程师学会)的测算已经被反复引用:整车每减重100千克ÿ…...

如何进行TVA仿真引擎的“光照地狱”训练?
重磅预告:本专栏将独家连载系列丛书《智能体视觉技术与应用》部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。Bohan先生师从美国三院院士、“…...

基于STM32与LoRa的低功耗物联网气象站DIY全攻略
1. 项目概述:打造一个低功耗的家庭气象站前阵子想给家里的智能家居系统加点“环境感知”能力,琢磨着搞个能实时监测室外温湿度、风速风向的小玩意儿。市面上成品气象站要么数据出不来,要么功耗感人,不适合长期户外部署。于是&…...

告别鼠标点击,微博图片批量下载的轻松方案
告别鼠标点击,微博图片批量下载的轻松方案 【免费下载链接】weiboPicDownloader Download weibo images without logging-in 项目地址: https://gitcode.com/gh_mirrors/we/weiboPicDownloader 还记得那个周末的下午吗?你喜欢的博主发布了九宫格美…...

终极STL到STEP转换指南:如何实现3D打印模型到CAD设计的无缝衔接
终极STL到STEP转换指南:如何实现3D打印模型到CAD设计的无缝衔接 【免费下载链接】stltostp Convert stl files to STEP brep files 项目地址: https://gitcode.com/gh_mirrors/st/stltostp 在数字化制造和工程设计领域,STL到STEP转换已成为连接3D…...

收藏干货|2026 版双非零基础入局大模型开发,RAG 与 Agent 就业上岸全攻略
日常总能收到不少初学伙伴的私信,大家普遍都有同一个疑惑:二本及普通院校学历,零基础入门 RAG、Agent 大模型应用开发,究竟能不能顺利入职?行业后续发展前景又如何? 本篇 2026 年全新内容,不空谈…...