hive数据存储格式
1、Hive存储数据的格式如下:
| 存储数据格式 | 存储形式 |
| TEXTFILE | 行式存储 |
| SEQUENCEFILE | 行式存储 |
| ORC | 列式存储 |
| PARQUET | 列式存储 |
2、行式存储和列式存储
解释:
1、上图左面为逻辑表;右面第一个为行式存储,第二个温列式存储;
2、行存储的特点: 查询满足条件的一整行数据的时候,行存储只需要找到其中一个值,其余的值都在相邻地方。列存储则需要去每个聚集的字段找到对应的每个列的值,所以此时行存储查询的速度更快。
3、列存储的特点: 因为每个字段的数据聚集存储,在查询只需要少数几个字段的时候,能大大减少读取的数据量;每个字段的数据类型一定是相同的,列式存储可以针对性的设计更好的设计压缩算法。
行式存储优点:
1、相关的数据保存在一起,比较符合面向对象的思维,因为一行数据就是一条记录
2、方便进行insert或update操作
行式存储缺点:
1、如果仅需要查询几列数据,它会把整行数据都读取出来,不能跳过不必要的列读取
2、由于每一行中列的数据类型不一致,导致不容易获得一个极高的压缩比(空间利用率不高)
列式存储优点:
1、查询时,只有涉及到的列才会被查询,可以跳过不必要的列查询
2、高效的压缩率,不仅节省储存空间也节省计算内存和CPU
3、任何列都可以作为索引
列式存储缺点:
1、不适合进行insert或update操作
2、不适合扫描小量的数据
3、存储格式详解:
TEXTFILE格式
默认格式,数据不做压缩,磁盘开销大,数据解析开销大。可结合Gzip、Bzip2使用(系统自动检查,执行查询时自动解压),但使用这种方式,hive不会对数据进行切分,从而无法对数据进行并行操作。
ORC格式
Orc (Optimized Row Columnar)是hive 0.11版里引入的新的存储格式。
可以看到每个Orc文件由1个或多个stripe组成,每个stripe250MB大小,这个Stripe实际相当于RowGroup概念,不过大小由4MB->250MB,这样能提升顺序读的吞吐率。每个Stripe里有三部分组成,分别是Index Data,Row Data,Stripe Footer:
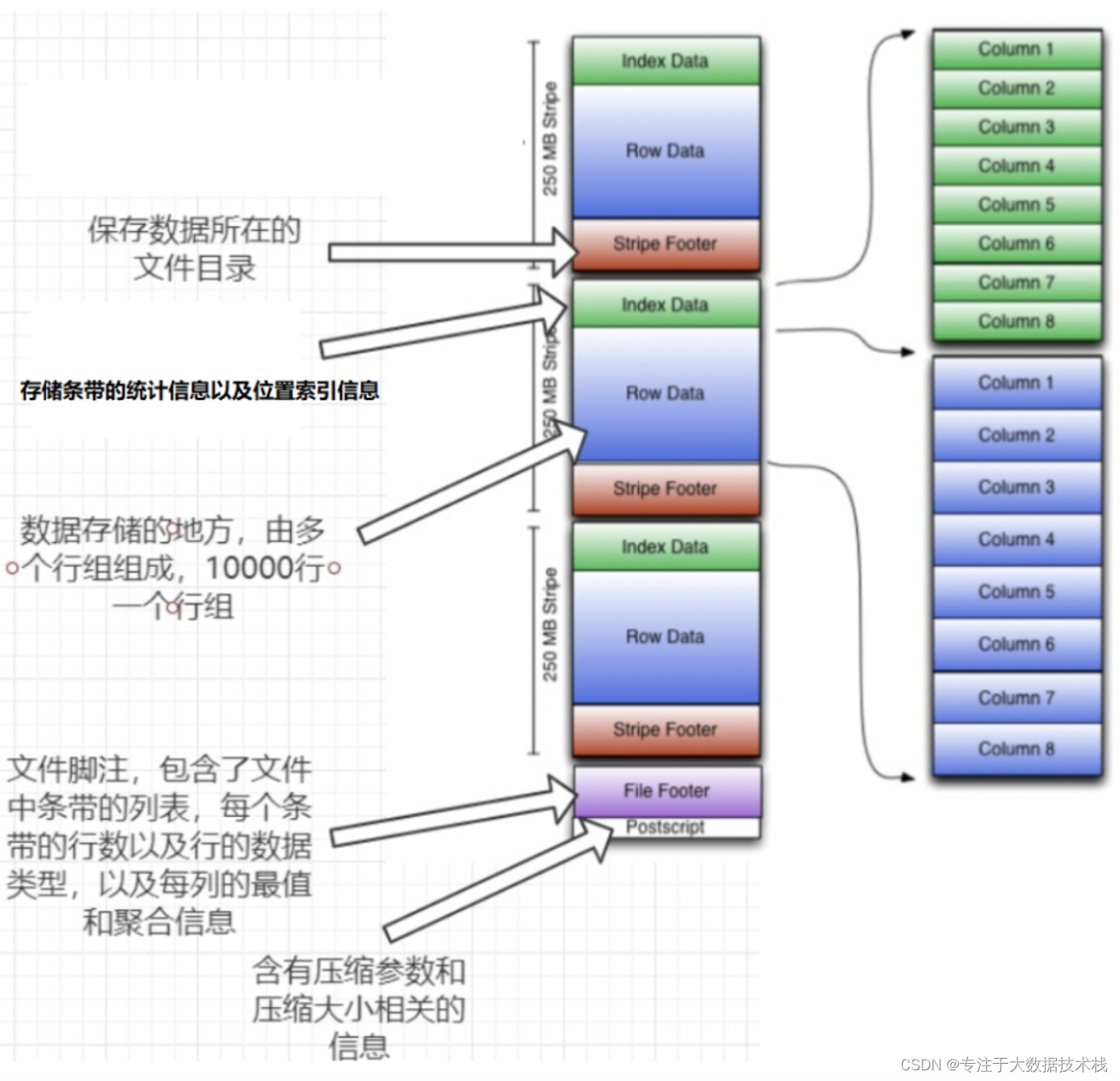
一个ORC文件可以分为若干个Stripe,一个stripe可以分为三个部分:
Index Data:一个轻量级的index,默认是每隔1W行做一个索引(目录)。这里做的索引只是记录某行的各字段在Row Data中的offset
Row Data:存储具体的数据,先取部分行,然后对这些行按列进行存储。对每个列进行了编码,分成多个Stream来存储。
Strip Footer:存储各个stripe的元数据信息
每个ORC文件文件有一个File Footer,存储的是每个Stripe的行数以及Stripe中每个Column的数据类型信息等;
每个ORC文件文件的尾部是一个Post Script,这里面记录了整个文件的压缩类型以及File Footer的长度信息等。
在读取文件时,会seek到文件尾部读Post Script,从里面解析到File Footer长度,再读FileFooter,从里面解析到各个Stripe信息,再读各个Stripe,即从后往前读。
parquet
面向分析型业务的列式存储格式,由Twitter和Cloudera合作开发,2015年5月从Apache的孵化器里毕业成为Apache顶级项目
parquet文件是以二进制方式存储的,所以是不可以直接读取。文件中包括该文件的数据和元数据,因此Parquet格式文件是自解析的
通常情况下,在存储Parquet数据的时候会按照Block大小设置行组的大小,由于一般情况下每一个Mapper任务处理数据的最小单位是一个Block,这样可以把每一个行组由一个Mapper任务处理,增大任务执行并行度。
ORC和Parquet区别
- ORC存储格式比Parquet压缩率更好
- Parquet格式对嵌套列的支持比较友好,可以只查询某个列中的嵌套子列,而不用查询其他的子列。
- ORC支持ACID事务,而Parquet目前还不支持。
问题:
1、Zlib和Snappy两种压缩算法的对比?
Zlib 压缩率 高, 解压速度 慢
Snappy则与Zlib相反,按照业务情况来选择使用
2、什么是压缩率?
压缩率(Compression rate),描述压缩文件的效果名,是文件压缩后的大小与压缩前的大小之比,例如:把100m的文件压缩后是90m,压缩率为90/100*100%=90%,压缩率一般是越小越好,但是压得越小,解压时间越长。
3、什么是解压速度?
解压速度是指将一个通过软件压缩的文件释放到目标地址,恢复为压缩前文件的速度。
相关文章:
hive数据存储格式
1、Hive存储数据的格式如下: 存储数据格式存储形式TEXTFILE行式存储SEQUENCEFILE行式存储ORC列式存储PARQUET列式存储 2、行式存储和列式存储 解释: 1、上图左面为逻辑表;右面第一个为行式存储,第二个温列式存储; …...

mysql数据库备份与恢复
mysql数据备份: 数据备份方式 物理备份: 冷备:.冷备份指在数据库关闭后,进行备份,适用于所有模式的数据库热备:一般用于保证服务正常不间断运行,用两台机器作为服务机器,一台用于实际数据库操作应用,另外…...

《NFL橄榄球》:辛辛那提猛虎·橄榄1号位
辛辛那提猛虎(英语:Cincinnati Bengals),又译辛辛那提孟加拉虎,是一支职业美式橄榄球球队位于俄亥俄州辛辛那提。他们现时为美联北区的其中一支球队,他们在1968年加入美国橄榄球联合会,并在1970…...

2、线程、块和网格
目录一、线程、块、网格概念二、代码分析2.1 打印第一个线程块的第一线程2.2 打印当前线程块的当前线程2.3 获取当前是第几个线程一、线程、块、网格概念 CUDA的软件架构由网格(Grid)、线程块(Block)和线程(Thread&am…...
C++ 算法主题系列之贪心算法的贪心之术
1. 前言 贪心算法是一种常见算法。是以人性之念的算法,面对众多选择时,总是趋利而行。 因贪心算法以眼前利益为先,故总能保证当前的选择是最好的,但无法时时保证最终的选择是最好的。当然,在局部利益最大化的同时&am…...
请注意,PDF正在传播恶意软件
据Bleeping Computer消息,安全研究人员发现了一种新型的恶意软件传播活动,攻击者通过使用PDF附件夹带恶意的Word文档,从而使用户感染恶意软件。 类似的恶意软件传播方式在以往可不多见。在大多数人的印象中,电子邮件是夹带加载了恶…...

【Kubernetes】【二】环境搭建 环境初始化
本章节主要介绍如何搭建kubernetes的集群环境 环境规划 集群类型 kubernetes集群大体上分为两类:一主多从和多主多从。 一主多从:一台Master节点和多台Node节点,搭建简单,但是有单机故障风险,适合用于测试环境多主…...
)
Python:每日一题之发现环(DFS)
题目描述 小明的实验室有 N 台电脑,编号 1⋯N。原本这 N 台电脑之间有 N−1 条数据链接相连,恰好构成一个树形网络。在树形网络上,任意两台电脑之间有唯一的路径相连。 不过在最近一次维护网络时,管理员误操作使得某两台电脑之间…...

C++设计模式(14)——享元模式
亦称: 缓存、Cache、Flyweight 意图 享元模式是一种结构型设计模式, 它摒弃了在每个对象中保存所有数据的方式, 通过共享多个对象所共有的相同状态, 让你能在有限的内存容量中载入更多对象。 问题 假如你希望在长时间工作后放…...

SpringCloud之Eureka客户端服务启动报Cannot execute request on any known server解决
项目场景: 在练习SpringCloud时,Eureka客户端(client)出现报错:Cannot execute request on any known server 问题描述 正常启动SpringCloud的Server端和Client端,结果发现Server端的控制台有个Error提示,如下&#…...

从零开始搭建kubernetes集群环境(虚拟机/kubeadm方式)
文章目录1 Kubernetes简介(k8s)2 安装实战2.1 主机安装并初始化2.2 安装docker2.3 安装Kubernetes组件2.4 准备集群镜像2.5 集群初始化2.6 安装flannel网络插件3 部署nginx 测试3.1 创建一个nginx服务3.2 暴漏端口3.3 查看服务3.4 测试服务1 Kubernetes简…...
【零基础入门前端系列】—表格(五)
【零基础入门前端系列】—表格(五) 一、表格 表格在数据展示方面非常简单,并且表现优秀,通过与CSS的结合,可以让数据变得更加美观和整齐。 单元格的特点:同行等高、同列等宽。 表格的基本语法࿱…...

C#开发的OpenRA的只读字典IReadOnlyDictionary实现
C#开发的OpenRA的只读字典IReadOnlyDictionary实现 怎么样实现一个只读字典? 这是一个高级的实现方式,一般情况下,开发人员不会考虑这个问题的。 毕竟代码里,只要小心地使用,还是不会出问题的。 但是如果在一个大型的代码,或者要求比较严格的代码里,就需要考虑这个问题了…...

mulesoft MCIA 破釜沉舟备考 2023.02.14.06
mulesoft MCIA 破釜沉舟备考 2023.02.14.06 1. A company is planning to extend its Mule APIs to the Europe region.2. A mule application is deployed to a Single Cloudhub worker and the public URL appears in Runtime Manager as the APP URL.3. An API implementati…...
Python网络爬虫 学习笔记(1)requests库爬虫
文章目录Requests库网络爬虫requests.get()的基本使用框架requests.get()的带异常处理使用框架(重点)requests库的其他方法和HTTP协议(非重点)requests.get()的可选参数网络爬虫引发的问题(非重点)常见问题…...

Splay
前言 Splay是一种维护平衡二叉树的算法。虽然它常数大,而且比较难打,但Splay十分方便,而且LCT需要用到。 约定 cnticnt_icnti:节点iii的个数 valival_ivali:节点iii的权值 sizisiz_isizi:节点iii的子…...
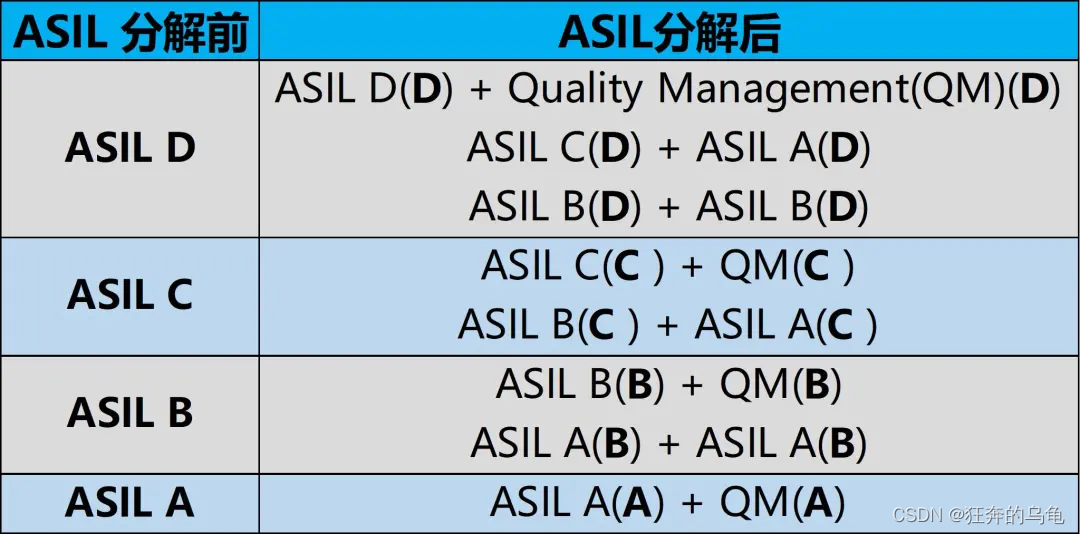
智能网联汽车ASIL安全等级如何划分
目录一、功能安全标准二、功能安全等级定义三、危险事件的确定四、ASIL安全等级五、危险分析和风险评定六、功能安全目标的分解一、功能安全标准 ISO 26262《道路车辆功能安全》脱胎于IEC 61508《电气/电子/可编程电子安全系统的功能安全》,主要定位在汽车行业&…...

Stable Diffusion 1 - 初始跑通 文字生成图片
文章目录关于 Stable DiffusionLexica代码实现安装依赖库登陆 huggingface查看 huggingface token下载模型计算生成设置宽高测试迭代次数生成多列图片关于 Stable Diffusion A latent text-to-image diffusion model Stable Diffusion 是一个文本到图像的潜在扩散模型ÿ…...
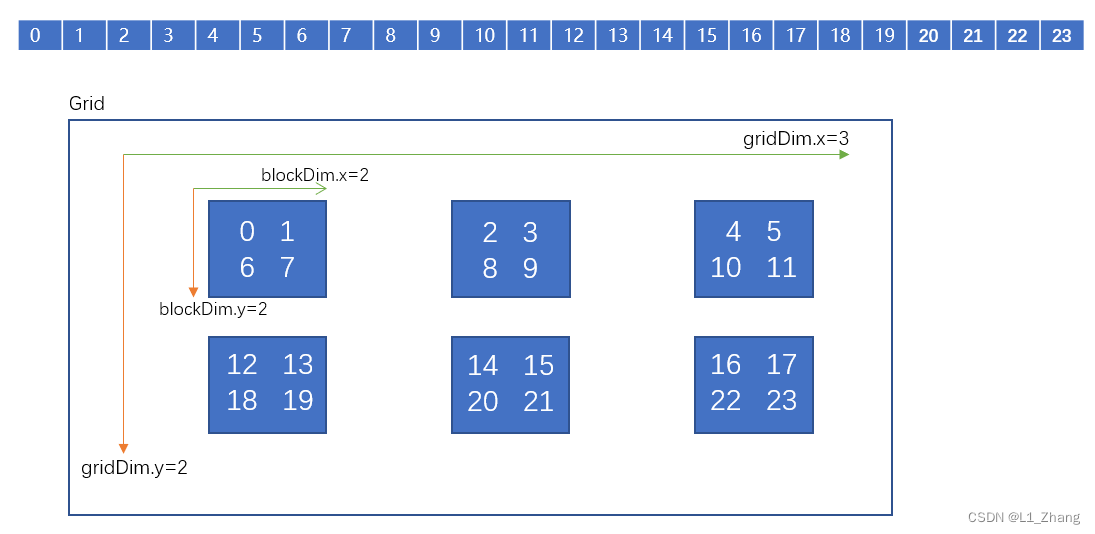
【cuda入门系列】通过代码真实打印线程ID
【cuda入门系列】通过代码真实打印线程ID1.gridDim(6,1),blockDim(4,1)2.gridDim(3,2),blockDim(2,2)【cuda入门系列之参加CUDA线上训练营】在Jetson nano本地跑 hello cuda! 【cuda入门系列之参加CUDA线上训练营】一文认识cuda基本概念 【cuda入门系列之参加CUDA线…...

【Python语言基础】——Python NumPy 数据类型
Python语言基础——Python NumPy 数据类型 文章目录 Python语言基础——Python NumPy 数据类型一、Python NumPy 数据类型一、Python NumPy 数据类型 Python 中的数据类型 默认情况下,Python 拥有以下数据类型: strings - 用于表示文本数据,文本用引号引起来。例如 “ABCD”…...
)
手把手教你用S7TCP驱动搞定西门子S7-200/300与Intouch的以太网通讯(保姆级图文)
西门子S7-200/300与Intouch以太网通讯全流程实战指南 工业自动化领域中,西门子PLC与上位机软件的稳定通讯是项目成功的关键环节。本文将带您从零开始,逐步完成西门子S7-200/300系列PLC与Intouch软件的以太网通讯配置。不同于简单的步骤罗列,我…...

使用Mergoo开源库实现LLM专家混合:原理、配置与实战指南
1. 项目概述:Mergoo,一个专为LLM专家融合而生的开源库在大型语言模型(LLM)的微调与应用实践中,我们常常面临一个经典困境:是训练一个“通才”模型来应对所有任务,还是为每个特定领域(…...

AI/ML学生持续参与意愿研究:从影响因素到测量模型
1. 项目概述:为什么我们要关心“持续参与意愿”?在机器学习与人工智能这个领域待了十几年,我见过太多满怀热情入行的学生,从最初的“我要改变世界”到后来的“这行太卷了,我还是考公吧”。这个现象背后,其实…...

XUnity翻译器:3步实现游戏自动汉化的完整指南
XUnity翻译器:3步实现游戏自动汉化的完整指南 【免费下载链接】XUnity.AutoTranslator 项目地址: https://gitcode.com/gh_mirrors/xu/XUnity.AutoTranslator 还在为外语游戏中的生涩文本而烦恼吗?是否曾经因为语言障碍而错过精彩的游戏剧情&…...

CANN Runtime进程间通信
# 进程间通信 【免费下载链接】runtime 本项目提供CANN运行时组件和维测功能组件。 项目地址: https://gitcode.com/cann/runtime 由某个主机线程创建的任意设备内存、Event资源或Notify资源,都可以在同一进程内被该进程中的其他线程直接引用。但…...

ChatGPT情感分析能力评测:零样本表现、小样本学习与实战应用
1. 项目概述:ChatGPT作为情感分析器的能力边界探索最近,但凡关注自然语言处理(NLP)领域的朋友,恐怕都绕不开ChatGPT这个名字。它展现出的通用对话和任务解决能力让人惊叹,但作为一个在一线搞了多年情感分析…...

保时捷裁撤重整数字化研发资源;特斯拉电动重卡的电池参数曝光;小米汽车调整人事筹备海外业务
保时捷裁撤Car-IT部门整合数字化研发资源牛喀网获悉,保时捷正式裁撤了三年前成立的Car-IT专属部门,将其负责的车联网、车机系统等数字化业务,重新整合回集团的核心研发部门,该部门的负责人SajjadKhan也将退出董事会。技术层面&…...
:自动生成实验报告,训练完成后输出指标表和对比图)
Pytorch图像去噪实战(五十七):自动生成实验报告,训练完成后输出指标表和对比图
Pytorch图像去噪实战(五十七):自动生成实验报告,训练完成后输出指标表和对比图 一、问题场景:训练完模型,还要手动整理结果 每次图像去噪训练结束后,通常都要做这些事: 找最佳模型 跑验证集 计算 PSNR / SSIM 保存对比图 整理表格 写实验记录 如果每次都手动做,很浪费…...

基因数据交易模拟平台:用金融市场模型探索基因组学动态分析
1. 项目概述:一个基因数据交易与分析的实验平台最近在GitHub上看到一个挺有意思的项目,叫“genome-trader-lab”。光看名字,你可能会觉得有点跨界——“genome”(基因组)和“trader”(交易者)这…...

Rust内存布局深度解析:从栈到堆的高效管理
Rust内存布局深度解析:从栈到堆的高效管理 引言 内存布局是理解Rust内存安全和性能的关键。与Python的自动内存管理不同,Rust通过编译时检查和显式的内存布局控制,实现了零成本抽象和内存安全。 本文将深入探讨Rust的内存布局原理,…...