linux内核篇-进程及其调度
介绍一个程序从源文件到进程执行的过程
1、编译链接(源文件到二进制文件)
Linux 下面二进制的程序也要有严格的格式,称为ELF(Executeable and Linkable Format,可执行与可链接格式) ,这个格式可以根据编译结果的不同,分为不同的格式。
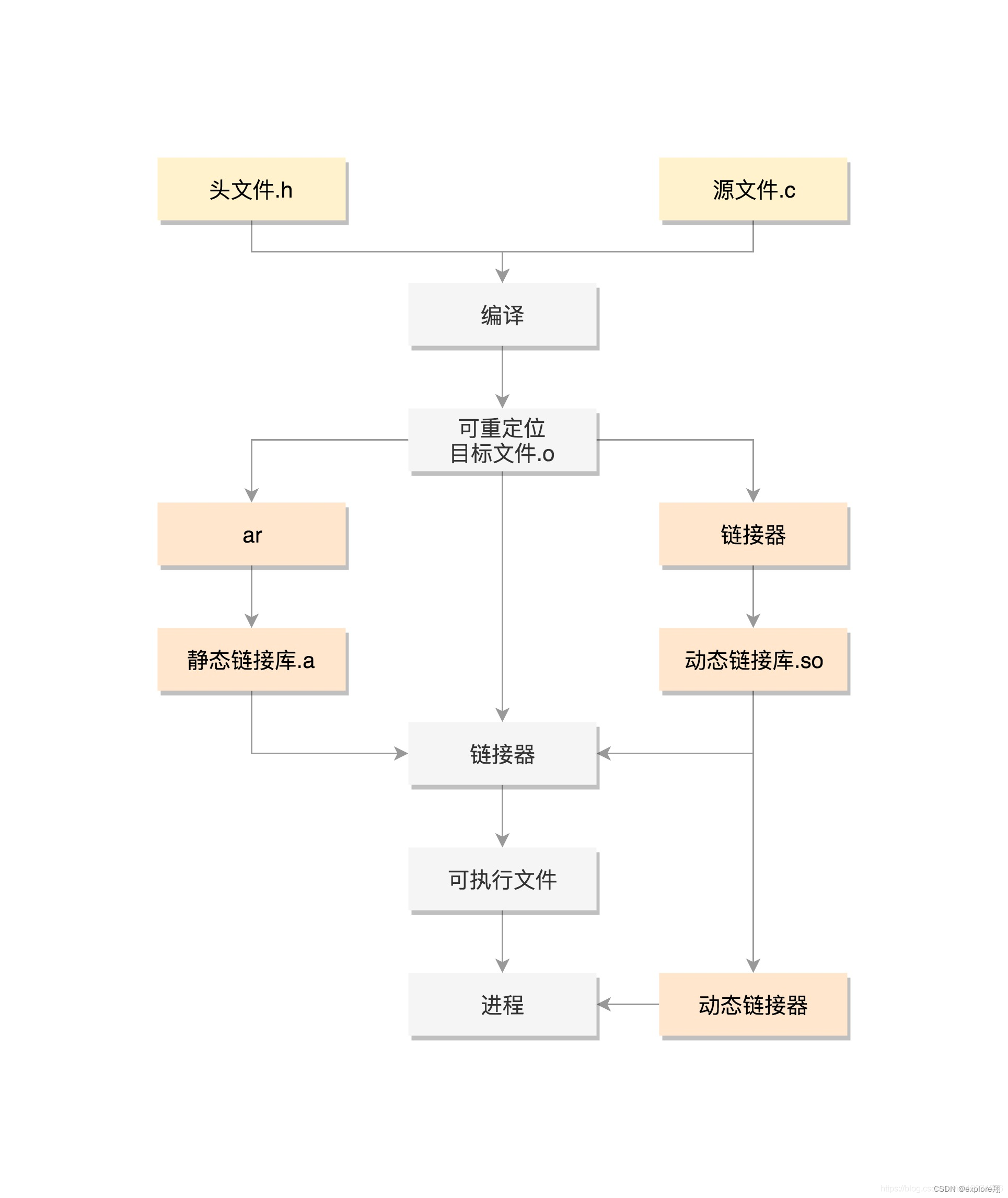
这里要复习一下静态链接和动态链接的特点以及整个过程。
静态库是编译的时候就加入到程序中;优点是运行快,发布时无需提供库文件;缺点是程序大,更新比较麻烦;
动态库是运行时动态调用的,优点是小,多个程序公用节省内存;缺点是慢,发布需要提供库。
静态库制作和使用:
gcc 源文件 -c :生成可重定位文件
ar rcs xx.a xx.o 通过ar工具生成静态库
使用: gcc main.c -lxx -L 路径 其中动态库要去掉lib前缀和.a后缀
动态库:
gcc -shared -fpic xx.c -o libxx.so
使用和静态库一样
fpic用于生成位置无关的代码。
整体:预处理(宏展开,删空格)、编译(.s的汇编文件)、汇编(.o的可重定位文件)、链接(链接多个.o文件以库文件组成可执行文件或者动态库)
gcc不加参数直接生成可执行文件, -o是修改生成可执行文件的名字;-c代表只生成可重定位的.o文件;
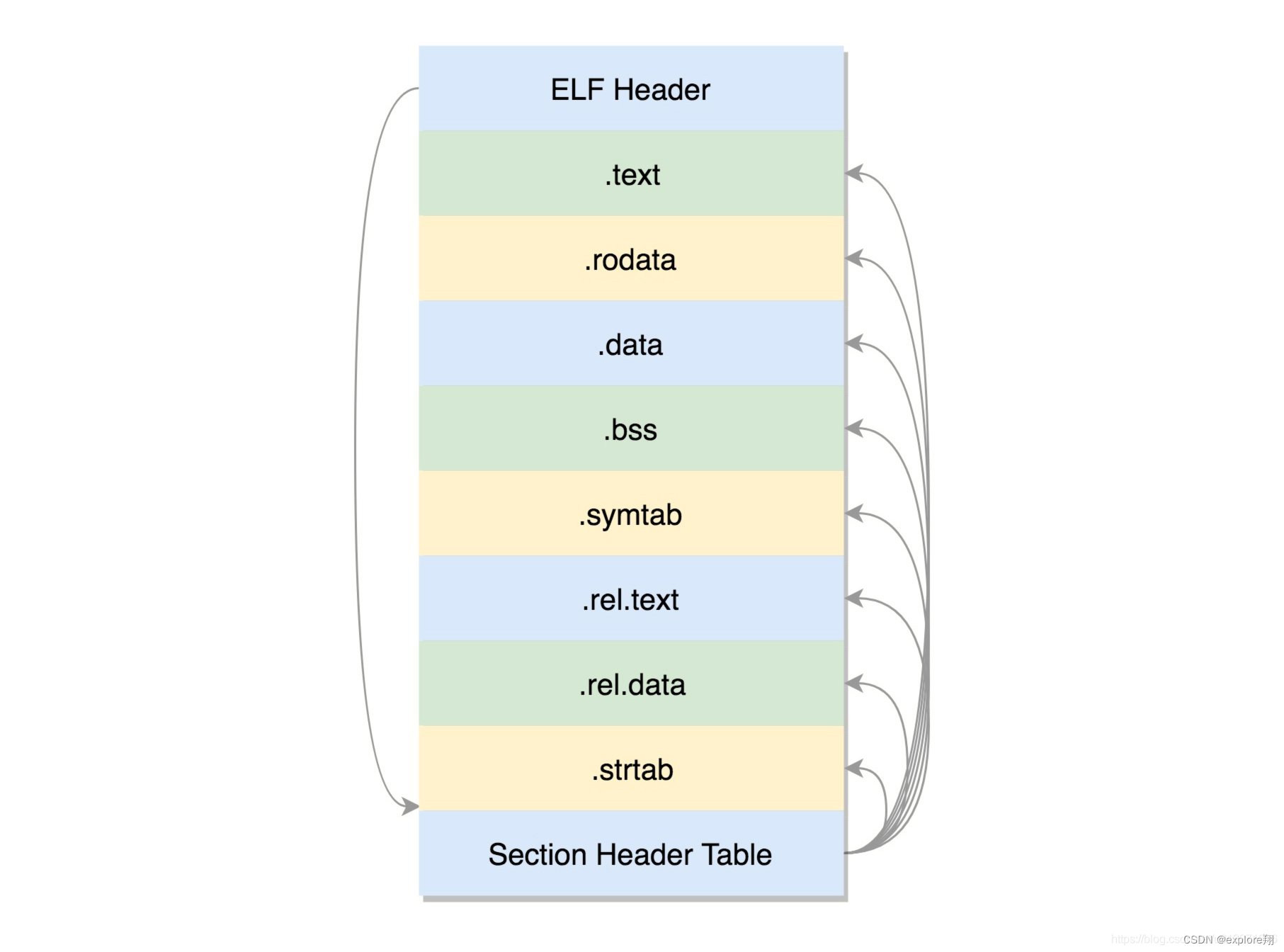
(主要有ELF头,以及元数据的信息(多少节,偏移等),代码区,全局变量区,只读数据区,符号表等,以及rel重定位的节) 没有局部变量的。局部变量是存放在栈里面的,是程序运行过程中随时分配空间,随时释放的
下面是连接后的可执行文件
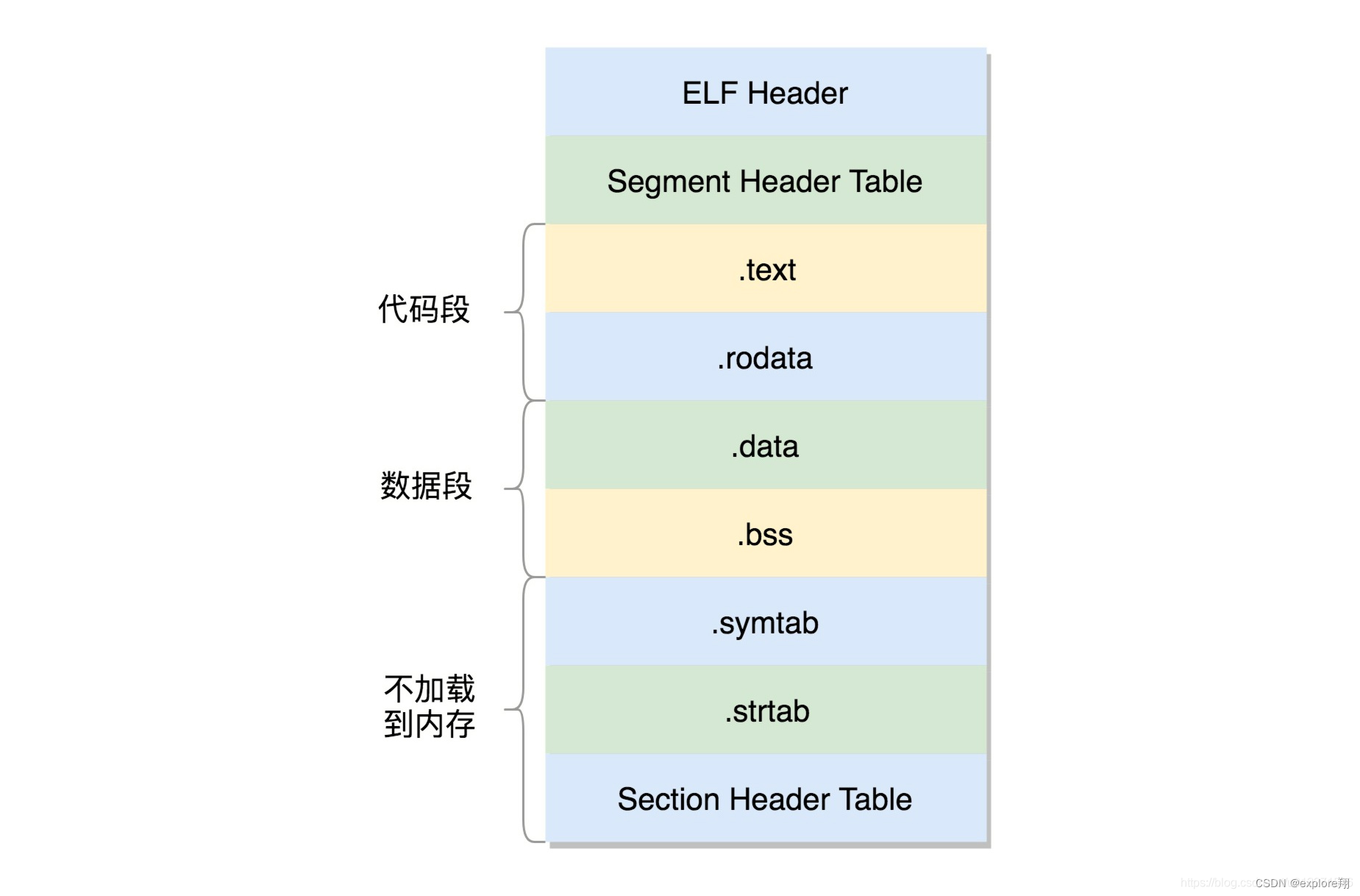
这个格式和.o 相似,还是分成一个个的 section, 并且被节头表描述,只不过这些section 是多个.o 文件合并过的。因为这些section被分成了需要加载到内存里面的代码段、数据段,和不需要加载到内存里面的部分(符号表字符表元数据等)。
将小的section 合成了大的段 segment ,并且再最前面加了一个段头表。这里面除了有对于段的描述之外,最重要的是p_vaddr,这个是这个段加载到内存的虚拟地址。
动态链接库,就是ELF 的第三种类型,共享对象文件。ELF 文件中还多了两个section ,一个是 .plt ,过程连接表(Procedure Linkage Table ,PLT )一个是.got.plt ,全局偏移量表(Global Offset Table ,GOT)
内存的程序如何变成进程
对于ELF的二进制文件,是如何加载到内存执行的呢?
学过了系统调用一节,你会发现,原理是exec 这个系统调用最终调用的 load_elf_binary。
所以实际上就是:execv用户层面-内核的execv函数-do-execv函数- load_elf_binary函数。通过用户到内核的系统调用,把可执行文件加载到进程的内存中执行。
pe -ef可以查看进程情况
进程树:
系统启动的 init 进程就是祖宗进程。祖宗进程会通过kernel_thread函数生成1号和2号进程。
2号进程kthreadd是负责内核进程调度管理的。
1号进程就是负责用户第一个进程的创建,涉及到内核态到用户态的转换以及根文件系统的挂载,1 号进程是 /sbin/init ,如果在centos7里面,查看是软连接到 systemd 的。
1号进程会启动很多的 daemon 进程,为系统运行提供服务(比如文件系统驱动,周期性任务等),然后就是启动getty让用户登录pts/0,登录后运行 shell,用户启动的进程都是通过shell 运行的,从而行程一颗进程树。
ps -ef 这个命令的父进程是bash;bash的父进程是pts;pts的父进程是 sshd。
tty 问号说明,一般不是前台启动的,是后台的服务。
用户态的不带中括号;内核态的带中括号。
线程:
为什么需要多线程编程?
如果一个任务是可以拆解的或者CPU利用率不高的,前后相关性没有很大关联,就可以并行执行。比如IO密集型的任务
比如有个开发任务,要开发200个页面,可以拆分成10个任务,每个任务负责10个页面,并行开发,完成之后再做一次整合,比一次开发200个页面快很多。
可以用多个进程实现并发吗? 不划算
立项成本。创建进程占用资源太多
(关于进程线程协程切换的时间具体是多少也有一篇文章介绍,进程创建要有PCB,分配内存、文件等资源,赋值到PCB(比较耗时),然后插入PCB链表;线程公用进程的地址空间,只分配自己的栈以及一些寄存器耗时小,线程前切换也比较方便)
沟通成本。进程之间的通信需要再不同的内存空间传来传去,无法共享
除了任务可以并行的需求外,还需要将前台和后台的任务隔离开,所以就需要创建额外的线程去处理后台的任务。
**关于多线程的知识可以看另外几篇的文章。**这里只是简单介绍一下
可以用pthread_xxx,也可以用C++11的std::thread;
将线程访问的数据分为三类
线程本地栈上的本地数据。
函数执行过程中的局部变量,每个线程都有自己的栈空间,栈的大小可以通过unlimit -a来查看。
为了避免线程之间的栈空间踩踏,线程栈之间还有有小块区域,用来隔离保护各自的栈空间,一个线程踏入隔离区,会引发段错误。
进程里共享的全局变量。全局变量在一个进程里是共享的,如果两个线程一起修改,就会有问题,需要一种机制来保护他们。锁机制(关于锁又有很多可以说的了)
线程私有数据。不常用-thread_local.(虽然可以共同访问,但是只会记录拥有者的修改)
锁最常用的互斥锁,自旋锁,原子锁的概念区别看另一篇。注意C++11里面提供了RAII形式的lock_guard和unique_lock。二者区别是后者更灵活,可以延迟上锁和解锁时间,有lock,unlock接口。而前者没有这些接口,构造函数析构函数自动执行。代价是后者性能差一点。
以及条件变量配合使用。当有某种同步关系的时候,不要让别人一直等着,wait阻塞一下,准备好了notify别人再执行。其中惊群现象可以用一个while解决,即达到条件再判断一次是不是真的达到了。
一般用PAUSE,不是while。
(对于调度时间简单理解:
系统调用:200ns级别,只是用户态到内核态的切换开销,比较小了;
进程切换:多任务操作系统,进程切换必不可少。进程切换涉及到页表全局目录切换、TLB、内核态的堆栈切换、硬件上下文,比较耗时的。以及还有缓存不热的间接开销。平均每次上下文切换耗时3.5us左右
对于线程,从操作系统视角看,调度上和进程没有什么区别,都是在等待队列的双向链表里选择一个task_struct切到运行态而已。只不过轻量级进程和普通进程的区别是可以共享同一内存地址空间、代码段、全局变量、同一打开文件集合而已。 大约每次线程切换开销大约是3.8us左右。从上下文切换的耗时上来看,Linux线程(轻量级进程)其实和进程差别不太大。
所以从代价来看,多线程错进程切换代价差别不大,主要的是进程持有的资源比线程大得多,所以有多线程替代多进程了,其他的以及多进程通信麻烦
对于协程,切换只需要120ns,很快,是进程的1/30,在空间上,协程初始化创建的时候为其分配的栈有2KB。而线程栈要比这个数字大的多,可以通过ulimit 命令查看,一般都在几兆,作者的机器上是10M。如果对每个用户创建一个协程去处理,100万并发用户请求只需要2G内存就够了。
实际上,线程池+IO多路复用比协程效果好得多,线程池避免频繁地创建销毁线程,协程的调度需要自己写,而线程的调度是操作系统完成的,肯定比我们写的好。协程主要的作用是同步写法异步性能。
再进一步,因为我们实现的是有栈协程对称协程,现在很多语言已经有自己的异步运行时了,比如rust,go,以及C++20也有了,关键字就是await,async, 这可以真正实现协程。go的协程调度已经是语言层面了,rust是规定了最基本的,上层根据需求自己写。如果是这种协程和线程池比,应该是协程更胜一筹的。毕竟创建和切换都轻量。
)
进程数据结构
进程或者线程,到了内核中**,统一都叫任务**(Task),由一个统一的结构 task_struct 进行管理。
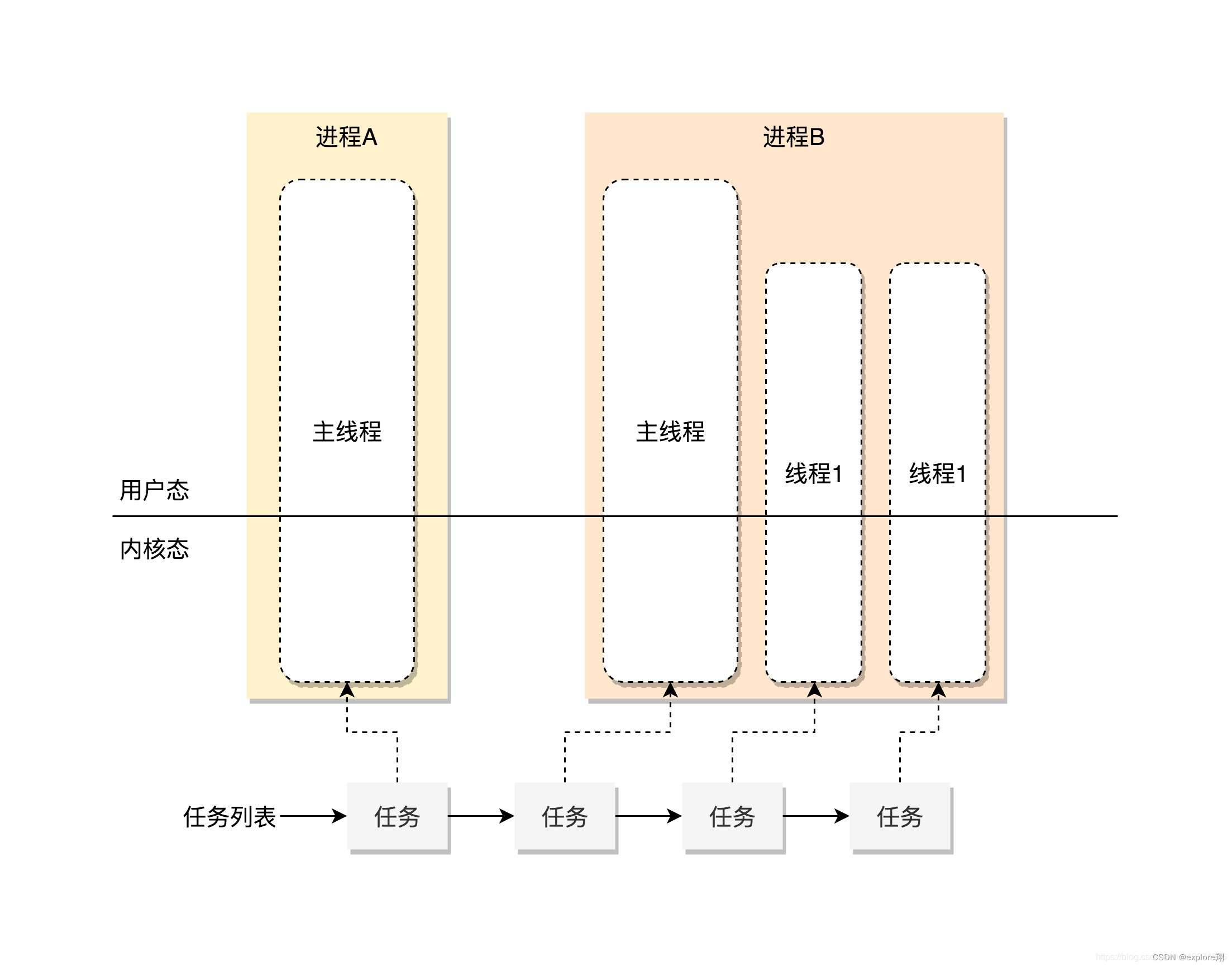
如何管理这些任务呢?
1/Linux 内核先弄一个链表,将所有的task_struct 串起来。
2 task_struct 里面涉及到任务ID的有下面几个:
pid_t pid tid; 进程id,线程id
pid_t tgid; 线程组Id,就是进程的id
struct task_struct *group_leader;
(一个进程,如果只有主线程,pid是自己,tgid 是自己,group_leader 指向的还是自己
一个进程,如果创建其他线程。线程有自己的pid,tgid是进程的主线程的pid,group_leader 指向的就是进程的主线程。有了 tgid,我们就知道 tast_struct 代表的是一个进程还是一个线程)
3、信号处理
task_struct就是一些信号处理的字段。
被阻塞暂不处理(blocked);
尚待处理(pending)
正在处理(sighand)
处理的结果:忽略、结束进程
信号处理函数:默认使用用户态的函数栈;
4、任务状态
volatile long state; /* -1 unrunnable, 0 runnable, >0 stopped */
TASK_RUNNING 并不是说进程正在运行,而是表示进程在时刻准备运行的状态。当处于这个状态的进程获得时间片的时候,就是在运行中;如果没有获得时间片,就说明它被其他进程抢占了,在等待再次分配时间片。相当于就绪状态。
在运行中的进程,一旦要进行一些I/O的操作,需要等待I/O完毕,这个时候会释放CPU,进入睡眠状态。在Linux中,有两种睡眠状态:
1、TASK_INTERRUPTIBLE (可中断的睡眠状态):
在浅睡眠,等待I/O完成。 一个信号来的时候,进程还是要被唤醒。唤醒后进行信号处理。 程序员可以根据自己的意愿来写处理函数,例如收到某些信号,放弃等待这个I/O操作完成,直接退出,或者收到某些消息继续等待。
2、TASK_UNINTERRUPTIBLE (不可中断的睡眠状态):
不可被信号唤醒,只能死等I/O操作完成。
一旦I/O操作因为特殊原因不能完成,这个时候谁也叫不醒这个进程。
kill 也是一个信号,kill 信号也被忽略。
除非重启电脑,没有其他办法。
因此这个是比较危险的事情,不然不要把进程设置成 TASK_UNINTERRUPTIBLE
TASK_STOPPED :是在进程接收到 SIGSTOP(kill -19,暂停进程相当于加了断点,SIGSTP是尽可能停止,可以捕获忽略)、SIGTTIN(crtl+c前台进程终止信号可自定义信号处理函数)、 SIGKILL(kill -9,不能忽略和重写,sigterm kill-15可以捕获忽略)信号之后进入该状态。
TASK_TRACED:进程被debugger 等进程监视,进程执行被调试程序所停止。 当一个进程被另外的进程所监视,每一个信号都会让进程进入该状态。
一旦一个进程要结束,先进入的是EXIT_ZOMBIE状态,但是这个时候它的父进程还没有使用 wait() 等系统调用来获知它的终止信息,此时进程就成了僵尸进程。
EXIT_DEAD 是进程的最终状态
(僵尸进程和孤儿进程
正常情况下:子进程由父进程创建,子进程再创建新的进程。父子进程是一个异步过程,父进程永远无法预测子进程的结束,所以,当子进程结束后,它的父进程会调用wait()或waitpid()取得子进程的终止状态,回收掉子进程的资源。
孤儿进程:父进程结束了,而它的一个或多个子进程还在运行,那么这些子进程就成为孤儿进程(father died)。子进程的资源由init进程(进程号PID = 1)回收。僵尸进程:子进程退出了,但是父进程没有用wait或waitpid去获取子进程的状态信息,那么子进程的进程描述符仍然保存在系统中,这种进程称为僵死进程。
危害
这种机制是:在每个进程退出的时候,内核会释放所有的资源,包括打开的文件,占用的内存等。但是仍保留一部分信息(进程号PID,退出状态,运行时间等)。直到父进程通过wait或waitpid来取时才释放。
但是这样就会产生问题:如果父进程不调用wait或waitpid的话,那么保留的信息就不会被释放,其进程号就会被一直占用,但是系统所能使用的进程号是有限的,如果大量产生僵死进程,将因没有可用的进程号而导致系统无法产生新的进程,这就是僵尸进程的危害
孤儿进程是没有父进程的进程,它由init进程循环的wait()回收资源,init进程充当父进程。因此孤儿进程并没有什么危害。
补充:任何一个子进程(init除外)在exit()之后,并非马上就消失掉,而是留下一个称为僵尸进程的数据结构(进程号PID,退出状态,运行时间),等待父进程去处理。如果父进程在子进程exit()之后,没有及时处理,出现僵尸进程,并可以用ps命令去查看,它的状态是“Z”。
为什么会产生Z进程:当父进程没有读取到子进程的exit信号,就会有僵尸进程。
解决办法:
1、直接杀死僵尸进程的父进程,这样就变成孤儿进程,被init进程回收(这样不好)
2、父进程用wait,waitpid等待子进程结束,这会导致父进程阻塞;更好的是下面信号的方式
3、子进程死后会发送一个sigchd信号,父进程只要signal(sigchild,sigign).表示不关心子进程的结束,这样内核就会直接回收,不再给父进程法信号了。
4、两次fork方法。子进程fork孙进程后立即退出,孙子完成任务后就变成孤儿进程init回收。
)
进程调度相关:
调度器,优先级,调度策略等等
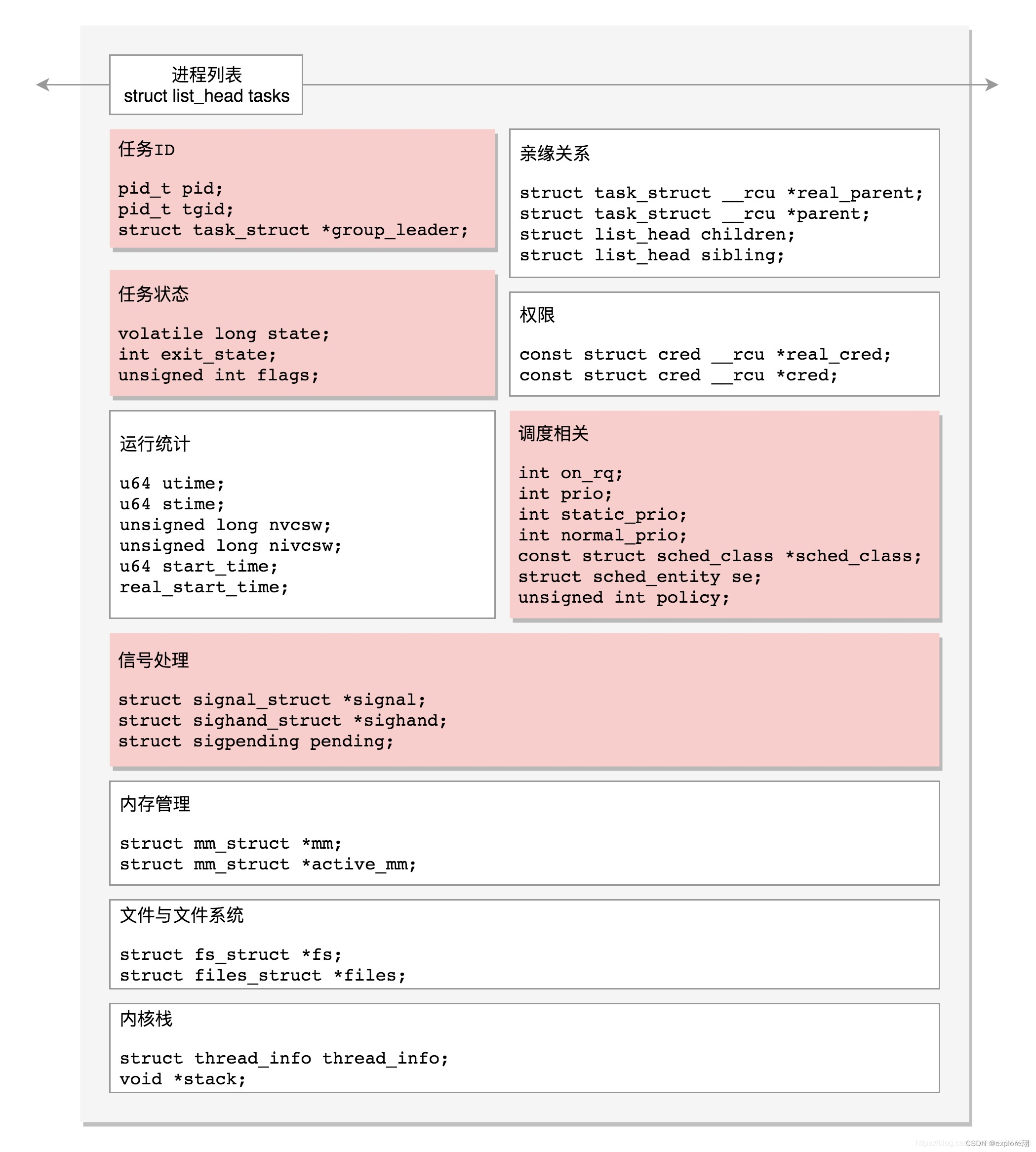
这个图总结了,task_struct的结构。主要包括了内存、文件管理相关的、内核栈、以及调度相关的(比如状态,信号处理及结果,调度器,优先级)、统计信息(运行时间开始时间等),id。
继续说结构:
运行统计信息
u64 utime;//用户态消耗的CPU时间
u64 stime;//内核态消耗的CPU时间
unsigned long nvcsw;//自愿(voluntary)上下文切换计数
unsigned long nivcsw;//非自愿(involuntary)上下文切换计数
u64 start_time;//进程启动时间,不包含睡眠时间
u64 real_start_time;//进程启动时间,包含睡眠时间
进程亲缘关系
parent 指向其父进程。当它终止时,必须向它的父进程发送信号
children 表示链表的头部,链表中的所有元素都是它的子进程
sibling 用于把当前进程插入到兄弟链表中
进程权限
uid gid euid egid rwxrwxrwx chgmod这些。(文件所有者、同组、其他用户权限)
UID/GID 实际用户ID和实际组ID,即登陆时候的用户名,比如我是lirobins登陆,那么UID/GID 为lirobins/lirobins
EUID/EGID 有效的用户ID和有效的组ID,它们指定了访问目标的权限。
当前登录用户为my,apps文件的ls -l 后的用户为my,组为mygroup,此时UID=my,GID=mygroup,EUID=my,EGID=mygroup。
当前登录用户为my,apps文件的ls -l 后的用户为other,组为othergroup,此时UID=my,GID=mygroup,EUID=other,EGID=othergroup。并且my用户无法访问other用户的文件。
SUID/SGID 针对文件而讲述的概念,他可以修改当前进程的EUID/EGID
chmod u+s filename # 设置SUID位
chmod u-s filename # 去掉SUID设置
chmod g+s filename # 设置SGID位
chmod g-s filename # 去掉SGID设置
.SUID权限
当一个具有执行权限的文件设置SUID权限后,用户执行这个文件时将以文件所有者的身份执行。
特点:只有可以执行的二进制程序才能设定SUID权限(可执行)
命令执行者要对该程序拥有x(执行)权
命令执行者在执行该程序时获得该程序文件属主的身份
SUID权限只在该程序执行过程中有效,就是说身份改变只在执行过程中有效。
可执行文件/usr/bin/passwd所属用户是root(UID为0),此文件被设置了SUID权限。当一个UID为1000、GID为1000的用户执行此命令时,产生的进程RUID和RGID分别是1000和 1000,EUID是0、EGID是1000。
user1用户登陆,取得了一个bash的shell类型。然后 执行passwd命令。在这个命令执行过程中,执行命令的身份被切换成了root用户。 在用户权限上 有一个s,这就是说明该文件设置了SUID权限。也就是说在普通用户在执 行passwd命令的时候是使用root的身份。
还有capabilities 更细粒度的权限,用位图表示权限
内存管理
每个进程都有自己独立的虚拟内存空间,这里需要一个数据结构来表示,mm_struct
文件与文件系统
每个进程都有一个文件系统和打开文件的数据结构:
用户态函数栈
用户态中,程序的执行往往是一个函数调用另一个函数,函数调用通过栈来执行的,函数调用就是指令跳转,重点是参数和返回地址怎么传递过去。具体的看另一篇。
内核态函数栈(用于进程实现系统调用)
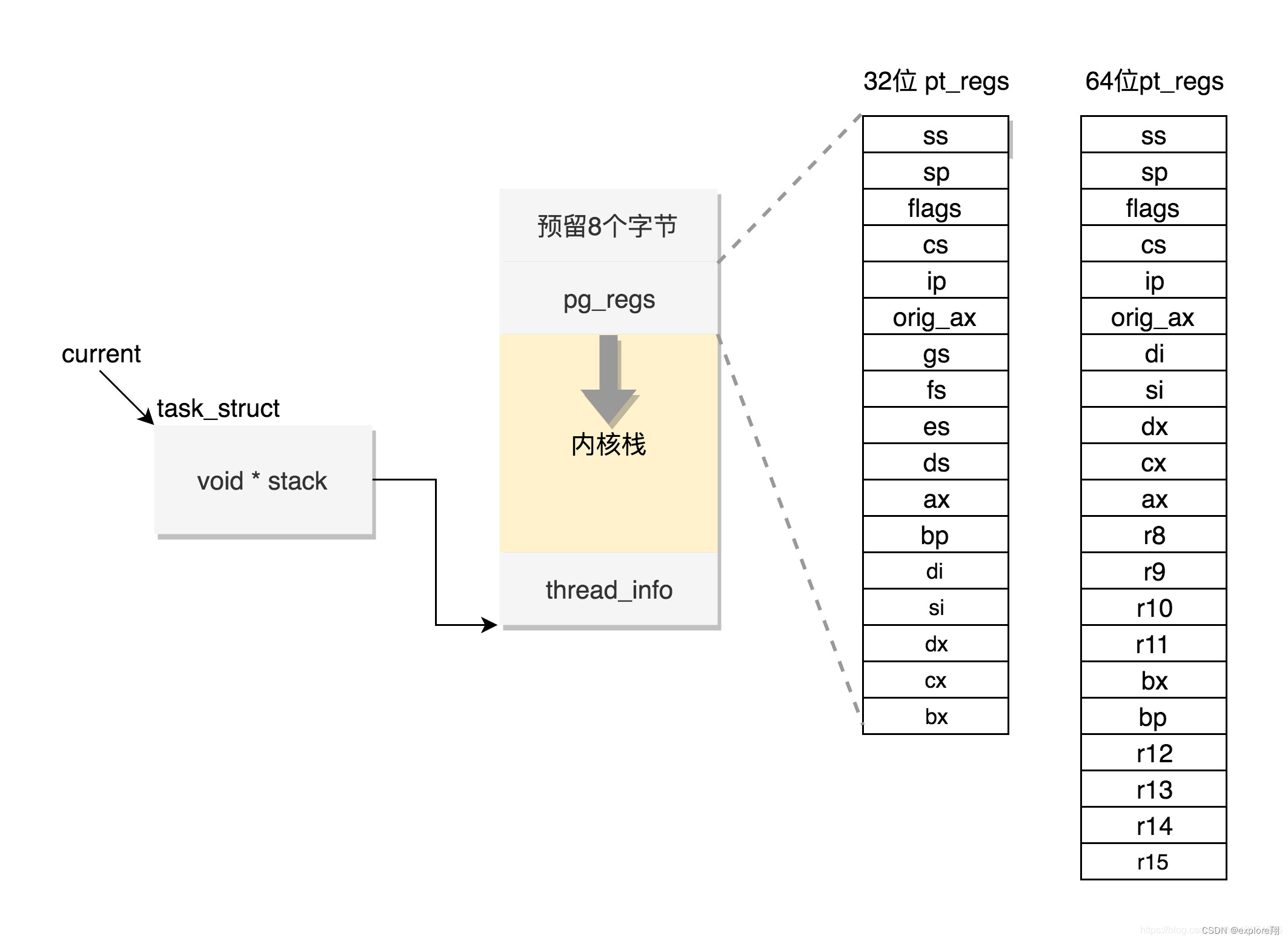
成员变量 stack ,在内核中各种各样的函数调用就用到了。Linux 给每个task 都分配了内核栈。
内核栈分布:空间最低的位置是一个 thread_info 结构,这个结构是对 task_struct 结构的补充。
因为 task_struct 结构庞大但是通用,不同的体系结构就需要保存不同的东西,与体系结构有关的,都放在 therad_info 里。
内核代码里有这样一个 union ,将 thread_info 和 stack 放在一起
在内核栈的最高地址端,存放的是另一个结构 pt_regs.当系统调用 从用户态到内核态的时候,要做的第一件事情,就是将用户态运行过程中的CPU 上下文保存起来,主要就是保存在这个结构的寄存器变量里 pt_regs。
调度,如何制定项目管理流程
在Linux里面,进程大概可以分为两种:
一种叫做实时进程,也就是需要尽快执行返回结果的那种,优先级一般比较高
一种叫做普通进程,大部分进程其实都是这种,按照正常流程完成即可
很显然,对于这两种进程,我们的调度策略肯定是不同的。
在task_struct中,有一个成员变量,叫做调度策略:对于实时进程,优先级的范围是0~99 ;
对于普通进程,优先级是100~139
SCHED_FIFO、SCHED_RR、SCHED_DEADLINE都是实时进程的调度策略:
SCHED_FIFO :高优先级的进程可以抢占低优先级的进程;而相同优先级的进程先来先服务
SCHED_RR 轮流调度算法:高优先级的进程可以抢占低优先级的进程;而相同优先级的任务采用时间片算法,当相同优先级的任务用完时间片会被放到队列外部,以保证公平性
SCHED_DEADLINE :按照任务的deadline进行调度。当产生一个调度点的时候,DL调度器总是选择其deadline具体当前时间点最近的那个任务执行
对于普通进程的调度策略有,SCHED_NORMAL、SCHED_BATCH、SCHED_IDLE。
SCHED_NORMAL:普通进程
SCHED_BATCH:后台进程,这些进程可以默默执行,不要影响需要交互的进程,可以降低它的优先级
SCHED_IDLE:特别空闲的时候才跑的进程
调度策略的执行逻辑,就封装在这里面,它是真正干活的那个。
sched_class有几种实现:
stop_sched_class :优先级最高的任务会使用这种策略,会中断所有其他线程,而且不会被其他任务打断
dl_sched_class :对应上面的 deadline 调度策略;
rt_sched_class:就对应 RR 算法或者 FIFO 算法的调度策略,具体调度策略由进程的task_struct->policy 指定;
fair_sched_class:普通进程的调度策略
idle_sched_class: 就是空闲进程的调度策略。
我们平常都是普通进程,也就是说fair_sched_class用的最多。fair_sched_class,顾名思义,对普通进程来讲,公平是最重要的
调度器的数据结构
完全公平调度算法
在linux里面,实现了一个基于CFS(Completely Fair Scheduling,完全公平调度)的调度算法。其实现原理是:
安排一个虚拟进行时间,如果一个进程在执行,随着时间的增长,也就是一个个tick的到来,进程的vruntime将不断增大。没有得到执行的进程vruntime不变显然,那些 vruntime 少的,原来受到了不公平的对待,需要给它补上,所以会优先运行这样的进程。
从上面可以推导出,CFS需要一个数据结构来对vruntime进行排序,找出最小的那个。
(不但查询要快,而且因为经常变,所以更新也要快)
能够平衡查询和更新速度的树,一般用的是红黑树。红黑树的节点是应该包括vruntime的,称为调度实体。如果这个进程是个普通进程,则通过sched_entity,将自己挂载在这颗红黑树上。
那这颗红黑树放在哪里呢?一个任务队列中
每个CPU都有自己的struct rq结构,用于描述在此CPU上所运行的所有进程,其中包括一个实时进程队列rt_rq和一个CFS运行队列cfs_rq
在调度时,调度器首先会先去实时进程队列找是否有实时进程需要运行;如果没有,才会去CFS运行队列中找是否有进程需要运行
串起来看:每个CPU都有自己的队列rq,这个队列里面包含多个子队列,比如rt_rq和cfs_rq,不同的队列有不同的实现方式,cfs_rq就是用红黑树实现的。当某个CPU需要找下一个任务执行的时候,会按照优先级依次调用类。先在实时队列找任务,没有的话再到fair_sched_class被调用,它会在cfs_rq上找下一个任务。
调度类涉及的函数就是 向就绪队列中添加一个进程,当某个进程进入可运行状态时,调用这个函数;删除一个进程;pick_next_task 选择接下来要运行的进程;等等。
前面说的主要是如何选择下一个任务。下面要说什么时候开始选择。
调度主要有两种方式
方式一:A任务做着做着,发现里面有一条指令sleep,就是要休息一下,或者在等待某个IO时间。那就没有办法,就要主动让出CPU,然后就可以开始做B任务了(主动调度)
方式二:A任务做着做着,旷日持久,实在受不了了。项目经理介入了,说这个任务A先听听,B任务也要做一下,要不然B任务就该投诉了(抢占式调度)
主动调度一般发生在网络IO等待,用不到CPU时选择主动调度schedule()。调度完成的事情:
1、在当前的CPU上,我们取出任务队列rq。task_struct *prev指向这个CPU的任务队列上面正在运行的那个进程curr。为啥是prev?因为一旦将来它被切换下来,那它就成为了前任了。
2、
`next = pick_next_task(rq, prev, &rf);
clear_tsk_need_resched(prev);
clear_preempt_need_resched();
`
获取下一个任务,task_struct *next指向下一个任务。pick_next_task已经说过了,如果不是实时的,就是在红黑树取最左边的节点。更新前任的虚拟时间放回到红黑树中。set_next_entity将继任者设为当前任务
3、第三步就是进行上下文切换,继任者进程正式进入运行。
上下文切换主要干两件事情,一是切换进程空间,也就是虚拟内存(页表块表等);二是切换寄存器和CPU上下文(这里其实就是项目中协程切换的原理了)。
抢占式调度
最常见的现象就是一个进程执行时间太长了,就会切换到另一个进程。主要用时钟中断处理函数会调用scheduler_tick()
void scheduler_tick(void)
{int cpu = smp_processor_id();struct rq *rq = cpu_rq(cpu);struct task_struct *curr = rq->curr;
......curr->sched_class->task_tick(rq, curr, 0);cpu_load_update_active(rq);calc_global_load_tick(rq);
......
}这个函数先获取当前CPU的运行队列,然后去这个队列上获取正在运行中的进程的task_struct,然后调用这个task_struct的调度类task_tick函数,顾名思义这个函数就是用来处理时钟事件的。
如果当前运行的进程是普通进程,调度类为fair_sched_class,调用的处理时钟的函数为task_tick_fair,实现如下:根据当前进程的task_struct,找到对应的调度实体sched_entity和cfs_rq队列,调用entity_tick:update_curr更新当前进程的vruntime,然后调用check_preempt_tick,顾名思义,就是检测是否是时候被抢占了。
怎么判断是否可以被抢占?
sum_exec_runtime-prev_sum_exec_runtime 就是这次调度占用实际时间。如果这个时间大于 ideal_runtime,则应该被抢占了。
除了这个条件之外,还会通过 __pick_first_entity 取出红黑树中最小的进程。如果当前进程的 vruntime 大于红黑树中最小的进程的 vruntime,且差值大于 ideal_runtime,也应该被抢占了。
当发现当前进程应该被抢占,不能直接把它踢下来,而是把它标记为应该被抢占。为什么呢?因为所有进程切换都必须等待正在运行的进程调用__schedule才行,所以这里只能先标记一下。
另一个可能抢占的场景是当一个进程被唤醒的时候当被唤醒的进程优先级高于CPU上的当前进程,就会触发抢占。到这里,你会发现,抢占问题只做完了一半。就是标识当前运行中的进程应该被抢占了,但是真正的抢占动作并没有发生。
真正的抢占还需要时机,也就是需要那么一个时刻,让正在运行中的进程有机会调用一次__schedule。 (代码里面不可能像主动调度一样写一个schedule函数,所以一定要规划几个时机,这个时机分为用户态和内核态)
对于用户态的进程来讲,从系统调用中返回的那个时刻,是一个被抢占的时机。可以看到在exit_to_usermode_loop函数中,上面打的标记起了作用,如果被打了_TIF_NEED_RESCHED,调度shcedule进行调度:选择一个进程让出CPU,做上下文切换。
对于用户态的进程来讲,从中断中返回的那个时刻,也是一个被抢占的时机
(二者不一样吗,系统调用不就是要陷入中断?int 80)
对内核态的执行中,被抢占的时机一般发生在preempty_enbale()中
在内核态的执行中,有的操作是不能被中断的,所以在进行这些操作之前,总是先调preempt_disable()关闭抢占,当再次打开的时候,就是一次内核态代码被抢占的机会。
内核态也会遇到中断的情况,当中断返回的时候,如果返回的仍然是内核态,这个时候也是一个被抢占的时机。
总结一下:
调度的基本策略、基本结构、调度两种方式(主动和抢占)。调度主要是选择下一个进程,进程切换(虚拟内存和CPU上下文)。抢占式调度先标记一下,再合适的时机真正调度(比如系统调用返回、中断返回时)
下面说一下进程和线程的创建
fork在内核里面做了什么事情?
fork解封装成sys_fork,宏里面定义调用do_fork函数。
做的第一件大事就是copy_process,复制的是task_struct这个进程数据结构。
主要做的事情是:alloc一块task_struct空间;alloc_thread_stack_node 创建内核栈,分配一个连续的THREAD_SIZE的内存空间,赋值给task_struct的void *stack成员变量;调用memcpy复制task_struct;
调用setup_thread_stack 设置thread_info。
这一步就是alloc分配空间,memcpy复制;
接下来就是权限相关了,copy_creds主要做了下面几件事情:
retval = copy_creds(p, clone_flags);也是分配cred结构并memcpy复制;
接下来是统计信息重置,比如用户内核态运行时间值为0,开始时间(睡眠和不包含睡眠)设置;
retval = sched_fork(clone_flags, p);设置调度相关的变量。
接下来,copy_process开始初始化与文件和文件系统相关的变量:
retval = copy_files(clone_flags, p);主要用于复制一个进程打开的文件信息,fd文件描述符
retval = copy_fs(clone_flags, p);主要用于复制一个进程的目录信息。根目录,当前目录的文件系统
接下来,copy_process开始初始化与信号相关的变量:
接下来,copy_process开始复制进程内存空间
retval = copy_mm(clone_flags, p);copy_mm函数中调用dup_mm,分配一个新的mm_struct,调用memcpy复制这个函数;
dup_mmap用于复制内存空间中内存映射的部分(mmap除了可以分配大块的内存,还可以将一个文件映射到内存中,方便可以像读写内存一样读写文件)
接下来,copy_process开始分配pid、设置tid、group_leader,并且建立进程之间的亲缘关系。
总结一下:首先就是分配task_struct空间和内核栈空间,并用memcpy复制;接着还有文件权限、统计信息、文件系统、内存空间(文件映射)、pid,亲缘设置等。
fork的第二件大事:唤醒新进程
_do_fork 做的第二件大事是 wake_up_new_task。新任务刚刚建立,有没有机会抢占别人,获得CPU呢?
首先,将进程的状态设置为TASK_RUNNING
activate_task函数会调用enqueue_task加入到队列中,设置更新一些统计量(队列数量,虚拟运行时间等);
3、然后,wake_up_new_task 会调用check_preempt_curr,看是否能够抢占当前进程。(fork是一个系统调用,从系统调用返回的时候,就是一个抢占的好时机,如果父进程判断自己已经被设置为TIF_NEED_RESCHED,就让子进程先跑,抢占自己)
总结,我们知道了进程的创建过程,复制task_struct,以及唤醒新进程看看是不是要抢占;前面调度策略已经说了,一般抢占调度一个场景就是一个进程被唤醒的时候,如果优先级高就会抢占。
linux线程的创建
**其实在内核中,线程和进程没有区别的,调度进程和线程都是一样的。都是统一的task_struct结构体放在链表中,调度策略也一样。连pid都一样。唯一不同的就是线程用的是进程的内存空间以及文件系统不用复制了,直接copy_vm标记。**五大结构仅仅是引用计数加一(文件描述符,文件系统,内存空间,信号),也就是线程共享进程的数据结构。
线程不是一个完全由内核实现的机制,它是由内核态和用户态合作完成的
pthread_create不是一个系统调用,是glibc库的一个函数。最重要的就是有一个入口函数,代表线程要完成的事情。因此
在用户态也有一个用于维护线程的结构,就是这个pthread结构(线程id就是它维护的):每个线程都有自己的栈。因此需要创建线程栈。(因为是一个函数,只要有函数调用就会有栈帧)
线程栈的分配是在进程的堆空间里分配的,只不过它是固定的一块大小而已。线程堆的分配在windows中是共享的,因此需要同步机制的保护。而linux中线程的堆是独占的,不需要同步保护,销毁时自动回收了。
接下来就是内核态的栈。调用的是系统调用clone,在copy_process函数里面,task_struct复制一遍。其中Pid变了,tgid没变,代表新建了线程。
相关文章:
linux内核篇-进程及其调度
介绍一个程序从源文件到进程执行的过程 1、编译链接(源文件到二进制文件) Linux 下面二进制的程序也要有严格的格式,称为ELF(Executeable and Linkable Format,可执行与可链接格式) ,这个格式可…...

C#开发的OpenRA游戏之基地工程车执行部署命令
C#开发的OpenRA游戏之基地工程车执行部署命令 前面已经分析接收到网络命令后,可以拿到多个命令对象, 通过命令对象进行遍历,最终会在比较部署命令的类里相同,从而执行部署命令。 可见,网络游戏里的对象操作,都是通过网络发送给服务器,再从服务器返回消息来执行对象的动…...
米哈游的春招实习面经,问的很基础
米哈游的春招实习面经,主要考察了java操作系统mysql网络,这四个方面。 面试流程,共1小时,1min自我介绍,20min写题,剩下问题基础知识。 Java String,StringBuilder, StringBuffer区…...
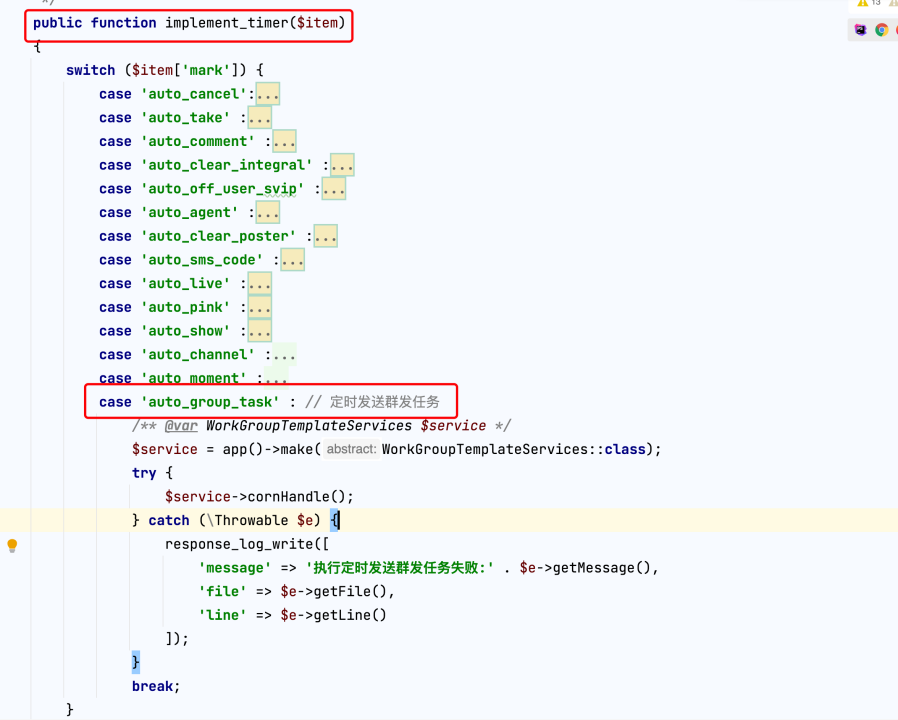
pro如何添加定时任务
Pro v2.4版本开始后台可以开关控制定时任务,那如何添加新的定时任务呢? 第一步:设置定时任务名称及标识; 文件app\controller\admin\v1\system\SystemTimer中task_name()方法 /**定时任务名称及标识 * return mixed */ public fu…...

bgp路由策略
* - valid 有效的, > - best 最佳的 上图中,有*和>,是有效最佳的。而没有*和没有>,是无效的,下一跳不可达 1--64511是公有AS 64512-65534为私有AS //属于哪个大的联盟 AS200 //连着一个子类AS 65002 //和子…...

chatGPT4.0编写性能测试报告
性能测试报告 测试概述 本次性能测试的目的是评估系统在高负载条件下的性能表现,以确保系统能够满足预期的性能需求。测试过程中,我们关注以下性能指标:响应时间、吞吐量、资源利用率(CPU、内存、磁盘、网络)以及错误…...

jpa多线程事务
百度都百度不到jpa多线程的事务回滚,废话少说,就是干, 实现思路(可看可不看,本人也不喜欢罗里吧嗦的,想直接看干货就跳过这里,直接执行代码): jpa本身是不支持多线程事务…...
:准备项目之SDK功能)
加密解密软件VMProtect教程(四):准备项目之SDK功能
VMProtect 是保护应用程序代码免遭分析和破解的可靠工具,但只有在正确构建应用程序内保护机制并且没有可能破坏整个保护的典型错误的情况下才能最有效地使用。 SDK 功能可以集成到受保护应用程序的源代码中,以设置受保护区域的边界,以检测调…...

夏令营教育小程序开发功能和优势有哪些?
随着人们生活水平的提高,对于孩子的教育问题也是越来越重视,无论是教育方式还是教育内容上都追求新颖、多样化。在暑假期间,很多家长也希望孩子能够在这个长假期之间参加一些活动,培养孩子兴趣的同时也丰富假期内容,让…...

Cocos CreatorXR 1.2.0 今日发布,正式支持 WebXR ,并开启 MR 之路
去年九月,Cocos CreatorXR v1.0.1 版本支持了 VR 内容创作,成为率先支持 XR 的国产引擎,今年三月,Cocos CreatorXR v1.1.0 版本实现了对 AR 内容开发的支持。在完成基本功能的建设后,更多开发者开始尝试使用 Cocos Cre…...

Linux 使用笔记(本人出品,必属精品)
文章目录 Part.I IntroductionChap.I 快应用Chap.II 课程所学 Part.II 基础知识Chap.X 杂记 Part.I Introduction Linux 是笔者在大四上学期学的,当时授课的刘老师现在还能偶尔见到。但是平时一般用 Windows,有机会接触 Linux 一般是偶尔在服务器上跑跑程…...
【2023 · CANN训练营第一季】初识新一代开发者套件 Atlas 200I DK A2 第二章——安装Atlas 200I DK A2跑通第一个案例
准备相关软件 包括一台PC机(空间大于10g),读卡器,32gsd卡,一根网线。 具体步骤: 开始烧录开发板镜像:将sd卡插入读卡器,将读卡器插入PC机的USB接口,根据相关链接在PC机下载制卡工具…...
concurrenthashmap
SizeCtl的用法 sizeCtl0或容量大小 (二个构造方法) sizeCtl>0(初始化或扩容后)扩容阈值 sizeCtl-1:正在初始化中 sizeCtl<-1:线程扩容中 知道为什么第一个线程扩容时2,后面的其他线程扩容…...

8年测试总结,项目/团队如何做自动化测试?效率价值?吐血整理...
目录:导读 前言一、Python编程入门到精通二、接口自动化项目实战三、Web自动化项目实战四、App自动化项目实战五、一线大厂简历六、测试开发DevOps体系七、常用自动化测试工具八、JMeter性能测试九、总结(尾部小惊喜) 前言 Python自动化测试&…...

图像动态裁剪
1. 背景 以两级级联模型为例,第一级目标检测模型用于检测人员,第二级目标检测模型用于检测手机、对讲机等。然后实际数据采集过程中,手机、对讲机这些设备并不在人员的一级检测框内,使得二级模型训练的样本较少。 二级目标检测模…...

Thematica: 炫彩主题与黑暗奇观的Vue3之旅
✅创作者:陈书予 🎉个人主页:陈书予的个人主页 🍁陈书予的个人社区,欢迎你的加入: 陈书予的社区 🌟专栏地址: 三十天精通 Vue 3 文章目录 一、介绍1.1 博客主题和目的1.2 Vue 3简介二、炫彩主题2.1 准备工作2.2 安装必要依赖2.3 创建Vue项目2.4 设置全局样式...

平凡的Python为什么能一跃成为世界排名第一的语言
本文首发自「慕课网」,想了解更多IT干货内容,程序员圈内热闻,欢迎关注"慕课网"! 作者:大周|慕课网讲师 一、前言 本文将结合个人经历为各位同学客观的分析是否有学习Python的必要、Python适合谁学、为什么…...

Wijmo 2023 v1 Crack
改进了 FlexGrid,支持 React 18 严格模式和可访问性。 5月 15, 2023 - 10:51 新版本 特征 改进了对 React 18 的支持 - 添加了对 React 18 严格模式的支持,可帮助开发人员在开发过程中查找常见错误。辅助功能改进 - 以下是此版本中…...

万物互联时代的边缘计算安全需求与挑战
随着物联网技术的快速发展,越来越多的设备和应用程序开始互联,这不仅提高了我们的生活质量,也带来了很多新的安全威胁。边缘计算作为连接数据和应用程序的关键环节,在万物互联的时代变得尤为重要。本文将讨论万物互联背景下的边缘…...

函数序列与函数项级数
文章目录 函数序列与函数项级数函数序列函数项级数Weierstrass M 判别法 函数序列与函数项级数 函数序列 点态收敛:设 f n ( x ) : [ a , b ] → R f_n(x):\,[a,\,b]\to\bold{R} fn(x):[a,b]→R 是定义在区间 [ a , b ] [a,\,b] [a,b] 上的函数序列࿱…...

深度学习从心电信号中解码呼吸频率:原理、实现与临床价值
1. 项目概述:从心电信号中“听”到呼吸声呼吸频率,这个我们每分钟都在进行却很少被精确量化的生命体征,在临床医学中扮演着至关重要的角色。它不仅是评估呼吸系统功能的直接指标,更是反映全身代谢、循环乃至神经系统状态的“窗口”…...

UE4动画蓝图实战:用双骨骼IK节点搞定手部穿模,附完整蓝图节点截图
UE4动画蓝图实战:双骨骼IK节点解决手部穿模的完整指南在角色动画开发中,手部穿模问题堪称"视觉杀手"。想象一下精心设计的角色挥拳时,拳头直接穿过墙壁或敌人身体——这种违和感足以毁掉整个场景的沉浸感。本文将彻底解决这个痛点&…...

Python开发者首次使用Taotoken接入大模型API的完整步骤指南
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Python开发者首次使用Taotoken接入大模型API的完整步骤指南 对于Python开发者而言,接入大模型API进行应用开发已成为一…...

OpenClaw用户如何快速接入Taotoken并开始Agent工作流
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 OpenClaw用户如何快速接入Taotoken并开始Agent工作流 对于使用OpenClaw框架构建AI智能体的开发者而言,快速接入稳定、多…...

基于ESP32与MQTT的家庭环境监测系统:从传感器选型到数据可视化实战
1. 项目概述与核心价值最近几年,我身边越来越多的朋友开始关注家里的空气质量、温湿度这些看不见摸不着,但又实实在在影响生活舒适度和健康的环境指标。从新装修的房子担心甲醛,到有老人小孩的家庭在意PM2.5和二氧化碳浓度,再到南…...

电信运营商每月处理海量工单,如何不再出错?基于AI Agent的端到端自动化解决方案
在2026年的电信行业,海量工单处理已不再仅仅是效率问题,而是合规与生存的底线。随着2026年5月20日《电信和互联网服务 基础电信企业网上营业厅服务规范》国家标准的正式实施,监管层对“信息透明、流程闭环、计费精准”的要求达到了前所未有的…...
)
YOLOv8晶圆体缺识别检测系统(项目源码+YOLO数据集+模型权重+UI界面+python+深度学习+环境配置)
摘要 晶圆制造过程中的缺陷检测是保证芯片良率的关键环节。本文基于YOLOv8目标检测算法,构建了一套针对晶圆表面9类典型缺陷的自动检测系统。所识别的缺陷类型包括:Center、Donut、Edge-Loc、Edge-Ring、Loc、Near-full、None、Random、Scratch。模型在…...

约束感知图缩减算法在量子优化中的应用
1. 约束感知图缩减算法概述在量子计算领域,资源受限一直是制约算法实际应用的主要瓶颈。以当前主流的超导量子计算机为例,其量子比特数通常在50-100个之间,且存在显著的噪声干扰。这种硬件限制使得许多经典优化问题难以直接映射到量子设备上求…...

ComfyUI-Manager完全指南:掌握AI工作流管理的核心技术
ComfyUI-Manager完全指南:掌握AI工作流管理的核心技术 【免费下载链接】ComfyUI-Manager ComfyUI-Manager is an extension designed to enhance the usability of ComfyUI. It offers management functions to install, remove, disable, and enable various custo…...

3步快速恢复加密压缩包密码:ArchivePasswordTestTool终极指南
3步快速恢复加密压缩包密码:ArchivePasswordTestTool终极指南 【免费下载链接】ArchivePasswordTestTool 利用7zip测试压缩包的功能 对加密压缩包进行自动化测试密码 项目地址: https://gitcode.com/gh_mirrors/ar/ArchivePasswordTestTool 面对遗忘的加密压…...