NumPy
目录
1、NumPy简介
2、利用元组、列表创建多维数组
3、数组索引
4、数组裁切
4.1、一维数组操作
4.2、二维数组操作
5、数据类型
6、副本/视图
7、数组形状
8、数组重塑
9、多维数组的迭代
10、数组连接
10.1、使用concatenate() 函数进行数组连接
10.2、使用堆栈函数连接数组
10.3、关于什么时间选择concatenate 函数和堆栈函数进行数组连接
11、拆分数组
12、搜索数组
13、数组排序
14、数组过滤
15、随机数
15.1 系统生成随机数
15.2、从数组中生成随机数
16、NumPy ufuncs
1、NumPy简介
NumPy 是用于处理数组的 python 库
它还拥有在线性代数、傅立叶变换和矩阵领域中工作的函数
在 Python 中,我们有满足数组功能的列表,但是处理起来很慢
NumPy 旨在提供一个比传统 Python 列表快 50 倍的数组对象
NumPy 中的数组对象称为 ndarray,它提供了许多支持函数,使得利用 ndarray 非常容易
数组在数据科学中非常常用,因为速度和资源非常重要
2、利用元组、列表创建多维数组
从下面的程序中可以看出来两个一维数组可以可以构成一个二维数组,也即一个二维数组的子元素是每一个一维数组
import numpy as nparr = np.array([[1, 2, 3], [4, 5, 6]])print(arr)
同理,两个二维数组可以构成一个三维数组
import numpy as nparr = np.array([[[1, 2, 3], [4, 5, 6]], [[1, 2, 3], [4, 5, 6]]])print(arr)

3、数组索引
数组索引等同于访问数组元素
可以通过引用其索引号来访问数组元素
NumPy 数组中的索引以 0 开头,这意味着第一个元素的索引为 0,第二个元素的索引为 1,以此类推
import numpy as nparr = np.array([1, 2, 3, 4])print(arr[2] + arr[3]) # arr[2] = 3,arr[3] = 4
访问第二维中的第五个元素(访问第二个数组中的第五个元素)
import numpy as nparr = np.array([[1,2,3,4,5], [6,7,8,9,10]])print('5th element on 2nd dim: ', arr[1, 4]) # 10print(f"当然这种方式也可以,类似于其他语言中的数组访问形式:{arr[1][4]}")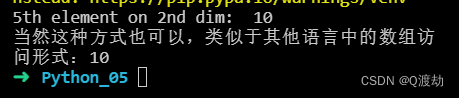
访问第一个数组的第二个数组的第三个元素
import numpy as nparr = np.array([[[1, 2, 3], [4, 5, 6]], [[7, 8, 9], [10, 11, 12]]])print(arr[1, 1, 2]) # 6print(f"当然这种方式也可以,类似于其他语言中的数组访问形式:{arr[1][1][2]}")

使用负索引
import numpy as nparr = np.array([[1,2,3,4,5], [6,7,8,9,10]])print('Last element from 2nd dim: ', arr[1, -1]) # 10
4、数组裁切
4.1、一维数组操作
裁切(切片操作)从开头到索引 4(不包括)的元素,返回的是一个新的数组
import numpy as nparr = np.array([1, 2, 3, 4, 5, 6, 7])print(arr[:4])

从末尾开始的索引 3 到末尾开始的索引 1,对数组进行裁切
import numpy as nparr = np.array([1, 2, 3, 4, 5, 6, 7])print(arr[-3:-1])![]()
请使用 step 值确定裁切的步长,从索引 1 到索引 5,返回相隔的元素
import numpy as nparr = np.array([1, 2, 3, 4, 5, 6, 7])print(arr[1:5:2])![]()
返回数组中相隔的元素
import numpy as nparr = np.array([1, 2, 3, 4, 5, 6, 7])print(arr[::2])
![]()
4.2、二维数组操作
arr[x,y],其中x是具体要操作的行数,y是具体要操作的列
从第二个元素开始,对从索引 1 到索引 4(不包括)的元素进行切片
其中 1 指的是 [6, 7, 8, 9, 10]这个数组,也即第二行
import numpy as nparr = np.array([[1, 2, 3, 4, 5], [6, 7, 8, 9, 10]])print(arr[1, 1:4])
取一个二维数组 `arr` 中前两行(第一行、第二行,因为索引为 0、1,不包括2)的第 3 列(索引为 2)组成的一维数组
import numpy as nparr = np.array([[1, 2, 3, 4, 5], [6, 7, 8, 9, 10]])print(arr[0:2, 2])
![]()
取一个二维数组中第 1 到第 2 行和第 2 到第 4 列所组成的子数组
import numpy as nparr = np.array([[1, 2, 3, 4, 5], [6, 7, 8, 9, 10]])print(arr[0:2, 1:4])

5、数据类型
NumPy 有一些额外的数据类型,并通过一个字符引用数据类型,例如 i 代表整数,u 代表无符号整数等。
以下是 NumPy 中所有数据类型的列表以及用于表示它们的字符。
i- 整数b- 布尔u- 无符号整数f- 浮点c- 复合浮点数m- timedeltaM- datetimeO- 对象S- 字符串U- unicode 字符串V- 固定的其他类型的内存块 ( void )
我们使用 array() 函数来创建数组,该函数可以使用可选参数:dtype,它允许我们定义数组元素的预期数据类型
用数据类型字符串创建数组
需要注意的是,字符类型的数组在使用时需要使用 `b''` 将字符串进行编码。在上面的例子中,`b'1'` 表示字符 `'1'` 的字节编码
在 numpy 中,`'S'` 数据类型表示字符串类型,`'S1'` 表示长度为 1 的字符串类型,`'S2'` 表示长度为 2 的字符串类型,以此类推。因,,`dtype='S'` 表示创建字符类型长度为 1 的数组
import numpy as nparr = np.array([1, 2, 3, 4], dtype='S')print(arr)
print(arr.dtype)

创建数据类型为 4 字节整数的数组
import numpy as nparr = np.array([1, 2, 3, 4], dtype='i4')print(arr)
print(arr.dtype)
通过使用 'i'/int 作为参数值,将数据类型从浮点数更改为整数
import numpy as nparr = np.array([1.1, 2.1, 3.1])# newarr = arr.astype(int)newarr = arr.astype('i')print(newarr)
print(newarr.dtype)
将数据类型从整数更改为布尔值
import numpy as nparr = np.array([1, 0, 3])newarr = arr.astype(bool)print(newarr)
print(newarr.dtype)
6、副本/视图
副本和数组视图之间的主要区别在于副本是一个新数组,而这个视图只是原始数组的视图
副本拥有数据,对副本所做的任何更改都不会影响原始数组,对原始数组所做的任何更改也不会影响副本
视图不拥有数据,对视图所做的任何更改都会影响原始数组,而对原始数组所做的任何更改都会影响视图
说白了和数据库中的视图是一个道理
副本不应受到对原始数组所做更改的影响,也即副本和
import numpy as nparr = np.array([1, 2, 3, 4, 5])
x = arr.copy()
arr[0] = 61print(arr)
print(x) 
视图应该受到对原始数组所做更改的影响,有点像人和人的影子一样,影子和人本身同时是相同的动作
import numpy as nparr = np.array([1, 2, 3, 4, 5])
x = arr.view()
x[0] = 31print(arr)
print(x)

副本拥有数据,而视图不拥有数据
每个 NumPy 数组都有一个属性 base,如果该数组拥有数据,则这个 base 属性返回 None。
否则,base 属性将引用原始对象
import numpy as nparr = np.array([1, 2, 3, 4, 5])x = arr.copy()
y = arr.view()
print(x) # [1 2 3 4 5]
print(x.base) # None
print(y.base) # [1 2 3 4 5]
7、数组形状
数组的形状是每个维中元素的数量
NumPy 数组有一个名为 shape 的属性,该属性返回一个元组,每个索引具有相应元素的数量、
下面的例子返回 (2, 4),这意味着该数组有 2 个维,每个维有 4 个元素
import numpy as nparr = np.array([[1, 2, 3, 4], [5, 6, 7, 8]])print(arr.shape)8、数组重塑
重塑意味着更改数组的形状,但是要切记原数组中元素总个数一定要等于重塑数组的元素总个数
我们可以将 8 元素 1D 数组重塑为 2 行 2D 数组中的 4 个元素,但是我们不能将其重塑为 3 元素 3 行 2D 数组,因为这将需要 3x3 = 9 个元素
数组的形状是每个维中元素的数量
通过重塑,我们可以添加或删除维度或更改每个维度中的元素数量
将以下具有 12 个元素的 1-D 数组转换为 2-D 数组
最外面的维度将有 4 个数组,每个数组包含 3 个元素
import numpy as nparr = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12])newarr = arr.reshape(4, 3)print(newarr)

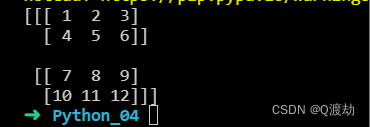
将一个数组重新变形为 3 维矩阵,其中第一维大小为 2(最外层,也即最高维),第二维大小为 3(最外层的次层),第三维大小为 2(最里面的一层,也就是一维)
最外面的维度将具有 2 个数组,其中包含 3 个数组,每个数组包含 2 个元素
import numpy as nparr = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12])newarr = arr.reshape(2, 3, 2)print(newarr)

对上面的数组进行重新改变形状,变为最外层是2个数组,但是每一个数组中又包含两个数组,这两个数组中每一个又包含3个元素
import numpy as nparr = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12])newarr = arr.reshape(2,2 , 3)print(newarr)
重塑之后的多维数组是一个视图
import numpy as nparr = np.array([1, 2, 3, 4, 5, 6, 7, 8])print(arr.reshape(2, 4).base)![]()
9、多维数组的迭代
使用 for 循环迭代三维数组,n维数组则必有n个for循环
import numpy as nparr = np.array([[[1, 2, 3], [4, 5, 6]], [[7, 8, 9], [10, 11, 12]]])for x in arr: # 迭代所有的二维数组,即 x 为 [[1, 2, 3], [4, 5, 6]] 、 [[7, 8, 9] [10, 11, 12]]for y in x: # 迭代二维数组x中的一维数组,即y为 [1, 2, 3]、[4, 5, 6]、[7, 8, 9]、[10, 11, 12]for z in y: # 迭代一维数组y中的元素,即z为 1.....12print(z)
对上面的三维数组使用nditer()辅助函数进行迭代
import numpy as nparr = np.array([[[1, 2, 3], [4, 5, 6]], [[7, 8, 9], [10, 11, 12]]])for x in np.nditer(arr):print(x)
我们可以使用 op_dtypes 参数,并传递期望的数据类型,以在迭代时更改元素的数据类型。
NumPy 不会就地更改元素的数据类型(元素位于数组中),因此它需要一些其他空间来执行此操作,该额外空间称为 buffer,为了在 nditer() 中启用它,我们传参 flags=['buffered']
import numpy as nparr = np.array([1, 2, 3])for x in np.nditer(arr, flags=['buffered'], op_dtypes=['S']):print(x)
每遍历 2D 数组的一个标量元素,跳过 1 个元素
import numpy as nparr = np.array([[1, 2, 3, 4], [5, 6, 7, 8]])for x in np.nditer(arr[:, ::2]):print(x)

使用 ndenumerate() 方法进行枚举迭代,换句话说就是一边迭代一边打印带元素对应的下标
枚举是指逐一提及事物的序号
有时,我们在迭代时需要元素的相应索引,对于这些用例,可以使用 ndenumerate() 方法
import numpy as nparr = np.array([[1, 2, 3, 4], [5, 6, 7, 8]])for idx, x in np.ndenumerate(arr):print(idx, x)

10、数组连接
需要注意的是,待合并的几个数组的维度必须相同,即一维数组只能和一维数组合并,二维数组只能和二维数组合并。此外,如果合并的是一维数组,数组的形状可以不一样;但如果合并的是多维数组,则数组的形状必须相同,也就是数组的行列数必须一样
10.1、使用concatenate() 函数进行数组连接
行之和,列不变,使用参数 axis = 0(改变行),连接两个二维数组
import numpy as nparr1 = np.array([[1, 2], [3, 4]]) # 2行2列arr2 = np.array([[5, 6], [7, 8]]) # 2行2列arr = np.concatenate((arr1, arr2), axis=0)print(arr)print("---------------------------");print(arr.shape)
行不变,列之和,使用参数 axis = 1(改变列),连接两个二维数组,结果函数二维数组
import numpy as nparr1 = np.array([[1, 2], [3, 4]]) # 2 行 2 列arr2 = np.array([[5, 6], [7, 8]]) # 2 行 2 列arr = np.concatenate((arr1, arr2), axis=1)print(arr)print("---------------------------");print(arr.shape)
深度和,行不变,列不变,使用参数 axis = 0(改变深度),连接两个三维数组
import numpy as np
arr1 = np.ones((2, 3, 4))
arr2 = np.zeros((2, 3, 4))
result = np.concatenate((arr1, arr2), axis=0)
print(arr1)
print("----------------------------------")
print(arr2)
print("----------------------------------")
print(result)
print("----------------------------------")
print(result.shape) 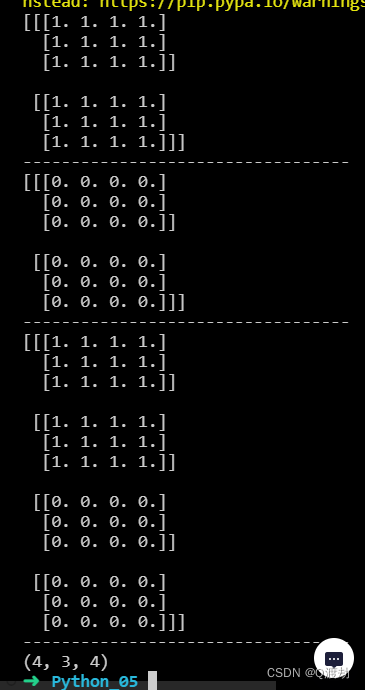
深度不变,行之和,列不变,使用参数 axis = 1(改变行),连接两个三维数组
import numpy as np
arr1 = np.ones((2, 3, 4))
arr2 = np.zeros((2, 3, 4))
result = np.concatenate((arr1, arr2), axis=1)
print(arr1)
print("----------------------------------")
print(arr2)
print("----------------------------------")
print(result)
print("----------------------------------")
print(result.shape) 
深度不变,行不变,列之和,使用参数 axis = 2(改变列),连接两个三维数组
import numpy as np
arr1 = np.ones((2, 3, 4))
arr2 = np.zeros((2, 3, 4))
result = np.concatenate((arr1, arr2), axis=2)
print(arr1)
print("----------------------------------")
print(arr2)
print("----------------------------------")
print(result)
print("----------------------------------")
print(result.shape) 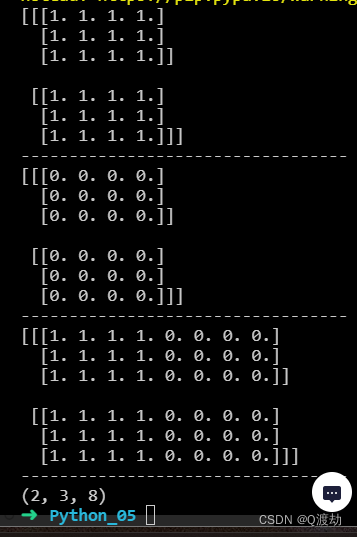
10.2、使用堆栈函数连接数组
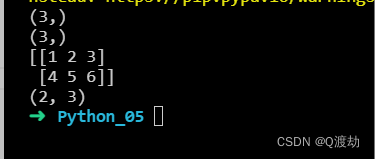
import numpy as nparr1 = np.array([1, 2, 3])print(arr1.shape)arr2 = np.array([4, 5, 6])print(arr2.shape)arr = np.stack((arr1, arr2), axis=0)print(arr)print(arr.shape)
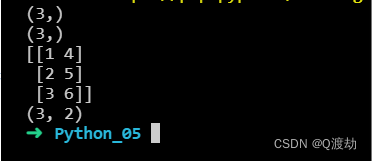
import numpy as nparr1 = np.array([1, 2, 3])print(arr1.shape)arr2 = np.array([4, 5, 6])print(arr2.shape)arr = np.stack((arr1, arr2), axis=1)print(arr)print(arr.shape)
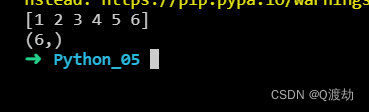
NumPy 提供了一个辅助函数:hstack() 沿行堆叠。
import numpy as nparr1 = np.array([1, 2, 3])arr2 = np.array([4, 5, 6])arr = np.hstack((arr1, arr2))print(arr)print(arr.shape)
NumPy 提供了一个辅助函数:vstack() 沿列堆叠
import numpy as nparr1 = np.array([1, 2, 3])arr2 = np.array([4, 5, 6])arr = np.vstack((arr1, arr2))print(arr)print(arr.shape)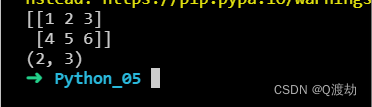
NumPy 提供了一个辅助函数:dstack() 沿高度堆叠,该高度与深度相同
import numpy as nparr1 = np.array([1, 2, 3])arr2 = np.array([4, 5, 6])arr = np.dstack((arr1, arr2))print(arr)print(arr.shape)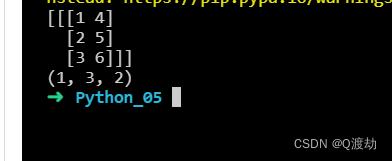
10.3、关于什么时间选择concatenate 函数和堆栈函数进行数组连接
在 Numpy 中,有两种方法可以用来连接多个数组,即使用堆栈函数(stack、hstack、vstack、dstack等)或者使用 concatenate 函数。两者都可以将多个数组沿着某个维度拼接起来形成一个新的数组
使用堆栈函数连接数组的情况一般是比较简单的,例如: - 如果想要将两个一维数组沿着行方向(即水平方向)拼接起来,可以使用 hstack 函数
- 如果想要将两个一维数组沿着列方向(即垂直方向)拼接起来,可以使用 vstack 函数
- 如果想要将两个二维数组沿着深度方向(即沿着第三个维))拼接起来,可以使用 dstack 函数
使用 concatenate 函数连接数组的情况一般是比较复杂的
例如: - 如果想要将多个数组沿着不同的轴(即不同的维度)拼接起来,可以使用 concatenate 函数,并且需要在函数参数中指定拼接的轴。
- 如果想要将多个不同形状的数组拼接起来,需要先对这些数组进行变形(reshape),使得它们在拼接轴上的大小相同或者为 1,然后再使用 concatenate 函数进行拼接。 因此,一般来说,在拼接时只需要考虑拼接的方向和是否需要考虑变形即可。如果非常简单,比如只需要在水平或者垂直方向上拼接几个数组,那么可以使用堆栈函数;如果比较复杂,需要在不同的轴上进行拼接或者需要进行变形操作,那么可以使用 concatenate 函数
11、拆分数组
拆分是连接的反向操作
连接(Joining)是将多个数组合并为一个,拆分(Spliting)将一个数组拆分为多个
我们使用 array_split() 分割数组,将要分割的数组和分割数传递给它
访问拆分的数组
import numpy as nparr = np.array([1, 2, 3, 4, 5, 6])newarr = np.array_split(arr, 3)
print(newarr)
print(newarr[0])
print(newarr[1])
print(newarr[2])
import numpy as nparr = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9], [10, 11, 12], [13, 14, 15], [16, 17, 18]])newarr = np.array_split(arr, 3, axis=0)print(newarr) 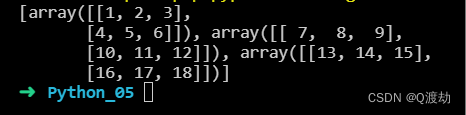
import numpy as nparr = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9], [10, 11, 12], [13, 14, 15], [16, 17, 18]])newarr = np.array_split(arr, 3, axis=1)print(newarr) 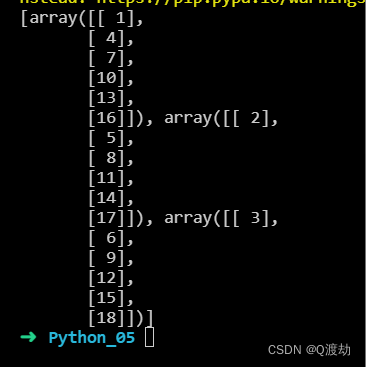
使用 hsplit() 方法将 2-D 数组沿着行分成三个 2-D 数组
import numpy as nparr = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9], [10, 11, 12], [13, 14, 15], [16, 17, 18]])newarr = np.hsplit(arr, 3)print(newarr)
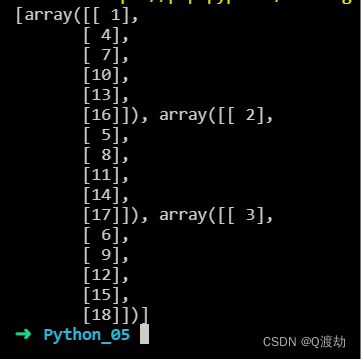
vsplit() 和 dsplit() 可以使用与 vstack() 和 dstack() 类似的替代方法
12、搜索数组
可以在数组中搜索(检索)某个值,然后返回获得匹配的索引
使用 where() 方法查找值为 4 的索引
import numpy as nparr = np.array([1, 2, 3, 4, 5, 4, 4])x = np.where(arr == 4)print(x) # (array([3, 5, 6], dtype=int64),),也即数字4对应的下标import numpy as nparr = np.array([1, 2, 3, 4, 5, 6, 7, 8])x = np.where(arr%2 == 1)print(x) # 返回元组(array([0, 2, 4, 6], dtype=int64),)
有一个名为 searchsorted() 的方法,该方法在数组中执行二进制搜索,并返回将在其中插入指定值以维持搜索顺序的索引
假定 searchsorted() 方法用于排序数组
应该在索引 1 上插入数字 7,以保持排序顺序
该方法从左侧开始搜索,并返回第一个索引,其中数字 7 不再大于下一个值
import numpy as nparr = np.array([6, 7, 8, 9])x = np.searchsorted(arr, 7)print(x) # 1
从右边开始查找应该插入值 7 的索引
应该在索引 2 上插入数字 7,以保持排序顺序
该方法从右边开始搜索,并返回第一个索引,其中数字 7 不再小于下一个值
import numpy as nparr = np.array([6, 7, 8, 9])x = np.searchsorted(arr, 7, side='right')print(x) # 2
使用拥有指定值的数组,查找应在其中插入值 2、4 和 6 的索引
import numpy as nparr = np.array([1, 3, 5, 7])x = np.searchsorted(arr, [2, 4, 6])print(x) # [1 2 3]# 2 插入的是原数组 3 的位置,为索引 1# 4 插入的是原数组 5 的位置,为索引 2# 6 插入的是原数组 7 的位置,为索引 313、数组排序
排序是指将元素按有序顺序排列
有序序列是拥有与元素相对应的顺序的任何序列,例如数字或字母、升序或降序
NumPy ndarray 对象有一个名为 sort() 的函数,该函数将对指定的数组进行排序
此方法返回数组的副本,而原始数组保持不变
import numpy as nparr = np.array(['banana', 'cherry', 'apple'])arr1 = np.array([True, False, True])arr2 = np.array([[3, 2, 4], [5, 0, 1]])# 对数组以字母顺序进行排序print(np.sort(arr))# 对布尔数组进行排序print(np.sort(arr1))# 如果在二维数组上使用 sort() 方法,则将对两个数组进行排序print(np.sort(arr2))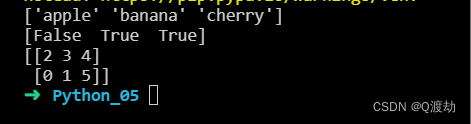
14、数组过滤
从现有数组中取出一些元素并从中创建新数组称为过滤(filtering)
在 NumPy 中,我们使用布尔索引列表来过滤数组
布尔索引列表是与数组中的索引相对应的布尔值列表
如果索引处的值为 True,则该元素包含在过滤后的数组中;如果索引处的值为 False,则该元素将从过滤后的数组中排除
# 用索引 0 和 2、4 上的元素创建一个数组import numpy as nparr = np.array([61, 62, 63, 64, 65])x = [True, False, True, False, True] # 61对应true、62对应false、63对应true、64对应false、65对应true,所以保留true对应的数字重新构成数组newarr = arr[x]print(newarr) # [61, 63, 65]根据条件创建过滤器,创建一个过滤器数组,该数组仅返回原始数组中的偶数元素
import numpy as nparr = np.array([1, 2, 3, 4, 5, 6, 7])# 创建一个空列表
filter_arr = []# 遍历 arr 中的每个元素
for element in arr:# 如果元素可以被 2 整除,则将值设置为 True,否则设置为 Falseif element % 2 == 0:filter_arr.append(True)else:filter_arr.append(False)newarr = arr[filter_arr]print(filter_arr)
print(newarr)
直接从数组创建过滤器
上例是 NumPy 中非常常见的任务,NumPy 提供了解决该问题的好方法
我们可以在条件中直接替换数组而不是 iterable 变量,它会如我们期望地那样工作
创建一个仅返回大于 62 的值的过滤器数组
import numpy as nparr = np.array([61, 62, 63, 64, 65])filter_arr = arr > 62 newarr = arr[filter_arr]print(filter_arr)
print(newarr)

15、随机数
15.1 、系统生成随机数
NumPy 提供了 random 模块来处理随机数
# 生成一个 0 到 100 之间的随机整数from numpy import randomx = random.randint(100)print(x)
randint() 方法接受 size 参数,您可以在其中指定数组的形状
# 生成一个 1-D 数组,其中包含 5 个从 0 到 100 之间的随机整数from numpy import randomx=random.randint(100, size=(5))print(x)![]()
# 生成有 3 行的 2-D 数组,每行包含 5 个从 0 到 100 之间的随机整数from numpy import randomx = random.randint(100, size=(3, 5))print(x)# 生成有 3 行的 2-D 数组,每行包含 5 个随机数from numpy import randomx = random.rand(3, 5)print(x)random 模块的 rand() 方法返回 0 到 1 之间的随机浮点数
# random 模块的 rand() 方法返回 0 到 1 之间的随机浮点数from numpy import randomx = random.rand()print(x)
15.2、从数组中生成随机数
choice() 方法使您可以基于值数组生成随机值
choice() 方法将数组作为参数,并随机返回其中一个值
# 返回数组中的值之一from numpy import randomx = random.choice([3, 5, 7, 9])print(x)choice() 方法还允许返回一个值数组
添加一个 size 参数以指定数组的形状
# 生成由数组参数(3、5、7 和 9)中的值组成的二维数组from numpy import randomx = random.choice([3, 5, 7, 9], size=(3, 5))print(x)

16、NumPy ufuncs
ufuncs 指的是“通用函数”(Universal Functions),它们是对 ndarray 对象进行操作的 NumPy 函数
ufunc 用于在 NumPy 中实现矢量化,这比迭代元素要快得多
它们还提供广播和其他方法,例如减少、累加等,它们对计算非常有帮助
ufuncs 还接受其他参数,比如:
where 布尔值数组或条件,用于定义应在何处进行操作
dtype 定义元素的返回类型
out 返回值应被复制到的输出数组
将迭代语句转换为基于向量的操作称为向量化
由于现代 CPU 已针对此类操作进行了优化,因此速度更快


对此,NumPy 有一个 ufunc,名为 add(x, y),它会输出相同的结果
通过 ufunc,我们可以使用 add() 函数
import numpy as npx = [1, 2, 3, 4]
y = [4, 5, 6, 7]
z = np.add(x, y)print(z)

相关文章:
NumPy
目录 1、NumPy简介 2、利用元组、列表创建多维数组 3、数组索引 4、数组裁切 4.1、一维数组操作 4.2、二维数组操作 5、数据类型 6、副本/视图 7、数组形状 8、数组重塑 9、多维数组的迭代 10、数组连接 10.1、使用concatenate() 函数进行数组连接 10.2、使用堆栈…...

C++17完整导引-模板特性之类模板参数推导
模板特性之类模板参数推导 使用类模板参数推导默认以拷贝方式推导推导lambda的类型没有类模板部分参数推导使用类模板参数推导代替快捷函数 推导指引使用推导指引强制类型退化非模板推导指引推导指引VS构造函数显式推导指引聚合体的推导指引标准推导指引pair和tuple的推导指引从…...

CSS3小可爱亲吻表白特效,给你的五一假期增添点小乐趣
马上五一假期了,小伙伴们是不是都准备出去旅游呢,或者回老家陪陪父母。今天我用CSS3制作一个小可爱亲吻表白的特效,来给你即将到来的五一假期增添点小小的乐趣。 目录 实现思路 左边小可爱的实现 右边小可爱的实现 左右摇摆动效的实现 右…...

Samba CentOS 7 安装
安装步骤 Samba是在Linux与Windows系统间共享文件和打印机的标准协议。要在CentOS上安装Samba,可以按以下步骤操作: 安装Samba相关包: yum install samba samba-client samba-common创建Samba配置文件/etc/samba/smb.conf: vim /etc/samba/smb.conf添加如下配置: [global]…...

Mac电脑 Vscode : Flutter 开发环境搭建(最细节教程)
参考链接: MacVSCode安装flutter环境_mac vscode配置flutter_GalenWu的博客-CSDN博客 mac搭建Flutter环境以及初始化项目 - 简书 注意: *下载xcode 就包含git了, *苹果芯片和intel 芯片需要的环境不同,苹果芯片需要安装: Im…...

BEVFormer 论文学习
1. 解决了什么问题? 3D 视觉感知任务,包括基于多相机图像的 3D 目标检测和分割,对于自动驾驶系统非常重要。与基于 LiDAR 的方法相比,基于相机图像的方法能够检测到更远距离的目标,识别交通信号灯、交通标识等信息。有…...

现在的00后,实在是太卷了,我们这些老油条都想辞职了......
现在的小年轻真的卷得过分了。前段时间我们公司来了个00年的,工作没两年,跳槽到我们公司起薪20K,都快要超过我了。 后来才知道人家是个卷王,从早干到晚就差搬张床到工位睡觉了。 最近和他聊了一次天,原来这位小老弟家…...

shell 数组定义与使用
一维数组 数组定义 array_name(value1 value2 ... value)也可以使用数字下表来定义数组 array_name[0]value0 array_name[1]value1 array_name[2]value2读取数组 ${array_name[index]}实例1 [rootiZj6c3slqbp8xuu2w3i4roZ devops]# cat array_name.sh #!/usr/bin/bashmy_…...

24 KVM管理虚拟机-配置VNC-TLS登录
文章目录 24 KVM管理虚拟机-配置VNC-TLS登录24.1 概述24.2 操作步骤 24 KVM管理虚拟机-配置VNC-TLS登录 24.1 概述 VNC服务端和客户端默认采用明文方式进行数据传输,因此通信内容可能被第三方截获。为了提升安全性,openEuler支持VNC服务端配置TLS模式进…...
)
C++基础讲解第六期(多态、虚函数、虚析构函数、dynamic_cast、typeid纯虚函数)
C基础讲解第六期 代码中也有对应知识注释,别忘看,一起学习! 一、多态1. 问题引出2. 多态的概念和使用3. 多态的原理4. 虚析构函数5. 动态类型识别(dynamic_cast)(1) 自定义类型(2). dynamic_cast(3). typeid 6. 纯虚函数 纯虚函数需要补充 一…...

防火墙之iptables(二)
防火墙之iptables(二) 一.SNAT原理与应用 1.应用环境 局域网主机共享单个公网IP地址接入Internet(私网不能被Internet中正常路由)2.SNAT原理 修改数据包的源地址内网访问外网 将从内网发送到外网的数据包的源IP由私网IP转换成…...

亚马逊销量暴跌该如何查找原因?
很多卖家经常遇到一个棘手的问题,就是突然会遇到链接销量暴跌的问题。 比如之前链接可以稳定出单10多单的,突然连续几天只有两三单,这到底是什么原因呢? 1.查看链接的类目是否被修改 这个类目修改不一定是卖家自己修改,更多的时…...

Vue中的脚手架和路由
私人博客 许小墨のBlog —— 菜鸡博客直通车 系列文章完整版,配图更多,CSDN博文图片需要手动上传,因此文章配图较少,看不懂的可以去菜鸡博客参考一下配图! 系列文章目录 前端系列文章——传送门 后端系列文章——传送…...
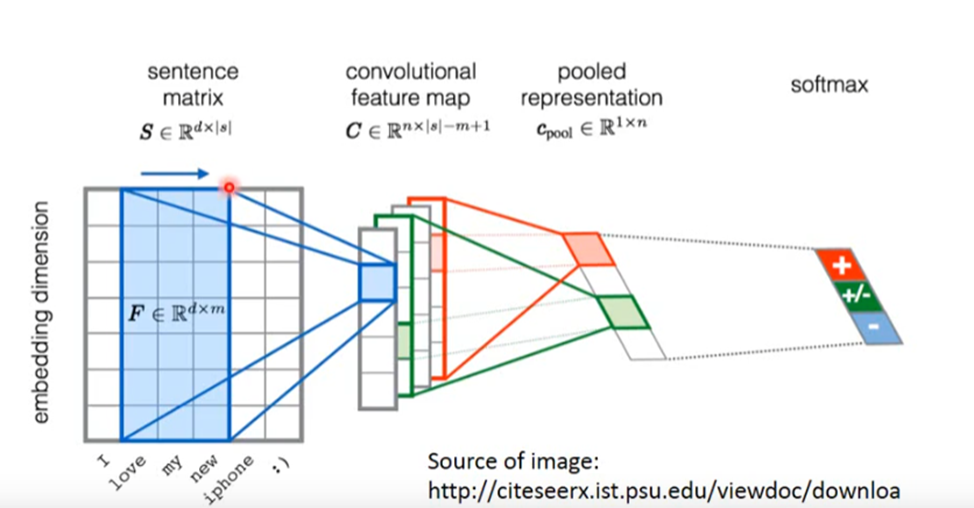
Convolutional Neural network(卷积神经网络)
目录 Why CNN for Image? The whole CNN structure Convolution(卷积) Max Pooling Flatten CNN in Keras What does CNN learn? what does filter do what does neuron do what about output Deep Dream Application Pla…...

【资料分享】高边、低边晶体管开关及电路解析
高边和低边晶体管开关 电路中,晶体管常常被用来当做开关使用。晶体管用作开关时有两种不同的接线方式:高边(high side)和低边(low side)。 高边和低边是由晶体管在电路中的位置决定的。晶体管可以是双极性晶体管(BJT…...

六级备考28天|CET-6|听力第二讲|长对话满分技巧|听写技巧|2022年6月考题|14:30~16:00
目录 1. 听力策略 2. 第一二讲笔记 3. 听力原文复现 (5)第五小题 (6)第六小题 (7)第七小题 (8)第八小题 扩展业务 expand business 4. 重点词汇 1. 听力策略 2. 第一二讲笔记 3. 听力原文复现 (5)第五小题 our guest is Molly Sundas, a university stud…...

计算机图形学 | 实验九:纹理贴图和天空盒
计算机图形学 | 实验九:纹理贴图和天空盒 计算机图形学 | 实验九:纹理贴图和天空盒实验概述顶点数据立方体顶点数据天空盒顶点数组 纹理载入创建纹理纹理读取纹理绑定 使用纹理立方体着色器顶点着色器片元着色器 天空盒着色器顶点着色器片元着色器 立方体…...

Unity A* Pathfinding Project
先下载免费版 https://arongranberg.com/astar/download# 教程首页 https://arongranberg.com/astar/docs/getstarted.html 创建一个plane 当地面 创建一个gameobject 添加组件 PathFinder 长这样 调整每个格子大小的 创建两个layer 一个是阻挡物的 一个是地面的 这里填入阻…...

SpringBoot ( 一 ) 搭建项目环境
1.搭建环境 1.1.创建项目向导 使用idea中的向导创建SpringBoot项目 1.1.1.建立新的项目 位置 : 菜单 > File > New > Project… 1.1.2.选择向导 默认的向导URL 是 https://start.spring.io 建议使用 https://start.aliyun.com 1.1.3.配置项目信息 Group : 组织…...

idea中关联Git
注意:未安装和配置Git软件,请先跳转到 Git宝典_没办法,我就是这么菜的博客-CSDN博客 idea关联git 关联git.exe 选择你的Version Control 下的Git 选择你的Git安装目录bin下的git.exe,点击ok 点击Test,显示版本号…...

3个关键功能解析:USBToolBox如何简化macOS与Windows的USB端口映射难题
3个关键功能解析:USBToolBox如何简化macOS与Windows的USB端口映射难题 【免费下载链接】tool the USBToolBox tool 项目地址: https://gitcode.com/gh_mirrors/too/tool 在Hackintosh和跨平台开发领域,USB端口映射一直是个令人头疼的技术难题。US…...

AMLP框架实战:基于MACE构建高精度机器学习势函数
1. 项目概述:当机器学习势函数遇上自动化管道在计算化学和材料科学领域,我们长久以来面临着一个核心矛盾:精度与效率的权衡。密度泛函理论(DFT)能提供接近实验的精度,但计算成本高昂,通常只能处…...

iPaaS 应用场景深度解析:从系统孤岛到数据自由流动的六大实战路径
写在前面 一个企业的数字化程度越高,系统就越多。系统越多,集成问题就越严重。 这不是假设,而是我们在服务客户过程中反复验证的结论——企业数字化转型的瓶颈,往往不在于"造新系统",而在于"连老系统&q…...

广州因特智能:AI视觉软硬结合,打破半导体检测装备“卡脖子”困境
【导语:广州因特智能科技孵化于西安电子科技大学广州研究院,专注用AI视觉技术解决工业场景的“卡脖子”检测难题,为半导体、光通信、新能源三大领域提供高端检测装备。】校地合作孵化,构建完整能力体系广州因特智能科技由西安电子…...

3分钟快速安装BetterNCM插件管理器,让你的网易云音乐功能翻倍
3分钟快速安装BetterNCM插件管理器,让你的网易云音乐功能翻倍 【免费下载链接】BetterNCM-Installer 一键安装 Better 系软件 项目地址: https://gitcode.com/gh_mirrors/be/BetterNCM-Installer 还在为网易云音乐功能单一而烦恼吗?想要解锁更多个…...

java项目011-ssm 宠物医院系统
java项目011-ssm 宠物医院系统 是一款基于springspringmvcmybatis的宠物系统, 包含界面布局、医生信息管理、客户信息管理、宠物管理、浏览管理、 诊断管理、医生管理、用户管理 其中医生管理、用户管理只能管理员有权限进行操作。 采用spingboot方式启动 运行截图...

基于ISDN信令的来电语音播报系统:从原理到树莓派实现
1. 项目概述:一个基于ISDN的来电语音播报系统如果你家里或办公室里还有一台老式的ISDN路由器,别急着把它当电子垃圾处理掉。我最近就利用手头一台闲置的ISDN路由器,折腾出了一个挺有意思的小玩意儿:一个能自动识别来电号码&#x…...

VideoDownloadHelper终极指南:解锁浏览器视频下载的完整解决方案
VideoDownloadHelper终极指南:解锁浏览器视频下载的完整解决方案 【免费下载链接】VideoDownloadHelper Chrome Extension to Help Download Video for Some Video Sites. 项目地址: https://gitcode.com/gh_mirrors/vi/VideoDownloadHelper 还在为无法保存网…...

智能体任务分配算法:从启发式到深度强化学习的演进与实践
1. 项目概述:从“谁来做”到“如何做得更好”的智能进化在机器人集群、无人机编队或是自动化仓储系统中,我们常常面临一个看似简单实则复杂的问题:眼前有一堆任务,手头有一群可用的智能体(机器人、无人机、服务器等&am…...

Python到Android的魔法之旅:5步将你的代码变成移动应用
Python到Android的魔法之旅:5步将你的代码变成移动应用 【免费下载链接】python-for-android Turn your Python application into an Android APK 项目地址: https://gitcode.com/gh_mirrors/py/python-for-android 想象一下,你花了几个月时间精心…...