Elasticsearch(一)
Elasticsearch(一)
初始elasticsearch
什么是elasticsearch
elasticsearch是一款非常强大的开源搜索引擎,可以帮助我们从海量数据中快速查找到需要的内容
elasticsearch结合kibana、Logstash、Beats,也就是elastic stack(ELK)。被广泛应用在日志数据分析、实时监控等领域。
elasticsearch是elastic stack的核心,负责存储、搜索、分析数据
Lucene是一个Java语言的搜索引擎类库:https://lucene.apache.org/
优势:
- 易扩展
- 高性能(基于倒排索引)
缺点:
- 只限于Java语言开发
- 学习路线陡峭
- 不支持水平扩展
Elasticsearch:https://www.elastic.co/cn/
相比与lucene,elasticsearch具备下列优势:
- 支持分布式,可水平扩展
- 提供Restful接口,可被任何语言调用
搜索引擎技术排名:
- Elasticsearch:开源分布式搜索引擎
- Splunk:商业项目
- Solr:Apache的开源搜索引擎
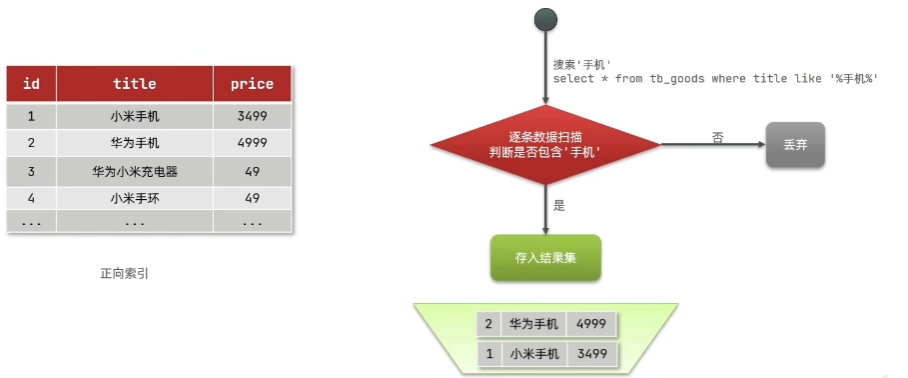
正向索引和倒排索引
传统数据库采用正向索引,例如给下表中创建id索引:
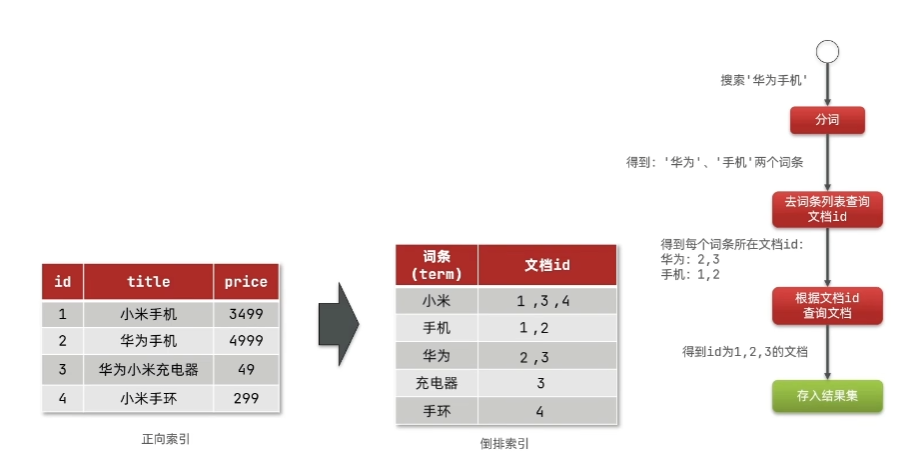
elasticsearch采用倒排索引:
- 文档:每条数据就是一个文档
- 词条:文档按照语义分成词语
文档
elasticsearch是面向文档存储的,可以是数据库中的一条商品数据,一个订单信息
文档数据会被序列化为json格式后存储在elasticsearch中

索引
索引:相同类型的文档的集合
映射:索引中文案的字段约束信息,类似于表的结构约束

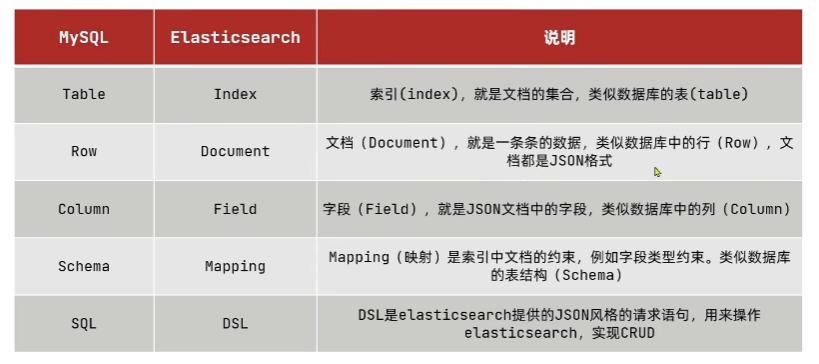
概念对比
架构
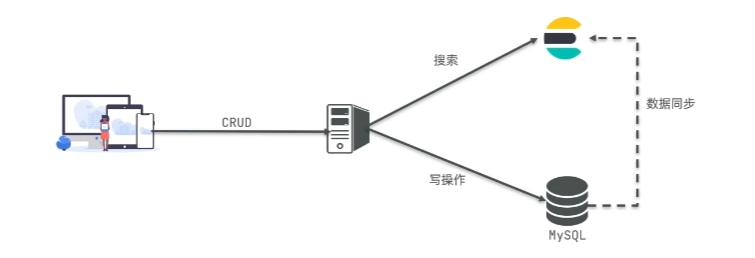
Mysql:擅长事务类型操作,可以确保数据的安全和一致性
Elasticsearch:擅长海量数据的搜索、分析、计算
安装elasticsearch、kibana
1.部署单点es
1.1.创建网络
因为我们还需要部署kibana容器,因此需要让es和kibana容器互联。这里先创建一个网络:
docker network create es-net
1.2.加载镜像
这里我们采用elasticsearch的7.12.1版本的镜像,这个镜像体积非常大,接近1G。不建议大家自己pull。
课前资料提供了镜像的tar包:
大家将其上传到虚拟机中,然后运行命令加载即可:
# 导入数据
docker load -i es.tar
同理还有kibana的tar包也需要这样做。
1.3.运行
运行docker命令,部署单点es:
docker run -d \--name es \-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \-e "discovery.type=single-node" \-v es-data:/usr/share/elasticsearch/data \-v es-plugins:/usr/share/elasticsearch/plugins \--privileged \--network es-net \-p 9200:9200 \-p 9300:9300 \
elasticsearch:7.12.1
命令解释:
- -e “cluster.name=es-docker-cluster”:设置集群名称
- -e “http.host=0.0.0.0”:监听的地址,可以外网访问
- -e “ES_JAVA_OPTS=-Xms512m -Xmx512m”:内存大小
- -e “discovery.type=single-node”:非集群模式
- -v es-data:/usr/share/elasticsearch/data:挂载逻辑卷,绑定es的数据目录
- -v es-logs:/usr/share/elasticsearch/logs:挂载逻辑卷,绑定es的日志目录
- -v es-plugins:/usr/share/elasticsearch/plugins:挂载逻辑卷,绑定es的插件目录
- –privileged:授予逻辑卷访问权
- –network es-net :加入一个名为es-net的网络中
- -p 9200:9200:端口映射配置
在浏览器中输入:http://192.168.72.133:9200 即可看到elasticsearch的响应结果:
2.部署kibana
kibana可以给我们提供一个elasticsearch的可视化界面,便于我们学习。
2.1.部署
运行docker命令,部署kibana
docker run -d \
--name kibana \
-e ELASTICSEARCH_HOSTS=http://es:9200 \
--network=es-net \
-p 5601:5601 \
kibana:7.12.1
- –network es-net :加入一个名为es-net的网络中,与elasticsearch在同一个网络中
- -e ELASTICSEARCH_HOSTS=http://es:9200":设置elasticsearch的地址,因为kibana已经与elasticsearch在一个网络,因此可以用容器名直接访问elasticsearch
- -p 5601:5601:端口映射配置
kibana启动一般比较慢,需要多等待一会,可以通过命令:
docker logs -f kibana
查看运行日志,当查看到下面的日志,说明成功:
此时,在浏览器输入地址访问:http://192.168.72.133:5601,即可看到结果
2.2.DevTools
kibana中提供了一个DevTools界面:
这个界面中可以编写DSL来操作elasticsearch。并且对DSL语句有自动补全功能。
3.安装IK分词器
官网:https://github.com/medcl/elasticsearch-analysis-ik
3.1.在线安装ik插件(较慢)
# 进入容器内部
docker exec -it elasticsearch /bin/bash# 在线下载并安装
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.12.1/elasticsearch-analysis-ik-7.12.1.zip#退出
exit
#重启容器
docker restart elasticsearch
3.2.离线安装ik插件(推荐)
1)查看数据卷目录
安装插件需要知道elasticsearch的plugins目录位置,而我们用了数据卷挂载,因此需要查看elasticsearch的数据卷目录,通过下面命令查看:
docker volume inspect es-plugins
显示结果:
[{"CreatedAt": "2022-05-06T10:06:34+08:00","Driver": "local","Labels": null,"Mountpoint": "/var/lib/docker/volumes/es-plugins/_data","Name": "es-plugins","Options": null,"Scope": "local"}
]
说明plugins目录被挂载到了:/var/lib/docker/volumes/es-plugins/_data这个目录中。
2)解压缩分词器安装包
下面我们需要把课前资料中的ik分词器解压缩,重命名为ik
3)上传到es容器的插件数据卷中
也就是/var/lib/docker/volumes/es-plugins/_data:
4)重启容器
# 4、重启容器
docker restart es
# 查看es日志
docker logs -f es
5)测试:
IK分词器包含两种模式:
- ik_smart:最少切分
- ik_max_word:最细切分
POST /_analyze
{"analyzer": "ik_max_word","text": "希诚是无敌的,xc is best"
}
结果:
{"tokens" : [{"token" : "希","start_offset" : 0,"end_offset" : 1,"type" : "CN_CHAR","position" : 0},{"token" : "诚","start_offset" : 1,"end_offset" : 2,"type" : "CN_CHAR","position" : 1},{"token" : "是","start_offset" : 2,"end_offset" : 3,"type" : "CN_CHAR","position" : 2},{"token" : "无敌","start_offset" : 3,"end_offset" : 5,"type" : "CN_WORD","position" : 3},{"token" : "的","start_offset" : 5,"end_offset" : 6,"type" : "CN_CHAR","position" : 4},{"token" : "xc","start_offset" : 7,"end_offset" : 9,"type" : "ENGLISH","position" : 5},{"token" : "best","start_offset" : 13,"end_offset" : 17,"type" : "ENGLISH","position" : 6}]
}
3.3 扩展词词典
随着互联网的发展,“造词运动”也越发的频繁。出现了很多新的词语,在原有的词汇列表中并不存在。比如:“奥力给”,“泰库辣” 等。
所以我们的词汇也需要不断的更新,IK分词器提供了扩展词汇的功能。
1)打开IK分词器config目录:
2)在IKAnalyzer.cfg.xml配置文件内容添加:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties><comment>IK Analyzer 扩展配置</comment><!--用户可以在这里配置自己的扩展字典 *** 添加扩展词典--><entry key="ext_dict">ext.dic</entry>
</properties>
3)新建一个 ext.dic,可以参考config目录下复制一个配置文件进行修改
泰库辣
奥力给
4)重启elasticsearch
docker restart es# 查看 日志
docker logs -f elasticsearch
日志中已经成功加载ext.dic配置文件
5)测试效果:
GET /_analyze
{"analyzer": "ik_max_word","text": "如果你也跟我一样的话,那么我觉得,泰库辣"
}
注意当前文件的编码必须是 UTF-8 格式,严禁使用Windows记事本编辑
3.4 停用词词典
在互联网项目中,在网络间传输的速度很快,所以很多语言是不允许在网络上传递的,如:关于宗教、政治等敏感词语,那么我们在搜索时也应该忽略当前词汇。
IK分词器也提供了强大的停用词功能,让我们在索引时就直接忽略当前的停用词汇表中的内容。
1)IKAnalyzer.cfg.xml配置文件内容添加:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties><comment>IK Analyzer 扩展配置</comment><!--用户可以在这里配置自己的扩展字典--><entry key="ext_dict">ext.dic</entry><!--用户可以在这里配置自己的扩展停止词字典 *** 添加停用词词典--><entry key="ext_stopwords">stopword.dic</entry>
</properties>
3)在 stopword.dic 添加停用词
习大大
4)重启elasticsearch
# 重启服务
docker restart elasticsearch
docker restart kibana# 查看 日志
docker logs -f elasticsearch
日志中已经成功加载stopword.dic配置文件
5)测试效果:
GET /_analyze
{"analyzer": "ik_max_word","text": "如果你也跟我一样的话,那么我觉得,泰库辣,xxx!"
}
注意当前文件的编码必须是 UTF-8 格式,严禁使用Windows记事本编辑
索引库操作
mapping属性
mapping是对索引库中文档的约束,常见的mapping属性包括:https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping.html
-
type:字段数据类型,常见的简单类型有:
-
- 字符串:text(可分词的文本)、keyword(精确值,例如:品牌、国家、ip地址)
- 数值:long、integer、short、byte、double、float
- 布尔:boolean
- 日期:date
- 对象:object
-
index:是否创建索引,默认为true
-
analyzer:使用哪种分词器
-
properties:该字段的子字段
创建索引库
ES通过Restful请求操作索引库、文档。请求内容用DSL语句来表示。创建索引库和mapping的DSL语法如下:

# 创建索引库
PUT /xc
{"mappings": {"properties": {"info":{"type": "text","analyzer": "ik_smart"},"email":{"type": "keyword","index": false },"name":{"type": "object","properties": {"firstName":{"type": "keyword"},"lastName":{"type": "keyword"}}}}}
}
查看、删除索引库
查看索引库语法:
GET /索引库名称
删除索引库的语法
DELETE /索引库名称
修改索引库
索引库和mapping一旦创建无法修改,但是可以添加新的字段,语法:
PUT /索引库名/_mapping
{"properties": {"新字段名":{"type": "text"}}
}
文档操作
添加文档
新增文档的DSL语法:
POST /索引库名/_doc/文档id
{"字段1": "值1","字段2": "值2","字段3": {"子属性1": "值3","子属性2": "值4"}
}
查询、删除文档
查询
GET /索引库名/_doc/文档id
删除
DELETE /索引库名/_doc/文档id
修改文档
方式一:全量修改,会删除旧文档,添加新文档
PUT /索引库名/_doc/文档id
{"字段1": "值1","字段2": "值2","字段3": {"子属性1": "值3","子属性2": "值4"}
}
方式二:增量修改,修改指定字段值
POST /索引库名/_update/文档id
{"doc":{"字段值":"新的值"}
}
RestAPI
ES官网提供了各种不同语言的客户端,用来操作ES。这些客户端的本质就是组装DSL语句,通过http请求发送给ES。官网:https://www.elastic.co/guide/en/elasticsearch/client/index.html
案例:利用JavaRestClient实现创建、删除索引库,判断索引库是否存在
1. 分析数据结构,定义mapping属性
小提示:

定义mapping属性

PUT /hotel
{"mappings": {"properties": {"id":{"type": "keyword"},"name":{"type": "text","analyzer": "ik_max_word","copy_to": "all"},"address":{"type": "keyword","index": false},"price":{"type": "integer"},"score":{"type":"integer"},"brand":{"type": "keyword","copy_to": "all"},"city":{"type": "keyword"},"starName":{"type": "keyword"},"business":{"type": "keyword","copy_to": "all"},"location":{"type": "geo_point"},"pic":{"type": "keyword","index": false},"all":{"type": "text","analyzer": "ik_max_word"}}}
}
2. 初始化JavaRestClient
导入依赖
<dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId><version>7.12.1</version></dependency>
将springboot管理的es依赖7.6.x的替换成直接管理的
<properties><elasticsearch.version>7.12.1</elasticsearch.version></properties>
初始化RestHignLevelClient
package cn.itcast.hotel;import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;import java.io.IOException;/*** @author xc* @date 2023/5/10 18:38*/
@SpringBootTest
public class HotelIndexTest {private RestHighLevelClient client;@Testvoid testInit(){System.out.println(client);}// 在调用方法后执行的操作@BeforeEachvoid setUp() {this.client = new RestHighLevelClient(RestClient.builder(HttpHost.create("http://192.168.72.133:9200")));}// 在调用方法前执行的操作@AfterEachvoid tearDown() throws IOException {this.client.close();}
}
3. 创建索引库

创建索引库
@Testvoid testInit() throws IOException {// 1.创建Request对象CreateIndexRequest request = new CreateIndexRequest("hotel");// 2.准备请求参数:DSL语句request.source(MAPPING_TEMPLATE, XContentType.JSON);// 3.发送请求client.indices().create(request, RequestOptions.DEFAULT);}
4. 删除索引库、判断索引库是否存在
- 删除索引库代码
@Testvoid testDeleteHotelIndex() throws IOException {// 1.创建Request对象DeleteIndexRequest request = new DeleteIndexRequest("hotel");// 2.发送请求client.indices().delete(request,RequestOptions.DEFAULT);}
- 判断索引库是否存在
@Testvoid testExistsHotelIndex() throws IOException {// 1.创建Request对象GetIndexRequest request = new GetIndexRequest("hotel");// 2.发送请求boolean exists = client.indices().exists(request, RequestOptions.DEFAULT);System.out.println(exists);}
案例:利用JavaRestClient实现文档的CRUD
1.利用JavaRestClient新增酒店数据
@Testvoid testAddDocument() throws IOException {List<Hotel> hotel = hotelService.list();hotel.forEach(h -> {HotelDoc hotelDoc = new HotelDoc(h);IndexRequest request = new IndexRequest("hotel").id(h.getId().toString());request.source(JSON.toJSONString(hotelDoc),XContentType.JSON);try {client.index(request,RequestOptions.DEFAULT);} catch (IOException e) {throw new RuntimeException(e);}});}
2.利用JavaRestClient根据id查询酒店数据
@Testvoid testGETDocument() throws IOException {GetRequest request = new GetRequest("hotel","61083");GetResponse documentFields = client.get(request, RequestOptions.DEFAULT);String json = documentFields.getSourceAsString();System.out.println(json);}
3.利用JavaRestClient删除酒店数据
@Testvoid testDELETEDocument() throws IOException {DeleteRequest request = new DeleteRequest("hotel","61083");client.delete(request, RequestOptions.DEFAULT);}
4.利用JavaRestClient修改酒店数据
@Testvoid testUpdateDocument() throws IOException {UpdateRequest request = new UpdateRequest("hotel", "61083");request.doc("city","武汉");client.update(request, RequestOptions.DEFAULT);}
案例:批量导入数据
@Testvoid testBulkRequest() throws IOException {BulkRequest request = new BulkRequest();List<Hotel> hotel = hotelService.list();hotel.forEach(h -> {HotelDoc hotelDoc = new HotelDoc(h);request.add(new IndexRequest("hotel").id(hotelDoc.getId().toString()).source(JSON.toJSONString(hotelDoc),XContentType.JSON));});client.bulk(request,RequestOptions.DEFAULT);}
EFAULT);}
4.利用JavaRestClient修改酒店数据
@Testvoid testUpdateDocument() throws IOException {UpdateRequest request = new UpdateRequest("hotel", "61083");request.doc("city","武汉");client.update(request, RequestOptions.DEFAULT);}
案例:批量导入数据
@Testvoid testBulkRequest() throws IOException {BulkRequest request = new BulkRequest();List<Hotel> hotel = hotelService.list();hotel.forEach(h -> {HotelDoc hotelDoc = new HotelDoc(h);request.add(new IndexRequest("hotel").id(hotelDoc.getId().toString()).source(JSON.toJSONString(hotelDoc),XContentType.JSON));});client.bulk(request,RequestOptions.DEFAULT);}
相关文章:
Elasticsearch(一)
Elasticsearch(一) 初始elasticsearch 什么是elasticsearch elasticsearch是一款非常强大的开源搜索引擎,可以帮助我们从海量数据中快速查找到需要的内容 elasticsearch结合kibana、Logstash、Beats,也就是elastic stack&…...

深入探究Java中的枚举类型:定义、特性和应用
引言: 在Java编程中,枚举类型是一种强大而灵活的工具,用于定义一组具名的常量。它不仅提供了代码可读性和可维护性的优势,还为开发人员提供了一种更安全和结构化的方式来处理固定的常量集合。本文将深入探讨Java中的枚举类型&…...

linux密码忘了?一招解决
目录 一、前言 二、进入编辑界面 三、单用户模式 四、修改密码 五、更新信息 六、退出 七、验证 一、前言 版本:centos7.9、VMware15.5 在我们学习linux运行级别的时候,面试题可能会出如何找回root密码,下面来详细的介绍一波ÿ…...
苹果mac清理软件CleanMyMac X v4.13兼容13系统,堪称Mac最好的系统清理工具
CleanMyMac X for mac是MacOS上一款Mac清理优化工具,不仅包含各种清理功能,更是具有卸载器、维护、扩展、碎纸机这些实用功能,可以同时代替很多工具。它可以清理,优化,保养和监测您的电脑,确保您的Mac运行…...
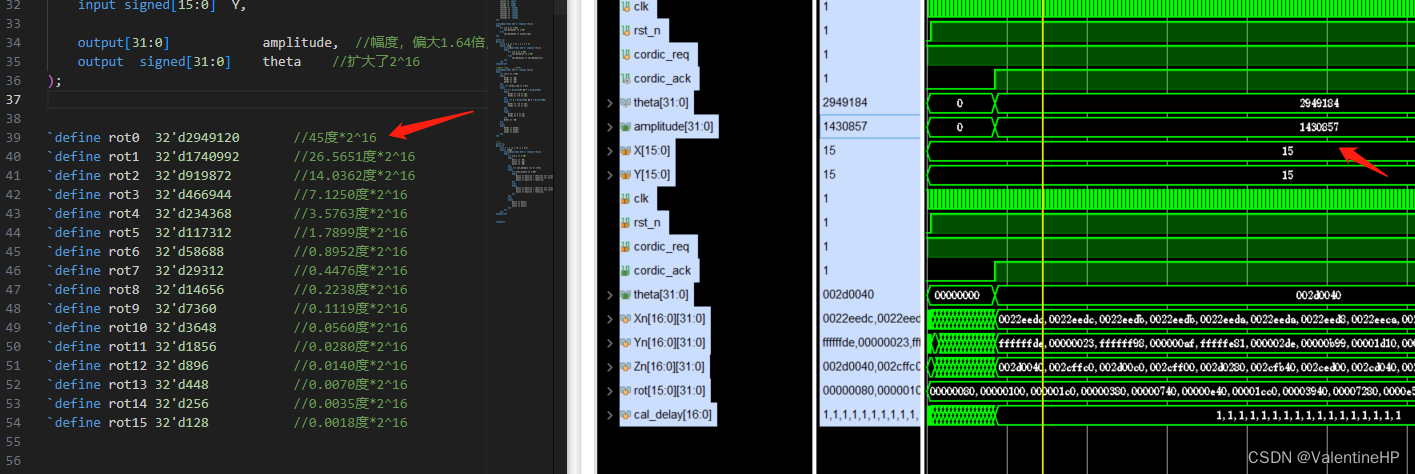
FPGA实现Cordic算法求解arctan和sqr(x*2 + y* 2)
一. 简介 由于在项目中需要使用的MPU6050,进行姿态解算,计算中设计到**arctan 和 sqr(x2 y 2),**这两部分的计算,在了解了一番之后,发现Cordic算法可以很方便的一次性求出这两个这两部分的计算。另外也可以一次性求出sin和cos的…...

【最终截稿 | Springer 独立出版 | EI稳定检索】 2023年绿色建筑国际会议(ICoGB 2023)
会议简介 Brief Introduction 2023年绿色建筑国际会议(ICoGB 2023) 会议时间:2023年5月21日-23日 召开地点:瑞典斯德哥尔摩 大会官网:www.icogb.org ICoGB 2023将围绕“绿色建筑”的最新研究领域而展开,为研究人员、工程师、专家学…...

Flutter常用状态管理框架及优缺点
Flutter 中常见的状态管理框架有以下几种: Provider: Provider 是一个轻量级的状态管理框架,可用于单个 Widget 或整个 Widget 树中分发状态。它通过 InheritedWidget 和 ChangeNotifier 来实现状态管理,并支持依赖项注入。Redux…...
Ubuntu 20.04 系统配置 OpenVINO 2022.3 环境
由于 OpenVINO 2021 版本在调用 IECore 时会出现 Segmentation fault 的问题,因此需要将其升级为 2022 版本的。 1. 卸载原来版本的 OpenVINO 进入OpenVINO的卸载目录,通常在 /opt/intel 文件夹下, cd /opt/intel/openvino_2021/openvino_…...

浏览器存储技术:localStorage、sessionStorage和cookie的区别
随着互联网技术的不断发展,人们越来越依赖浏览器进行网页浏览和数据处理。浏览器存储技术是Web开发中非常重要的一部分,它可以帮助我们在浏览器端存储数据,而无需将数据传输到服务器。本文将介绍三种常见的浏览器存储技术:localSt…...

MySQL中的内连接和外连接
一、MySQL内连接(INNER JOIN) 内连接,又称为等值连接,是最常见的连接类型。它根据两个(或多个)表中具有相同列值的行来创建一个新的结果表。在内连接中,只有通过连接条件匹配的行才会被包含在结…...

node学习手册
Node.js 是一个基于 Chrome V8 引擎的 JavaScript 运行时,使 JavaScript 可以脱离浏览器环境运行在服务端。它提供了一组 API,可以让开发者轻松地进行服务器端编程。 以下是 Node.js 的学习手册: 安装 Node.js 首先,需要在官网…...

Java中的JSP是什么?如何实现JSP
JavaServer Pages(JSP)是一种Java技术,可以用于开发动态Web应用程序。它允许开发人员将Java代码嵌入到HTML页面中,以便生成动态内容。本文将介绍JSP的工作原理,以及如何在Java中实现JSP。 JSP的工作原理 JSP的工作原…...
c++之函数对象和谓词
目录 函数对象: 谓词: 一元谓词函数举例如下 二元谓词举例如下 函数对象和函数的区别 一元谓词的案例 二元函数对象案例 二元谓词案例 函数对象: 重载函数调用操作符的类,其对象常称为函数对象(function obj…...
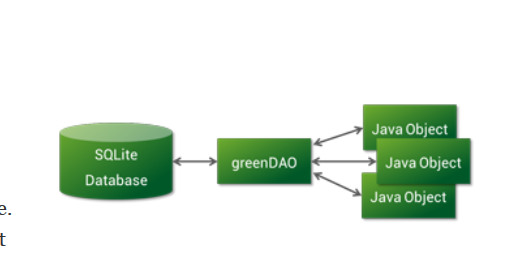
《Andorid开源》greenDao 数据库orm框架
一 前言:以前没用框架写Andorid的Sqlite的时候就是用SQLiteDatabase ,SQLiteOpenHelper ,SQL语句等一些东西,特别在写SQL语句来进行 数据库操作的时候是一件很繁琐的事情,有时候没有错误提示的,很难找到错误的地方&a…...
Android类似微信聊天页面教程(Kotlin)五——选择发送图片
前提条件 安装并配置好Android Studio Android Studio Electric Eel | 2022.1.1 Patch 2 Build #AI-221.6008.13.2211.9619390, built on February 17, 2023 Runtime version: 11.0.150-b2043.56-9505619 amd64 VM: OpenJDK 64-Bit Server VM by JetBrains s.r.o. Windows 11 …...

MongoDB:Win/Linux环境安装及一键部署脚本
1. Win安装 1.1 下载 MongoDB 安装程序 访问 MongoDB 官网,进入下载页面:Download MongoDB Community Server | MongoDB 选择 Windows 平台并下载最新版的 MongoDB 安装程序。 1.2 安装 MongoDB 双击安装程序,按照提示完成 MongoDB 的安装…...

KingbaseES V8R3 集群运维系列 -- failover切换后集群自动恢复
案例说明: KingbaseES V8R3集群默认在触发failover切换后,为保证数据安全,原主库需要通过人工介入后,恢复为新的备库加入到集群。在无人值守的现场环境,需要在触发failover切换后,主库可以自动恢复为新备…...
【Selenium中】——全栈开发——如桃花来
目录索引 查找元素:查找方法:单个元素查找:多个元素查找:*代码演示:* 元素交互操作:清空文字: 推荐的变量名定义名称:执行JavaScript :滚动页面方法:*滚动到底…...

Sarsa增强版之Sarsa-λ依然走迷宫
Sarsa-λ(Sarsa Lambda)是Sarsa算法的一种变体,其中“λ”表示一个介于0和1之间的参数,用于平衡当前状态和之前所有状态的重要性。 Sarsa算法是一种基于Q-learning算法的增量式学习方法,通过在实际环境中不断探索和学…...

生成 Cypher 能力:MOSS VS ChatGLM
生成 Cypher 能力:MOSS VS ChatGLM 生成 Cypher 能力:MOSS VS ChatGLM一、 测试结果二、 测试代码(包含Prompt) Here’s the table of contents: 生成 Cypher 能力:MOSS VS ChatGLM MOSS介绍:MOSS 是复旦大…...

Shiro RememberMe反序列化漏洞深度解析与实战利用
1. 这个漏洞不是“老古董”,而是理解Java安全边界的活教材很多人看到CVE-2016-4437,第一反应是“Shiro都淘汰了,还讲这个干啥?”——我去年在给一家做政企内部系统的客户做渗透复测时,就遇到过一个上线三年的审批平台&…...

Obsidian PDF++:如何在Obsidian中实现PDF与笔记的无缝双向链接?
Obsidian PDF:如何在Obsidian中实现PDF与笔记的无缝双向链接? 【免费下载链接】obsidian-pdf-plus PDF: the most Obsidian-native PDF annotation & viewing tool ever. Comes with optional Vim keybindings. 项目地址: https://gitcode.com/gh_…...

告别沉浸式白屏!UniApp中iOS/Android底部安全区与顶部状态栏颜色自定义全攻略
告别沉浸式白屏!UniApp中iOS/Android底部安全区与顶部状态栏颜色自定义全攻略当开发者尝试在UniApp中实现沉浸式设计时,往往会遇到一个令人头疼的问题——默认的白色安全区和状态栏导致界面元素(如电池图标、信号强度)几乎不可见。…...

2026年HR招聘偏好白皮书:这5项附加技能出现频率暴涨
2026 年的招聘市场,正在从“看你会什么岗位技能”,转向“看你能不能把岗位做得更智能”。HR筛简历时,越来越关注候选人的AI应用能力、数据化思维和业务落地能力。人社部近年发布的新职业中,已经出现生成式人工智能系统应用员、人工…...

网易云音乐NCM转MP3终极指南:ncmdump工具完整使用教程
网易云音乐NCM转MP3终极指南:ncmdump工具完整使用教程 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 你是否曾经从网易云音乐下载了心爱的歌曲,却发现只能在特定播放器上收听?NCM格式的限制让音乐…...

新手村任务:成为一个架构师需要哪些装备?
新手村任务:成为一个架构师需要哪些装备? 一、前言 如果你刚入行不久,想成为一名架构师,那这篇文章就是为你写的。 我们把成为架构师比作一个RPG游戏,你是主角,需要收集各种装备、刷经验、升级技能。 新手村的第一个任务就是:了解你需要哪些装备。 二、架构师技能树…...

极致精简,功能强大的PDF编辑工具
这是一款功能全面的PDF编辑工具 你只需要导入一份PDF格式文件 就可以快速的对它进行插入 批注编辑保护转换等各种操作 而且无需登录 也可以直接使用 在插入选项中可以进行插入文字图片 页面页眉页脚页码文档背景水印视频音频等 在批注选项中可以管理批注隐藏批注 高亮显示 文本…...

串口通信粘包问题:成因深度解析与项目实战解决方案
在嵌入式开发、工业工控、上位机下位机交互项目中,串口(RS232/RS485)是最基础、最常用的通信方式。绝大多数开发者都遇到过这样的问题:串口接收的数据偶尔错乱、解析报错、数据拼接异常,单次接收的数据时而半包、时而多…...

TVA注意力层INT8量化配置技巧
重磅预告:本专栏将独家连载系列丛书《智能体视觉技术与应用》部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。Bohan先生师从美国三院院士、“…...

yolo视频识别 车辆速度估计识别 yolo11视频实时速度测量与测速估计
文章目录YOLOv11:视频实时速度测量与测速估计一、YOLOv11概述二、速度测量原理三、距离测量方法四、应用场景五、实践案例以下是关于使用YOLOv11进行视频实时速度测量与测速估计的介绍: YOLOv11:视频实时速度测量与测速估计 随着计算机视觉…...