Elasticsearch 集群部署插件管理及副本分片概念介绍
Elasticsearch 集群配置版本均为8以上
安装前准备
CPU 2C 内存4G或更多
操作系统: Ubuntu20.04,Ubuntu18.04,Rocky8.X,Centos 7.X
操作系统盘50G
主机名设置规则为nodeX.qingtong.org
生产环境建议准备单独的数据磁盘
主机名
#各自服务器配置自己的主机名
hostnamectl set-hostname es-node1.qingtong.org
关闭防火墙和SELINUX
#RHEL系列的系统执行下以下配置
[root@es-node1 ~]# systemctl disable firewalld
[root@es-node1 ~]# systemctl disable NetworkManager
[root@es-node1 ~]# sed -i '/SELINUX/s/enforcing/disabled/' /etc/selinux/config
[root@es-node1 ~]# reboot
服务器配置本地域名解析可以选择做也可以不做
优化资源限制配置
内核参数 vm.max_map_count 用于限制一个进程可以拥有的VMA(虚拟内存区域)的数量
使用默认系统配置,二进制安装时会提示下面错误,包安装会自动修改此配置
#查看默认值
[root@es-node1 ~]#sysctl -a |grep vm.max_map_count
vm.max_map_count = 65530
#修改配置
[root@es-node1 ~]#echo "vm.max_map_count = 262144" >> /etc/sysctl.conf
[root@es-node1 ~]#echo "fs.file-max = 1000000" >> /etc/sysctl.conf
[root@es-node1 ~]#sysctl -p
vm.max_map_count = 262144
修改资源限制配置
[root@es-node1 ~]#vi /etc/security/limits.conf
* soft core unlimited
* hard core unlimited
* soft nproc 1000000
* hard nproc 1000000
* soft nofile 1000000
* hard nofile 1000000
* soft memlock 32000
* hard memlock 32000
* soft msgqueue 8192000
* hard msgqueue 8192000
安装Java环境(可选)
Elasticsearch 是基于java的应用,所以依赖JDK环境
注意: 安装7.X以后版本官方建议要安装集成JDK的包,所以无需再专门安装 JDK
关于JDK环境说明
1.x 2.x 5.x 6.x都没有集成JDK的安装包,也就是需要自己安装java环境
7.x的安装包分为带JDK和不带JDK两种包,带JDK的包在安装时不需要再安装java,如果不带JDK的包仍然需要自己去安装java
8.x的安装包默认不区分带JDK和不带JDK,所以8版本此处忽略
官网JAVA版支持说明:
https://www.elastic.co/cn/support/matrix#matrix_jvm
Elasticsearch 安装
!!! 推荐7.x及以上版本安装,避免手动配置JAVA环境出错 !!!
官方下载地址:
https://www.elastic.co/cn/downloads/elasticsearch
包安装
如果是 X86_64 版本可以考虑吧国内清华大学镜像源下载安装
https://mirrors.tuna.tsinghua.edu.cn/elasticstack/
# Centos安装
yum -y install elasticsearch-8.7.1-x86_64.rpm# Ubuntu安装
dpkg -i elasticsearch-8.7.1-amd64.deb
如果是linux_arrch64 版本就设置官方的 yum 源来下载
https://www.elastic.co/guide/en/elasticsearch/reference/8.7/rpm.html#rpm-repo
按照官方的文档操作下载即可
1、下载并安装公共签名密钥:
rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
2、手动创建 Elasticsearch.repo
cat << EOF > /etc/yum.repos.d/elasticsearch.repo
[elasticsearch]
name=Elasticsearch repository for 8.x packages
baseurl=https://artifacts.elastic.co/packages/8.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=0
autorefresh=1
type=rpm-md
EOF
3、安装
sudo yum install --enablerepo=elasticsearch elasticsearch
sudo dnf install --enablerepo=elasticsearch elasticsearch
二进制安装
官方文档
https://www.elastic.co/guide/en/elasticsearch/reference/master/targz.html
下载二进制文件
https://www.elastic.co/cn/downloads/elasticsearch
范例:基于二进制包含JDK文件安装
1、下载解压安装包
[root@ubuntu1804 ~]#ls
elasticsearch-7.6.2-linux-x86_64.tar.gz
[root@ubuntu1804 ~]#tar xf elasticsearch-7.6.2-linux-x86_64.tar.gz -C
/usr/local/
[root@ubuntu1804 ~]#ls /usr/local/
bin elasticsearch-7.6.2 etc games include lib man sbin share src
[root@ubuntu1804 ~]#ln -s /usr/local/elasticsearch-7.6.2/
/usr/local/elasticsearch
[root@ubuntu1804 ~]#ls /usr/local/elasticsearch
bin config jdk lib LICENSE.txt logs modules NOTICE.txt plugins
README.asciidoc
2、编辑配置文件
编辑配置文件可参考下一个标题内的内容。8.X以下版本无需配置 Xpack
3、二进制安装需手动创建用户,在所有节点上创建用户
useradd -r elasticsearch
4、更改目录权限,配置方法参照下面
5、启动服务(在所有节点上配置)
[root@es-node1 ~]#echo 'PATH=/usr/local/elasticsearch/bin:$PATH' >
/etc/profile.d/elasticsearch.sh
[root@es-node1 ~]#. /etc/profile.d/elasticsearch.sh
[root@es-node1 ~]#tail -f /data/es-logs/es-cluster.log
#不能以root用户运行,切换用户
[root@es-node1 ~]#su - elasticsearch
6、验证端口
ss -ntl | grep java
7、创建service文件
[root@es-node1 ~]#cat /lib/systemd/system/elasticsearch.service
[Unit]
Description=Elasticsearch
Documentation=http://www.elastic.co
Wants=network-online.target
After=network-online.target
[Service]
RuntimeDirectory=elasticsearch
PrivateTmp=true
Environment=PID_DIR=/var/run/elasticsearch
WorkingDirectory=/usr/local/elasticsearch
User=elasticsearch
Group=elasticsearch
ExecStart=/usr/local/elasticsearch/bin/elasticsearch -p
${PID_DIR}/elasticsearch.pid --quiet
# StandardOutput is configured to redirect to journalctl since
# some error messages may be logged in standard output before
# elasticsearch logging system is initialized. Elasticsearch
# stores its logs in /var/log/elasticsearch and does not use
# journalctl by default. If you also want to enable journalctl
# logging, you can simply remove the "quiet" option from ExecStart.
# Specifies the maximum file descriptor number that can be opened by this
process
LimitNOFILE=65535
# Specifies the maximum number of processes
LimitNPROC=4096
# Specifies the maximum size of virtual memory
LimitAS=infinity
# Specifies the maximum file size
LimitFSIZE=infinity
# Disable timeout logic and wait until process is stopped
TimeoutStopSec=0
# SIGTERM signal is used to stop the Java process
KillSignal=SIGTERM
# Send the signal only to the JVM rather than its control group
KillMode=process
# Java process is never killed
SendSIGKILL=no
# When a JVM receives a SIGTERM signal it exits with code 143
SuccessExitStatus=143
[Install]
WantedBy=multi-user.target
# Built for packages-7.6.2 (packages)
[root@es-node1 ~]#systemctl daemon-reload
[root@es-node1 ~]#systemctl enable --now elasticsearch.service
基于docker部署
官方文档
https://www.elastic.co/guide/en/elasticsearch/reference/7.5/docker.html
单节点部署
[root@ubuntu1804 ~]#docker run --name es-single-node -d -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" docker.elastic.co/elasticsearch/elasticsearch:7.6.2
多节点集群部署
注意:此方式需要3G以上的内存,否则会出现OOM的告警
创建docker-compose.yml 文件
[root@ubuntu1804 ~]#cat docker-compose.yml
version: '2.2'
services:es01:image: docker.elastic.co/elasticsearch/elasticsearch:7.5.2container_name: es01environment:- node.name=es01- cluster.name=es-docker-cluster- discovery.seed_hosts=es02,es03- cluster.initial_master_nodes=es01,es02,es03- bootstrap.memory_lock=true- "ES_JAVA_OPTS=-Xms512m -Xmx512m"ulimits:memlock:soft: -1hard: -1volumes:- data01:/usr/share/elasticsearch/dataports:- 9200:9200networks:- elastices02:image: docker.elastic.co/elasticsearch/elasticsearch:7.5.2container_name: es02environment:- node.name=es02- cluster.name=es-docker-cluster- discovery.seed_hosts=es01,es03- cluster.initial_master_nodes=es01,es02,es03- bootstrap.memory_lock=true- "ES_JAVA_OPTS=-Xms512m -Xmx512m"ulimits:memlock:soft: -1hard: -1volumes:- data02:/usr/share/elasticsearch/datanetworks:- elastices03:image: docker.elastic.co/elasticsearch/elasticsearch:7.5.2container_name: es03environment:- node.name=es03- cluster.name=es-docker-cluster- discovery.seed_hosts=es01,es02- cluster.initial_master_nodes=es01,es02,es03- bootstrap.memory_lock=true- "ES_JAVA_OPTS=-Xms512m -Xmx512m"ulimits:memlock:soft: -1hard: -1volumes:- data03:/usr/share/elasticsearch/datanetworks:- elastic
volumes:data01:driver: localdata02:driver: localdata03:driver: local
networks:elastic:driver: bridge
启动集群
[root@ubuntu1804 ~]#docker-compose up -d
编辑服务配置文件
配置文件说明
[root@es-node1 ~]# grep -Ev '#|^$'/etc/elasticsearch/elasticsearch.yml#ELK集群名称,同一个集群内每个节点的此项必须相同,新加集群的节点此项和其它节点相同即可加入集群,而
无需再验证
cluster.name: ELK-Cluster
#当前节点在集群内的节点名称,同一集群中每个节点要确保此名称唯一
node.name: es-node1
#ES 数据保存目录
path.data: /data/es-data
#ES 日志保存目录
path.logs: /data/es-logs
#服务启动的时候立即分配(锁定)足够的内存,防止数据写入swap,提高启动速度
bootstrap.memory_lock: true
#指定监听IP,如果绑定了错误的IP,可将此修改为指定IP
network.host: 0.0.0.0
#监听端口
http.port: 9200
#8.x版本的新特性 xpack认证
xpack.security.enabled: true
xpack.security.enrollment.enabled: true
xpack.security.http.ssl:enabled: truekeystore.path: certs/http.p12
xpack.security.transport.ssl:enabled: trueverification_mode: certificatekeystore.path: certs/transport.p12truststore.path: certs/transport.p12
#发现集群的node节点列表,可以添加部分或全部节点IP
#在新增节点到集群时,此处需指定至少一个已经在集群中的节点地址
discovery.seed_hosts: ["10.0.0.101","10.0.0.102","10.0.0.103"] #集群初始化时指定希望哪些节点可以被选举为 master,只在初始化时使用,新加节点到已有集群时此项可不
配置
cluster.initial_master_nodes: ["10.0.0.101","10.0.0.102","10.0.0.103"] #一个集群中的 N 个节点启动后,才允许进行数据恢复处理,默认是1,一般设为为所有节点的一半以上,防止
出现脑裂现象
#当集群无法启动时,可以将之修改为1,或者将下面行注释掉,实现快速恢复启动
gateway.recover_after_nodes: 2 #设置是否可以通过正则表达式或者_all匹配索引库进行删除或者关闭索引库,默认true表示必须需要明确指
定索引库名称,不能使用正则表达式和_all,生产环境建议设置为 true,防止误删索引库。
action.destructive_requires_name: true
#不参与主节点选举
node.master: false
#存储数据,此值为false则不存储数据而成为一个路由节点
#如果将true改为false,需要先执行/usr/share/elasticsearch/bin/elasticsearch-node
repurpose 清理数据
node.data: true
#7.x以后版本下面指令已废弃,在2.x 5.x 6.x 版本中用于配置节点发现列表
discovery.zen.ping.unicast.hosts: ["10.0.0.101", "10.0.0.102","10.0.0.103"]
单节点配置
[root@ubuntu2004 ~]#grep -v '#' /etc/elasticsearch/elasticsearch.yml
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
node.name: node-1
network.host: 0.0.0.0
discovery.seed_hosts: ["10.0.0.100"]
cluster.initial_master_nodes: ["node-1"]
集群配置
cluster.name: es-cluster
node.name: es-node1
path.data: /data/es-data
path.logs: /data/es-logs
xpack.security.enabled: false #建议关闭
xpack.security.enrollment.enabled: false #建议关闭
xpack.security.http.ssl:enabled: false #建议关闭keystore.path: certs/http.p12
xpack.security.transport.ssl:enabled: false #建议关闭verification_mode: certificatekeystore.path: certs/transport.p12truststore.path: certs/transport.p12
bootstrap.memory_lock: true
network.host: 0.0.0.0
http.port: 9200
discovery.seed_hosts: ["192.168.31.14","192.168.31.178","192.168.31.184"]
cluster.initial_master_nodes: ["192.168.31.14","192.168.31.178","192.168.31.184"]
将配置同步至其他集群节点
[root@es-node1 ~]# scp /etc/elasticsearch/elasticsearch.yml esnode2:/etc/elasticsearch/[root@es-node2 ~]#grep -v "#" /etc/elasticsearch/elasticsearch.yml
cluster.name: es-cluster
node.name: es-node2 #只需修改次行,每个节点都不能相同
path.data: /data/es-data
path.logs: /data/es-logs
xpack.security.enabled: false
xpack.security.enrollment.enabled: false
xpack.security.http.ssl:enabled: falsekeystore.path: certs/http.p12
xpack.security.transport.ssl:enabled: falseverification_mode: certificatekeystore.path: certs/transport.p12truststore.path: certs/transport.p12
bootstrap.memory_lock: true
network.host: 0.0.0.0
http.port: 9200
discovery.seed_hosts: ["192.168.31.14","192.168.31.178","192.168.31.184"]
cluster.initial_master_nodes: ["192.168.31.14","192.168.31.178","192.168.31.184"]
开启bootstrap.memory_lock: true 导致无法启动的错误解决方法
官方文档:
https://www.elastic.co/guide/en/elasticsearch/reference/current/setupconfiguration-memory.html#bootstrap-memory_lock
https://www.elastic.co/guide/en/elasticsearch/reference/current/setting-systemsettings.html#systemd
解决办法:
[root@es-node1 ~]# vim /usr/lib/systemd/system/elasticsearch.service
LimitMEMLOCK=infinity[root@node1 ~]#systemctl daemon-reload
[root@node1 ~]#systemctl restart elasticsearch.service
[root@node1 ~]#systemctl is-active elasticsearch.service
active
目录权限
在各个ES服务器创建数据和日志目录并修改目录权限为elasticsearch
#此步可选,可以不用创建下面目录es-data和es-logs,系统可以自动创建
[root@es-node1 ~]# mkdir -p /data/es-{data,logs}
[root@es-node1 ~]# ll /data/
total 0
drwxr-xr-x 2 root root 6 Apr 18 18:44 es-data
drwxr-xr-x 2 root root 6 Apr 18 18:44 es-logs
#必须分配权限,否则服务无法启动
[root@es-node1 ~]# chown -R elasticsearch.elasticsearch /data/
[root@es-node1 ~]# ll /data/
total 0
drwxr-xr-x 2 elasticsearch elasticsearch 6 Apr 18 18:44 es-data
drwxr-xr-x 2 elasticsearch elasticsearch 6 Apr 18 18:44 es-logs
启动Elasticsearch服务并验证
[root@es-node1 ~]#systemctl enable --now elasticsearch
验证端口监听成功
9200端口集群访问端口,9300集群同步端口

通过浏览器访问 Elasticsearch 服务端口
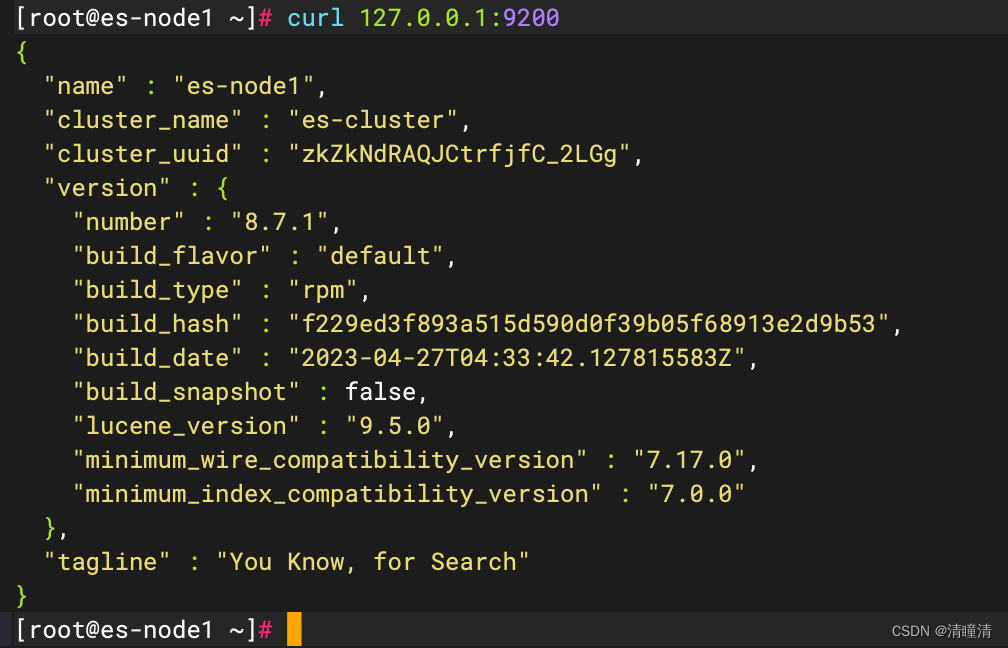
Elasticsearch 集群状态监控
官方文档
https://www.elastic.co/guide/en/elasticsearch/reference/master/rest-apis.html
Elasticsearch 支持各种语言使用 RESTful API 通过端口 9200 与之进行通信,可以用你习惯的 web 客户端访问 Elasticsearch
可以用三种方式和 Elasticsearch进行交互
- curl 命令和其它浏览器: 基于命令行,操作不方便
- 插件: 在node节点上安装head,Cerebro 等插件,实现图形操作,查看数据方便
- Kibana: 需要java环境并配置,图形操作,显示格式丰富
监控下面两个条件都满足才是正常的状态
- 集群状态为 green
- 所有节点都启动
SHELL命令
curl -sXGET http://elk服务器:9200/_cluster/health?pretty=true
获取到的是一个json格式的返回值,那就可以通过python对其中的信息进行分析,例如对status进行分析,如果等于green(绿色)就是运行在正常,等于yellow(黄色)表示副本分片丢失,red(红色)表示主分片丢失
ES集群状态:
- 绿色状态:表示集群各节点运行正常,而且没有丢失任何数据,各主分片和副本分片都运行正常
- 黄色状态:表示由于某个节点宕机或者其他情况引起的,node节点无法连接、所有主分片都正常分配,有副本分片丢失,但是还没有丢失任何数据
- 红色状态:表示由于某个节点宕机或者其他情况引起的主分片丢失及数据丢失,但仍可读取数据和存储
#查看支持的指令
curl http://127.0.0.1:9200/_cat
#查看es集群状态
curl http://127.0.0.1:9200/_cat/health
curl 'http://127.0.0.1:9200/_cat/health?v'
#查看所有的节点信息
curl 'http://127.0.0.1:9200/_cat/nodes?v'
#列出所有的索引 以及每个索引的相关信息
curl 'http://127.0.0.1:9200/_cat/indices?v'
#查看集群分健康性
curl http://127.0.0.1:9200/_cluster/health?pretty=true
创建索引
#创建索引index1,简单输出
[root@node1 ~]#curl -XPUT '192.168.31.14:9200/index1'
{"acknowledged":true,"shards_acknowledged":true,"index":"index1"}#创建索引index2,格式化输出
[root@node1 ~]#curl -XPUT '192.168.31.14:9200/index2?pretty'
{"acknowledged" : true,"shards_acknowledged" : true,"index" : "index2"
}#创建3个分片和2个副本
[root@node1 ~]#curl -XPUT '192.168.31.14:9200/index2' -H 'Content-Type:
application/json' -d '
{"settings": {"index": {"number_of_shards": 3, "number_of_replicas": 2}}
}'#调整副本数为1,但不能调整分片数
[root@node1 ~]#curl -XPUT '192.168.31.14:9200/index2/_settings' -H 'Content-Type:
application/json' -d '
{"settings": { "number_of_replicas": 1}
}'
{"acknowledged":true}
删除索引
#删除格式
curl -XDELETE http://kibana服务器:9200/<索引名称>
Elasticsearch 插件
head 插件
通过使用插件可以实现对 ES 集群的状态监控, 数据访问, 管理配置等功能。
Head 是一个 ES 在生产较为常用的插件
git地址::https://github.com/mobz/elasticsearch-head
安装方式
GitHub 上提供了三种安装方式(编译安装,docker,浏览器插件)可以根据自己的需要自行选择
这里我们选择比较简单也是比较常用的一种:浏览器插件
从谷歌应用商店下载安装插件,支持chrome 和 edge浏览器
注意:需要科学上网
https://chrome.google.com/webstore/detail/elasticsearchhead/ffmkiejjmecolpfloofpjologoblkegm/related
针对没办法科学上网的小伙伴,我已经将Head插件文件下载下来了,放在资源文件里。需要请移步自取 https://download.csdn.net/download/m0_51277041/87800160
安装完插件,点击图标就可以打开插件
登陆,集群中的任意节点IP登陆即可
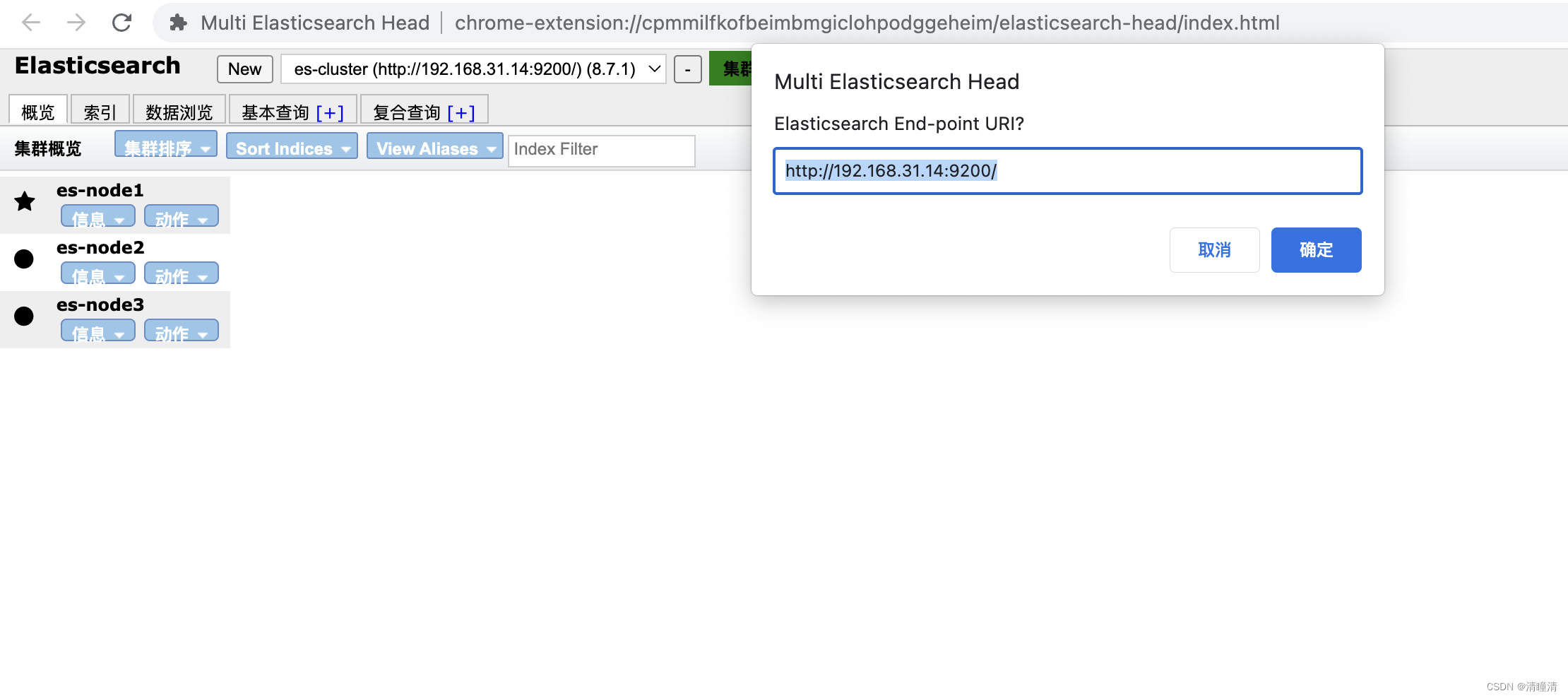
利用Head插件观察状态
head插件集群状态说明
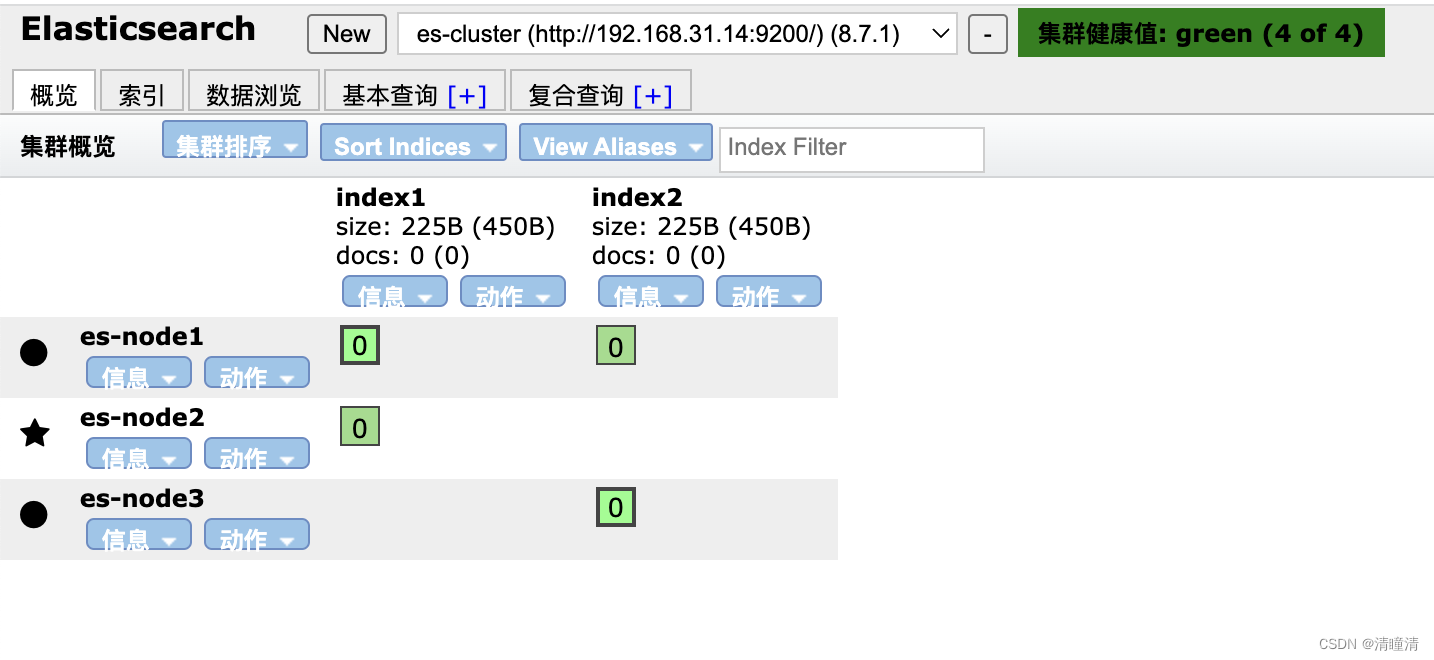
状态颜色说明:
- 绿色:索引数据完整,副本满足,所有条件都满足
- 黄色:索引数据完整,副本不满足,即数据没有丢失,但副本丢失,可能会影响容错功能
- 红色:有索引数据不完整的情况,即数据丢失
- 紫色:有数据分片正在同步过程中
0 表示分片的片shard编号
粗体线框为主分片,细体线框为副本分片
星表示主master节点,圆点表示slave工作节点
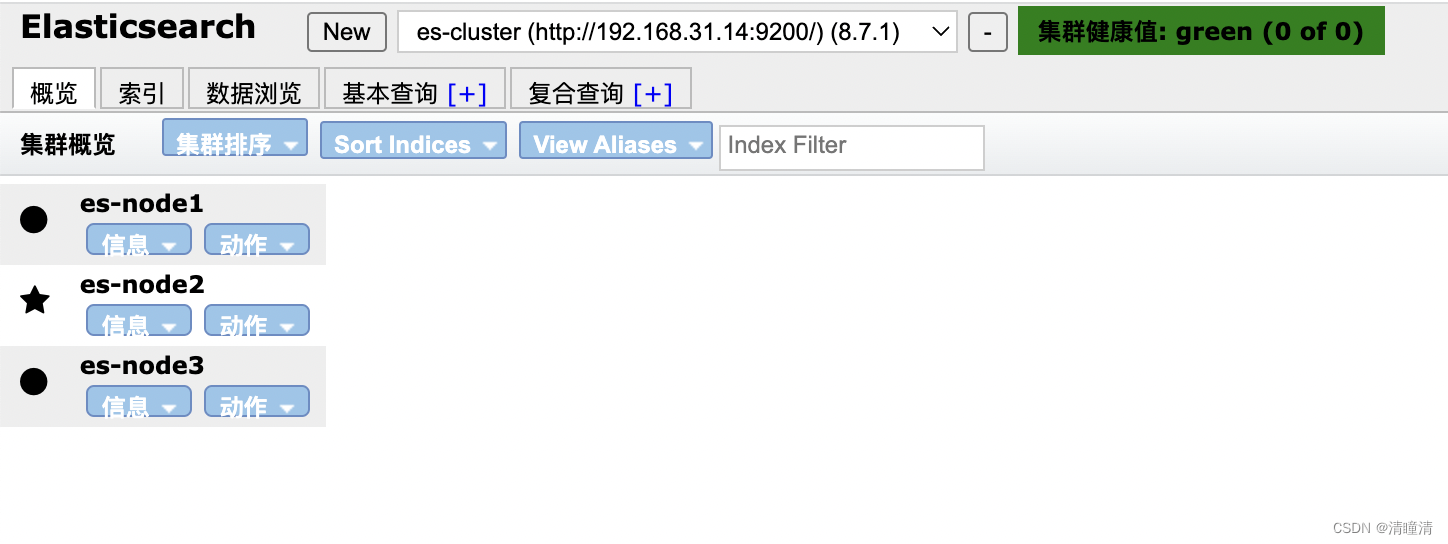
添加索引后,可以观察到下面的显示
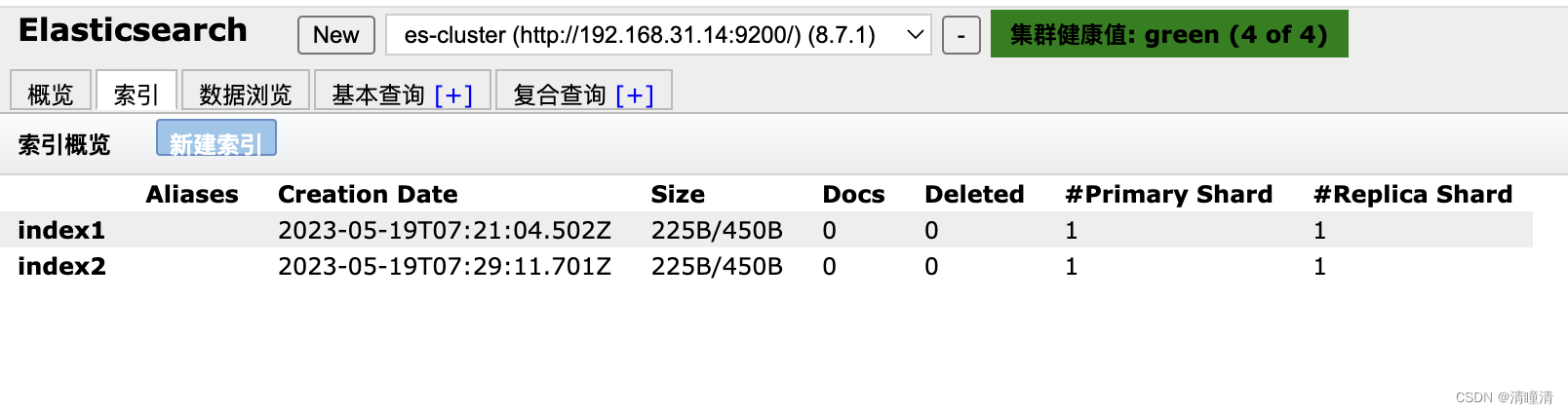
给索引插入数据
#_id 自动生成
#index1是索引数据库
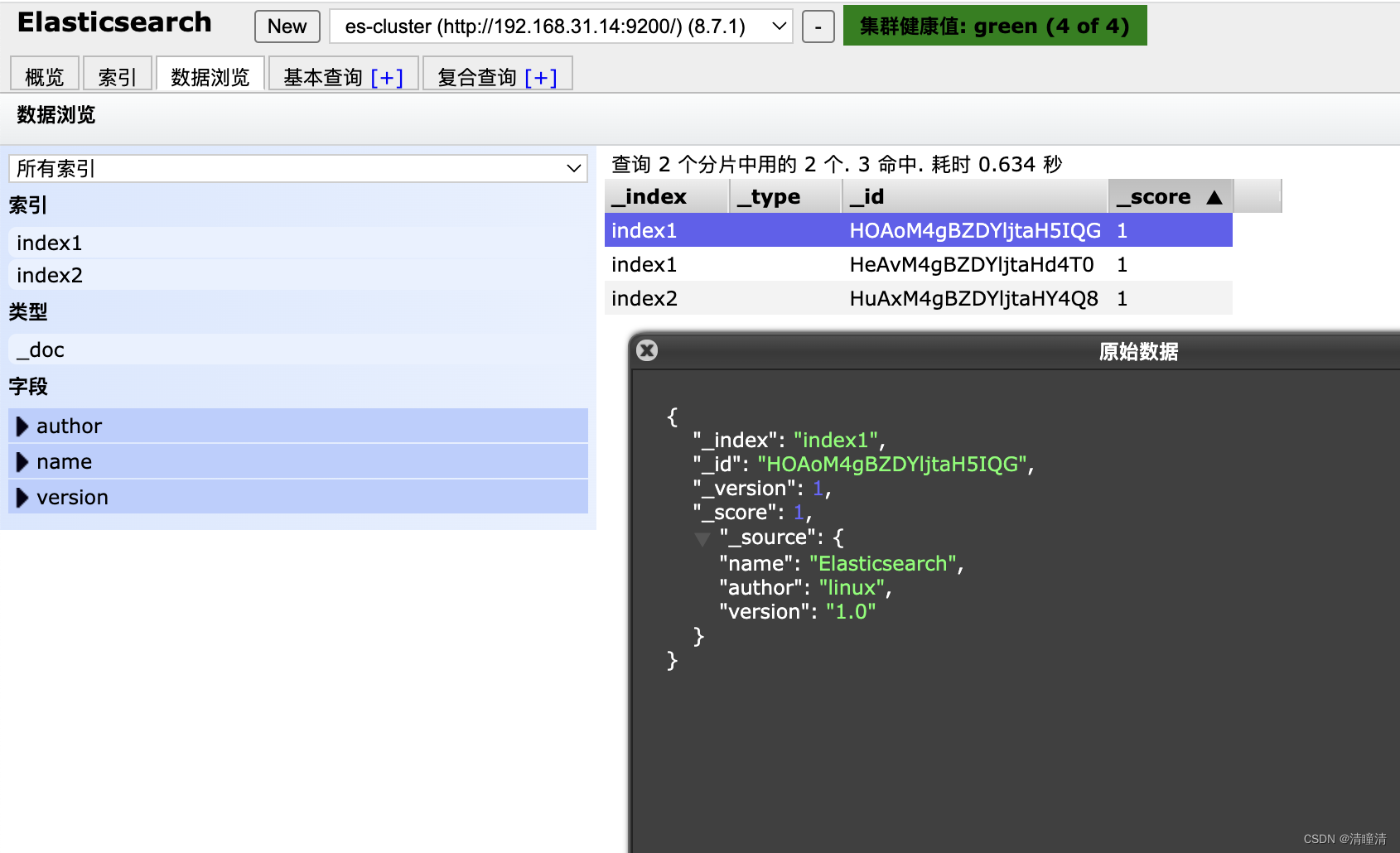
[root@node1 ~]#curl -XPOST http://192.168.31.14:9200/index1/_doc -H 'Content-Type: application/json' -d '{"name":"Elasticsearch", "author": "linux", "version": "1.0"}'
{"_index":"index1","_id":"HeAvM4gBZDYljtaHd4T0","_version":1,"result":"created","_shards:{"total":2,"successful":2,"failed":0},"_seq_no":1,"_primary_term":1}
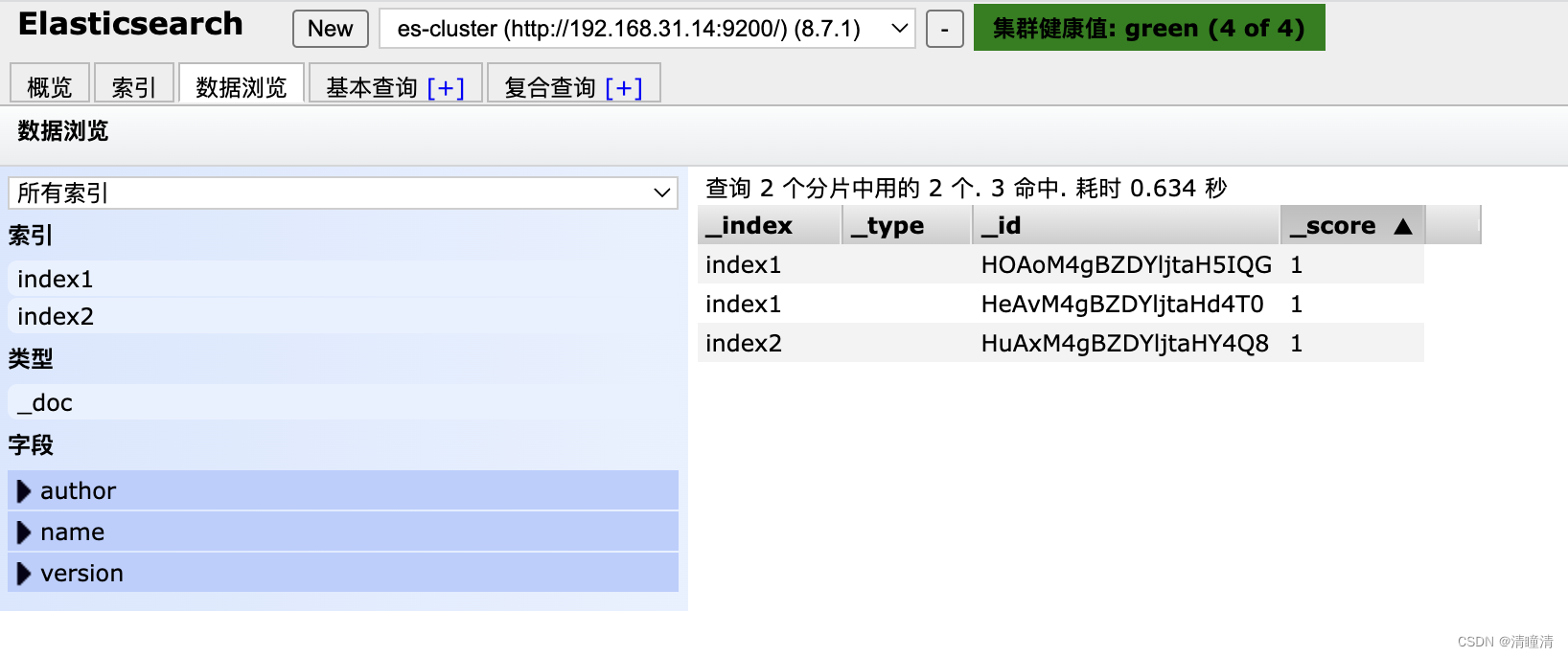
相关文章:
Elasticsearch 集群部署插件管理及副本分片概念介绍
Elasticsearch 集群配置版本均为8以上 安装前准备 CPU 2C 内存4G或更多 操作系统: Ubuntu20.04,Ubuntu18.04,Rocky8.X,Centos 7.X 操作系统盘50G 主机名设置规则为nodeX.qingtong.org 生产环境建议准备单独的数据磁盘主机名 #各自服务器配置自己的主机名 hostnamectl set-ho…...

Liunx 套接字编程(2)TCP接口通信程序
1.TCP通信程序的编写 面向连接、可靠传输、提供字节流传输服务 客户端向服务器发送一个连接建立的请求流程,上图中服务端第三步详细流程 2.TCP接口 socket--创建套接字 int socket(int domain, int type, int protocol); bind---绑定 intbind(int sockfd, struct s…...
8年开发经验,浅谈 API 管理
随着信息化飞速增长的还有各信息系统中的应用接口(API),API作为信息系统内部及不同信息系统之间进行数据传输的渠道,其数量随着软件系统的不断庞大而呈指数型增长,如何管理这些API已经在业界变得越来越重要,…...

【软考备战·四月模考】希赛网四月模考软件设计师上午题
文章目录 一、成绩报告二、错题总结第一题第二题第三题第四题第五题第六题第七题第八题第九题第十题第十一题第十二题第十三题第十四题第十五题第十六题第十七题第十八题第十九题第二十题第二十一题第二十二题 三、知识查缺 题目及解析来源:2023上半年软考-模考大赛…...

MySQL中的@i:=@i+1用法详解
在MySQL中,i:i1是一个非常有用的表达式,用于在查询中生成一个递增的序列号。它可以帮助我们对结果进行编号,或者在需要连续的数字序列时提供便利。 我们先来了解一下MySQL中的用户变量。用户变量是一个用户定义的变量,其以开头。…...
web安全第一天 ,域名,dns
第一天 什么是域名?域名就是网络地址 在hhtp之后的就是域名 域名在哪里注册呢 国内注册商有很多,在网络上搜索一下阿里云万网就可以注册 什么是二级域名和多级域名 域名通常都是www.开头 ,而www.被称为顶级域名,在搜索的时候…...

【Linux】Linux编辑神器vim的使用
目录 一、Vim的基本概念 二、Vim的基本操作 1、进入vim 2、正常模式切换至插入模式 3、插入模式切换至正常模式 4、正常模式切换至底行模式 5、退出Vim编辑器 三、Vim正常模式命令集 1、移动光标 2、删除文字 3、复制 4、替换 5、撤销 四、Vim底行模式命令集 1、列出行号 2、光…...
vulnhub渗透测试靶场练习1
靶场介绍 靶场名:Medium_socialnetwork 下载地址:https://www.vulnhub.com/entry/boredhackerblog-social-network,454/ 环境搭建 靶机建议选择VM VirtualBox,我一开始尝试使用VMware时会报错,所以改用VM VirtualBox,攻击机使用…...

Uart,RS232,RS485串口通讯协议学习
目录 定义 UART(通常被称为串口,简单意味着使用广泛,具有普适性) RS232 RS232电平转换 RS485 -Recommended Standard (再推荐标准) 485和232的对比 RS485组网 总结 定义 串口是我们都很熟悉的,尤其是需要串口调试的时候,打印信息插…...
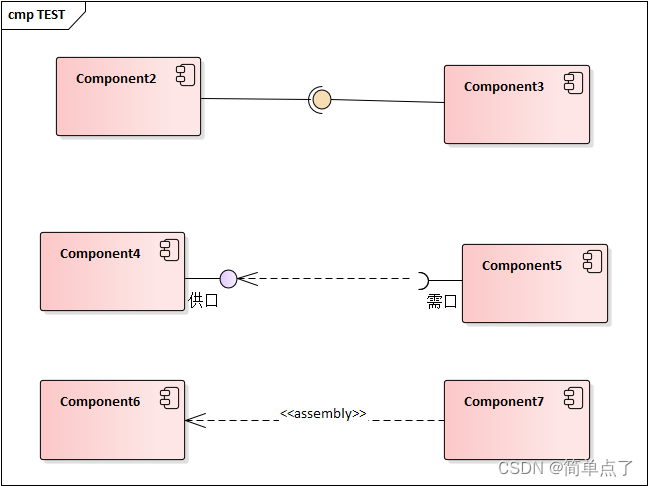
UML中的assembly关系
UML中的assembly关系 1.什么是Assembly关系 在UML(统一建模语言)中,"assembly"(组装)是一种表示组件之间关系的关联关系。组件是系统中可替换和独立的模块,可以通过组装来构建更大的系统。 当一…...

[Python]缓存cachetools与TTLCache简介
文章目录 cachetools缓存策略缓存操作 TTLCache cachetools是一个Python第三方库,提供了多种缓存算法的实现。 cachetools 使用前需要先安装pip install cachetools,说明文档参见https://cachetools.readthedocs.io/en/latest/。 cachetools提供了五种…...

现在的00后,真是卷死了呀,辞职信已经写好了·····
都说00后躺平了,但是有一说一,该卷的还是卷。这不,三月份春招我们公司来了个00后,工作没两年,跳槽到我们公司起薪23K,都快接近我了。 后来才知道人家是个卷王,从早干到晚就差搬张床到工位睡觉了…...

【wpf】列表类,用相对源时,如何绑定到子项
前言 在之前的一篇文章 :《【wpf】深度解析,Binding是如何寻找数据源的》https://blog.csdn.net/songhuangong123/article/details/126195727#:~:text%E3%80%90wpf%E3%80%91%E6%B7%B1%E5%BA%A6%E8%A7%A3%E6%9E%90%EF%BC%8CBinding%E6%98%AF%E5%A6%82%E4…...

头歌计算机组成原理实验—运算器设计(3)第3关:4位快速加法器设计
第3关:4位快速加法器设计 实验目的 帮助学生掌握快速加法器中先行进位的原理,能利用相关知识设计4位先行进位电路,并利用设计的4位先行进位电路构造4位快速加法器,能分析对应电路的时间延迟。 视频讲解 实验内容 利用前一步设…...

Java中synchronized的优化
本文介绍为了实现高效并发,虚拟机对 synchronized 做的一系列的锁优化措施 高效并发是从 JDK5 升级到 JDK6 后一项重要的改进项,HotSpot 虚拟机开发团队在 JDK6 这个版本上花费了大量的资源去实现各种锁优化技术,如适应性自旋(Ada…...

软件测试技术课程:软件测试流程
软件测试流程如下: 测试计划测试设计测试执行 单元测试集成测试确认测试系统测试验收测试回归测试验证活动 测试计划 测试计划由测试负责人来编写,用于确定各个测试阶段的目标和策略。这个过程将输出测试计划,明确要完成的测试活动&#x…...
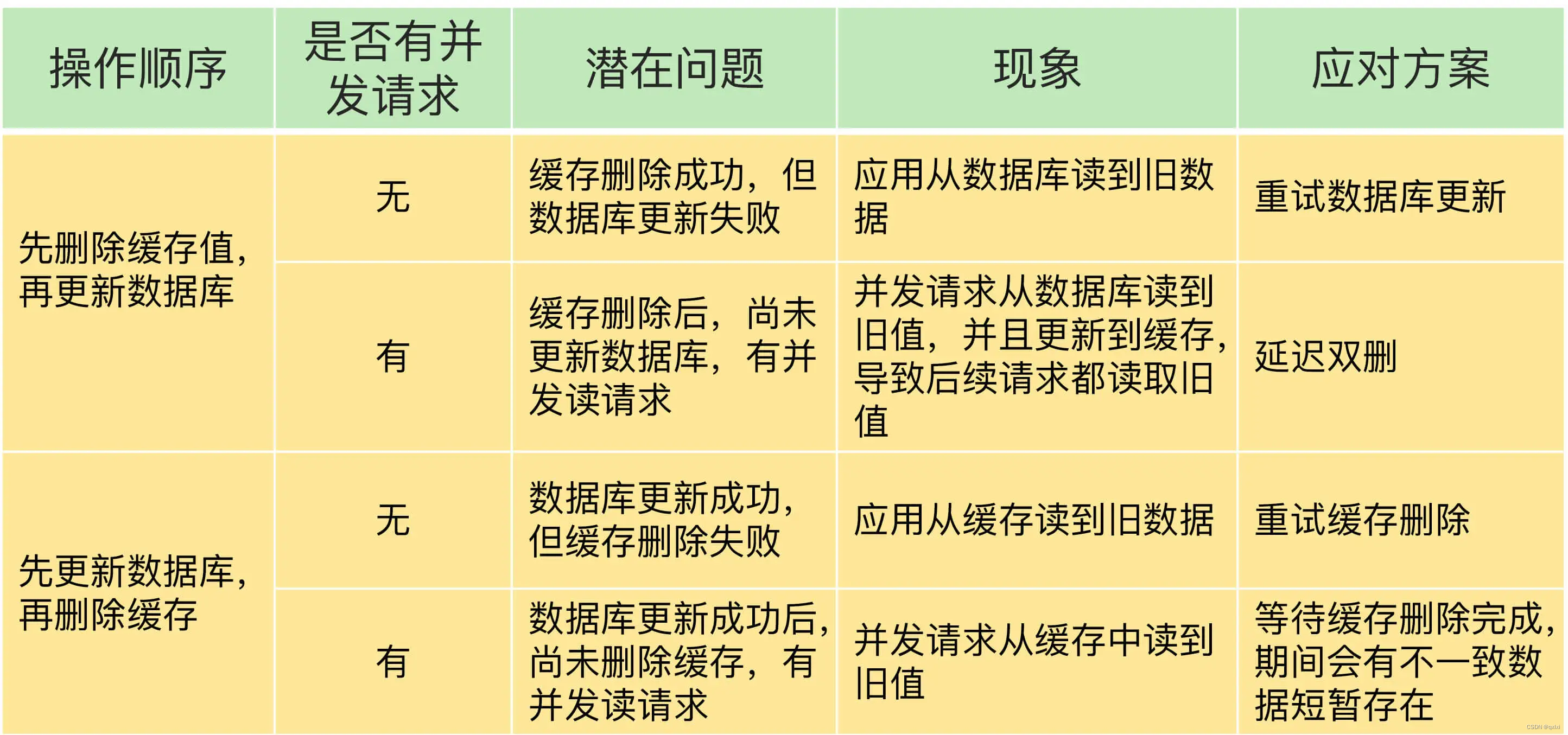
【Redis】聊一下缓存双写一致性
缓存虽然可以提高查询数据的的性能,但是在缓存和数据 进行更新的时候 其实会出现数据不一致现象,而这个不一致其实可能会给业务来带一定影响。无论是Redis 分布式缓存还是其他的缓存机制都面临这样的问题。 数据不一致是如何发生? 数据一致…...
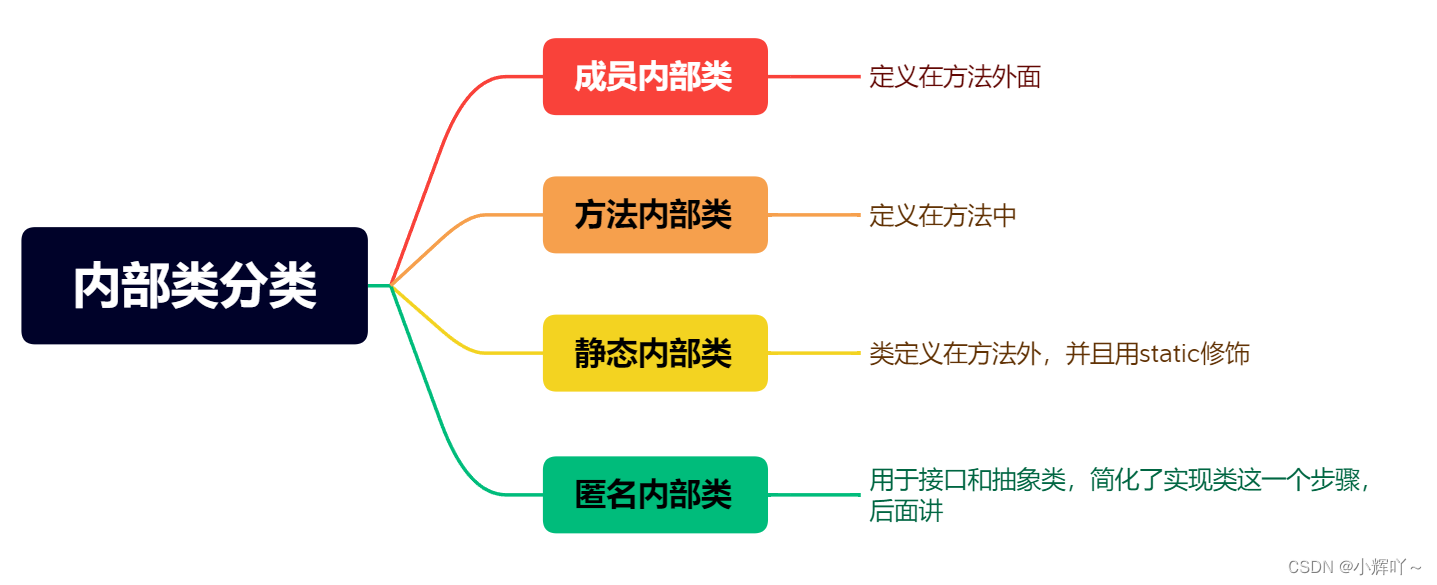
Java学习笔记-04
目录 静态成员 mian方法 多态 抽象类 接口 内部类 成员内部类 静态内部类 方法内部类 匿名内部类 静态成员 static关键字可以修饰成员方法,成员变量被static修饰的成员,成员变量就变成了静态变量,成员方法就变成了静态方法static修…...

pubspec.yaml 第三方依赖版本控制
以下是一些常见的版本控制方式: 精确版本号:您可以指定特定的版本号,例如 dependency_name: 1.2.3。这将确保只有指定的版本被安装和使用。 范围约束:您可以使用比较运算符来指定版本范围,例如 dependency_name: ^1.2…...

打印机出现错误0x00000709的原因及解决方法
一般来说,出现错误0x00000709,可能是用户试图设置默认打印机时,系统无法完成操作的错误。这种错误通常发生在Windows 10或Windows 7操作系统上。**驱动人生**分析,其原因可能是以下几种情况: 1、已经设置了另一个打印…...

物理引导的机器学习工作流:气候建模的融合创新与实践
1. 项目概述:当气候建模遇见机器学习如果你像我一样,在气候模拟这个领域摸爬滚打超过十年,就会深刻体会到一种“甜蜜的负担”:我们构建的地球系统模型(ESM)越来越精细,物理过程越来越复杂&#…...
)
ParaView时间戳设置全攻略:从基础标注到自定义格式(5.8.0实测)
ParaView时间戳设置全攻略:从基础标注到自定义格式(5.8.0实测) 在科学可视化领域,时间戳不仅是数据演变的见证者,更是研究成果呈现的专业语言。ParaView作为开源可视化工具链的标杆,其时间标注功能在学术论…...

SkillVLA:通过技能复用应对双-臂操纵中的组合多样性
26年3月来自新加坡国立、北京中关村学院、上海创新研究院、上海AI实验室、上海交大和复旦的论文“SkillVLA: Tackling Combinatorial Diversity in Dual-Arm Manipulation via Skill Reuse”。 视觉-语言-动作(VLA)模型近期取得的进展,已充分…...

Jupyter Notebook里跑argparse脚本总报错?一个空列表参数搞定ipykernel_launcher.py error
Jupyter Notebook中argparse报错的终极解决方案:空列表参数实战解析在数据科学和机器学习的工作流中,Jupyter Notebook因其交互式特性成为众多研究者的首选工具。然而,当我们尝试在Notebook中运行那些原本为命令行设计的Python脚本时…...
)
手把手教你用Mind+和Blynk,让手机轻松遥控掌控板(含自建服务器避坑指南)
从零搭建物联网控制平台:Mind与Blynk深度整合实战 当你第一次尝试用手机控制硬件设备时,那种"隔空取物"的奇妙感总会让人兴奋不已。想象一下,躺在沙发上就能调节书桌上的智能台灯亮度,或者在外出时随时查看家中的温湿度…...

基于树莓派打造万能遥控器:从硬件选型到Web控制界面全解析
1. 项目概述:打造一个能“学习”的万能遥控器家里遥控器越来越多,电视、空调、风扇、灯带……每个设备都配一个,找起来麻烦,用起来也乱。市面上所谓的“万能遥控器”其实并不万能,它内置的码库有限,很多小众…...

如何优化 MySQL 千万级数据分页查询的性能?
它的本质是:**传统 LIMIT offset, size 在大数据量下性能急剧下降,是因为 MySQL 必须 扫描并丢弃 前 offset 行数据。当 offset 很大时(如 LIMIT 1000000, 10),MySQL 需要读取 1,000,010 行记录,执行 1,000…...

3步终结Windows热键冲突:Hotkey Detective终极排查指南
3步终结Windows热键冲突:Hotkey Detective终极排查指南 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detective 你是否曾…...

Hitboxer:终极SOCD按键重映射解决方案,彻底解决游戏按键冲突问题
Hitboxer:终极SOCD按键重映射解决方案,彻底解决游戏按键冲突问题 【免费下载链接】socd Key remapper for epic gamers 项目地址: https://gitcode.com/gh_mirrors/so/socd 在激烈的游戏对战中,你是否曾因同时按下左右方向键而导致角色…...
)
第 2 期:广告视觉提效:FastAPI+LangChain 对接豆包图片模型(附完整代码)
https://mp.weixin.qq.com/s/El8_eV3wYCW-OPungbt7ng...