python字典翻转教学
目录
第1关 创建大学英语四级单词字典
第2关 合并大学英语四六级词汇字典
第3关 查单词输出中文释义
第4关 删除字典中特定字母开头的单词
第5关 单词英汉记忆训练
第1关 创建大学英语四级单词字典
本关任务:编写一个能创建大学英语四级单词字典的小程序。
测试输入:
10预期输出:
[('African', 'a.非洲的 n.非洲人'), ('Arabian', 'a.阿拉伯的'), ('Atlantic', 'a.大西洋的 n.大西洋'), ('August', 'n.八月'), ('Australia', 'n.澳大利亚'), ('Australian', 'a.澳大利亚的'), ('B.C.', '(缩)公元前'), ('Bible', 'n.基督教《圣经》'), ('Britain', 'n.不列颠,英国'), ('British', 'a.不列颠的,英联邦的')]
def create_dict(file):"""接收表示文件名的字符串参数,读文件中的单词及释义,以单词为键,其他部分为值创建字典。多个释义间可能是逗号或空格分隔,但单词与第一个释义间至少有一个空格,将文件每一行根据空格切分一次,切分结果分别作为键和值创新字典。返回字典。"""# 在下面一行补充代码,创建一个空字典dic = {} # 创建空字典with open(file, 'r', encoding='utf-8') as data: # 打开文件,以读模式创建文件对象for x in data: # 遍历文件对象word, trans = x.strip().split(maxsplit=1) # 每行根据空格切分为列表,只切分一次,将单词与释义分开# 补充程序,列表的首个元素作为字典的键,第二个元素做字典的值,加入字典中,返回这个字典dic.update({word:trans}) return dicif __name__ == '__main__':filename = '/data/bigfiles/cet4.txt'n = int(input()) # 输入一个正整数cet_dict = create_dict(filename) # 调用函数,返回字典类型数据# 在下面补充语句,根据字典的键对字典进行排序,得到排序的列表,输出列表前n项print([x for x in sorted(cet_dict.items())][:n])第2关 合并大学英语四六级词汇字典
本关任务:编写一个能将大学英语四级、六级词汇合并为一个字典的小程序。
小明同学在准备参加大学英语四六级考试,为了督促自己背单词,他决定自己写一个背单词的程序。 cet4.txt cet6.txt
编程要求
根据提示,在右侧编辑器补充代码,读取数据集中的四级单和六级词文件,以单词为键,以中文解释为值,将两个文件中的数据创建为一个字典。输入一个正整数n,输出所创建字典排序后的前n项。
def create_dict(file):"""接收表示文件名的字符串参数,读文件中的单词及释义,以单词为键,其他部分为值创建字典。多个释义间可能是逗号或空格分隔,但单词与第一个释义间至少有一个空格,将文件每一行根据空格切分一次,切分结果分别作为键和值创新字典。返回字典。"""# 补充你的代码dic = {} # 创建空字典with open(file, 'r', encoding='utf-8') as data: # 打开文件,以读模式创建文件对象for x in data: # 遍历文件对象word, trans = x.strip().split(maxsplit=1) # 每行根据空格切分为列表,只切分一次,将单词与释义分开dic.update({word:trans}) return dicdef merge_dic(file1, file2):"""将读取两个文件中获得的字典合并为一个,返回合并后的字典"""# 补充你的代码dict1 = create_dict(file1)dict2 = create_dict(file2)dict3 = dict1 | dict2return dict3def sort_dic(cet_dic, n):"""根据字典的键对字典进行排序,得到排序的列表,返回列表前n项"""# 补充你的代码return [x for x in sorted(cet_dict.items())][:n]if __name__ == '__main__':filename1 = '/data/bigfiles/cet4.txt' # 数据文件名filename2 = '/data/bigfiles/cet6.txt' # 数据文件名num = int(input()) # 输入一个正整数cet_dict = merge_dic(filename1, filename2) # 调用函数,返回字典类型数据print(sort_dic(cet_dict, num)) # 输出排序后列表前n项第3关 查单词输出中文释义
本关任务:编写一个能查询单词中文释义的小程序。
小明同学在准备参加大学英语四六级考试,为了督促自己背单词,他决定自己写一个背单词的程序。根据提示,在右侧编辑器补充代码,读取数据集中的四级单和六级词文件,以单词为键,以中文解释为值,将两个文件中的数据创建为一个字典。输入一个单词,查询并输出对应的释义,单词在字典中不存在时,输出'单词不存在'。
def create_dict(file):"""接收表示文件名的字符串参数,读文件中的单词及释义,以单词为键,其他部分为值创建字典。多个释义间可能是逗号或空格分隔,但单词与第一个释义间至少有一个空格,将文件每一行根据空格切分一次,切分结果分别作为键和值创新字典。返回字典。"""# 补充你的代码dic = {} # 创建空字典with open(file, 'r', encoding='utf-8') as data: # 打开文件,以读模式创建文件对象for x in data: # 遍历文件对象word, trans = x.strip().split(maxsplit=1) # 每行根据空格切分为列表,只切分一次,将单词与释义分开dic.update({word:trans}) return dicdef merge_dic(file1, file2):"""将读取两个文件中获得的字典合并为一个,返回合并后的字典"""# 补充你的代码dict1 = create_dict(file1)dict2 = create_dict(file2)dict3 = dict1 | dict2return dict3def translate(cet_dic, word):"""接收两个参数,第一个是读文件创建的字典,第二个参数为要查询的单词,字符串根据文件创建的字典,从中查询单词word,如果查询单词存在,元组形式返回词与词的释义;如果查询不存在,返回'单词不存在'"""# 补充你的代码if word in cet_dic:return word,cet_dic[word]else:return word,'单词不存在'if __name__ == '__main__':filename1 = '/data/bigfiles/cet4.txt' # 数据文件名filename2 = '/data/bigfiles/cet6.txt' # 数据文件名word = input() # 输入一个单词cet_dict = merge_dic(filename1, filename2) # 调用函数,返回字典类型数据result = translate(cet_dict, word)print('{}: {}'.format(*result))第4关 删除字典中特定字母开头的单词
本关任务:编写一个能删除字典中特定字母开头的单词的小程序。
小明同学在准备参加大学英语四六级考试,为了督促自己背单词,他决定自己写一个背单词的程序。根据提示,在右侧编辑器补充代码,读取数据集中的四级单和六级词文件,以单词为键,以中文解释为值,将两个文件中的数据创建为一个字典。删除字典中特定字母开头的单词(首字母不区分大小写),输出删除后字典长度。
def create_dict(file):"""接收表示文件名的字符串参数,读文件中的单词及释义,以单词为键,其他部分为值创建字典。多个释义间可能是逗号或空格分隔,但单词与第一个释义间至少有一个空格,将文件每一行根据空格切分一次,切分结果分别作为键和值创新字典。返回字典。"""# 补充你的代码dic = {} # 创建空字典with open(file, 'r', encoding='utf-8') as data: # 打开文件,以读模式创建文件对象for x in data: # 遍历文件对象word, trans = x.strip().split(maxsplit=1) # 每行根据空格切分为列表,只切分一次,将单词与释义分开dic.update({word:trans}) return dicdef merge_dic(file1, file2):"""将读取两个文件中获得的字典合并为一个,返回合并后的字典"""# 补充你的代码dict1 = create_dict(file1)dict2 = create_dict(file2)dict3 = dict1 | dict2return dict3def del_words(cet_dic, letter):"""删除字典中首字母与参数letter相同的单词,返回删除后的字典"""# 补充你的代码list1 = [x for x in cet_dic]for i in range(len(list1)):if list1[i][0].lower() == letter:cet_dic.pop(list1[i])return cet_dicif __name__ == '__main__':filename1 = '/data/bigfiles/cet4.txt' # 数据文件名filename2 = '/data/bigfiles/cet6.txt' # 数据文件名alphabet = input().lower() # 输入一个字母cet_dict = merge_dic(filename1, filename2) # 调用函数,返回字典类型数据result = del_words(cet_dict, alphabet) # 删除特定单词后的字典print(len(result)) # 输出字典长度第5关 单词英汉记忆训练
编程要求
根据提示,在右侧编辑器补充代码,读取数据集中的四级单和六级词文件,以单词为键,以中文解释为值,将两个文件中的数据创建为一个字典。用户输入一个字母,用这个字母的ASCII值为随机数种子,随机抽取这个字母开头的单词(首字母不区分大小写)进行记忆训练,用户填写词义,用户输入的词义在释义中存在时认为回答正确,此时输出当前词全部释义;输入错误时,记录该单词信息到错词字典;用户直接输入回车时结束训练,并输出正确率并输出全部出错单词的信息。
import randomdef create_dict(file):"""接收表示文件名的字符串参数,读文件中的单词及释义,以单词为键,其他部分为值创建字典。多个释义间可能是逗号或空格分隔,但单词与第一个释义间至少有一个空格,将文件每一行根据空格切分一次,切分结果分别作为键和值创新字典。返回字典。"""# 补充你的代码dic = {} # 创建空字典with open(file, 'r', encoding='utf-8') as data: # 打开文件,以读模式创建文件对象for x in data: # 遍历文件对象word, trans = x.strip().split(maxsplit=1) # 每行根据空格切分为列表,只切分一次,将单词与释义分开# 补充程序,列表的首个元素作为字典的键,第二个元素做字典的值,加入字典中,返回这个字典dic.update({word:trans}) return dicdef merge_dic(file1, file2):"""将读取两个文件中获得的字典合并为一个,返回合并后的字典"""# 补充你的代码dict1 = create_dict(file1)dict2 = create_dict(file2)dict3 = dict1 | dict2return dict3def training(cet_dic, letter):"""输入一个字母,返回以这个字母开头的词汇的字典(不区分大小写),用于单词记忆训练"""# 补充你的代码list1 = [x for x in cet_dic]for i in range(len(list1)):if list1[i][0].lower() != letter:cet_dic.pop(list1[i])return cet_dicdef en_to_ch(train_dic):"""从训练字典中随机抽取以某个字母开头的单词,用户填写词义回答正确时,输出当前词全部释义,输入错误时,记录该单词信息,直接输入回车时结束输入,训练结束后输出全部出错单词的信息"""# 创建空字典,用于容纳答错单词dic1 = {}while True: # 无限循环用于一次训练记忆多个单词word = random.choice(list(train_dic.keys())) # 从字典的键中随机抽取一个单词print(f'请输入单词{word}的中文翻译:') # 输出提示语句answer = input() # 输入当前单词的语义if not answer: # 直接回车时输入为空,结束循环print('训练结束!')break# 补充你的程序,如果输入在释义中存在,输出完整释义,否则输出'答案错误'并将当前单词加入答错单词字典elif answer in train_dic[word]:print(f'{word}的释义为:{train_dic[word]}')elif answer not in train_dic[word]:print('答案错误')dic1[word] = train_dic[word]print('需要加强记忆的单词:')# 补充代码,逐个输出答错字典中的单词和释义for i in dic1:print(f'{i}:{dic1[i]}')if __name__ == '__main__':filename1 = '/data/bigfiles/cet4.txt' # 数据文件名filename2 = '/data/bigfiles/cet6.txt' # 数据文件名alphabet = input('输入今天训练单词首字母:\n').lower()random.seed(ord(alphabet)) # 用当前字典的ASCII值做随机数种子,方便评测cet_dict = merge_dic(filename1, filename2) # 调用函数,返回字典类型数据train_dict = training(cet_dict, alphabet) # 本次训练单词的字典en_to_ch(train_dict) # 调用函数进行训练相关文章:

python字典翻转教学
目录 第1关 创建大学英语四级单词字典 第2关 合并大学英语四六级词汇字典 第3关 查单词输出中文释义 第4关 删除字典中特定字母开头的单词 第5关 单词英汉记忆训练 第1关 创建大学英语四级单词字典 本关任务:编写一个能创建大学英语四级单词字典的小程序。 测…...
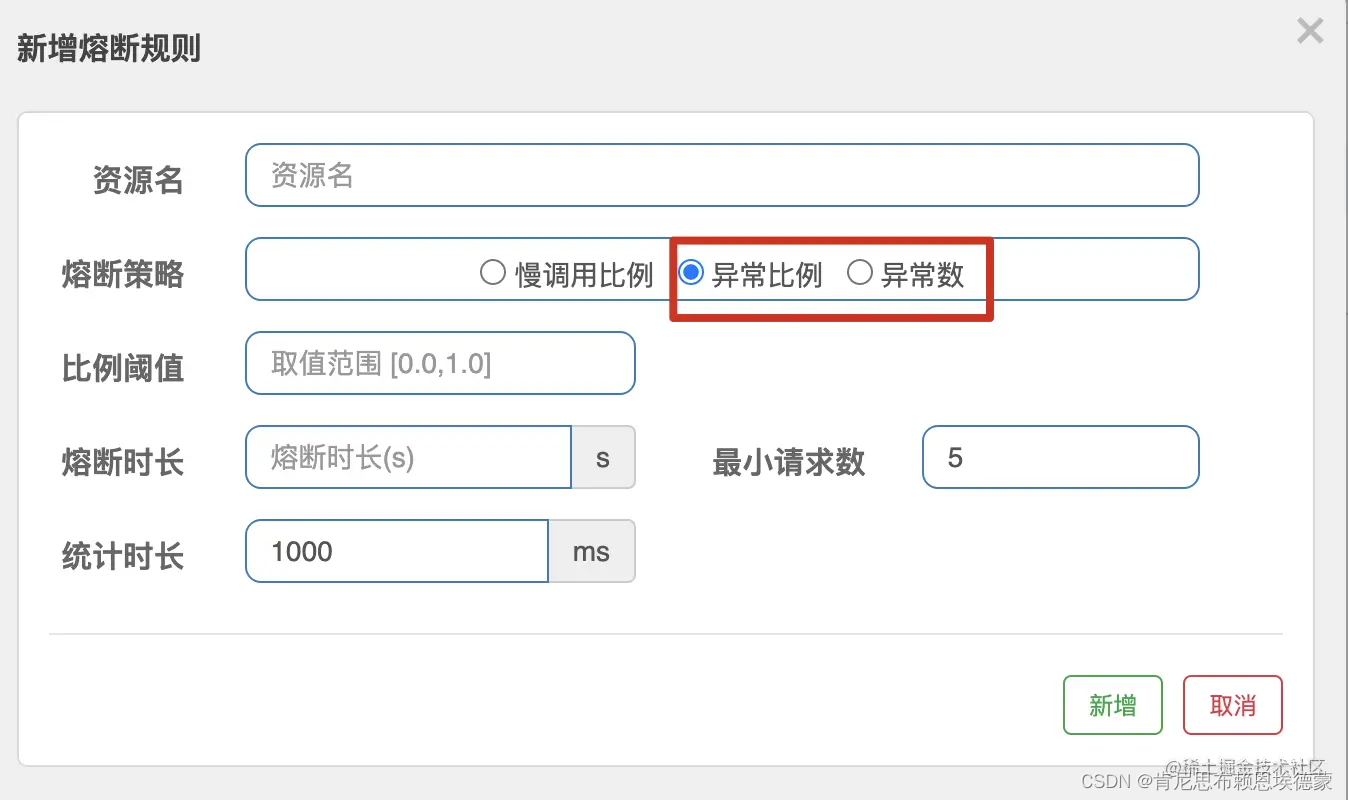
sentinel 随笔 3-降级处理
0. 像喝点东西,但不知道喝什么 先来段源码,看一下 我们在dashboard 录入的降级规则,都映射到哪些字段上 package com.alibaba.csp.sentinel.slots.block.degrade;public class DegradeRule extends AbstractRule {public DegradeRule(String…...

如何解决IP能ping通但无法上网的问题?
当我们在网络环境中遇到无法上网的问题时,可能会尝试使用ping命令来测试网络连接是否正常。如果ping测试成功,说明我们的IP地址能够和网络中其他设备进行通信,但是无法上网。这种情况下,我们需要采取一些措施来解决这个问题。本文…...

Autosar实践-CANTp
文章目录 前言一、CanTp是什么?二、Autosar配置三、诊断数据传输流程1.接收单帧失败,上层没有适当的buffer2.成功接收单帧3.成功发送单帧4.成功接收多帧5.成功发送多帧前言 CANTp模块作为提供数据拆包、组包、流控制传输的服务,在Autosar基础软件通信中起着至关重要的作用。…...

Redis简介
Redis(Remote Dictionary Server)是一个开源的键值对(key-value)数据库,支持网络、可基于内存亦可持久化。 Redis的数据结构包括列表(List)、集合(Set)、有序集合&#…...

报错问题修改
Vue 项目报错:‘$‘ is not defined ( no-undef ) 错误原因是不认识 $ 符,他是 JQuery 中得符号,引入了 JQuery 文件里的函数报错onclick is not defined问题(作用域问题) window.onload function (){ onload function (){ 第二种方法…...

专访惠众科技|元宇宙应用如何借助3DCAT实时云渲染实现流畅大并发呈现?
当前互联网流量红利已经逐渐消失,营销同质化愈发严重。在这样的背景下,催生了以为元宇宙 焦点的虚拟产业经济。元宇宙在各行各业中以不同形式快速萌生、成长,呈现出多元化的应用场景。尤其是众多品牌,将元宇宙视为品牌建设与营销新…...

加速开放计算产业化,OCTC五大原则瞄准需求痛点
回顾计算产业过去十余载的历程,开放计算始终是一个绕不开的核心焦点。 始于2011年Facebook发起的数据中心硬件开源项目--开放计算项目(简称:OCP),开放计算犹如星星之火,不仅迅速形成燎原之势,更…...

【RabbitMQ】安装及六种模式
文章目录 安装rabbitmq镜像访问容器内部15672端口映射到外面的端口地址RabbitMQ六种模式Hello world模式Work queues模式Publish/Subscribe模式交换机fanout类型 Routing模式Topics模式RPC模式 rabbitmq:0->1的学习 学习文档:https://www.cnblogs.com…...

数据结构刷题(三十一):1049. 最后一块石头的重量 II、完全背包理论、518零钱兑换II
一、1049. 最后一块石头的重量 II 1.思路:01背包问题,其中dp[j]表示容量为j的背包,最多可以背最大重量为dp[j]。 2.注意:递推公式dp[j] max(dp[j], dp[j - stones[i]] stones[i]);本题中的重量就是价值,所以第二个…...

opencv_c++学习(四)
图像在opencv中的存储方式 在上图中可以看出,在opencv中采用的是像素值来代表每一个像素三通道颜色的深浅。 Mat对象 Mat对象是在OpenCV2.0之后引进的图像数据结构、自动分配内存、不存在内存泄漏的问题,是面向对象的数据结构。分了两个部分࿰…...

基于AT89C51单片机的篮球计时记分设计
点击链接获取Keil源码与Project Backups仿真图: https://download.csdn.net/download/qq_64505944/87771065 源码获取 主要内容: 基于51单片机设计篮球计时计分器,结合单片机串行接口原理,用AT89C51设计一个篮球比赛计分计时器,能够通过数码管显示分数和比赛时间(并设有…...

并发编程-Day2
并发编程 1.共享模型-内存 共享变量在多线程间的<可见性>问题与多条指令执行时的<有序性>问题 1.1Java内存模型 JMM它定义了主存、工作内存抽象概念,底层对应着CPU寄存器、缓存、硬件内存CPU指令优化等. JMM体现在: 原子性-保证指令不会受到线程上…...

第1章 Nginx简介
基于 Nginx版本 1.14.2 ,Tomcat版本 9.0.0 演示 第1章 Nginx简介 1.1 Nginx发展介绍 Nginx (engine x) 是一个高性能的Web服务器和反向代理服务器,也可以作为邮件代理服务器。 Nginx 特点是占有内存少,并发处理能力…...
一个.Net功能强大、易于使用、跨平台开源可视化图表
可视化图表运用是非常广泛的,比如BI系统、报表统计等。但是针对桌面应用的应用,很多报表都是收费的,今天给大家推荐一个免费.Net可视化开源的项目! 项目简介 基于C#开发的功能强大、易于使用、跨平台高质量的可视化图表库&#…...

浅谈 ext2 文件系统的特点、优缺点以及使用场景
ext2(Extended File System 2)是 Linux 中最早的一种文件系统,它是 Linux 文件系统的基础,也被广泛用于其他类 Unix 系统中。下面是 ext2 文件系统的特点、优缺点以及使用场景: 特点: ext2 文件系统可以支…...

Map和Set数据结构和ES6模块化语法
Map和Set数据结构 ●ES6 新增的两种数据结构 ●共同的特点: 不接受重复数据 Set数据结构 ●是一个 类似于 数组的数据结构 ●按照索引排列的数据结构 创建 Set 数据结构 语法: var s new Set([ 数据1, 数据2, 数据3, ... ]) Set 数据结构的属性和方法 ●size 属性 ○语法: 数…...

10_Uboot启动流程_2
目录 _main函数详解 board_init_f函数详解 relocate_code函数详解 relocate_vectors函数详解 board_init_r 函数详解 _main函数详解 在上一章得知会执行_main函数_main函数定义在文件arch/arm/lib/crt0.S 中,函数内容如下: 第76行,设置sp指针为CONFIG_SYS_INIT_SP_ADDR,也…...
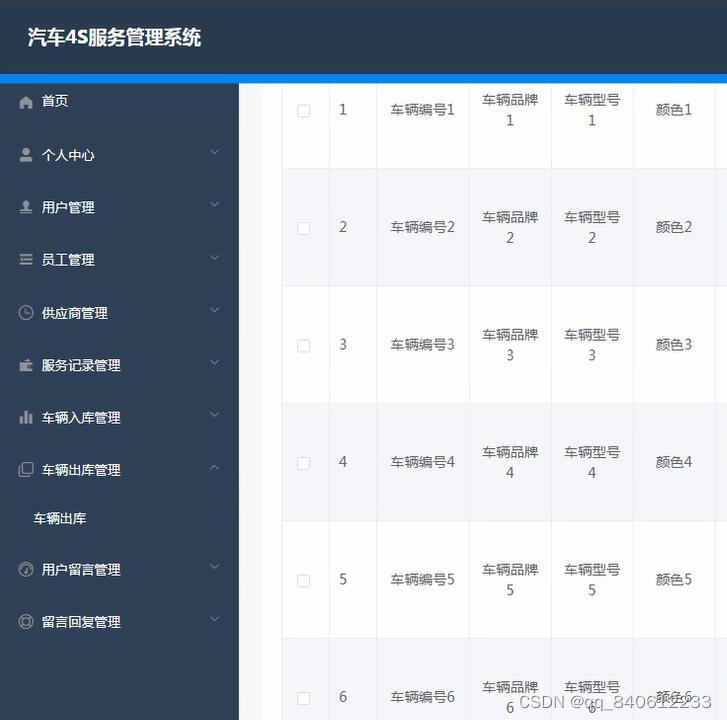
python+django汽车4S店零配件保养服务管理系统
汽车4S服务管理系统包括三种用户。管理员、普通员工、客户。 开发语言:Python 框架:django/flask Python版本:python3.7.7 数据库:mysql 数据库工具:Navicat 开发软件:PyCharm django 应用目录结构管…...

STM32F4的输出比较极性和PWM1,PWM2的关系
PWM 输出比较通道 在这里以通用定时器的通道1作为介绍。 如图,左边就是CNT计数器和CCR1第一路的捕获/比较寄存器,它俩进行比较,当CNT>CCR1, 或者CNTCCR1时,就会给输出模式控制器传送一个信号,然后输出模式控制器就…...

Unity-MCP协议:可嵌入、可协商的AI上下文通信标准
1. 这不是又一个“AI插件”,而是Unity开发工作流的底层重定义你有没有过这样的时刻:在Unity里反复调整Animator Controller的过渡条件,只为让角色转身动画不穿模;写完一段NavMesh寻路逻辑,却要花两小时调试Agent卡在斜…...

App Inventor蓝牙调试避坑指南:从连接失败到数据乱码,一次讲清所有常见问题
App Inventor蓝牙调试避坑指南:从连接失败到数据乱码的实战解决方案在移动应用开发领域,蓝牙通信一直是实现设备间短距离数据交换的核心技术之一。对于使用App Inventor的开发者而言,蓝牙模块提供了无需复杂编码即可实现无线通信的便捷途径。…...

为什么视频代剪辑会影响你的内容传播效果
为什么你精心拍的视频,发出去却没人看? 你有没有过这样的经历:花了一整天拍Vlog,素材画质高清、内容真实,可一剪出来就显得平淡无奇,点赞寥寥?或者婚礼当天感动全场,回看成片却像流水…...

WPF虚拟桌宠组件:可嵌入、高性能、工程化UI生命体
1. 这不是“桌面宠物”,而是一个可嵌入的WPF UI组件化生命体你可能在Windows XP时代见过那只晃着尾巴、偶尔打哈欠的3D小猫,也可能在Win10系统托盘里点开过一个会眨眼的像素狐狸——但那些是独立进程、是系统级小工具、是“看一眼就关掉”的轻量娱乐。而…...

解决方法:庐山派K230接串口没识别到端口问题
一、插入usb转串口工具之前二、插入usb转串口工具之后三、解决方法说明:🔍 核心原因:USB Serial 设备,没有被识别为 COM 口你现在看到的 USB Serial,说明开发板已经正常启动了,USB 也被电脑识别到了&#x…...
【php语法学习,iscc校赛wp】)
学习日志(三)【php语法学习,iscc校赛wp】
1. 任务 1.1.1.1.1.1. 知识部分 rce看【之前的笔记?】php的知识点学习继续jwt token好像是比赛的题目考察内容,我看看php伪协议 1.1.1.1.1.2. 题目 参加iscc比赛【五一】rce题目 1.1.1.1.1.3. 环境配置 把vscode搞好,上学期没有把Php配…...

构建智能音乐档案:SoundCloud Downloader 的技术架构与实现哲学
构建智能音乐档案:SoundCloud Downloader 的技术架构与实现哲学 【免费下载链接】scdl Soundcloud Music Downloader 项目地址: https://gitcode.com/gh_mirrors/sc/scdl 在流媒体音乐主导的时代,音乐爱好者面临着一种矛盾:我们享受着…...

如何用Untrunc拯救损坏视频?2025年终极MP4修复工具完全指南
如何用Untrunc拯救损坏视频?2025年终极MP4修复工具完全指南 【免费下载链接】untrunc Restore a damaged (truncated) mp4, m4v, mov, 3gp video. Provided you have a similar not broken video. 项目地址: https://gitcode.com/gh_mirrors/unt/untrunc 当你…...

基于BLE模块的低功耗无线遥控器设计与实现
1. 项目概述:基于BLE模块的无线遥控器设计与实现几年前,我在捣鼓智能家居时,一直想找一个低功耗、响应快、又能自己完全掌控的无线遥控方案。市面上的成品要么协议封闭,要么功耗感人,要么延迟高得让人着急。后来&#…...

如何高效使用HiveWE:魔兽争霸III地图制作的完整秘籍
如何高效使用HiveWE:魔兽争霸III地图制作的完整秘籍 【免费下载链接】HiveWE A Warcraft III world editor. 项目地址: https://gitcode.com/gh_mirrors/hi/HiveWE 还在为魔兽争霸III原版编辑器加载缓慢、操作卡顿而烦恼吗?HiveWE作为一款专注于速…...