python基于卷积神经网络实现自定义数据集训练与测试
注意:
如何更改图像尺寸在这篇文章中,修改完之后你就可以把你自己的数据集应用到网络。如果你的训练集与测试集也分别为30和5,并且样本类别也为3类,那么你只需要更改图像标签文件地址以及标签内容(如下面两图所示)。 图片名-标签文件如何生成请看这篇文章。
如果你想扩大数据集量,那么你只需要更改对应的文件内标签长度以及数据集图像量。


再次注意:我已经扩大了数据集的数量,展示在正文1的后面!
正文1:
样本取自岩心照片,识别岩心是最基础的地质工作,如果用机器来划分岩心类型则会大大削减工作量。
下面叙述中0指代Anhydrite_rock(膏岩),1指代Limestone(灰岩),2指代Gray Anhydrite_rock(灰质膏岩)。
原本自定义训练集与测试集是这样的:
训练集x_train:

标签是这样的y_train:

测试集x_test:
标签是这样的y_test:

但是由于图片像素为3456*5184,电脑内存不足,所以只能统一修i该为下面(256*256):
训练集:
测试集:

两个数据集的标签没有更改。
#导入库
import os
import cv2
import torch
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
from torchvision.io import read_image
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
from torchvision import transforms
import tensorflow.keras as ka
import datetime
import tensorflow as tf
import os
import PySide2
from tensorflow.keras.layers import Conv2D,BatchNormalization,Activation,MaxPooling2D,Dropout,Flatten,Dense
from tensorflow.keras import Model
import tensorflow as tf'''加载数据集'''
#创建自定义数据集类,参考可见:http://t.csdn.cn/gkVNC
class Custom_Dataset(Dataset):#函数,设置图像集路径索引、图像标签文件读取def __init__(self, img_dir, img_label_dir, transform=None):super().__init__()self.img_dir = img_dirself.img_labels = pd.read_csv(img_label_dir)self.transform = transform#函数,设置数据集长度def __len__(self):return len(self.img_labels)#函数,设置指定图像读取、指定图像标签索引def __getitem__(self, index):#'所在文件路径+指定图像名'img_path = os.path.join(self.img_dir + self.img_labels.iloc[index, 1])#读指定图像#image = cv2.imdecode(np.fromfile(img_path,dtype=np.uint8),-1)image=plt.imread(img_path)#height,width = image.shape[0],image.shape[1] #获取原图像的垂直方向尺寸和水平方向尺寸。#image = image.resize((height//4,width//4))#'指定图像标签'label = self.img_labels.iloc[index, 0]return image, label'''画图函数'''
def tensorToimg(img_tensor):img=img_tensorplt.imshow(img)#python3.X必须加下行plt.show()#标签指示含义
label_dic = {0: '膏岩', 1: '灰岩', 2: '灰质膏岩'}
'''图像集及标签路径'''
label_path = "C:/Users/yeahamen/AppData/Local/Programs/Python/Python310/train_label.csv"
img_root_path = "C:/Users/yeahamen/Desktop/custom_dataset/train_revise/"
test_image_path="C:/Users/yeahamen/Desktop/custom_dataset/test_revise/"
test_label_path="C:/Users/yeahamen/AppData/Local/Programs/Python/Python310/test_label.csv"
#加载图像集与标签路径到函数
#实例化类
dataset = Custom_Dataset(img_root_path, label_path)
dataset_test = Custom_Dataset(test_image_path,test_label_path)'''查看指定图像(18)'''
#索引指定位置的图像及标签
image, label = dataset.__getitem__(18)
#展示图片及其形状(tensor)
print('单张图片(18)形状:',image.shape)
print('单张图片(18)标签:',label_dic[label])#批量输出
dataloader = DataLoader(dataset, batch_size=1, shuffle=True)
'''查看图像的形状'''
for imgs, labels in dataloader:print('一批训练为1张图片(随机)形状:',imgs.shape)#一批图像形状:torch.Size([5, 3456, 5184, 3])print('一批训练为1张图片(随机)标签:',labels)#标签:tensor([3, 2, 3, 3, 1])break#仅需要查看一批'''查看自定义数据集'''
showimages=[]
showlabels=[]
#把图片信息依次加载到列表
for imgs, labels in dataloader:c = torch.squeeze(imgs, 0)#减去一维数据形成图片固定三参数d = torch.squeeze(labels,0)showimages.append(c)showlabels.append(d)
#依次画出图片
def show_image(nrow, ncol, sharex, sharey):fig, axs = plt.subplots(nrow, ncol, sharex=sharex, sharey=sharey, figsize=(10, 10))for i in range(0,nrow):for j in range(0,ncol):axs[i,j].imshow(showimages[i*4+j])axs[i,j].set_title('Label={}'.format(showlabels[i*4+j]))plt.show()plt.tight_layout()
#给定参数
#show_image(2, 4, False, False)'''创建训练集与测试集'''
dataloader_train = DataLoader(dataset, batch_size=30, shuffle=True)
for imgs, labels in dataloader_train:x_train=imgsy_train=labels
print('训练集图像形状:',x_train.shape)
print('训练集标签形状:',y_train.shape)
dataloader_test = DataLoader(dataset_test, batch_size=5, shuffle=True)
for imgs, labels in dataloader_test:x_test=imgsy_test=labels
print('测试集图像形状:',x_test.shape)
print('测试集标签形状:',y_test.shape)'''将图像转变为网络可用的数据类型'''
x_train,x_test = tf.cast(x_train/255.0,tf.float32),tf.cast(x_test/255.0,tf.float32)
y_train,y_test = tf.cast(y_train,tf.int16),tf.cast(y_test,tf.int16)#参考:http://t.csdn.cn/eRQX2
print('注意:',x_train.shape)
'''归一化灰度值'''
x_train = x_train/255
x_test = x_test/255'''标签转为独热编码,注意:如果标签不是从0开始,独热编码会增加1位(即0)'''
y_train = ka.utils.to_categorical(y_train)
y_test = ka.utils.to_categorical(y_test)
print('独热后训练集标签形状:',y_train.shape)
print('独热后测试集标签形状:',y_test.shape)
#获取测试集特征数
num_classes = y_test.shape[1]'''CNN模型'''
#输入3456*5184*3
model = ka.Sequential([ka.layers.Conv2D(filters = 32,kernel_size=(5,5),input_shape=(256,256,3),data_format="channels_last",activation='relu'),#卷积3456*5184*32、卷积层;参量依次为:卷积核个数、卷积核尺寸、单个像素点尺寸、使用ReLu激活函数、解释可见:http://t.csdn.cn/6s3dzka.layers.MaxPooling2D(pool_size=(4,4),strides = None,padding='VALID'),#池化1—864*1296*32、最大池化层,池化核尺寸4*4、步长默认为4、无填充、解释可见:http://t.csdn.cn/sES2uka.layers.MaxPooling2D(pool_size=(2,2),strides = None,padding='VALID'),#池化2—432*648*32再加一个最大池化层,池化核尺寸为2*2、步长默认为2、无填充ka.layers.Dropout(0.2),#模型正则化防止过拟合, 只会在训练时才会起作用,随机设定输入的值x的某一维=0,这个概率为输入的百分之20,即丢掉1/5神经元不激活#在模型预测时,不生效,所有神经元均保留也就是不进行dropout。解释可见:http://t.csdn.cn/RXbmS、http://t.csdn.cn/zAIuJka.layers.Flatten(),#拉平432*648*32=8957952;拉平池化层为一个向量ka.layers.BatchNormalization(),#批标准化层,提高模型准确率ka.layers.Dense(10,activation='relu'),#全连接层1,10个神经元,激活函数为ReLuka.layers.Dense(num_classes,activation='softmax')])#全连接层2,3个神经元(对应标签0-2),激活函数为softmax,作用是把神经网络的输出转化为概率,参考可见:http://t.csdn.cn/bcWgu;http://t.csdn.cn/A1Jyn
'''模型参数展示、编译与训练'''
model.summary()
model.compile(loss='categorical_crossentropy',optimizer='adam',metrics=['accuracy'])
startdate = datetime.datetime.now()
#训练轮数epochs=n,即训练n轮
model.fit(x_train,y_train,validation_data=(x_test,y_test),epochs=100,batch_size=1,verbose=2)
#训练样本、训练标签、指定验证数据为测试集、训练轮数、显示每一轮训练进程,参考可见:http://t.csdn.cn/oE46K
#获取训练结束时间
enndate=datetime.datetime.now()
print("训练用时:"+str(enndate-startdate))程序运行结果是这样的:
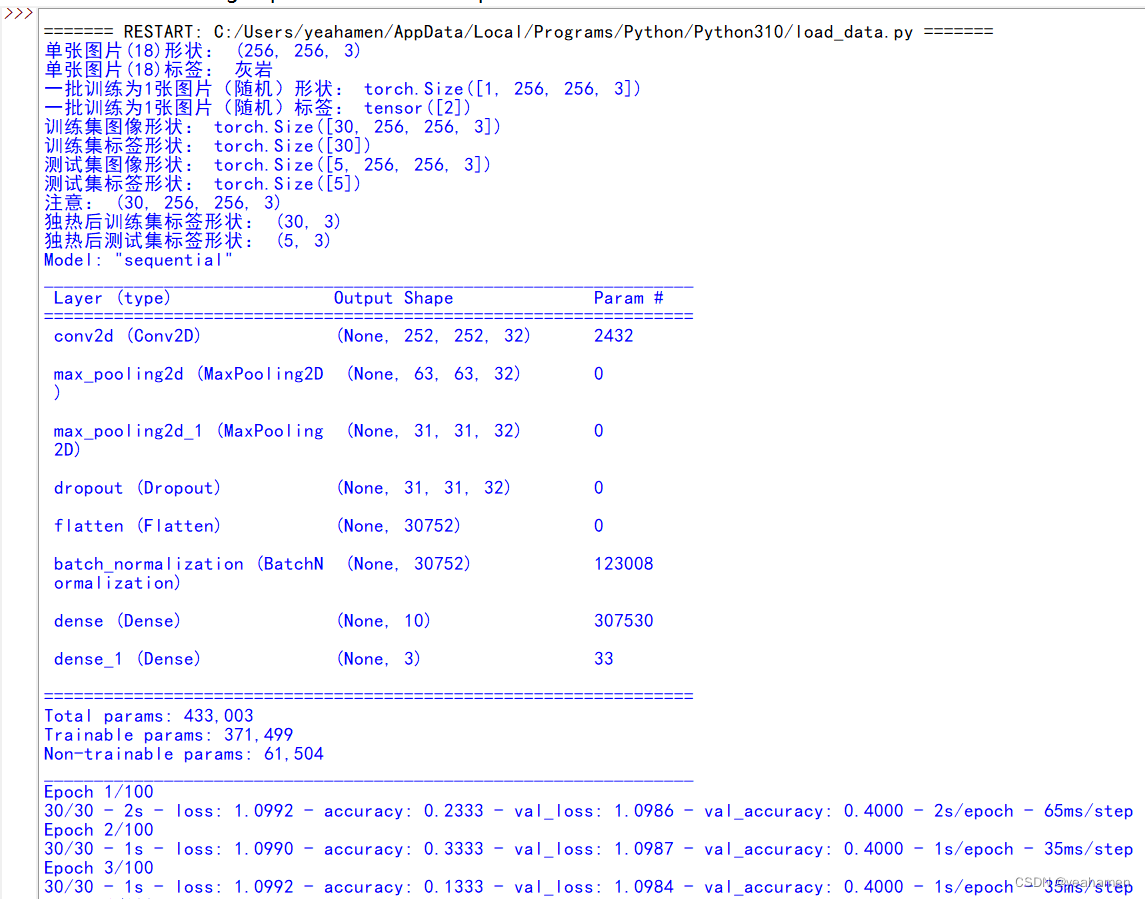
显然由于样本过少,模型训练精度并不高,3轮训练达到0.4;如果有时间再进一步增加样本数量并完善。
正文2
由之前的30个训练集、5个测试集扩大到320个训练集,40个测试集:
训练集:
测试集 :

修改后的代码如下,你可以与上面的代码进行对比,从而修改数据集量为适合你的大小!
#导入库
import os
import cv2
import torch
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
from torchvision.io import read_image
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
from torchvision import transforms
import tensorflow.keras as ka
import datetime
import tensorflow as tf
import os
import PySide2
from tensorflow.keras.layers import Conv2D,BatchNormalization,Activation,MaxPooling2D,Dropout,Flatten,Dense
from tensorflow.keras import Model
import tensorflow as tf'''加载数据集'''
#创建自定义数据集类,参考可见:http://t.csdn.cn/gkVNC
class Custom_Dataset(Dataset):#函数,设置图像集路径索引、图像标签文件读取def __init__(self, img_dir, img_label_dir, transform=None):super().__init__()self.img_dir = img_dirself.img_labels = pd.read_csv(img_label_dir)self.transform = transform#函数,设置数据集长度def __len__(self):return len(self.img_labels)#函数,设置指定图像读取、指定图像标签索引def __getitem__(self, index):#'所在文件路径+指定图像名'img_path = os.path.join(self.img_dir + self.img_labels.iloc[index, 1])#读指定图像#image = cv2.imdecode(np.fromfile(img_path,dtype=np.uint8),-1)image=plt.imread(img_path)#height,width = image.shape[0],image.shape[1] #获取原图像的垂直方向尺寸和水平方向尺寸。#image = image.resize((height//4,width//4))#'指定图像标签'label = self.img_labels.iloc[index, 0]return image, label'''画图函数'''
def tensorToimg(img_tensor):img=img_tensorplt.imshow(img)#python3.X必须加下行plt.show()#标签指示含义
label_dic = {0: '膏岩', 1: '灰岩', 2: '灰质膏岩',3: '膏质灰岩'}
'''图像集及标签路径'''
label_path = "C:/Users/yeahamen/AppData/Local/Programs/Python/Python310/train_label.csv"
img_root_path = "C:/Users/yeahamen/Desktop/custom_dataset/train_revise/"
test_image_path="C:/Users/yeahamen/Desktop/custom_dataset/test_revise/"
test_label_path="C:/Users/yeahamen/AppData/Local/Programs/Python/Python310/test_label.csv"
#加载图像集与标签路径到函数
#实例化类
dataset = Custom_Dataset(img_root_path, label_path)
dataset_test = Custom_Dataset(test_image_path,test_label_path)'''查看指定图像(18)'''
#索引指定位置的图像及标签
image, label = dataset.__getitem__(18)
#展示图片及其形状(tensor)
print('单张图片(18)形状:',image.shape)
print('单张图片(18)标签:',label_dic[label])#批量输出
dataloader = DataLoader(dataset, batch_size=1, shuffle=True)
'''查看图像的形状'''
for imgs, labels in dataloader:print('一批训练为1张图片(随机)形状:',imgs.shape)#一批图像形状:torch.Size([5, 256, 256, 3])print('一批训练为1张图片(随机)标签:',labels)#标签:tensor([3, 2, 3, 3, 1])break#仅需要查看一批'''查看自定义数据集'''
showimages=[]
showlabels=[]
#把图片信息依次加载到列表
for imgs, labels in dataloader:c = torch.squeeze(imgs, 0)#减去一维数据形成图片固定三参数d = torch.squeeze(labels,0)showimages.append(c)showlabels.append(d)
#依次画出图片
def show_image(nrow, ncol, sharex, sharey):fig, axs = plt.subplots(nrow, ncol, sharex=sharex, sharey=sharey, figsize=(10, 10))for i in range(0,nrow):for j in range(0,ncol):axs[i,j].imshow(showimages[i*4+j])axs[i,j].set_title('Label={}'.format(showlabels[i*4+j]))plt.show()plt.tight_layout()
#给定参数
#show_image(2, 4, False, False)'''创建训练集与测试集'''
dataloader_train = DataLoader(dataset, batch_size=320, shuffle=True)
for imgs, labels in dataloader_train:x_train=imgsy_train=labels
print('训练集图像形状:',x_train.shape)
print('训练集标签形状:',y_train.shape)
dataloader_test = DataLoader(dataset_test, batch_size=40, shuffle=True)
for imgs, labels in dataloader_test:x_test=imgsy_test=labels
print('测试集图像形状:',x_test.shape)
print('测试集标签形状:',y_test.shape)'''将图像转变为网络可用的数据类型'''
X_test = x_test#这里保留是为了预测时查看原始图像
Y_test = y_test#这里保留是为了预测时查看原始标签
x_train,x_test = tf.cast(x_train/255.0,tf.float32),tf.cast(x_test/255.0,tf.float32)
y_train,y_test = tf.cast(y_train,tf.int16),tf.cast(y_test,tf.int16)#参考:http://t.csdn.cn/eRQX2
print('注意:',x_train.shape)
'''归一化灰度值'''
x_train = x_train/255
x_test = x_test/255'''标签转为独热编码,注意:如果标签不是从0开始,独热编码会增加1位(即0)'''
y_train = ka.utils.to_categorical(y_train)
y_test = ka.utils.to_categorical(y_test)
print('独热后训练集标签形状:',y_train.shape)
print('独热后测试集标签形状:',y_test.shape)
#获取测试集特征数
num_classes = y_test.shape[1]'''CNN模型'''
#输入256*256*3
model = ka.Sequential([ka.layers.Conv2D(filters = 32,kernel_size=(5,5),input_shape=(256,256,3),data_format="channels_last",activation='relu'),#卷积252*252*32、卷积层;参量依次为:卷积核个数、卷积核尺寸、单个像素点尺寸、使用ReLu激活函数、解释可见:http://t.csdn.cn/6s3dzka.layers.MaxPooling2D(pool_size=(4,4),strides = None,padding='VALID'),#池化1—63*63*32、最大池化层,池化核尺寸4*4、步长默认为4、无填充、解释可见:http://t.csdn.cn/sES2uka.layers.MaxPooling2D(pool_size=(2,2),strides = None,padding='VALID'),#池化2—31*31*32再加一个最大池化层,池化核尺寸为2*2、步长默认为2、无填充ka.layers.Dropout(0.2),#模型正则化防止过拟合, 只会在训练时才会起作用,随机设定输入的值x的某一维=0,这个概率为输入的百分之20,即丢掉1/5神经元不激活#在模型预测时,不生效,所有神经元均保留也就是不进行dropout。解释可见:http://t.csdn.cn/RXbmS、http://t.csdn.cn/zAIuJka.layers.Flatten(),#拉平432*648*32=8957952;拉平池化层为一个向量ka.layers.BatchNormalization(),#批标准化层,提高模型准确率ka.layers.Dense(50,activation='relu'),#全连接层1,10个神经元,激活函数为ReLuka.layers.Dense(num_classes,activation='softmax')])#全连接层2,4个神经元(对应标签0-3),激活函数为softmax,作用是把神经网络的输出转化为概率,参考可见:http://t.csdn.cn/bcWgu;http://t.csdn.cn/A1Jyn
'''模型参数展示、编译与训练'''
model.summary()
model.compile(loss='categorical_crossentropy',optimizer='adam',metrics=['accuracy'])
startdate = datetime.datetime.now()
#训练轮数epochs=n,即训练n轮
history = model.fit(x_train,y_train,validation_data=(x_test,y_test),epochs=40,batch_size=5,verbose=2)
#训练样本、训练标签、指定验证数据为测试集、训练轮数、显示每一轮训练进程,参考可见:http://t.csdn.cn/oE46K
#获取训练结束时间
enndate=datetime.datetime.now()
print("训练用时:"+str(enndate-startdate))#模型损失值与精度画图展示
#参考http://t.csdn.cn/fUdtO
print(history.history)
loss = history.history['loss'] #训练集损失
val_loss = history.history['val_loss'] #测试集损失
acc = history.history['accuracy'] #训练集准确率
val_acc = history.history['val_accuracy'] #测试集准确率plt.figure(figsize=(10,3))
plt.subplot(121)
plt.plot(loss,color='b',label='train')
plt.plot(val_loss,color='r',label='test')
plt.ylabel('Loss')
plt.legend()plt.subplot(122)
plt.plot(acc,color='b',label='train')
plt.plot(val_acc,color='r',label='test')
plt.ylabel('Accuracy')
plt.legend()
plt.show()plt.figure(2)
'''使用模型进行预测'''
for i in range(10):#在测试集中随机选10个random_test = np.random.randint(1,40)plt.subplot(2,5,i+1)plt.axis('off')#去掉坐标轴plt.imshow(X_test[random_test])#展示要预测的图片predict_image = tf.reshape(x_test[random_test],(1,256,256,3))y_label_predict = np.argmax(model.predict(predict_image))#使用模型进行预测plt.title('R_value:'+str(Y_test[random_test])+'\nP_value:'+str(y_label_predict))#图名显示预测值与实际标签值进行对比
plt.show()
在这里我展示无论训练几轮都会有的输出面板:

下面展示训练5轮、10轮、20轮、40轮的结果。
训练5轮结果:

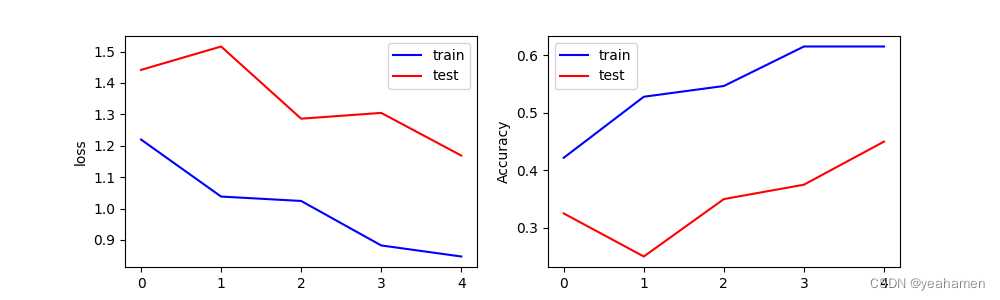

训练10轮结果:



训练20轮结果:
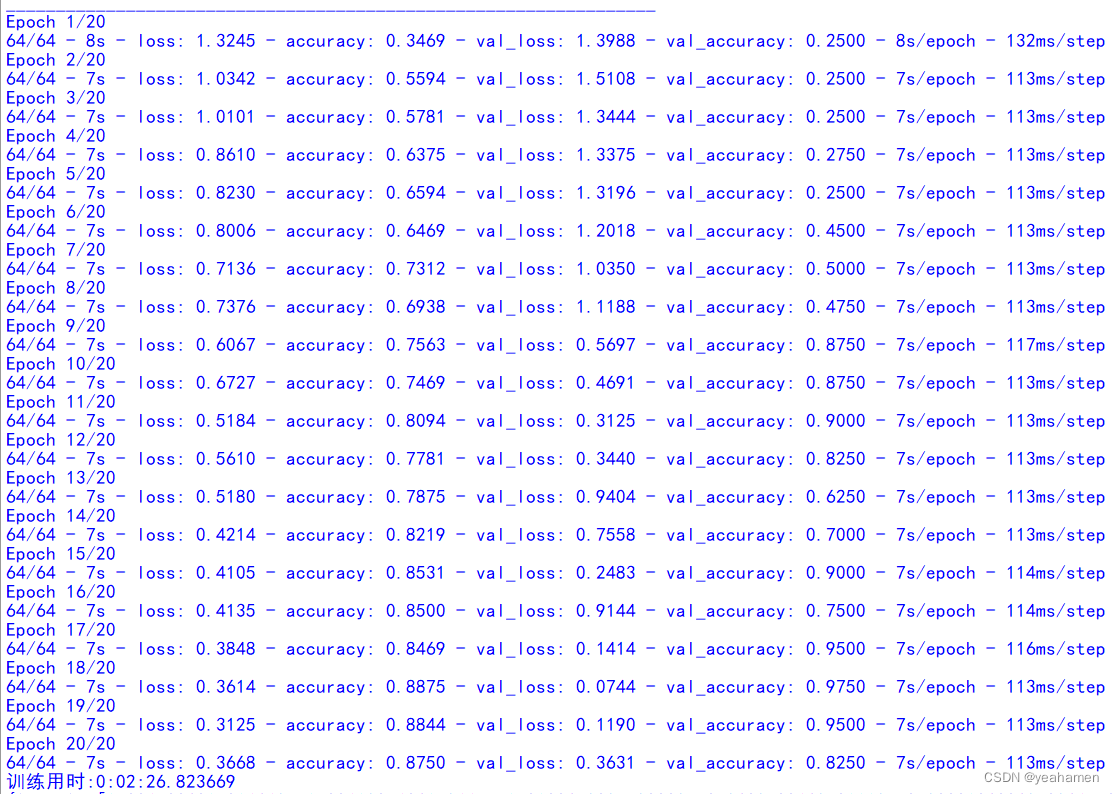


训练40轮结果:

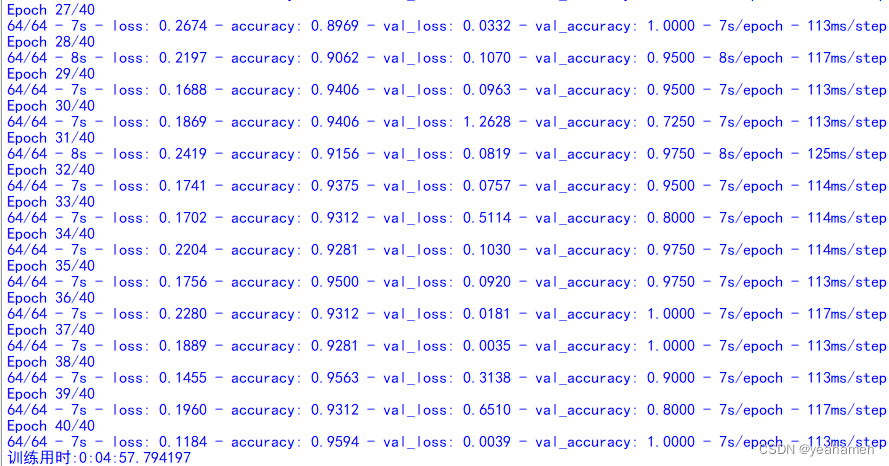

 识别精度的提升是显而易见的!
识别精度的提升是显而易见的!
最后放上整个实践过程用到的模块:
| import os |
| import cv2 |
| import torch |
| import pylab |
| import PySide2 |
| import datetime |
| import numpy as np |
| import pandas as pd |
| from PIL import Image |
| import tensorflow as tf |
| import tensorflow.keras as ka |
| from torchvision import models |
| import matplotlib.pyplot as plt |
| from tensorflow.keras import Model |
| from torchvision import transforms |
| from torch.utils.data import Dataset |
| from torchvision.io import read_image |
| from torch.utils.data import DataLoader |
| import tensorflow.keras.applications.vgg19 as vgg19 |
| import tensorflow.keras.preprocessing.image as imagepre |
| from tensorflow.keras.layers import Conv2D,BatchNormalization,Activation,MaxPooling2D,Dropout,Flatten,Dense |
相关文章:
python基于卷积神经网络实现自定义数据集训练与测试
注意: 如何更改图像尺寸在这篇文章中,修改完之后你就可以把你自己的数据集应用到网络。如果你的训练集与测试集也分别为30和5,并且样本类别也为3类,那么你只需要更改图像标签文件地址以及标签内容(如下面两图所示&…...
跟着LearnOpenGL学习3--四边形绘制
文章目录 一、前言二、元素缓冲对象三、完整代码四、绘制模式 一、前言 通过跟着LearnOpenGL学习2–三角形绘制一文,我们已经知道了怎么配置渲染管线,来绘制三角形; OpenGL主要处理三角形,当我们需要绘制别的图形时,…...

c#笔记-结构
装箱 结构是值类型。值类型不能继承其他类型,也不能被其他类型继承。 所以它的方法都是确定的,没有虚方法需要在运行时进行动态绑定。 值类型没有对象头,方法调用由编译器直接确定。 但是,如果使用引用类型变量(如接…...

Es分布式搜索引擎
目录 一、什么是ES? 二、什么是elk? 三、什么是倒排索引? 四、正向索引和倒排索引的优缺点对比 五、mysql数据库和es的区别? 六、索引库(es中的数据库表)操作有哪些? 八、ES分片存储原理 …...
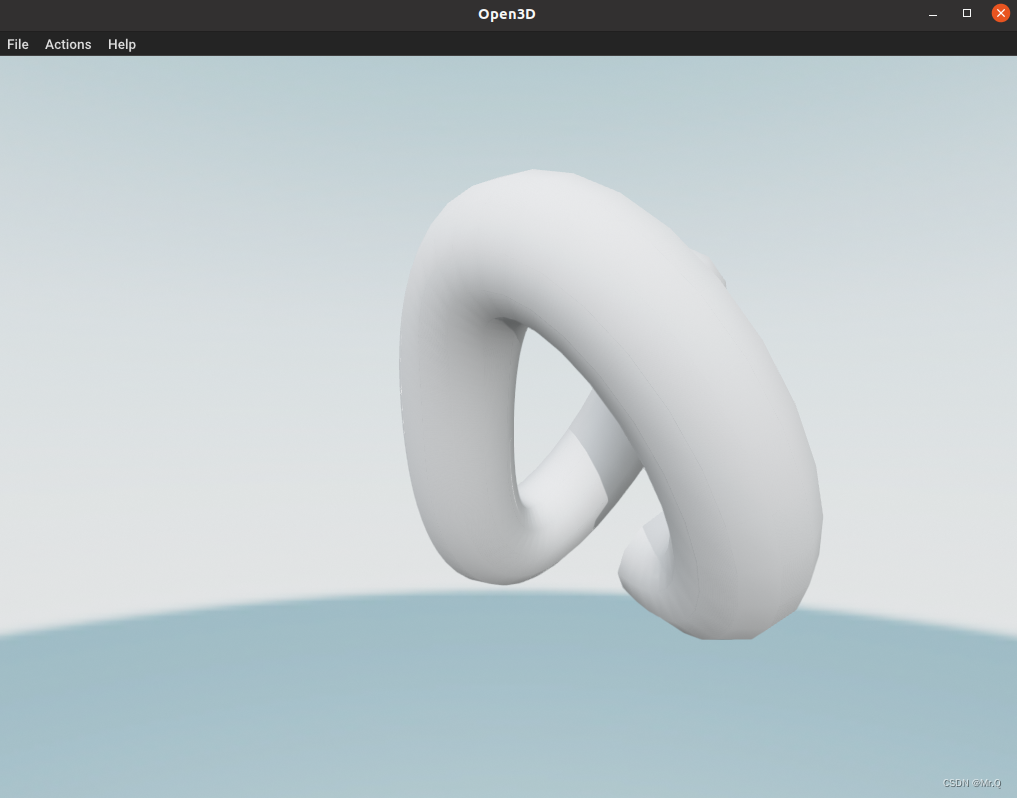
open3d 裁剪点云
目录 1. crop_point_cloud 2. crop 3. crop_mesh 1. crop_point_cloud 关键函数 chair vol.crop_point_cloud(pcd) # vol: SelectionPolygonVolume import open3d as o3dif __name__ "__main__":# 1. read pcdprint("Load a ply point cloud, crop it…...

如何对第三方相同请求进行筛选过滤
文章目录 问题背景处理思路注意事项代码实现 问题背景 公司内部多个系统共用一套用户体系库,对外(钉钉)我们是两个客户身份(这里是根据系统来的),例如当第三方服务向我们发起用户同步请求:是一个更新用户操作,它会同时发送一个 d…...

Go RPC
目录 文章目录 Go RPCHTTP RPCTCP RPCJSON RPC Go RPC Go 标准包中已经提供了对 RPC 的支持,而且支持三个级别的 RPC:TCP、HTTP、JSONRPC。但 Go 的 RPC 包是独一无二的 RPC,它和传统的 RPC 系统不同,它只支持 Go 开发的服务器与…...

真正的智能不仅仅是一个技术问题
智能并不是单一的技术问题,而是一个包括技术、人类智慧、社会制度和文化等多个方面的综合体,常常涉及技术变革、系统演变、运行方式创新、组织适应。智能是指人类的思考、判断、决策和创造等高级认知能力,可以通过技术手段来实现增强和扩展。…...

【数据结构】复杂度包装泛型
目录 1.时间和空间复杂度 1.1时间复杂度 1.2空间复杂度 2.包装类 2.1基本数据类型和对应的包装类 2.2装箱和拆箱 //阿里巴巴面试题 3.泛型 3.1擦除机制 3.2泛型的上界 1.时间和空间复杂度 1.1时间复杂度 定义:一个算法所花费的时间与其语句的执行次数成…...

Ae:绘画面板
Ae菜单:窗口/绘画 Paint 快捷键:Ctrl 8 绘画工具(画笔工具、仿制图章工具及橡皮擦工具)仅能工作在图层面板上。在使用绘画工具之前,建议先在绘画 Paint面板中查看或进行相关设置。 说明: 如果要在绘画描边…...
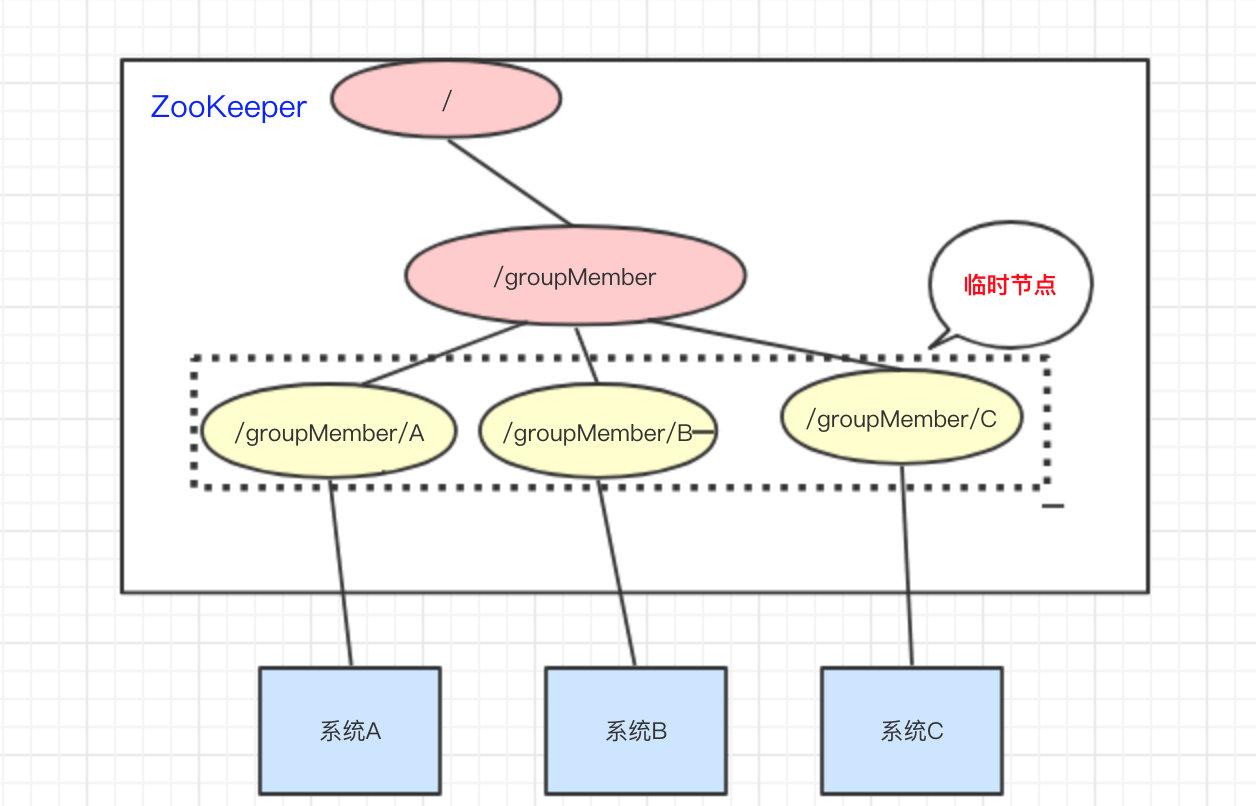
常见的锁和zookeeper
zookeeper 本文由 简悦 SimpRead 转码, 原文地址 zhuanlan.zhihu.com 前言 只有光头才能变强。 文本已收录至我的 GitHub 仓库,欢迎 Star:https://github.com/ZhongFuCheng3y/3y 上次写了一篇 什么是消息队列?以后,本来…...
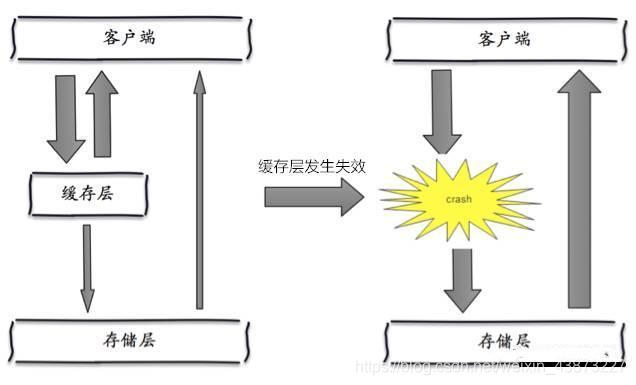
经验总结:(Redis NoSQL数据库快速入门)
一、Nosql概述 为什么使用Nosql 1、单机Mysql时代 90年代,一个网站的访问量一般不会太大,单个数据库完全够用。随着用户增多,网站出现以下问题 数据量增加到一定程度,单机数据库就放不下了数据的索引(B Tree),一个机…...
form表单与模板引擎
文章目录 一、form表单的基本使用1、什么是表单2、表单的组成部分3、 <form>标签的属性4、表单的同步提交及缺点(1) 什么是表单的同步提交(2) 表单同步提交的缺点(3) 如何解决表单同步提交的缺点 二、…...
医院检验信息管理系统源码(云LIS系统源码)JQuery、EasyUI
云LIS系统是一种医疗实验室信息管理系统,提供全面的实验室信息管理解决方案。它的主要功能包括样本管理、检测流程管理、报告管理、质量控制、数据分析和仪器管理等。 云LIS源码技术说明: 技术架构:Asp.NET CORE 3.1 MVC SQLserver Redis等…...

React 组件
文章目录 React 组件复合组件 React 组件 本节将讨论如何使用组件使得我们的应用更容易来管理。 接下来我们封装一个输出 “Hello World!” 的组件,组件名为 HelloMessage: React 实例 <!DOCTYPE html> <html> <head> &…...

硕士学位论文的几种常见节奏
摘要: 本文描述硕士学位论文的几种目录结构, 特别针对机器学习方向. 1. 基础版 XX算法及其在YY中的应用 针对情况: 只有一篇小论文支撑. 第 1 章: 引言 ( > 5页) 1.1 背景及意义 (应用背景、研究意义, 2 页) 1.2 研究进展及趋势 (算法方面, 2 页) 1.3 论文结构 (1 页) 第 …...

找兄弟单词
描述 定义一个单词的“兄弟单词”为:交换该单词字母顺序(注:可以交换任意次),而不添加、删除、修改原有的字母就能生成的单词。 兄弟单词要求和原来的单词不同。例如: ab 和 ba 是兄弟单词。 ab 和 ab 则不…...

python字典翻转教学
目录 第1关 创建大学英语四级单词字典 第2关 合并大学英语四六级词汇字典 第3关 查单词输出中文释义 第4关 删除字典中特定字母开头的单词 第5关 单词英汉记忆训练 第1关 创建大学英语四级单词字典 本关任务:编写一个能创建大学英语四级单词字典的小程序。 测…...
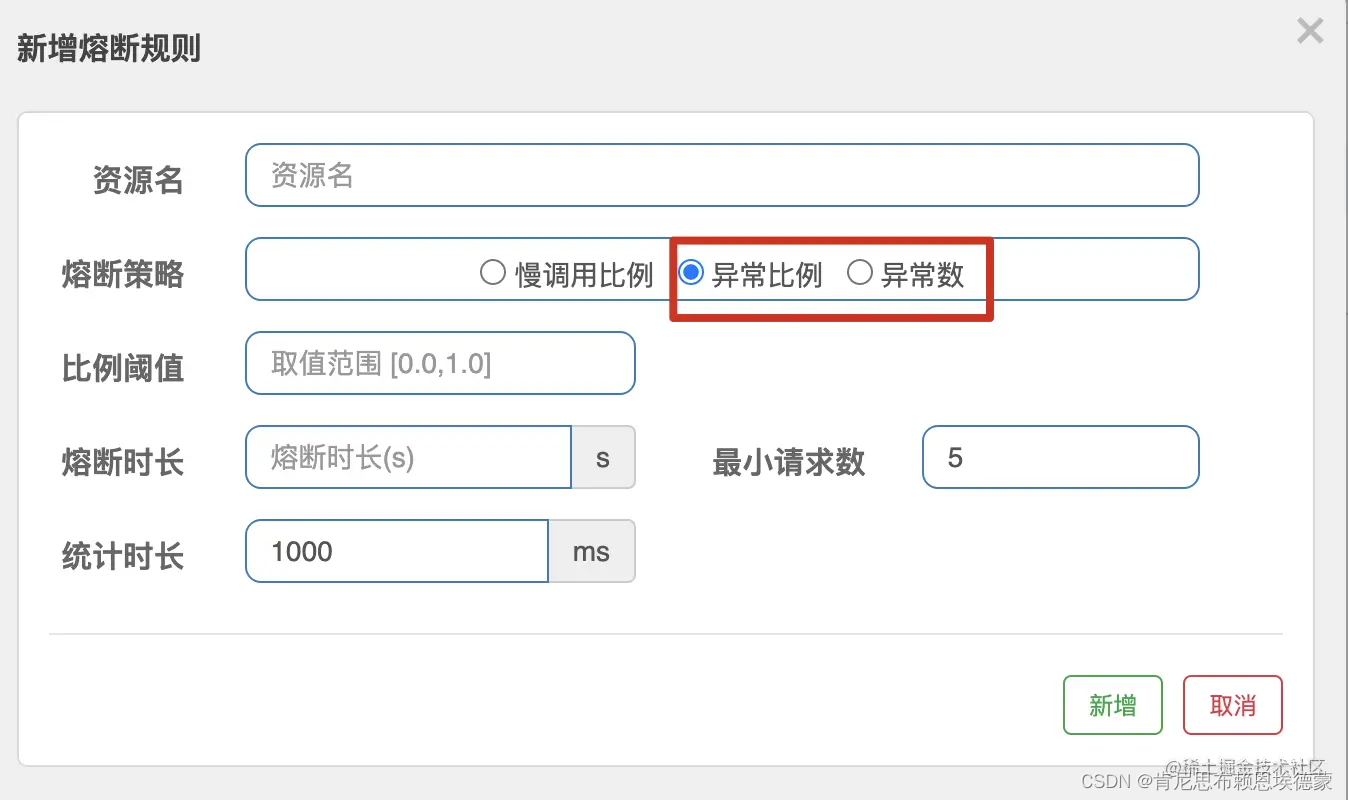
sentinel 随笔 3-降级处理
0. 像喝点东西,但不知道喝什么 先来段源码,看一下 我们在dashboard 录入的降级规则,都映射到哪些字段上 package com.alibaba.csp.sentinel.slots.block.degrade;public class DegradeRule extends AbstractRule {public DegradeRule(String…...

如何解决IP能ping通但无法上网的问题?
当我们在网络环境中遇到无法上网的问题时,可能会尝试使用ping命令来测试网络连接是否正常。如果ping测试成功,说明我们的IP地址能够和网络中其他设备进行通信,但是无法上网。这种情况下,我们需要采取一些措施来解决这个问题。本文…...
)
保姆级教程:在ROS2 Humble/Foxy的Gazebo中配置RGB-D相机(附解决点云颜色/坐标问题)
ROS2 Humble/Foxy中Gazebo深度相机仿真全攻略:从配置到点云问题解决在机器人仿真开发中,深度相机(RGB-D)是不可或缺的传感器之一。它能够同时提供彩色图像和深度信息,为SLAM、物体识别、避障等任务提供关键数据支持。本…...
)
蓝牙抓包不求人:从HCI日志里‘挖’出Link Key的两种实用方法(附安卓路径)
蓝牙安全逆向实战:从HCI日志中提取Link Key的深度解析在蓝牙协议安全研究领域,Link Key作为设备配对认证的核心凭证,其获取方式一直是逆向工程师关注的焦点。许多安全审计场景下,我们往往只能获得加密后的HCI通信日志,…...

新手也能懂的SSRF漏洞实战:用iwebsec靶场复现文件读取与内网探测
从零开始掌握SSRF漏洞:iwebsec靶场实战指南1. 认识SSRF漏洞的本质想象一下,你正在一家高档餐厅点餐,服务员承诺可以帮你从任何地方获取食材——包括隔壁竞争对手的厨房。SSRF(Server-Side Request Forgery)漏洞就像这个…...

DIY复刻经典:Texar Audio Prism动态处理器克隆套件全攻略
1. 项目概述:Texar Audio Prism 克隆套件如果你在专业音频圈子里混过一段时间,尤其是对上世纪八九十年代那些经典的、带点“魔法”色彩的外置动态处理器感兴趣,那么“Texar Audio Prism”这个名字你大概率不会陌生。它不是最常见的1176或者LA…...

终极免费方案:WandEnhancer完整解锁WeMod Pro功能快速指南
终极免费方案:WandEnhancer完整解锁WeMod Pro功能快速指南 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer 你是否渴望享受WeMod Pro会员的所…...

PvZ Toolkit终极指南:三步掌握植物大战僵尸最强修改器
PvZ Toolkit终极指南:三步掌握植物大战僵尸最强修改器 【免费下载链接】pvztoolkit 植物大战僵尸 PC 版综合修改器 项目地址: https://gitcode.com/gh_mirrors/pv/pvztoolkit PvZ Toolkit是一款专为植物大战僵尸PC版设计的综合修改器工具,能够让你…...

绝了!原来毕业论文还能这样写?2026降AIGC工具推荐合集
还在为查重率爆红、AI痕迹太明显、格式乱成一团而发愁?2026 年的 AI 论文工具早已不只是写文章那么简单,从选题构思到降AIGC率、去AI痕迹、查重优化,全流程智能辅助,帮你把论文写作变得简单高效,告别熬夜改稿的焦虑&am…...

无声输入革命:如何用Chaplin在5分钟内构建本地唇语识别系统
无声输入革命:如何用Chaplin在5分钟内构建本地唇语识别系统 【免费下载链接】chaplin A real-time silent speech recognition tool. 项目地址: https://gitcode.com/gh_mirrors/chapl/chaplin 在嘈杂的办公室、安静的图书馆,或是需要绝对隐私的医…...

抖音批量下载工具:免费获取无水印视频的终极解决方案
抖音批量下载工具:免费获取无水印视频的终极解决方案 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback suppor…...

安卓逆向实战:Frida内存砸壳提取DEX原理与技巧
1. 这不是“脱壳”,是逆向工程中一次精准的内存手术你打开一个加固过的安卓App,用常规工具解包,发现classes.dex只有几KB,里面全是混淆到面目全非的壳代码;用dex2jar反编译,报错“Not a valid dex file”&a…...