五、c++学习(加餐1:汇编基础学习)
经过前面几节课的学习,我们在一些地方都会使用汇编来分析,我们学习汇编,只是学习一些基础,主要是在我们需要深入分析语法的时候,使用汇编分析,这样会让我们更熟悉c++编译器和语法。
从这节课开始,会持续加餐,争取把类对象模型,分析出来。好了,不多说了,我们继续。
C++学习,b站直播视频
文章目录
- 5.1 x86汇编介绍
- 5.1.1 Intel汇编
- 5.1.2 AT&T汇编
- 5.2 x86寄存器介绍
- 5.2.1 Intel寄存器解读
- 5.2.2 Intel对数据的描述
- 5.2.3 寄存器作用描述
- 5.3 x86常用指令
- 5.3.1 mov 传送指令
- 5.3.2 push&pop
- 5.3.3 lea取地址
- 5.3.4 跳转语句
- 5.3.5 函数调用&返回
- 5.3.6 算术运算
- 5.3.7 位运算指令
- 5.3.8 附加:rep stos
- 5.4 AT&T汇编分析
- 5.5 Intel vs AT&T
- 5.5.1 操作数长度
- 5.5.2 寄存器命名
- 5.5.3 立即数
- 5.5.4 操作数的方向
- 5.5.5 内存单元操作数
- 5.5.6 间接寻址方式
- 5.5.7 总结
- 5.6 函数调用详解
- 5.6.1 函数参数约定
- 5.6.1.1 Intel方式
- 5.6.1.2 AT&T方式
- 5.6.2 函数的栈帧
- 5.6.2.1 Intel方式
- 5.6.2.2 AT&T方式
- 5.6.3 函数返回值
- 5.6.3.1 Intel方式
- 5.6.3.2 AT&T方式
- 5.6.4 函数退出
- 5.6.4.1 Intel方式
- 5.6.4.2 AT&T方式
- 5.7 扩展:ARM平台汇编分析
- 5.7.1 RISC与CISC的区别
- 5.7.2 ARM寄存器解读
- 5.7.3 ARM对数据的描述
- 5.7.4 ARM汇编浅析
5.1 x86汇编介绍
5.1.1 Intel汇编
Windows派系的汇编代码,VS就是我们一直用的这个IDE,就是这种风格的。不知道clang是什么风格,clang占的内存较大,我就不安装了,有条件的同学,可以自行测试。
后面几节课都是使用vs2022来分析的,所以这种汇编风格,我们是需要学习的。可以先来看看:
int func(int i)
{
00007FF72DF617E0 89 4C 24 08 mov dword ptr [rsp+8],ecx
00007FF72DF617E4 55 push rbp
00007FF72DF617E5 57 push rdi
00007FF72DF617E6 48 81 EC E8 00 00 00 sub rsp,0E8h
00007FF72DF617ED 48 8D 6C 24 20 lea rbp,[rsp+20h]
00007FF72DF617F2 48 8D 0D 6E F8 00 00 lea rcx,[00007FF72DF71067h]
00007FF72DF617F9 E8 54 FB FF FF call 00007FF72DF61352 return 2 * i;
00007FF72DF617FE 8B 85 E0 00 00 00 mov eax,dword ptr [rbp+00000000000000E0h]
00007FF72DF61804 D1 E0 shl eax,1
}
00007FF72DF61806 48 8D A5 C8 00 00 00 lea rsp,[rbp+00000000000000C8h]
00007FF72DF6180D 5F pop rdi
00007FF72DF6180E 5D pop rbp
00007FF72DF6180F C3 ret int main()
{
00007FF72DF61830 40 55 push rbp
00007FF72DF61832 57 push rdi
00007FF72DF61833 48 81 EC 08 01 00 00 sub rsp,108h
00007FF72DF6183A 48 8D 6C 24 20 lea rbp,[rsp+20h]
00007FF72DF6183F 48 8D 0D 21 F8 00 00 lea rcx,[00007FF72DF71067h]
00007FF72DF61846 E8 07 FB FF FF call 00007FF72DF61352 // std::cout << "Hello World!\n";int s = func(255);
00007FF72DF6184B B9 FF 00 00 00 mov ecx,0FFh
00007FF72DF61850 E8 82 F8 FF FF call 00007FF72DF610D7
00007FF72DF61855 89 45 04 mov dword ptr [rbp+4],eax return 0;
00007FF72DF61858 33 C0 xor eax,eax
}
00007FF72DF6185A 48 8D A5 E8 00 00 00 lea rsp,[rbp+00000000000000E8h]
00007FF72DF61861 5F pop rdi
00007FF72DF61862 5D pop rbp
00007FF72DF61863 C3 ret
5.1.2 AT&T汇编
AT&T汇编:读作“AT and T”,是 American Telephone & Telegraph 的缩写,是在贝尔实验室多年运营。
主要使用的地方就是GCC,Objdump。(这个我们学linux就知道了)。
主要使用的平台:Linux、Unix、Max OS、iOS(模拟器)
同一份代码,我们在linux下看看:
0000000000401146 <_Z4funci>:401146: 55 push %rbp401147: 48 89 e5 mov %rsp,%rbp40114a: 89 7d fc mov %edi,-0x4(%rbp)40114d: 8b 45 fc mov -0x4(%rbp),%eax401150: 01 c0 add %eax,%eax401152: 5d pop %rbp401153: c3 retq 0000000000401154 <main>:401154: 55 push %rbp401155: 48 89 e5 mov %rsp,%rbp401158: 48 83 ec 10 sub $0x10,%rsp40115c: bf ff 00 00 00 mov $0xff,%edi401161: e8 e0 ff ff ff callq 401146 <_Z4funci>401166: 89 45 fc mov %eax,-0x4(%rbp)401169: b8 00 00 00 00 mov $0x0,%eax40116e: c9 leaveq 40116f: c3 retq
感觉还是g++的风格简单些。
5.2 x86寄存器介绍

这个图来自《深入理解计算机系统》。
这些寄存器都是x86体系下的寄存器,当然x86的寄存器还有很多,我下载过intel的芯片手册,都是英文,看的头都大了。我们只要了解这些就可以了。当然x86还有存浮点数的寄存器,这个没有了解,就不说,上面这个图,才是我们重点。注意最后面注释介绍的是AT&T。
5.2.1 Intel寄存器解读
Intel的寄存器有一个很有意思的地方,就是因为要兼容以前的,所以寄存器的位数从8位到16位到32位再到64位都有,我们看上面第一个寄存器RAX:
64位叫:rax
32位叫:eax
16位叫:ax
8位叫:al
所以我们待会看汇编的时候,就会看到,不过一般会看到rax和eax,现在16位和8位已经被淘汰了。
5.2.2 Intel对数据的描述
Intel作为业界的老大哥,背负的历史包袱过重,哈哈哈。
| c声明 | Intel数据类型 |
|---|---|
| char | 字节 |
| short | 字 |
| int | 双字 |
| long | 四字 |
总感觉当年16位的时候,觉得够大了吧,所以叫字,然后int出来之后,懵逼了,只能叫双字,这个其实不用记,只是简单介绍一下。(到时候可以看看ARM,没有历史负担就是任性)
5.2.3 寄存器作用描述
为啥是简单描述,是因为两种汇编风格对函数调用的传参不一样,这就有点难搞,哈哈哈。

图片引用了https://blog.csdn.net/c2682736/article/details/122349851这个链接的。
特殊用处寄存器介绍:
rax:函数返回值
rdx:在Intel方式中做第二个参数,在AT&T中做第三个参数,甚至还可以做第二个返回值寄存器。
rsp:栈顶指针,linux是满减栈,看着windows是往上加的栈
rbp:栈底指针,两个指针一减,就可以算出栈大小。
rip:指令寄存器
函数参数寄存器:这个因为两种方式不一样,所以在后面再详解。
5.3 x86常用指令
上面介绍了寄存器,接着我们介绍一下常用指令,指令+寄存器的操作,就相当于我们的一条语句。不过这个指令,不需要记,也记不住,说实话,看到不懂再查询。
5.3.1 mov 传送指令
// 我们先开始看mov命令,这个命令是出常见的,也是我们c++使用的赋值语句。int s = 1;
00007FF72F8E562D C7 45 04 01 00 00 00 mov dword ptr [rbp+4],1 // rbp是栈基地址,rbp+4就是s的地址,mov就是把1赋值到[rbp+4] (dword就是双字)// []是对这个地址寻址,也就是*(rbp+4)的意思int s1 = s;
00007FF72F8E5634 8B 45 04 mov eax,dword ptr [rbp+4] // 这是两个变量赋值,两个变量赋值,需要借助寄存器了,eax.// 第一次,先把[rbp+4]赋值eax寄存器
00007FF72F8E5637 89 45 24 mov dword ptr [rbp+24h],eax// 第二次,再把这个寄存器eax赋值到[rbp+24h],[rbp+24]就是s1的地址int* ps = &s;
00007FF72F8E563A 48 8D 45 04 lea rax,[rbp+4] // lea是我们后面介绍的,取地址指令,把[rbp+4]的地址赋值到rax中
00007FF72F8E563E 48 89 45 48 mov qword ptr [rbp+48h],rax // 然后在把rax的值赋值到[rbp+48h]中,(qword是四字,指针在64位系统都是8字节)*ps = 111;
00007FF72F8E5642 48 8B 45 48 mov rax,qword ptr [rbp+48h] // 把ps的值赋值到rax(因为ps是指针,所以这个值其实就是地址)
00007FF72F8E5646 C7 00 6F 00 00 00 mov dword ptr [rax],6Fh // 然后对rax就是指向的内存就行赋值,[]就是寻址的意思
5.3.2 push&pop
这两个命令一起来,很明显push是压栈,pop是出栈,只有调用函数才有这个操作。
我们来看看:
int test()
{
00007FF7486817D0 40 55 push rbp // 这是把上一个函数的栈基地址保存到栈里,具体的函数栈帧我们后面分析
00007FF7486817D2 57 push rdi // rdi没记错应该是第一个参数,我也不清楚为啥要入栈????
00007FF7486817D3 48 81 EC E8 00 00 00 sub rsp,0E8h // 这句也是我疑惑的地方,不是不知道这句意思,是不知道为啥windos栈能隔这么大。// 这句意思就是把栈指针往下减0E8h这么大空间
00007FF7486817DA 48 8D 6C 24 20 lea rbp,[rsp+20h]// 然后在把rsp往上加20h作为这个函数的栈空间,这个我试过了,如果变量过大,这个空间也会变大,等下我们试试
00007FF7486817DF 48 8D 0D 81 F8 00 00 lea rcx,[00007FF748691067h]
00007FF7486817E6 E8 67 FB FF FF call 00007FF748681352 // 后面这两句我更疑惑了,调用了一个函数,就不分析这个函数干啥了。return 0;
00007FF7486817EB 33 C0 xor eax,eax // xor是后面的指令,意思就是异或,反正两个都是0
}
00007FF7486817ED 48 8D A5 C8 00 00 00 lea rsp,[rbp+00000000000000C8h] // rbp+C8h其实就是等于rsp原来指向的地址,因为上面rbp=rsp+20h,这个20h+C8h=E8h,就是当初rsp减少的空间
00007FF7486817F4 5F pop rdi // 然后再把rdi从栈中弹出到rdi寄存器里
00007FF7486817F5 5D pop rbp // 上面把rsp还原了,这里肯定要把rbp也还原
00007FF7486817F6 C3 ret
5.3.3 lea取地址
这个上面说了,就不继续说,用处就是取地址。
5.3.4 跳转语句
int s2 = 0;
00007FF650C34671 C7 45 64 00 00 00 00 mov dword ptr [rbp+64h],0 if (s == 1)
00007FF650C34678 83 7D 04 01 cmp dword ptr [rbp+4],1 // cmp就是比较语句,比较这两个值是否想等// 如果operand1等于operand2,则ZF被置为1;否则,ZF被置为0。如果operand1小于operand2,则SF被置为1;否则,SF被置为0。如果操作过程中有进位,则CF被置为1;否则,CF被置为0。
00007FF650C3467C 75 07 jne 00007FF650C34685 // jne是判断上一条语句不等于0(即ZF标志位为0),两个不想等ZF为0才跳转// 还有其他跳转命令je jle jl jg等等{s2 = 1;
00007FF650C3467E C7 45 64 01 00 00 00 mov dword ptr [rbp+64h],1 }s2 = 2;
00007FF650C34685 C7 45 64 02 00 00 00 mov dword ptr [rbp+64h],2 // 后面就不解释了
5.3.5 函数调用&返回
// 测试push poptest();
00007FF650C3466C E8 54 CD FF FF call 00007FF650C313C5
call 函数调用&ret 返回这也比较常见了。
5.3.6 算术运算
- add 想加
- sub 相减
- inc 加1
- mul 相乘
- div 相除
int s4 = s3 + 4;
00007FF63E6F4C66 8B 85 84 00 00 00 mov eax,dword ptr [rbp+0000000000000084h]
00007FF63E6F4C6C 83 C0 04 add eax,4
其他的就不演示了。
5.3.7 位运算指令
- and 与运算
- or 或运算
- xor 异或运算
- not 取反
不演示了。
5.3.8 附加:rep stos
int s5[20] = { 0 };
00007FF6BD944C75 48 8D 85 D0 00 00 00 lea rax,[rbp+00000000000000D0h] // 把数组的地址赋值到rax中
00007FF6BD944C7C 48 8B F8 mov rdi,rax // 然后在赋值到rdi中
00007FF6BD944C7F 33 C0 xor eax,eax // 然后把eax清0
00007FF6BD944C81 B9 50 00 00 00 mov ecx,50h // 50h是这个数组的大小
00007FF6BD944C86 F3 AA rep stos byte ptr [rdi]
这个还挺常用的,用在一个结构体或类或数组,一些符合数据结构置0的时候。
后面的rep stos是我们重点,这其实是两个指令复合使用。
REP(Repeat)汇编指令是一种重复执行指令的控制指令,它通常和其他指令组合使用,用于在处理字符串或数组时进行重复操作。
REP指令可以和多个其他指令搭配使用,如MOV、STOS等。其语法如下:
rep instruction
其中,instruction是要重复执行的指令。REP指令会将ECX寄存器中的值作为计数器,循环执行instruction指定的操作。每次循环都会将ECX减1,直到ECX的值为0为止。
还记得刚刚ecx赋值了50h
STOS指令:将AL/AX/EAX的值存储到[EDI]指定的内存单元
STOS指令使用AL(字节 - STOSB),AX(字 - STOSW)或EAX(对于双 - STOSD的)数据复制目标字符串,在内存中通过ES:DI指向。
我们这个数组是int,是双子,所以使用eax,我们前面不是刚用eax异或就是为了清0.
所以这个句话就是把数组清0了。
5.4 AT&T汇编分析
上面我们是对windos下的Intel汇编格式的分析,下面我们就分析linux下的AT&T汇编格式,这里就不在区分了,我们直接看了,看完了,我们下一节,就可以总结两种方式的差异。
// 编译是需要加-g,objdump -S 才能反汇编出带源码
0000000000401146 <_Z4testv>:#include <iostream>int test()
{401146: 55 push %rbp401147: 48 89 e5 mov %rsp,%rbpreturn 0;40114a: b8 00 00 00 00 mov $0x0,%eax
}40114f: 5d pop %rbp401150: c3 retq // retq就是退出// linux的函数风格我比较喜欢,因为比较简单,不像windos那么复杂0000000000401151 <main>:int main()
{401151: 55 push %rbp// 把栈基地址入栈,寄存器是用%401152: 48 89 e5 mov %rsp,%rbp// 把新的rsp地址移动到rbp,AT&T的mov源操作数是在中间401155: 48 83 ec 70 sub $0x70,%rsp// 把rsp栈的大小设置为0x70h,这么大int s = 1;401159: c7 45 e0 01 00 00 00 movl $0x1,-0x20(%rbp)// l其实就是int,rbp-20h就是s的地址,原来这就是满减栈的意思,window是栈是往上加int s1 = s;401160: 8b 45 e0 mov -0x20(%rbp),%eax// 如果不看源码,这个确实不好理解,就是把rbp-20h的值赋值给eax401163: 89 45 fc mov %eax,-0x4(%rbp)// 然后再把eax的值赋值到s1,这里有点奇怪为啥s1的地址是rbp-4h??int* ps = &s;401166: 48 8d 45 e0 lea -0x20(%rbp),%rax// lea取地址,熟悉不,就是把s的地址赋值到rax中40116a: 48 89 45 f0 mov %rax,-0x10(%rbp)// 然后再在rax赋值到ps里,这里ps的地址是rbp-10h*ps = 111;40116e: 48 8b 45 f0 mov -0x10(%rbp),%rax401172: c7 00 6f 00 00 00 movl $0x6f,(%rax)// 这个也是赋值,这个()也是寻址意思,跟Intel的[]是一个意思// 测试push poptest();401178: e8 c9 ff ff ff callq 401146 <_Z4testv>// 调用也是用call,不过加了个后缀int s2 = 0;40117d: c7 45 ec 00 00 00 00 movl $0x0,-0x14(%rbp)if (s == 1)401184: 8b 45 e0 mov -0x20(%rbp),%eax401187: 83 f8 01 cmp $0x1,%eax40118a: 75 07 jne 401193 <main+0x42>// 这个cmp和jne就一样了{s2 = 1;40118c: c7 45 ec 01 00 00 00 movl $0x1,-0x14(%rbp)}s2 = 2;401193: c7 45 ec 02 00 00 00 movl $0x2,-0x14(%rbp)int s3 = 1 + 4;40119a: c7 45 e8 05 00 00 00 movl $0x5,-0x18(%rbp)int s4 = s3 + 4;4011a1: 8b 45 e8 mov -0x18(%rbp),%eax4011a4: 83 c0 04 add $0x4,%eax4011a7: 89 45 e4 mov %eax,-0x1c(%rbp)// add也是一样的int s5[20] = { 0 };4011aa: 48 c7 45 90 00 00 00 movq $0x0,-0x70(%rbp)4011b1: 00 4011b2: 48 c7 45 98 00 00 00 movq $0x0,-0x68(%rbp)4011b9: 00 4011ba: 48 c7 45 a0 00 00 00 movq $0x0,-0x60(%rbp)4011c1: 00 4011c2: 48 c7 45 a8 00 00 00 movq $0x0,-0x58(%rbp)4011c9: 00 4011ca: 48 c7 45 b0 00 00 00 movq $0x0,-0x50(%rbp)4011d1: 00 4011d2: 48 c7 45 b8 00 00 00 movq $0x0,-0x48(%rbp)4011d9: 00 4011da: 48 c7 45 c0 00 00 00 movq $0x0,-0x40(%rbp)4011e1: 00 4011e2: 48 c7 45 c8 00 00 00 movq $0x0,-0x38(%rbp)4011e9: 00 4011ea: 48 c7 45 d0 00 00 00 movq $0x0,-0x30(%rbp)4011f1: 00 4011f2: 48 c7 45 d8 00 00 00 movq $0x0,-0x28(%rbp)4011f9: 00 // 看来linux下没有rep stos这个命令,在使用笨方式一个一个清0return 0;4011fa: b8 00 00 00 00 mov $0x0,%eax
}4011ff: c9 leaveq 401200: c3 retq
5.5 Intel vs AT&T
上面我们分析过了Intel和AT&T的汇编,然后我们来总结一下,这两种汇编的区别。
5.5.1 操作数长度
我们操作一个数的大小,其实可以通过在汇编指令上体现出来的。
AT&T的操作码后面有一个后缀,其含义就是操作码的大小。
(后缀分别为:b、w、l、q)
在Intel的语法中,则要在内存单元操作数的前面加上前缀。
(前缀分别为:byte ptr、world ptr、dworld ptr、qworld ptr)
| c声明 | Intel数据类型 | Intel语法 | AT&T语法 | 大小 |
|---|---|---|---|---|
| char | 字节 | mov al,bl | movb %bl,%al | 1 |
| short | 字 | mov ax,bx | movw %bx,%ax | 2 |
| int | 双字 | mov eax,dworld ptr[ebx] | movl (%ebx),%eax | 4 |
| long | 四字 | mov rax, qworld ptr[rbx] | movq (%rbx),%rax | 8 |
| float | 单精度 | 不知道 | 后缀s | 4 |
| char * | 四字 | 不知道 | 后缀q | 8 |
| double | 双精度 | 不知道 | 后缀l | 8 |
我对汇编指令操作浮点确实不熟悉,因为我们自己分析的大部分都是整数,以后如果碰到了,操作浮点的,再回来补充补充。
5.5.2 寄存器命名
通过上面的例子,应该都发现了,寄存器命名两种方式的汇编不一样。
在Intel的语法中,寄存器是不需要前缀的。
在AT&T的语法中,寄存器是需要加%前缀
| Intel语法 | AT&T语法 |
|---|---|
| mov rax, qworld ptr[rbx] | movq (%rbx),%rax |
5.5.3 立即数
立即数的写法也不一样。
在Intel语法中,十六进制和二进制立即数后面分别冠以h和b
在AT&T语法中,立即数前面加上$,然后如果是十六进制前面再加上0x
| Intel语法 | AT&T语法 |
|---|---|
| mov eax,8 | movl **$**8,%eax |
| mov ebx,0ffffh | movl **$**0xffff,%ebx |
5.5.4 操作数的方向
这一点我就好奇,为啥搞的方向相反,这样看起代码,真的难受。
Intel与AT&T操作数的方式正好相反。
在Intel语法中,第一个操作数是目的操作数,第二个操作数是源操作数
在AT&T中,第一个数是源操作数,第二个数是目的操作数
| Intel语法 | AT&T语法 |
|---|---|
| mov eax,[ecx] | movl (%ecx),%eax |
5.5.5 内存单元操作数
从上面例子可以看出,内存操作数也有所不同。
在Intel的语法中,基寄存器用"[]"括起来。
在AT&T中,基寄存器用"()"括起来
| Intel语法 | AT&T语法 |
|---|---|
| mov eax,[ecx] | movl (%ecx),%eax |
5.5.6 间接寻址方式
与Intel的语法比较,AT&T间接寻址方式可能更晦涩难懂一些。
Intel的指令格式是:
segreg:[base+index*scale+disp]
AT&T的指令格式是:
%segreg:disp(base,index,scale)
格式解读:
- 其中index/scale/disp/segreg 全部可选的,完全可以简化掉。
- 如果没有指定scale而指定了index,则scale的缺省值为1.
- segreg段寄存器依赖于指令以及应用程序是运行在实模式还是保护模式下。在实模式下它依赖于指令,在保护模式下segreg是多余的。
- 在AT&T中,当立即数用在scale/disp中时,不应当在其前冠以$前缀
| Intel语法 指令segrg:[base+index*scale+disp] | AT&T语法 指令%segreg:disp(base,index,scale) |
|---|---|
| mov eax,[ebx+10h] | movl 0x10(%ebx),%eax |
| add eax,[ebx+ecx*2h] | addl (%ebx,%ecx,0x2),%eax |
| lea eax,[ebx+ecx] | leal (%ebx,%ecx),%eax |
| sub eax,[ebx+ecx*4h-20h] | subl -0x20(%eax,%ecx,0x4), %eax |
5.5.7 总结
| 项目 | Intel | AT&T | 说明 |
|---|---|---|---|
| 操作数长度 | mov rax, qworld ptr[rbx] | movq (%rbx),%rax | 一个加前缀,一个加后缀 |
| 寄存器命名 | mov rax, qworld ptr[rbx] | movq (%rbx),%rax | AT&T需要加% |
| 立即数 | mov ebx,0ffffh | movl **$**0xffff,%ebx | AT&T需要加$ |
| 操作数的方向 | mov eax,[ecx] | movl (%ecx),%eax | 刚好相反 |
| 内存单元操作数 | mov eax,[ecx] | movl (%ecx),%eax | 一个使用[],一个使用() |
| 间接寻址方式 | segreg:[base+index*scale+disp] | %segreg:disp(base,index,scale) | 其实都是Intel的方式计算 |
5.6 函数调用详解
前面吹了这么多水,终于来到我们这一篇的重点了,趁着我们刚学习汇编,还热乎,我们来分析一下函数是怎么调用的。
5.6.1 函数参数约定
我们调用函数的时候,会进行函数传参,那函数是怎么知道我们传了几个参数,并且每个参数的值是多少??
其实这都是约定好的,要命的是不同平台约定的不一样,真是离了大谱,增加了学习成本。
5.6.1.1 Intel方式
我们用什么方法来看这个约定的方式呢?其实很简单,我们直接写10个参数,哈哈哈哈。
test1(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
00007FF6EDCA1958 C7 44 24 48 0A 00 00 00 mov dword ptr [rsp+48h],0Ah
00007FF6EDCA1960 C7 44 24 40 09 00 00 00 mov dword ptr [rsp+40h],9
00007FF6EDCA1968 C7 44 24 38 08 00 00 00 mov dword ptr [rsp+38h],8
00007FF6EDCA1970 C7 44 24 30 07 00 00 00 mov dword ptr [rsp+30h],7
00007FF6EDCA1978 C7 44 24 28 06 00 00 00 mov dword ptr [rsp+28h],6
00007FF6EDCA1980 C7 44 24 20 05 00 00 00 mov dword ptr [rsp+20h],5 // 第5个参数开始入栈了
00007FF6EDCA1988 41 B9 04 00 00 00 mov r9d,4 // 第四个参数r9
00007FF6EDCA198E 41 B8 03 00 00 00 mov r8d,3 // 第三个参数r8
00007FF6EDCA1994 BA 02 00 00 00 mov edx,2 // 第二个参数rdx
00007FF6EDCA1999 B9 01 00 00 00 mov ecx,1 // 第一个参数rcx
00007FF6EDCA199E E8 7D F9 FF FF call 00007FF6EDCA1320
是不是一看汇编就明白了,这里我们就分析整数,浮点不做分析,后面有兴趣可以自行分析。
- rcx,rdx,r8,r9:用来存储整数或指针参数,安装从左到右顺序
- xmm0,1,2,3 用来存储浮点参数
- 其余参数会压入栈中。
5.6.1.2 AT&T方式
我们接下来看看AT&T方式:
test1(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);40125c: 6a 0a pushq $0xa // 第10个参数40125e: 6a 09 pushq $0x9 // 第九个参数401260: 6a 08 pushq $0x8 // 第八个参数401262: 6a 07 pushq $0x7 // 第七个参数401264: 41 b9 06 00 00 00 mov $0x6,%r9d // 第六个参数40126a: 41 b8 05 00 00 00 mov $0x5,%r8d // 第五个参数401270: b9 04 00 00 00 mov $0x4,%ecx // 第四个参数401275: ba 03 00 00 00 mov $0x3,%edx // 第三个参数40127a: be 02 00 00 00 mov $0x2,%esi // 第二个参数40127f: bf 01 00 00 00 mov $0x1,%edi // 第一个参数401284: e8 c8 fe ff ff callq 401151 <_Z5test1iiiiiiiiii>
这个也会看下汇编就懂了,下面是总结:
- 当参数在 6 个以内,参数从左到右依次放入寄存器: rdi, rsi, rdx, rcx, r8, r9。(多了rdi,rsi)
- 当参数大于 6 个, 大于六个的部分的依次从 “右向左” 压入栈中,和32位汇编一样。
5.6.2 函数的栈帧
通过上面认识到了函数参数,那我们来看看函数内部,这个函数的栈是怎么使用的。
5.6.2.1 Intel方式
int test1(int i1, int i2, int i3, int i4, int i5, int i6, int i7, int i8, int i9, int i10)
{
00007FF6EDCA1810 44 89 4C 24 20 mov dword ptr [rsp+20h],r9d
00007FF6EDCA1815 44 89 44 24 18 mov dword ptr [rsp+18h],r8d
00007FF6EDCA181A 89 54 24 10 mov dword ptr [rsp+10h],edx
00007FF6EDCA181E 89 4C 24 08 mov dword ptr [rsp+8],ecx // 这是rsp把前面的4个参数入栈,前面4个存储在寄存器里的,需要入栈\// 我们来看看这里的rsp = 000000D318CFF808 rbp = 000000D318CFF860// 第一个参数 = 000000D318CFF808 + 8h = 000000D318CFF810// 第二个参数 = 000000D318CFF808 + 10h = 000000D318CFF818// 第三个参数 = 000000D318CFF808 + 18h = 000000D318CFF820// 第10个参数 = 000000D318CFF808 + 48h = 000000D318CFF850
00007FF6EDCA1822 55 push rbp //
00007FF6EDCA1823 57 push rdi
00007FF6EDCA1824 48 81 EC E8 00 00 00 sub rsp,0E8h
00007FF6EDCA182B 48 8D 6C 24 20 lea rbp,[rsp+20h]
00007FF6EDCA1830 48 8D 0D 30 F8 00 00 lea rcx,[00007FF6EDCB1067h]
00007FF6EDCA1837 E8 25 FB FF FF call 00007FF6EDCA1361 return i1 + i10;
00007FF6EDCA183C 8B 85 28 01 00 00 mov eax,dword ptr [rbp+0000000000000128h]
00007FF6EDCA1842 8B 8D E0 00 00 00 mov ecx,dword ptr [rbp+00000000000000E0h]
00007FF6EDCA1848 03 C8 add ecx,eax
00007FF6EDCA184A 8B C1 mov eax,ecx
}
00007FF6EDCA184C 48 8D A5 C8 00 00 00 lea rsp,[rbp+00000000000000C8h]
00007FF6EDCA1853 5F pop rdi
00007FF6EDCA1854 5D pop rbp
00007FF6EDCA1855 C3 ret
我把Intel的函数调用的栈帧画了一个图:

因为test1函数没有定义变量,所以函数栈里并没有值。如果定义了变量也会跟main函数一样,就是有点搞不懂,每个变量离的这么远是因为怕踩到内存????有知道的可以留言告诉我。
5.6.2.2 AT&T方式
0000000000401151 <_Z5test1iiiiiiiiii>:int test1(int i1, int i2, int i3, int i4, int i5, int i6, int i7, int i8, int i9, int i10)
{401151: 55 push %rbp401152: 48 89 e5 mov %rsp,%rbp401155: 89 7d fc mov %edi,-0x4(%rbp)401158: 89 75 f8 mov %esi,-0x8(%rbp)40115b: 89 55 f4 mov %edx,-0xc(%rbp)40115e: 89 4d f0 mov %ecx,-0x10(%rbp)401161: 44 89 45 ec mov %r8d,-0x14(%rbp)401165: 44 89 4d e8 mov %r9d,-0x18(%rbp)// 这个会把其他参数都存进栈里return i1 + i10;401169: 8b 55 fc mov -0x4(%rbp),%edx40116c: 8b 45 28 mov 0x28(%rbp),%eax40116f: 01 d0 add %edx,%eax
}401171: 5d pop %rbp401172: c3 retq
linux就比较节省内存,因为test1没有使用临时变量,所以栈大小是0。

5.6.3 函数返回值
我们都知道,函数可以返回一个值,那函数是怎么返回这个值的呢?我们继续分析
5.6.3.1 Intel方式
char test2()
{
00007FF7DFC51870 40 55 push rbp
00007FF7DFC51872 57 push rdi
00007FF7DFC51873 48 81 EC 08 01 00 00 sub rsp,108h
00007FF7DFC5187A 48 8D 6C 24 20 lea rbp,[rsp+20h]
00007FF7DFC5187F 48 8D 0D E1 F7 00 00 lea rcx,[00007FF7DFC61067h]
00007FF7DFC51886 E8 D6 FA FF FF call 00007FF7DFC51361 char s = 9;
00007FF7DFC5188B C6 45 04 09 mov byte ptr [rbp+4],9 return s;
00007FF7DFC5188F 0F B6 45 04 movzx eax,byte ptr [rbp+4] // 返回到char型
}short test3()
{
00007FF7DFC519E0 40 55 push rbp
00007FF7DFC519E2 57 push rdi
00007FF7DFC519E3 48 81 EC 08 01 00 00 sub rsp,108h
00007FF7DFC519EA 48 8D 6C 24 20 lea rbp,[rsp+20h]
00007FF7DFC519EF 48 8D 0D 71 F6 00 00 lea rcx,[00007FF7DFC61067h]
00007FF7DFC519F6 E8 66 F9 FF FF call 00007FF7DFC51361 short s = 9;
00007FF7DFC519FB B8 09 00 00 00 mov eax,9
00007FF7DFC51A00 66 89 45 04 mov word ptr [rbp+4],ax return s;
00007FF7DFC51A04 0F B7 45 04 movzx eax,word ptr [rbp+4]
}int test4()
{
00007FF7DFC518B0 40 55 push rbp
00007FF7DFC518B2 57 push rdi
00007FF7DFC518B3 48 81 EC 08 01 00 00 sub rsp,108h
00007FF7DFC518BA 48 8D 6C 24 20 lea rbp,[rsp+20h]
00007FF7DFC518BF 48 8D 0D A1 F7 00 00 lea rcx,[00007FF7DFC61067h]
00007FF7DFC518C6 E8 96 FA FF FF call 00007FF7DFC51361 int s = 9;
00007FF7DFC518CB C7 45 04 09 00 00 00 mov dword ptr [rbp+4],9 return s;
00007FF7DFC518D2 8B 45 04 mov eax,dword ptr [rbp+4]
}long long test5()
{
00007FF7873C18E0 40 55 push rbp
00007FF7873C18E2 57 push rdi
00007FF7873C18E3 48 81 EC 08 01 00 00 sub rsp,108h
00007FF7873C18EA 48 8D 6C 24 20 lea rbp,[rsp+20h]
00007FF7873C18EF 48 8D 0D 71 F7 00 00 lea rcx,[00007FF7873D1067h]
00007FF7873C18F6 E8 66 FA FF FF call 00007FF7873C1361 long long s = 9;
00007FF7873C18FB 48 C7 45 08 09 00 00 00 mov qword ptr [rbp+8],9 return s;
00007FF7873C1903 48 8B 45 08 mov rax,qword ptr [rbp+8]
}
实验证明,现在是64位系统了,没有数据类型比64位的长了,尴尬,所以测不了超过rax的时候,会不会用其他寄存器了。
5.6.3.2 AT&T方式
看下linux的返回值应该是一样的。
0000000000401173 <_Z5test2v>:char test2()
{401173: 55 push %rbp401174: 48 89 e5 mov %rsp,%rbpchar s = 9;401177: c6 45 ff 09 movb $0x9,-0x1(%rbp)return s;40117b: 0f b6 45 ff movzbl -0x1(%rbp),%eax
}40117f: 5d pop %rbp401180: c3 retq 0000000000401181 <_Z5test3v>:short test3()
{401181: 55 push %rbp401182: 48 89 e5 mov %rsp,%rbpshort s = 9;401185: 66 c7 45 fe 09 00 movw $0x9,-0x2(%rbp)return s;40118b: 0f b7 45 fe movzwl -0x2(%rbp),%eax
}40118f: 5d pop %rbp401190: c3 retq 0000000000401191 <_Z5test4v>:int test4()
{401191: 55 push %rbp401192: 48 89 e5 mov %rsp,%rbpint s = 9;401195: c7 45 fc 09 00 00 00 movl $0x9,-0x4(%rbp)return s;40119c: 8b 45 fc mov -0x4(%rbp),%eax
}40119f: 5d pop %rbp4011a0: c3 retq 00000000004011a1 <_Z5test5v>:long long test5()
{4011a1: 55 push %rbp4011a2: 48 89 e5 mov %rsp,%rbplong long s = 9;4011a5: 48 c7 45 f8 09 00 00 movq $0x9,-0x8(%rbp)4011ac: 00 return s;4011ad: 48 8b 45 f8 mov -0x8(%rbp),%rax
}4011b1: 5d pop %rbp4011b2: c3 retq
看来64位系统就是这么强大,不需要两个寄存器了,直接一个寄存器就可以返回值成功了。
5.6.4 函数退出
函数退出就比较简单了。
5.6.4.1 Intel方式
00007FF7873C1907 48 8D A5 E8 00 00 00 lea rsp,[rbp+00000000000000E8h] // 处理rsp的值,这样计算就是得到前面函数的rsp
00007FF7873C190E 5F pop rdi// 还记得rdi进栈不,现在就弹出
00007FF7873C190F 5D pop rbp// 也继续弹出rbp
00007FF7873C1910 C3 ret // ret指令是一种汇编指令,它的作用是从一个子程序中返回到调用该子程序的主程序。在执行时,ret指令将从堆栈中弹出返回地址,并跳转到该地址继续执行主程序。(还记得下一个执行的地址,也入栈了吧)
5.6.4.2 AT&T方式
4011b1: 5d pop %rbp4011b2: c3 retq
从上面写的几个简单函数分析,rsp的值都不会变,所以函数退出,只需要把rbp还原,然后在ret到下一条执行的指令。
5.7 扩展:ARM平台汇编分析
本来不打算介绍ARM,因为我们以后都是使用Intel了,ARM芯片做服务器还是比较少的,但是想想如果作为比较的方式学习还是不错的。
5.7.1 RISC与CISC的区别
RISC全称Reduced Instruction Set Compute,精简指令集计算机。
CISC全称Complex Instruction Set Computers,复杂指令集计算机。
RISC的主要特点:
1)选取使用频率较高的一些简单指令以及一些很有用但不复杂的指令,让复杂指令的功能由使用频率高的简单指令的组合来实现。
2)指令长度固定,指令格式种类少,寻址方式种类少。
3)只有取数/存数指令访问存储器,其余指令的操作都在寄存器内完成。
4)CPU中有多个通用寄存器(比CICS的多)
5)采用流水线技术(RISC一定采用流水线),大部分指令在一个时钟周期内完成。采用超标量超流水线技术,可使每条指令的平均时间小于一个时钟周期。
6)控制器采用组合逻辑控制,不用微程序控制。
7)采用优化的编译程序
CICS的主要特点:
1)指令系统复杂庞大,指令数目一般多达200~300条。
2)指令长度不固定,指令格式种类多,寻址方式种类多。
3)可以访存的指令不受限制(RISC只有取数/存数指令访问存储器)
4)各种指令执行时间相差很大,大多数指令需多个时钟周期才能完成。
5)控制器大多数采用微程序控制。
6)难以用优化编译生成高效的目标代码程序
RISC与CICS的比较
1.RISC比CICS更能提高计算机运算速度;RISC寄存器多,就可以减少访存次数,指令数和寻址方式少,因此指令译码较快。
2.RISC比CISC更便于设计,可降低成本,提高可靠性。
3.RISC能有效支持高级语言程序。
4.CICS的指令系统比较丰富,有专用指令来完成特定的功能,因此处理特殊任务效率高。
这个转载自https://blog.csdn.net/weixin_40491661/article/details/121351113
很明显,Intel的芯片就是CICS指令,现在我们来学习的ARM其实就是RISC,经常使用在手机芯片上,因为功耗较低。
5.7.2 ARM寄存器解读

ARM的寄存器比较多,但是指令是精简的,所以才是RISC的风格。
ARM的寄存器都是通用的都是R0-R15,但是因为ARM有7种模式,所以不同模式的寄存器用法可能不一样,主要是这些模式的寄存器虽然名字相同,但都是不同寄存器。
但是这里有两个寄存器比较特殊:
R13:栈顶指针
R15:指令寄存器
5.7.3 ARM对数据的描述
ARM的发展比较晚,基本没有经历过8位和16位的时代,所以ARM没有什么历史负担,所以对数据描述没有windows看的那么难受。
| c声明 | Intel数据类型 |
|---|---|
| char | 字节 |
| short | 半字 |
| int | 字 |
| long | 双字 |
5.7.4 ARM汇编浅析
这个就不写了,因为我现在没有交叉编译工具链,等后面有机会再说吧。
参考文章:
https://blog.csdn.net/weixin_39946798/article/details/113708680
https://blog.csdn.net/c2682736/article/details/122349851
https://blog.csdn.net/weixin_38633659/article/details/125221443
https://blog.csdn.net/oqqHuTu12345678/article/details/125676002
https://www.jianshu.com/p/338d2f85e954
https://blog.csdn.net/weixin_40491661/article/details/121351113
相关文章:
五、c++学习(加餐1:汇编基础学习)
经过前面几节课的学习,我们在一些地方都会使用汇编来分析,我们学习汇编,只是学习一些基础,主要是在我们需要深入分析语法的时候,使用汇编分析,这样会让我们更熟悉c编译器和语法。 从这节课开始,…...
iOS正确获取图片参数深入探究及CGImageRef的使用(附源码)
一 图片参数的正确获取 先拿一张图片作为测试使用 图片参数如下: 图片的尺寸为: -宽1236个像素点 -高748个像素点 -色彩空间为RGB -描述文件为彩色LCD -带有Alpha通道 请记住这几个参数,待会儿我们演示如何正确获取。 将这张图片分别放在…...

Typescript 5.0 发布:快速概览
探索最令人兴奋的功能和更新 作为一种不断发展的编程语言,TypeScript 带来了大量的改进和新功能。在本文中,我们将深入探讨 TypeScript 的最新版本 5.0,并探索其最值得关注的更新。 1. 装饰器 TypeScript 5.0 引入了一个重新设计的装饰器系…...

【图像处理 】卡尔曼滤波器原理
目录 一、说明 二、它是什么? 2.1 我们可以用卡尔曼滤波器做什么? 2.2 卡尔曼滤波器如何看待您的问题...

YOLOv5 实例分割入门
介绍 YOLOv5 目标检测模型以其出色的性能和优化的推理速度而闻名。因此,YOLOv5 实例分割模型已成为实时实例分割中最快、最准确的模型之一。 在这篇文章中,我们将回答以下关于 YOLOv5 实例分割的问题: YOLOv5检测模型做了哪些改动,得到了YOLOv5实例分割架构?使用的 Prot…...

数字城市发展下的技术趋势,你知道多少?
提到数字城市、智慧城市大家都会感觉经常在耳边听到,但是要确切说出具体的概念还是有一点难度的。具体来说:数字城市是一个集合多种技术的系统,以计算机技术、多媒体技术和大规模存储技术为基础,以宽带网络为纽带,运用…...
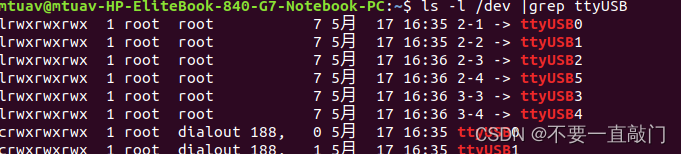
linux 串口改为固定
在/etc/udev/rules.d 目录下新建定义规则的文件 1. 文件名要按规范写否则改动无效2. 规则文件必须以.rules 结尾3. 规则文件名称必须遵循 xx-name.rules 格式(xx 为数字或字母,name 为规则名称),例如 99-serial-ports.rules。4. 规…...
【SCI一区】考虑P2G和碳捕集设备的热电联供综合能源系统优化调度模型(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...
Redis缓存数据库(四)
目录 一、概述 1、Redis Sentinel 1.1、docker配置Redis Sentinel环境 2、Redis存储方案 2.1、哈希链 2.2、哈希环 3、Redis分区(Partitioning) 4、Redis面试题 一、概述 1、Redis Sentinel Redis Sentinel为Redis提供了高可用解决方案。实际上这意味着使用Sentinel…...

View中的滑动冲突
View中的滑动冲突 1.滑动冲突的种类 滑动冲突一般有3种, 第一种是ViewGroup和子View的滑动方向不一致 比如: 父布局是可以左右滑动,子view可以上下滑动 第二种 ViewGroup和子View的滑动方向一致 第三种 第三种类似于如下图 2.滑动冲突的解决方式 滑动冲突一般情况下有2…...
java boot项目基础配置之banner与日志配置演示 并教会你如何使用文档查看配置
上文 我们简单讲了一下 springboot 项目的配置 都是写在resources下的application.properties中 springboot 项目中 配置都写在这一个文件 可以说非常方便 不像之前 写个项目配置这里一个哪里一个 看到是非常费力 我们启动项目 这里有个图案 其实 这叫 banner 我们就用配置来…...
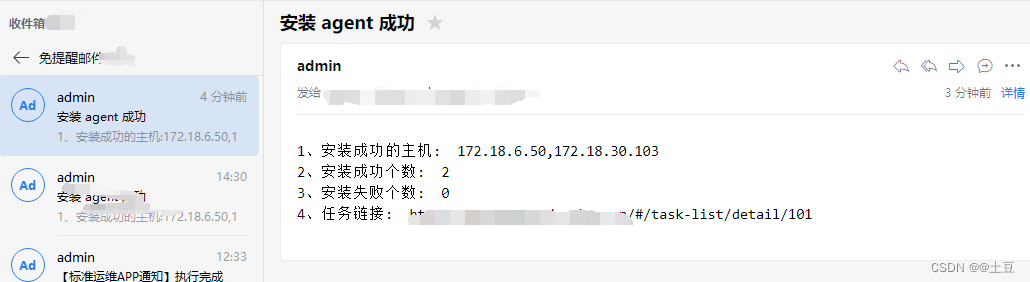
蓝鲸平台通过标准运维 API 安装 Agent
目录 一、背景 二、目的 三、创建安装agent流程 四、通过标准运维 API 安装 Agent 五、总结 一、背景 蓝鲸平台正常情况纳管主机需要在节点管理手工安装agent,不能达到完成自动化安装agent的效果。想通过脚本一键安装agent,而不需要在蓝鲸平台进行过…...

python 图片保存成视频
👨💻个人简介: 深度学习图像领域工作者 🎉工作总结链接:https://blog.csdn.net/qq_28949847/article/details/128552785 链接中主要是个人工作的总结,每个链接都是一些常用demo,…...

uniapp 引入 Less SCSS
✨求关注~ 😀博客:www.protaos.com 本文将介绍如何在 UniApp 中引入 Less 和 SCSS,两种流行的 CSS 预处理器。通过使用 Less 和 SCSS,你可以在 UniApp 项目中更灵活地编写样式,并享受预处理器提供的便利功能。 代码实现…...

Linux程序设计:文件操作
文件操作 系统调用 write //函数定义 #include <unistd.h> size_t write(int fildes, const void *buf, size_t nbytes); //示例程序 #include <unistd.h> #include <stdlib.h> int main() { if ((write(1, “Here is some data\n”, 18)) ! 18)write(2, …...

【自制C++深度学习推理框架】Tensor模板类的设计思路
Tensor模板类的设计思路 为什么要把Armadillo线性代数库arma::fcube封装成Tensor模板类? arma::fcube是Armadillo线性代数库中的一种数据类型,它是一个三维的float类型张量。Armadillo库是一个C科学计算库,提供了高效的线性代数和矩阵运算。…...
linux--systemd、systemctl
linux--systemd、systemctl 1 介绍1.1 发展sysvinitupstart主角 systemd 登场 1.2 简介 2 优点兼容性启动速度systemd 提供按需启动能力采用 linux 的 cgroups 跟踪和管理进程的生命周期启动挂载点和自动挂载的管理实现事务性依赖关系管理日志服务systemd journal 的优点如下&a…...

加密解密软件VMProtect教程(七):主窗口之控制面板“详情”部分
VMProtect是新一代软件保护实用程序。VMProtect支持德尔菲、Borland C Builder、Visual C/C、Visual Basic(本机)、Virtual Pascal和XCode编译器。 同时,VMProtect有一个内置的反汇编程序,可以与Windows和Mac OS X可执行文件一起…...

国产仪器 4945B/4945C 无线电通信综合测试仪
4945系列无线电通信综合测试仪是多功能、便携式无线电综合测试类仪器,基于软件无线电架构,集成了跳频信号发生与分析、矢量信号发生与解调分析、模拟调制信号发生与解调分析、音频信号发生与分析、音频示波器、自动测试等功能,它可完成无线通…...
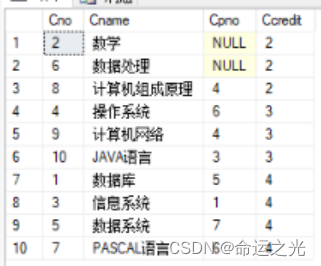
数据库原理及应用上机实验一
✨作者:命运之光 ✨专栏:数据库原理及应用上机实验报告整理 目录 ✨一、实验目的和要求 ✨二、实验内容与步骤 🍓🍓前言: 数据库原理及应用上机实验报告的一个简单整理后期还会不断完善🍓🍓…...

Visual Paradigm 17.0 团队协作新功能实测:手把手教你用项目模板和文件夹管理提效
Visual Paradigm 17.0 团队协作实战指南:从模板配置到文件夹管理的高效工作流在敏捷开发团队中,项目启动速度和资产管理的规范性往往直接影响整体效率。Visual Paradigm 17.0针对这一痛点推出的团队协作增强功能,特别是服务器端项目模板和文件…...

除了排错,你可能不知道OPC Expert v8.1还能做这些:数据归档、计算与冗余实战
解锁OPC Expert v8.1的隐藏潜力:数据归档、实时计算与冗余架构实战指南在工业自动化领域,OPC Expert常被视为故障排查的"急救箱",但它的能力远不止于此。当大多数工程师还在用它解决DCOM配置问题时,少数先行者已经用它重…...

从Office功能区的“局外人“到“掌控者“:Office RibbonX Editor深度指南
从Office功能区的"局外人"到"掌控者":Office RibbonX Editor深度指南 【免费下载链接】office-ribbonx-editor An overhauled fork of the original Custom UI Editor for Microsoft Office, built with WPF 项目地址: https://gitcode.com/g…...

Agent开发面试通关攻略:吃透稳拿offer
阅读前置:2026年当下最卷也最缺人的AI岗位,一定是AI Agent开发。最近刷遍CSDN、牛客、力扣最新面经,发现一个非常明显的招聘趋势:普通大模型微调岗位饱和内卷,而AI Agent开发岗位人才严重缺口,薪资更高、竞…...

ARM架构CONSTRAINED UNPREDICTABLE行为解析与应对
1. ARM架构中的CONSTRAINED UNPREDICTABLE行为解析在处理器架构设计中,UNPREDICTABLE行为通常指架构规范未明确定义的执行结果,可能导致不可预期的系统状态。ARM架构通过引入CONSTRAINED UNPREDICTABLE机制,将这类行为限制在特定范围内&#…...
)
Python基础语法:生成器 generator(yield)
一、简介根据指定的规则循环生成数据,当条件不成立时则生成数据结束。数据不是一次性全部生成出来,而是使用一个,再生成一个,好处是可以节约大量的内存。就像设计模式中的懒汉式。适合处理大数据或流数。生成器是一种特殊的迭代器…...

2026年LLM推理加速全景:量化、投机解码与KV Cache工程实战
大语言模型推理速度慢、成本高,是阻碍AI大规模落地的核心障碍之一。一个7B参数的模型,在标准配置下每秒只能生成约30个token,对于需要实时响应的应用来说几乎无法接受。但2026年,一系列推理加速技术的成熟,让这一局面发…...

基于雷达与光敏传感器的低功耗智能窗防设备设计与实现
1. 项目概述:一个基于雷达与光敏的智能窗防设备几年前,我因为一次短暂的出差,家里空置了几天,回来后就一直琢磨着怎么给家里的窗户加点“动静”。市面上的智能安防摄像头固然好,但要么需要复杂的布线,要么云…...

OpenRASP原理与实战:Java应用层实时防护技术详解
1. 为什么我宁愿花三天部署OpenRASP,也不愿再写第五个自定义WAF过滤器去年冬天,我在给一家做在线教育SaaS平台做安全加固时,连续踩了三个坑:第一次用NginxLua写了套SQL注入规则,结果学生提交的“SELECT * FROM courses…...

京东自动购物终极指南:告别缺货烦恼,智能抢购神器
京东自动购物终极指南:告别缺货烦恼,智能抢购神器 【免费下载链接】Jd-Auto-Shopping 京东商品补货监控及自动下单 项目地址: https://gitcode.com/gh_mirrors/jd/Jd-Auto-Shopping 还在为心仪商品瞬间售罄而苦恼吗?还在熬夜等待补货却…...