Python爬虫(三):BeautifulSoup库
BeautifulSoup 是一个可以从 HTML 或 XML 文件中提取数据的 Python 库,它能够将 HTML 或 XML 转化为可定位的树形结构,并提供了导航、查找、修改功能,它会自动将输入文档转换为 Unicode 编码,输出文档转换为 UTF-8 编码。
BeautifulSoup 支持 Python 标准库中的 HTML 解析器和一些第三方的解析器,默认使用 Python 标准库中的 HTML 解析器,默认解析器效率相对比较低,如果需要解析的数据量比较大或比较频繁,推荐使用更强、更快的 lxml 解析器。
1 安装
1)BeautifulSoup 安装
如果使用 Debain 或 ubuntu 系统,可以通过系统的软件包管理来安装:apt-get install Python-bs4,如果无法使用系统包管理安装,可以使用 pip install beautifulsoup4 来安装。
2)第三方解析器安装
如果需要使用第三方解释器 lxml 或 html5lib,可是使用如下命令进行安装:apt-get install Python-lxml(html5lib) 和 pip install lxml(html5lib)。
看一下主要解析器和它们的优缺点:
| 解析器 | 使用方法 | 优势 | 劣势 |
|---|---|---|---|
| Python标准库 | BeautifulSoup(markup,"html.parser") | Python的内置标准库;执行速度适中;文档容错能力强。 | Python 2.7.3 or 3.2.2)前的版本中文档容错能力差。 |
| lxml HTML 解析器 | BeautifulSoup(markup,"lxml") | 速度快;文档容错能力强。 | 需要安装C语言库。 |
| lxml XML 解析器 |
| 速度快;唯一支持XML的解析器。 | 需要安装C语言库 |
| html5lib | BeautifulSoup(markup,"html5lib") | 最好的容错性;以浏览器的方式解析文档;生成HTML5格式的文档。 | 速度慢;不依赖外部扩展。 |
2 快速上手
将一段文档传入 BeautifulSoup 的构造方法,就能得到一个文档的对象,可以传入一段字符串或一个文件句柄,示例如下:
1)使用字符串
我们以如下一段 HTML 字符串为例:
html = '''<!DOCTYPE html><html lang="en"><head><meta charset="UTF-8"><title>BeautifulSoup学习</title></head><body>Hello BeautifulSoup</body></html>'''
使用示例如下:
from bs4 import BeautifulSoup#使用默认解析器soup = BeautifulSoup(html,'html.parser')#使用 lxml 解析器soup = BeautifulSoup(html,'lxml')
2)本地文件
还以上面那段 HTML 为例,将上面 HTML 字符串放在 index.html 文件中,使用示例如下:
#使用默认解析器soup = BeautifulSoup(open('index.html'),'html.parser')#使用 lxml 解析器soup = BeautifulSoup(open('index.html'),'lxml')
2.1 对象的种类
BeautifulSoup 将 HTML 文档转换成一个树形结构,每个节点都是 Python 对象,所有对象可以归纳为4种:Tag,NavigableString,BeautifulSoup,Comment。
1)Tag 对象
Tag 对象与 HTML 或 XML 原生文档中的 tag 相同,示例如下:
soup = BeautifulSoup('<title>BeautifulSoup学习</title>','lxml')tag = soup.titletp =type(tag)print(tag)print(tp)#输出结果'''<title>BeautifulSoup学习</title><class 'bs4.element.Tag'>'''
Tag 有很多方法和属性,这里先看一下它的的两种常用属性:name 和 attributes。
我们可以通过 .name 来获取 tag 的名字,示例如下:
soup = BeautifulSoup('<title>BeautifulSoup学习</title>','lxml')tag = soup.titleprint(tag.name)#输出结果#title
我们还可以修改 tag 的 name,示例如下:
tag.name = 'title1'print(tag)#输出结果#<title1>BeautifulSoup学习</title1>
一个 tag 可能有很多个属性,先看一它的 class 属性,其属性的操作方法与字典相同,示例如下:
soup = BeautifulSoup('<title class="tl">BeautifulSoup学习</title>','lxml')tag = soup.titlecls = tag['class']print(cls)#输出结果#['tl']
我们还可以使用 .attrs 来获取,示例如下:
ats = tag.attrsprint(ats)#输出结果#{'class': ['tl']}
tag 的属性可以被添加、修改和删除,示例如下:
#添加 id 属性tag['id'] = 1#修改 class 属性tag['class'] = 'tl1'#删除 class 属性del tag['class']
2)NavigableString 对象
NavigableString 类是用来包装 tag 中的字符串内容的,使用 .string 来获取字符串内容,示例如下:
str = tag.string可以使用 replace_with() 方法将原有字符串内容替换成其它内容 ,示例如下:
tag.string.replace_with('BeautifulSoup')3)BeautifulSoup 对象
BeautifulSoup 对象表示的是一个文档的全部内容,它并不是真正的 HTML 或 XML 的 tag,因此它没有 name 和 attribute 属性,为方便查看它的 name 属性,BeautifulSoup 对象包含了一个值为 [document] 的特殊属性 .name,示例如下:
soup = BeautifulSoup('<title class="tl">BeautifulSoup学习</title>','lxml')print(soup.name)#输出结果#[document]
4)Comment 对象
Comment 对象是一个特殊类型的 NavigableString 对象,它会使用特殊的格式输出,看一下例子:
soup = BeautifulSoup('<title class="tl">Hello BeautifulSoup</title>','html.parser')comment = soup.title.prettify()print(comment)#输出结果'''<title class="tl">Hello BeautifulSoup</title>'''
我们前面看的例子中 tag 中的字符串内容都不是注释内容,现在将字符串内容换成注释内容,我们来看一下效果:
soup = BeautifulSoup('<title class="tl"><!--Hello BeautifulSoup--></title>','html.parser')str = soup.title.stringprint(str)#输出结果#Hello BeautifulSoup
通过结果我们发现注释符号 <!----> 被自动去除了,这一点我们要注意一下。
2.2 搜索文档树
BeautifulSoup 定义了很多搜索方法,我们来具体看一下。
1)find_all()
find_all() 方法搜索当前 tag 的所有 tag 子节点,方法详细如下:find_all(name=None, attrs={}, recursive=True, text=None,limit=None, **kwargs),来具体看一下各个参数。
name 参数可以查找所有名字为 name 的 tag,字符串对象会被自动忽略掉,示例如下:
soup = BeautifulSoup('<title class="tl">Hello BeautifulSoup</title>','html.parser')print(soup.find_all('title'))#输出结果#[<title class="tl">Hello BeautifulSoup</title>]
attrs 参数定义一个字典参数来搜索包含特殊属性的 tag,示例如下:
soup = BeautifulSoup('<title class="tl">Hello BeautifulSoup</title>','html.parser')soup.find_all(attrs={"class": "tl"})
调用 find_all() 方法时,默认会检索当前 tag 的所有子孙节点,通过设置参数 recursive=False,可以只搜索 tag 的直接子节点,示例如下:
soup = BeautifulSoup('<html><head><title>Hello BeautifulSoup</title></head></html>','html.parser')print(soup.find_all('title',recursive=False))#输出结果#[]
通过 text 参数可以搜搜文档中的字符串内容,它接受字符串、正则表达式、列表、True,示例如下:
from bs4 import BeautifulSoupimport resoup = BeautifulSoup('<head>myHead</head><title>BeautifulSoup</title>','html.parser')#字符串soup.find_all(text='BeautifulSoup')#正则表达式soup.find_all(soup.find_all(text=re.compile('title')))#列表soup.find_all(soup.find_all(text=['head','title']))#Truesoup.find_all(text=True)
limit 参数与 SQL 中的 limit 关键字类似,用来限制搜索的数据,示例如下:
soup = BeautifulSoup('<a id="link1" href="http://example.com/elsie">Elsie</a><a id="link2" href="http://example.com/elsie">Elsie</a>','html.parser')soup.find_all('a', limit=1)
我们经常见到 Python 中 *arg 和 **kwargs 这两种可变参数,*arg 表示非键值对的可变数量的参数,将参数打包为 tuple 传递给函数;**kwargs 表示关键字参数,参数是键值对形式的,将参数打包为 dict 传递给函数。
使用多个指定名字的参数可以同时过滤 tag 的多个属性,如:
soup = BeautifulSoup('<a id="link1" href="http://example.com/elsie">Elsie</a><a id="link2" href="http://example.com/elsie">Elsie</a>','html.parser')soup.find_all(href=re.compile("elsie"),id='link1')
有些 tag 属性在搜索不能使用,如 HTML5 中的 data-* 属性,示例如下:
soup = BeautifulSoup('<div data-foo="value">foo!</div>')soup.find_all(data-foo='value')
首先当我在 Pycharm 中输入 data-foo='value' 便提示语法错误了,然后我不管提示直接执行提示 SyntaxError: keyword can't be an expression 这个结果也验证了 data-* 属性在搜索中不能使用。我们可以通过 find_all() 方法的 attrs 参数定义一个字典参数来搜索包含特殊属性的 tag,示例如下:
print(soup.find_all(attrs={'data-foo': 'value'}))2)find()
方法详细如下:find(name=None, attrs={}, recursive=True, text=None,**kwargs),我们可以看出除了少了 limit 参数,其它参数与方法 find_all 一样,不同之处在于:find_all() 方法的返回结果是一个列表,find() 方法返回的是第一个节点,find_all() 方法没有找到目标是返回空列表,find() 方法找不到目标时,返回 None。来看个例子:
soup = BeautifulSoup('<a id="link1" href="http://example.com/elsie">Elsie</a><a id="link2" href="http://example.com/elsie">Elsie</a>','html.parser')print(soup.find_all('a', limit=1))print(soup.find('a'))#输出结果'''[<a href="http://example.com/elsie" id="link1">Elsie</a>]<a href="http://example.com/elsie" id="link1">Elsie</a>'''
从示例中我们也可以看出,find() 方法返回的是找到的第一个节点。
3)find_parents() 和 find_parent()
find_all() 和 find() 用来搜索当前节点的所有子节点,find_parents() 和 find_parent() 则用来搜索当前节点的父辈节点。
4)find_next_siblings() 和 find_next_sibling()
这两个方法通过 .next_siblings 属性对当前 tag 所有后面解析的兄弟 tag 节点进行迭代,find_next_siblings() 方法返回所有符合条件的后面的兄弟节点,find_next_sibling() 只返回符合条件的后面的第一个tag节点。
5)find_previous_siblings() 和 find_previous_sibling()
这两个方法通过 .previous_siblings 属性对当前 tag 前面解析的兄弟 tag 节点进行迭代,find_previous_siblings() 方法返回所有符合条件的前面的兄弟节点,find_previous_sibling() 方法返回第一个符合条件的前面的兄弟节点。
6)find_all_next() 和 find_next()
这两个方法通过 .next_elements 属性对当前 tag 之后的 tag 和字符串进行迭代,find_all_next() 方法返回所有符合条件的节点,find_next() 方法返回第一个符合条件的节点。
7)find_all_previous() 和 find_previous()
这两个方法通过 .previous_elements 属性对当前节点前面的 tag 和字符串进行迭代,find_all_previous() 方法返回所有符合条件的节点,find_previous() 方法返回第一个符合条件的节点。
2.3 CSS选择器
BeautifulSoup 支持大部分的 CSS 选择器,在 Tag 或 BeautifulSoup 对象的 .select() 方法中传入字符串参数,即可使用 CSS 选择器的语法找到 tag,返回类型为列表。示例如下:
soup = BeautifulSoup('<body><a id="link1" class="elsie">Elsie</a><a id="link2" class="elsie">Elsie</a></body>','html.parser')print(soup.select('a'))#输出结果#[<a clss="elsie" id="link1">Elsie</a>, <a clss="elsie" id="link2">Elsie</a>]
通过标签逐层查找
soup.select('body a')找到某个 tag 标签下的直接子标签
soup.select('body > a')通过类名查找
soup.select('.elsie')soup.select('[class~=elsie]')
通过 id 查找
soup.select('#link1')使用多个选择器
soup.select('#link1,#link2')通过属性查找
soup.select('a[class]')通过属性的值来查找
soup.select('a[class="elsie"]')查找元素的第一个
soup.select_one('.elsie')查找兄弟节点标签
#查找所有soup.select('#link1 ~ .elsie')#查找第一个soup.select('#link1 + .elsie')
相关文章:
:BeautifulSoup库)
Python爬虫(三):BeautifulSoup库
BeautifulSoup 是一个可以从 HTML 或 XML 文件中提取数据的 Python 库,它能够将 HTML 或 XML 转化为可定位的树形结构,并提供了导航、查找、修改功能,它会自动将输入文档转换为 Unicode 编码,输出文档转换为 UTF-8 编码。 Beauti…...
Python使用CV2库捕获、播放和保存摄像头视频
Python使用CV2库捕获、播放和保存摄像头视频 特别提示:CV2指的是OpenCV2(Open Source Computer Vision Library),安装的时候是 opencv_python,但在导入的时候采用 import cv2。 若想使用cv2库必须先安装,P…...

[数据结构 -- C语言] 栈(Stack)
目录 1、栈 1.1 栈的概念及结构 2、栈的实现 2.1 接口 3、接口的实现 3.1 初始化 3.2 入栈/压栈 3.3 出栈 3.4 获取栈顶元素 3.5 获取栈中有效元素个数 3.6.1 bool 类型接口 3.6.2 int 类型接口 3.7 销毁栈 4、完整代码 5、功能测试 1、栈 1.1 栈的概念及结构 …...
【我的C++入门之旅】(上)
前言 C的发展史 1979年,贝尔实验室的Bjarne等人试图分析unix内核的时候,试图将内核模块化,但是发现C语言有很多的不足之处,于是在C语言的基础上进行扩展,增加了类的机制,完成了一个可以运行的预处理程序&…...
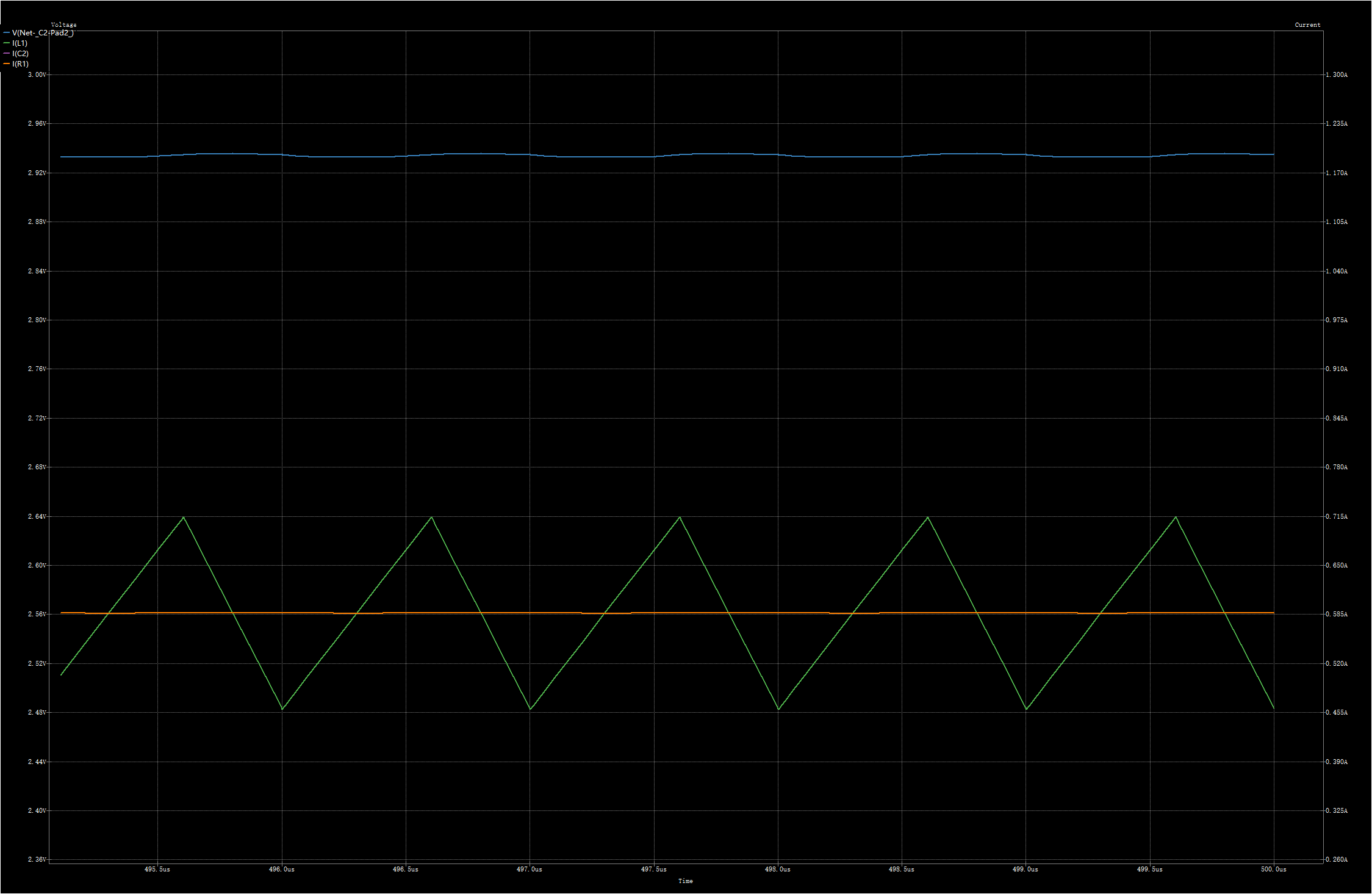
dcdc降压电路原理及仿真
在之前的文章 DCDC 降压芯片基本原理及选型主要参数介绍 中已经大致讲解了dcdc降压电路的工作原理,今天再结合仿真将buck电路工作过程讲一讲。 基本拓扑 上图为buck电路的基本拓扑结构,开关打到1,电感充电;开关打到0,…...
搭建Redis主从集群+哨兵+代理predixy
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、Redis是什么?二、搭建Redis集群步骤1.环境和版本2.Redis 安装部署3.主从同步配置4.哨兵模式配置5.代理predixy配置 总结 前言 提示:…...

Syncthing文件同步 - 免费搭建开源的文件自动同步服务器并公网远程访问【私人云盘】
文章目录 1. 前言2. Syncthing网站搭建2.1 Syncthing下载和安装2.2 Syncthing网页测试2.3 注册安装cpolar内网穿透 3. 本地网页发布3.1 Cpolar云端设置3.2 Cpolar本地设置 4. 公网访问测试5. 结语 1. 前言 在数据爆炸的当下,每天都会产生海量的数据,这些…...
SQL——索引
💡 索引 在关系型数据库中,索引是一种单独的、物理上的对数据库表中的一列或多列的值进行排序的一种存储结构,他是某个表中的一列或着若干列值的集合和相应的指向表中物理标识这些值的数据页的逻辑指针清单(类似于图书目录&#x…...

Java代码组成部分
一、构造函数与默认构造函数 构造函数,是一种特殊方法。主要用来在创建对象时初始化对象,即为对象成员变量赋初始值,总与new运算符一起使用在创建对象的语句中。 /** * 矩形 */ class Rectangle {/*** 构造函数*/public Rectangle(int leng…...

vue2和vue3有啥区别,vue3的优点有哪些?
Vue.js 是一种流行的 JavaScript 框架,用于开发现代 Web 应用程序。Vue.js 具有简单易用、高效和灵活等特点,能够极大地提高开发效率并改进用户体验。Vue.js 一直在不断更新和改进,它的最新版本是 Vue 3。 在本文中,我们将探讨 V…...

就业内推 | 上市公司招网工,最高25k*14薪,六险一金
01 锐捷网络 招聘岗位:网络工程师 职责描述: 1、承接本产品线(无线或数通)所有咨询、故障、网络变更等业务,响应内外部客户的业务响应需求,需要值班。 2、同时作为产品线技术力的核心,需要负责…...
低代码让开发变得不再复杂
文章目录 前言低代码 VS 传统开发为什么选择IVX?平台比对总结 前言 在数字化的时代背景下,企业都面临巨大的数字化转型的挑战。为了应对这样的挑战,企业软件开发工具和平台也在不断革新和发展。低代码开发平台随之应运而生,成为了…...

【前端客栈】使用CSS实现畅销书排行榜页面
📬📫hello,各位小伙伴们,我是小浪。大家都知道,我最近是在更新各大厂的软件测试开发的面试真题,也是得到了很大的反馈和好评,几位小伙伴也是成功找到了测开的实习,非常不错。如果能前…...

【周末闲谈】超越ChatGPT?科大讯飞星火认知大模型
个人主页:【😊个人主页】 系列专栏:【❤️周末闲谈】 ✨第一周 二进制VS三进制 ✨第二周 文心一言,模仿还是超越? ✨第二周 畅想AR 文章目录 前言星火名字的由来科大讯飞星火落地应用演示赶超ChatGPT的底气在哪里?“硬…...

第N2周:中文文本分类-Pytorch实现
目录 一、前言二、准备工作三、数据预处理1.加载数据2.构建词典3.生成数据批次和迭代器 三、模型构建1. 搭建模型2. 初始化模型3. 定义训练与评估函数 四、训练模型1. 拆分数据集并运行模型 一、前言 🍨 本文为🔗365天深度学习训练营 中的学习记录博客 …...
Salesforce许可证和版本有什么区别,购买帐号时应该如何选择?
Salesforce许可证分配给特定用户,授予他们访问Salesforce产品和功能的权限。Salesforce版本和许可证是不同的概念,但极易混淆。 Salesforce版本:这是对组织购买的Salesforce产品和功能的访问权限。大致可分为Essentials、Professional、Ente…...
接口测试怎么做?全网最详细从接口测试到接口自动化详解,看这篇就够了...
目录:导读 前言一、Python编程入门到精通二、接口自动化项目实战三、Web自动化项目实战四、App自动化项目实战五、一线大厂简历六、测试开发DevOps体系七、常用自动化测试工具八、JMeter性能测试九、总结(尾部小惊喜) 前言 抛出一个问题&…...

DataStore入门及在项目中的使用
首先给个官网的的地址:应用架构:数据层 - DataStore - Android 开发者 | Android Developers 小伙伴们可以直接看官网的资料,本篇文章是对官网的部分细节进行补充 一、为什么要使用DataStore 代替SharedPreferences SharedPreferences&a…...

用Python爬取中国各省GDP数据
介绍 在数据分析和经济研究中,了解中国各省份的GDP数据是非常重要的。然而,手动收集这些数据可能是一项繁琐且费时的任务。幸运的是,Python提供了一些强大的工具和库,使我们能够自动化地从互联网上爬取数据。本文将介绍如何使用P…...
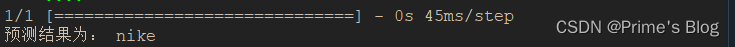
深度学习-第T5周——运动鞋品牌识别
深度学习-第T5周——运动鞋品牌识别 深度学习-第T5周——运动鞋品牌识别一、前言二、我的环境三、前期工作1、导入数据集2、查看图片数目3、查看数据 四、数据预处理1、 加载数据1、设置图片格式2、划分训练集3、划分验证集4、查看标签 2、数据可视化3、检查数据4、配置数据集 …...

零基础友好:快马AI为你定制专属visual studio code图文安装与上手教程
作为一名从零开始学习编程的新手,我深刻体会到安装开发环境是很多人遇到的第一个"拦路虎"。最近在InsCode(快马)平台上发现了一个特别适合新手的Visual Studio Code安装教程项目,它完全解决了我的困惑。下面分享我的学习笔记,希望能…...

Ostrakon-VL-8B LaTeX文档自动化:将手写公式草图转换为排版代码
Ostrakon-VL-8B LaTeX文档自动化:将手写公式草图转换为排版代码 每次写论文或者报告,最头疼的部分是什么?对我而言,绝对是敲那些复杂的LaTeX公式。一个积分符号、一个分式结构,往往要花上好几分钟去回忆语法、调整括号…...
)
RenderDoc实战:5分钟搞定OpenGL性能瓶颈定位(附Android联调技巧)
RenderDoc实战:5分钟定位OpenGL性能瓶颈的完整指南 移动端图形开发最令人头疼的瞬间,莫过于看到测试报告上"FPS波动大"的红色标记,却不知道从哪开始排查。上周团队里新来的工程师花了三天时间逐行检查着色器代码,最后发…...

科研人必备:用浏览器插件给IEEEXplore做个‘小手术’,告别20秒加载
科研效率革命:用浏览器插件精准优化IEEEXplore访问体验 每次打开IEEEXplore文献库,那个转不停的加载图标是否让你焦躁不安?作为每天要与学术数据库打交道的科研工作者,20秒的等待时间足以打断思考流,降低工作效率。这背…...

水墨江南模型效果对比:不同参数下的笔触与渲染风格
水墨江南模型效果对比:不同参数下的笔触与渲染风格 最近在尝试用AI生成水墨画,发现一个挺有意思的现象:同一个“水墨江南”模型,用不同的参数设置,画出来的效果天差地别。有时候是寥寥几笔的写意小品,有时…...

抖音音乐高效解决方案:douyin-downloader批量下载与智能管理指南
抖音音乐高效解决方案:douyin-downloader批量下载与智能管理指南 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fall…...

AzurLaneAutoScript:碧蓝航线终极自动化助手完全指南
AzurLaneAutoScript:碧蓝航线终极自动化助手完全指南 【免费下载链接】AzurLaneAutoScript Azur Lane bot (CN/EN/JP/TW) 碧蓝航线脚本 | 无缝委托科研,全自动大世界 项目地址: https://gitcode.com/gh_mirrors/az/AzurLaneAutoScript 在碧蓝航线…...

从零构建树莓派人脸识别门禁:硬件选型、环境部署与实战避坑
1. 硬件选型与采购清单 第一次玩树莓派人脸识别项目时,我在淘宝上花了整整三天对比各种硬件参数。当时最纠结的就是摄像头模块——普通USB摄像头才30块钱,而官方推荐的Raspberry Pi Camera Module V2要200多。后来实测发现,这差价真不能省。 …...

SmallThinker-3B-Preview部署教程:边缘设备一键运行的保姆级指南
SmallThinker-3B-Preview部署教程:边缘设备一键运行的保姆级指南 想试试在树莓派或者你的旧笔记本上跑一个自己的AI助手吗?今天要聊的SmallThinker-3B-Preview,可能就是你的菜。它是个小个子,但本事不小,专门为那些内…...

警惕!新型U盘蠕虫伪装文档传播:实测火绒5.0查杀+防御全攻略
深度解析U盘蠕虫病毒:从防御到查杀的全面安全指南 1. 新型U盘蠕虫病毒的运作机制剖析 U盘蠕虫病毒近年来呈现出越来越复杂的传播方式和技术手段。这类病毒通常利用Windows系统的自动播放功能(AutoRun.inf)或注册表劫持技术进行传播࿰…...