机器学习面试题库:K-means
一、简述K-means算法的原理及工作流程?
原理:
K-means是一个无监督的聚类算法。它的主要目的是对同一组数据对象进行分类。其原理是基于样本间的相似性来聚类分析的,即将所有样本分为K个簇,使得同一个簇间中样本相似性最高,不同簇间样本相似性最低。
工作流程:
1.初始化:随机选择K个样本作为初始化簇心
2.分配:对于每个样本,计算其到每个簇心的距离,并将分配到距离最短的簇中
3.重新计算簇心:重新计算每个簇的簇心
4.重复步骤2和步骤3,直至簇心不在发生变化,或者达到预定的聚类次数。
二、K-means聚类中的K如何取?
确定K的值是K-means聚类算法中最重要的问题之一,一般可以采用以下两种方法来确定K的合适取值:
-
手肘法:通过计算不同K值下聚类结果的SSE(误差平方和)或SSB(组间平方和)值,观察这些指标与K值的关系,找到SSE或SSB下降速度趋于平稳的K值,即所谓的“肘部”位置,作为合适的聚类数。
-
轮廓系数法:通过计算不同K值下聚类结果中每个样本的轮廓系数,综合考虑聚类结果的紧密度和分离度,找到轮廓系数达到最大值时对应的K值,作为最佳聚类数。
需要注意的是,以上方法只是参考,无法保证一定能够得到最优的K值,实际应用中可能需要结合业务需求和实际场景综合考虑。
三、常见的距离度量方式有那些?
常见的距离度量方式有以下几种:
-
欧几里得距离(Euclidean Distance):是指在m维空间中两个点之间的真实距离,即勾股定理。在实际应用中,欧几里得距离被广泛应用于K-means算法中。
-
曼哈顿距离(Manhattan Distance):是指在m维空间中两点之间的城市街区距离,即横、纵坐标绝对值的和。
-
闵可夫斯基距离(Minkowski Distance):是指在m维空间中两点之间的距离,在欧几里得距离和曼哈顿距离的基础上进行推广,公式为$d=(\sum_{i=1}^m|X_i-Y_i|^p)^{\frac{1}{p}}$,其中p为距离度量的阶数,当p=1和2时,闵可夫斯基距离分别对应曼哈顿距离和欧几里得距离。
-
切比雪夫距离(Chebyshev Distance):是指在二维空间中两点之间的切比雪夫距离,即两点横、纵坐标差的绝对值的最大值。
-
余弦相似度(Cosine Similarity):是指用向量空间中两个向量夹角的余弦值作为衡量它们之间的相似性,适用于文本分类、信息检索等领域。
四、马氏距离和欧式距离的区别是什么?
欧式距离和马氏距离都是用来度量样本之间的距离,二者的区别如下:
-
度量方式不同:欧式距离是指欧几里得距离,即二维空间中两点之间的真实距离;而马氏距离则是在样本协方差矩阵的基础上进行计算的,能够考虑不同特征之间的相关性和方差。
-
应用范围不同:欧式距离适用于绝大多数情况下,如图像分类、文本分类、聚类等;而马氏距离则更适合于处理高维度、相关数据。
-
距离结果的表达方式不同:欧式距离的结果是一个标量,反映两个样本之间的距离;而马氏距离的结果是一个矩阵,反映样本之间的相关性。
总的来说,欧式距离是一种通用的度量距离的方式,在绝大多数情况下都能够使用;而马氏距离则更适合于处理含有相关性变量的高维数据。
五、K-means聚类对空簇如何处理?
在K-means聚类算法中,空簇是指在某一轮迭代后没有样本点被划分到该簇中的情况。对于空簇,一般可以采用以下两种方法进行处理:
-
随机分配法:可以将空簇内的质心随机分配给剩余的簇。这样可以保证建立的新簇数不变,不影响后续的聚类计算。
-
剔除法:可以将空簇直接剔除,同时将聚类数目减1,然后重新进行聚类计算。由于空簇的存在可能会导致分类结果不够准确,因此剔除空簇也是一个常见的处理方法。
需要注意的是,处理空簇的方法应该根据具体问题而定,考虑到数据的性质和应用场景选择一个合适的方法。在实际应用中,可以尝试多种方法并进行比较,以得到最好的聚类结果。
六、为什么K-means聚类会容易收到异常值的影响
K-means聚类算法的本质是在寻找每个簇的中心点,进而对样本点进行划分。这就意味着它容易受到异常值的影响。由于异常值偏离了大多数点的分布,它们会改变每个簇的中心位置,并且在迭代过程中会影响质心的计算。如果异常值的数量很多,那么K-means可能会出现明显的错误,如不合理的簇划分、聚类数目偏少等。
为了减少异常值的影响,我们可以采用以下两种方法:
-
离群值检测和剔除:可以使用一些离群值检测算法,如Z-score或箱线图等方法,来识别和剔除离群值,以减少异常值对聚类结果的影响。
-
选择合适的距离度量方式:如曼哈顿距离等距离度量方式提供了对异常值的一定鲁棒性,可以减轻异常值的影响。
需要注意的是,剔除异常值可能会导致数据信息丢失,因此需要根据具体问题和应用场景进行相应的权衡和考虑。
七、如何对K-means聚类的效果进行评估?
K-means聚类是一种无监督学习算法,通常无法事先确定簇的数量或分类结果的正确性。因此对于K-means算法的评估主要基于内部指标和外部指标两种方法。
-
内部指标:主要是针对聚类结果本身的评估指标,比如样本间距离、簇内距离、簇间距离、簇内平均距离、轮廓系数等。这些指标可以帮助判断聚类结果的紧密性和一致性,从而确定最佳聚类数量,并对不同的聚类结果进行比较。
-
外部指标:主要是通过与已知分类或真实标签进行对比,评估聚类结果的正确性和准确性。比如精确率、召回率、F1值等指标。这些指标通常需要已知样本的真实标签或分类信息,因此只适用于那些有人工标注或已知分类的数据集。
同时,需要注意的是,K-means算法的评估指标存在一定的局限性,如聚类的结果依赖于初始质心的选择,存在可能陷入局部最优解的问题等。因此,在使用K-means算法时,需要注意选择合适的评估指标,并结合实际问题和经验进行综合判断和分析。
八、简述K-means聚类的优缺点?
K-means聚类是一种常见的无监督学习算法,通过将数据集中的样本划分到不同的簇中,从而实现对数据集的分析和分类。它的优点和缺点如下:
优点:
-
简单易用:K-means算法是一种简单易用的聚类方法,不需要任何先验知识和标记,可以自动发现数据的内在规律。
-
速度快:K-means算法计算量小,在数据量较大时也能以较快的速度实现分类。
-
可扩展性好:K-means算法的计算过程容易分布式实现,并且可以方便地应用于大规模数据集的聚类任务。
-
结果可解释性好:K-means算法将每个数据点分配到最近的质心中,所以簇的分割结果易于理解。同时,可以通过可视化手段直观地展示聚类效果。
缺点:
-
对初始质心敏感:随机化的初始质心选择方法会导致K-means算法对于不同的初始值产生不同的输出结果。
-
容易收敛于局部最优:由于在初始质心的选择和簇的合并过程中,会陷入局部最优解,从而可能得到不理想的聚类结果。
-
聚类数量需先验确定:在应用K-means算法时,需要手动确定合适的簇的数量K,且簇的数量可能很难事先估计。
-
对于非球形的簇效果欠佳:K-means算法假设每个簇是一个球形分布,对于非球形或不规则簇的聚类效果不佳。
需要注意的是,K-means算法的优缺点需要在具体应用场景中综合考虑。对于规模较小、簇形态较简单、具体规律明显的数据集,K-means算法的效果良好;对于复杂、高维数据集,可能需要考虑其他更加复杂的聚类算法。
九、K-means聚类中,如何规避不同质心选取对聚类结果的影响?
K-means聚类算法是一种迭代型的聚类算法,其中选择质心是一项重要的操作。不同的质心选择会导致不同的聚类结果。为了避免不同质心选择对聚类结果的影响,可以考虑以下几种方法:
-
多次运行聚类:可以通过多次运行聚类算法,每次使用不同的质心初始化方法,然后选择最好的聚类结果。多次运行聚类可以有效降低质心选择对结果的影响,并增加聚类稳定性和准确性。
-
选择多个随机初始质心:一种简单的方法是通过同时选择多组随机初始质心,然后平均多个聚类结果来减小初始质心选择对聚类结果的影响。
-
选择合适的初始质心:除了使用随机初始质心的方法,还可以采用基于特征分析的方法,比如利用PCA(主成分分析)或TSNE(T分布邻域嵌入)等方法减少不同质心选取带来的影响。
需要注意的是,虽然质心选择是K-means聚类算法中一个重要的因素,但是对于大规模的数据集,通常可以通过多次迭代和加入合适的正则化方法等措施来减小初始质心对聚类结果的影响。因此,在实际的应用中,需要根据具体问题和数据集特点选择合适的处理方法。
十、K-means聚类和DBSCAN算法的对比?
K-means聚类和DBSCAN聚类算法都是经典的聚类算法,但它们的原理和应用场景有所不同。具体来说,它们的区别如下:
-
原理不同:K-means算法是基于质心的距离来实现聚类的,它寻找一组质心分别代表不同的簇,并以此划分数据集。而DBSCAN聚类算法是基于密度的距离来实现聚类的,通过不断扩展核心对象的直接密度可达区域,找出密度连接的点进行聚类。
-
适用场景不同:K-means算法适用于数据规模较大且数据的特征呈现出近似于球状分布的数据集。DBSCAN更适合于数据集中存在不同密度区域的情况,并且可以有效地发现任意形状的簇,对于噪声和异常值的处理也相对较好。
-
参数设置不同:K-means算法需要给定聚类的数量K,而DBSCAN算法不需要事先确定具体的聚类数目。
-
聚类效果不同:K-means算法的聚类效果可能会收到初始质心的选择影响,因此需要通过多次试验来选择最优质心。而DBSCAN算法的聚类效果的稳定性相对较好。
因此,对于数据分布近似于球形的数据集,且需要事先知道聚类数量的情况下,可以使用K-means聚类。而对于具有复杂数据分布,且聚类数量未知的数据集,则可以使用DBSCAN算法。当然,在实际应用中,还需要考虑数据量大小、数据维度、算法的计算效率等因素,选择最合适的算法。
相关文章:

机器学习面试题库:K-means
一、简述K-means算法的原理及工作流程? 原理: K-means是一个无监督的聚类算法。它的主要目的是对同一组数据对象进行分类。其原理是基于样本间的相似性来聚类分析的,即将所有样本分为K个簇,使得同一个簇间中样本相似性最高&#…...

Linux:文本三剑客之awk
Linux:文本三剑客之awk 一、awk编辑器1.1 awk概述1.2 awk工作原理1.3 awk与sed的区别 二、awk的应用2.1 命令格式2.2 awk常见的内建变量(可直接用) 三、awk使用3.1 按行输出文本3.2 按字段输出文本3.3 通过管道、双引号调用 Shell 命令 一、a…...
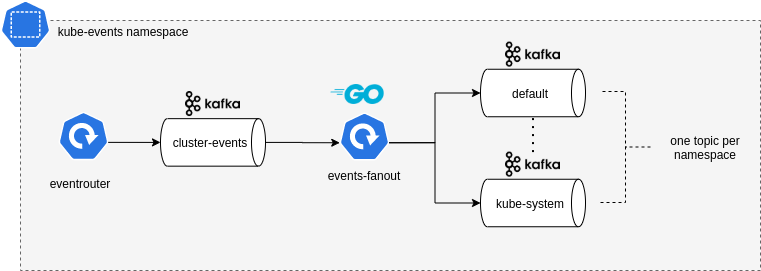
如何借助Kafka持久化存储K8S事件数据?
大家应该对 Kubernetes Events 并不陌生,特别是当你使用 kubectl describe 命令或 Event API 资源来了解集群中的故障时。 $ kubectl get events15m Warning FailedCreate …...
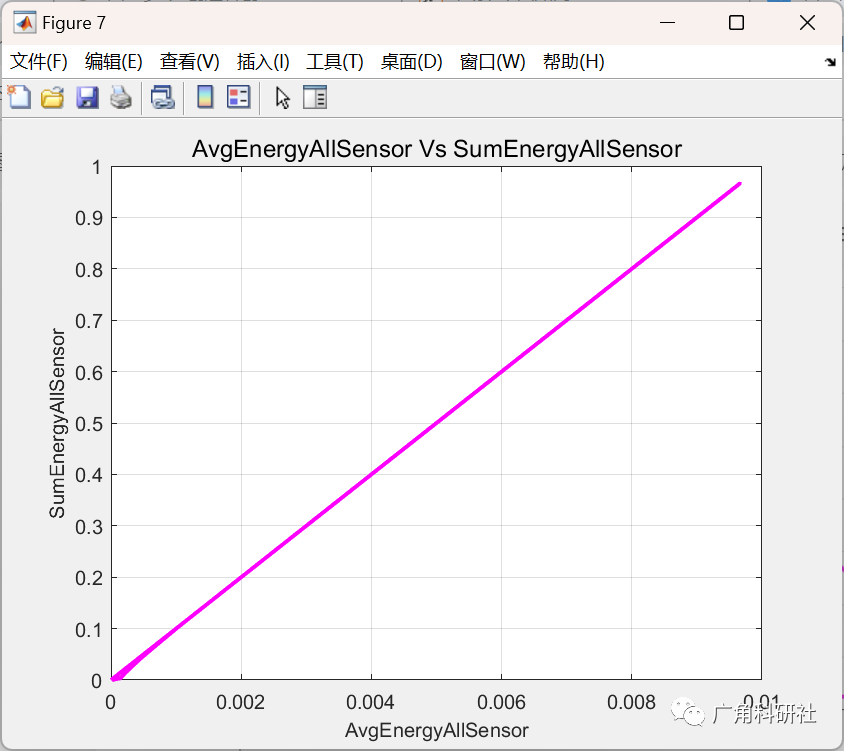
一种基于非均匀分簇和建立簇间路由的算法的无线传感器网络路由协议(Matlab代码实现)
目录 💥1 概述 📚2 运行结果 🎉3 参考文献 👨💻4 Matlab代码 💥1 概述 本文准备了一种路由方法,该方法使传感器通过有效地使用能量将数据从发送方加载到接收器,因为它在 LEAC…...
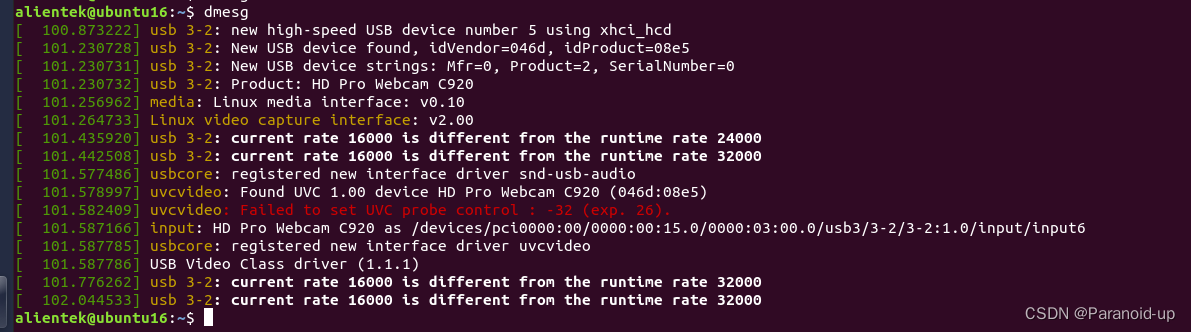
usb摄像头驱动打印信息
usb摄像头驱动打印信息 文章目录 usb摄像头驱动打印信息 在ubuntu中接入罗技c920摄像头打印的信息如下: [ 100.873222] usb 3-2: new high-speed USB device number 5 using xhci_hcd [ 101.230728] usb 3-2: New USB device found, idVendor046d, idProduct08e5 …...

银行半结构化和无领导群面注意事项
银行可以同时报考多家,因此部分同学也积累了不少宝贵的面试“失败”经验。今天小编就来给大家说说半结构化和无领导群面的注意事项,从如信银行考试中心了解到的整理如下: 一、半结构化面试注意事项: 半结构化面试更侧重于了解考生…...

今天公司来了个拿 30K 出来的测试,算是见识到了基础的天花板
今天上班开早会就是新人见面仪式,听说来了个很厉害的大佬,年纪还不大,是上家公司离职过来的,薪资已经达到中高等水平,很多人都好奇不已,能拿到这个薪资应该人不简单,果然,自我介绍的…...
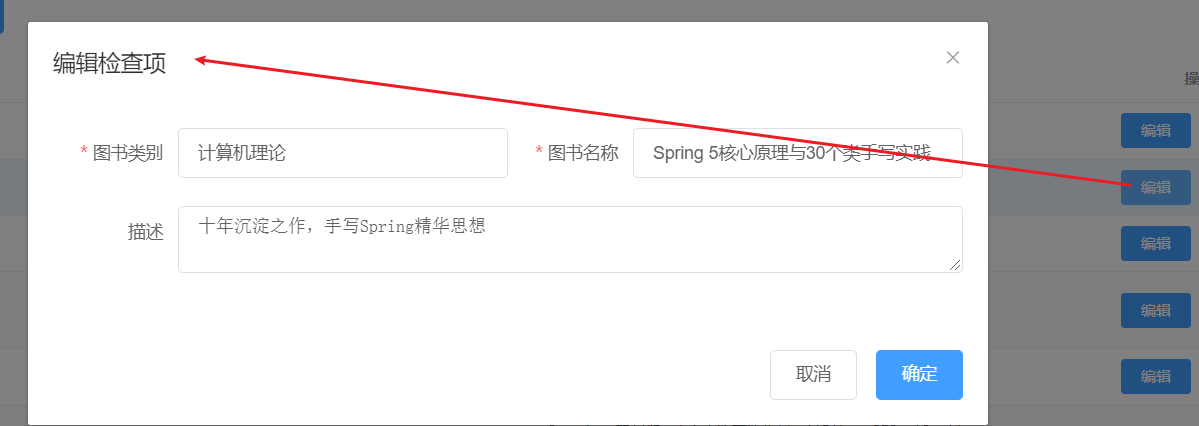
SSM整合(单元测试、结果封装、异常处理)
文章目录 1,SSM整合1.1 流程分析1.2 整合配置步骤1:创建Maven的web项目步骤2:添加依赖步骤3:创建项目包结构步骤4:创建SpringConfig配置类步骤5:创建JdbcConfig配置类步骤6:创建MybatisConfig配置类步骤7:创建jdbc.properties步骤8:创建SpringMVC配置类步…...

C++ list
C list 📟作者主页:慢热的陕西人 🌴专栏链接:C 📣欢迎各位大佬👍点赞🔥关注🚓收藏,🍉留言 本博客主要内容介绍了C中list和相关接口的使用 Clist C listⅠ. li…...
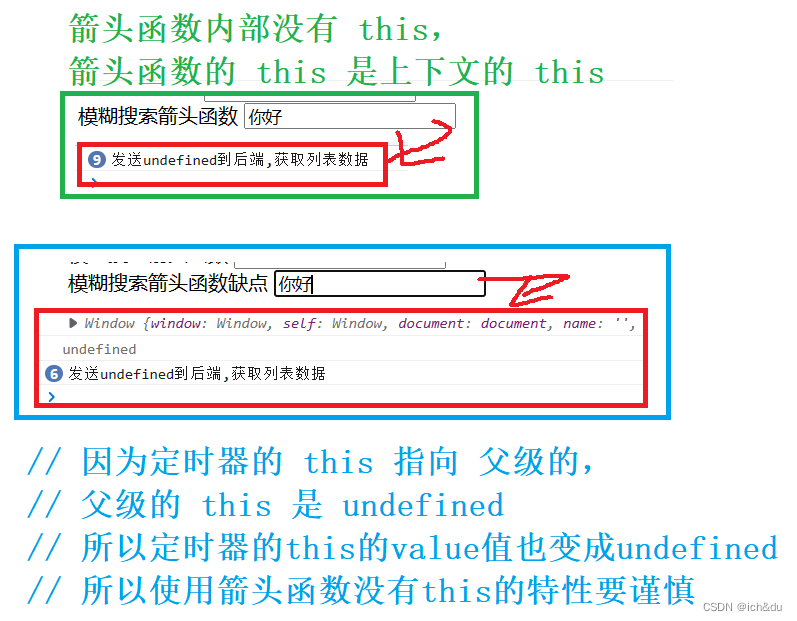
【JavaScript】ES6新特性(2)
5. 字符串扩展 5.1 includes函数 判断字符串中是否存在指定字符 <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8"><meta http-equiv"X-UA-Compatible" content"IEedge"><meta name&q…...
CST-FSS/周期谐振单元的仿真
引言 这几天要仿真超表面,上下求索CST有关相关内容的教程,视频倒是有不少,不过发现很多人忽略了官方帮助文档。本文以官方帮助文档为基础,写一个有关使用CST实现FSS/超表面这类周期结构的笔记。 官方帮助文档 CST有关FSS的内容使用了一个金属谐振圆环作为例子,这是由于…...
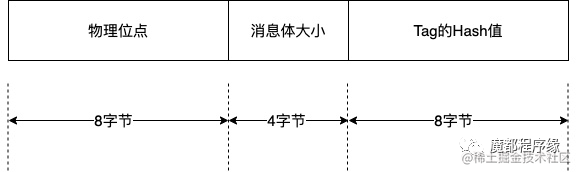
重新理解RocketMQ Commit Log存储协议
最近突然感觉:很多软件、硬件在设计上是有root reason的,不是by desgin如此,而是解决了那时、那个场景的那个需求。一旦了解后,就会感觉在和设计者对话,了解他们的思路,学习他们的方法,思维同屏…...
ROS 开发环境搭建(虚拟机版本)(一)
相关工具,以及镜像(以后有用) 链接:https://pan.baidu.com/s/1xgtp-XGFFNCACV_-0TJO2A 提取码:ar1w 1. 下载vm虚拟机(我选择的官方最新的vm虚拟机),安装好 2.安装百度网盘里面的…...

vue3做项目是需要注意的事项
Vue.js是一款非常优秀的前端开发框架,其第三代版本Vue3已经发布了。Vue3在性能、体验和功能等方面有了很大的提升,因此它成为了前端工程师们关注的焦点之一。在使用Vue3做项目时,有一些需要注意的事项,以下是对这些注意事项的介绍…...

docker日志轮转
cat /etc/docker/daemon.json { "log-driver": "json-file", "log-opts": { "max-size": "250m", "max-file": "3" } }...
论文阅读_音频压缩_Encodec
论文信息 name_en: High Fidelity Neural Audio Compression name_ch: 高保真神经音频压缩 paper_addr: http://arxiv.org/abs/2210.13438 date_read: 2023-04-27 date_publish: 2022-10-24 tags: [‘深度学习’,‘音频’] author: Alexandre Dfossez, Meta AI, FAIR Team cod…...
第06章_多表查询
第06章_多表查询 多表查询,也称为关联查询,指两个或更多个表一起完成查询操作。 前提条件:这些一起查询的表之间是有关系的(一对一、一对多),它们之间一定是有关联字段,这个关联字段可能建立了…...

自学黑客(网络安全)有哪些技巧——初学者篇
很多人说,要想学好黑客技术,首先你得真正热爱它。 热爱,听着多么让人激情澎湃,甚至热泪盈眶。 但很可惜,“热爱”这个词对还没入门的小白完全不管用。 如果一个人还没了解过你就说爱你,不是骗财就是骗色…...

CMD与DOS脚本编程【第四章】
预计更新 第一章. 简介和基础命令 1.1 介绍cmd/dos脚本语言的概念和基本语法 1.2 讲解常用的基础命令和参数,如echo、dir、cd等 第二章. 变量和运算符 2.1 讲解变量和常量的定义和使用方法 2.2 介绍不同类型的运算符和运算规则 第三章. 控制流程和条件语句 3.1 介…...

Liunx安装Docker
Liunx在线安装Docker 简介: Docker 是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的容器中,然后发布到任何流行的 Linux 机器上,也可以实现虚拟化。容器是完全使用沙箱机制,相互之间不…...

Unity安卓构建实战指南:解决APK真机安装闪退与构建失败
1. 这不是一本“从零开始”的书,而是一份你真正上手Unity安卓游戏开发前必须撕开的说明书我带过三届Unity实习工程师,也帮二十多个独立开发者把Demo打包进Google Play。每次看到新人在“安卓构建失败”报错里反复挣扎,或者对着“IL2CPP编译卡…...

开启Python GUI开发新纪元:Tkinter Designer可视化界面自动化生成终极指南
开启Python GUI开发新纪元:Tkinter Designer可视化界面自动化生成终极指南 【免费下载链接】Tkinter-Designer An easy and fast way to create a Python GUI 🐍 项目地址: https://gitcode.com/gh_mirrors/tk/Tkinter-Designer 在Python GUI开发…...

HarmonyOS 6学习:解决图片放大后无法移动至边缘的matrix4矩阵变换技巧
从"卡在中间"到"自由拖拽":一次完整的图片缩放平移边界问题攻关在HarmonyOS 6应用开发中,我最近遇到了一个看似简单却让人头疼的图片查看器问题:用户双指放大图片后,想要拖动查看边缘细节,却发现图…...
)
GIS工程应用记录(AI辅助编程)
问题的问题:语境坍缩“从各个角度提出问题,AI做出对应积极答复和修改,结果没有什么变化。”这,就是元问题最核心的症状。你尝试了所有你已知的“高级”协作手段,但就像重拳打在棉花上,AI永远在积极回应&…...

【Lindy营销自动化工作流终极指南】:20年实战验证的7大反脆弱性设计原则,92%企业漏掉的关键衰减阈值
更多请点击: https://intelliparadigm.com 第一章:Lindy营销自动化工作流的基本范式与历史验证 Lindy效应指出,一个事物的预期剩余寿命与其当前年龄成正比——在营销自动化领域,Lindy范式体现为:经时间检验仍被广泛采…...
)
别再只用鼠标了!用Leap Motion手势控制Unity游戏,保姆级配置避坑指南(2024版)
2024年Unity手势交互开发实战:Leap Motion从配置到游戏逻辑全解析在游戏开发领域,交互方式的创新往往能带来全新的体验。想象一下,玩家不再需要键盘鼠标,仅凭自然的手部动作就能操控游戏角色——这正是Leap Motion手势识别技术为U…...

yuzu模拟器完整指南:在电脑上畅玩Switch游戏的终极解决方案
yuzu模拟器完整指南:在电脑上畅玩Switch游戏的终极解决方案 【免费下载链接】yuzu 任天堂 Switch 模拟器 项目地址: https://gitcode.com/GitHub_Trending/yu/yuzu 想在电脑上体验任天堂Switch游戏的魅力吗?yuzu模拟器正是你寻找的完美答案。作为…...

告别漫长等待:UE5.2.1 Windows打包效率优化与插件问题排查指南
告别漫长等待:UE5.2.1 Windows打包效率优化与插件问题排查指南第一次点击"打包项目"按钮时,进度条仿佛被冻结的场景,每个UE5开发者都经历过。尤其当项目规模达到数十GB时,等待时间可能超过一小时——这背后隐藏着引擎底…...

2026数据治理平台选型:五款产品如何赋能数据中台建设?
一、引言:数据中台的成败,关键在治理在数字化浪潮的席卷下,“数据中台”已成为当代企业信息化架构中的核心战略组件。然而,一个悖论正困扰着大量企业:数据中台的基础设施搭建日趋完善,但真正将数据转化为业…...

XZ6128A工作电压5-100V 输出电流5A 升压型大功率LED灯恒流驱动控制芯片
概述 XZ6128A是一款高效率、高精度的升压型大功率LED灯恒流驱动控制芯片。 XZ6128A内置高精度误差放大器,固定关断时间控制电路,恒流驱动电路等,特别适合大功率、多个高亮度LED灯串的恒流驱动。 XZ6128A采用固定关断时间的控制方式࿰…...