BEVFormer 论文学习
1. 解决了什么问题?
3D 视觉感知任务,包括基于多相机图像的 3D 目标检测和分割,对于自动驾驶系统非常重要。与基于 LiDAR 的方法相比,基于相机图像的方法能够检测到更远距离的目标,识别交通信号灯、交通标识等信息。有一些方法使用单目画面,然后进行跨相机的后处理操作;这类方法的缺点就是各图像是分开处理的,无法取得跨相机的画面信息,因而效果和效率都比较差。
与单目方法相比,BEV 是表示周围环境的常用方法,它能清晰呈现目标的位置和大小,适合自动驾驶感知和规划任务。但现有的基于 BEV 的检测方法所提供的 BEV 特征要么不够鲁棒,无法准确地预测 3D 目标;要么深度信息不够准确。
人类视觉系统会通过时间信息推理出目标的运动状态与被遮挡物体,但现有的方法很少考虑时间信息。在驾驶过程中,目标移动速度很快,直接使用各时间戳的 BEV 特征,会增加计算成本与干扰信息,因此不是最佳的。
2. 提出了什么方法?
本文提出了 BEVFormer,一个基于 transformer 的 BEV encoder,通过预先定义的网格状 BEV queries 实现信息在时间和空间内的交互。BEVFormer 包括三个部分:
- 网格形状的 BEV queries,通过注意力机制灵活地融合空间和时间特征;
- 空间 cross-attention 模块,从多个相机画面聚合空间特征;
- 时间 self-attention 模块,从历史 BEV 特征提取时间信息,有助于预测运动物体的速度以及被遮挡的目标。

2.1 整体架构
如上图,BEVFormer 包括 6 个标准的 encoder 层,以及 3 项特殊设计,即 BEV queries、空间 cross-attention 和时间 self-attention。BEV queries 是网格形状的可学习参数,在 BEV 空间内,对多相机的画面利用注意力机制 query 特征。
推理时,在时间戳 t t t,将多相机画面输入进主干网络 ResNet,获取不同相机画面的特征 F t = { F t i } i = 1 N v i e w F_t=\lbrace F_t^i \rbrace_{i=1}^{N_{view}} Ft={Fti}i=1Nview, F t i F_t^i Fti是第 t t t时刻、第 i i i个相机画面的特征, N v i e w N_{view} Nview是画面的个数。保留时间戳 t − 1 t-1 t−1的 BEV 特征 B t − 1 B_{t-1} Bt−1。在每个 encoder 层,首先使用 BEV queries Q Q Q,通过时间 self-attention 对 BEV 特征 B t − 1 B_{t-1} Bt−1查询时域信息。然后通过空间 cross-attention 使用 Q Q Q来查询多相机特征 F t F_t Ft的空间信息。在 FFN 后,encoder 层输出优化后的 BEV 特征,作为下一个 encoder 层的输入。一共经过 6 个 encoder 层,就得到了时间戳 t t t的 BEV 特征 B t B_t Bt。接下来,使用 B t B_t Bt进行后续的 3D 检测和语义分割任务。
2.2 BEV Queries
定义一组网格状的可学习参数 Q ∈ R H × W × C Q\in \mathbb{R}^{H\times W\times C} Q∈RH×W×C,作为 BEVFormer 的 queries,其中 H , W H,W H,W是 BEV 平面的高度和宽度。Query Q p ∈ R 1 × C Q_p\in \mathbb{R}^{1\times C} Qp∈R1×C位于 p = ( x , y ) p=(x,y) p=(x,y),负责 BEV 平面的相应的格子。BEV 平面上的每个网格都对应着真实世界的 s s s米长度。BEV 特征的中心对应着车辆自身(ego)的位置。在输入 BEVFormer 前,在 queries Q Q Q中加入可学习的 positional encoding。
2.3 Spatial Cross-Attention
因为多相机 3D 感知的输入尺度太大,原始的 multi-head attention 的计算成本就过高。因此,作者基于 deformable attention 设计了空间 cross-attention,每个 BEV query Q Q Q只和相机画面内的兴趣区域(RoI)发生作用。
如上图(b),将 BEV 平面的每个 query 变为 pillar-like query,从该 pillar 中采样 N r e f N_{ref} Nref个 3D reference points,然后再将这些点映射到 2D 画面。对于一个 BEV query,映射的 2D 点只会落到某些画面里面,这些画面叫做 V h i t \mathcal{V}_{hit} Vhit。将这些 2D 点看作为 query Q p Q_p Qp的 reference points,然后从 V h i t \mathcal{V}_{hit} Vhit画面中提取这些 reference points 的特征。最后,计算这些采样特征的加权和,作为空间 cross-attention 的输出。SCA 计算如下:
SCA ( Q p , F t ) = 1 ∣ V h i t ∣ ∑ i ∈ V h i t ∑ j = 1 N r e f DeformAttn ( Q p , P ( p , i , j ) , F t i ) \text{SCA}(Q_p, F_t)=\frac{1}{\left| \mathcal{V}_{hit}\right|}\sum_{i\in \mathcal{V}_{hit}}\sum_{j=1}^{N_{ref}}\text{DeformAttn}(Q_p, \mathcal{P}(p,i,j),F_t^i) SCA(Qp,Ft)=∣Vhit∣1i∈Vhit∑j=1∑NrefDeformAttn(Qp,P(p,i,j),Fti)
其中 i i i是相机画面索引, j j j是 reference point 的索引, N r e f N_{ref} Nref是每个 BEV query pillar 中 reference points 的个数。 F t i F_t^i Fti是第 i i i个相机画面的特征。对于每个 BEV query Q p Q_p Qp,使用一个映射函数 P ( p , i , j ) \mathcal{P}(p,i,j) P(p,i,j)获取第 i i i个画面上 p = ( x , y ) p=(x,y) p=(x,y)位置的第 j j j个 reference point。
接下来,介绍如何使用映射函数 P \mathcal{P} P从图像上获取 reference point。首先计算 p = ( x , y ) p=(x,y) p=(x,y)位置上 Q p Q_p Qp对应的真实世界的坐标 ( x ′ , y ′ ) (x',y') (x′,y′):
x ′ = ( x − W 2 ) × s ; y ′ = ( y − H 2 ) × s x'=(x-\frac{W}{2})\times s;\quad\quad y'=(y-\frac{H}{2})\times s x′=(x−2W)×s;y′=(y−2H)×s
这里 H , W H,W H,W是 BEV queries 空间的高度和宽度, s s s是 BEV 网格的大小, ( x ′ , y ′ ) (x',y') (x′,y′)是坐标位置。在 3D 空间, ( x ′ , y ′ ) (x',y') (x′,y′)处的目标可能出现在 z ′ z' z′高度。因此,作者预先定义了一组 anchor heights { z j ′ } j = 1 N r e f \lbrace z'_j \rbrace_{j=1}^{N_{ref}} {zj′}j=1Nref,确保我们可以获取不同高度的信息。这样,对于每个 query Q p Q_p Qp,得到一个柱状的 3D reference points ( x ′ , y ′ , z j ′ ) j = 1 N r e f (x',y',z'_j)_{j=1}^{N_{ref}} (x′,y′,zj′)j=1Nref。最后,通过相机参数矩阵,将 3D reference points 映射到不同的相机画面中:
P ( p , i , j ) = ( x i j , y i j ) \mathcal{P}(p,i,j)=(x_{ij}, y_{ij}) P(p,i,j)=(xij,yij)
where z i j ⋅ [ x i j y i j 1 ] T = T i ⋅ [ x ′ y ′ z j ′ 1 ] T . \text{where}\quad z_{ij}\cdot \left[ x_{ij}\quad y_{ij}\quad 1 \right]^T = T_i \cdot \left[ x' \quad y'\quad z'_j\quad 1 \right]^T. wherezij⋅[xijyij1]T=Ti⋅[x′y′zj′1]T.
其中, P ( p , i , j ) \mathcal{P}(p,i,j) P(p,i,j)是第 j j j个 3D reference point ( x ′ , y ′ , z j ′ ) (x',y',z'_j) (x′,y′,zj′)映射到第 i i i个画面的 2D 点。 T i ∈ R 3 × 4 T_i\in \mathbb{R}^{3\times 4} Ti∈R3×4是第 i i i个相机的参数矩阵。
2.4 Temporal Self-Attention
时间信息对于视觉系统也非常重要,有助于预测运动物体的速度,或者检测遮挡物体。于是,作者设计了 temporal self-attention,融合历史 BEV 特征来表征当前的环境。
给定时间戳 t t t的 BEV queries Q Q Q和 t − 1 t-1 t−1时间戳的历史 BEV 特征 B t − 1 B_{t-1} Bt−1。首先基于车辆自身的运动,将 B t − 1 B_{t-1} Bt−1与 Q Q Q对齐,保证同一网格内的特征对应着同一个真实的世界坐标。将对齐后的历史 BEV 特征 B t − 1 B_{t-1} Bt−1记为 B t − 1 ′ B'_{t-1} Bt−1′。但是从 t − 1 t-1 t−1到 t t t,真实世界的目标运动偏移是各不相同的。因此,作者通过 TSA 层对特征间的时间关系建模:
TSA ( Q p , { Q , B t − 1 ′ } ) = ∑ V ∈ { Q , B t − 1 ′ } DeformAttn ( Q p , p , V ) \text{TSA}(Q_p, \lbrace Q,B'_{t-1} \rbrace)=\sum_{V\in\lbrace Q,B'_{t-1} \rbrace}\text{DeformAttn}(Q_p, p, V) TSA(Qp,{Q,Bt−1′})=V∈{Q,Bt−1′}∑DeformAttn(Qp,p,V)
Q p Q_p Qp表示 p = ( x , y ) p=(x,y) p=(x,y)处的 BEV query。$\lbrace Q,B’{t-1}\rbrace 是将 是将 是将Q 和 和 和B’{t-1} c o n c a t 起来,预测 T S A D e f o r m A t t n 的偏移量 concat 起来,预测 TSA DeformAttn 的偏移量 concat起来,预测TSADeformAttn的偏移量\Delta p$。对于每个序列中的第一个样本,TSA 会退化为一个不带时间信息的 self-attention,用 BEV queries { Q , Q } \lbrace Q,Q \rbrace {Q,Q}代替 { Q , B t − 1 ′ } \lbrace Q,B'_{t-1} \rbrace {Q,Bt−1′}。
2.5 实验
2.5.1 Training
对于时间戳 t t t的样本,从过去 2 秒的连续帧中另外选取 3 个样本,这个随机采样策略能增强车辆自身运动的多样性。将这4个样本的时间戳分别记做 t − 3 , t − 2 , t − 1 t-3,t-2,t-1 t−3,t−2,t−1和 t t t。前 3 个时间戳负责递归地产生 BEV 特征 { B t − 3 , B t − 2 , B t − 1 } \lbrace B_{t-3},B_{t-2},B_{t-1} \rbrace {Bt−3,Bt−2,Bt−1}。对于 t − 3 t-3 t−3时间戳的初始样本,TSA 会退化为 self-attention。在 t t t时刻,模型基于多相机输入和 B t − 1 B_{t-1} Bt−1,产生 BEV 特征 B t B_t Bt,这样 B t B_t Bt就包含了横跨 4 个样本的时间和空间信息。最后将 B t B_t Bt输入进检测和分割 heads,计算相应的损失。
2.5.2 Inference
推理时,按时间顺序在视频的每一帧上做预测。保留前一时间戳的 BEV 特征在后面使用,这个在线推理策略节约了大量时间。

从下图可看出,BEVFormer 能够检测出高度遮挡的目标。

#3. 有什么优点?
在 nuScenes test 数据集上,取得了 56.9 % 56.9\% 56.9%的 NDS,与基于 LiDAR 的方法相近。BEVFormer 能够显著提高速度的预测准确率和低可见度情况下的目标召回率。
相关文章:
BEVFormer 论文学习
1. 解决了什么问题? 3D 视觉感知任务,包括基于多相机图像的 3D 目标检测和分割,对于自动驾驶系统非常重要。与基于 LiDAR 的方法相比,基于相机图像的方法能够检测到更远距离的目标,识别交通信号灯、交通标识等信息。有…...

现在的00后,实在是太卷了,我们这些老油条都想辞职了......
现在的小年轻真的卷得过分了。前段时间我们公司来了个00年的,工作没两年,跳槽到我们公司起薪20K,都快要超过我了。 后来才知道人家是个卷王,从早干到晚就差搬张床到工位睡觉了。 最近和他聊了一次天,原来这位小老弟家…...

shell 数组定义与使用
一维数组 数组定义 array_name(value1 value2 ... value)也可以使用数字下表来定义数组 array_name[0]value0 array_name[1]value1 array_name[2]value2读取数组 ${array_name[index]}实例1 [rootiZj6c3slqbp8xuu2w3i4roZ devops]# cat array_name.sh #!/usr/bin/bashmy_…...

24 KVM管理虚拟机-配置VNC-TLS登录
文章目录 24 KVM管理虚拟机-配置VNC-TLS登录24.1 概述24.2 操作步骤 24 KVM管理虚拟机-配置VNC-TLS登录 24.1 概述 VNC服务端和客户端默认采用明文方式进行数据传输,因此通信内容可能被第三方截获。为了提升安全性,openEuler支持VNC服务端配置TLS模式进…...
)
C++基础讲解第六期(多态、虚函数、虚析构函数、dynamic_cast、typeid纯虚函数)
C基础讲解第六期 代码中也有对应知识注释,别忘看,一起学习! 一、多态1. 问题引出2. 多态的概念和使用3. 多态的原理4. 虚析构函数5. 动态类型识别(dynamic_cast)(1) 自定义类型(2). dynamic_cast(3). typeid 6. 纯虚函数 纯虚函数需要补充 一…...

防火墙之iptables(二)
防火墙之iptables(二) 一.SNAT原理与应用 1.应用环境 局域网主机共享单个公网IP地址接入Internet(私网不能被Internet中正常路由)2.SNAT原理 修改数据包的源地址内网访问外网 将从内网发送到外网的数据包的源IP由私网IP转换成…...

亚马逊销量暴跌该如何查找原因?
很多卖家经常遇到一个棘手的问题,就是突然会遇到链接销量暴跌的问题。 比如之前链接可以稳定出单10多单的,突然连续几天只有两三单,这到底是什么原因呢? 1.查看链接的类目是否被修改 这个类目修改不一定是卖家自己修改,更多的时…...

Vue中的脚手架和路由
私人博客 许小墨のBlog —— 菜鸡博客直通车 系列文章完整版,配图更多,CSDN博文图片需要手动上传,因此文章配图较少,看不懂的可以去菜鸡博客参考一下配图! 系列文章目录 前端系列文章——传送门 后端系列文章——传送…...
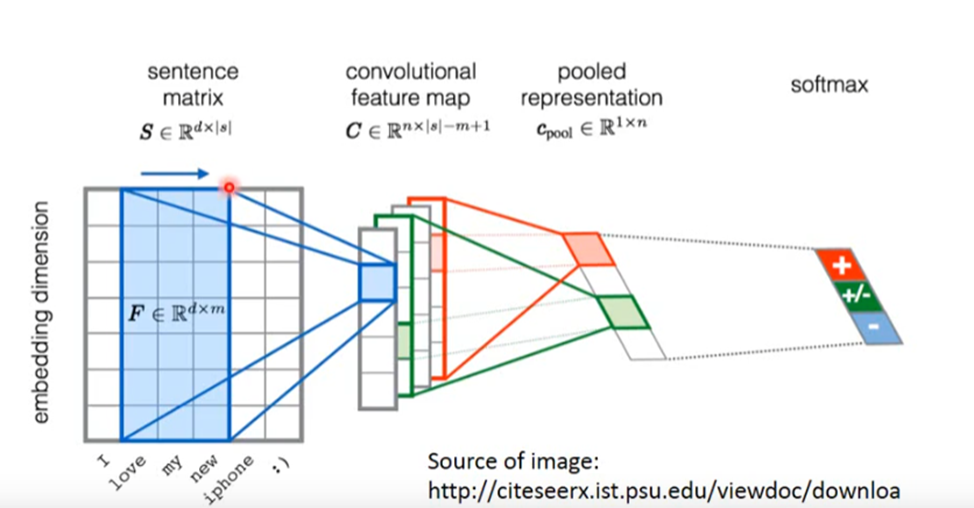
Convolutional Neural network(卷积神经网络)
目录 Why CNN for Image? The whole CNN structure Convolution(卷积) Max Pooling Flatten CNN in Keras What does CNN learn? what does filter do what does neuron do what about output Deep Dream Application Pla…...

【资料分享】高边、低边晶体管开关及电路解析
高边和低边晶体管开关 电路中,晶体管常常被用来当做开关使用。晶体管用作开关时有两种不同的接线方式:高边(high side)和低边(low side)。 高边和低边是由晶体管在电路中的位置决定的。晶体管可以是双极性晶体管(BJT…...

六级备考28天|CET-6|听力第二讲|长对话满分技巧|听写技巧|2022年6月考题|14:30~16:00
目录 1. 听力策略 2. 第一二讲笔记 3. 听力原文复现 (5)第五小题 (6)第六小题 (7)第七小题 (8)第八小题 扩展业务 expand business 4. 重点词汇 1. 听力策略 2. 第一二讲笔记 3. 听力原文复现 (5)第五小题 our guest is Molly Sundas, a university stud…...

计算机图形学 | 实验九:纹理贴图和天空盒
计算机图形学 | 实验九:纹理贴图和天空盒 计算机图形学 | 实验九:纹理贴图和天空盒实验概述顶点数据立方体顶点数据天空盒顶点数组 纹理载入创建纹理纹理读取纹理绑定 使用纹理立方体着色器顶点着色器片元着色器 天空盒着色器顶点着色器片元着色器 立方体…...

Unity A* Pathfinding Project
先下载免费版 https://arongranberg.com/astar/download# 教程首页 https://arongranberg.com/astar/docs/getstarted.html 创建一个plane 当地面 创建一个gameobject 添加组件 PathFinder 长这样 调整每个格子大小的 创建两个layer 一个是阻挡物的 一个是地面的 这里填入阻…...

SpringBoot ( 一 ) 搭建项目环境
1.搭建环境 1.1.创建项目向导 使用idea中的向导创建SpringBoot项目 1.1.1.建立新的项目 位置 : 菜单 > File > New > Project… 1.1.2.选择向导 默认的向导URL 是 https://start.spring.io 建议使用 https://start.aliyun.com 1.1.3.配置项目信息 Group : 组织…...

idea中关联Git
注意:未安装和配置Git软件,请先跳转到 Git宝典_没办法,我就是这么菜的博客-CSDN博客 idea关联git 关联git.exe 选择你的Version Control 下的Git 选择你的Git安装目录bin下的git.exe,点击ok 点击Test,显示版本号…...
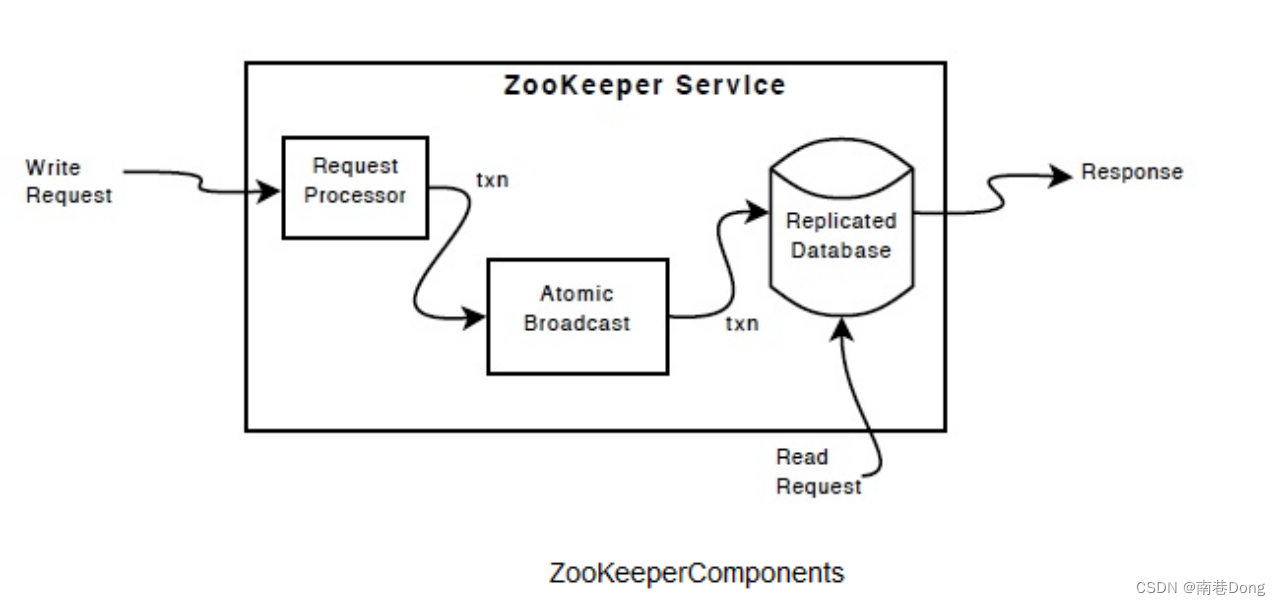
Java面试知识点(全)-分布式微服务-zookeeper面试知识点
Java面试知识点(全) 导航: https://nanxiang.blog.csdn.net/article/details/130640392 注:随时更新 ZooKeeper是什么? ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现&…...
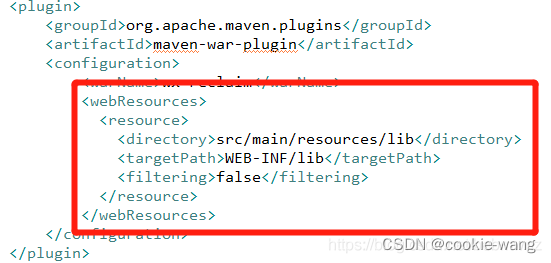
(IDEA)springCloud项目导入本地jar包方法和项目打包时找不到引入本地jar包的问题解决方案
idea导入本地jar包 方法一:点击左上角File–>Project Structure–>Modules。打开Modules界面点击下方号,选择第一项,找到想要导入的本地jar包。此方法可以使项目使用导入的jar包程序不报错,但是在打包项目时,会出现找不到程…...

非线性系统的线性化与泰勒级数
线性系统与非线性系统的区别 我们在读论文的时候经常会遇到这两个系统,线性系统与非线性系统,这两者之间有什么区别呢? 线性指量与量之间按比例、成直线的关系,在空间和时间上代表规则和光滑的运动;非线性则指不按比…...
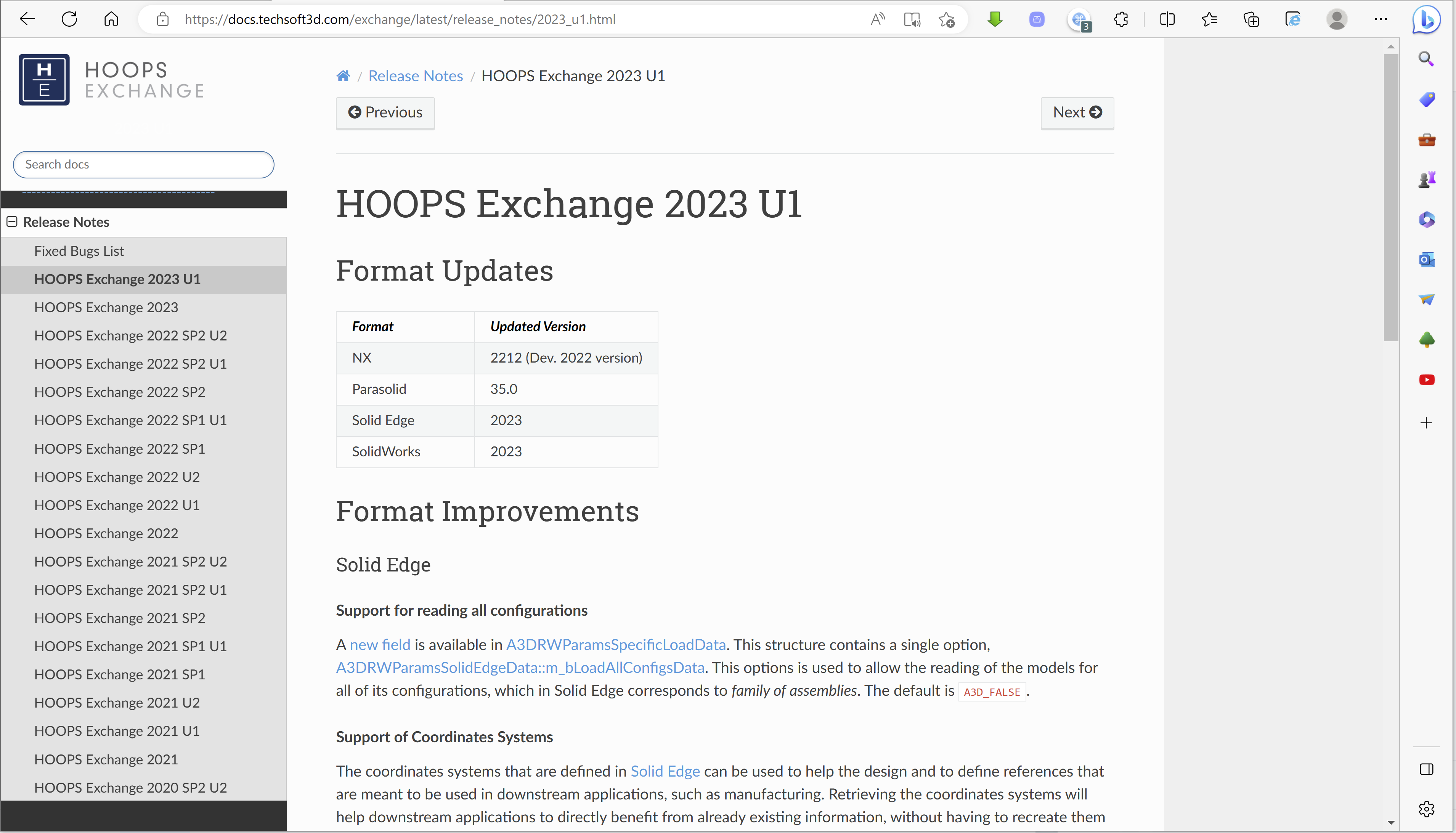
HOOPS全新文档系统上线!三维模型文件转换更便捷!
HOOPS 2023 U1版本已经正式发布,伴随新版本上线的还有全新的文档系统,新的文档系统亮点包括: 改进了样式和布局,使导航更加简单快捷;修订了导航结构,提高了产品相关信息的清晰度;SDK API参考章…...

第三篇:强化学习发展历史
你好,我是zhenguo(郭震) 这是强化学习第三篇,我们回顾一下它的发展历史:强化学习发展历史 强化学习作为一门研究领域,经历了多年的发展和演进。以下是强化学习的主要发展历史里程碑: 1950年代-1…...

Taurus多执行器对比实战:JMeter/Gatling/Locust统一压测方案
1. 为什么选Taurus做多执行器对比——不是为了炫技,而是为了少踩坑在性能测试领域,我见过太多团队卡在“选型”这一步:刚招来一个会写JMeter脚本的工程师,项目突然要压测WebSocket接口,发现JMeter原生支持弱、插件维护…...
到底在‘看’什么?)
从社交关系到分子结构:图解GCN(图卷积网络)到底在‘看’什么?
从社交关系到分子结构:图解GCN(图卷积网络)到底在‘看’什么?想象一下,你刚搬到一个新社区,想快速了解周围的邻居。最直接的方式是什么?不是挨家挨户敲门,而是通过社区活动认识几位关…...

[智能体-69]:重新认知MCP:协议不生产智能,只是AI全域交互的标准化基石
MCP只是提供了大模型、编排调度、外部工具能够进行结构化交流的标准,而整个系统的智能主要依赖编排调度,与外部软件系统的交互取决于外部工具,包括外部语音交互、视觉交互、数字化交互。当下MCP(Model Context Protocol࿰…...

Python基础语法:常用内置函数
round():四舍五入 # 省略 ndigits print(round(3.14)) # 输出 3(int) print(round(3.66)) # 输出 4# 指定 ndigits print(round(3.14159, 2)) # 输出 3.14(float) print(round(3.666, 2)) # 输出 3.67# …...

Owl-Alpha 新手快速上手指南
在处理大规模数据或构建高性能应用时,我们常常会遇到一个棘手的问题:如何在不阻塞主线程的情况下,高效地执行耗时任务?无论是处理图像、解析大型文件,还是进行复杂的数学运算,传统的单线程模式往往会让界面…...

随机森林算法在儿童出行方式预测中的实战应用与优化
1. 项目概述:用随机森林预测孩子怎么上学做城市交通规划或者做家长接送方案的时候,你肯定想过一个问题:孩子们到底是怎么上学的?是走路、骑车、坐公交还是家长开车送?这个问题看似简单,背后却牵扯到城市规划…...

开源ELM327 OBD-II适配器:从硬件设计到多协议固件实现全解析
1. 项目概述:开源ELM327 OBD适配器如果你对汽车诊断、数据监控或者嵌入式开发感兴趣,那么自己动手做一个OBD-II适配器绝对是个能让你学到很多东西的硬核项目。今天要聊的,就是一个完全开源的、基于NXP LPC1517微控制器的ELM327兼容OBD适配器。…...

特定任务需求场景下的过约束并联机构构型设计与控制方法【附代码】
✨ 长期致力于曲面加工、构型综合、运动学和动力学建模、性能评价、多目标优化、滑模控制、鲁棒控制、视觉传感技术研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (…...

通用物联网开发板设计:基于ESP8266的硬件集成与开发实践
1. 项目概述:为什么我们需要一块“通用”的物联网开发板?在捣鼓了几年物联网项目之后,我发现自己桌面上堆满了各种开发板:ESP8266、ESP32、Arduino Uno、STM32 Nucleo……每个项目都要重新连线、配置电源、焊接传感器接口…...
3分钟搞定专业短视频!Pixelle-Video终极AI创作指南
3分钟搞定专业短视频!Pixelle-Video终极AI创作指南 【免费下载链接】Pixelle-Video 🚀 AI 全自动短视频引擎 | AI Fully Automated Short Video Engine 项目地址: https://gitcode.com/GitHub_Trending/pi/Pixelle-Video 还在为视频制作发愁吗&am…...