C++ 算法主题系列之贪心算法的贪心之术
1. 前言
贪心算法是一种常见算法。是以人性之念的算法,面对众多选择时,总是趋利而行。
因贪心算法以眼前利益为先,故总能保证当前的选择是最好的,但无法时时保证最终的选择是最好的。当然,在局部利益最大化的同时,也可能会带来最终利益的最大化。
假如在你面前有 3 个盘子,分别放了很多苹果、橙子、梨子。
现以贪心之名,从 3 个盘子里分别拿出其中最重的那个,则能求解出不同品种间最重水果的最大重量之和。这时,3 个盘子可认为是 3 个子问题(局部问题)。
贪心算法会有一个排序过程。当看到盘子里的水果时,潜意识中你就在给它们排序。有时,因可排序的属性较多,必然导致使用贪心算法求解问题时,贪心策略可能会有多种。
比如说选择水果,你可以选择每盘里最大的、最重的、最成熟的……具体应用那个策略,要根据求解的问题要求而定。贪心策略不同,导致的结论也会不一样。
本文将通过几个案例深入探讨贪心算法的贪心策略。
2. 活动安排问题
问题描述:
- 有
n个活动a1,a2,…,an……需要在同一天使用同一个教室,且教室同一时刻只能由一个活动使用。 - 每个活动
ai都有一个开始时间si和结束时间fi。 - 一个活动被选择后,另一个活动则需等待前一个活动结束后方可进入教室。
- 请问,如何安排这些活动才能使得尽量多的活动能不冲突的举行。
分析问题:
教室同一时间点只能安排一个活动,如果活动与活动之间存在时间交集(重叠),则这两个活动肯定是不能在同一天安排。
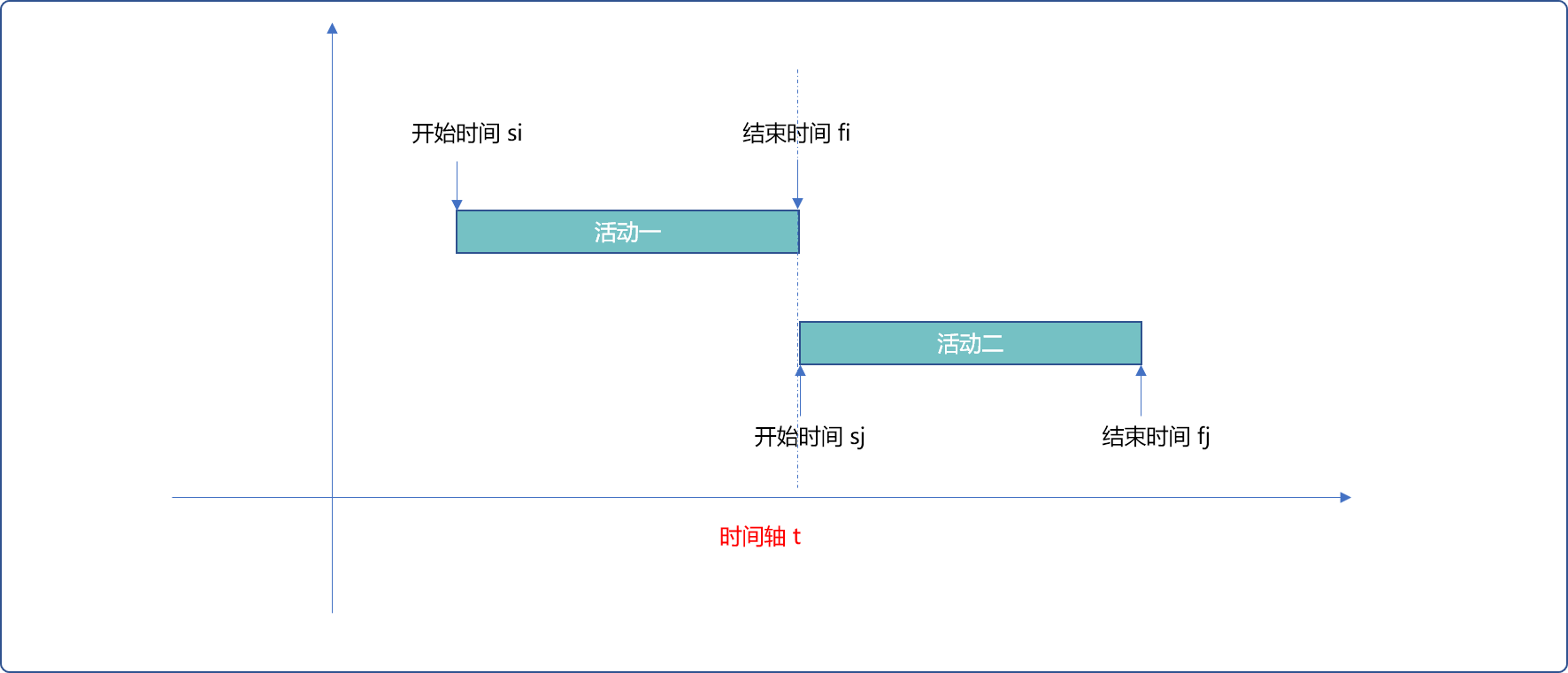
使用 S表示活动的开始时间,f表示活动的结束时间。则可使用 [si,fi]表示活动一,[sj,fj]表示活动二。
如果存在:si<sj<fi<fj,则称这 2 个活动不相容,不相容的活动不能在一天内同时出现。如下图所示。

只有当活动二的开始时间等于或晚于上活动一的结束时间时方可以在同一天出现。如下图所示。也即sj>=fi。此时,称这 2 个活动是相容。
此问题中,活动的属性有:
- 活动的开始时间。
- 活动的结束时间。
- 活动的时长。
那么,在使用贪心算法时,贪心的策略应该如何定夺?
2.1 贪心策略
2.1.1 策略一
最直接的想法是:每次安排活动时长最短的活动,必然可保证一天内容纳的活动数最多。
逻辑层面上讲,先以活动时长递增排序,然后依次选择。
但是忽视了一个问题,每一个活动都有固定的开始时间和结束时间。
如下图所示,因活动一所需时长最短,先选择。又因活动二所需时长次短,选择活动二。因两个活动时间间隔较长,采用此策略,会导致教室出现空闲时间。
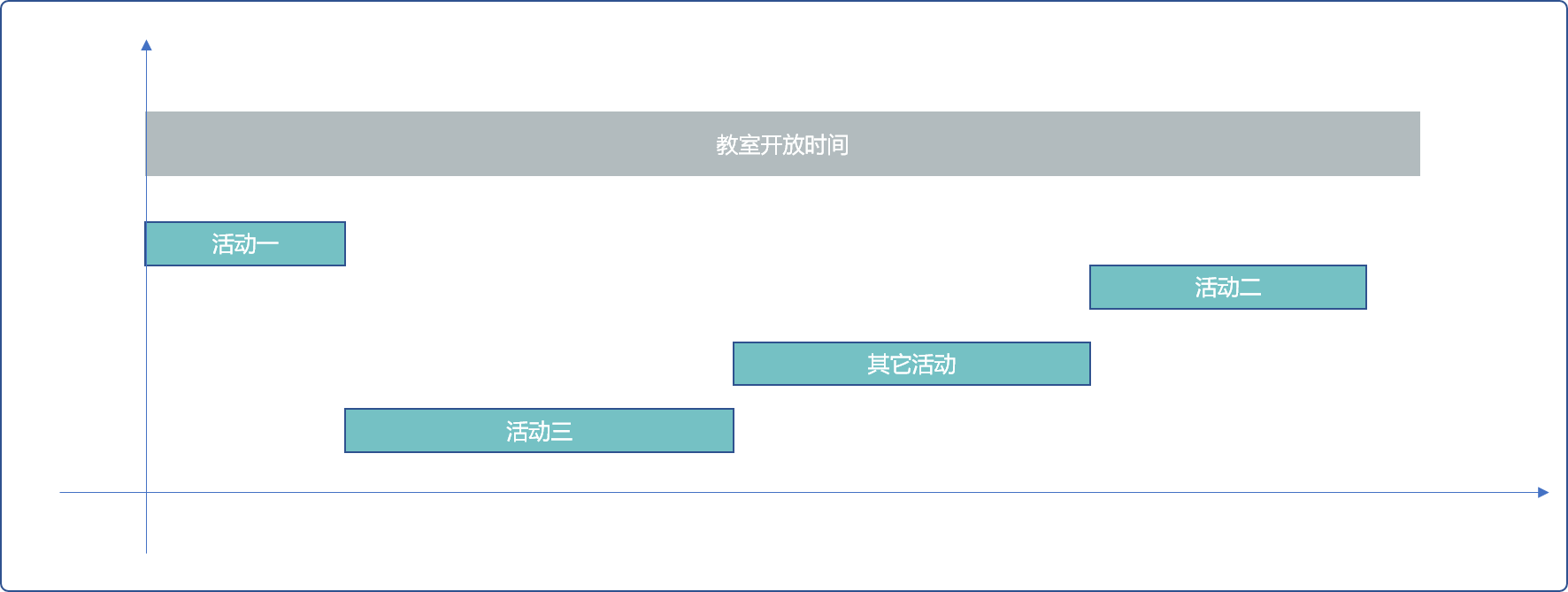
针对此问题,贪心算法的出发点应该是保证每一时刻教室的最大利用率,才有可能容纳最多活动。
显然,受限于活动固定时间限制,此策略不可行。
2.1.2 策略二
能否每次选择活动时长最长的活动。提出这个策略时,就不是很自信的。分析问题吗?就不论正确,只论角度。
此策略和策略一相悖论。题目要求尽可能安排活动的数量,如果某活动的时长很长,一个活动就占据了大部分时间,显然,此种策略是无法实现题目要求的。
如下图,选择活动一,后再选择活动三。一天仅能安排 2 次活动。根据图示,根据每个活动的开始、结束时间,一天之内至少可以安排 3 个活动。

2.1.3 策略三
每次选择最早开始的活动。
先选择最早开始,等活动结束后,再选择相容且次开始的。这个策略和策略二会有同样的问题。如果最早开始的活动时长较长,必然会导致,大部分活动插入不进去。
2.1.4 策略四
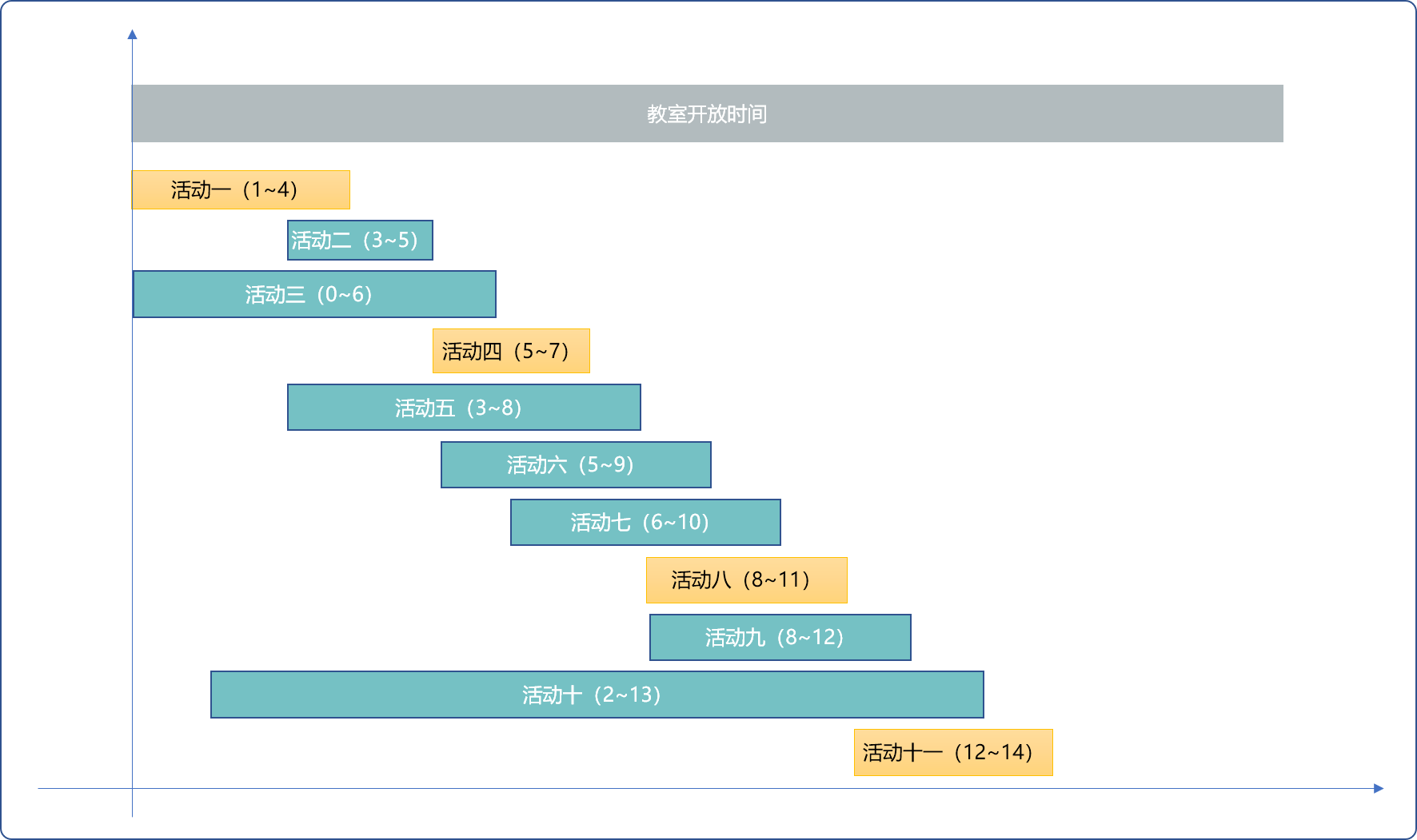
还是回到策略一上面来,以时长最短的活动为优先,理论上是没有错的,但是不能简单的仅以时长作为排序依据。
可以以活动结束时间为依据。活动结束的越早,活动时长相对而言是较短的。因同时安排的活动需要有相容性,所以,再选择时,可选择开始时间等于或晚于前一个活动结束时间的活动,这也是与策略一不同之处,并不是简单的选择相容且绝对时长短的活动。
在活动时长较短情况,又能保证教室的使用时间一直连续的,则必然可以安排的活动最多。如下图所示:
- 选择最早结束的活动。
- 开始时间与上一次结束时间相容的活动。
- 如此,反复。且保证活动的相容同时保持了时间上的连续性。
2.2 编码实现
#include <iostream>
#include <algorithm>
#define MAX 5
using namespace std;
/*
*描述活动的结构体
*/
struct Activity {//活动开始时间int startTime;//活动结束时间int endTime;//是否选择bool isSel=false;void desc() {cout<<this->startTime<<"-"<<this->endTime<<endl;}
};
//所有活动
Activity acts[MAX];
//初始化活动
void initActivities() {for(int i=0; i<MAX; i++) {cout<<"输入活动的开始时间-结束时间:"<<endl;cin>>acts[i].startTime>>acts[i].endTime;}
}
/*
*比较函数
*/
bool cmp(const Activity &act0, const Activity &act1) {return act0.endTime<act1.endTime;
}
/*
*活动安排
*/
int getMaxPlan() {//计数器int count=1;//当前选择的活动int currentSel=0;acts[currentSel].isSel=true;for(int i=1; i<MAX; i++) {if(acts[i].startTime>=acts[currentSel].endTime ) {count++;currentSel=i;acts[i].isSel=true;}}return count;
}
/*
*输出活动
*/
void showActivities() {for(int i=0; i<MAX; i++) {if(acts[i].isSel==true)acts[i].desc();}
}
/*
*测试
*/
int main() {initActivities();//排序,使用 STL 算法中的 sortsort(acts,acts+MAX,cmp);getMaxPlan();showActivities();return 0;
}
输出结果:
3. 调度问题
3.1 多机调度
问题描述:
n个作业组成的作业集,可由m台相同机器加工处理。- 要求使所给的
n个作业在尽可能短的时间内由m台机器加工处理完成。 - 作业不能拆分成更小的子作业。
分析问题:
此问题是可以使用贪心算法的,可以把每一个作业当成一个子问题看待。
- 当
n<=m时,可满足每一个作业同时有一台机器为之服务。最终时间由最长作业时间决定。 - 当
n>m时,则作业之间需要轮流使用机器 ,这时有要考虑贪心策略问题。
本问题和上题差异之处:不在意作业什么时候完成,所以作业不存在开始时间和结束时间,每个作业仅有一个作业时长属性。所以,贪心策略也就只有 2 个选择:
- 按作业时长从小到大轮流使用机器。
如果是求解在规定的时间之内,能完成的作业数量最多,则可以使用此策略。
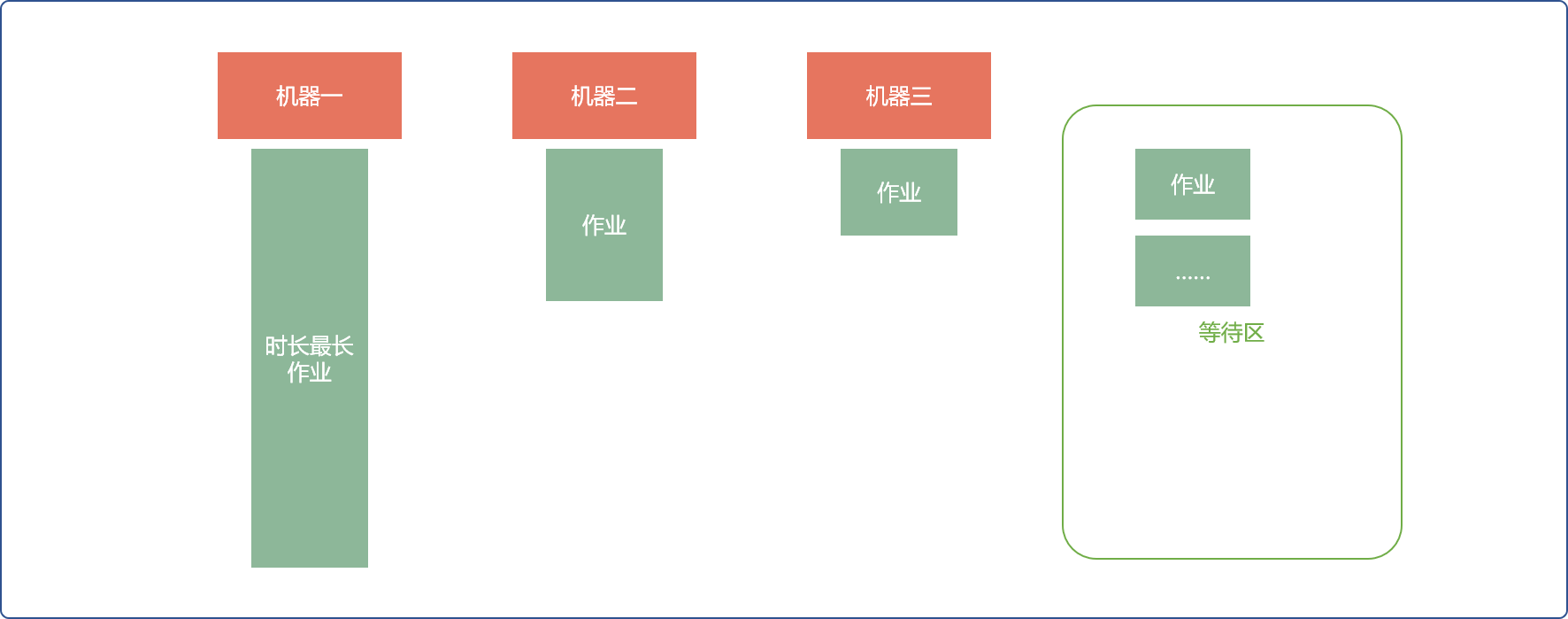
而本题是求解最终最短时间,此策略就不行。在几个作业同时工作时,**最终完成的的时长是由最长时长的作业决定的。**这是显然易见的道理。一行人行走,总是被行动被慢的人拖累。
如果把最长时长的作业排在最后,则其等待时间加上自己的作业时长,必然会导致最终总时长不是最优解。
- 按作业时长从大到小轮流使用机器。
先安排时长较长的作业,最理想状态可以保证在它工作时,其它时长较小的作业在它的周期内完成。
3.2 编码实现
#include <iostream>
#include <algorithm>
#include <vector>
#include <cstring>
using namespace std;//每个作业的工作时长
int* workTimes;
//机器数及状态
int* machines;/*
*初始化作业
*/
void initWorks(int size) {workTimes=new int[size];for(int i=0; i<size; i++) {cout<<"输入作业的时长"<<endl;cin>>workTimes[i];}
}
/*
*比较函数
*/
bool cmp(const int &l1, const int &l2) {return l1>l2;
}/*
*调度
* size: 作业多少
* count:机器数量
*/
int attemper(int size,int count) {int totalTime=0;int minTime=0;int minInit=workTimes[0];int k=0;vector<int> vec;for(int i=0; i<size;) {//查找空闲机器for(int j=0; j<count; j++) {if( workTimes[i]!=0 && machines[j]==-1 ) {//安排作业machines[j]=i;//记录已经安排的作业vec.push_back(i);i++;}}//找最小时长作业minTime=minInit;for(int j=0; j<vec.size(); j++) {if( workTimes[ vec[j] ] !=0 && workTimes[ vec[j] ] < minTime ) {minTime= workTimes[ vec[j] ];//记下作业编号k=vec[j];}}totalTime+=minTime;//清除时间for(int j=0; j<vec.size(); j++) {if(workTimes[vec[j]]>=minTime )workTimes[vec[j]]-=minTime;}for(int j=0; j<count; j++) {//机器复位为闲if(machines[j]==k)machines[j]=-1;}}//最大值int ma=0;for(int i=0; i<size; i++) {if(workTimes[i]!=0 && workTimes[i]>ma )ma=workTimes[i];}totalTime+=ma;return totalTime;
}
/*
*测试
*/
int main() {cout<<"请输入作业个数:"<<endl;int size;cin>>size;initWorks(size);//对作业按时长大到小排序sort(workTimes,workTimes+size,cmp);cout<<"请输入机器数量"<<endl;int count=0;cin>>count;//初始为空闲状态machines=new int[count] ;for(int i=0; i<count; i++)machines[i]=-1;int res= attemper(size,count);cout<<res;return 0;
}4.背包问题
背包问题是类型问题,不是所有的背包问题都能使用贪心算法。
- 不能分割背包问题也称为
0,1背包问题不能使用贪心算法。 - 可分割的背包问题则可以使用贪心算法。
问题描述:
现有一可容纳重量为 w的背包,且有不同重量的物品,且每一个物品都有自己的价值,请问,怎么选择物品,才能保证背包里的价值最大化。
如果物品不可分,则称为0~1问题,不能使用贪心算法,因为贪心算法无法保证背包装满。一般采用动态规划和递归方案。
如果物品可分,则可以使用贪心算法,本文讨论是可分的情况。
分析问题:
既然可以使用贪心算法,则现在要考虑贪心策略。
4.1 贪心策略
物品的有 2 个属性:
- 重量。
- 价值。
直观的策略有 2 个:
- 贪重量:先放重量最轻的或重量最重的。显然,这个策略是有问题的。以重为先,相当于先放较重的石头,再放较经的金子。以轻为先,相当于先放一堆类似于棉花的物品,最后再放金子。都无法得到背包中的价值最大化。
- 贪价值:以价值高的优先,理论上可行。但是,如果以纯价值优先,如下图所示,无法让背包价值最大化。因为把物品
3、物品4、物品5一起放入背包,总价值可以达到254,且背包还可以容纳其它物品。
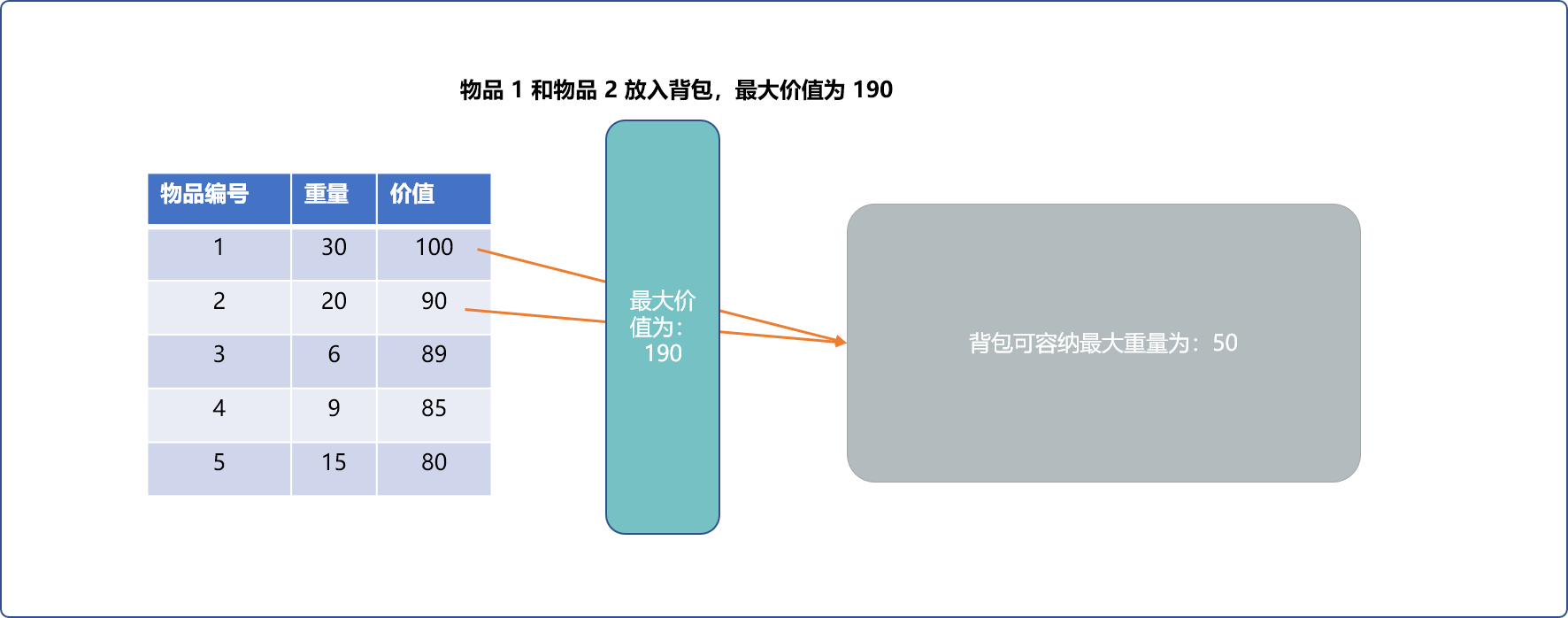
显然,以纯价值优先,是不行。
为什么以纯价值优先不行?
因为没有把价值和重量放在一起考虑。表面上一个物品的价值是较大的,这是宏观上的感觉。但是,这个物品是不是有较高的价值,应该从重量和价值比考虑,也就是价值密度。
Tips: 一块铁重
10克,价值为100。一块金子重1克,价值为90。不能仅凭价值这么一个参数就说明铁比金子值钱。
所以,应该以重量、价值比高的物品作为贪心策略。
4.2 编码实现
#include<iostream>
#include <algorithm>
using namespace std;
/*
*物品类型
*/
struct Goods {//重量double weight;//价值double price;void desc() {cout<<"物品重量:"<<this->weight<<"物品价值:"<<this->price;}
};//所有物品
Goods allGoods[10];
//物品数量
int size;
//背包重量
int bagWeight;
//存储结果,初始值为 0
double result[10]= {0.0};/*
*初始化物品
*/
void initGoods() {for(int i=0; i<size; i++) {cout<<"请输入物品的重量、价值"<<endl;cin>>allGoods[i].weight>>allGoods[i].price;}
}/*
*用于排序的比较函数
*/
bool cmp( const Goods &g1,const Goods &g2) {//按重量价值比return g1.price/g1.weight>g2.price/g2.weight;
}
/*
*贪心算法求可分割背包问题
*/
void knapsack() {int i=0;for(; i<size; i++) {if( allGoods[i].weight<=bagWeight ) {//如果物品重量小于背包重量,记录下来result[i]=1;//背包容量减小bagWeight-= allGoods[i].weight;} else//退出循环break;}//如果背包还有空间if(bagWeight!=0) {result[i]=bagWeight/allGoods[i].weight;}
}
/*
*显示背包内的物品
*/
void showBag() {double maxValue=0;for(int i=0; i<size; i++) {if( result[i] ==0)continue;allGoods[i ].desc();maxValue+=allGoods[i ].price*result[i];cout<<"数量"<<result[i]<<endl;}cout<<"总价值:"<<maxValue<<endl;
}
/*
*测试
*/
int main() {cout<<"请输入物品数量"<<endl;cin>>size;cout<<"请输入背包最大容纳重量"<<endl;cin>>bagWeight;initGoods();//排序sort(allGoods,allGoods+size,cmp);knapsack();showBag();
}
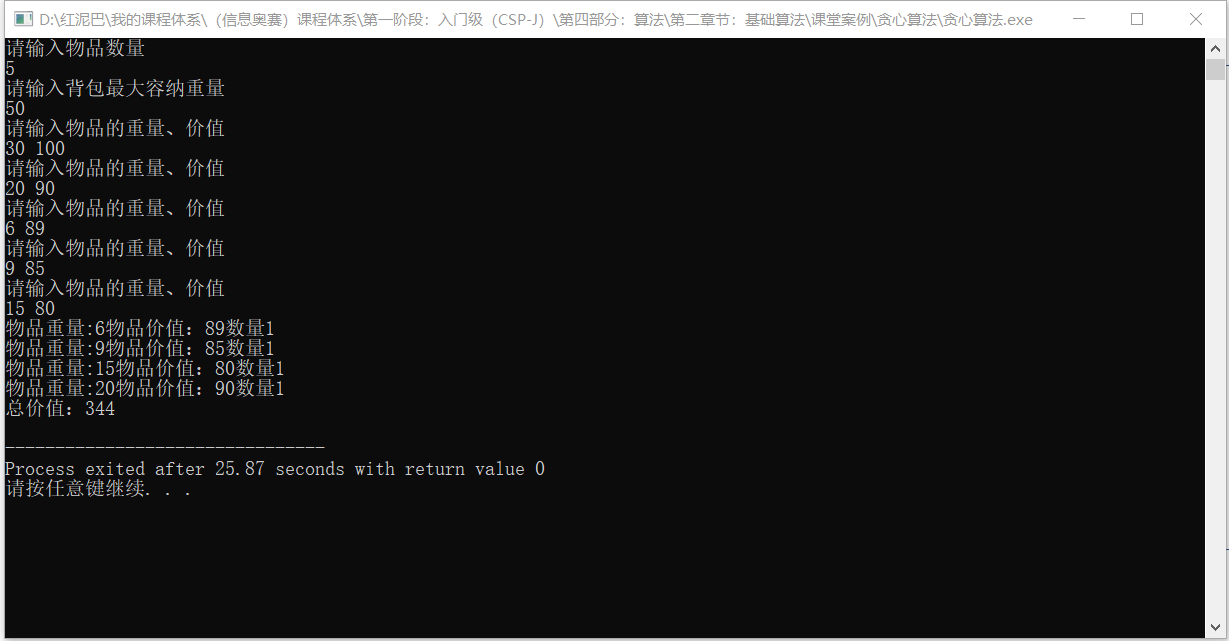
输出结果:
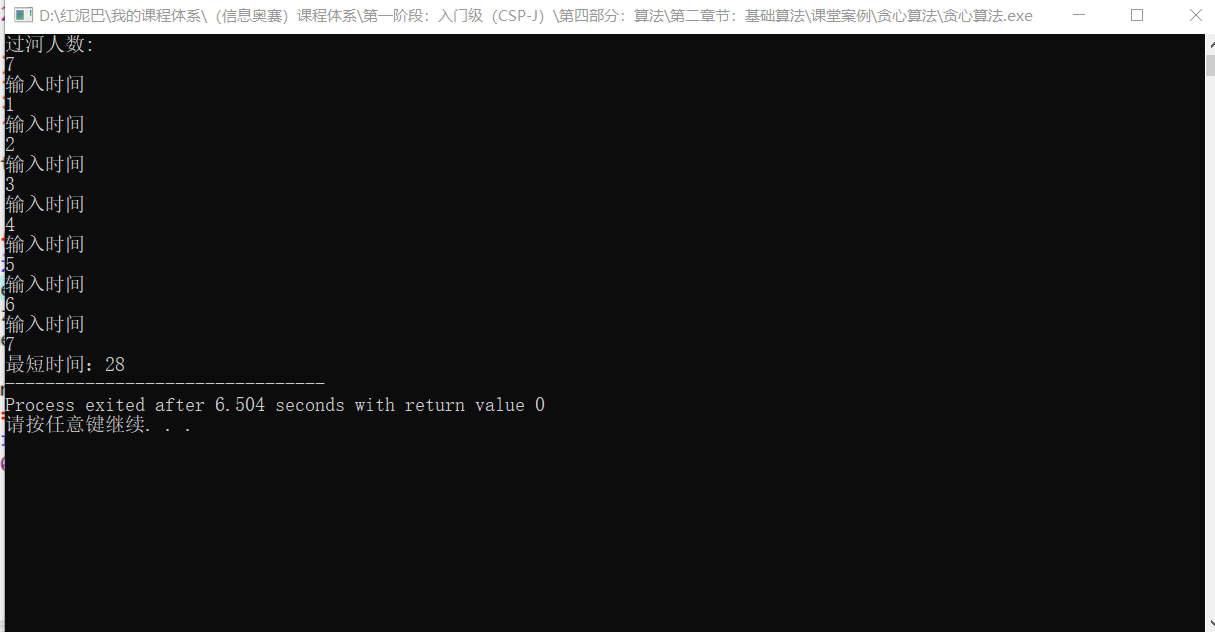
5. 过河
问题描述:
有一艘小船,每次只能载两个人过河。其中只能一人划船,渡河的时间等于其中划船慢的那个人的时间。现给定一群人和他们的划船时间,请求解最小全部渡河的时间。
分析问题:
可根据人数分情况讨论。如下n表示人数:
当总人数n<=3时:
n=1, t=t[1]。只有一个人时,过河时间为此人划船时间。n=2 t=max(t[1],t[2])。当只有二个人时,1和2中耗时长的那个。n=3 t=t[1]+t[2]+t[3]。1和3先去,1回来,再和2去。
否则,按划船的时间由快到慢排序。

基本原则,回来时,选择最快的。
1(最快)和n(最慢)先去,1(最快)回来,1和n-1(次慢)去,1(最快)的回来 ,n-=2, 用时2*t[1]+t[n]+t[n-1]。
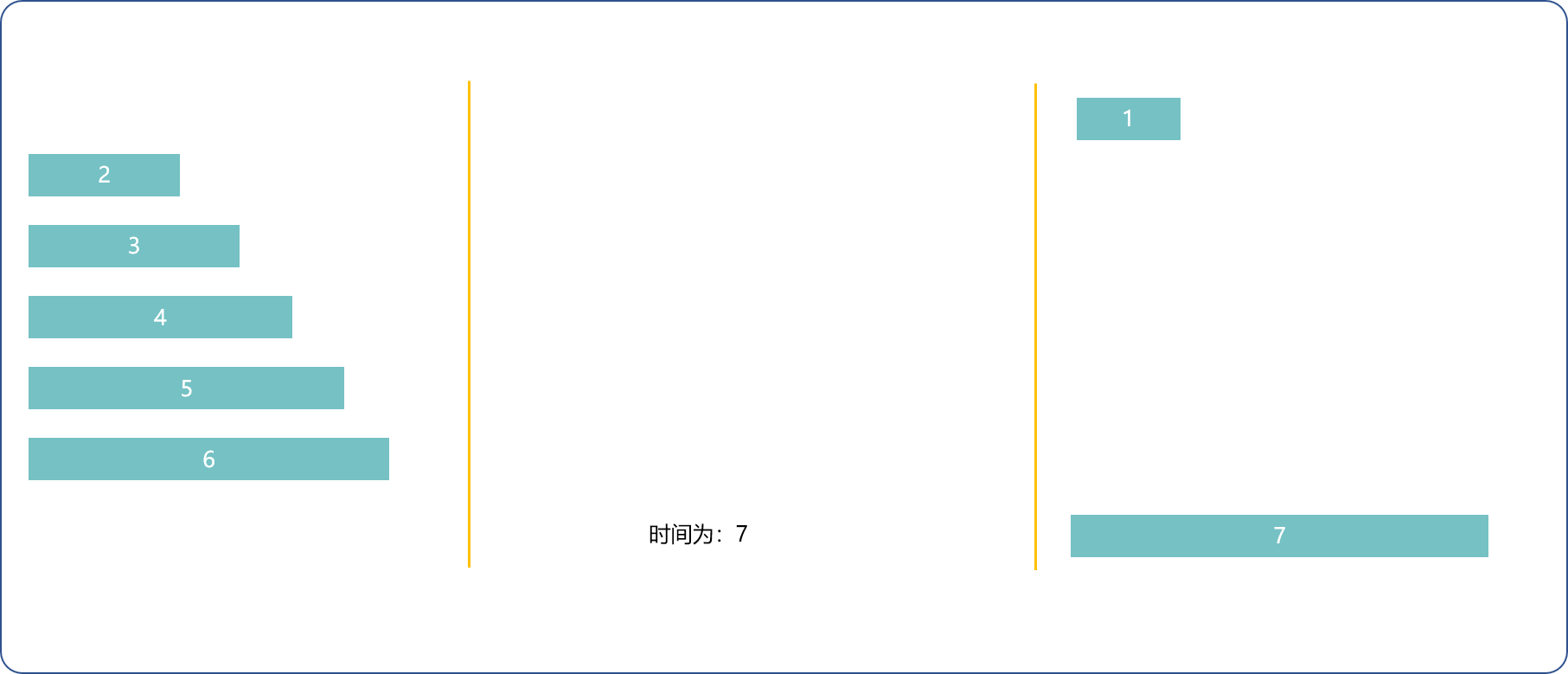

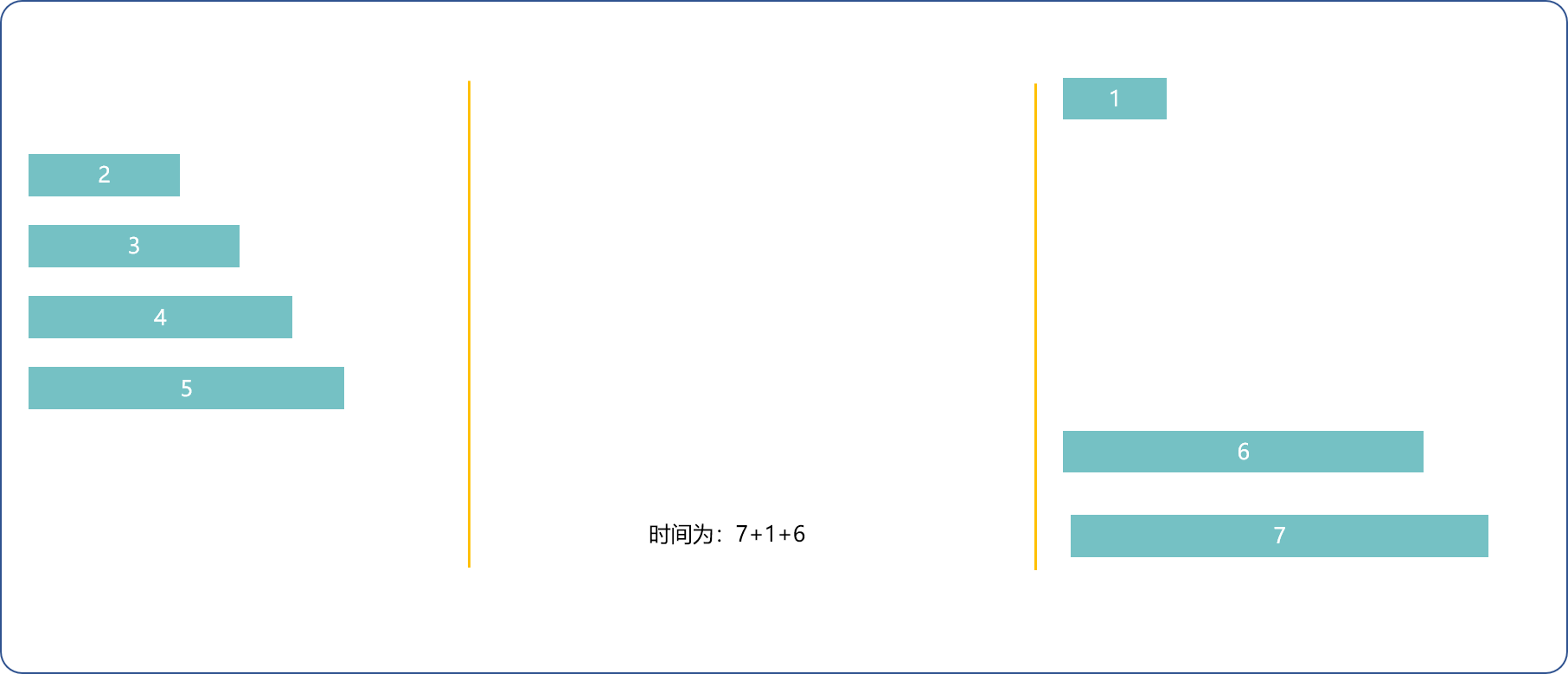
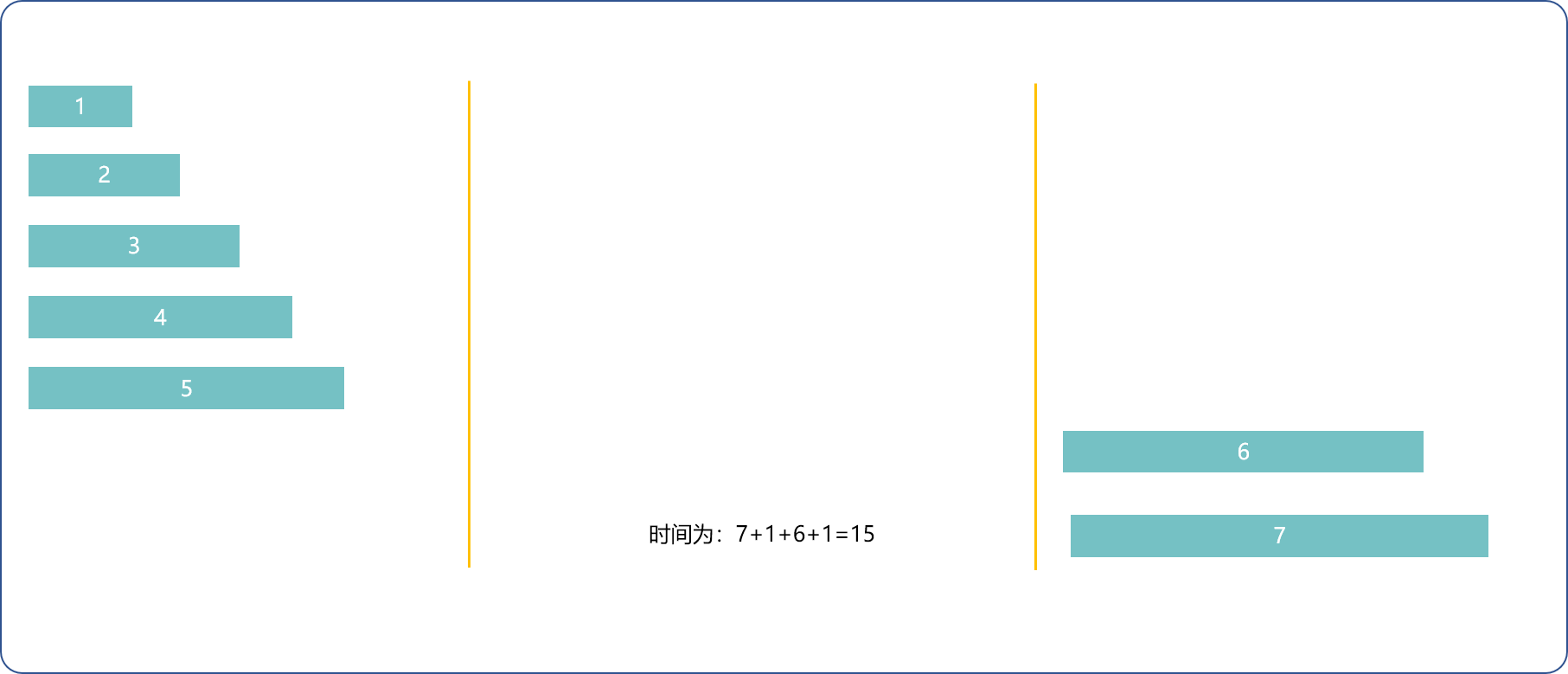
1(最快)和2(次快)去,1(最快)回来,n和n-1去,2回来,n-=2用时t[1]+2*t[2]+t[n]。
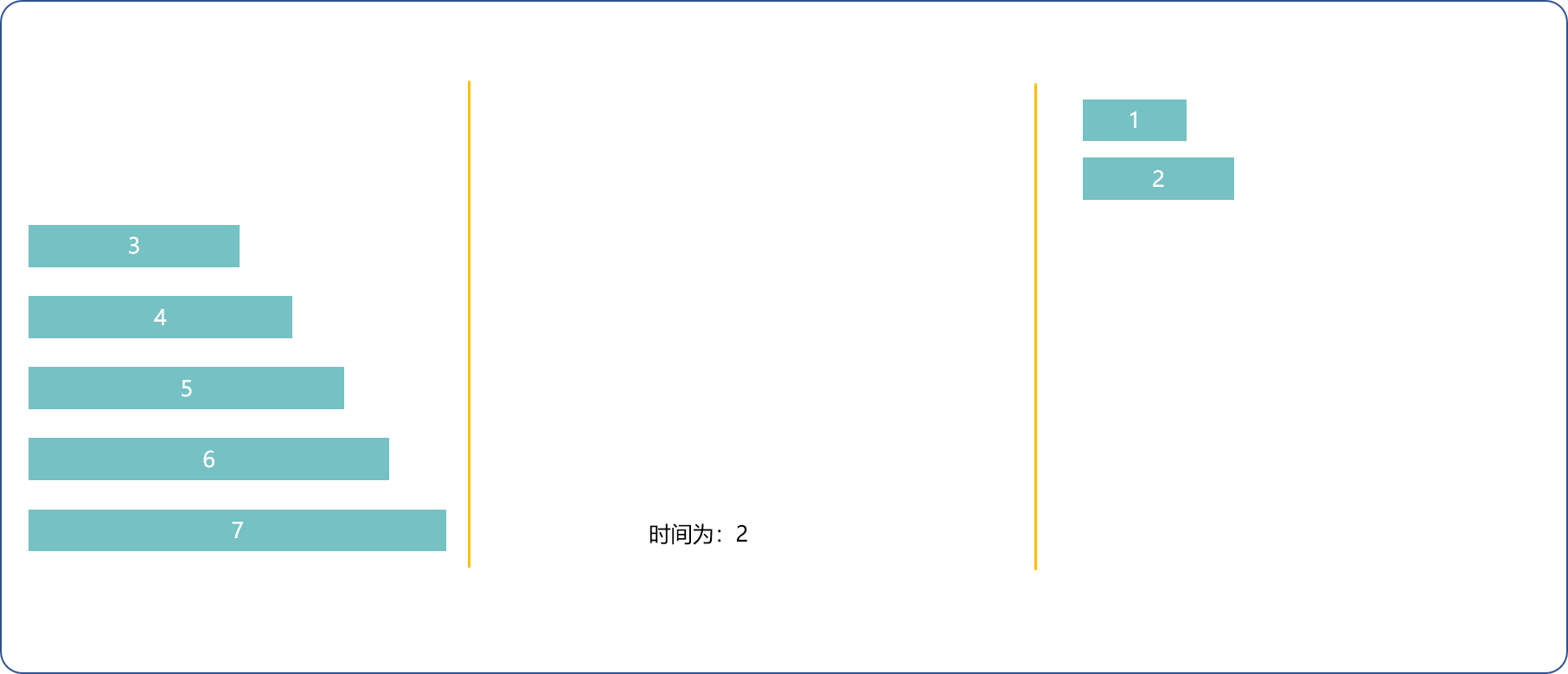
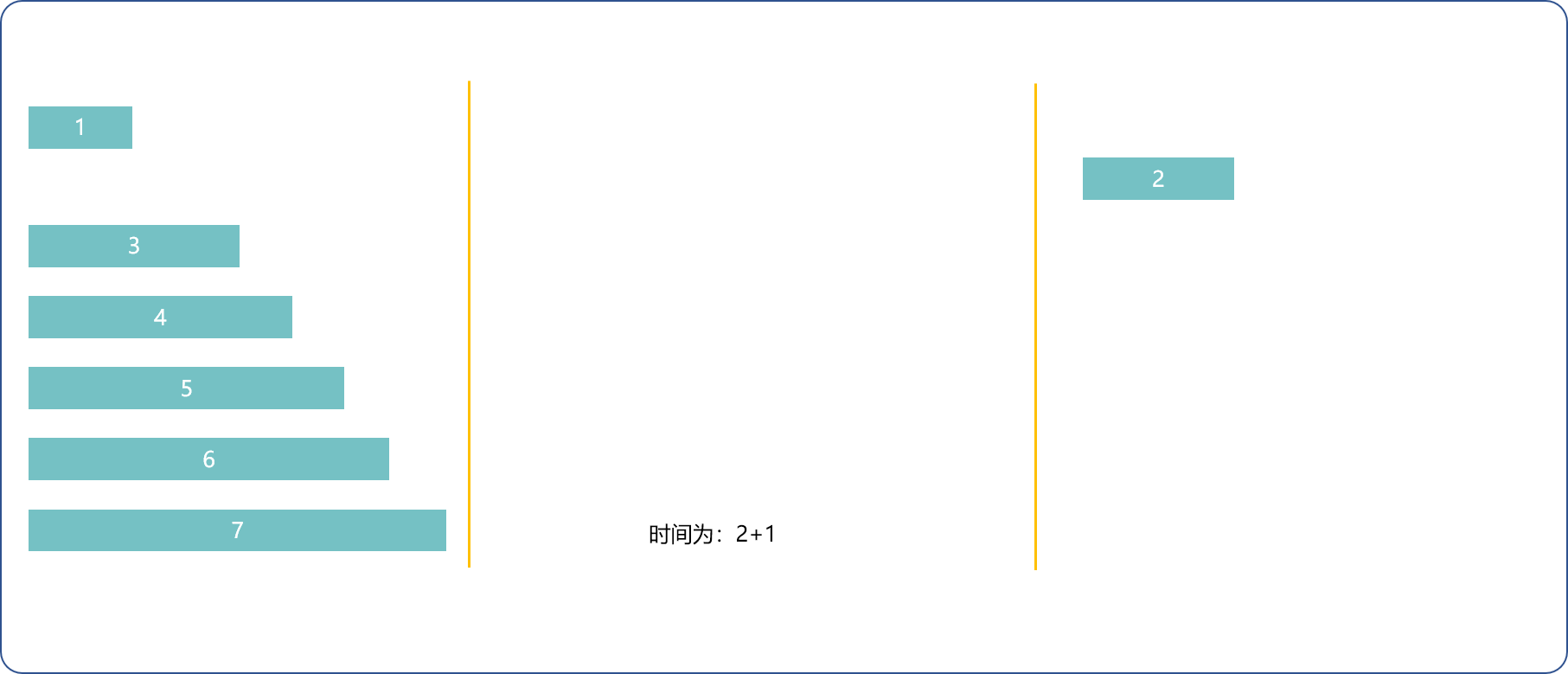
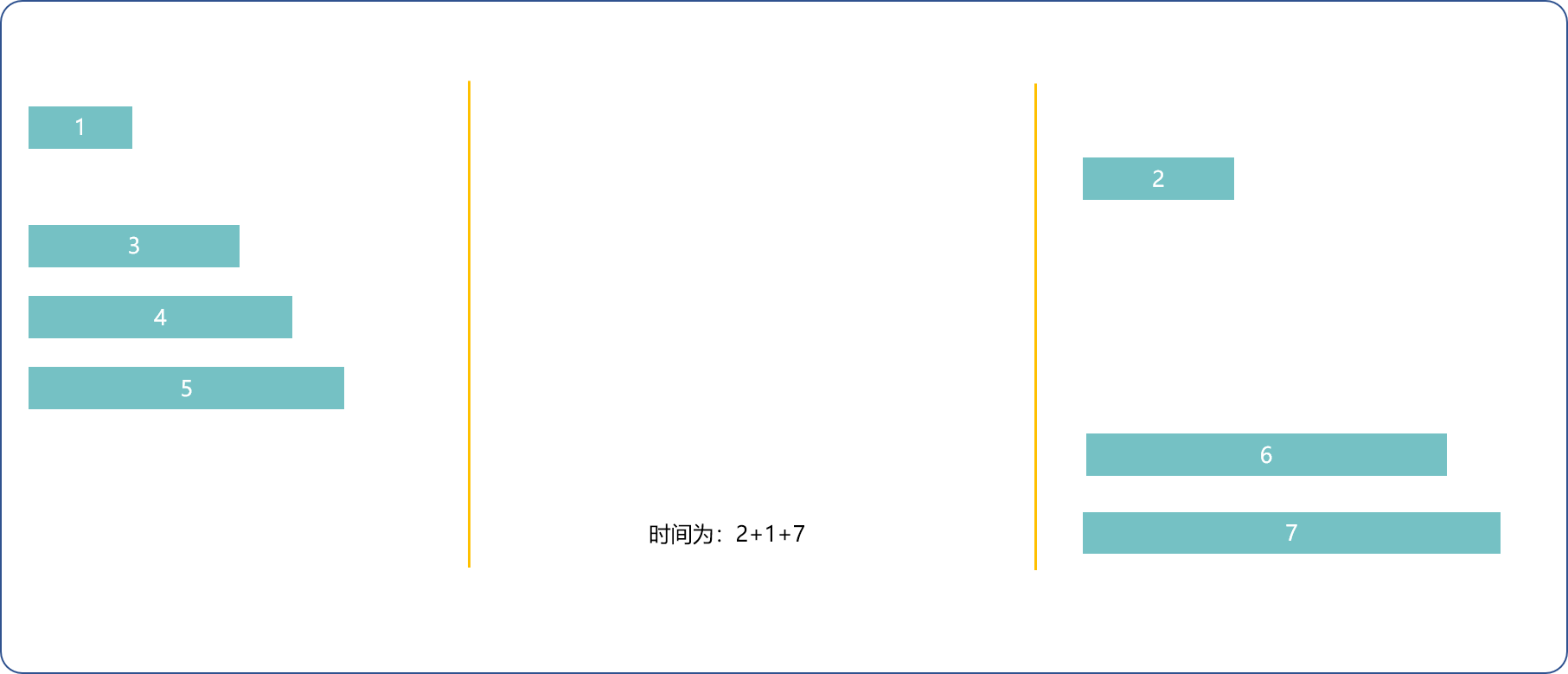

- 每次取两种方法的最小耗时,直到
n<=3。
编码实现:
#include <algorithm>
#include <iostream>
using namespace std;//每个人的过河时间
int times[100];/*
*初始化过河时间
*/
void initTimes(int size) {for(int i=0; i<size; i++) {cout<<"输入时间"<<endl;cin>>times[i];}
}/*
*比较函数
*/
bool cmp(const int &i, const int &j) {return i<j;
}/*
*贪心算法计算过河最短时间
*/
int river(int size) {int totalTime=0;int i=0;int j=size-1;while(1) {if(j-i<=2)break;int t1=2*times[0]+times[j]+times[j-1];int t2=times[0]+2*times[1]+times[j];totalTime+=min(t1,t2);j-=2;}if(j==0)totalTime+= times[0];if(j==1)totalTime+= max(times[0],times[1] );if(j==2)totalTime+=times[0]+times[1]+times[2];return totalTime;
}int main() {cout<<"过河人数:"<<endl;int size=0;cin>>size;initTimes(size);//排序sort(times,times+size,cmp);int res= river(size);cout<<"最短时间:"<<res;return 0;
}
输出结果:
6. 总结
贪心算法在很多地方就可看其身影。如最短路径查找、最小生成树算法里都用到贪心算法。
贪心算法的关键在于以什么属性优先(贪心策略),这个选对了,后续实现都很简单。
相关文章:
C++ 算法主题系列之贪心算法的贪心之术
1. 前言 贪心算法是一种常见算法。是以人性之念的算法,面对众多选择时,总是趋利而行。 因贪心算法以眼前利益为先,故总能保证当前的选择是最好的,但无法时时保证最终的选择是最好的。当然,在局部利益最大化的同时&am…...
请注意,PDF正在传播恶意软件
据Bleeping Computer消息,安全研究人员发现了一种新型的恶意软件传播活动,攻击者通过使用PDF附件夹带恶意的Word文档,从而使用户感染恶意软件。 类似的恶意软件传播方式在以往可不多见。在大多数人的印象中,电子邮件是夹带加载了恶…...

【Kubernetes】【二】环境搭建 环境初始化
本章节主要介绍如何搭建kubernetes的集群环境 环境规划 集群类型 kubernetes集群大体上分为两类:一主多从和多主多从。 一主多从:一台Master节点和多台Node节点,搭建简单,但是有单机故障风险,适合用于测试环境多主…...
)
Python:每日一题之发现环(DFS)
题目描述 小明的实验室有 N 台电脑,编号 1⋯N。原本这 N 台电脑之间有 N−1 条数据链接相连,恰好构成一个树形网络。在树形网络上,任意两台电脑之间有唯一的路径相连。 不过在最近一次维护网络时,管理员误操作使得某两台电脑之间…...

C++设计模式(14)——享元模式
亦称: 缓存、Cache、Flyweight 意图 享元模式是一种结构型设计模式, 它摒弃了在每个对象中保存所有数据的方式, 通过共享多个对象所共有的相同状态, 让你能在有限的内存容量中载入更多对象。 问题 假如你希望在长时间工作后放…...

SpringCloud之Eureka客户端服务启动报Cannot execute request on any known server解决
项目场景: 在练习SpringCloud时,Eureka客户端(client)出现报错:Cannot execute request on any known server 问题描述 正常启动SpringCloud的Server端和Client端,结果发现Server端的控制台有个Error提示,如下&#…...

从零开始搭建kubernetes集群环境(虚拟机/kubeadm方式)
文章目录1 Kubernetes简介(k8s)2 安装实战2.1 主机安装并初始化2.2 安装docker2.3 安装Kubernetes组件2.4 准备集群镜像2.5 集群初始化2.6 安装flannel网络插件3 部署nginx 测试3.1 创建一个nginx服务3.2 暴漏端口3.3 查看服务3.4 测试服务1 Kubernetes简…...
【零基础入门前端系列】—表格(五)
【零基础入门前端系列】—表格(五) 一、表格 表格在数据展示方面非常简单,并且表现优秀,通过与CSS的结合,可以让数据变得更加美观和整齐。 单元格的特点:同行等高、同列等宽。 表格的基本语法࿱…...

C#开发的OpenRA的只读字典IReadOnlyDictionary实现
C#开发的OpenRA的只读字典IReadOnlyDictionary实现 怎么样实现一个只读字典? 这是一个高级的实现方式,一般情况下,开发人员不会考虑这个问题的。 毕竟代码里,只要小心地使用,还是不会出问题的。 但是如果在一个大型的代码,或者要求比较严格的代码里,就需要考虑这个问题了…...

mulesoft MCIA 破釜沉舟备考 2023.02.14.06
mulesoft MCIA 破釜沉舟备考 2023.02.14.06 1. A company is planning to extend its Mule APIs to the Europe region.2. A mule application is deployed to a Single Cloudhub worker and the public URL appears in Runtime Manager as the APP URL.3. An API implementati…...
Python网络爬虫 学习笔记(1)requests库爬虫
文章目录Requests库网络爬虫requests.get()的基本使用框架requests.get()的带异常处理使用框架(重点)requests库的其他方法和HTTP协议(非重点)requests.get()的可选参数网络爬虫引发的问题(非重点)常见问题…...

Splay
前言 Splay是一种维护平衡二叉树的算法。虽然它常数大,而且比较难打,但Splay十分方便,而且LCT需要用到。 约定 cnticnt_icnti:节点iii的个数 valival_ivali:节点iii的权值 sizisiz_isizi:节点iii的子…...
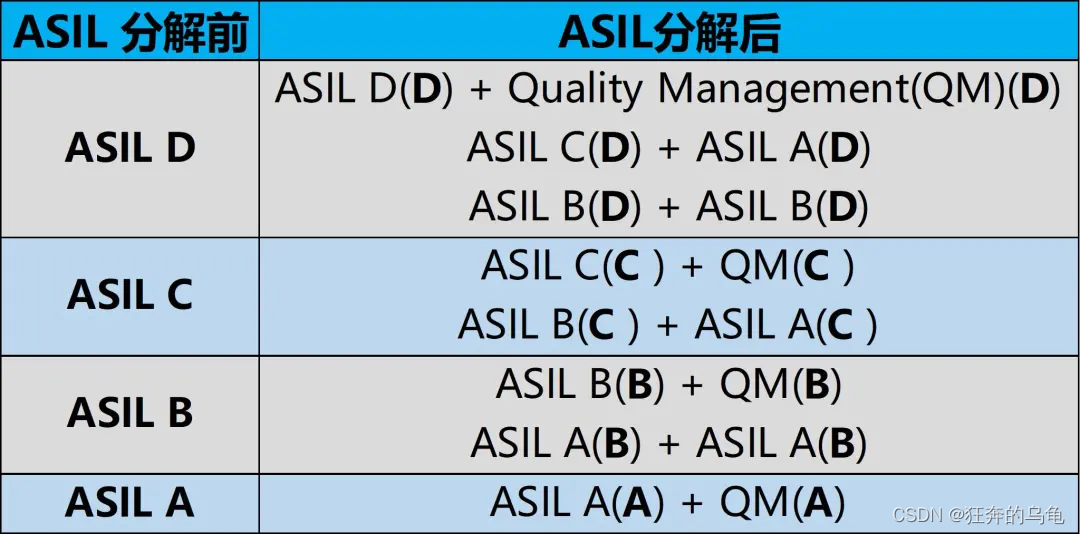
智能网联汽车ASIL安全等级如何划分
目录一、功能安全标准二、功能安全等级定义三、危险事件的确定四、ASIL安全等级五、危险分析和风险评定六、功能安全目标的分解一、功能安全标准 ISO 26262《道路车辆功能安全》脱胎于IEC 61508《电气/电子/可编程电子安全系统的功能安全》,主要定位在汽车行业&…...

Stable Diffusion 1 - 初始跑通 文字生成图片
文章目录关于 Stable DiffusionLexica代码实现安装依赖库登陆 huggingface查看 huggingface token下载模型计算生成设置宽高测试迭代次数生成多列图片关于 Stable Diffusion A latent text-to-image diffusion model Stable Diffusion 是一个文本到图像的潜在扩散模型ÿ…...
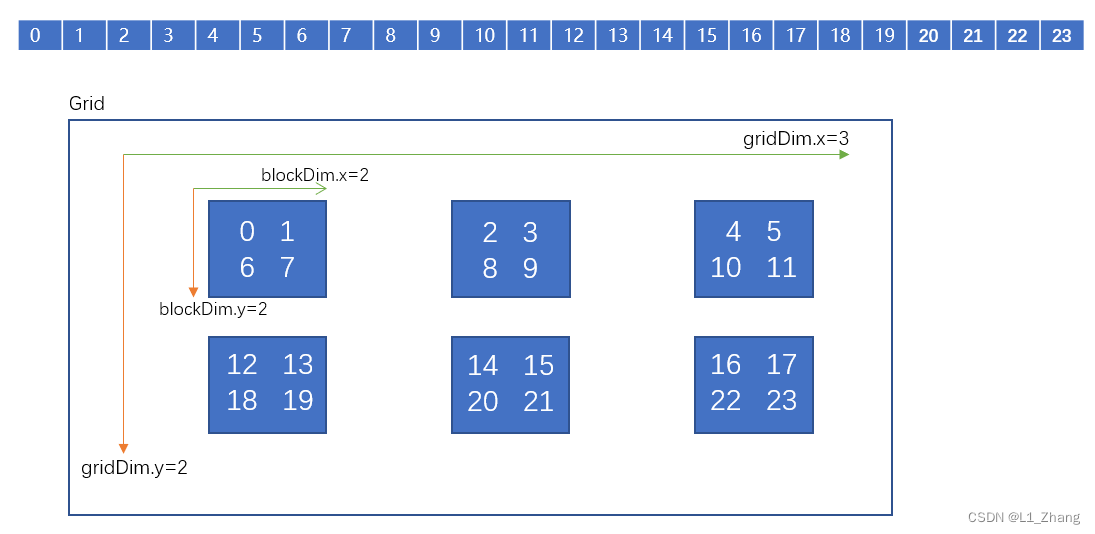
【cuda入门系列】通过代码真实打印线程ID
【cuda入门系列】通过代码真实打印线程ID1.gridDim(6,1),blockDim(4,1)2.gridDim(3,2),blockDim(2,2)【cuda入门系列之参加CUDA线上训练营】在Jetson nano本地跑 hello cuda! 【cuda入门系列之参加CUDA线上训练营】一文认识cuda基本概念 【cuda入门系列之参加CUDA线…...

【Python语言基础】——Python NumPy 数据类型
Python语言基础——Python NumPy 数据类型 文章目录 Python语言基础——Python NumPy 数据类型一、Python NumPy 数据类型一、Python NumPy 数据类型 Python 中的数据类型 默认情况下,Python 拥有以下数据类型: strings - 用于表示文本数据,文本用引号引起来。例如 “ABCD”…...

数据工程师需要具备哪些技能?
成为数据工程师需要具备哪些技能?数据工程工作存在于各个行业,在银行业、医疗保健业、大型科技企业、初创企业和其他行业找到工作机会。许多职位描述要求数据工程师、拥有数学或工程学位,但如果有合适的经验学位往往没那么重要。 大数据开发…...
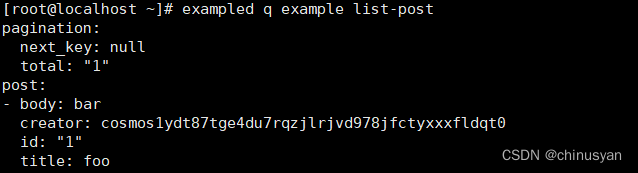
Cosmos 基础 -- Ignite CLI(二)Module basics: Blog
一、快速入门 Ignite CLI version: v0.26.1 在本教程中,我们将使用一个模块创建一个区块链,该模块允许我们从区块链中写入和读取数据。这个模块将实现创建和阅读博客文章的功能,类似于博客应用程序。最终用户将能够提交新的博客文章&#x…...

Quartz 快速入门案例,看这一篇就够了
前言 Quartz 是基于 Java 实现的任务调度框架,对任务的创建、修改、删除、触发以及监控这些操作直接提供了 api,这意味着开发人员拥有最大的操作权,也带来了更高的灵活性。 什么是任务调度? 任务调度指在将来某个特定的时间、固…...

图解LeetCode——1233. 删除子文件夹(难道:中等)
一、题目 你是一位系统管理员,手里有一份文件夹列表 folder,你的任务是要删除该列表中的所有 子文件夹,并以 任意顺序 返回剩下的文件夹。 如果文件夹 folder[i] 位于另一个文件夹 folder[j] 下,那么 folder[i] 就是 folder[j] …...

构建Telegram硬件钱包哨兵:安全远程监控加密资产
1. 项目概述:一个为Telegram设计的硬件钱包哨兵 如果你和我一样,既是一个加密货币的深度用户,又是一个Telegram的活跃分子,那你肯定遇到过这个矛盾:一方面,你希望能在Telegram这个即时通讯的“主战场”里方…...
)
从STP到RSTP:一次协议‘进化’带来的网络稳定性实战(避坑BPDU攻击与根桥抢占)
从STP到RSTP:构建高弹性企业网络的实战指南 在当今高度依赖网络连接的业务环境中,即使是几秒钟的网络中断也可能导致严重的业务损失。想象一下在线教育平台正在直播重要课程,或者金融网点处理实时交易时突然遭遇网络震荡——这种场景下&#…...

OpenCore Legacy Patcher终极指南:老Mac升级新系统的完整教程
OpenCore Legacy Patcher终极指南:老Mac升级新系统的完整教程 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher OpenCore Legacy Patcher是一款免费…...

如何高效配置ComfyUI-Manager:3个专业技巧让你事半功倍
如何高效配置ComfyUI-Manager:3个专业技巧让你事半功倍 【免费下载链接】ComfyUI-Manager ComfyUI-Manager is an extension designed to enhance the usability of ComfyUI. It offers management functions to install, remove, disable, and enable various cust…...

5步实现茅台自动预约:告别手动抢购的智能解决方案
5步实现茅台自动预约:告别手动抢购的智能解决方案 【免费下载链接】campus-imaotai i茅台app自动预约,每日自动预约,支持docker一键部署(本项目不提供成品,使用的是已淘汰的算法) 项目地址: https://gitc…...
)
SITS2026摄影服务背后的数据真相:单日处理17.8TB视觉流、327台终端协同、端到端延迟压至≤83ms(附完整时序拓扑图)
更多请点击: https://intelliparadigm.com 第一章:SITS2026摄影服务背后的数据真相:单日处理17.8TB视觉流、327台终端协同、端到端延迟压至≤83ms(附完整时序拓扑图) SITS2026并非传统影楼系统,而是一套面…...

从零开始:使用USBASP编程器为Atmega328P芯片烧录Arduino Bootloader
1. 认识Bootloader与硬件准备 当你拿到一块全新的Atmega328P芯片时,它就像一张白纸,没有任何程序。这时候就需要Bootloader——这个小程序相当于芯片的"启动管家",负责接收来自Arduino IDE的程序指令。我刚开始玩Arduino时也纳闷&a…...

Excel平均值函数全解析:AVERAGE、AVERAGEIF、AVERAGEIFS与AVERAGEA实战选型指南
1. 为什么AVERAGE()是Excel里最常被低估、却最该先吃透的核心函数在Excel里,我见过太多人一上来就猛学VLOOKUP、INDEXMATCH甚至Power Query,结果连自己算出来的平均值为什么比预期低20%都搞不清。不是他们不努力,而是跳过了最基础却最易踩坑的…...

技术深度解析:NxNandManager——Nintendo Switch存储管理核心功能与加密架构价值主张
技术深度解析:NxNandManager——Nintendo Switch存储管理核心功能与加密架构价值主张 【免费下载链接】NxNandManager Nintendo Switch NAND management tool : explore, backup, restore, mount, resize, create emunand, etc. (Windows) 项目地址: https://gitc…...

R6900P/R7000P刷梅林固件前必读:商家定制版与官方版的区别,以及如何安全备份防变砖
R6900P/R7000P刷梅林固件完全指南:从风险规避到实战操作 在路由器玩家圈子里,刷第三方固件一直是提升设备性能的热门选择。特别是对于网件R6900P和R7000P这类中高端机型,梅林固件以其稳定性与丰富功能吸引了大量用户。但不同于官方固件的&quo…...