RabbitMQ --- 惰性队列、MQ集群
一、惰性队列
1.1、消息堆积问题
当生产者发送消息的速度超过了消费者处理消息的速度,就会导致队列中的消息堆积,直到队列存储消息达到上限。之后发送的消息就会成为死信,可能会被丢弃,这就是消息堆积问题。
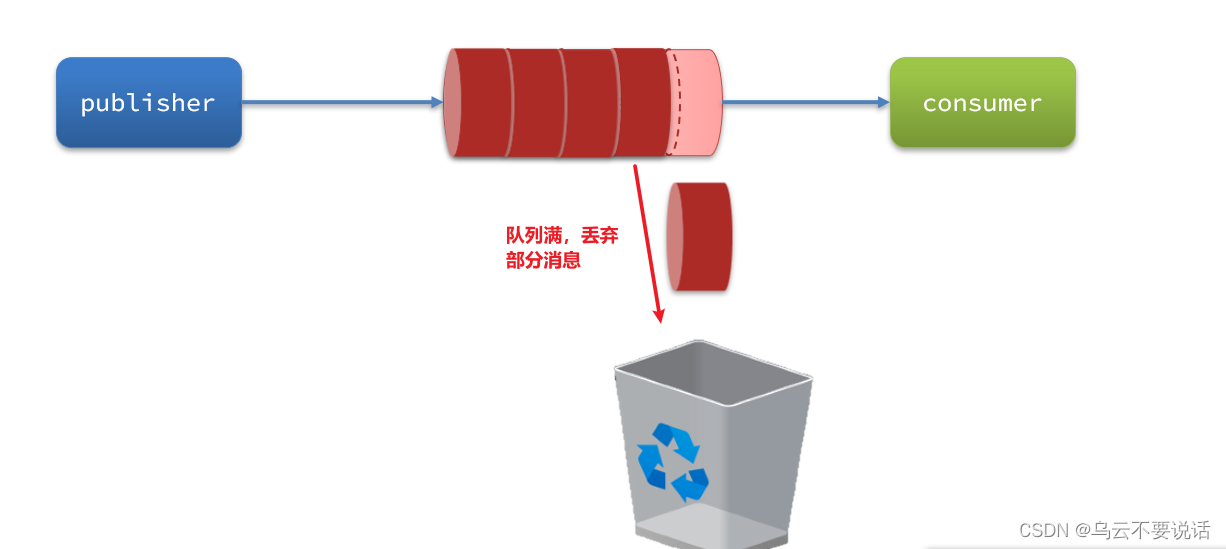
解决消息堆积有三种思路:
-
增加更多消费者,提高消费速度。也就是我们之前说的work queue模式
-
在消费者内开启线程池加快消息处理速度
-
扩大队列容积,提高堆积上限
要提升队列容积,把消息保存在内存中显然是不行的。
1.2、惰性队列
从RabbitMQ的3.6.0版本开始,就增加了Lazy Queues的概念,也就是惰性队列。惰性队列的特征如下:
-
接收到消息后直接存入磁盘而非内存
-
消费者要消费消息时才会从磁盘中读取并加载到内存
-
支持数百万条的消息存储
1.2.1、基于命令行设置lazy-queue
而要设置一个队列为惰性队列,只需要在声明队列时,指定x-queue-mode属性为lazy即可。可以通过命令行将一个运行中的队列修改为惰性队列:
rabbitmqctl set_policy Lazy "^lazy-queue$" '{"queue-mode":"lazy"}' --apply-to queues 命令解读:
-
rabbitmqctl:RabbitMQ的命令行工具 -
set_policy:添加一个策略 -
Lazy:策略名称,可以自定义 -
"^lazy-queue$":用正则表达式匹配队列的名字 -
'{"queue-mode":"lazy"}':设置队列模式为lazy模式 -
--apply-to queues:策略的作用对象,是所有的队列
1.2.2、基于@Bean声明lazy-queue

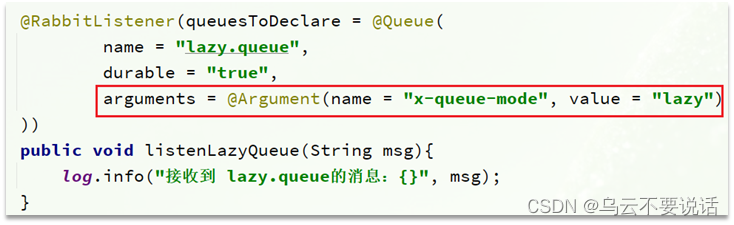
1.2.3、基于@RabbitListener声明LazyQueue
1.3、总结
消息堆积问题的解决方案?
-
队列上绑定多个消费者,提高消费速度
-
使用惰性队列,可以再mq中保存更多消息
惰性队列的优点有哪些?
-
基于磁盘存储,消息上限高
-
没有间歇性的page-out,性能比较稳定
惰性队列的缺点有哪些?
-
基于磁盘存储,消息时效性会降低
-
性能受限于磁盘的IO
二、MQ集群
2.1、集群分类
RabbitMQ的是基于Erlang语言编写,而Erlang又是一个面向并发的语言,天然支持集群模式。RabbitMQ的集群有两种模式:
- 普通集群:是一种分布式集群,将队列分散到集群的各个节点,从而提高整个集群的并发能力。
- 镜像集群:是一种主从集群,普通集群的基础上,添加了主从备份功能,提高集群的数据可用性。
镜像集群虽然支持主从,但主从同步并不是强一致的,某些情况下可能有数据丢失的风险。因此在RabbitMQ的3.8版本以后,推出了新的功能:仲裁队列来代替镜像集群,底层采用Raft协议确保主从的数据一致性。
2.2、普通集群
2.2.1、集群结构和特征
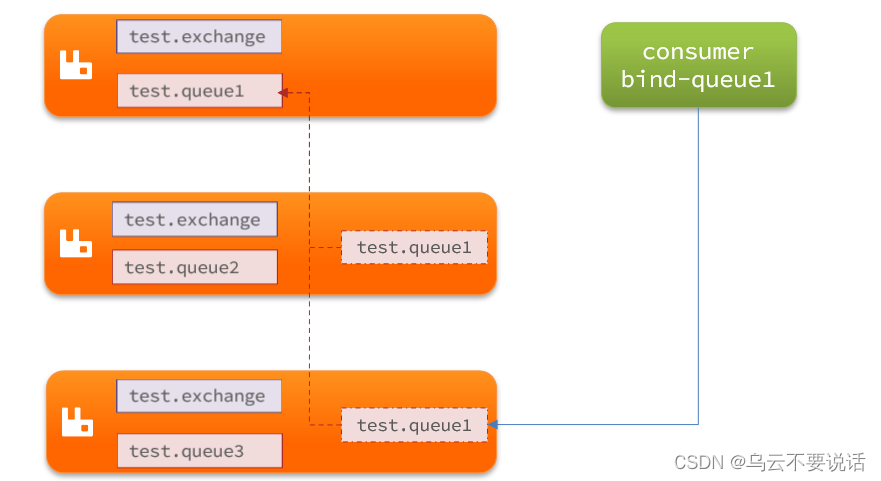
普通集群,或者叫标准集群(classic cluster),具备下列特征:
-
会在集群的各个节点间共享部分数据,包括:交换机、队列元信息。不包含队列中的消息。
-
当访问集群某节点时,如果队列不在该节点,会从数据所在节点传递到当前节点并返回
-
队列所在节点宕机,队列中的消息就会丢失
结构如图:
2.2.2、部署
集群分类
在RabbitMQ的官方文档中,讲述了两种集群的配置方式:
普通模式:普通模式集群不进行数据同步,每个MQ都有自己的队列、数据信息(其它元数据信息如交换机等会同步)。例如我们有2个MQ:mq1,和mq2,如果你的消息在mq1,而你连接到了mq2,那么mq2会去mq1拉取消息,然后返回给你。如果mq1宕机,消息就会丢失。
镜像模式:与普通模式不同,队列会在各个mq的镜像节点之间同步,因此你连接到任何一个镜像节点,均可获取到消息。而且如果一个节点宕机,并不会导致数据丢失。不过,这种方式增加了数据同步的带宽消耗。
我们先来看普通模式集群,我们的计划部署3节点的mq集群:
主机名 控制台端口 amqp通信端口 mq1 8081 ---> 15672 8071 ---> 5672 mq2 8082 ---> 15672 8072 ---> 5672 mq3 8083 ---> 15672 8073 ---> 5672 集群中的节点标示默认都是:
rabbit@[hostname],因此以上三个节点的名称分别为:
rabbit@mq1
rabbit@mq2
rabbit@mq3
获取cookie
RabbitMQ底层依赖于Erlang,而Erlang虚拟机就是一个面向分布式的语言,默认就支持集群模式。集群模式中的每个RabbitMQ 节点使用 cookie 来确定它们是否被允许相互通信。
要使两个节点能够通信,它们必须具有相同的共享秘密,称为Erlang cookie。cookie 只是一串最多 255 个字符的字母数字字符。
每个集群节点必须具有相同的 cookie。实例之间也需要它来相互通信。
我们先在之前启动的mq容器中获取一个cookie值,作为集群的cookie。执行下面的命令:
docker exec -it mq cat /var/lib/rabbitmq/.erlang.cookie可以看到cookie值如下:
FXZMCVGLBIXZCDEMMVZA接下来,停止并删除当前的mq容器,我们重新搭建集群。
docker rm -f mq

准备集群配置
在/tmp目录新建一个配置文件 rabbitmq.conf:
cd /tmp # 创建文件 touch rabbitmq.conf文件内容如下:
loopback_users.guest = false listeners.tcp.default = 5672 cluster_formation.peer_discovery_backend = rabbit_peer_discovery_classic_config cluster_formation.classic_config.nodes.1 = rabbit@mq1 cluster_formation.classic_config.nodes.2 = rabbit@mq2 cluster_formation.classic_config.nodes.3 = rabbit@mq3再创建一个文件,记录cookie
cd /tmp # 创建cookie文件 touch .erlang.cookie # 写入cookie echo "FXZMCVGLBIXZCDEMMVZQ" > .erlang.cookie # 修改cookie文件的权限 chmod 600 .erlang.cookie准备三个目录,mq1、mq2、mq3:
cd /tmp # 创建目录 mkdir mq1 mq2 mq3然后拷贝rabbitmq.conf、cookie文件到mq1、mq2、mq3:
# 进入/tmp cd /tmp # 拷贝 cp rabbitmq.conf mq1 cp rabbitmq.conf mq2 cp rabbitmq.conf mq3 cp .erlang.cookie mq1 cp .erlang.cookie mq2 cp .erlang.cookie mq3
启动集群
创建一个网络:
docker network create mq-netdocker volume create运行命令
docker run -d --net mq-net \ -v ${PWD}/mq1/rabbitmq.conf:/etc/rabbitmq/rabbitmq.conf \ -v ${PWD}/.erlang.cookie:/var/lib/rabbitmq/.erlang.cookie \ -e RABBITMQ_DEFAULT_USER=mq \ -e RABBITMQ_DEFAULT_PASS=123321 \ --name mq1 \ --hostname mq1 \ -p 8071:5672 \ -p 8081:15672 \ rabbitmq:3.8-managementdocker run -d --net mq-net \ -v ${PWD}/mq2/rabbitmq.conf:/etc/rabbitmq/rabbitmq.conf \ -v ${PWD}/.erlang.cookie:/var/lib/rabbitmq/.erlang.cookie \ -e RABBITMQ_DEFAULT_USER=mq \ -e RABBITMQ_DEFAULT_PASS=123321 \ --name mq2 \ --hostname mq2 \ -p 8072:5672 \ -p 8082:15672 \ rabbitmq:3.8-managementdocker run -d --net mq-net \ -v ${PWD}/mq3/rabbitmq.conf:/etc/rabbitmq/rabbitmq.conf \ -v ${PWD}/.erlang.cookie:/var/lib/rabbitmq/.erlang.cookie \ -e RABBITMQ_DEFAULT_USER=mq \ -e RABBITMQ_DEFAULT_PASS=123321 \ --name mq3 \ --hostname mq3 \ -p 8073:5672 \ -p 8083:15672 \ rabbitmq:3.8-management
测试
在mq1这个节点上添加一个队列:
如图,在mq2和mq3两个控制台也都能看到:
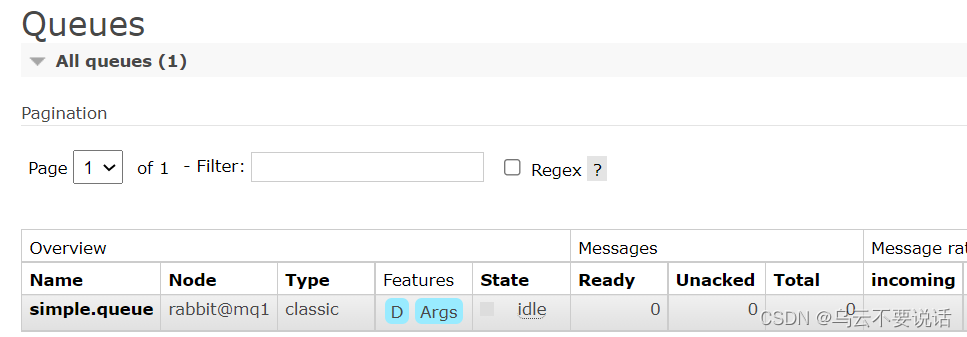
数据共享测试
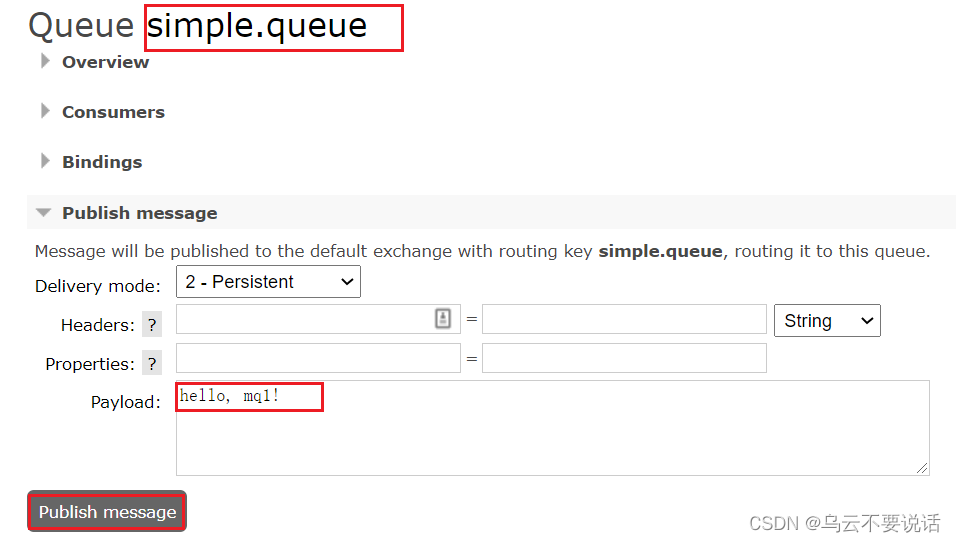
点击这个队列,进入管理页面:
然后利用控制台发送一条消息到这个队列:
在mq2、mq3上都能看到这条消息:

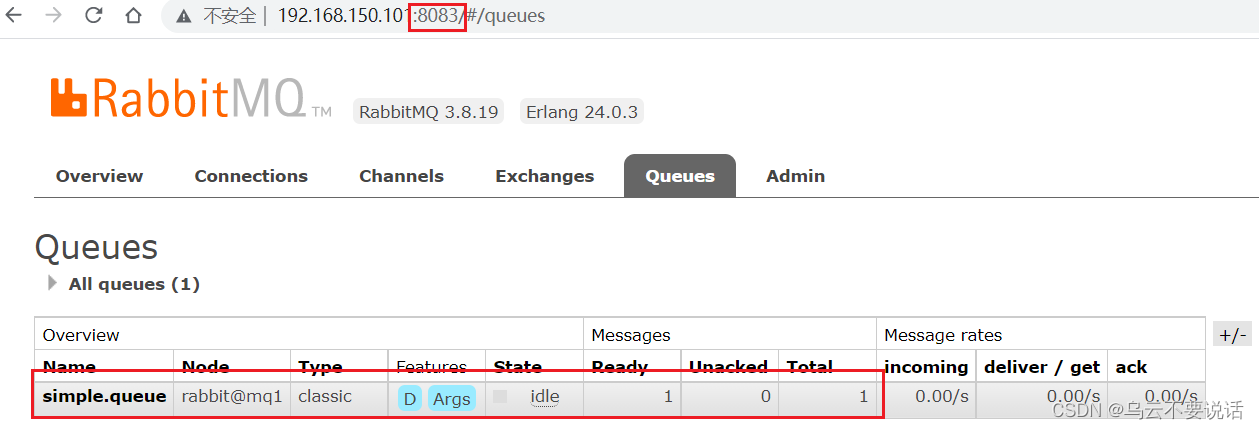
可用性测试
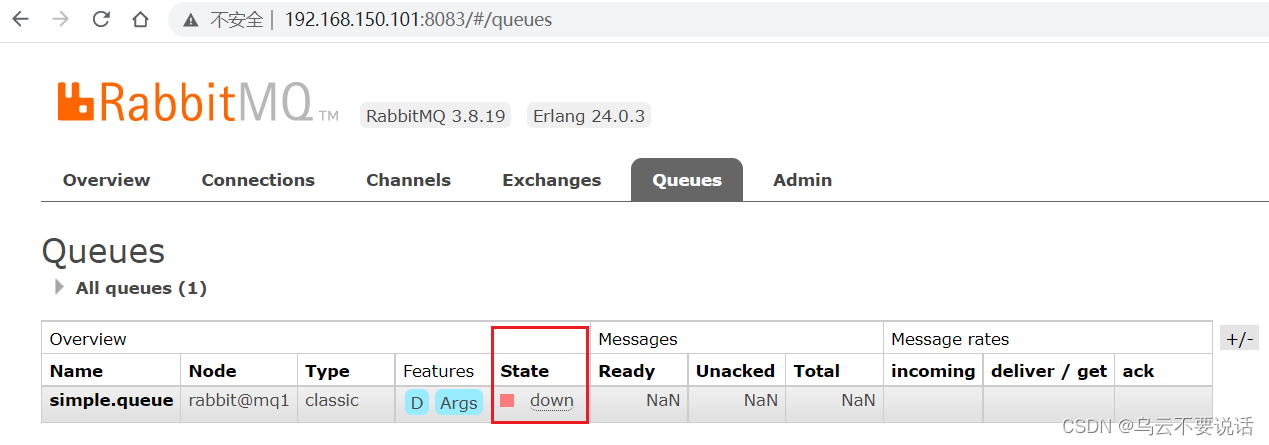
我们让其中一台节点mq1宕机:
docker stop mq1
说明数据并没有拷贝到mq2和mq3。
2.3、镜像集群
2.3.1、集群结构和特征
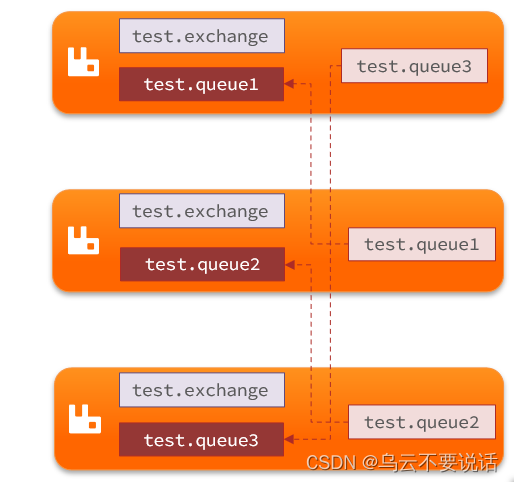
镜像集群:本质是主从模式,具备下面的特征:
-
交换机、队列、队列中的消息会在各个mq的镜像节点之间同步备份。
-
创建队列的节点被称为该队列的主节点,备份到的其它节点叫做该队列的镜像节点。
-
一个队列的主节点可能是另一个队列的镜像节点
-
所有操作都是主节点完成,然后同步给镜像节点
-
主宕机后,镜像节点会替代成新的主
结构如图:
2.3.2、部署
在刚刚的案例中,一旦创建队列的主机宕机,队列就会不可用。不具备高可用能力。如果要解决这个问题,必须使用官方提供的镜像集群方案。
官方文档地址:Classic Queue Mirroring — RabbitMQ
镜像模式的特征
默认情况下,队列只保存在创建该队列的节点上。而镜像模式下,创建队列的节点被称为该队列的主节点,队列还会拷贝到集群中的其它节点,也叫做该队列的镜像节点。
但是,不同队列可以在集群中的任意节点上创建,因此不同队列的主节点可以不同。甚至,一个队列的主节点可能是另一个队列的镜像节点。
用户发送给队列的一切请求,例如发送消息、消息回执默认都会在主节点完成,如果是从节点接收到请求,也会路由到主节点去完成。镜像节点仅仅起到备份数据作用。
当主节点接收到消费者的ACK时,所有镜像都会删除节点中的数据。
总结如下:
镜像队列结构是一主多从(从就是镜像)
所有操作都是主节点完成,然后同步给镜像节点
主宕机后,镜像节点会替代成新的主(如果在主从同步完成前,主就已经宕机,可能出现数据丢失)
不具备负载均衡功能,因为所有操作都会有主节点完成(但是不同队列,其主节点可以不同,可以利用这个提高吞吐量)
镜像模式的配置
镜像模式的配置有3种模式:
ha-mode ha-params 效果 准确模式exactly 队列的副本量count 集群中队列副本(主服务器和镜像服务器之和)的数量。count如果为1意味着单个副本:即队列主节点。count值为2表示2个副本:1个队列主和1个队列镜像。换句话说:count = 镜像数量 + 1。如果群集中的节点数少于count,则该队列将镜像到所有节点。如果有集群总数大于count+1,并且包含镜像的节点出现故障,则将在另一个节点上创建一个新的镜像。 all (none) 队列在群集中的所有节点之间进行镜像。队列将镜像到任何新加入的节点。镜像到所有节点将对所有群集节点施加额外的压力,包括网络I / O,磁盘I / O和磁盘空间使用情况。推荐使用exactly,设置副本数为(N / 2 +1)。 nodes node names 指定队列创建到哪些节点,如果指定的节点全部不存在,则会出现异常。如果指定的节点在集群中存在,但是暂时不可用,会创建节点到当前客户端连接到的节点。 这里我们以rabbitmqctl命令作为案例来讲解配置语法
exactly模式
rabbitmqctl set_policy ha-two "^two\." '{"ha-mode":"exactly","ha-params":2,"ha-sync-mode":"automatic"}'
rabbitmqctl set_policy:固定写法
ha-two:策略名称,自定义
"^two\.":匹配队列的正则表达式,符合命名规则的队列才生效,这里是任何以two.开头的队列名称
'{"ha-mode":"exactly","ha-params":2,"ha-sync-mode":"automatic"}': 策略内容
"ha-mode":"exactly":策略模式,此处是exactly模式,指定副本数量
"ha-params":2:策略参数,这里是2,就是副本数量为2,1主1镜像
"ha-sync-mode":"automatic":同步策略,默认是manual,即新加入的镜像节点不会同步旧的消息。如果设置为automatic,则新加入的镜像节点会把主节点中所有消息都同步,会带来额外的网络开销
all模式
rabbitmqctl set_policy ha-all "^all\." '{"ha-mode":"all"}'
ha-all:策略名称,自定义
"^all\.":匹配所有以all.开头的队列名
'{"ha-mode":"all"}':策略内容
"ha-mode":"all":策略模式,此处是all模式,即所有节点都会称为镜像节点
nodes模式
rabbitmqctl set_policy ha-nodes "^nodes\." '{"ha-mode":"nodes","ha-params":["rabbit@nodeA", "rabbit@nodeB"]}'
rabbitmqctl set_policy:固定写法
ha-nodes:策略名称,自定义
"^nodes\.":匹配队列的正则表达式,符合命名规则的队列才生效,这里是任何以nodes.开头的队列名称
'{"ha-mode":"nodes","ha-params":["rabbit@nodeA", "rabbit@nodeB"]}': 策略内容
"ha-mode":"nodes":策略模式,此处是nodes模式
"ha-params":["rabbit@mq1", "rabbit@mq2"]:策略参数,这里指定副本所在节点名称
测试
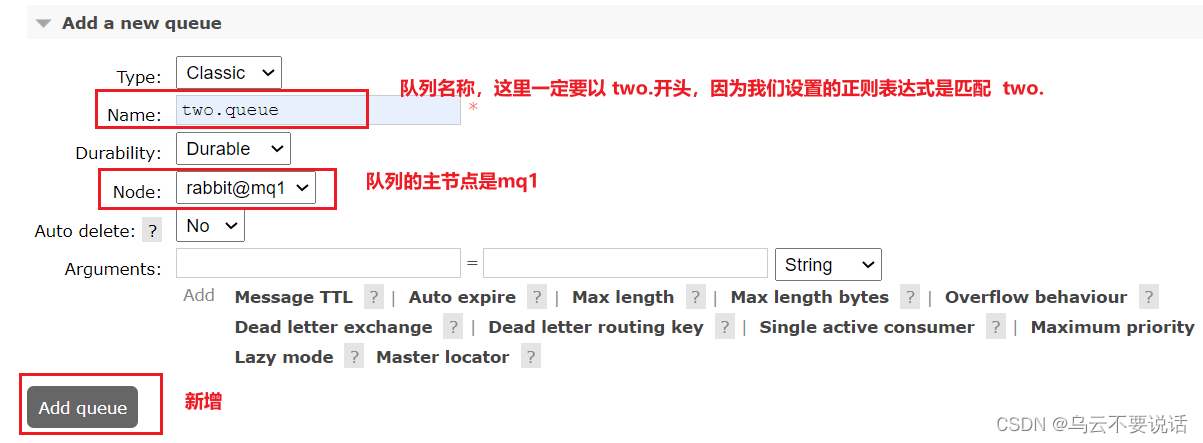
我们使用exactly模式的镜像,因为集群节点数量为3,因此镜像数量就设置为2.
运行下面的命令:
docker exec -it mq1 rabbitmqctl set_policy ha-two "^two\." '{"ha-mode":"exactly","ha-params":2,"ha-sync-mode":"automatic"}'下面,我们创建一个新的队列:
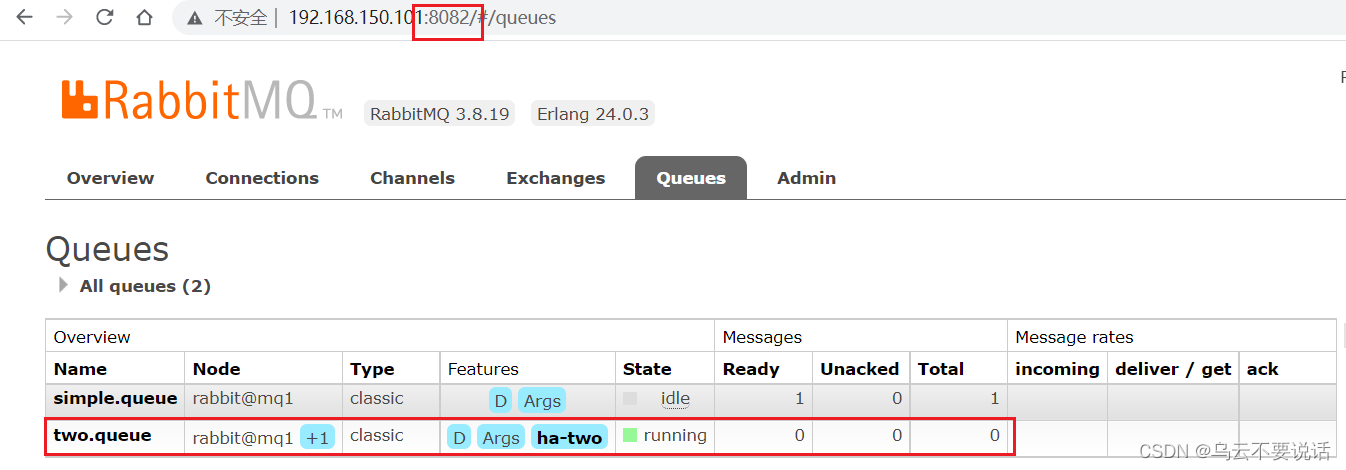
在任意一个mq控制台查看队列:
测试数据共享
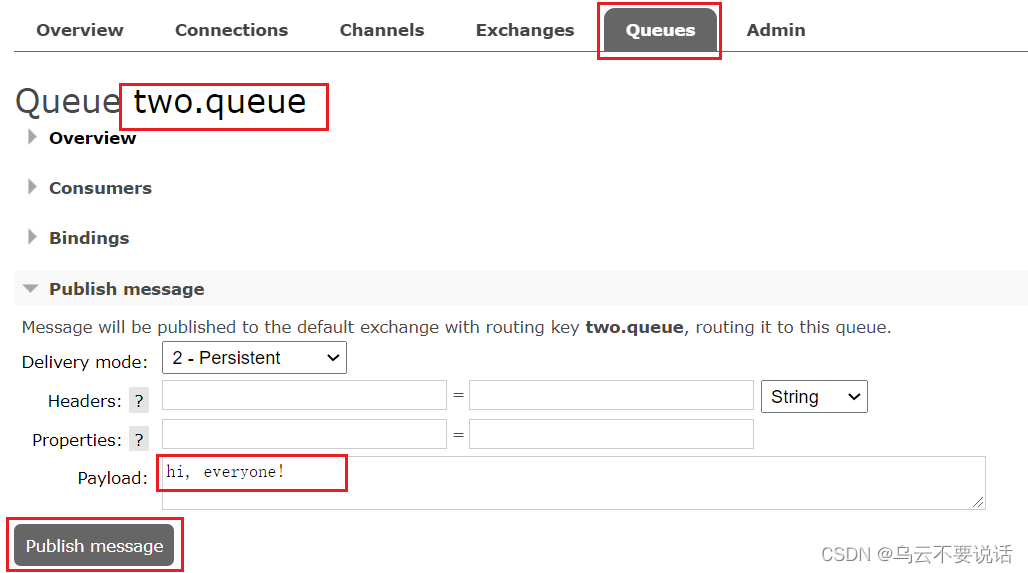
给two.queue发送一条消息:
然后在mq1、mq2、mq3的任意控制台查看消息:
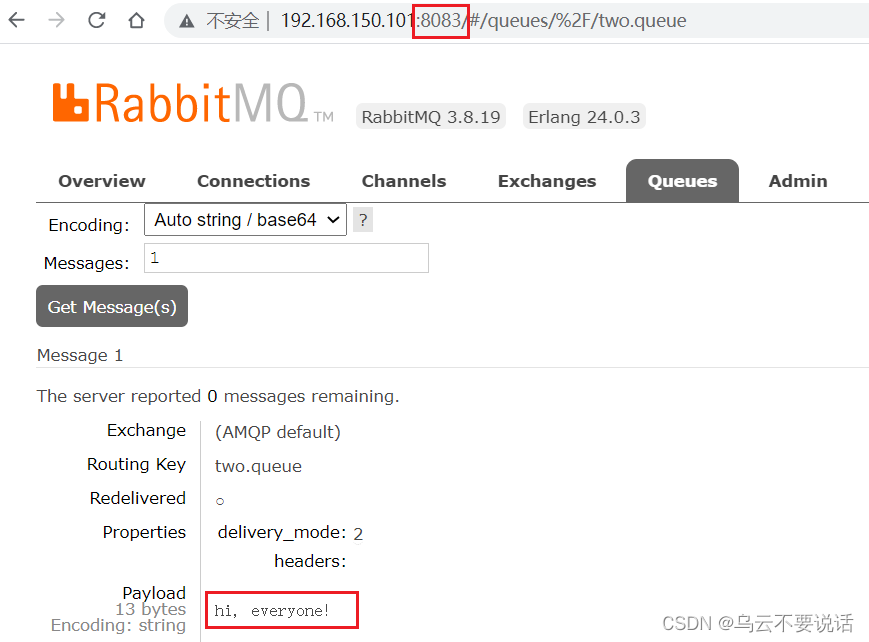
测试高可用
现在,我们让two.queue的主节点mq1宕机:
docker stop mq1查看集群状态:
查看队列状态:
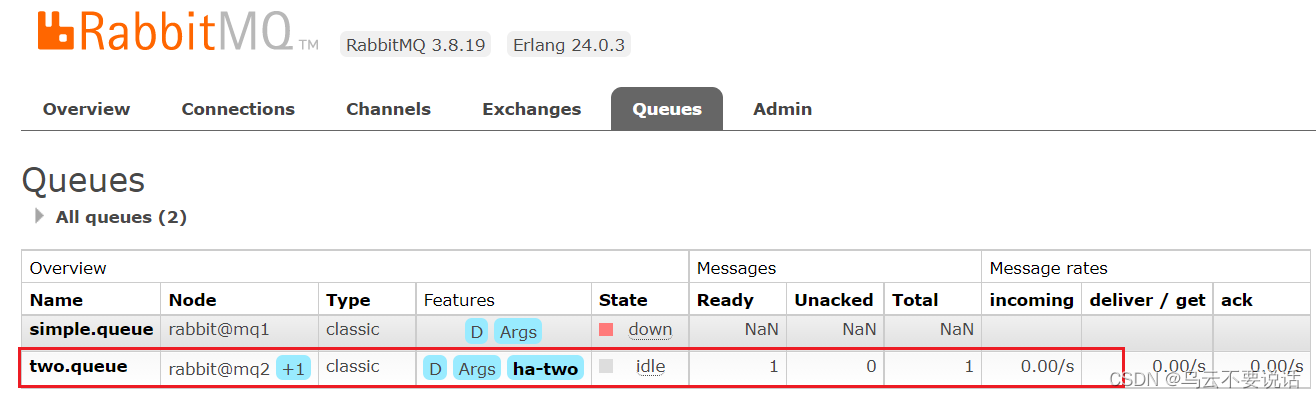
发现依然是健康的!并且其主节点切换到了rabbit@mq2上

2.4、仲裁队列
2.4.1、集群特征
仲裁队列:仲裁队列是3.8版本以后才有的新功能,用来替代镜像队列,具备下列特征:
-
与镜像队列一样,都是主从模式,支持主从数据同步
-
使用非常简单,没有复杂的配置
-
主从同步基于Raft协议,强一致
2.4.2、部署
从RabbitMQ 3.8版本开始,引入了新的仲裁队列,他具备与镜像队里类似的功能,但使用更加方便。
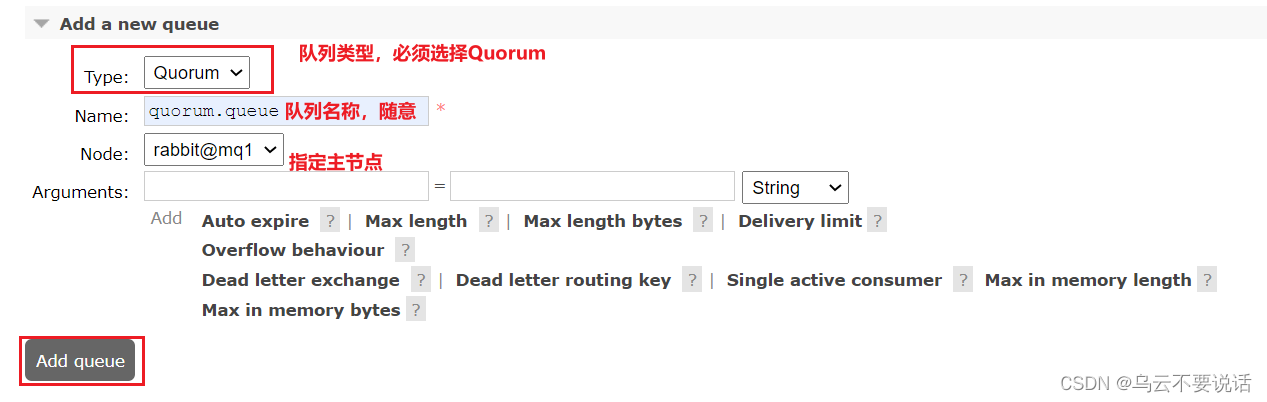
添加仲裁队列
在任意控制台添加一个队列,一定要选择队列类型为Quorum类型。
在任意控制台查看队列:
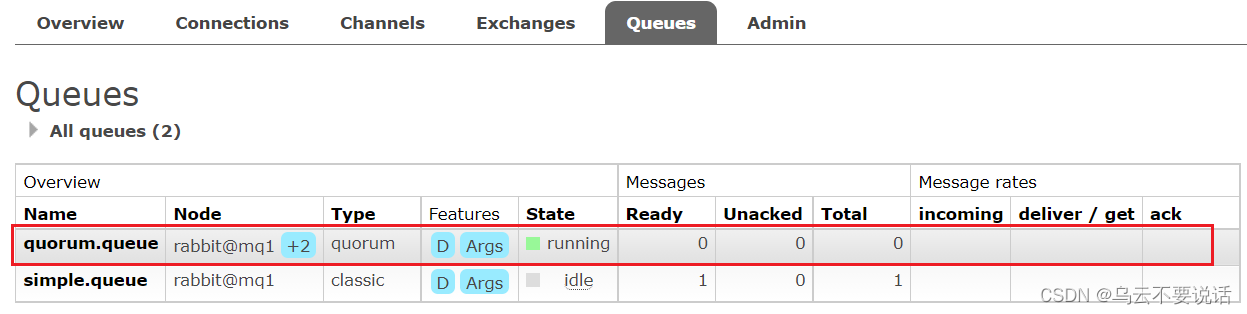
可以看到,仲裁队列的 + 2字样。代表这个队列有2个镜像节点。
因为仲裁队列默认的镜像数为5。如果你的集群有7个节点,那么镜像数肯定是5;而我们集群只有3个节点,因此镜像数量就是3.
2.4.3、Java代码创建仲裁队列
@Bean
public Queue quorumQueue() {return QueueBuilder.durable("quorum.queue") // 持久化.quorum() // 仲裁队列.build();
}
2.4.4、SpringAMQP连接MQ集群
注意,这里用address来代替host、port方式
spring:rabbitmq:addresses: 192.168.150.105:8071, 192.168.150.105:8072, 192.168.150.105:8073username: mqpassword: 123321virtual-host: /相关文章:
RabbitMQ --- 惰性队列、MQ集群
一、惰性队列 1.1、消息堆积问题 当生产者发送消息的速度超过了消费者处理消息的速度,就会导致队列中的消息堆积,直到队列存储消息达到上限。之后发送的消息就会成为死信,可能会被丢弃,这就是消息堆积问题。 解决消息堆积有三种…...

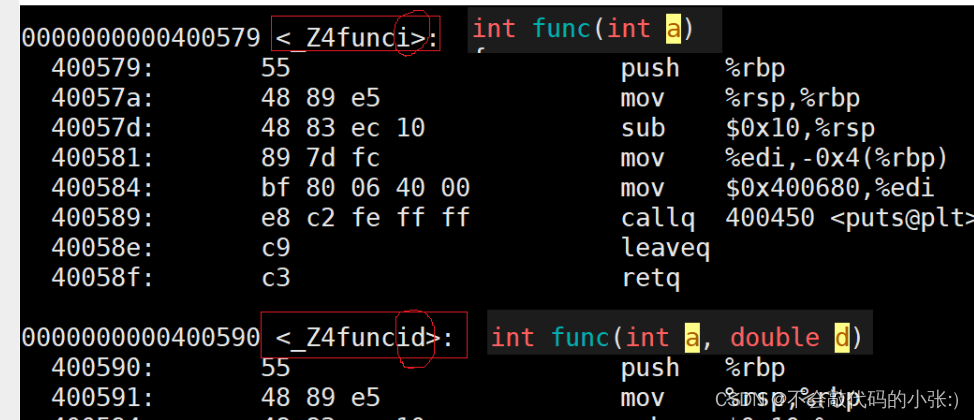
1.Buffer_Overflow-1.Basic_Jump
github上面的练习题 git clone https://github.com/Adamkadaban/LearnPwn 然后开始做 先进行 readelf 然后进行执行看看 是怎么回事 ./buf1发现就是一个输入和输出 我们checksec看看 发现stack 保护关闭 开启了NX保护 我们进入ida64看看反汇编 我习惯先看看字符串 SHITF…...

MySQL入门语法第三课:表结构的创建
数据表结构 定点数类型decimal(m,d) m表示数字总位数 d表示小数位数 ★创建数据表先要选择数据库 1 . CREATE TABLE 表名称 创建数据表 (字段名1 数据类型1 [,字段名2 数据名2] [, .....] ); 一个字段写一行 修改表名 alter table 旧表名 rename 新表名…...
SpringSecurity框架学习与使用
SpringSecurity框架学习与使用 SpringSecurity学习SpringSecurity入门SpringSecurity深入认证授权自定义授权失败页面权限注解SecuredPreAuthorizePostAuthorizePostFilterPreFilter 参考 SpringSecurity学习 SpringSecurity入门 引入相关的依赖,SpringBoot的版本…...
DHCP+链路聚合+NAT+ACL小型实验
实验要求: 1.按照拓扑图上标识规划网络。 2.使用0SPF协议进程100实现ISP互通。 3.私网内PC属于VLAN1O, FTP Server属于VLAN2O,网关分 别为所连接的接入交换机,其中PC要求通过DHCP动态获取 4:私网内部所有交换机都为三层交换机,请合理规划VLAN&#…...
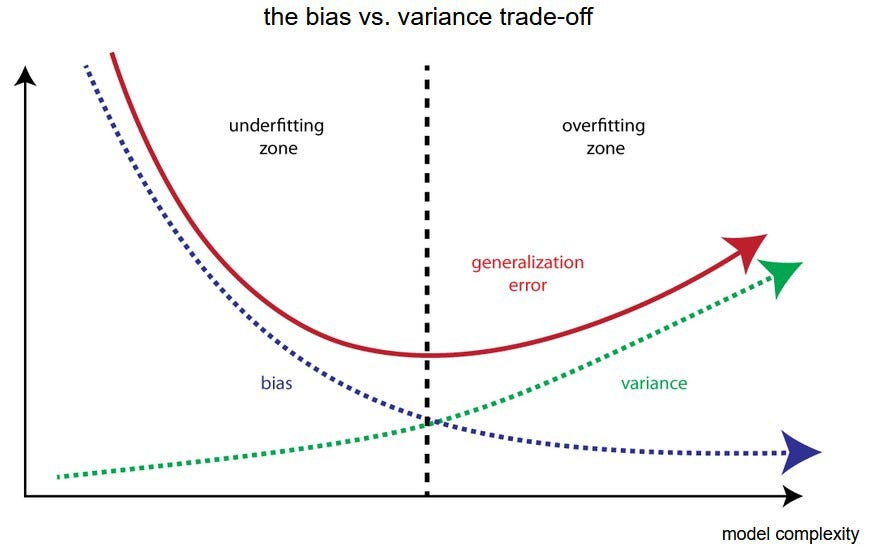
西瓜书读书笔记整理(三)—— 第二章 模型评估与选择
第二章 模型评估与选择 第 2 章 模型评估与选择2.1 经验误差与过拟合1. 错误率 / 精度 / 误差2. 训练误差 / 经验误差 / 泛化误差3. 过拟合 / 欠拟合4. 学习能力5. 模型选择 2.2 评估方法1. 评估方法概述2. 留出法3. 交叉验证法4. 自助法5. 调参 / 最终模型 2.3 性能度量1. 回归…...

AcWing算法提高课-1.3.6货币系统
宣传一下算法提高课整理 <— CSDN个人主页:更好的阅读体验 <— 本题链接(AcWing) 点这里 题目描述 给你一个n种面值的货币系统,求组成面值为m的货币有多少种方案。 输入格式 第一行,包含两个整数n和m。 接…...

vue3回到上一个路由页面
学习链接 Vue Router获取当前页面由哪个路由跳转 在Vue3的setup中如何使用this beforeRouteEnter 在这个路由方法中不能访问到组件实例this,但是可以使用next里面的vm访问到组件实例,并通过vm.$data获取组件实例上的data数据getCurrentInstance 是vue3提…...

Linux三种网络模式 | 仅主机、桥接、NAT
💗wei_shuo的个人主页 💫wei_shuo的学习社区 🌐Hello World ! Linux三种网络模式 仅主机模式:虚拟机只能访问物理机,不能上网 桥接模式:虚拟机和物理机连接同一网络,虚拟机和物理机…...

数据库设计与前端框架
数据库设计与前端框架 学习目标: 理解多租户的数据库设计方案 熟练使用PowerDesigner构建数据库模型理解前端工程的基本架构和执行流程 完成前端工程企业模块开发 多租户SaaS平台的数据库方案 多租户是什么 多租户技术(Multi-TenancyTechnology&a…...

技术探秘:揭秘Bean Factory与FactoryBean的区别!
大家好,我是小米,一个热衷于技术分享的29岁小编。今天,我们来聊一聊在Spring框架中常用的两个概念:beanFactory和FactoryBean。它们虽然看似相似,但实际上有着不同的用途和作用。让我们一起来揭开它们的神秘面纱吧&…...

MD-MTSP:遗传算法GA求解多仓库多旅行商问题(提供MATLAB代码,可以修改旅行商个数及起点)
一、多仓库多旅行商问题 多旅行商问题(Multiple Traveling Salesman Problem, MTSP)是著名的旅行商问题(Traveling Salesman Problem, TSP)的延伸,多旅行商问题定义为:给定一个𝑛座城市的城市集…...

技术面试的终极指南:助你取得成功的关键步骤
背景 技术面试是许多求职者最关键的一环,因为它评估了你在特定领域的知识和技能。无论你是刚毕业的大学应届生,还是有多年工作经验的职场老兵,准备充分是成功面试的关键。 这篇文章将提供一系列关键步骤,帮助你充分准备和展现自己…...

Nautilus Chain 测试网第二阶段,推出忠诚度计划及广泛空投
随着更多的公链底层面向市场,通过参与早期测试在主网上线后获得激励成为了行业的一个热点话题,在 Apots、Arbitrum One、Optimism等陆续发放了测试空投后,以 Layer3为主要特性的 Nautilus Chain 也在前不久明确表示将会有空投,引发…...
:BeautifulSoup库)
Python爬虫(三):BeautifulSoup库
BeautifulSoup 是一个可以从 HTML 或 XML 文件中提取数据的 Python 库,它能够将 HTML 或 XML 转化为可定位的树形结构,并提供了导航、查找、修改功能,它会自动将输入文档转换为 Unicode 编码,输出文档转换为 UTF-8 编码。 Beauti…...
Python使用CV2库捕获、播放和保存摄像头视频
Python使用CV2库捕获、播放和保存摄像头视频 特别提示:CV2指的是OpenCV2(Open Source Computer Vision Library),安装的时候是 opencv_python,但在导入的时候采用 import cv2。 若想使用cv2库必须先安装,P…...

[数据结构 -- C语言] 栈(Stack)
目录 1、栈 1.1 栈的概念及结构 2、栈的实现 2.1 接口 3、接口的实现 3.1 初始化 3.2 入栈/压栈 3.3 出栈 3.4 获取栈顶元素 3.5 获取栈中有效元素个数 3.6.1 bool 类型接口 3.6.2 int 类型接口 3.7 销毁栈 4、完整代码 5、功能测试 1、栈 1.1 栈的概念及结构 …...
【我的C++入门之旅】(上)
前言 C的发展史 1979年,贝尔实验室的Bjarne等人试图分析unix内核的时候,试图将内核模块化,但是发现C语言有很多的不足之处,于是在C语言的基础上进行扩展,增加了类的机制,完成了一个可以运行的预处理程序&…...
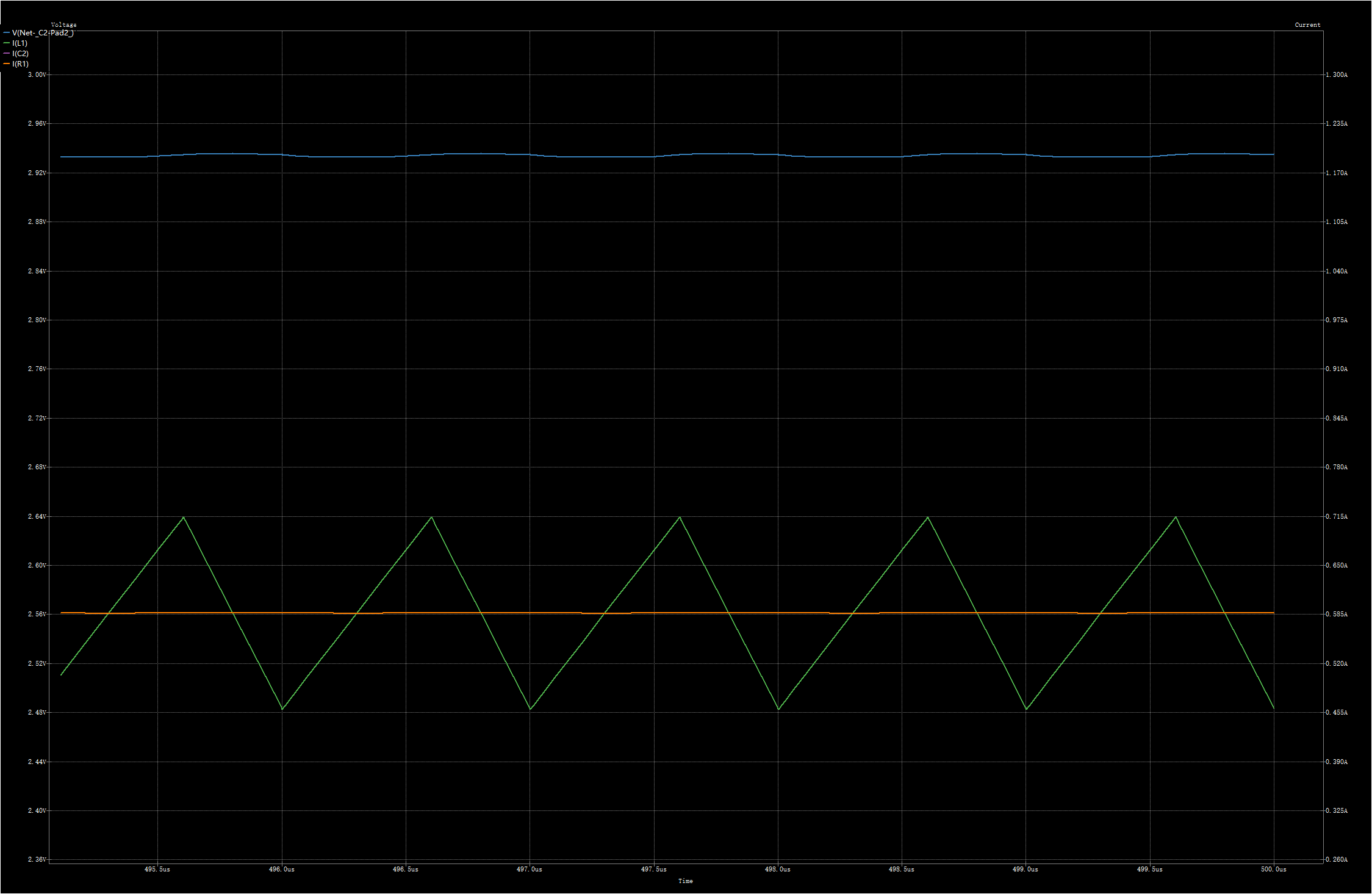
dcdc降压电路原理及仿真
在之前的文章 DCDC 降压芯片基本原理及选型主要参数介绍 中已经大致讲解了dcdc降压电路的工作原理,今天再结合仿真将buck电路工作过程讲一讲。 基本拓扑 上图为buck电路的基本拓扑结构,开关打到1,电感充电;开关打到0,…...
搭建Redis主从集群+哨兵+代理predixy
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、Redis是什么?二、搭建Redis集群步骤1.环境和版本2.Redis 安装部署3.主从同步配置4.哨兵模式配置5.代理predixy配置 总结 前言 提示:…...

CVAT在Ubuntu 20.04上的完整安装指南:从Docker配置到多人协作避坑
CVAT在Ubuntu 20.04上的完整安装指南:从Docker配置到多人协作避坑 在计算机视觉项目中,高质量的数据标注是模型成功的关键。CVAT(Computer Vision Annotation Tool)作为英特尔开源的图像标注工具,凭借其丰富的标注功能…...

从不确定性到规律:随机信号的统计特性深度解析
1. 从噪声到规律:随机信号为何重要 每天清晨被手机闹钟唤醒时,你可能没意识到这个简单的动作背后隐藏着一个有趣的数学现象——你听到的闹铃声其实是一个典型的随机信号。与规律的音乐不同,闹铃声的波形无法用简单的数学公式预测,…...

Windows 11游戏兼容终极指南:让经典游戏重获新生
Windows 11游戏兼容终极指南:让经典游戏重获新生 【免费下载链接】dxwrapper Fixes compatibility issues with older games running on Windows 10/11 by wrapping DirectX dlls. Also allows loading custom libraries with the file extension .asi into game pr…...

Cats Blender插件:快速导入和优化VRChat模型的终极解决方案 [特殊字符]
Cats Blender插件:快速导入和优化VRChat模型的终极解决方案 🚀 【免费下载链接】cats-blender-plugin :smiley_cat: A tool designed to shorten steps needed to import and optimize models into VRChat. Compatible models are: MMD, XNALara, Mixamo…...

从手机干扰到车辆‘趴窝’:聊聊新能源汽车里那些看不见的‘电磁战争’
新能源汽车的隐形战场:电磁兼容如何影响你的每一次出行 1. 从手机干扰到车辆故障:电磁兼容的日常启示 你是否遇到过这样的场景——当手机靠近音响时,扬声器会发出"滋滋"的杂音?这个看似简单的现象,其实揭示了…...

告别代码恐惧:AppEEARS可视化下载MODIS GPP数据全流程解析
1. 为什么选择AppEEARS下载MODIS数据? 作为一个常年和遥感数据打交道的科研狗,我太理解新手面对代码时的恐惧了。记得我第一次用Python下载MODIS数据时,光是安装GDAL库就折腾了两天,最后还因为投影转换出错导致整个数据集报废。直…...

League Akari助手:革新英雄联盟游戏体验的终极智能工具箱
League Akari助手:革新英雄联盟游戏体验的终极智能工具箱 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 你是否曾在英雄选择阶段因…...

植物大战僵尸PC版终极修改器:PvZ Toolkit完全使用指南
植物大战僵尸PC版终极修改器:PvZ Toolkit完全使用指南 【免费下载链接】pvztoolkit 植物大战僵尸 PC 版综合修改器 项目地址: https://gitcode.com/gh_mirrors/pv/pvztoolkit 你是否厌倦了《植物大战僵尸》PC版一成不变的玩法?想挑战极限生存模式…...

如何用Python快速掌握严格耦合波分析:光学仿真的终极指南
如何用Python快速掌握严格耦合波分析:光学仿真的终极指南 【免费下载链接】Rigorous-Coupled-Wave-Analysis modules for semi-analytic fourier series solutions for Maxwells equations. Includes transfer-matrix-method, plane-wave-expansion-method, and rig…...

【SITS2026权威前瞻】:全球TOP12AI代码引擎实测对比,3大生产级陷阱你避开了吗?
第一章:SITS2026圆桌:智能代码生成未来 2026奇点智能技术大会(https://ml-summit.org) 在SITS2026圆桌论坛上,来自GitHub、Tabnine、DeepMind与国内大模型实验室的七位核心研发者共同探讨了智能代码生成从“补全助手”迈向“协同编程伙伴”…...