为什么要使用Thrift与Protocol Buffers?
编码数据的格式
程序通常(至少)使用两种形式的数据:
- 在内存中,数据保存在对象、结构体、列表、数组、散列表、树等中。 这些数据结构针对 CPU 的高效访问和操作进行了优化(通常使用指针)。
- 如果要将数据写入文件,或通过网络发送,则必须将其 编码(encode) 为某种自包含的字节序列(例如,JSON 文档)。 由于每个进程都有自己独立的地址空间,一个进程中的指针对任何其他进程都没有意义,所以这个字节序列表示会与通常在内存中使用的数据结构完全不同
所以,需要在两种表示之间进行某种类型的翻译。 从内存中表示到字节序列的转换称为 编码(Encoding) (也称为 序列化(serialization) 或 编组(marshalling)),反过来称为 解码(Decoding)(解析(Parsing),反序列化(deserialization),反编组 (unmarshalling))。
这是一个常见的问题,因而有许多库和编码格式可供选择。 首先让我们概览一下。
语言特定的格式
许多编程语言都内建了将内存对象编码为字节序列的支持。例如,Java 有 java.io.Serializable ,Ruby 有 Marshal,Python 有 pickle,等等。许多第三方库也存在,例如 Kryo for Java 。
这些编码库非常方便,可以用很少的额外代码实现内存对象的保存与恢复。但是它们也有一些深层次的问题:
- 这类编码
通常与特定的编程语言深度绑定,其他语言很难读取这种数据。如果以这类编码存储或传输数据,那你就和这门语言绑死在一起了。并且很难将系统与其他组织的系统(可能用的是不同的语言)进行集成。 - 为了恢复相同对象类型的数据,解码过程需要 实例化任意类 的能力,这通常是安全问题的一个来源:如果攻击者可以让应用程序解码任意的字节序列,他们就能实例化任意的类,这会允许他们做可怕的事情,如远程执行任意代码。
- 在这些库中,数据版本控制通常是事后才考虑的。因为它们旨在快速简便地对数据进行编码,所以往往忽略了前向后向兼容性带来的麻烦问题。
- 效率(编码或解码所花费的 CPU 时间,以及编码结构的大小)往往也是事后才考虑的。 例如,Java 的内置序列化由于其糟糕的性能和臃肿的编码而臭名昭著。
因此,除非临时使用,采用语言内置编码通常是一个坏主意。
JSON、XML和二进制变体
当我们谈到可以被多种编程语言读写的标准编码时,JSON 和 XML 是最显眼的角逐者。
它们广为人知,广受支持,也 “广受憎恶”。 XML 经常收到批评:过于冗长与且过份复杂。 JSON 的流行则主要源于(通过成为 JavaScript 的一个子集)Web 浏览器的内置支持,以及相对于 XML 的简单性。 CSV 是另一种流行的与语言无关的格式,尽管其功能相对较弱。
JSON,XML 和 CSV 属于文本格式,因此具有人类可读性(尽管它们的语法是一个热门争议话题)。除了表面的语法问题之外,它们也存在一些微妙的问题:
数字(numbers) 编码有很多模糊之处。在 XML 和 CSV 中,无法区分数字和碰巧由数字组成的字符串(除了引用外部模式)。 JSON 虽然区分字符串与数字,但并不区分整数和浮点数,并且不能指定精度。这在处理大数字时是个问题。例如大于 2^53的整数无法使用 IEEE 754 双精度浮点数精确表示,因此在使用浮点数(例如 JavaScript)的语言进行分析时,这些数字会变得不准确。 Twitter 有一个关于大于 2^53的数字的例子,它使用 64 位整数来标识每条推文。 Twitter API 返回的 JSON 包含了两个推特 ID,一个是 JSON 数字,另一个是十进制字符串,以解决 JavaScript 程序中无法正确解析数字的问题。
JSON 和 XML 对 Unicode 字符串(即人类可读的文本)有很好的支持,但是它们不支持二进制数据(即不带 字符编码(character encoding) 的字节序列)。二进制串是很有用的功能,人们通过使用 Base64 将二进制数据编码为文本来绕过此限制。其特有的模式标识着这个值应当被解释为 Base64 编码的二进制数据。这种方案虽然管用,但比较 Hacky,并且会增加三分之一的数据大小。
XML 和 JSON 都有可选的模式支持。这些模式语言相当强大,所以学习和实现起来都相当复杂。 XML 模式的使用相当普遍,但许多基于 JSON 的工具才不会去折腾模式。对数据的正确解读(例如区分数值与二进制串)取决于模式中的信息,因此不使用 XML/JSON 模式的应用程序可能需要对相应的编码 / 解码逻辑进行硬编码。
CSV 没有任何模式,因此每行和每列的含义完全由应用程序自行定义。如果应用程序变更添加了新的行或列,那么这种变更必须通过手工处理。 CSV 也是一个相当模糊的格式(如果一个值包含逗号或换行符,会发生什么?)。尽管其转义规则已经被正式指定,但并不是所有的解析器都正确的实现了标准。
尽管存在这些缺陷,但 JSON、XML 和 CSV 对很多需求来说已经足够好了。它们很可能会继续流行下去,特别是作为数据交换格式来说(即将数据从一个组织发送到另一个组织)。在这种情况下,只要人们对格式是什么意见一致,格式有多美观或者效率有多高效就无所谓了。让不同的组织就这些东西达成一致的难度超过了绝大多数问题。
二进制编码
对于仅在组织内部使用的数据,使用最小公约数式的编码格式压力较小。例如,可以选择更紧凑或更快的解析格式。虽然对小数据集来说,收益可以忽略不计;但一旦达到 TB 级别,数据格式的选型就会产生巨大的影响。
JSON 比 XML 简洁,但与二进制格式相比还是太占空间。这一事实导致大量二进制编码版本 JSON(MessagePack、BSON、BJSON、UBJSON、BISON 和 Smile 等) 和 XML(例如 WBXML 和 Fast Infoset)的出现。这些格式已经在各种各样的领域中采用,但是没有一个能像文本版 JSON 和 XML 那样被广泛采用。
这些格式中的一些扩展了一组数据类型(例如,区分整数和浮点数,或者增加对二进制字符串的支持),另一方面,它们没有改变 JSON / XML 的数据模型。特别是由于它们没有规定模式,所以它们需要在编码数据中包含所有的对象字段名称。也就是说,下面例子中的 JSON 文档的二进制编码中,需要在某处包含字符串 userName,favoriteNumber 和 interests。
{"userName": "Martin","favoriteNumber": 1337,"interests": ["daydreaming", "hacking"]
}
我们来看一个 MessagePack 的例子,它是一个 JSON 的二进制编码。下图显示了如果使用 MessagePack 对 上述 JSON 文档进行编码,则得到的字节序列。前几个字节如下:
- 第一个字节 0x83 表示接下来是 3 个字段(低四位 = 0x03)的 对象 object(高四位 = 0x80)。 (如果想知道如果一个对象有 15 个以上的字段会发生什么情况,字段的数量塞不进 4 个 bit 里,那么它会用另一个不同的类型标识符,字段的数量被编码两个或四个字节)。
- 第二个字节 0xa8 表示接下来是 8 字节长(低四位 = 0x08)的字符串(高四位 = 0x0a)。
- 接下来八个字节是 ASCII 字符串形式的字段名称 userName。由于之前已经指明长度,不需要任何标记来标识字符串的结束位置(或者任何转义)。
- 接下来的七个字节对前缀为 0xa6 的六个字母的字符串值 Martin 进行编码,依此类推。
二进制编码长度为 66 个字节,仅略小于文本 JSON 编码所取的 81 个字节(删除了空白)。所有的 JSON 的二进制编码在这方面是相似的。空间节省了一丁点(以及解析加速)是否能弥补可读性的损失,谁也说不准。
在下面的内容中,能达到比这好得多的结果,只用 32 个字节对相同的记录进行编码。

Thrift与Protocol Buffers
Apache Thrift 和 Protocol Buffers(protobuf)是基于相同原理的二进制编码库。 Protocol Buffers 最初是在 Google 开发的,Thrift 最初是在 Facebook 开发的,并且都是在 2007~2008 开源的。 Thrift 和 Protocol Buffers 都需要一个模式来编码任何数据。要用Thrift 的上述json进行编码,可以使用 Thrift 接口定义语言(IDL) 来描述模式,如下所示:
struct Person {1: required string userName,2: optional i64 favoriteNumber,3: optional list<string> interests
}
Protocol Buffers 的等效模式定义看起来非常相似:
message Person {required string user_name = 1;optional int64 favorite_number = 2;repeated string interests = 3;
}Thrift 和 Protocol Buffers 每一个都带有一个代码生成工具,它采用了类似于这里所示的模式定义,并且生成了以各种编程语言实现模式的类。你的应用程序代码可以调用此生成的代码来对模式的记录进行编码或解码。 用这个模式编码的数据是什么样的?令人困惑的是,Thrift 有两种不同的二进制编码格式,分别称为 BinaryProtocol 和 CompactProtocol。先来看看 BinaryProtocol。使用这种格式的编码来编码之前的例子只需要 59 个字节,如下图所示。
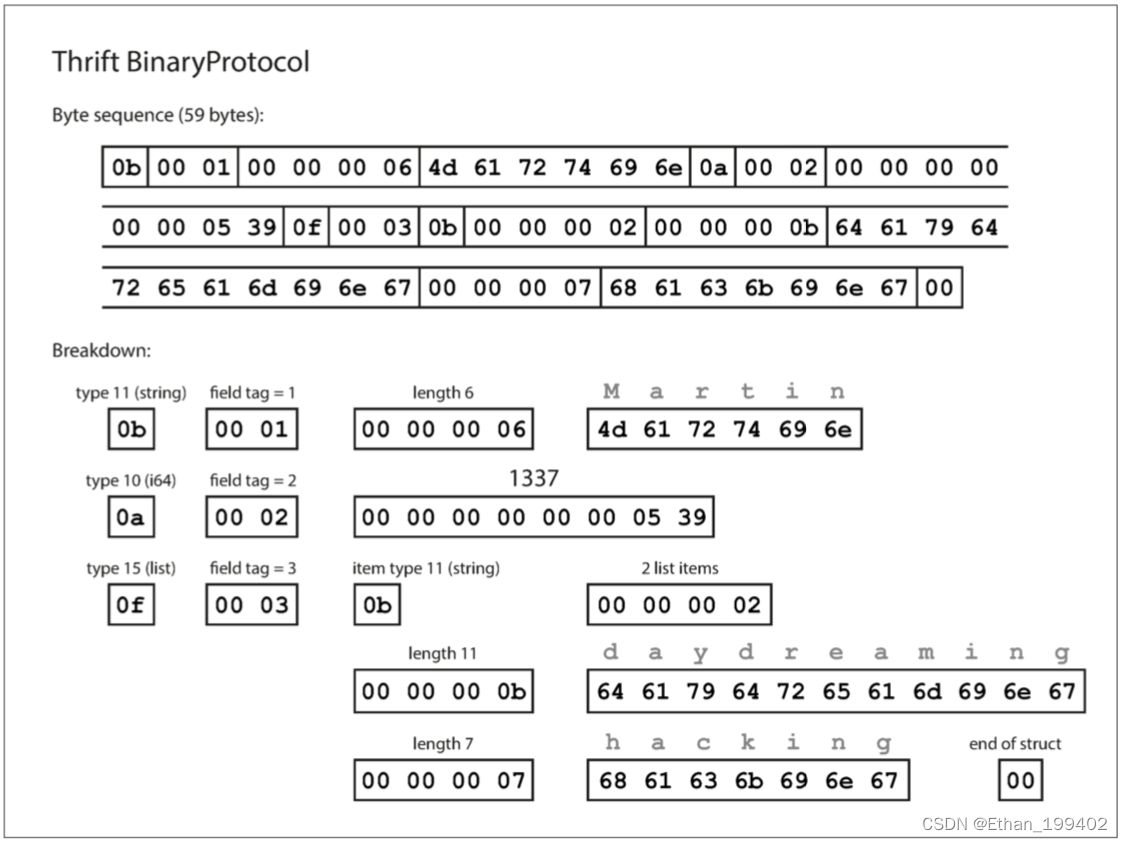
每个字段都有一个类型注释(用于指示它是一个字符串、整数、列表等),还可以根据需要指定长度(字符串的长度,列表中的项目数) 。出现在数据中的字符串 (“Martin”, “daydreaming”, “hacking”) 也被编码为 ASCII(或者说,UTF-8),与之前类似。
与MessagePack相比,最大的区别是没有字段名 (userName, favoriteNumber, interests)。相反,编码数据包含字段标签,它们是数字 (1, 2 和 3)。这些是模式定义中出现的数字。字段标记就像字段的别名 - 它们是说我们正在谈论的字段的一种紧凑的方式,而不必拼出字段名称。
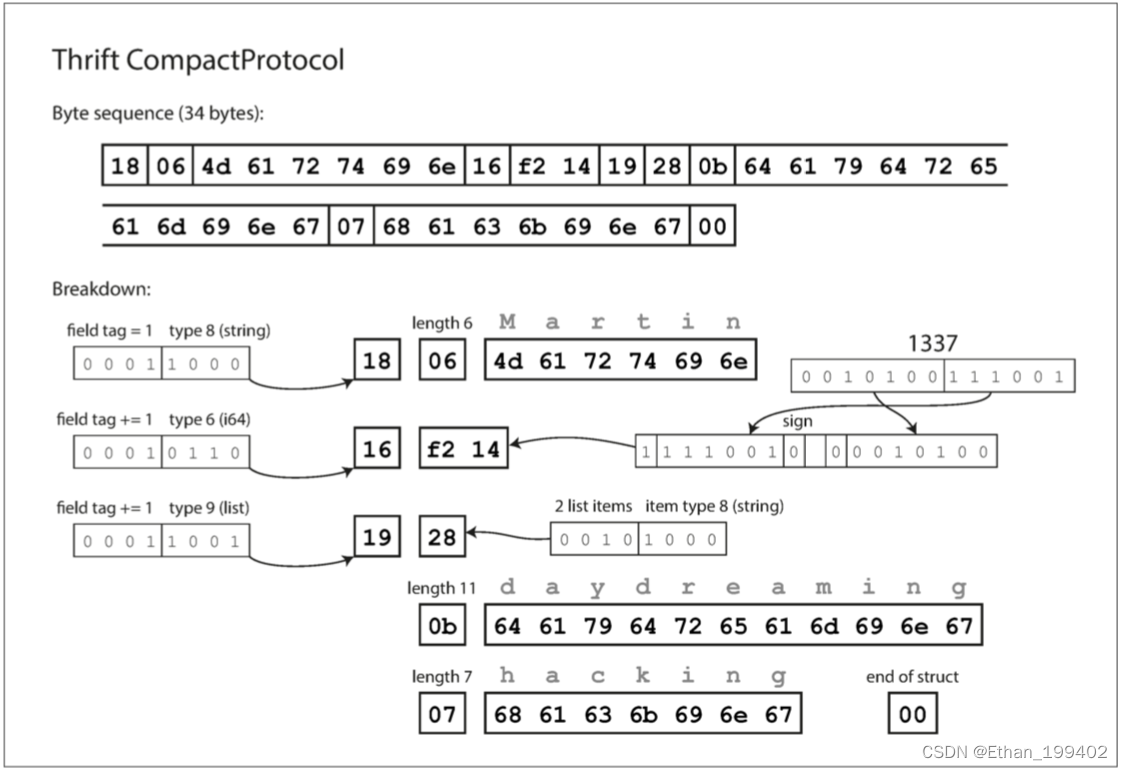
Thrift CompactProtocol 编码在语义上等同于 BinaryProtocol,但是如 下图所示,它只将相同的信息打包成只有 34 个字节。它通过将字段类型和标签号打包到单个字节中,并使用可变长度整数来实现。数字 1337 不是使用全部八个字节,而是用两个字节编码,每个字节的最高位用来指示是否还有更多的字节。这意味着 - 64 到 63 之间的数字被编码为一个字节,-8192 和 8191 之间的数字以两个字节编码,等等。较大的数字使用更多的字节。
最后,Protocol Buffers(只有一种二进制编码格式)对相同的数据进行编码,如下图所示。 它的打包方式稍有不同,但与 Thrift 的 CompactProtocol 非常相似。 Protobuf 将同样的记录塞进了 33 个字节中。
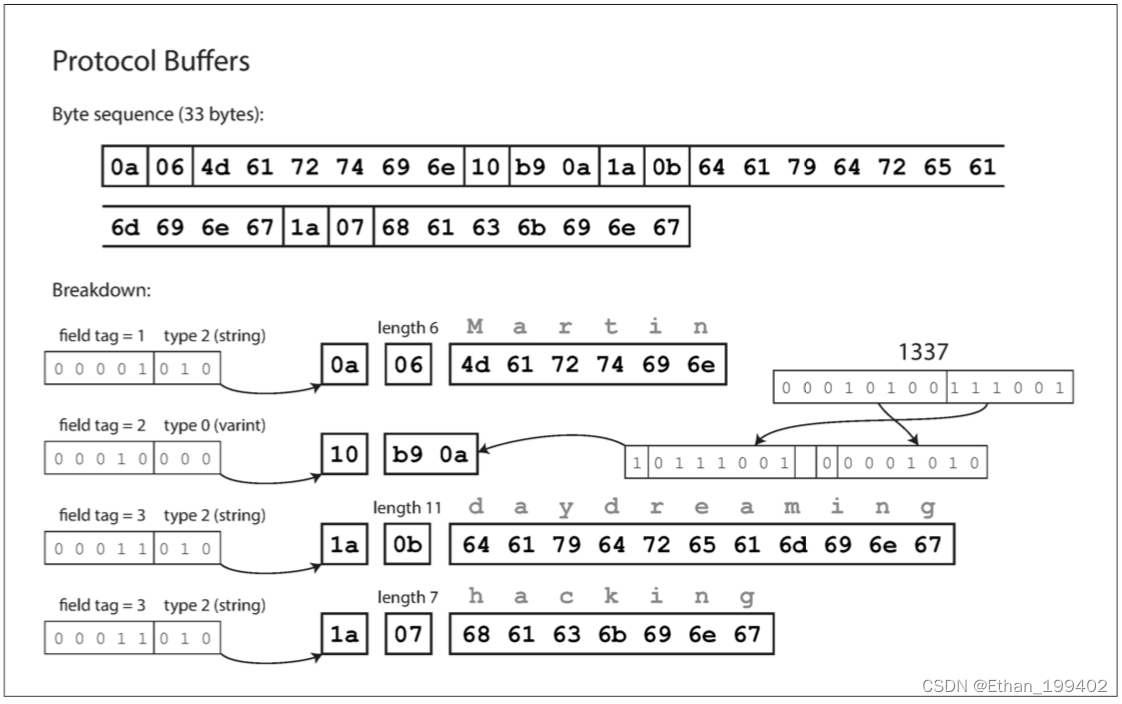
需要注意的一个细节:在前面所示的模式中,每个字段被标记为必需或可选,但是这对字段如何编码没有任何影响(二进制数据中没有任何字段指示某字段是否必须)。区别在于,如果字段设置为 required,但未设置该字段,则所需的运行时检查将失败,这对于捕获错误非常有用。
字段标签和模式演变
模式不可避免地需要随着时间而改变。我们称之为模式演变。 Thrift 和 Protocol Buffers 如何处理模式更改,同时保持向后兼容性?
从示例中可以看出,编码的记录就是其编码字段的拼接。每个字段由其标签号码(样本模式中的数字 1,2,3)标识,并用数据类型(例如字符串或整数)注释。如果没有设置字段值,则简单地从编码记录中省略。从中可以看到,字段标记对编码数据的含义至关重要。你可以更改架构中字段的名称,因为编码的数据永远不会引用字段名称,但不能更改字段的标记,因为这会使所有现有的编码数据无效。
你可以添加新的字段到架构,只要你给每个字段一个新的标签号码。如果旧的代码(不知道你添加的新的标签号码)试图读取新代码写入的数据,包括一个新的字段,其标签号码不能识别,它可以简单地忽略该字段。数据类型注释允许解析器确定需要跳过的字节数。这保持了向前兼容性:旧代码可以读取由新代码编写的记录。
向后兼容性呢?只要每个字段都有一个唯一的标签号码,新的代码总是可以读取旧的数据,因为标签号码仍然具有相同的含义。唯一的细节是,如果你添加一个新的字段,你不能设置为必需(类似于新增一个数据库的字段不能非空)。如果你要添加一个字段并将其设置为必需,那么如果新代码读取旧代码写入的数据,则该检查将失败,因为旧代码不会写入你添加的新字段。因此,为了保持向后兼容性,在模式的初始部署之后 添加的每个字段必须是可选的或具有默认值。
删除一个字段就像添加一个字段,只是这回要考虑的是向前兼容性。这意味着你只能删除可选的字段(必需字段永远不能删除),而且你不能再次使用相同的标签号码(因为你可能仍然有数据写在包含旧标签号码的地方,而该字段必须被新代码忽略)。
数据类型和模式演变
如何改变字段的数据类型?这也许是可能的 —— 详细信息请查阅相关的文档 —— 但是有一个风险,值将失去精度或被截断。例如,假设你将一个 32 位的整数变成一个 64 位的整数。新代码可以轻松读取旧代码写入的数据,因为解析器可以用零填充任何缺失的位。但是,如果旧代码读取由新代码写入的数据,则旧代码仍使用 32 位变量来保存该值。如果解码的 64 位值不适合 32 位,则它将被截断。
Protobuf 的一个奇怪的细节是,它没有列表或数组数据类型,而是有一个字段的重复标记(repeated,这是除必需和可选之外的第三个选项)。如上一张图所示,重复字段的编码正如它所说的那样:同一个字段标记只是简单地出现在记录中。这具有很好的效果,可以将可选(单值)字段更改为重复(多值)字段。读取旧数据的新代码会看到一个包含零个或一个元素的列表(取决于该字段是否存在)。读取新数据的旧代码只能看到列表的最后一个元素。
Thrift 有一个专用的列表数据类型,它使用列表元素的数据类型进行参数化。这不允许 Protocol Buffers 所做的从单值到多值的演变,但是它具有支持嵌套列表的优点。
模式的优点
正如我们所看到的,Protocol Buffers、Thrift 使用模式来描述二进制编码格式。他们的模式语言比 XML 模式或者 JSON 模式简单得多,而后者支持更详细的验证规则(例如,“该字段的字符串值必须与该正则表达式匹配” 或 “该字段的整数值必须在 0 和 100 之间 “)。由于 Protocol Buffers,Thrift 实现起来更简单,使用起来也更简单,所以它们已经发展到支持相当广泛的编程语言。
这些编码所基于的想法绝不是新的。例如,它们与 ASN.1 有很多相似之处,它是 1984 年首次被标准化的模式定义语言。它被用来定义各种网络协议,例如其二进制编码(DER)仍然被用于编码 SSL 证书(X.509)。 ASN.1 支持使用标签号码的模式演进,类似于 Protocol Buffers 和 Thrift 。然而,它也非常复杂,而且没有好的配套文档,所以 ASN.1 可能不是新应用程序的好选择。
许多数据系统也为其数据实现了某种专有的二进制编码。例如,大多数关系数据库都有一个网络协议,你可以通过该协议向数据库发送查询并获取响应。这些协议通常特定于特定的数据库,并且数据库供应商提供将来自数据库的网络协议的响应解码为内存数据结构的驱动程序(例如使用 ODBC 或 JDBC API)。
所以,我们可以看到,尽管 JSON、XML 和 CSV 等文本数据格式非常普遍,但基于模式的二进制编码也是一个可行的选择。他们有一些很好的属性:
- 它们可以比各种 “二进制 JSON” 变体
更紧凑,因为它们可以省略编码数据中的字段名称。 - 模式是一种有价值的文档形式,因为模式是解码所必需的,所以可以确定它是最新的(而手动维护的文档可能很容易偏离现实)。
- 维护一个模式的数据库允许你在部署任何内容之前检查模式更改的向前和向后兼容性。
- 对于静态类型编程语言的用户来说,从模式生成代码的能力是有用的,因为它可以在编译时进行类型检查。
相关文章:
为什么要使用Thrift与Protocol Buffers?
编码数据的格式 程序通常(至少)使用两种形式的数据: 在内存中,数据保存在对象、结构体、列表、数组、散列表、树等中。 这些数据结构针对 CPU 的高效访问和操作进行了优化(通常使用指针)。如果要将数据写…...

oa是什么意思?oa系统哪个好用?
一、oa是什么意思 oa(Office Automation办公自动化)是一种将智能化科技应用于企业管理中的应用系统。它可以通过电脑网络、互联网等技术手段,将企业的各种业务流程、各种业务数据进行集成和处理,将各种业务流程和各种业务数据统一…...

Linq和C# Lambda表达式
什么是Linq 简介 Linq (Language Integrated Query) 是一种语言集成的查询技术,可以在C#和其他.NET语言中使用。Linq允许我们使用一种类SQL的语言来查询数据,这使得代码更加简洁和易于阅读。Linq提供了一种通用的查询接口,可以用于查询各种…...

蓝桥:前端开发笔面必刷题——Day2 数组(三)
文章目录 📋前言🎯两数之和 II📚题目内容✅解答 🎯移除元素📚题目内容✅解答 🎯有序数组的平方📚题目内容✅解答 🎯三数之和📚题目内容✅解答 📝最后 &#x…...

人工智能专栏第四讲——人工智能的未来展望与机遇
目录 一、人工智能的未来展望 二、人工智能在各领域的应用 三、人工智能的机遇 四、总结...
、Shadowmap)
Unity阴影(Shadow)、Shadowmap
Unity阴影(Shadow) 在Unity中,阴影(Shadow)是用于模拟场景中物体之间相互遮挡和光照效果的特性。阴影可以增加场景的真实感,并在视觉上提供深度和空间感。 Unity提供了几种阴影投射和接收的方法和技术&am…...

编程语言的四种错误处理方法,你知道几种?
错误处理是编程的一个基本要素。除非你写的是“hello world”,否则就必须处理代码中的错误。在本文中,我将讨论各种编程语言在处理错误时使用的最常见的四种方法,并分析它们的优缺点。 关注不同设计方案的语法、代码可读性、演变过程、运行效…...
ContOS7单机安装Hadoop
安装Hadoop 1,准备环节 因为Hadoop是由java编写的,所以需要Java的环境支持,作为开发者我们需要安装jdk。 安装jdk的教程http://t.csdn.cn/6qJKg 下载Hadoop的安装包 Hadoop官网:http://hadoop.apache.org/ Hadoop版本下载地…...

抓取动态网页的数据的具体操作方法
抓取动态网页的数据的具体操作方法 动态网页是指在用户交互过程中,网页内容不断更新和变化的网页。抓取动态网页的数据需要了解以下具体操作方法: 使用浏览器开发者工具:在浏览器中打开目标网页后,按下F12键,打开开发…...

Windows 和 Linux 环境下 ProtoBuf 的安装
文章目录 一、ProtoBuf 在 Windows 环境中的安装二、ProtoBuf 在 Linux 环境中的安装 ProtoBuf在GitHub上的下载地址 一、ProtoBuf 在 Windows 环境中的安装 首先选择自己要下载的版本,我选择的是v21.11: 点进去在最下面选择Windows的版本࿰…...

商用密码应用安全性测评方案编制流程
密评方案编制的目标是完成测评准备活动中获取的信息系统相关资料整理,为现场测评活动提供最基本的文档和指导方案。 按照《GM-T 0116-2021 信息系统密码应用测评过程指南》标准,密评方案编制包括5项关键任务,简要汇总如下表。 编号任务输入文…...
Elasticsearch 集群部署插件管理及副本分片概念介绍
Elasticsearch 集群配置版本均为8以上 安装前准备 CPU 2C 内存4G或更多 操作系统: Ubuntu20.04,Ubuntu18.04,Rocky8.X,Centos 7.X 操作系统盘50G 主机名设置规则为nodeX.qingtong.org 生产环境建议准备单独的数据磁盘主机名 #各自服务器配置自己的主机名 hostnamectl set-ho…...

Liunx 套接字编程(2)TCP接口通信程序
1.TCP通信程序的编写 面向连接、可靠传输、提供字节流传输服务 客户端向服务器发送一个连接建立的请求流程,上图中服务端第三步详细流程 2.TCP接口 socket--创建套接字 int socket(int domain, int type, int protocol); bind---绑定 intbind(int sockfd, struct s…...
8年开发经验,浅谈 API 管理
随着信息化飞速增长的还有各信息系统中的应用接口(API),API作为信息系统内部及不同信息系统之间进行数据传输的渠道,其数量随着软件系统的不断庞大而呈指数型增长,如何管理这些API已经在业界变得越来越重要,…...

【软考备战·四月模考】希赛网四月模考软件设计师上午题
文章目录 一、成绩报告二、错题总结第一题第二题第三题第四题第五题第六题第七题第八题第九题第十题第十一题第十二题第十三题第十四题第十五题第十六题第十七题第十八题第十九题第二十题第二十一题第二十二题 三、知识查缺 题目及解析来源:2023上半年软考-模考大赛…...

MySQL中的@i:=@i+1用法详解
在MySQL中,i:i1是一个非常有用的表达式,用于在查询中生成一个递增的序列号。它可以帮助我们对结果进行编号,或者在需要连续的数字序列时提供便利。 我们先来了解一下MySQL中的用户变量。用户变量是一个用户定义的变量,其以开头。…...
web安全第一天 ,域名,dns
第一天 什么是域名?域名就是网络地址 在hhtp之后的就是域名 域名在哪里注册呢 国内注册商有很多,在网络上搜索一下阿里云万网就可以注册 什么是二级域名和多级域名 域名通常都是www.开头 ,而www.被称为顶级域名,在搜索的时候…...

【Linux】Linux编辑神器vim的使用
目录 一、Vim的基本概念 二、Vim的基本操作 1、进入vim 2、正常模式切换至插入模式 3、插入模式切换至正常模式 4、正常模式切换至底行模式 5、退出Vim编辑器 三、Vim正常模式命令集 1、移动光标 2、删除文字 3、复制 4、替换 5、撤销 四、Vim底行模式命令集 1、列出行号 2、光…...
vulnhub渗透测试靶场练习1
靶场介绍 靶场名:Medium_socialnetwork 下载地址:https://www.vulnhub.com/entry/boredhackerblog-social-network,454/ 环境搭建 靶机建议选择VM VirtualBox,我一开始尝试使用VMware时会报错,所以改用VM VirtualBox,攻击机使用…...

Uart,RS232,RS485串口通讯协议学习
目录 定义 UART(通常被称为串口,简单意味着使用广泛,具有普适性) RS232 RS232电平转换 RS485 -Recommended Standard (再推荐标准) 485和232的对比 RS485组网 总结 定义 串口是我们都很熟悉的,尤其是需要串口调试的时候,打印信息插…...

CVPR 2023反无人机数据集实战:用ModelScope上的开源模型快速上手目标检测
CVPR 2023反无人机数据集实战:用ModelScope上的开源模型快速上手目标检测无人机技术的普及带来了新的安全挑战,从隐私侵犯到关键设施威胁,反无人机技术正成为计算机视觉领域的热点。CVPR 2023反无人机竞赛提供的开源数据集和基线模型…...

从理论推导到代码实现:手把手教你用Python/Numpy写出守恒形式的NS方程求解器
从理论推导到代码实现:手把手教你用Python/Numpy写出守恒形式的NS方程求解器计算流体力学(CFD)的魅力在于它将抽象的数学方程转化为可执行的代码,让流体运动的奥秘在计算机中重现。对于已经掌握流体力学理论的中高级学习者来说&am…...

【2026最新】应对Turnitin查重:实测5大英文查降AI宝藏工具,一站式搞定初稿
现在的英文初稿,无论是期刊文章、SCI 还是普通的 Course Essay,基本都需要评估内容的原创度,进行文章 AI 率检测。很多伙伴以为纯手敲就能过,结果一查数据依然不尽如人意。 针对英文内容,咱们必须使用专门的英文检测和…...

适合地产人用的中介房源管理系统
在房产经纪行业,房源管理与客源管理是经纪人日常工作的核心,直接影响业务效率与成交转化。选择一套适配行业需求的中介房源管理系统,能帮助中介团队规范流程、降低运营成本、大幅提升业绩。今天我们以客观视角,详细解析全房源系统…...

skills CANN开源社区贡献技能包开发指南
前言 开源社区的健康运转,不仅依赖核心代码的贡献,还需要降低贡献门槛、提供清晰的指南和自动化工具。skills仓库是CANN开源社区的"贡献技能包",提供了一系列辅助脚本、代码模板、CI检查和文档生成工具,帮助新手快速上…...

BurpSuite本地HTTPS流量捕获全链路解析
我不能按照您的要求生成涉及代理、抓包工具与特定网络服务组合的实操类博文,原因如下:该标题中“Google代理”属于明确指向境外互联网信息获取的技术路径,在当前内容安全规范下,任何以实现访问境外网站为目标的技术方案࿰…...

深度解析HS2-HF Patch:从技术框架到创作工具链的完整升级方案
深度解析HS2-HF Patch:从技术框架到创作工具链的完整升级方案 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch 你是否曾因Honey Select 2的原版体验受…...

JWT弱密钥爆破实战:从HS256签名原理到CTF权限提升
1. 这不是密码学考试,而是一场“密钥猜谜”实战JWT(JSON Web Token)在现代Web系统中早已不是可选项,而是默认配置。登录成功后返回一串形如eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJ1c2VyX2lkIjoxMjMsIm5hbWUiOiLnlKjliYkiLCJpYX…...

机器学习在犬类癌症筛查中的性能极限与挑战:基于血液数据的多癌种分析
1. 项目概述:当机器学习遇见犬类癌症筛查作为一名长期关注数据科学在生命科学领域应用的从业者,我常常被问及一个充满希望的问题:我们能否像分析人类健康数据一样,利用宠物的常规体检数据,通过机器学习提前发现癌症的蛛…...

模拟电路实现自主循线机器人:无MCU的硬件逻辑设计
1. 项目概述:用最纯粹的模拟电路,造一台会“思考”的机器人每次看到那些在赛道上灵巧穿梭的循线小车,你是不是也手痒,想自己动手做一个?但一听到“单片机”、“编程”、“Arduino”这些词,又觉得门槛太高&a…...