知识推理——CNN模型总结(一)
记录一下我看过的利用CNN实现知识推理的论文。
最后修改时间:2023.05.12
目录
1.ConvE
1.1.解决的问题
1.2.优势
1.3.贡献与创新点
1.4.方法
1.4.1 为什么用二维卷积,而不是一维卷积?
1.4.2.ConvE具体实现
1.4.3.1-N scoring
1.5.实验
1.5.1.数据集
1.5.2.实验设置
1.5.3.Inverse Model
1.6.实验结果
1.6.1.去不去除inverse relations
1.6.2.模型效率
1.6.3.消融实验
1.6.4.Indegree和PageRank分析
1.7.总结与感想
2.ConvKB
2.1.解决的问题
2.2.优势
2.3.贡献与创新点
2.4.方法
2.4.1方法介绍
2.4.2.ConvKB与TransE的转换推导
2.5.实验
2.5.1.数据集
2.5.2.实验细节
2.6.实验结果
2.7.总结与感想
1.ConvE
论文:Convolutional 2D Knowledge Graph Embeddings
会议/期刊:2018 AAAI
1.1.解决的问题
(1)以往的模型都太浅了,虽然可以快速用于大型数据集,但是学到的特征表达能力比较差;
(2)另一个比较严重的问题是数据集的泄露问题“test set leakage”,也就是训练集出现过的关系三元组,取了反后,在测试集中又出现了一遍。比如,(A,妈妈,B)在训练集中出现过,(B,女儿,A)又在测试集中出现。这个问题导致一些很简单的rule-based模型也可以达到很好的效果。
1.2.优势
(1)采用多层神经网络,特征表达能力强;
(2)参数量很少,相同的实验效果,参数量比DistMult少8倍,比R-GCN少17倍;
(3)可以高效建模大型数据集常出现的入度高的节点。
1.3.贡献与创新点
(1)设计2D卷积模型,进行链接预测;
(2)设计1-N scoring步骤,提升训练和评估的速度;
(3)参数量少;
(4)随着知识图谱复杂性的提升,ConvE与一些shallow算法的差距成比例增大;
(5)分析了各数据集泄露的问题,并提出了不泄露的版本;
(6)sota。
1.4.方法
1.4.1 为什么用二维卷积,而不是一维卷积?
NLP任务中大多采用的是一维卷积,包括下面要提到的ConvKB算法,但是ConvE却创新的使用了二维卷积。因为二维卷积使得嵌入向量间的交互点变多了,模型的表达能力变强。举个栗子~
一维卷积:
两个一维嵌入分别为和
,两个嵌入concat后得到向量
。
一维卷积核大小为3,那么卷积的过程中,两个向量只有连接点处的值(比如或
)发生了交互,并且交互程度会随着卷积核大小的增加而变深。
二维卷积:
两个二维嵌入分别为和
,两个嵌入concat后得到嵌入
。
二维卷积核大小为3×3,卷积的过程中,卷积核可以建模concat边界线处的交互,特征交互更多。
换一个模式(将嵌入的几行调换一下位置),得到,那么可以发现交互的点更多了。
1.4.2.ConvE具体实现
链接预测算法一般由编码模块和打分模块构成,编码模块负责得到实体和关系的嵌入向量,打分模块负责为三元组打分。
ConvE由卷积层和全连接层构成。
下面是ConvE的算法流程图:
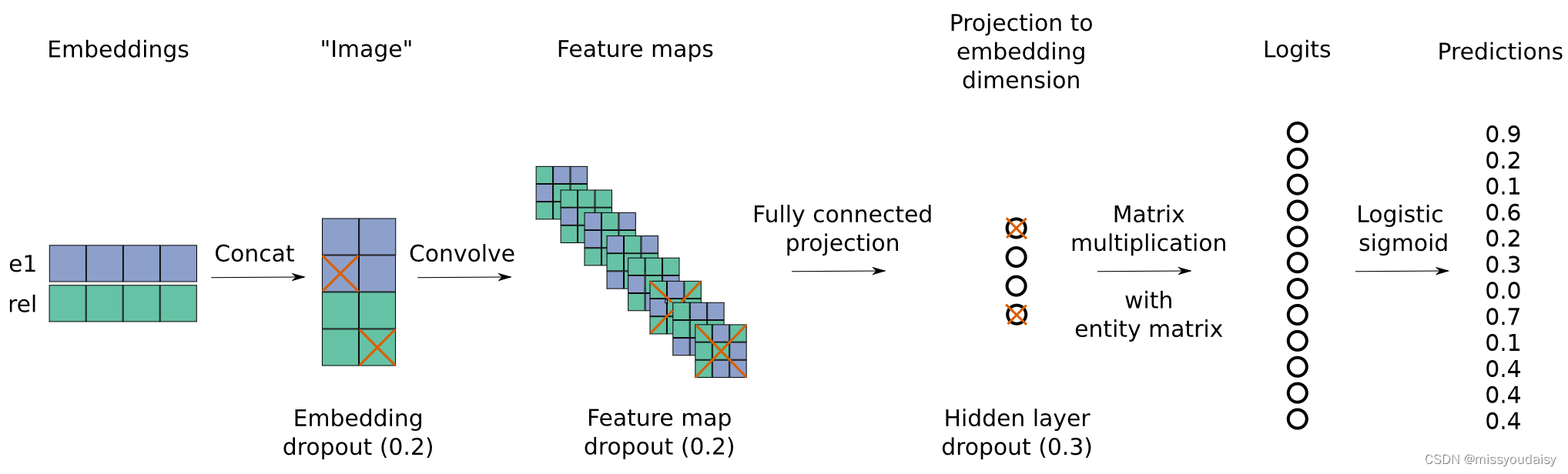
步骤:(可结合上图食用~)
(1)在所有的实体和关系的嵌入矩阵中,查找当前计算的实体和关系的嵌入向量和
;
(2)对嵌入向量做2D的reshape,得到嵌入矩阵和
,维度从
变为
;
(3)concat嵌入矩阵和
,并将结果作为卷积的输入,输出
个
的特征图;
(4)将特征图reshape成的向量,并利用全连接层将向量映射为
维;
(5)然后将该向量与实体嵌入向量做内积,进行匹配,得到分数。这里涉及到1-N scoring,后面会讲到。
(6)为了训练,对分数进行logistic sigmoid函数计算,得到最终分数。
打分函数:
![]()
是ReLU激活函数。
损失函数:
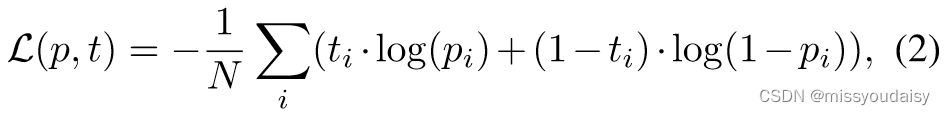
如果三元组存在,为1,否则,为0。最小化损失函数。
Dropout:
作者还使用了很多种dropout手段,包括对嵌入矩阵、卷积后的特征图和全连接层后的输出进行不同概率的dropout。(可以看一下上面的流程图)
1.4.3.1-N scoring
1-N scoring主要是为了算法加速,评估速度可以提升300倍。
1-1 scoring:对三元组(s,r,o)打分
1-N scoring:给定(s,r),然后尾实体取全部实体,同时进行打分。
并且作者说1-N scoring达到了batch normalization的效果。如果将N变为0.1N,那么计算速度变快,收敛速度变慢,这与降低batch的大小是一样的效果。
1.5.实验
1.5.1.数据集
WN18(WN18RR:去除WN18中的inverse三元组)、FB15k(FB15k-237:去除FB15k中的inverse三元组)、YAGO-3、Countries。
1.5.2.实验设置
参数采用网格搜索的方法获得。
作者还研究了对2D卷积做修改对结果的影响:(1)用全连接层代替2D卷积;(2)用1D卷积代替2D卷积。(3)不同filter大小。
1.5.3.Inverse Model
主要是为了证明inverse relation的危害。作者构建了一个之前讲过的简单的rule-based模型,只学习inverse relations,没有学习知识图谱具体的语义,称作inverse model。
怎么确定是不是inverse relations呢?(inverse model怎么做的呢?)
假定inverse relations量与总数据量的比例正比于训练集量与总数据量的比例。判断(s,r1,o)和(o,r2,s)同时出现的概率是否大于等于,其中
和
分别表示验证集和测试集占总数据量的比例,如果满足,则表明r1和r2互为inverse关系。
在测试inverse model的时候,验证测试样本在测试集外有没有inverse matches:如果找到了k个inverse matches,那么对这k个matches进行排名;如果没有找到match,那么随机为测试三元组生成排名。
(这里之前理解错了,感谢这位博主:论文浅尝 | Convolutional 2D knowledge graph embedding_开放知识图谱的博客-CSDN博客)
1.6.实验结果
采用filtered设置,即评估时只排序没在train、test、validate中出现过的三元组。
1.6.1.去不去除inverse relations


可以看到,如果不去除数据集中的inverse relations(WN18和FB15k),那么简单的inverse model可以得到很好的结果。inverse model在FB15k-237和YAGO3-10上的效果很差,因为没有inverse relations。但是为什么在WN18RR上的效果还行呢?因为生成WN18RR的时候,没有去掉对称关系,如“similar to”,这个被inverse model学到了。(这段应该是这个意思,如有错误,麻烦指出哈~)
1.6.2.模型效率

可以看出,ConvE仅凭0.23M的参数量就打败了DistMult。
1.6.3.消融实验
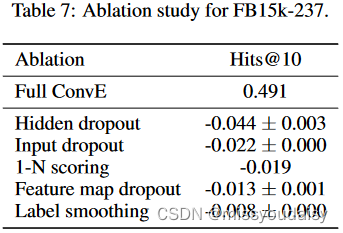
验证各个环节对ConvE模型的影响,其中隐藏层dropout(全连接层输出的dropout)的影响是最大的。
1.6.4.Indegree和PageRank分析
Indegree
ConvE在YAGO3-10、FB15k-237数据集上效果好,因为这些数据集具有相同的特点,就是节点有非常高的relation-specific indegree。比如,节点“美国”对于关系“出生于”的indegree超过10000。而这10000多个节点差异非常大,包括演员、作家、商人等,正是ConvE这种复杂模型才能建模这种差异。
WN18RR和WN18就是indegree低的数据集,对于这种数据集,shallow模型就足以表达了。
实验设定:
在四个数据集上做实验:low-WN18、high-FB15k、high-WN18(去掉indegree低的节点)、low-FB15k(去掉indegree高的节点)。
实验结论:
deeper模型,如ConvE,适合建模复杂的知识图谱(FB15k);shallow模型,如DistMult,适合建模简单一点的知识图谱(WN18)。
PageRank
PageRank度量有向图中节点的重要程度,通过迭代计算节点的indegree得到。一个节点的indegree值正比于该节点的indegree、邻居的indegree、邻居的邻居的indegree,以及所有其他节点的indegree。这里应该能感受到迭代计算的需要了吧。
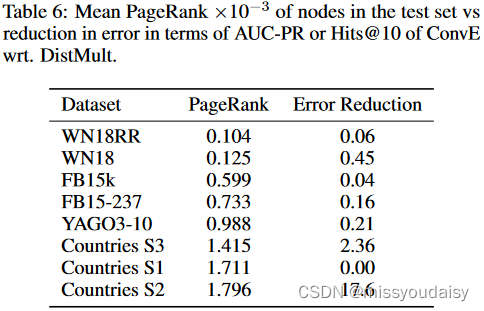
经统计,WN18中PageRank值最高的节点的PageRank比YAGO3-10和Countries中的最高PageRank值小一个数量级,比FB15k中的最高PageRank小4倍。
作者发现,DistMult和ConvE在Hits@10指标上的性能差异正比于测试集的平均PageRank值,可以看一下Table 6。
1.7.总结与感想
ConvE模型是首个用卷积神经网络解决知识推理问题的模型,看完这篇论文觉得受益匪浅。作为一个从视觉转NLP的人,一直也在思考二者结合和技术通用的问题。作者利用了视觉中常用的2D卷积,提升特征的表达能力。还使用了多种dropout方法、1-N scoring等。然后,我觉得作者特别好的一个点就是分析了数据集的问题,并且对问题做了修正。最后,我觉得作者的实验做的也非常的充分,实验环节设计的也非常合理。
2.ConvKB
论文:A Novel Embedding Model for Knowledge Base Completion Based on Convolutional Neural Network
会议/期刊:Proceedings of NAACL-HLT 2018
2.1.解决的问题
没明确说。
2.2.优势
首先,作者先分析了一下ConvE的缺点:ConvE的输入只考虑了实体和关系两个嵌入向量间的局部关系,没有考虑整个三元组(头实体,关系,尾实体)(全局 global),并且忽略了transition-based模型中最重要的transitional特性。
2.3.贡献与创新点
(1)设计了ConvKB模型,用神经网络表示transition-based模型中的transitional特性;
(2)在WN18RR和FB15k-237数据集上验证算法,SOTA。
2.4.方法
2.4.1方法介绍
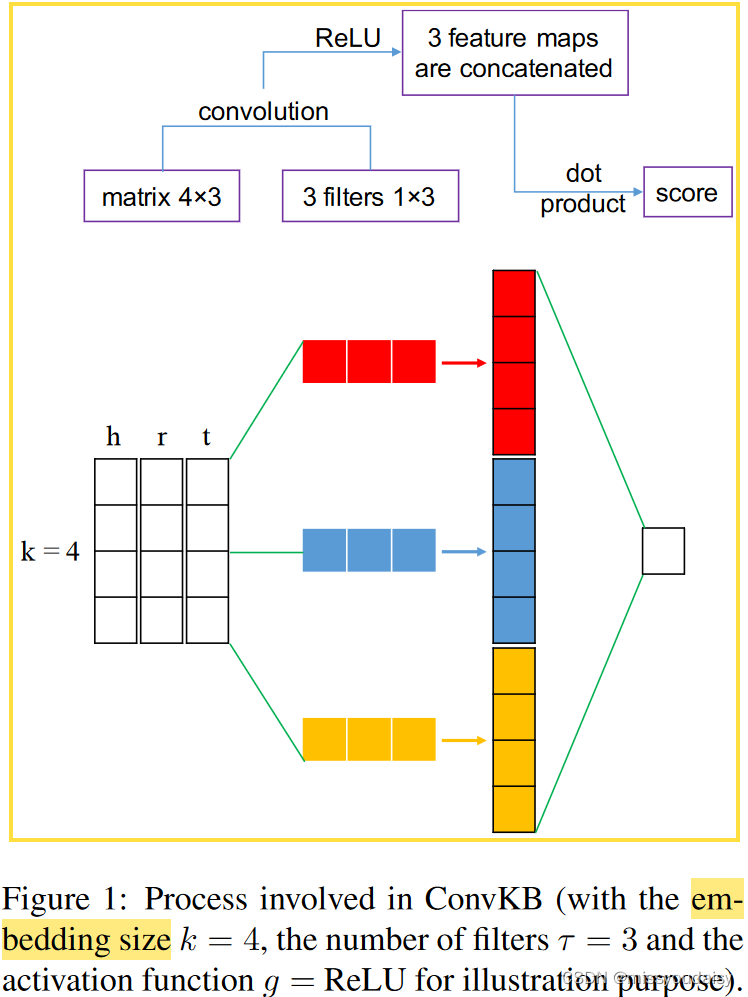
流程:
(1)求实体和关系
的
维嵌入向量,
、
、
;
(2)每个三元组的嵌入可表示为的矩阵,
;
(3)将矩阵输入卷积层,生成特征图:卷积层一共有个
的filters,每一个filter循环处理矩阵的每一维,得到
的特征图。最终得到
个
的特征图;
(4)将所有的特征图concat成单一的特征向量,也就是维;
(5)特征向量与权重向量做点积,得到当前三元组的分数,用来判断三元组是否valid。
第个特征图的计算公式:

ConvKB的打分函数为:
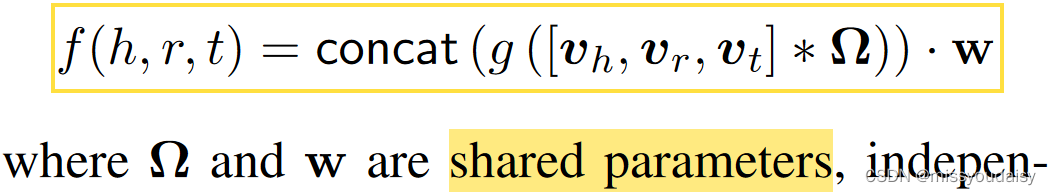
注意:这里的打分函数给出的是每个三元组的implausibility score,也就是三元组越假,分数就越高,三元组越真,分数就越低。这里与ConvE的是反的,ConvE应该是三元组越真,分数越高。
损失函数为:

问题:这里我按照正样本负样本的得分都是正的来推导,推不出minimize loss这个做法,难道负样本的得分其实是负的?取绝对值后大吗?下面贴一个原文对打分函数的解释:

2.4.2.ConvKB与TransE的转换推导
先附上一个各模型的打分函数表:

下面一段文字是ConvKB转换为TransE的参数设置:

推导一下~
所以,ConvKB可以看作是TransE的延申,可以建模全局关系。
2.5.实验
2.5.1.数据集
WN18RR和FB15k-237。
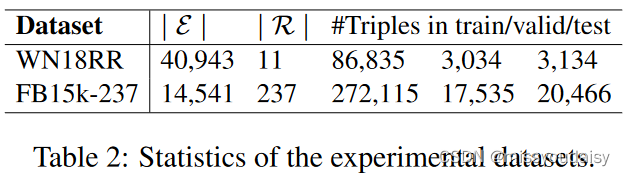
2.5.2.实验细节
按照伯努利分布采样corrupted样本中的头实体或尾实体。
利用TransE来初始化实体和关系的嵌入。
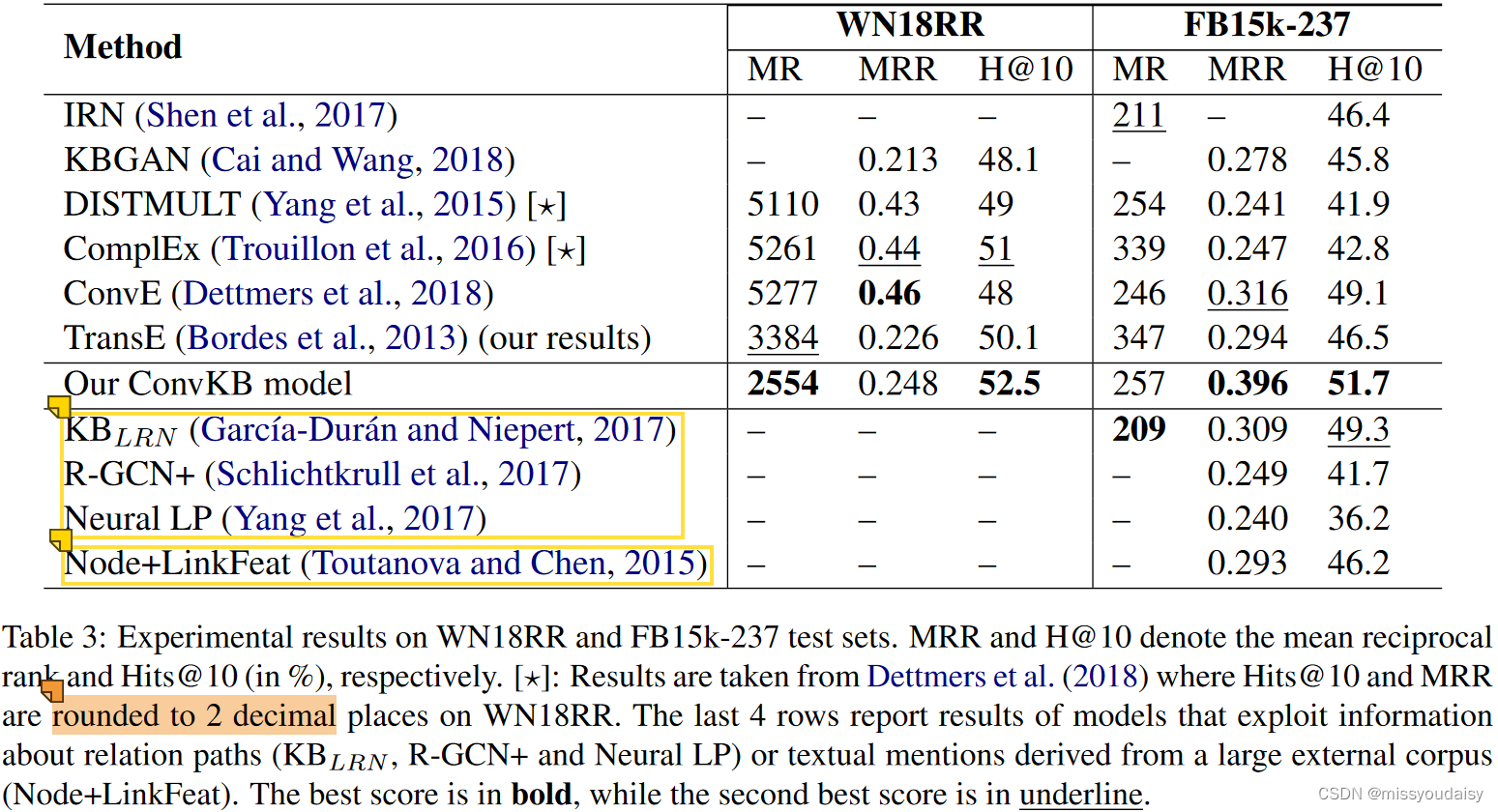
2.6.实验结果
2.7.总结与感想
感觉与ConvE比,这篇的思想还是更常规一点,二者虽然都是从CNN的角度来解决知识表示问题,但是思路还是完全不一样的。
相关文章:
知识推理——CNN模型总结(一)
记录一下我看过的利用CNN实现知识推理的论文。 最后修改时间:2023.05.12 目录 1.ConvE 1.1.解决的问题 1.2.优势 1.3.贡献与创新点 1.4.方法 1.4.1 为什么用二维卷积,而不是一维卷积? 1.4.2.ConvE具体实现 1.4.3.1-N scoring 1.5.…...

OpengES中 GLSL优化要点
本文整理一些日常积累的可以优化的方向 一.延迟vector计算 在进行float与vector计算的时候,可以先确定float再计算,不要多个float一起计算 如: highp float f0,f1;highp vec4 v0,v1;v0 (v1 * f0) * f1;优化为 highp float f0,f1;highp vec…...

项目集角色定义
一、项目集经理的角色 项目集经理是由执行组织授权、领导团队实现项目集目标的人员。项目集经理对项目集的领导、 实施和绩效负责,并负责组建一支能够实现项目集目标和预期项目集效益的项目集团队。项目集经 理的角色与项目经理的角色不同。二者之间的差异是基于项…...

Unreal Engine11:触发器和计时器的使用
写在前面 主要是介绍一下触发器和计时器的使用; 一、在Actor中使用触发器 1. 新建一个C类 创建的C类也是放在Source文件夹中的Public和Private文件夹中;选择Actor作为继承的父类;头文件包括一个触发器和两个静态网格,它们共同…...

Qt之信号槽原理
Qt之信号槽原理 一.概述 所谓信号槽,实际就是观察者模式。当某个事件发生之后,比如,按钮检测到自己被点击了一下,它就会发出一个信号(signal)。这种发出是没有目的的,类似广播。如果有对象对这…...

【MySqL】 表的创建,查看,删除
目录 一.使用Cmd命令执行操作 1.使用( mysql -uroot -p)命令进入数据库 2.创建表之前先要使用数据库 3.创建表之前要先确定表的名称,列名,以及每一列的数据类型及属性 4.创建表 注意: 5.查看所有已创建的表 6.查看单表 …...

Python 字典修改对应的键值
将 key ‘1’ 的值 ‘1’, ‘3’, ‘5’ 字符,修改为 ‘2’, ‘4’, ‘5’ 。 【学习的细节是欢悦的历程】 Python 官网:https://www.python.org/ Free:大咖免费“圣经”教程《 python 完全自学教程》,不仅仅是基础那么简单………...

【JFace】ComboViewer 设置了默认值,但没有效果
问题 在数据回显时,明明在代码中通过comboViewer.setSelection设置了默认值,但没有生效(回显),是怎么回事呢 ? 分析 如果comboViewer.setSelection(new StructuredSelection(items[1]))不起作用…...

基于Redis的Stream结构作为消息队列,实现异步秒杀下单
文章目录 1 认识消息队列2 基于List实现消息队列3 基于PubSub的消息队列4 基于Stream的消息队列5 基于Stream的消息队列-消费者组6 基于Redis的Stream结构作为消息队列,实现异步秒杀下单 1 认识消息队列 什么是消息队列:字面意思就是存放消息的队列。最…...
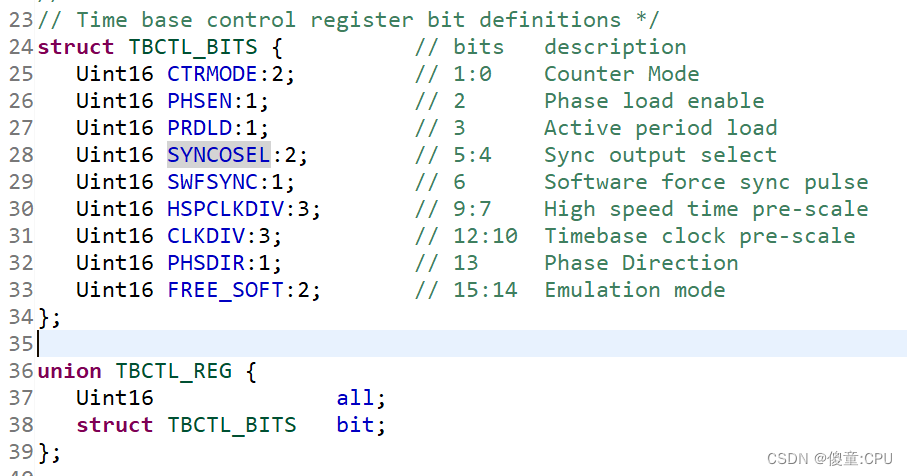
ePWM模块-时基模块(2)
ePWM模块(2) 时基模块的使用 TBPRD:周期寄存器 (设置的时钟周期存入此,可通过阴影寄存器缓冲后写入,也可通过活动寄存器立即写入) TBCTR:时基计数变值寄存器 (时基当前所计数的值存入,用于和所设定周期值比较) TBPHS:时基相位寄存器 TBSTS:时基状态寄存器 …...

让GPT对话写小说
## 来自你的消息: 写个小说 ## 来自ChatAI的消息: 很好,我可以为您编写一个小故事。以下是一个短小精干的故事: 《夜行者》 夜,是个寂静而神秘的时间,很多人都选择睡眠。但在这个城市,有一群人——夜行者,他…...
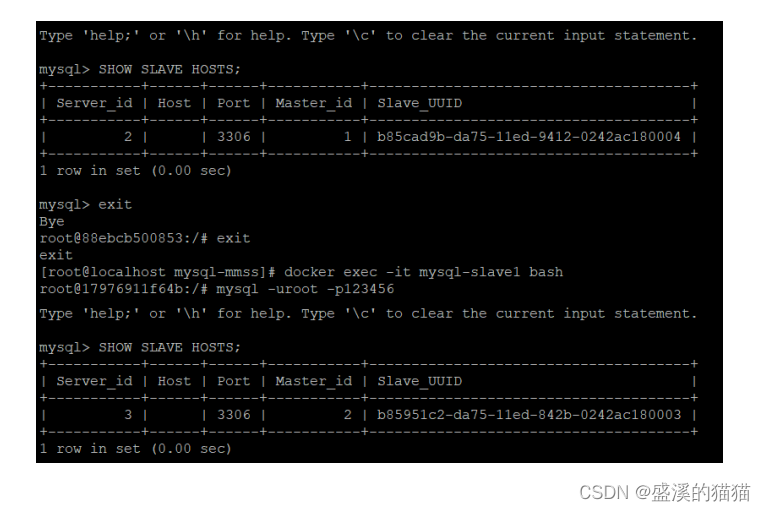
Docker 应用部署-MySQL
一、安装MySQL 1搜索mysql镜像 docker search mysql 2拉取mysql镜像 docker pull mysql:8.0.20 3创建容器 通过下面的命令,创建容器并设置端口映射、目录映射 #在用户名目录下创建mysql目录用于存储mysql数据信息 mkdir /home/mysql cd /home/mysql #创建docker容…...

电容笔哪个厂家的产品比较好?苹果平板的电容笔推荐
从目前来说,这个苹果的正版电容笔,售价真的是太贵了,一支就要接近上千元。事实上,对于那些没有很多预算的人来说,平替电容笔是一个很好的选择。一支苹果电容笔,价格是四支平替电容笔的四倍,但平…...

今年的面试难度有点大....
大家好,最近有不少小伙伴在后台留言,又得准备面试了,不知道从何下手! 不论是跳槽涨薪,还是学习提升!先给自己定一个小目标,然后再朝着目标去努力就完事儿了! 为了帮大家节约时间&a…...

【PWN · ret2libc】ret2libc2
ret2libc1的略微进阶——存在systemplt但是不存在“/bin/sh”怎么办? 目录 前言 python3 ELF 查看文件信息 strings 查看寻找"/bin/sh" IDA反汇编分析 思路及实现 老规矩,偏移量 offset EXP编写 总结 前言 经过ret2libc1的洗礼&a…...
深度学习01-tensorflow开发环境搭建
文章目录 简介运行硬件cuda和cuddntensorflow安装。tensorflow版本安装Anaconda创建python环境安装tensorflow-gpupycharm配置配置conda环境配置juypternotebook 安装cuda安装cudnn安装blas 云服务器运行云服务器选择pycharm配置代码自动同步远程interpreter 简介 TensorFlow是…...

linux相关操作
1 系统调用 通过strace直接看程序运行过程中的系统调用情况 其中每一行为一个systemcall ,调用write系统调用将内容最终输出。 无论什么编程语言都必须通过系统调用向内核发起请求。 sar查看进程分别在用户模式和内核模式下的运行时间占比情况, ALL显…...
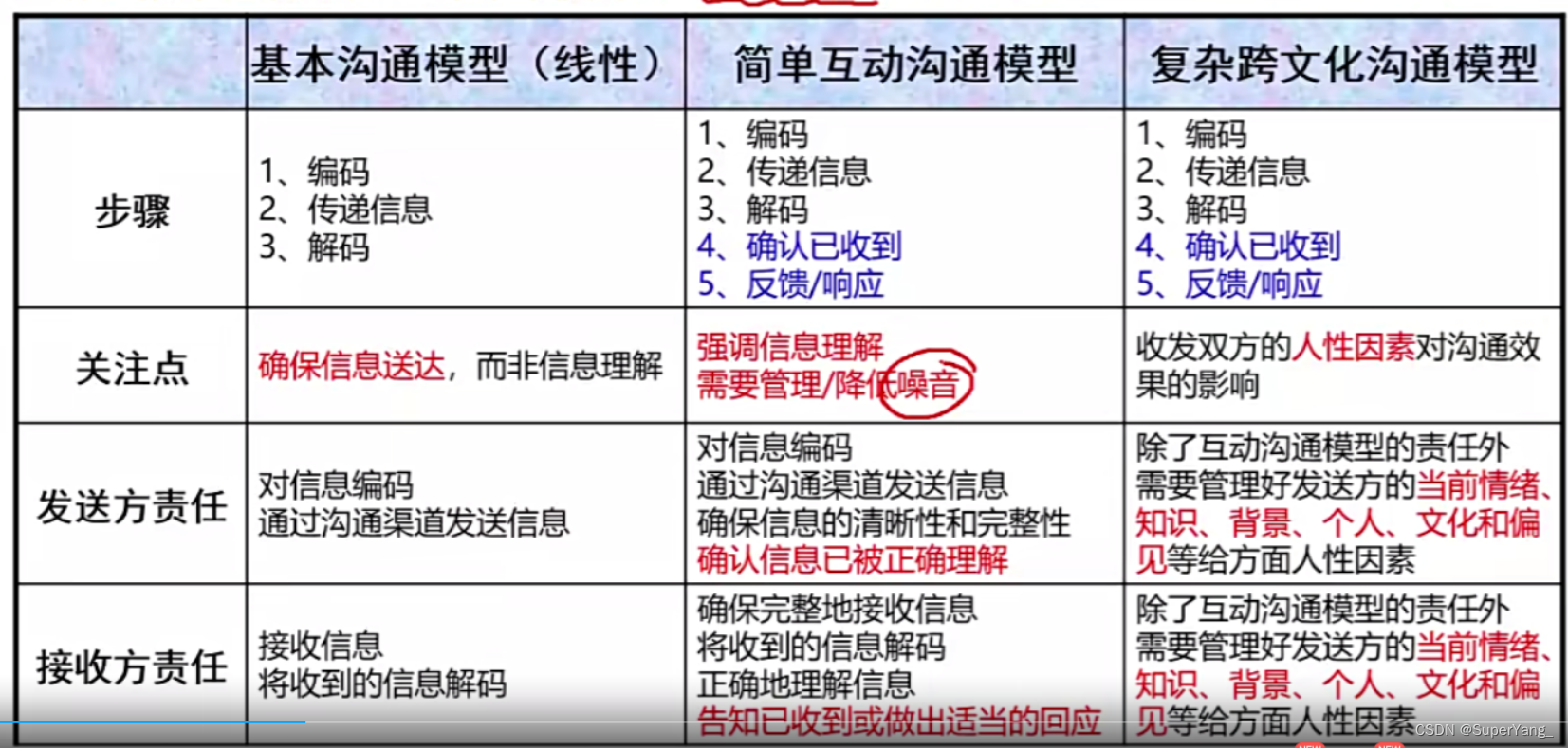
PMP项目管理-[第十章]沟通管理
沟通管理知识体系: 规划沟通管理: 10.1 沟通维度划分 10.2 核心概念 定义:通过沟通活动(如会议和演讲),或以工件的方式(如电子邮件、社交媒体、项目报告或项目文档)等各种可能的方式来发送或接受消息 在项目沟通中,需要…...
13个UI设计软件,一次满足你的UI设计需求
UI设计师的角色是当今互联网时代非常重要的一部分。许多计算机和移动软件都需要UI设计师的参与,这个过程复杂而乏味。这里将与您分享13个UI设计软件,希望帮助您正确选择UI设计软件,节省工作量,创建更多优秀的UI设计作品。 1.即时…...
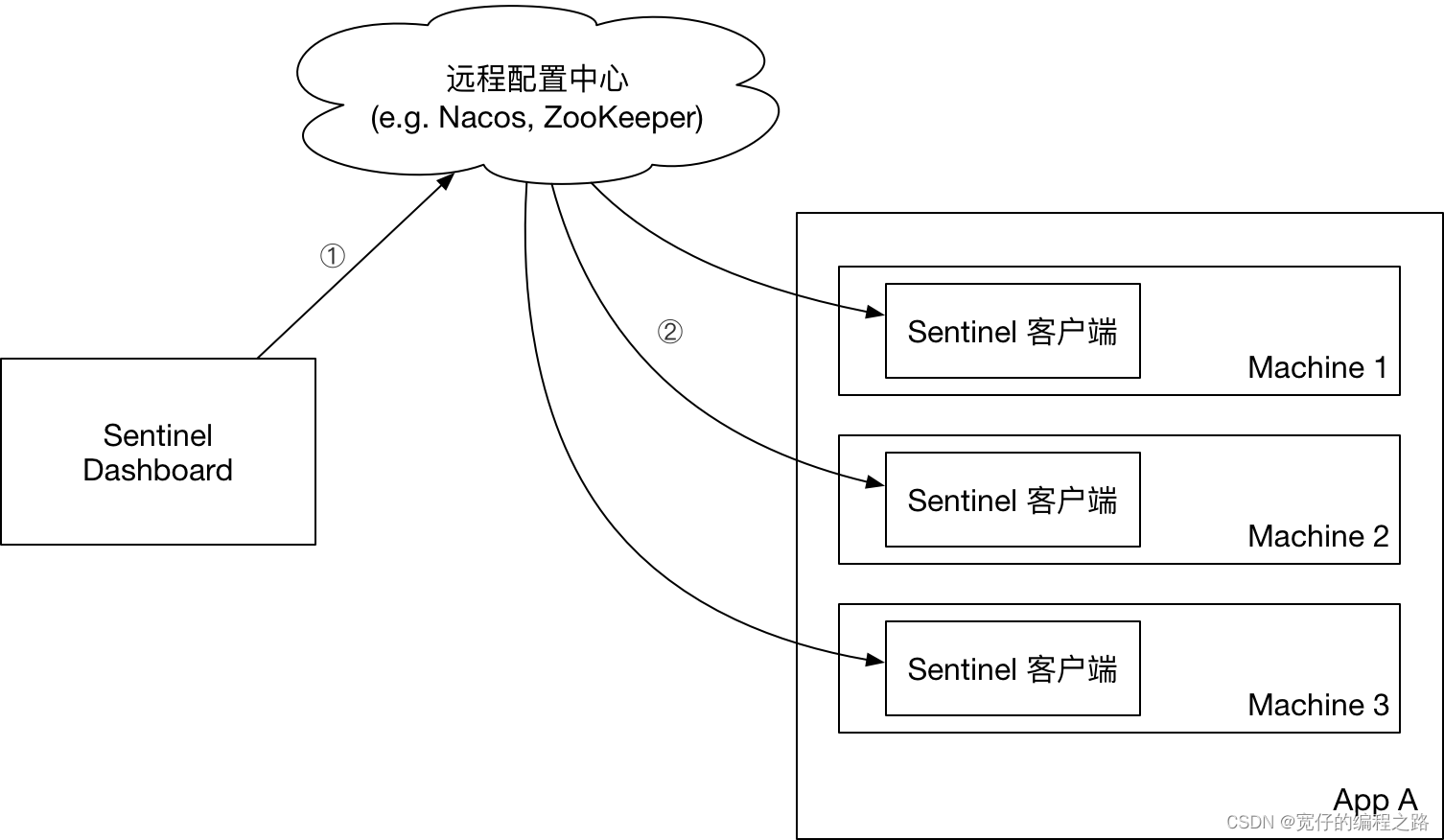
sentinel介绍
介绍 官网地址 Sentinel 和 Hystrix 的原则是一致的: 当调用链路中某个资源出现不稳定,例如,表现为 timeout,异常比例升高的时候,则对这个资源的调用进行限制,并让请求快速失败,避免影响到其它的资源&…...

百考通智能任务书:贴合你的选题,拒绝空话假大空
毕业设计任务书是高校教学管理中的关键环节,它不仅标志着研究工作的正式启动,更是后续开题、实施、论文撰写和答辩全过程的行动依据。然而,许多学生在撰写时常常因不熟悉本专业写作规范、技术表达能力有限,或缺乏权威模板参考而陷…...

iPaaS 应用场景深度解析:从系统孤岛到数据自由流动的六大实战路径
写在前面 一个企业的数字化程度越高,系统就越多。系统越多,集成问题就越严重。 这不是假设,而是我们在服务客户过程中反复验证的结论——企业数字化转型的瓶颈,往往不在于"造新系统",而在于"连老系统&q…...

DeepSeek基准测试避坑手册:92%开发者忽略的4大陷阱——硬件配置偏差、tokenizer不一致、batch size幻觉、温度值污染
更多请点击: https://codechina.net 第一章:DeepSeek基准测试避坑手册:92%开发者忽略的4大陷阱——硬件配置偏差、tokenizer不一致、batch size幻觉、温度值污染 硬件配置偏差:GPU显存与计算精度的隐性干扰 在A100(8…...

3步解锁网易云音乐NCM加密:让音乐真正属于你
3步解锁网易云音乐NCM加密:让音乐真正属于你 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 还在为下载的网易云音乐只能在特定客户端播放而烦恼吗?当你精心收藏的歌曲被NCM格式"锁"在单一平台时&a…...

2026年LLM推理加速全景:量化、投机解码与KV Cache工程实战
大语言模型推理速度慢、成本高,是阻碍AI大规模落地的核心障碍之一。一个7B参数的模型,在标准配置下每秒只能生成约30个token,对于需要实时响应的应用来说几乎无法接受。但2026年,一系列推理加速技术的成熟,让这一局面发…...
)
保姆级避坑指南:在Ubuntu 22.04上搞定ROS2 Humble、PX4与Gazebo的联合仿真(附Empy版本降级)
保姆级避坑指南:Ubuntu 22.04下ROS2 Humble与PX4联合仿真的21个关键陷阱当你在Ubuntu 22.04上第一次尝试搭建ROS2 Humble、PX4与Gazebo的联合仿真环境时,可能会遇到比预期更多的挑战。这不是一个简单的"复制粘贴命令就能完成"的任务——版本冲…...

在多轮对话应用中观察Taotoken计费对成本的影响
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在多轮对话应用中观察Taotoken计费对成本的影响 效果展示类,结合一个需要维护长上下文的多轮对话应用案例,…...

Windows Cleaner深度解析:5大核心模块彻底解决系统空间不足问题
Windows Cleaner深度解析:5大核心模块彻底解决系统空间不足问题 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner Windows Cleaner是一款完全免费开源的…...

基于GSM与Arduino的远程控制系统:DIY电话控制与短信报警方案
1. 项目概述与核心价值如果你曾经想过,在离家几十公里外,仅凭一部普通的手机,就能远程打开家里的车库门、查看门窗是否关好,甚至在异常情况发生时让系统自动打电话给你报警,那么这个基于GSM的远程控制系统项目…...
)
用Python复现Nature论文:仅需100次循环数据,提前预测锂电池寿命(附完整代码与数据集)
用Python实战预测锂电池寿命:从数据特征到模型部署全解析锂电池作为现代能源存储的核心组件,其寿命预测一直是工业界和学术界关注的焦点。传统方法往往需要等待电池出现明显容量衰减才能进行判断,而最新研究表明,通过分析早期循环…...