深度模型中的正则化、梯度裁剪、偏置初始化操作
最近调试代码,发现怎么调试都不行,就想着用一些优化方式,然后又不是很清楚这些优化方式的具体细节,然后就学习了一下,这里记录下来,方便以后查阅。
深度模型中的正则化、梯度裁剪、偏置初始化操作
- 正则化
- 常用的正则化方法
- L1正则化
- L2正则化
- Dropout正则化
- 数据增强
- Kernel max-norm regularization
- 在损失中加入L1、L2正则化从而实现防止过拟合的效果的原理是什么
- L1正则化和L2正则化有什么区别
- 正则化系数λ的取值对模型有什么影响
- 如何确定正则化系数λ的最佳取值
- 网格搜索(Grid Search)
- 随机搜索(Random Search)
- 交叉验证(Cross-Validation)
- 带正则化的自适应学习率(Adaptive Regularization of Weights)
- 如何在模型中加入L2正则化
- pytorch中优化函数中的weight_decay 参数是对网络中所有的参数进行正则化吗
- SGD和Adam等优化器中和RMSprop等优化器中weight_decay参数的意义有什么不同
- Adam优化算法和AdamW优化算法的区别是什么
- 如何对模型的某一层加入正则化项
- 模型中加入clip_grad_norm_
- 正则化和梯度裁剪的作用是什么,有什么区别,分别在什么情况下使用
- 将卷积层的偏置初始化为0
正则化
常用的正则化方法
L1正则化
L1正则化是基于L1范数的正则化方法,其数学公式为:
L = L d a t a + λ ∑ i = 1 n ∣ w i ∣ L = L_{data} + \lambda \sum_{i=1}^n |w_i| L=Ldata+λi=1∑n∣wi∣
其中 L d a t a L_{data} Ldata为数据损失, w i w_i wi为模型参数, λ \lambda λ为正则化参数。L1正则化的作用是惩罚模型参数的绝对值,使得一些参数变为0,从而实现特征选择的效果,减少模型的复杂度。
L2正则化
L2正则化是基于L2范数的正则化方法,其数学公式为:
L = L d a t a + λ ∑ i = 1 n w i 2 L = L_{data} + \lambda \sum_{i=1}^n w_i^2 L=Ldata+λi=1∑nwi2
其中 L d a t a L_{data} Ldata为数据损失, w i w_i wi为模型参数, λ \lambda λ为正则化参数。L2正则化的作用是惩罚模型参数的平方和,使得模型的权重分布更加平滑,减少模型的复杂度,避免过拟合。
Dropout正则化
Dropout正则化是一种随机失活正则化方法,其数学公式为:
y = 1 1 − p × x × m y = \frac{1}{1-p} \times x \times m y=1−p1×x×m
其中 p p p为保留节点的概率, x x x为输入, m m m为二值化的掩码,表示哪些节点被保留,哪些节点被随机失活。Dropout正则化的作用是随机丢弃一些节点,从而减少模型中的共适应性,避免过拟合。
数据增强
数据增强是一种基于数据扩充的正则化方法,其数学公式为:
x a u g = f ( x ) x_{aug} = f(x) xaug=f(x)
其中 x x x为原始数据, f f f为数据增强函数, x a u g x_{aug} xaug为增强后的数据。数据增强可以通过随机裁剪、旋转、翻转、缩放等方式扩充数据集,从而提高模型的泛化能力,防止过拟合。
Kernel max-norm regularization
https://github.com/kevinzakka/pytorch-goodies#max-norm-constraint
《Improving neural networks by preventing co-adaptation of feature detectors》
Kernel max-norm regularization是一种常用的正则化方法,它可以限制神经网络中每个卷积核的权重值的最大范数,从而可以控制过拟合的程度。
Kernel max-norm regularization只能在训练时有效,因此需要在模型编译时设置相应的参数。在测试或预测时,不需要使用这个正则化方法。
If a hidden unit’s weight vector’s L2 norm L L L ever gets bigger than a certain max value c c c, multiply the weight vector by c / L c/L c/L. Enforce it immediately after each weight vector update or after every X X X gradient update.
This constraint is another form of regularization. While L2 penalizes high weights using the loss function, “max norm” acts directly on the weights. L2 exerts a constant pressure to move the weights near zero which could throw away useful information when the loss function doesn’t provide incentive for the weights to remain far from zero. On the other hand, “max norm” never drives the weights to near zero. As long as the norm is less than the constraint value, the constraint has no effect.
第一种实现方式:
def max_norm(model, max_val=3, eps=1e-8):for name, param in model.named_parameters():if 'bias' not in name:norm = param.norm(2, dim=0, keepdim=True)desired = torch.clamp(norm, 0, max_val)param = param * (desired / (eps + norm))
第二种实现方式:
class Conv2dWithConstraint(nn.Conv2d):def __init__(self, *args, doWeightNorm = True, max_norm=1, **kwargs):self.max_norm = max_normself.doWeightNorm = doWeightNormsuper(Conv2dWithConstraint, self).__init__(*args, **kwargs)def forward(self, x):if self.doWeightNorm: self.weight.data = torch.renorm(self.weight.data, p=2, dim=0, maxnorm=self.max_norm)return super(Conv2dWithConstraint, self).forward(x)class Conv1dWithConstraint(nn.Conv1d):def __init__(self, *args, doWeightNorm = True, max_norm=1, **kwargs):self.max_norm = max_normself.doWeightNorm = doWeightNormsuper(Conv1dWithConstraint, self).__init__(*args, **kwargs)def forward(self, x):if self.doWeightNorm: self.weight.data = torch.renorm(self.weight.data, p=2, dim=0, maxnorm=self.max_norm)return super(Conv1dWithConstraint, self).forward(x)class LinearWithConstraint(nn.Linear):def __init__(self, *args, doWeightNorm = True, max_norm=1, **kwargs):self.max_norm = max_normself.doWeightNorm = doWeightNormsuper(LinearWithConstraint, self).__init__(*args, **kwargs)def forward(self, x):if self.doWeightNorm: self.weight.data = torch.renorm(self.weight.data, p=2, dim=0, maxnorm=self.max_norm)return super(LinearWithConstraint, self).forward(x)
在损失中加入L1、L2正则化从而实现防止过拟合的效果的原理是什么
在损失函数中加入正则化项,是一种常见的防止过拟合的方法。其基本原理是通过对模型参数进行约束,来减小模型的复杂度,从而避免模型过度拟合训练数据。
具体来说,正则化项通常有两种形式:L1正则化和L2正则化。L1正则化是将模型参数的绝对值作为正则化项,L2正则化是将模型参数的平方作为正则化项。在损失函数中加入正则化项后,优化器在训练模型时不仅需要最小化损失函数的输出值,还需要最小化正则化项的输出值,从而使得模型参数尽量接近于0。
加入正则化项的效果是使得模型参数的值不会变得过大,从而避免模型过度拟合训练数据。这是因为模型参数过大的情况下,模型会过度适应训练数据,而无法泛化到测试数据。通过正则化项的约束,模型参数的值会被控制在一个较小的范围内,使得模型更具有泛化性能。
需要注意的是,正则化项的约束力度由正则化参数控制,即正则化参数越大,模型参数的值越接近于0。但是,正则化参数过大也会导致模型欠拟合,因此需要根据具体的情况选择合适的正则化参数。
L1正则化和L2正则化有什么区别
L1正则化是通过对权重参数施加L1范数的约束来实现的。具体地说,L1正则化是将权重参数中每个元素的绝对值相加,然后乘以一个正则化系数λ,得到一个正则化项,加到目标函数中。通过L1正则化可以使得部分权重参数变成0,从而实现特征选择的效果,即去除对模型影响较小的特征。
L2正则化是通过对权重参数施加L2范数的约束来实现的。具体地说,L2正则化是将权重参数中每个元素的平方相加,然后乘以一个正则化系数λ,得到一个正则化项,加到目标函数中。通过L2正则化可以使得权重参数的值变得更加平滑,从而减少模型的复杂度,提高模型的泛化性能。
正则化系数λ的取值对模型有什么影响
- 当正则化系数λ较小时,模型的拟合能力较强,可以更好地拟合训练数据,但可能会出现过拟合的问题,导致模型在测试数据上表现不佳
- 当正则化系数λ较大时,模型的拟合能力较弱,可以避免过拟合的问题,但可能会出现欠拟合的问题,导致模型在训练数据上表现不佳。
如何确定正则化系数λ的最佳取值
确定正则化系数λ的最佳取值是深度学习中常见的问题,有多种方法可以用来解决这个问题,下面介绍几种常用的方法:
网格搜索(Grid Search)
网格搜索是一种简单但有效的方法,可以用来寻找最佳的正则化系数λ。具体来说,可以先定义一组候选的正则化系数λ的取值,然后在这些取值中进行穷举搜索,最后选择使得模型在验证集上表现最好的正则化系数λ。
随机搜索(Random Search)
随机搜索是一种更加高效的方法,可以用来寻找最佳的正则化系数λ。具体来说,可以先定义一组正则化系数λ的取值的分布,然后在这些分布中随机采样,最后选择使得模型在验证集上表现最好的正则化系数λ。
交叉验证(Cross-Validation)
交叉验证是一种常用的方法,可以用来评估模型的泛化性能和选择最佳的正则化系数λ。具体来说,可以将数据集分为训练集和验证集,然后在训练集上训练模型,使用验证集来选择最佳的正则化系数λ,最后使用测试集来评估模型的泛化性能。
带正则化的自适应学习率(Adaptive Regularization of Weights)
带正则化的自适应学习率是一种有效的方法,可以同时优化权重参数和正则化系数λ。具体来说,可以在损失函数中添加一个惩罚项,使得权重参数和正则化系数λ一起进行优化。这种方法可以自动调整正则化系数λ的取值,从而获得更好的泛化性能。
如何在模型中加入L2正则化
下面是一个使用PyTorch定义一个简单的深度学习框架,并加入L2正则化的示例代码:
import torch
import torch.nn as nn
import torch.optim as optim# 定义模型
class Net(nn.Module):def __init__(self):super(Net, self).__init__()self.fc1 = nn.Linear(784, 64)self.fc2 = nn.Linear(64, 10)def forward(self, x):x = x.view(-1, 784)x = nn.functional.relu(self.fc1(x))x = self.fc2(x)return x# 创建模型实例
model = Net()# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, weight_decay=0.01)# 训练模型
for epoch in range(10):running_loss = 0.0for i, data in enumerate(trainloader, 0):inputs, labels = data# 梯度清零optimizer.zero_grad()# 前向传播outputs = model(inputs)# 计算损失loss = criterion(outputs, labels)# 反向传播loss.backward()# 更新参数optimizer.step()running_loss += loss.item()print('Epoch %d, loss: %.3f' % (epoch + 1, running_loss / len(trainloader)))
在优化器中设置了weight_decay参数后,优化器会自动将正则化项添加到梯度更新中,从而实现L2正则化。
pytorch中优化函数中的weight_decay 参数是对网络中所有的参数进行正则化吗
在PyTorch中,优化器中的weight_decay参数是用来控制L2正则化(也称为权重衰减)的强度的。当设置了weight_decay参数时,优化器会在每次更新参数时对所有的参数进行L2正则化,即对每个参数的更新值乘以一个小于1的因子,这个因子就是weight_decay参数的值。因此,weight_decay参数对网络中所有参数进行了正则化。
需要注意的是,weight_decay参数对于不同的优化器有不同的含义。在SGD和Adam等优化器中,weight_decay参数控制的是L2正则化的强度;在RMSprop等优化器中,weight_decay参数控制的是L2正则化的系数。因此,在使用不同的优化器时,需要根据具体的情况来调整weight_decay参数的取值,以获得更好的泛化性能。此外,有些优化器中还提供了其他的正则化方法,例如AdamW和LAMB等优化器,可以在使用这些优化器时进一步控制正则化的效果。
SGD和Adam等优化器中和RMSprop等优化器中weight_decay参数的意义有什么不同
在SGD和Adam等优化器中,weight_decay参数通常用来控制L2正则化的强度。具体地说,weight_decay参数会在每次参数更新时对参数值进行衰减,从而使得权重参数尽量分散,防止过拟合。在SGD和Adam中,weight_decay参数的作用相当于在损失函数中添加L2正则化项,即将权重的平方和乘以一个权重衰减系数,从而约束权重参数的范数。
而在RMSprop等优化器中,weight_decay参数的含义有所不同,它被用来控制L2正则化的系数。具体地说,weight_decay参数会在计算梯度平方的移动平均值时,对其进行加权衰减,从而使得梯度的范数尽量分散,防止过拟合。在RMSprop中,weight_decay参数的作用相当于在梯度上方添加一个L2正则化项,即将权重的平方和乘以一个权重衰减系数,从而约束权重参数的范数。
Adam优化算法和AdamW优化算法的区别是什么
Adam优化算法中的权重衰减是基于L2正则化实现的,即在每次参数更新时,将权重参数乘以一个权重衰减系数。但是,这种方式会导致权重参数的更新受到了较大的约束,特别是在学习率较小时,可能会导致模型的收敛速度减慢。
为了解决这个问题,AdamW优化算法提出了一种新的权重衰减方式。在AdamW中,权重衰减是基于L2正则化和权重衰减的加权和实现的,即在每次参数更新时,将权重参数乘以一个L2正则化系数和一个权重衰减系数的加权和。这种方式可以缓解权重参数更新受到较大约束的问题,同时还可以防止过拟合。
除了权重衰减的处理方式不同之外,AdamW和Adam在其他方面的处理方式基本相同。它们都是基于自适应学习率的优化算法,可以自动调整学习率大小,以适应不同的模型和数据集。此外,它们都可以处理稀疏梯度和非平稳目标函数等问题。
在应用方面,Adam优化算法比较适合应用于深度学习中的大多数任务,特别是对于参数较多的模型,Adam的表现通常比SGD等基本优化算法要好。而AdamW优化算法则更适合于处理权重衰减问题,特别是在学习率较小时,AdamW可以更好地控制权重参数的更新,从而提高模型的泛化性能。因此,在需要进行权重衰减的任务中,使用AdamW可以获得更好的性能。
如何对模型的某一层加入正则化项
下面是一个示例代码,演示了如何在PyTorch中实现对某一层的正则化:
import torch
import torch.nn as nn
import torch.optim as optim# 定义模型
class MyModel(nn.Module):def __init__(self):super(MyModel, self).__init__()self.lin1 = nn.Linear(10, 10)self.lin2 = nn.Linear(10, 5)def forward(self, x):x = self.lin1(x)x = nn.functional.relu(x)x = self.lin2(x)return xmodel = MyModel()# 定义正则化项的权重
weight_decay = 0.01# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)# 训练模型
for epoch in range(10):running_loss = 0.0for i in range(100):# 获取数据和标签inputs = torch.randn(10)labels = torch.randint(0, 5, (1,)).long()# 清空梯度optimizer.zero_grad()# 前向传播和计算损失outputs = model(inputs)loss = criterion(outputs, labels)# 计算正则化项reg_loss = 0.0for name, param in model.named_parameters():if 'weight' in name:reg_loss += torch.norm(param, p=2)**2# 总损失为交叉熵损失加上正则化项total_loss = loss + weight_decay * reg_loss# 反向传播和计算梯度total_loss.backward()# 更新参数optimizer.step()running_loss += loss.item()print("Epoch %d, loss: %.3f" % (epoch+1, running_loss/100))
在上述代码中,我们首先定义了一个名为MyModel的简单模型,该模型包含两个全连接层。接着,我们定义了正则化项的权重weight_decay。在训练过程中,我们在计算总损失时,将交叉熵损失和正则化项的乘积添加到总损失中,从而实现对某一层的正则化。
需要注意的是,对于不同的模型和任务,最适合的正则化项类型和权重可能会有所不同。通常情况下,我们可以通过尝试不同的正则化方法和权重值,来找到一个合适的正则化策略,从而实现更好的模型性能。
模型中加入clip_grad_norm_
下面是一个使用PyTorch框架的示例代码,演示了如何在模型训练过程中使用torch.nn.utils.clip_grad_norm_()函数对梯度进行裁剪:
import torch
import torch.nn as nn
import torch.optim as optim# 定义模型
class MyModel(nn.Module):def __init__(self):super(MyModel, self).__init__()self.lin1 = nn.Linear(10, 10)self.lin2 = nn.Linear(10, 5)def forward(self, x):x = self.lin1(x)x = nn.functional.relu(x)x = self.lin2(x)return xmodel = MyModel()# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)# 训练模型
for epoch in range(10):running_loss = 0.0for i in range(100):# 获取数据和标签inputs = torch.randn(10)labels = torch.randint(0, 5, (1,)).long()# 清空梯度optimizer.zero_grad()# 前向传播和计算损失outputs = model(inputs)loss = criterion(outputs, labels)# 反向传播和计算梯度loss.backward()# 对梯度进行裁剪nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)# 更新参数optimizer.step()running_loss += loss.item()print("Epoch %d, loss: %.3f" % (epoch+1, running_loss/100))
在上述代码中,我们首先定义了一个名为MyModel的简单模型,该模型包含两个全连接层。接着,我们定义了损失函数和优化器,并开始训练模型。在每个小批量数据的反向传播过程中,我们使用nn.utils.clip_grad_norm_()函数对模型的梯度进行裁剪,以避免梯度爆炸的问题。在此之后,我们调用优化器的step()函数来更新模型的参数。
需要注意的是,对于不同的模型和任务,最适合的梯度裁剪阈值可能会有所不同。通常情况下,我们可以通过调整阈值的大小来找到一个合适的裁剪范围,从而实现更好的模型性能。
正则化和梯度裁剪的作用是什么,有什么区别,分别在什么情况下使用
正则化和梯度裁剪是常用的模型优化技术,它们的作用是为了避免模型过拟合或者梯度爆炸的问题。虽然这两种技术都有类似的目的,但是它们的实现方式和使用情况略有不同。
正则化的作用是通过在损失函数中加入对模型参数的约束,以避免模型过拟合的问题。常见的正则化方法包括L1正则化、L2正则化等。在实现过程中,我们可以通过在损失函数中添加正则化项(如权重的范数),来惩罚模型参数的大小,从而实现对模型的约束。正则化通常应用于模型训练过程中,以减少模型的泛化误差。
梯度裁剪的作用是通过对模型梯度进行限制,以避免梯度爆炸的问题。当模型的梯度过大时,我们可以通过对梯度进行剪裁,将其限制在一个合理的范围内,从而避免对模型参数的过度更新。梯度裁剪通常应用于优化器的反向传播过程中,以避免梯度爆炸对模型的影响。
区别:
- 正则化是对模型参数进行约束,而梯度裁剪是对梯度进行限制。
- 正则化可以避免模型过拟合,而梯度裁剪可以避免梯度爆炸。
- 正则化通常应用于模型训练过程中,而梯度裁剪通常应用于优化器的反向传播过程中。
使用场景:
- 正则化通常适用于模型过拟合的情况,当模型在训练集上表现良好,但在测试集上表现不佳时,可以尝试使用正则化技术。
- 梯度裁剪通常适用于模型出现梯度爆炸的情况,当模型的梯度过大,导致模型参数的更新过于剧烈而影响模型性能时,可以尝试使用梯度裁剪技术。
将卷积层的偏置初始化为0
在大多数深度学习框架中,可以通过设置卷积层的偏置初始化参数为0来实现该操作。下面是一个使用Python和PyTorch框架的示例代码:
import torch.nn as nn# 定义卷积层(具体参数可以根据实际情况进行修改)
conv_layer = nn.Conv2d(in_channels=3, out_channels=16, kernel_size=3, stride=1, padding=1, bias=True)# 将卷积层的偏置初始化为0
conv_layer.bias.data.fill_(0.0)
在上述代码中,我们首先使用PyTorch框架定义了一个卷积层conv_layer,并通过bias=True参数指定了该层需要包含偏置。接下来,我们通过conv_layer.bias.data.fill_(0.0)将卷积层的偏置初始化为0。
相关文章:

深度模型中的正则化、梯度裁剪、偏置初始化操作
最近调试代码,发现怎么调试都不行,就想着用一些优化方式,然后又不是很清楚这些优化方式的具体细节,然后就学习了一下,这里记录下来,方便以后查阅。 深度模型中的正则化、梯度裁剪、偏置初始化操作 正则化常…...

设计模式之装饰模式
定义 装饰模式指的是在不必改变原类文件和使用继承的情况下,动态地扩展一个对象的功能。它是通过创建一个包装对象,也就是装饰来包裹真实的对象。 模式特点 (1) 装饰对象和真实对象有相同的接口。这样客户端对象就能以和真实对…...

华为OD机试真题 Java 实现【最佳对手】【2023Q1 200分】
一、题目描述 游戏里面,队伍通过匹配实力相近的对手进行对战。但是如果匹配的队伍实力相差太大,对于双方游戏体验都不会太好。 给定 n 个队伍的实力值,对其进行两两实力匹配,两支队伍实例差距在允许的最大差距 d内,则可以匹配。 要求在匹配队伍最多的情况下匹配出的各组…...
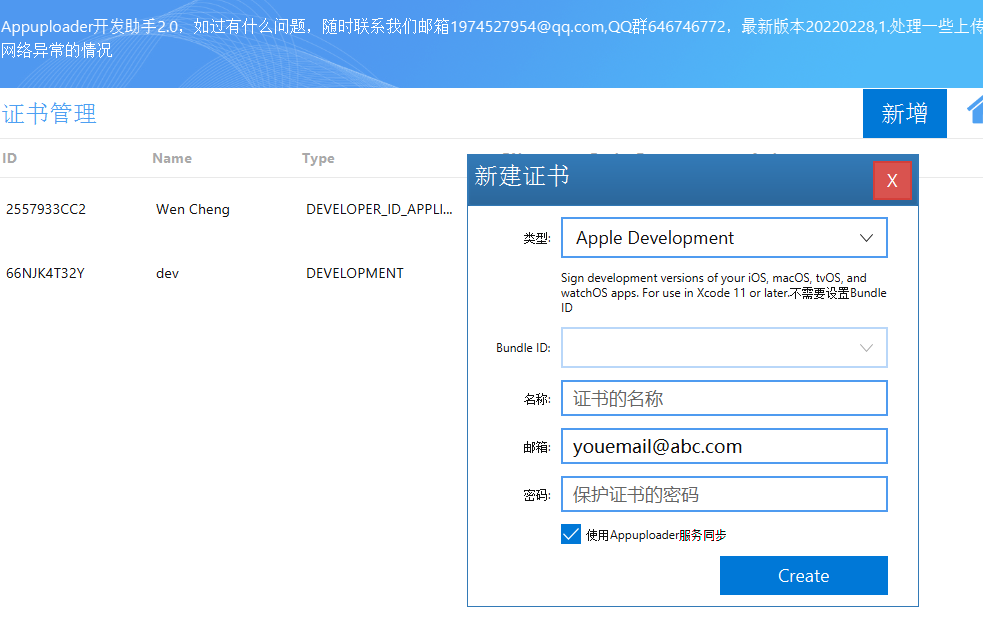
IOS证书制作教程
IOS证书制作教程 点击苹果证书 按钮 点击新增 输入证书密码,名称 这个密码不是账号密码,而是一个保护证书的密码,是p12文件的密码,此密码设置后没有其他地方可以找到,忘记了只能删除证书重新制作,所以请务…...

【人工智能】蚁群算法(密恐勿入)
蚁群算法(密恐勿入) 蚁群算法--给你一个感性认识 蚁群算法(密恐勿入)1. 算法简介1.1 基本原理1.1.1 模拟蚂蚁在简单地形,寻找食物1.1.2 模拟蚂蚁在复杂地形,找到食物1.2 算法应用 2. 算法解析3.算法应用——…...
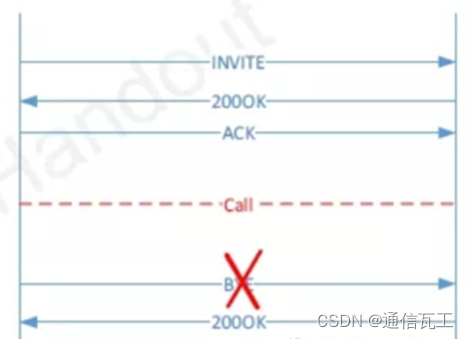
VONR排查指导分享
不能注册或呼叫到SIP服务器端30秒挂断呼叫的黄金法则咬线或摘机状态单通或无语音收到400 bad request收到413,513 Request Entity Too Large或Message Too Large消息收到408, 480或者487 消息483 - Too Many Hops488 – Not Acceptable Here语音质量和思…...

Daftart.ai:人工智能专辑封面生成器
前言 Daft Art AI是一款使用人工智能技术来帮助您制作专辑封面的软件,它可以让您在几分钟内,用简单的编辑器和精选的美学风格,为您的专辑或歌曲创建出惊艳的高质量的艺术品。Daft Art AI有以下几个特点:简单易用:您只…...

ZigBee案例笔记 - 定时器
文章目录 1.片内外设I/O2.定时器简介3.定时器1寄存器4.定时器1操作自由运行模式模模式正计数/倒计数模式 5.16位计数器定时器1控制LED 示例 6.定时器3概述自由运行模式倒计数模式模模式正/倒计数模式 7.定时器3寄存器定时器3控制LED闪烁 1.片内外设I/O 定时器这样的片内外设也…...

GE H201TI 全系统自检和自诊断
Hydran 201Ti是一个小型在线预警发射器。它永久安装在变压器上,将为工作人员提供各种故障气体复合值的单一ppm读数,以提醒他们潜在的问题。 可以下载该值,并且可以将警报设置在预定水平,以提醒人员并能够监控发展中的故障状况。 …...
这个屏幕录制太好用了!
哈喽,大家好!今天给各位小伙伴测试了一屏幕录制的小工具——ApowerREC。它是一款专业同步录制屏幕画面及声音的录屏软件。界面简洁,操作简单,支持实时编辑屏幕录像、创建计划任务、录制摄像头高清视频等功能。废话不多说ÿ…...

初识redis【redis的安装使用与卸载】
一.redis的概念 Redis(Remote Dictionary Server ),即远程字典服务,是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。在redis官网中对redis的描述是这样的&#…...

接口测试总结及其用例设计方法整理,希望可以帮到你
目录 接口测试的总结文档 第一部分: 第二部分: 接口测试用例设计 接口测试的总结文档 第一部分:主要从问题出发,引入接口测试的相关内容并与前端测试进行简单对比,总结两者之前的区别与联系。但该部分只交代了怎么做…...

基于FPGA的多功能数字钟的设计
摘要 数字钟是采用数字电路实现对时、分、秒数字显示的计时装置,是人们日常 生活中不可少的必需品。本文介绍了应用FPGA芯片设计多功能数字钟的•种方 案,并讨讨论了有关使用FPGA芯片和VHDL语言实现数字钟设计的技术问题。 关键词数字钟、分频器、译码器、计数器、校时电路、…...
第四十二天学习记录:C语言进阶:笔试题整理Ⅲ
问:解释一下int(*a[20])(int)是什么? ChatAI答: int (*a[20])(int) 是一个数组,该数组中每个元素都是一个指向函数的指针,该函数具有一个int类型的参数,并返回一个int类型的值。 具体来说,a是一…...

GLSL 代码规范
文件 文件顶点,片段,几何和计算着色器文件应该分别有 _vert, _frag, geom 和 _comp 后缀(例如: eevee_film_fragg.glsl)。Shader文件名必须是唯一的,并且必须以它们所属的模块作为前缀(例如: workbench_material_lib.glsl eevee_film_lib.glsl)。一个 shader 文件必须包含且…...

红黑树封装map和set
文章目录 红黑树封装map和set1. 改良红黑树1.1 改良后的节点1.2 改良后的类分别添加仿函数代码 3. 封装map和set3.1 set3.2 map 3. 迭代器3.1 begin 和 end3.2 operator()和operator--()3.3 const迭代器set的迭代器map的迭代器 4. map的operator[]的重载5. 完整代码实现5.1 RBT…...

python序列
在Python中,序列类型包括字符串、列表、元组、集合和字典,这些序列支持以下几种通用的操作,但比较特殊的是,集合和字典不支持索引、切片、相加和相乘操作。 字符串也是一种常见的序列,它也可以直接通过索引访问字符串内…...
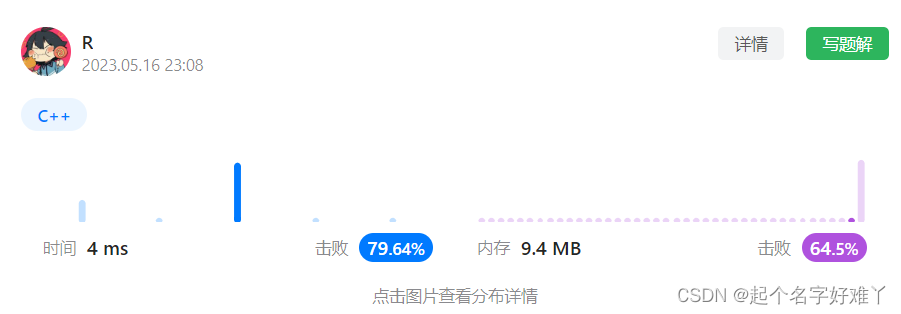
LeetCode35. 搜索插入位置(二分法入门)
写在前面: 题目链接:LeetCode35. 搜索插入位置 编程语言:C 题目难度:简单 一、题目描述 给定一个排序数组和一个目标值,在数组中找到目标值,并返回其索引。如果目标值不存在于数组中,返回它将会…...
macOS Ventura 13.4 RC3(22F66)发布
系统介绍 5 月 17 日消息,苹果今日向 Mac 电脑用户推送了 macOS 13.4 RC 3 更新(内部版本号:22F66),本次更新距离上次发布隔了 5 天。 macOS Ventura 带来了台前调度、连续互通相机、FaceTime 通话接力等功能。其中&…...

CSI和DSI介绍
1、CSI和DSI的接触协议介绍 MIPI、CSI、CCI 协议基础介绍_csi协议_赵哈哈x的博客-CSDN博客 流媒体技术基础-摄像头接口与标准_【零声教育】音视频开发进阶的博客-CSDN博客 《摄像头 —— MIPI CSI-2简介》 USB摄像头使用 — Lichee zero 文档 2、AIO-3288J ,and…...

Kerberos身份认证原理与企业级排错实战指南
1. 这不是“另一个登录框”,而是一套精密运转的身份验证齿轮系统很多人第一次听说 Kerberos,是在公司内网登录邮箱或访问内部系统时,看到那个带小盾牌图标的弹窗——“正在使用 Kerberos 协议进行身份验证”。于是下意识觉得:“哦…...

AMLP框架实战:基于MACE构建高精度机器学习势函数
1. 项目概述:当机器学习势函数遇上自动化管道在计算化学和材料科学领域,我们长久以来面临着一个核心矛盾:精度与效率的权衡。密度泛函理论(DFT)能提供接近实验的精度,但计算成本高昂,通常只能处…...

用Python和MNE库玩转BCI Competition IV 2a脑电数据集:从数据加载到可视化全流程
用Python和MNE库玩转BCI Competition IV 2a脑电数据集:从数据加载到可视化全流程当你第一次接触脑电信号处理时,面对原始数据文件可能会感到无从下手。BCI Competition IV 2a数据集作为脑机接口领域的经典基准数据,包含了9名受试者四种运动想…...

HFSS仿真结果怎么看?一文读懂S参数与电场图,让你的T型波导分析不再迷茫
HFSS仿真结果深度解析:从S参数到电场图的工程实践指南面对HFSS仿真生成的复杂数据图表,许多工程师常陷入"看得见数据却读不懂含义"的困境。本文将带您穿透数据表象,掌握T型波导性能分析的核心方法论。1. S参数:波导性能…...

2026 西安 AI 问答曝光搭建技术解析:GEO 知识图谱 + 深度测评
随着大语言模型技术的快速普及,AI 搜索已经成为用户获取企业信息、商家服务的核心入口。根据中国互联网信息中心 2026 年发布的《中国人工智能搜索发展报告》显示,2025 年国内 AI 搜索用户规模突破 8.2 亿,日均搜索请求超过 20 亿次ÿ…...

RevSSH反向SSH隧道:无公网IP设备的安全远程运维方案
1. 这不是又一个SSH封装工具——RevSSH解决的是“根本性连接悖论”你有没有遇到过这样的场景:一台部署在客户内网的嵌入式设备,没有公网IP,NAT穿透失败,防火墙策略死死锁住所有入向端口,连ICMP都被禁了;或者…...
)
DeepSeek代码风格检查避坑指南(内部审计报告首次披露:37个被忽略的合规红线)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek代码风格检查的合规性本质与审计背景 DeepSeek代码风格检查并非单纯的技术偏好约束,而是嵌入研发治理链条中的合规性控制节点。其本质是将编程实践与组织级安全策略、行业监管要求&…...

Lovable电商网站搭建:如何用不到3人技术团队,72小时内上线PCI-DSS合规MVP版本?
更多请点击: https://codechina.net 第一章:Lovable电商网站搭建 Lovable 是一个面向中小商户的轻量级电商解决方案,采用现代 Web 技术栈构建,强调可扩展性、用户体验与快速部署能力。本章将指导你从零开始搭建一个具备商品展示、…...

UE5项目打包后RenderTarget导出图片全黑?手把手教你解决伽马校正与资产打包问题
UE5打包后RenderTarget导出图片全黑的终极解决方案当你花了整整三天时间调试RenderTarget导出功能,终于在编辑器里看到完美的截图效果,却在打包成可执行文件后发现所有导出的图片都变成了一片漆黑——这种从云端跌入谷底的感觉,每个UE开发者都…...

避坑指南:Unity中AABB碰撞检测失效的5种常见原因及解决方法
Unity中AABB碰撞检测失效的深度排查与解决方案在Unity开发中,AABB(轴对齐包围盒)碰撞检测是基础但容易出问题的环节。许多开发者都遇到过这样的情况:明明逻辑正确,测试时却出现物体穿透、碰撞时有时无等诡异现象。本文…...