PBDB Data Service:Measurements of specimens(标本测量)
Measurements of specimens(标本测量)
- 描述
- 参数
- 以下参数可用于指定您感兴趣的标本种类
- 以下参数可用于筛选所选内容
- 以下参数还可用于根据分类筛选结果列表
- 以下参数可用于生成数据存档
- 您可以使用以下参数选择要检索的额外信息,以及要获取记录的顺序
- 方法
- 响应结果
- 1:basic
- 2:spec
- 3:attr
- 4:refattr
- 5:class
- 6:classext
- 7:genus
- 8:plant
- 9:abund
- 10:ecospace
- 11:etbasis
- 12:taphonomy
- 13:coll
- 14:coords
- 15:loc
- 16:paleoloc
- 17:strat
- 18:stratext
- 19:lith
- 20:lithext
- 21:methods
- 22:env
- 23:geo
- 24:ref
- 25:resgroup
- 26:ent
- 27:entname
- 28:crmod
- 格式
- 术语表
描述
此操作返回与所选标本相关的测量信息。
参数
如果您希望检索输入该数据库的整组测量记录,您可以使用以下参数。请小心使用它,因为结果集将包含超过 300,000 条记录并且大小至少为 17 Mb。
- all_records:根据您可能指定的任何其他参数,选择数据库中输入的所有事件。此参数不需要任何值。
以下参数可用于指定您感兴趣的标本种类
-
spectype:根据标本是副模式还是正模式来选择标本。可接受的值包括:
holo只选择全息模式。para只选择正模式和副模式。any选择所有标本。这是默认值。
如果希望从已知的样本、事件或集合列表中检索测量值,可以使用以下参数。只有与您指定的其他参数相匹配的记录才会被返回。
- spec_id:样本标识符的逗号分隔列表。选择由这些标识符识别的样本,前提是它们满足本请求中给出的任何其他参数。
- occ_id:以逗号分隔的化石产出记录标识列表。选择指定的产出记录,前提是它们满足此请求的其他参数。您也可以使用参数名称 id。您还可以将此参数与任何其他参数一起使用,以根据其他条件筛选已知的匹配项列表。
- coll_id:以逗号分隔的采集记录标识列表。选择与指定采集记录相关的所有化石产出记录,前提是采集记录满足此请求的其他参数。
以下参数可用于按各种标准查询标本。除了下面提到的,您可以任意组合使用它们。这些相同的参数都可以用来选择事件,收集,或相关的参考或分类群。
- clust_id:返回仅与指定地理集群相关的记录。您可以指定一个或多个集群 ID,以逗号分隔。
- coll_match:返回与collection_name和collection_aka字段匹配的字符串。仅返回属于匹配的采集记录的产出记录。字符串可以包含通配符 % 和 _ 。事实上,除非你在字符串的开头和/或结尾加上%,否则你不会匹配到任何结果。
- coll_re:与coll_match相似,唯一不同在于此项接收正则表达式。你可以使用 | 二者或多者择一,可以使用包括 \ 在内的所有标准正则表达式。
- base_name:仅返回与特定分类名相关的记录,包括所有亚类群和异名。您可以用逗号分隔来指定多个名称。您可以使用 ^ 排除掉任意名称。例如,Osteichthyes^Tetrapoda 将会选择除Tetrapoda外的所有Osteichthyes记录。
- taxon_name:仅返回与特定分类名相关的记录,包括所有异名。您可以用逗号分隔来指定多个名称。名称可以包含通配符,但如果匹配到了不止一个名称,那么只会使用数据库中产出记录数量最多的那个。
- match_name:仅返回与特定分类名相关的记录。您可以用逗号分隔来指定多个名称。名称可以包含通配符 % 和 _ ,所有与匹配到的名称相关的产出记录都会返回。将会忽略掉异名。此项比起分类学匹配而言,更像是语法匹配。
- immediate:您可以与base_name,base_id或taxon_name一起设置此项。设置此项会忽略掉指定名称的异名。此参数不需要值,在请求中包含此参数即可。
- base_id:仅返回与特定分类名相关的记录,包括所有亚类群和异名。您可以用逗号分隔来指定多个ID。请注意,您最多可以指定taxon_name、taxon_id、base_name和 base_id之一。
- taxon_id:仅返回与特定分类名相关的记录,不包括亚类群和异名。您可以用逗号分隔来指定多个ID。
- exclude_id:排除掉与指定类群ID相关的分类名称或其下级名称。这是 **^**的另一种方式。
- idreso:选择与指定分类阶元匹配的产出记录,或将同属/同科的产出记录合并。可接受的值有:
species:仅选择鉴定为种的产出记录
genus:仅选择鉴定到属或种的产出记录
family:仅选择鉴定到科或属或种的产出记录
lump_genus:仅选择鉴定到属或种的产出记录,并将同一采集记录中同属的所有产出记录合并为单条记录
lump_gensub*:仅选择鉴定到属或种的产出记录,并将同一采集记录中同属/亚属的所有产出记录合并为单条记录 - idtype:本参数决定如何处理重新鉴定的产出记录。可接受的值包括:
latest:仅选择每项产出记录的最新鉴定,忽略掉其余鉴定。此值为默认值。
orig:仅选择每项产出记录的原始鉴定,忽略掉其余鉴定。
reid:选择被重新鉴定的产出记录的所有鉴定,包括原始鉴定。忽略数据库中没有重新鉴定记录的产出记录。这可能造成每项产出记录返回多条记录。注意,如果您指定了一个分类名称,那么不符合该名称的鉴定将被忽略。您可以通过按ID专门查询您感兴趣的产出记录来找到它们,加上idtype=all。
all:选择所有匹配其他搜索参数的鉴定。这可能会导致为给定产出记录返回多条记录。 - idqual:此参数根据其分类修饰符选择或排除产出记录。允许的值包括:
any: 选择所有匹配项,而不考虑修饰符。这是默认值。
certain:排除用以下任何修饰符标记的所有匹配项:aff. / cf. / ? / “” / informal / sensu lato.
genus_certain:类似certain,但只看属/亚属,忽略物种修饰符。
uncertain:选择用以下任何修饰符标记的所有匹配项:aff. / cf. / ? / “” / informal / sensu lato.
new:仅选择标有以下项之一的匹配项:n. gen. / n. subgen. / n. sp. - idmod:此参数根据分类修饰符的任意组合选择或排除产出记录。如果您需要选择无法通过 idqual 获得的修饰符组合,则可以使用此参数和/或 idgen 和 idspc。您可以指定以下一个或多个代码,以逗号分隔。如果第一个前面是 !那么他们被排除在外。否则,仅包括标有至少一个的产出记录:
ns:n. sp.
ng:n. gen. or n. subgen.
af:aff.
cf:cf.
sl:sensu lato
if:informal
eg:ex gr.
qm:question mark(?)
qu:quotes(“”) - idgenmod:此参数根据属和/或亚属名称上的分类修饰符的任意组合选择或排除产出记录。请参阅上面的 idmod。
- idspcmod:此参数根据物种名称上的分类修饰符的任意组合选择或排除产出记录。请参阅上面的 idmod。
- abundance:此参数仅选择具有特定种类丰度值的产出记录。接受的值为:
count:仅选择丰度类型为’individuals’, ‘specimens’ ‘grid-count’, ‘elements’, or 'fragments’的产出记录
coverage:仅选择丰度类型为“%-…”的产出记录
any:仅选择具有某种类型丰度信息的产出记录
您也可以附加一个冒号,后跟一个十进制数。这将仅选择丰度至少为指定最小值的产出记录。 - lngmin
- lngmax:仅返回当前经度在给定边界内的记录。如果指定其中一个参数,则必须同时指定这两个参数。如果提供的边界超出 -180° 到 180° 的范围,它们将被收缩到适当的范围内。例如,如果您指定 lngmin=270 和 lngmax=360,则查询将lngmin=-90 和 lngmax=0 进行处理。在这种情况下,查询结果中的所有经度值都将调整为落在您指定的实际数值范围内。
- latmin:仅返回当前纬度至少为给定值的记录。
- latmax:仅返回当前纬度最多为给定值的记录。
- loc:仅返回当前位置(经度和纬度)属于指定范围的记录,必须以 WKT 格式给出,坐标为经度和纬度值。
- plate:仅返回位于指定地质板块上的记录。如果此参数的值以 ! 开头,则排除指定板块上的所有记录。如果此参数的值继续以 G 开头,则这些值将被解释为 GPlates 模型中的板块编号。如果是S,则这些值将被解释为 Scotese 模型中的板块编号。否则,它们将根据参数 pgm 的值进行解释。该值的其余部分必须是板块编号。
- pgm:指定返回古坐标时要使用的古地理模型。您可以从以下列表中指定一个或多个,以逗号分隔。如果未为此参数指定值,则默认模型为 gplates。
gplates:Wright et. al., 2013; Towards community-driven paleogeographic reconstructions
scotese:Scotese, C.R., 2021. An Atlas of Paleogeographic Maps: The Seas Come In and the Seas Go Out, Annual Reviews of Earth and Planetary Sciences, v. 49, p. 669-718
seton:Seton et. al., 2012; Global continental and ocean basin reconstructions since 200 Ma - pgs:指定是返回每个采集记录的年龄范围的开头、中间还是结尾的古坐标。可接受的值为:early, mid, late。您可以指定多个作为逗号分隔的列表。
- cc:仅返回位置在指定地理区域内的记录。此参数的值应为一个或多个双字符国家/地区代码和/或三个字符的洲代码作为逗号分隔的列表。如果参数值以 ! 开头,则属于这些区域的记录将被排除而不是包括在内。任何以 ^ 开头的国家/地区代码都将从过滤器中减去。例如:
ATA,AU:选择来自南极洲和澳大利亚的产出记录
NOA,SOA,^AR,^BO:选择来自北美和南美的实例,但不包括阿根廷或玻利维亚
!EUR,^IS:排除来自欧洲的产出记录,但来自冰岛的除外 - state:仅从指示为属于指定州或省的采集记录中返回产出记录。此信息不会记录所有采集记录,并且未检查其准确性。鉴于国家/地区之间有时会重复州名称,因此建议也使用 cc 参数指定国家/地区。
- county:仅返回指定属于指定县或其他次州级行政区划的采集记录中的产出记录。此信息不会记录所有采集记录,并且未检查其准确性。鉴于县名经常在州和国家/地区之间重复,建议您同时使用 state 参数指定州,并使用 cc 参数指定国家/地区。
- continent:仅返回地理位置在一个或多个指定大陆内的记录。此参数的值应为以逗号分隔的洲代码列表。此参数已弃用;请改用cc。
- strat:仅返回属于指定地质地层或地层内的记录。您可以指定多个,用逗号分隔。名称可以包括标准的SQL通配符 % 和 _ ,并且可以跟着’fm’,‘gp’,'mbr’中的任何一个。如果未给出这些后缀,则将选择所有匹配的地层名称。如果参数值以 ! 开头,则与此层或地层关联的记录将被排除而不是包括在内。请注意,此参数仅通过字符串匹配进行解析。地层命名法目前在数据库中没有标准化,因此可能会出现拼写错误。
- formation:仅返回属于指定地层构造内的记录。此参数已弃用,请改用 strat。
- stratgroup:仅返回属于指定地层组内的记录。此参数已弃用,请改用 strat。
- member:仅返回属于指定地层成员的记录。此参数已弃用,请改用 strat。
- lithology:仅返回记录为来自任何指定岩性和/或岩性类型的记录。如果参数值字符串以 !然后,将改为排除匹配的记录。如果符号 ^ 出现在任何岩性名称的开头,则所有后续值将从过滤器中减去。例如:carbonate,^bafflestone。
- envtype:仅返回记录为属于任何指定环境和/或环境区域的记录。如果参数值字符串以 !然后,将改为排除匹配的记录。如果符号 ^ 出现在任何环境代码的开头,则将从筛选器中减去所有后续值。例如:terr,^fluvial,lacustrine or !slope,^carbonate。您可以指定以下一个或多个值作为逗号分隔的列表:
terr:任何陆相环境
marine:任何海相环境
carbonate:碳酸盐环境
silicic:硅碎屑环境
unknown:未知或不确定的环境
lacust:湖区
fluvial:河流区
karst:喀斯特地带
terrother:其他陆地区域
marginal:边缘海洋区
reef:礁石区
stshallow:浅潮下带
stdeep:深潮下带
offshore:近海区
slope:斜坡/盆地区
marindet:海洋不确定区 - interval_id:仅返回其时间在给定的地质时间间隔内(由数字标识符指定)的记录。如果指定多个间隔,则使用的时间范围将从最早指定间隔的开始到最晚指定间隔的结束的连续时间段。
- interval:仅返回其时空位置在命名的地质时间间隔内(由名称指定)内的记录。您可以指定多个间隔,用逗号或短划线分隔。如果指定多个间隔,则使用的时间范围将从最早指定间隔的开始到最晚指定间隔的结束的连续时间段。
- min_ma:仅返回其时间位置至少为此的记录,单位为Ma。
- max_ma:仅返回其时间位置至多为此的记录,单位为Ma。
- timerule:根据指定的规则解析时空位置,如下所示。对于多样性输出,此规则应用于将每个匹配项放入一个或多个时态条柱中,或者在与任何条柱不匹配时忽略该项。可用的规则包括:
contain:仅选择其时空位置严格包含在指定时间范围内的记录。这是最严格的规则。对于多样性输出,此规则保证每个匹配项最多落入一个时态图格,但许多实例将被忽略,因为它们的时间位置太宽而无法落入任何条柱中。
major:仅选择至少 50% 的时态位置范围落在指定时间范围内的记录。对于多样性输出,此规则还保证每个匹配项最多落入一个时态条柱。许多匹配项将被忽略,因为它们的时间位置宽度是任何重叠条柱的两倍多,但忽略的次数少于contain规则。这是默认时间规则,除非您专门选择一个时间规则。
buffer:仅选择其时间位置与指定时间范围重叠且完全位于此范围周围的“缓冲区”内的记录。这个缓冲区默认为古生代和中生代的1200万年,新生代的默认值为500万年。您可以使用参数timebuffer和late_buffer覆盖缓冲区宽度。对于多样性输出,某些事件将计为落入多个箱中。某些事件仍将被忽略,但比上述规则要少。
overlap:仅选择其时态位置与指定时间范围重叠任意数量的记录。这是最宽松的规则。对于多样性输出,将计算所有产出记录。许多人将被计入多个条箱中。 - timebuffer:解析时间局部性时覆盖默认缓冲期。该值必须以数百万年为单位给出。仅当timerule设置为buffer时,此参数才相关。
- latebuffer:解析时间局部性时,覆盖时间范围结束时的默认缓冲期。这允许缓冲区在间隔的后期与在早期结束时不同。该值必须以数百万年为单位给出。仅当timerule设置为buffer时,此参数才相关。
以下参数可用于筛选所选内容
- specs_created_before:仅选择与在指定日期或日期/时间之前创建的事件关联的记录。
- specs_created_after:仅选择与在指定日期或日期/时间之后创建的事件关联的记录。
- specs_modified_before:仅选择与在指定日期或日期/时间之前修改的事件关联的记录。
- specs_modified_after:仅选择与在指定日期或日期/时间之后修改的事件关联的记录。
- specs_authorized_by:仅选择与指定人员授权的事件关联的记录,这些事件由名称或标识符指示。
- specs_entered_by:仅选择与指定人员输入的由名称或标识符指示的事件关联的记录
- specs_modified_by:仅选择与指定人员修改的事件关联的记录,这些事件由名称或标识符指示
- specs_touched_by:仅选择与指定人员授权、输入或修改的事件关联的记录,这些事件由名称或标识符指示
- specs_authent_by:仅选择与由指定人员授权或输入的事件关联的记录,这些事件由名称或标识符指示
- occs_created_before:仅选择与在指定日期或日期/时间之前创建的事件关联的记录。
- occs_created_after:仅选择与在指定日期或日期/时间之后创建的事件关联的记录。
- occs_modified_before:仅选择与在指定日期或日期/时间之前修改的事件关联的记录。
- occs_modified_after:仅选择与在指定日期或日期/时间之后修改的事件关联的记录。
- occs_authorized_by:仅选择与指定人员授权的事件关联的记录,这些事件由名称或标识符指示。
- occs_entered_by:仅选择与指定人员输入的由名称或标识符指示的事件关联的记录
- occs_modified_by:仅选择与指定人员修改的事件关联的记录,这些事件由名称或标识符指示
- occs_touched_by:仅选择与指定人员授权、输入或修改的事件关联的记录,这些事件由名称或标识符指示
- occs_authent_by:仅选择与由指定人员授权或输入的事件关联的记录,这些事件由名称或标识符指示
以下参数还可用于根据分类筛选结果列表
- taxon_status:仅选择标识到分类群且具有指定状态的产出记录。默认值为all。可接受的值包括:
all:选择与其他指定条件匹配的所有分类名称。这是默认值。
valid:仅选择分类有效的名称
accepted:仅选择不是初级同义词的分类有效名称
junior:仅选择作为初级同义词的分类有效名称
invalid:仅选择分类无效的名称,例如 nomina dubia - pres:此参数指示是选择标识为遗迹分类群、形式分类群还是常规分类群的产出记录。默认值为 all,这将选择满足其他指定条件的所有记录。可以将以下一个或多个值指定为列表:
regular:选择常规分类群
form:选择形式分类群
ichno:选择遗迹分类群
all:选择所有分类群 - extant:仅选择已确定为现存或非现存分类群的产出记录。接受的值为:yes, no。
以下参数可用于生成数据存档
最简单的方法是使用下载生成器表单。
- archive_title:此参数的值指示使用指定的标题创建存档,除非已存在存档。
- archive_replace:此参数的 true 值指示如果存在具有指定标题的现有存档,则其内容应替换为当前请求的输出。如果没有此参数,如果指定的标题与现有记录匹配,则将返回错误代码E_EXISTING。如果现有记录具有 DOI,则将返回错误E_IMMUTABLE,并且无法覆盖。
- archive_authors:此参数的值(如果有)将放入已创建或更新的存档记录的“作者”字段中。
- archive_desc:此参数的值(如果有)将放入已创建或更新的存档记录的“描述”字段中。
您可以使用以下参数选择要检索的额外信息,以及要获取记录的顺序
- show:选择要返回的其他信息。此参数的值必须是以下一项或多项,以逗号分隔。
1. full:这是包含定义此记录的所有信息的快捷方式。目前,这包括以下块:attr, class, plant, ecospace, taphonomy abund, coll, coords, loc, paleoloc, prot, stratext, lithext, geo, methods, rem, refattr。如果我们随后将新的数据字段添加到样本记录中,则 full 也将包括这些字段。因此,如果您要发布 URL,最好包含 show=full。
2. acconly:禁止显示每个标本的确切分类标识,并仅显示接受的名称。
3. attr:该标本的公认名称的属性(作者和年份)。
4. class:标本的分类学分类:门、纲、目、科、属。
5. classext:与class类似,但也包括相关的分类标识符。
6. genus:对应于每个标本的属,如果标本已被鉴定为属级别。如果使用class或classext扩展,则此块是多余的。
7. subgenus:对应于每个标本的属,如果有的话,加上亚属。这可以添加到 class或classext 中以显示亚属,或者代替属来显示属和亚属(如果有)。
8. plant:与该标本相关的植物器官(如果有)。除非标本是植物化石,否则这些字段将是空的。
9. abund:有关其集合中相关事件的丰度(如果有)的信息
10. ecospace:有关该生物所占据或占用的生态空间的信息。这只被填补了相对较少的分类群。参见Ecological and taphonomic vocabulary(生态学和埋葬学术语)
11. taphonomy:有关该生物体的埋葬学信息。参见Ecological and taphonomic vocabulary(生态学和埋葬学术语)
12. etbasis:注释输出块生态空间,指示在哪个分类级别输入每条信息。
13. coll:在其中找到关联事件的集合的名称,以及输入的任何其他备注。
14. coords:关联事件的纬度和经度(如果有)。
15. loc:有关相关事件的地理位置的附加信息(如果有的话)。
16. paleoloc:根据参数pgm指定的模型评估的相关产状的古地理位置信息。
17. strat:化石产出记录的地层背景基本信息。
18. stratext:化石产出记录的地层背景详细信息。包含strat及额外字段。
19. lith:化石产出记录的岩性背景基本信息。
20. lithext:化石产出记录的岩性背景详细信息。包含lith及额外字段。
21. methods:采集时使用的方法。
22. env:化石产出记录的古环境。
23. geo:化石产出记录的地理背景信息(包含env)。
24. ref:化石产出记录的原始文献,格式化文本。如果没有原始文献,那么显示相关采集记录的原始文献。
25. refattr:原始文献的信息,作者和年份。
26. resgroup:化石产出记录和采集记录的研究团队。
27. ent:命名、录入和编辑化石产出记录的人员ID。
28. entname:录入和编辑化石产出记录的人名。
29. crmod:化石产出记录的created和modified时间戳。
当然还可以使用任何特殊参数,请参阅PBDB Data Service:Special parameters(特殊参数)。
方法
这个数据服务接受以下HTTP方法:GET,HEAD。
响应结果
使用此操作对HTTP请求的响应将包含以下列表中的字段。区块basic是一直显示的。其他的可以使用参数show来选择。
1:basic
| 字段名(pbdb) | 字段名(com) | 描述 |
|---|---|---|
| measurement_no | oid | 此度量在数据库中的唯一标识符 |
| _label | rlb | 对于新添加或更新的记录,此字段将报告与每条记录一起提交的记录标签值(如果有)。 |
| specimen_no | sid | 与此测量相关联的标本标识符 |
| record_type | typ | 该对象的类型:mea表示测量。 |
| n_measured | smn | 测量项目数 |
| position | mpo | 测量项目的位置(如果有记录) |
| measurement_type | mty | 实际测量结果 |
| average | mva | 平均测量值,或仅测量一个项目时的单个值 |
| min | mvl | 最小测量值(如果有记录) |
| max | mvu | 最大测量值(如果记录) |
2:spec
| 字段名(pbdb) | 字段名(com) | 描述 |
|---|---|---|
| flags | flg | 对于大多数记录,此字段将为空。否则,它将包含以下一个或多个字母:N——该标本无相关产出记录。D——为该样本输入的标识与为相应事件输入的标识不同。R——此标识已被最近的标识所取代。换句话说,这个标本已经被重新鉴定了。I——遗迹分类群。F——此标识是一个形式分类单元。对于大多数记录,此字段将为空。表示与发生事件无关的样本的记录在该字段中将具有N。代表一个样本的记录,其标识不同于其相关的出现,将在该字段中具有I。 |
| occurrence_no | qid | 与该样本相关的产状的标识符(如果有的话) |
| reid_no | eid | 如果关联的事件被重新标识,则为重新标识提供唯一标识符。 |
| collection_no | cid | 与该标本相关联的标本集的标识符(如果有的话) |
| permissions | prm | 此记录的可访问性。如果为空,则该记录是公共的。否则,这条记录的值将是以下之一:members:只有数据库成员才能访问该记录;authorizer:该记录可被其授权组以及获得许可的任何其他授权组访问;group(…):该记录仅供指定研究小组的成员查阅。 |
| specimen_id | smi | 根据其保管机构,该标本的识别标签 |
| is_type | smt | 指示此标本是正模还是副模 |
| specelt_no | els | 样本元素层次结构中最能描述此样本的标识符 |
| specimen_side | sms | 与样本部分相对应的身体一侧 |
| specimen_part | smp | 构成这个标本的身体部分 |
| specimen_sex | smx | 标本的性别,如果知道的话 |
| n_measured | smn | 测量的样品数量 |
| measurement_source | mms | 测量结果是如何获得的,如果知道的话 |
| magnification | mmg | 测量中使用的放大倍数(如果已知) |
| comments | smc | 对这个标本的评论,通常是作者和出版年份 |
| identified_name | idn | 标识此事件的分类名称。如果该字段与 accepted_name 的值相同,则对于紧凑词汇表中的响应,该字段将被忽略。 |
| identified_rank | idr | 已识别名称的分类等级(如果可以确定的话)。如果该字段与 accepted_rank 的值相同,则紧凑词汇表中的响应将被省略。 |
| identified_no | iid | 已识别的分类名称的唯一标识符。如果为空,则该名称从未进入存储在该数据库中的分类层次结构,并且我们没有关于该化石产出记录分类的进一步信息。 |
| difference | tdf | 如果标识的名称与接受的名称不同,则此字段给出原因。例如,如果标识的名称是初级同义词或命名,或者物种被重新组合,或者标识的拼写错误,则会出现此字段。 |
| accepted_name | tna | 该字段的值将是与标识的名称相对应的可接受的分类名称。 |
| accepted_rank | rnk | 公认名称的分类等级。如果识别的名称是一个名词或无效的,或者识别的名称没有完全输入到这个数据库的分类层次结构中,那么这可能与识别的等级不同。 |
| accepted_no | tid | 此数据库中接受的分类法名称的唯一标识符。 |
| early_interval | oei | 与此化石产出记录相关的特定地质时间范围(不一定是标准区间),或者如果给出了late_interval,则是该范围开始的区间 |
| late_interval | oli | 结束与此化石产出记录相关的特定地质时间范围的区间,如果与early_interval的值不同 |
| max_ma | eag | 与此发生相关的地质时间范围的早期界值(Ma) |
| min_ma | lag | 与此发生相关的地质时间范围的晚期界限(Ma) |
| reference_no | rid | 输入此数据的引用的标识符 |
3:attr
| 字段名(pbdb) | 字段名(com) | 描述 |
|---|---|---|
| accepted_attr | att | 接受名的属性(作者和年份) |
4:refattr
| 字段名(pbdb) | 字段名(com) | 描述 |
|---|---|---|
| ref_author | aut | 输入该数据的参考文献的作者。 |
| ref_pubyr | pby | 输入该数据的参考文献发表的年份 |
5:class
| 字段名(pbdb) | 字段名(com) | 描述 |
|---|---|---|
| phylum | phl | 分类阶元:门 |
| class | cll | 分类阶元:纲 |
| order | odl | 分类阶元:目 |
| family | fml | 分类阶元:科 |
| genus | gnl | 分类阶元:属 |
6:classext
| 字段名(pbdb) | 字段名(com) | 描述 |
|---|---|---|
| phylum_no | phn | 门的ID |
| class_no | cln | 纲的ID |
| order_no | odn | 目的ID |
| family_no | fmn | 科的ID |
| genus_no | gnn | 属的ID |
| subgenus_no | sgn | 亚属的ID |
7:genus
| 字段名(pbdb) | 字段名(com) | 描述 |
|---|---|---|
| genus | gnl | 分类阶元:属 |
8:plant
| 字段名(pbdb) | 字段名(com) | 描述 |
|---|---|---|
| plant_organ | pl1 | 与化石记录有关的植物器官,如果有的话。这个字段将是空值,除非记录的是植物化石。 |
| plant_organ2 | pl2 | 与化石记录相关的附加植物器官。 |
9:abund
| 字段名(pbdb) | 字段名(com) | 描述 |
|---|---|---|
| abund_value | abv | 化石记录在其采集记录中的丰度 |
| abund_unit | abu | 丰度单位 |
10:ecospace
| 字段名(pbdb) | 字段名(com) | 描述 |
|---|---|---|
| taxon_environment | jev | 发现这种生命形式的一般环境或环境。参阅生态学和埋葬学术语 |
| environment_basis | jec | 指定从其中继承环境信息的分类。 |
| motility | jmo | 生物是否有运动、附着和/或附生,以及它的运动方式(如果有的话)。参阅生态学和埋葬学术语 |
| life_habit | jlh | 这种生物的一般生活方式和位置。参阅生态学和埋葬学术语 |
| vision | jvs | 这种生物拥有的视觉程度。参阅生态学和埋葬学术语 |
| diet | jdt | 这种生物的一般饮食或摄食方式。参阅生态学和埋葬学术语 |
| reproduction | jre | 这种生物的繁殖方式。参阅生态学和埋葬学术语 |
| ontogeny | jon | 简要描述这种生物的个体发生。参阅生态学和埋葬学术语 |
| ecospace_comments | jcm | 如果有其他关于生态空间的评论的话。 |
11:etbasis
| 字段名(pbdb) | 字段名(com) | 描述 |
|---|---|---|
| motility_basis | jmc | 指定为其设置运动信息的分类群。埋藏学和生态空间信息继承自父类群,除非设置了特定的值。 |
| life_habit_basis | jhc | 指定为其设置生活习惯信息的分类单元。参见上面的motitiy_basis。只有在ecospace区块也包含的情况下,这些字段才会被包含。 |
| vision_basis | jvc | 指定为其设置视觉信息的分类单元。参见上面的motitiy_basis。只有在ecospace区块也包含的情况下,这些字段才会被包含。 |
| diet_basis | jdc | 指定为其设置饮食信息的分类单元。参见上面的motitiy_basis。只有在ecospace区块也包含的情况下,这些字段才会被包含。 |
| reproduction_basis | jrc | 指定为其设置繁殖信息的分类单元。参见上面的motitiy_basis。只有在ecospace区块也包含的情况下,这些字段才会被包含。 |
| ontogeny_basis | joc | 指定为其设置个体发育信息的分类单元。参见上面的motitiy_basis。只有在ecospace区块也包含的情况下,这些字段才会被包含。 |
| taphonomy_basis | jtc | 指定为其设置埋葬信息的分类。参见上面的motitiy_basis。只有在ecospace区块也包含的情况下,这些字段才会被包含。 |
12:taphonomy
| 字段名(pbdb) | 字段名(com) | 描述 |
|---|---|---|
| composition | jco | 这种生物骨骼部分的组成。参阅生态学和埋葬学术语 |
| architecture | jsa | 内部骨骼结构。参阅生态学和埋葬学术语 |
| thickness | jth | 表明骨骼的相对厚度。参阅生态学和埋葬学术语 |
| reinforcement | jsr | 显示骨骼加固。参阅生态学和埋葬学术语 |
13:coll
| 字段名(pbdb) | 字段名(com) | 描述 |
|---|---|---|
| collection_name | cnm | 标识采集记录的任意名称,不一定是唯一的 |
| collection_subset | cns | 如果此记录是另一记录的一部分,此字段指明是哪一部分 |
| collection_aka | aka | 化石记录的替代名称,或关于它的附加注释。 |
14:coords
| 字段名(pbdb) | 字段名(com) | 描述 |
|---|---|---|
| lng | lng | 化石记录的经度(度) |
| lat | lat | 化石记录的纬度(度) |
15:loc
| 字段名(pbdb) | 字段名(com) | 描述 |
|---|---|---|
| cc | cc2 | 该化石记录所在的国家,编码为ISO-3166-1 alpha-2 |
| state | stp | 化石记录所在的州或省(如果已知) |
| county | cny | 化石记录所在的县或市,如果知道的话 |
| latlng_basis | n/a | 所报告的化石记录位置的基础 |
| latlng_precision | n/a | 化石记录坐标的精度。按上面的链接查看代码值列表。 |
| n/a | prc | 表示地理坐标的基础和精度的两字母代码。在使用紧凑术语表的响应中,将报告此字段,而不是latlng_basis和latlng_precision。按上面的链接查看代码值列表。 |
| geogscale | gsc | 化石记录的地理刻度 |
| geogcomments | ggc | 关于化石记录地理位置的附加注释 |
16:paleoloc
| 字段名(pbdb) | 字段名(com) | 描述 |
|---|---|---|
| paleomodel | pm1 | 由参数pgm指定的主要模型。此字段仅在指定多个模型时包含。 |
| geoplate | gpl | 根据参数pgm所表示的初级模型来评价化石记录所在的地质板块的标识符。这可能是一个数字或一个字符串。 |
| paleoage | ps1 | 指示这些古坐标是否在每个化石记录的年龄范围的早期、中期或晚期计算 |
| paleolng | pln | 根据参数pgm*所表示的原始模型,对化石记录的古经度进行了计算。 |
| paleolat | pla | 根据参数pgm表示的原始模型,对化石记录的古纬度进行了计算。 |
| paleoage_b | ps1_b | 交互年龄选择器 |
| paleolng_b | pln_b | 对应于交互年龄选择器的古经度 |
| paleolat_b | pla_b | 对应于交互年龄选择器的古纬度 |
| paleoage_c | ps1_c | 交互年龄选择器 |
| paleolng_c | pln_c | 对应于交互年龄选择器的古经度 |
| paleolat_c | pla_c | 对应于交互年龄选择器的古纬度 |
| paleomodel2 | pm2 | 由参数pgm指定的替代模型。此字段仅在指定多个模型时包含。也可能有paleomodel3等。 |
| geoplate2 | gp2 | 一个替代的地质板块标识符,如果pgm参数表明一个以上的模型。也可能有geoplate3等。 |
| paleoage2 | ps2 | 指示第二个古坐标是在每个化石记录的早期、中期还是晚期计算的 |
| paleolng2 | pln2 | 如果pgm*参数表明有多个模型,则为集合提供一个替代的古经线。也可能有paleolng3等。 |
| paleolat2 | pla2 | 如果pgm参数表明有多个模型,则为集合提供一个替代的古纬度。也可能有paleolat3等。 |
| paleoage2_b | ps2_b | 交互年龄选择器 |
| paleolng2_b | pln2_b | 对应于交互年龄选择器的古经度 |
| paleolat2_b | pla2_b | 对应于交互年龄选择器的古纬度 |
| paleoage2_c | ps2_c | 交互年龄选择器 |
| paleolng2_c | pln2_c | 对应于交互年龄选择器的古经度 |
| paleolat2_c | pla2_c | 对应于交互年龄选择器的古纬度 |
17:strat
| 字段名(pbdb) | 字段名(com) | 描述 |
|---|---|---|
| formation | sfm | 化石记录所在的地层(如果已知) |
| stratgroup | sgr | 化石记录所在的地层组(如果已知) |
| member | smb | 化石记录所在的地层成员(如果已知) |
18:stratext
| 字段名(pbdb) | 字段名(com) | 描述 |
|---|---|---|
| stratscale | ssc | 该采集记录涵盖的地层范围 |
| zone | szn | 采集记录所在的地层带(如果已知) |
| localsection | stratext | 采集记录所在的地层部分(如果已知) |
| localbed | slb | 采集记录所在的岩床(如果已知) |
| localbedunit | slu | 计算岩床时使用的计量单位 |
| localorder | slo | 描述当地岩床的顺序(如果已知) |
| regionalsection | srs | 采集记录所在的局部地层(如果已知) |
| regionalbed | srb | 采集记录所在的局部岩床(如果已知) |
| regionalbedunit | sru | 计算局部岩床时使用的计量单位 |
| regionalorder | sro | 描述局部岩床的顺序(如果已知) |
| stratcomments | scm | 关于采集记录地层背景的其他评论(如果有的话) |
19:lith
| 字段名(pbdb) | 字段名(com) | 描述 |
|---|---|---|
| lithdescript | ldc | 对采集记录地点岩性方面的详细说明 |
| lithology1 | lt1 | 为采集记录地点描述的第一个岩性;该数据库每个化石记录最多可以代表两种不同的岩性 |
| lithification1 | lf1 | 为该遗址描述的第一个岩性的岩化状态 |
| minor_lithology1 | lm1 | 与该遗址描述的第一个岩性相关的次要岩性 |
| lithology2 | lt2 | 为采集地点描述的第二种岩性(如果有) |
| lithification2 | lf2 | 为该地点描述的第二岩性的岩化状态。有关值,请参见上文。 |
| minor_lithology2 | lm2 | 与该遗址描述的第二种岩性相关的次要岩性(如果有的话) |
20:lithext
| 字段名(pbdb) | 字段名(com) | 描述 |
|---|---|---|
| lithadj1 | la1 | 描述第一种岩性的形容词 |
| fossilsfrom1 | ff1 | 化石是否取自第一个描述的岩性 |
| lithadj2 | la2 | 描述第二岩性的形容词(如果有的话) |
| fossilsfrom2 | ff2 | 化石是否取自第二个描述的岩性 |
21:methods
| 字段名(pbdb) | 字段名(com) | 描述 |
|---|---|---|
| collection_type | cct | 化石记录的类型或用途。 |
| collection_methods | ccx | 所采用的一个或多个方法。 |
| museum | ccu | 收藏标本的博物馆。 |
| collection_coverage | ccv | 存在但未具体列出的化石。 |
| collection_size | ccs | 实际收集的化石数量。 |
| rock_censused | ccr | 岩石数量。 |
| collectors | ccc | 采集人的名字 |
| collection_dates | ccd | 收集完成的日期。 |
| collection_comments | ccm | 关于收集方法的评论。 |
| taxonomy_comments | tcm | 关于发现内容的分类的评论。 |
22:env
| 字段名(pbdb) | 字段名(com) | 描述 |
|---|---|---|
| environment | env | 与采集地点相关的古环境 |
23:geo
| 字段名(pbdb) | 字段名(com) | 描述 |
|---|---|---|
| environment | env | 采集遗址的古环境 |
| tectonic_setting | tec | 采集地点的构造环境 |
| geology_comments | gcm | 关于收集地点地质的一般评论 |
24:ref
| 字段名(pbdb) | 字段名(com) | 描述 |
|---|---|---|
| primary_reference | ref | 与此记录关联的主要引用(作为格式化文本) |
25:resgroup
| 字段名(pbdb) | 字段名(com) | 描述 |
|---|---|---|
| research_group | rgp | 与此馆藏相关的研究小组(如果有)。 |
26:ent
| 字段名(pbdb) | 字段名(com) | 描述 |
|---|---|---|
| authorizer_no | ati | 授权输入此记录的人员的标识符 |
| enterer_no | eni | 实际输入此记录的人员的标识符。 |
| modifier_no | mdi | 上次修改此记录的人员的标识符(如果已修改)。 |
27:entname
| 字段名(pbdb) | 字段名(com) | 描述 |
|---|---|---|
| authorizer_no | ati | 授权输入此记录的人员的标识符 |
| enterer_no | eni | 实际输入此记录的人员的标识符。 |
| modifier_no | mdi | 上次修改此记录的人员的标识符(如果已修改)。 |
| authorizer | ath | 授权输入此记录的人员的姓名 |
| enterer | ent | 实际输入此记录的人员的姓名 |
| modifier | mdf | 上次修改此记录的人员的姓名(如果已修改)。 |
28:crmod
| 字段名(pbdb) | 字段名(com) | 描述 |
|---|---|---|
| created | dcr | 创建此记录的日期和时间。 |
| modified | dmd | 上次修改此记录的日期和时间。 |
格式
以下响应格式可用于此操作。必须通过向 URI 路径添加适当的后缀来为请求选择所需的格式。
| 格式 | 后缀 | 文档 |
|---|---|---|
| JSON | .json | JSON format |
| Comma-separated text | .txt | Text formats |
| Comma-separated text | .csv | Text formats |
| Tab-separated text | .tsv | Text formats |
术语表
| 术语表 | 名称 | 默认格式 | 描述 |
|---|---|---|---|
| PaleobioDB field names | pbdb | txt, csv, tsv | PBDB词汇表来自数据库中的基础字段名和值,并增加了一些新字段。在大多数情况下,使用此词汇表的响应将直接与从PBDB Classic接口下载的响应相比较。此词汇表是Text格式响应的默认词汇。 |
| Compact field names | com | json | Compact词汇表是一组3个字符的字段名,旨在将响应消息的大小最小化。这是JSON格式响应的默认值。一些字段值被类似地简化,而其他字段值则被完整地传递。 |
相关文章:
)
PBDB Data Service:Measurements of specimens(标本测量)
Measurements of specimens(标本测量) 描述参数以下参数可用于指定您感兴趣的标本种类以下参数可用于筛选所选内容以下参数还可用于根据分类筛选结果列表以下参数可用于生成数据存档您可以使用以下参数选择要检索的额外信息,以及要获取记录的…...
低调的接口工具 ApiKit
最近发现一款接口测试工具--ApiKit,我们很难将它描述为一款接口管理工具 或 接口自测试工具。 官方给了一个简单的说明,更能说明 Apikit 可以做什么。 ApiKit API 管理 Mock 自动化测试 异常监控 团队协作 ApiKit的特点: 接口文档定义&a…...
opengauss 的回归测试
目录 一、回归测试说明 二、单独执行测试用例(开发调试) 一、回归测试说明 opengauss/postgresql 的回归测试,通过执行SQL比较输出打印,判断代码修改是否改变了其它功能逻辑。 OG的回归测试大体上和PG类似,主要是通…...

计算机组成原理基础练习题第四章-计算机的运算方法
对真值0表示形式唯一的机器数是()。A、原码 B、补码和移码C、反码 D、以上都不对在整数定点机中,下述说法正确的是()。A、原码和反码不能表示-1,补码可以表示-1B、三种机器数均可表示-1C、三种机器数均可表示…...

SpringBoot定时任务里的多线程
SpringBoot定时任务里的多线程 提示前言遇到的问题验证与解决验证单线程执行单任务分析代码及结果 单线程执行多任务 解决实现单任务的多线程为每个任务创建一个子线程 解决多任务的多线程设定固定容量线程池动态设定容量线程池固定线程池和动态线程池的选择 简单总结借鉴及引用…...

YOLO V3 SPP ultralytics 第二节:根据yolo的数据集,生成准备文件和yolo的配置文件
目录 1. 介绍 2. 完整代码 3. 代码讲解 3.1 生成 my_train_data.txt和my_val_data.txt 3.2 生成 my_data.data 文件 3.3 生成 my_yolov3.cfg 3.4 关于my_data_label.names文件 1. 介绍 根据 第一节 的操作,已经生成了下图中圆圈中的部分,而本…...

camunda流程引擎connector如何使用
在 Camunda 中,Connector 是一种用于与外部系统或服务交互的机制。它允许 BPMN 模型中的 Service Task 节点与外部系统或服务进行通信,从而使流程更加灵活和可扩展。使用 Connector,可以将业务流程与外部系统集成在一起,而无需编写…...

ECO基本概念:pre-mask eco gen patch flow
使用conformal LEC 进行pre-mask eco 时,如何产生patch,参考以下步骤: 官方推荐 Flattened ECO Flow(FEF) Conformal支持Flattened ECO Flow和Hierarchical ECO Flow。Flattened下,工具会将 ECO 分析重点…...
【初学人工智能原理】【4】梯度下降和反向传播:能改(下)
前言 本文教程均来自b站【小白也能听懂的人工智能原理】,感兴趣的可自行到b站观看。 本文【原文】章节来自课程的对白,由于缺少图片可能无法理解,故放到了最后,建议直接看代码(代码放到了前面)。 代码实…...

微信小程序路由传参
微信小程序路由传参 在微信小程序中,可以通过路由传参将数据传递给目标页面。以下是一种常见的方式: 在源页面中,使用 wx.navigateTo 或 wx.redirectTo 方法跳转到目标页面,并通过 URL 参数传递数据。示例: wx.navi…...
深入篇【C++】类与对象:再谈构造函数之初始化列表与explicit关键字
深入篇【C】类与对象:再谈构造函数之初始化列表与explicit关键字 Ⅰ.再谈构造函数①.构造函数体赋值②.初始化列表赋值【<特性分析>】1.至多性2.特殊成员必在性3.必走性:定义位置4.一致性5.不足性 Ⅱ.explicit关键字①.隐式类型转化②.作用 Ⅰ.再谈…...

广东棒球发展建设·棒球1号位
一、概述 棒球是一项源于美国的运动,自20世纪初开始传入中国,近年来在广东省的发展也逐渐受到关注。本文将就广东棒球的发展现状及未来发展方向进行分析。 二、发展现状 目前广东省内棒球赛事主要有以下几种: 1. 业余棒球联赛:…...

浅谈PMO对组织战略的支持︱美团骑行事业部项目管理中心负责人边国华
美团骑行事业部项目管理中心负责人边国华先生受邀为由PMO评论主办的2023第十二届中国PMO大会演讲嘉宾,演讲议题:浅谈PMO对组织战略的支持。大会将于6月17-18日在北京举办,更多内容请浏览会议日程 议题内容简要: 战略是组织运行的…...

互联网医院资质代办|互联网医院牌照的申请流程
随着互联网技术的不断发展,互联网医疗已经逐渐成为人们关注的热点话题。而互联网医院作为互联网医疗的一种重要形式,也越来越受到社会各界的关注。若想开展互联网医院业务,则需要具备互联网医院牌照。那么互联网医院牌照的申请流程和需要的资…...

网络:DPDK复习相关知识点_2
1.RTC运行至完成时模式,单核单模块 2.pipeline模式,多核多模块,每个模块都是一个处理引擎,但会有缓存一致性问题 3.Mbuff数据包内存操作对象,相当于是数据包的一个索引,对网络的处理都集中在这个Buff上 …...

阿里云大学考试Java中级题目及解析-java中级
阿里云大学考试Java中级题目及解析 1.servlet释放资源的方法是? A.int()方法 B.service()方法 C.close() 方法 D.destroy()方法 D servlet释放资源的方法是destroy() 2.order by与 group by的区别? A.order by用于排序,group by用于排序…...
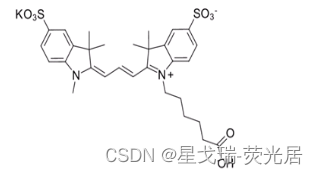
【星戈瑞】Sulfo-CY3-COOH磺化/水溶性Cyanine3羧酸1121756-11-3
Sulfo-CY3 COOH是一种荧光染料,其分子结构中含有COOH官能团,最大吸收波长为550纳米左右,可以通过分光光度计等设备进行检测。Sulfo-CY3 COOH是一种带有羧基的荧光染料,可以与含有氨基的生物分子通过偶联反应形成共价键,…...

Java NIO和IO的主要区别
当学习了Java NIO和IO的API后,一个问题马上涌入脑海: 我应该何时使用IO,何时使用NIO呢?在本文中,我会尽量清晰地解析Java NIO和IO的差异、它们的使用场景,以及它们如何影响您的代码设计。 下表总结了Java N…...

SQL查询语句
DQL语句--排序查询 # 格式: select * from 表名 order by 要排序的列1 [asc/desc], 要排序的列2 [asc/desc]; # 解释: # 1. 无论SQL语句简单或者是复杂, order by语句一般都放最后, 注意: 如果有limit(分页), 则它(limit)在最后. # 2. asc表示升序, desc表示降序, 其中, 默…...
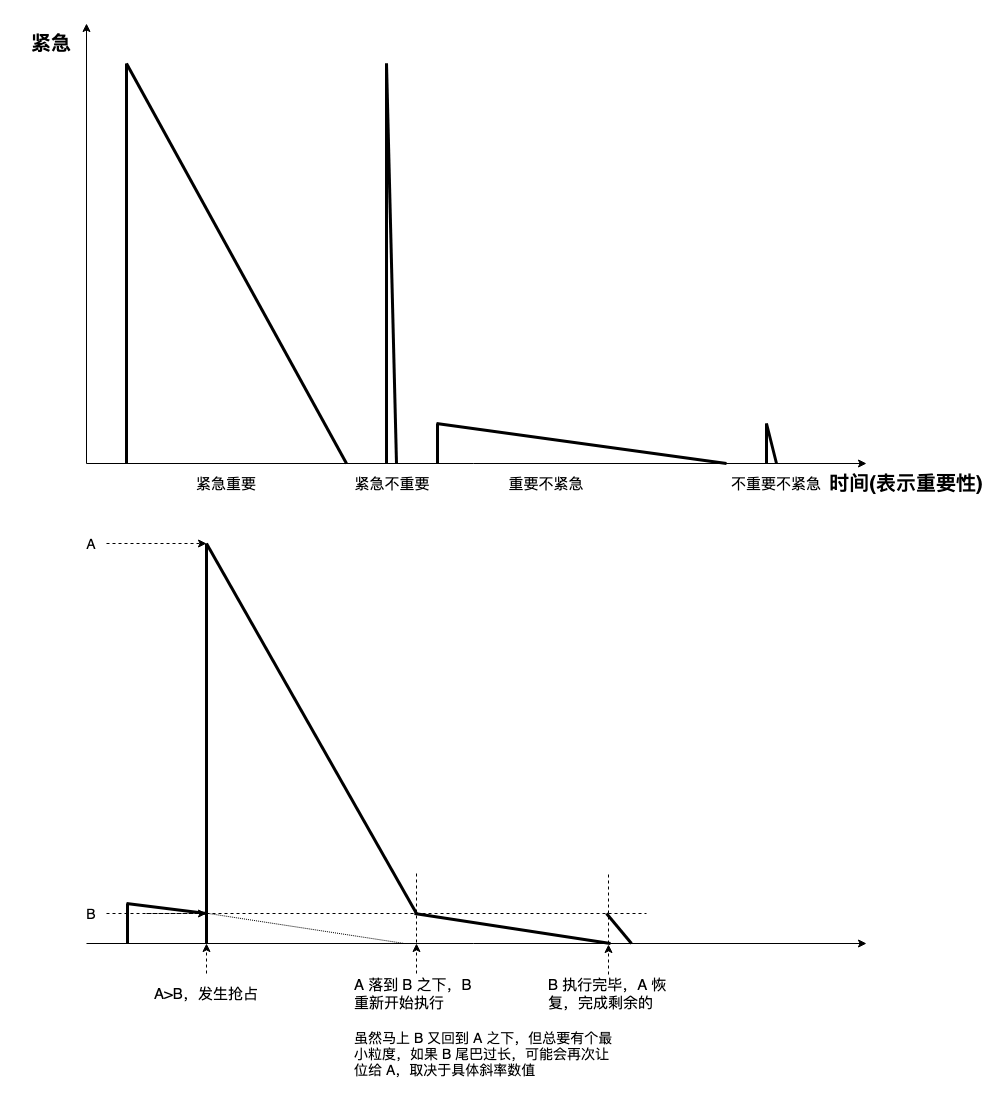
四象限法进程调度
周二收到一篇推送 一次云上网络毫秒级的优化与实践,很有意义的实践和探索,建议阅读,文章不长,没有冗长的源码分析,结论很清晰。 谈谈我的看法。 多少有种感觉,Linux 越来越像个响应系统而不是服务器。 虚…...

Topit:macOS窗口置顶神器,让多任务处理效率翻倍
Topit:macOS窗口置顶神器,让多任务处理效率翻倍 【免费下载链接】Topit Pin any window to the top of your screen / 在Mac上将你的任何窗口强制置顶 项目地址: https://gitcode.com/gh_mirrors/to/Topit 你是否经常在macOS上同时处理多个任务时…...

Win10家庭版别再卡了!保姆级教程:手动修复gpedit.msc路径,彻底关闭Antimalware Service
Win10家庭版性能优化实战:精准修复组策略路径与系统服务调优每次游戏激战正酣时突然卡顿,或是视频渲染到关键时刻系统响应迟缓,很多Win10家庭版用户都遭遇过这类困扰。任务管理器里那个名为"Antimalware Service Executable"的进程…...

软阴影:那个让虚拟世界“温柔起来“的光影小秘密
一、从一只小猫的影子说起 前几天我在朋友家做客,他家养了一只胖乎乎的橘猫,正趴在阳台的窗边晒太阳。我无意间瞥了一眼那只猫脚边的影子,突然被一个细节震撼了—— 那只猫的影子——并不是一片均匀的黑。 仔细看——猫肚子紧贴地板的地方——…...

BLE蓝牙扫描深度剖析:扫描原理、核心参数、前后台差异
一、前言BLE设备交互分为两大角色:广播端(外设Peripheral)与扫描端(中心Central)。上一篇博客详解了四大广播模式,本文聚焦配套核心能力——BLE扫描机制。绝大多数蓝牙开发疑难问题:前台能扫后台…...

Win10系统清理避坑指南:你的BAT脚本真的安全吗?盘点那些不能乱删的文件
Win10系统清理避坑指南:BAT脚本安全操作手册每次看到那些号称"一键清理系统垃圾"的BAT脚本在技术论坛被疯狂转发,我的工程师朋友老张就会忍不住摇头。上周他刚帮一位设计师修复了崩溃的Photoshop——原因正是某个清理脚本删除了Adobe的临时工作…...
)
Windows10下V-REP教育版安装保姆级教程(附百度网盘资源与避坑点)
Windows10系统V-REP教育版完整安装指南:从下载到实战避坑在机器人仿真和自动化控制领域,V-REP(现更名为CoppeliaSim)作为一款功能强大的跨平台机器人仿真软件,已经成为众多工科学生和研究人员的首选工具。特别是其教育…...

荣耀出征官方网站下载正版手游 翅膀养成细节玩法全方位讲解
玩荣耀出征的玩家都清楚,翅膀不仅是角色的颜值象征,更是提升整体战力的核心途径。很多新手玩家只顾着升级、刷装备,完全忽略翅膀养成,导致等级很高但战力始终上不去。还有不少玩家胡乱合成、盲目进阶,浪费了大量稀有翅…...
)
37家金融客户紧急启用的DeepSeek扫描辅助加固包(含未公开API调用密钥策略)
更多请点击: https://kaifayun.com 第一章:DeepSeek漏洞扫描辅助的背景与战略价值 近年来,大模型在安全领域的应用正从辅助问答向深度协同防御演进。DeepSeek系列模型凭借其开源、高推理精度及强代码理解能力,成为构建智能化漏洞…...

在多轮对话应用中观察Taotoken计费对成本的影响
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在多轮对话应用中观察Taotoken计费对成本的影响 效果展示类,结合一个需要维护长上下文的多轮对话应用案例,…...

Web渗透测试能力成长地图:从工具使用到漏洞认知跃迁
1. 这不是工具清单,而是一张Web渗透测试的“能力成长地图”你刚点开这篇文章,大概率正站在两个路口之间:一边是网上铺天盖地的“十大免费扫描器推荐”,点进去全是截图下载链接一句“一键扫漏洞”,结果装完跑两下&#…...