pytorch rpc如何实现分物理机器的model parallel
因为业务需要,最近接到一项任务,是如何利用pytorch实现model parallel以及distributed training。搜罗了网上很多资料,以及阅读了pytorch官方的教程,都没有可参考的案例。讲的比较多的是data parallel,关于model parallel的研究发现不多。
通过阅读pytorch官方主页,发现这个example是进行model parallel的,
官方博客地址:DISTRIBUTED PIPELINE PARALLELISM USING RPC
官方的example地址:Distributed Pipeline Parallel Example
通过阅读代码发现,这个代码以Resnet 50 model为例,将model直接拆分成两部分,并指定两部分在不同的worker运行,代码实现了在同一台机器上,创建多进程来拆分模型运行。关于这个代码的详细介绍可搜索关键词:pytorch RPC 的分布式管道并行,这里不多介绍。
通过在本地运行代码发现,不满足多机器运行的需求。接下来是思考的心路里程。
- 首先通过代码发现,python main.py程序运行时,无法指定rank,那么在跨机器运行时如何知道哪台机器是worker1,worker2?这个地方,我们首先怀疑需要去修改worker,人为在代码中指定worker的IP地址,如修改main.py 代码中191行
修改前:
model = DistResNet50(split_size, ["worker1", "worker2"])
修改后:
model = DistResNet50(split_size, ["worker1@xxx.xxx.xxx.xxx", "worker2@xxx.xxx.xxx.xxx"])
然后,很自然的就报错了,这里无法识别这样的worker名,不支持直接指定,这条路也就走不通了。 - 接着只能重新阅读代码,到最后251行,我们发现
mp.spawn(run_worker, args=(world_size, num_split), nprocs=world_size, join=True)
尤其是这行代码中mp.spawn引起了我们的怀疑,这不是多进程么,这本质还是在多进程情况下来执行程序,无法跨机器啊,不符合我们的需求。 - 最后的最后,我们重新阅读pytorch rpc机制,并通过简单测试程序,让两台机器互相通信,其中一台机器发起运算请求并传输原始数据,另外一台机器负责接收数据并进行相关运算,这个程序当时在两台物理机器上测试成功了,那说明rpc实现通信这件事并不复杂。结合前面给的代码,我们决定将worke1和worker2分开写代码,分开执行,并且在代码中需要指定这些worker所属的rank,这样理论上就能够将原始代码修改成分机器的rpc通信运行了。
上面主要是我们的心理历程,话不多说,接下来show the code。
实验环境,两台机器,均是cpu环境,conda安装的环境也保证了一致。
master机器代码:
# https://github.com/pytorch/examples/blob/main/distributed/rpc/pipeline/main.pyimport os
import threading
import time
import torch
import torch.nn as nn
import torch.distributed.autograd as dist_autograd
import torch.distributed.rpc as rpc
import torch.optim as optim
from torch.distributed.optim import DistributedOptimizer
from torch.distributed.rpc import RReffrom torchvision.models.resnet import Bottleneck
os.environ['MASTER_ADDR'] = 'XXX.XXX.XXX.XXX' # 指定master ip地址
os.environ['MASTER_PORT'] = '7856' # 指定master 端口号#########################################################
# Define Model Parallel ResNet50 #
########################################################## In order to split the ResNet50 and place it on two different workers, we
# implement it in two model shards. The ResNetBase class defines common
# attributes and methods shared by two shards. ResNetShard1 and ResNetShard2
# contain two partitions of the model layers respectively.num_classes = 1000def conv1x1(in_planes, out_planes, stride=1):"""1x1 convolution"""return nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=stride, bias=False)class ResNetBase(nn.Module):def __init__(self, block, inplanes, num_classes=1000,groups=1, width_per_group=64, norm_layer=None):super(ResNetBase, self).__init__()self._lock = threading.Lock()self._block = blockself._norm_layer = nn.BatchNorm2dself.inplanes = inplanesself.dilation = 1self.groups = groupsself.base_width = width_per_groupdef _make_layer(self, planes, blocks, stride=1):norm_layer = self._norm_layerdownsample = Noneprevious_dilation = self.dilationif stride != 1 or self.inplanes != planes * self._block.expansion:downsample = nn.Sequential(conv1x1(self.inplanes, planes * self._block.expansion, stride),norm_layer(planes * self._block.expansion),)layers = []layers.append(self._block(self.inplanes, planes, stride, downsample, self.groups,self.base_width, previous_dilation, norm_layer))self.inplanes = planes * self._block.expansionfor _ in range(1, blocks):layers.append(self._block(self.inplanes, planes, groups=self.groups,base_width=self.base_width, dilation=self.dilation,norm_layer=norm_layer))return nn.Sequential(*layers)def parameter_rrefs(self):r"""Create one RRef for each parameter in the given local module, and return alist of RRefs."""return [RRef(p) for p in self.parameters()]class ResNetShard1(ResNetBase):"""The first part of ResNet."""def __init__(self, device, *args, **kwargs):super(ResNetShard1, self).__init__(Bottleneck, 64, num_classes=num_classes, *args, **kwargs)self.device = deviceself.seq = nn.Sequential(nn.Conv2d(3, self.inplanes, kernel_size=7, stride=2, padding=3, bias=False),self._norm_layer(self.inplanes),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=3, stride=2, padding=1),self._make_layer(64, 3),self._make_layer(128, 4, stride=2)).to(self.device)for m in self.modules():if isinstance(m, nn.Conv2d):nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')elif isinstance(m, nn.BatchNorm2d):nn.init.ones_(m.weight)nn.init.zeros_(m.bias)def forward(self, x_rref):x = x_rref.to_here().to(self.device)with self._lock:out = self.seq(x)return out.cpu()class ResNetShard2(ResNetBase):"""The second part of ResNet."""def __init__(self, device, *args, **kwargs):super(ResNetShard2, self).__init__(Bottleneck, 512, num_classes=num_classes, *args, **kwargs)self.device = deviceself.seq = nn.Sequential(self._make_layer(256, 6, stride=2),self._make_layer(512, 3, stride=2),nn.AdaptiveAvgPool2d((1, 1)),).to(self.device)self.fc = nn.Linear(512 * self._block.expansion, num_classes).to(self.device)def forward(self, x_rref):x = x_rref.to_here().to(self.device)with self._lock:out = self.fc(torch.flatten(self.seq(x), 1))return out.cpu()class DistResNet50(nn.Module):"""Assemble two parts as an nn.Module and define pipelining logic"""def __init__(self, split_size, workers, *args, **kwargs):super(DistResNet50, self).__init__()self.split_size = split_size# Put the first part of the ResNet50 on workers[0]self.p1_rref = rpc.remote(workers[0],ResNetShard1,args = ("cuda:0",) + args,kwargs = kwargs)# Put the second part of the ResNet50 on workers[1]self.p2_rref = rpc.remote(workers[1],ResNetShard2,args = ("cpu",) + args,kwargs = kwargs)def forward(self, xs):# Split the input batch xs into micro-batches, and collect async RPC# futures into a listout_futures = []for x in iter(xs.split(self.split_size, dim=0)):x_rref = RRef(x)y_rref = self.p1_rref.remote().forward(x_rref)print(y_rref)z_fut = self.p2_rref.rpc_async().forward(y_rref)print(z_fut)out_futures.append(z_fut)# collect and cat all output tensors into one tensor.return torch.cat(torch.futures.wait_all(out_futures))def parameter_rrefs(self):remote_params = []remote_params.extend(self.p1_rref.remote().parameter_rrefs().to_here())remote_params.extend(self.p2_rref.remote().parameter_rrefs().to_here())return remote_params#########################################################
# Run RPC Processes #
#########################################################num_batches = 3
batch_size = 8
image_w = 128
image_h = 128if __name__=="__main__":options = rpc.TensorPipeRpcBackendOptions(num_worker_threads=256, rpc_timeout=300)# 初始化主节点的RPC连接rpc.init_rpc("master", rank=0, world_size=2, rpc_backend_options=options)for num_split in [1,2]:tik = time.time()model = DistResNet50(num_split, ["master", "worker"])loss_fn = nn.MSELoss()opt = DistributedOptimizer(optim.SGD,model.parameter_rrefs(),lr=0.05,)one_hot_indices = torch.LongTensor(batch_size) \.random_(0, num_classes) \.view(batch_size, 1)for i in range(num_batches):print(f"Processing batch {i}")# generate random inputs and labelsinputs = torch.randn(batch_size, 3, image_w, image_h)labels = torch.zeros(batch_size, num_classes) \.scatter_(1, one_hot_indices, 1)with dist_autograd.context() as context_id:outputs = model(inputs)dist_autograd.backward(context_id, [loss_fn(outputs, labels)])opt.step(context_id)tok = time.time()print(f"number of splits = {num_split}, execution time = {tok - tik}")# 关闭RPC连接rpc.shutdown()worker端的代码
# https://github.com/pytorch/examples/blob/main/distributed/rpc/pipeline/main.pyimport os
import threading
import time
from functools import wrapsimport torch
import torch.nn as nn
import torch.distributed.rpc as rpc
from torch.distributed.rpc import RReffrom torchvision.models.resnet import Bottleneck
os.environ['MASTER_ADDR'] = 'XXX.XXX.XXX.XXX' # 指定master 端口号
os.environ['MASTER_PORT'] = '7856' # 指定master 端口号#########################################################
# Define Model Parallel ResNet50 #
########################################################## In order to split the ResNet50 and place it on two different workers, we
# implement it in two model shards. The ResNetBase class defines common
# attributes and methods shared by two shards. ResNetShard1 and ResNetShard2
# contain two partitions of the model layers respectively.num_classes = 1000def conv1x1(in_planes, out_planes, stride=1):"""1x1 convolution"""return nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=stride, bias=False)class ResNetBase(nn.Module):def __init__(self, block, inplanes, num_classes=1000,groups=1, width_per_group=64, norm_layer=None):super(ResNetBase, self).__init__()self._lock = threading.Lock()self._block = blockself._norm_layer = nn.BatchNorm2dself.inplanes = inplanesself.dilation = 1self.groups = groupsself.base_width = width_per_groupdef _make_layer(self, planes, blocks, stride=1):norm_layer = self._norm_layerdownsample = Noneprevious_dilation = self.dilationif stride != 1 or self.inplanes != planes * self._block.expansion:downsample = nn.Sequential(conv1x1(self.inplanes, planes * self._block.expansion, stride),norm_layer(planes * self._block.expansion),)layers = []layers.append(self._block(self.inplanes, planes, stride, downsample, self.groups,self.base_width, previous_dilation, norm_layer))self.inplanes = planes * self._block.expansionfor _ in range(1, blocks):layers.append(self._block(self.inplanes, planes, groups=self.groups,base_width=self.base_width, dilation=self.dilation,norm_layer=norm_layer))return nn.Sequential(*layers)def parameter_rrefs(self):r"""Create one RRef for each parameter in the given local module, and return alist of RRefs."""return [RRef(p) for p in self.parameters()]class ResNetShard2(ResNetBase):"""The second part of ResNet."""def __init__(self, device, *args, **kwargs):super(ResNetShard2, self).__init__(Bottleneck, 512, num_classes=num_classes, *args, **kwargs)self.device = deviceself.seq = nn.Sequential(self._make_layer(256, 6, stride=2),self._make_layer(512, 3, stride=2),nn.AdaptiveAvgPool2d((1, 1)),).to(self.device)self.fc = nn.Linear(512 * self._block.expansion, num_classes).to(self.device)def forward(self, x_rref):x = x_rref.to_here().to(self.device)print(x)with self._lock:out = self.fc(torch.flatten(self.seq(x), 1))return out.cpu()#########################################################
# Run RPC Processes #
#########################################################if __name__=="__main__":options = rpc.TensorPipeRpcBackendOptions(num_worker_threads=256, rpc_timeout=300)# 初始化工作节点的RPC连接rpc.init_rpc("worker", rank=1, world_size=2, rpc_backend_options=options)# 等待主节点的调用rpc.shutdown()代码中的MASTER_ADDR和port需要指定为一致,分别在master机器上运行master.py,worker机器上运行worker.py,这样就可以实现Resnet 50 model在两台物理机器上model parallel。
注意事项
- 确保物理机器能够互相ping通,同时关闭防火墙
- 两个物理机器最好都是linux环境,我们的实验发现pytorch的分布式不支持在Windows环境运行
- 两个物理机器的python运行环境要求保持一致
相关文章:

pytorch rpc如何实现分物理机器的model parallel
因为业务需要,最近接到一项任务,是如何利用pytorch实现model parallel以及distributed training。搜罗了网上很多资料,以及阅读了pytorch官方的教程,都没有可参考的案例。讲的比较多的是data parallel,关于model paral…...
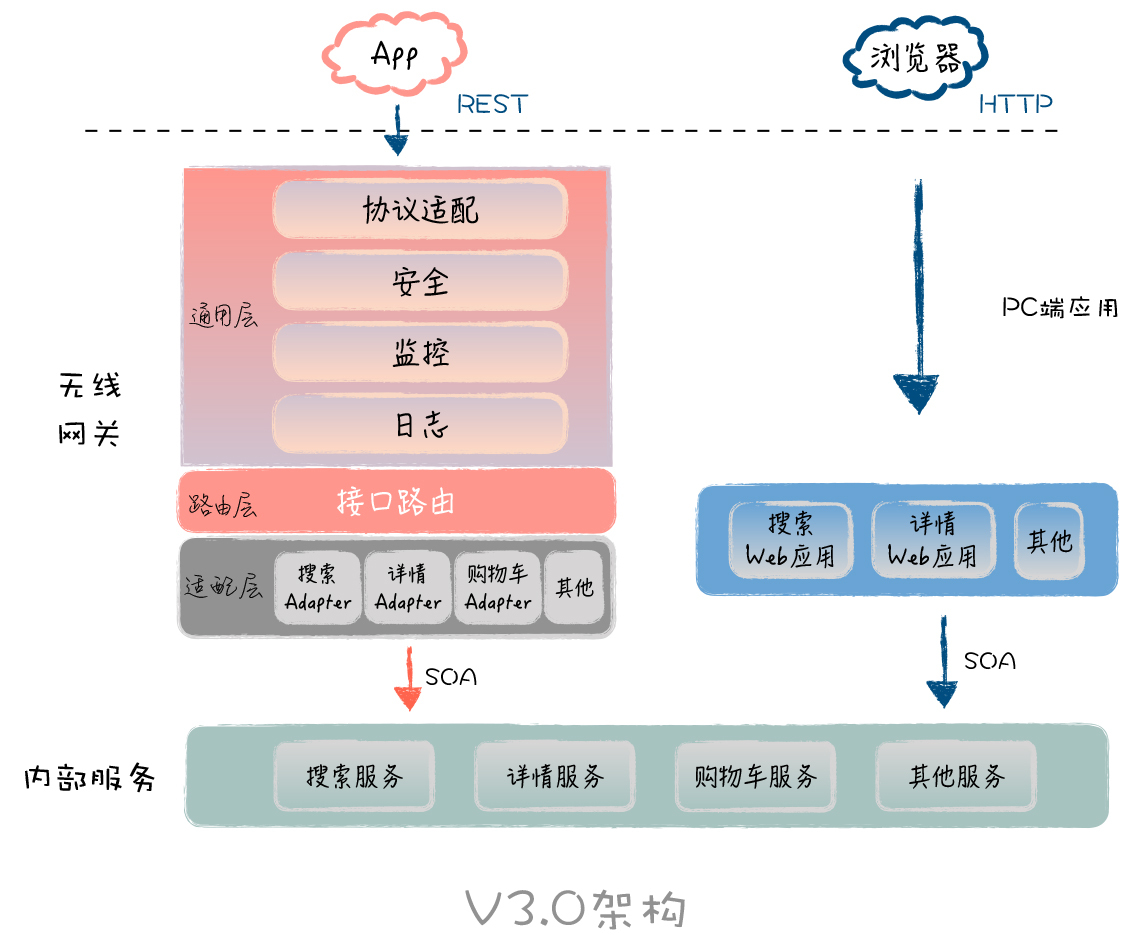
APP服务端架构的演变
大家好,我是易安! 早期2013年的时候,随着智能设备的普及和移动互联网的发展,移动端逐渐成为用户的新入口,各个电商平台都开始聚焦移动端App,如今经历了10年的发展,很多电商APP早已经没入历史的洪…...
EasyRecovery16适用于Windows和Mac的专业硬盘恢复软件
无论你对数据恢复了解多少, 我们将为您处理所有复杂的流程并简化恢复!适用于Windows和Mac的 专业硬盘恢复软件 硬盘数据无法保证绝对安全。有时会发生数据丢失,需要使用硬盘恢复工具。支持恢复不同存储介质数据:硬盘、光盘、U盘/移动硬盘、数…...

详解Jetpack Compose中的状态管理与使用
前言 引用一段官方描述,如下 由于 Compose 是声明式工具集,因此更新它的唯一方法是通过新参数调用同一可组合项。这些参数是界面状态的表现形式。每当状态更新时,都会发生重组。因此,TextField 不会像在基于 XML 的命令式视图中那…...

改进YOLOv7 | 头部解耦 | 将YOLOX解耦头添加到YOLOv7 | 涨点杀器
改进YOLOv7 | 头部解耦 | 将YOLOX解耦头添加到YOLOv7 论文地址:https://arxiv.org/abs/2107.08430 文章目录 改进YOLOv7 | 头部解耦 | 将YOLOX解耦头添加到YOLOv71. 解耦头原理2. 解耦头对收敛速度的影响3. 解耦头对精度的影响4. 代码改进方式第一步第二步第三步第四步第五步参…...

第七章 中断
中断是什么,为什么要有中断 并发是指单位时间内的累积工作量。 并行是指真正同时进行的工作量。 一个CPU在一个时间只能执行一个进程,任何瞬间任务只在一个核心上运行。 而CPU外的设备是独立于CPU的,它与CPU同步运行,CPU抽出一点…...
)
1116 Come on! Let‘s C(38行代码+详细注释)
分数 20 全屏浏览题目 作者 CHEN, Yue 单位 浙江大学 "Lets C" is a popular and fun programming contest hosted by the College of Computer Science and Technology, Zhejiang University. Since the idea of the contest is for fun, the award rules are f…...
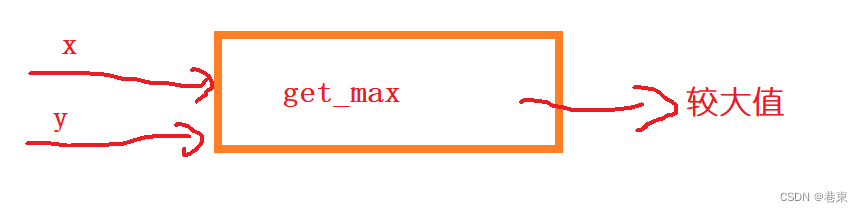
深入学习《c语言函数》
📕博主介绍:目前大一正在学习c语言,数据结构,计算机网络。 c语言学习,是为了更好的学习其他的编程语言,C语言是母体语言,是人机交互接近底层的桥梁。 本章学习函数。 让我们开启c语言学习之旅吧…...

Pytorch从零开始实现Vision Transformer (from scratch)
Pytorch从零开始实现Vision Transformer 前言一、Vision Transformer架构介绍1. Patch Embedding2. Multi-Head Attention3. Transformer BlockFeed Forward 二、预备知识1. Einsum2. Einops 三、Vision Transformer代码实现0. 导入库1. Patch Embedding2. Residual & Norm…...

ES6函数新增了哪些扩展?
目录 一、参数二、属性函数的length属性name属性 三、作用域四、严格模式五、箭头函数 一、参数 ES6允许为函数的参数设置默认值 function log(x, y World) {console.log(x, y); }console.log(Hello) // Hello World console.log(Hello, China) // Hello China console.log(…...
【firewalld防火墙】
目录 一、firewalld概述二、firewalld 与 iptables 的区别1、firewalld 区域的概念 三、firewalld防火墙默认的9个区域四、Firewalld 网络区域1、区域介绍2、firewalld数据处理流程 五、firewalld防火墙的配置方法1、使用firewall-cmd 命令行工具。2、使用firewall-config 图形…...
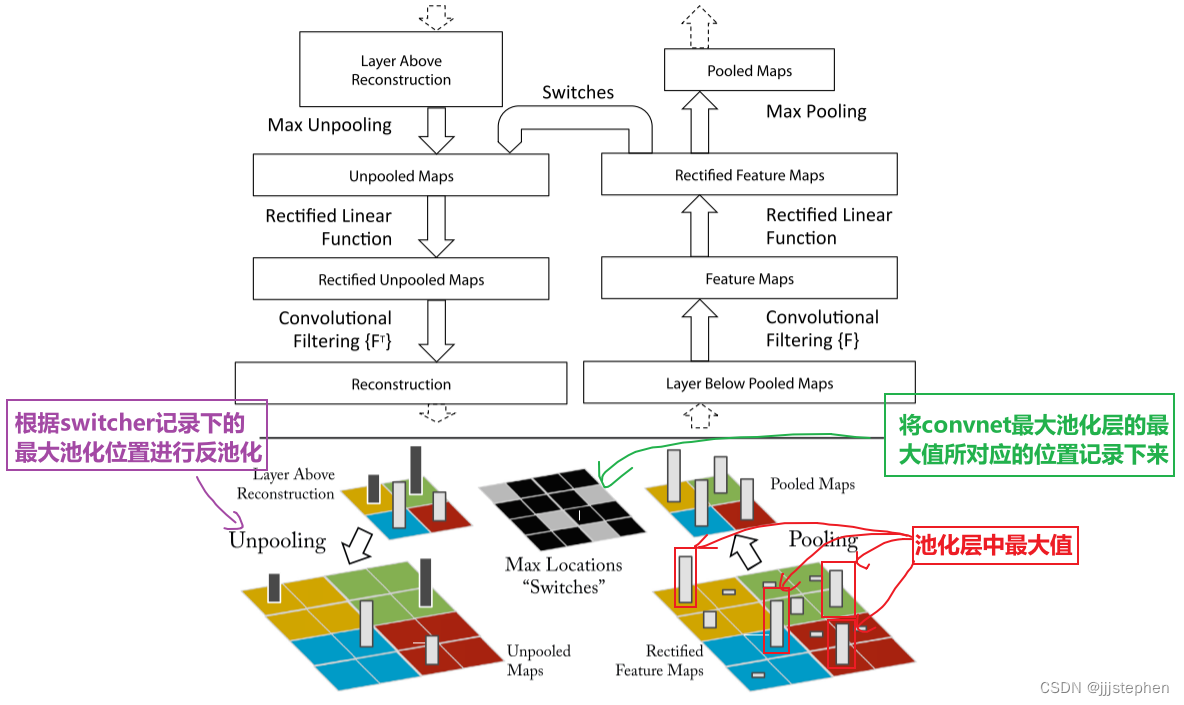
CNNs: ZFNet之CNN的可视化网络介绍
CNNs: ZFNet之CNN的可视化网络介绍 导言Deconvnet1. Unpooling2. ReLU3. Transpose conv AlexNet网络修改AlexNet Deconv网络介绍特征可视化 导言 上一个内容,我们主要学习了AlexNet网络的实现、超参数对网络结果的影响以及网络中涉及到一些其他的知识点࿰…...

云原生之深入解析Airbnb的动态Kubernetes集群扩缩容
一、前言 Airbnb 基础设施的一个重要作用是保证我们的云能够根据需求上升或下降进行自动扩缩容,我们每天的流量波动都非常大,需要依靠动态扩缩容来保证服务的正常运行。为了支持扩缩容,Airbnb 使用了 Kubernetes 编排系统,并且使…...
Django框架之模板其他补充
本篇文章是对django框架模板内容的一些补充。包含注释、html转义和csrf内容。 目录 注释 单行注释 多行注释 HTML转义 Escape Safe Autoescape CSRF 防止csrf方式 表单中使用 ajax请求添加 注释 单行注释 语法:{# 注释内容 #} 示例: {# 注…...
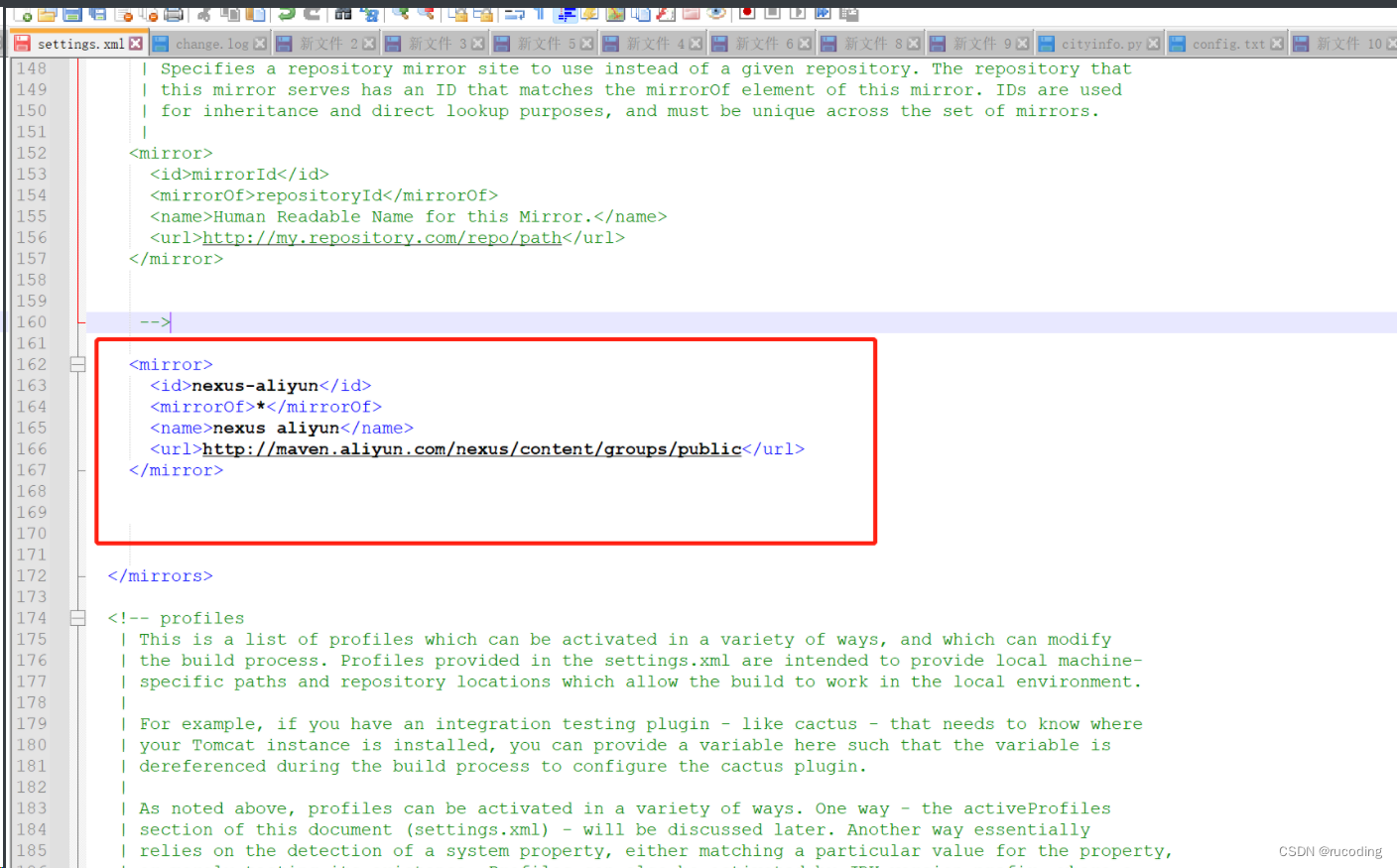
安装Maven 3.6.1:图文详细教程(适用于Windows系统)
一、官网下载对应版本 推荐使用maven3.6.1版本,对应下载链接: Maven3.6.1下载地址 或者,这里提供csdn下载地址,点击下载即可: Maven3.6.1直链下载 其他版本下载地址: 进入网址:http://mave…...

计算机图形学 | 实验八:Phong模型
计算机图形学 | 实验八:Phong模型 计算机图形学 | 实验八:Phong模型Phong模型光源设置 光照计算定向光点光源聚光 华中科技大学《计算机图形学》课程 MOOC地址:计算机图形学(HUST) 计算机图形学 | 实验八:…...

第三十一回:GestureDetector Widget
文章目录 概念介绍使用方法示例代码 我们在上一章回中介绍了ListView响应事件的内容t,本章回中将介绍 GestureDetector Widget.闲话休提,让我们一起Talk Flutter吧。 概念介绍 我们在这里介绍的GestureDetector是一个事件响应Widget,它可以响应双击事件࿰…...
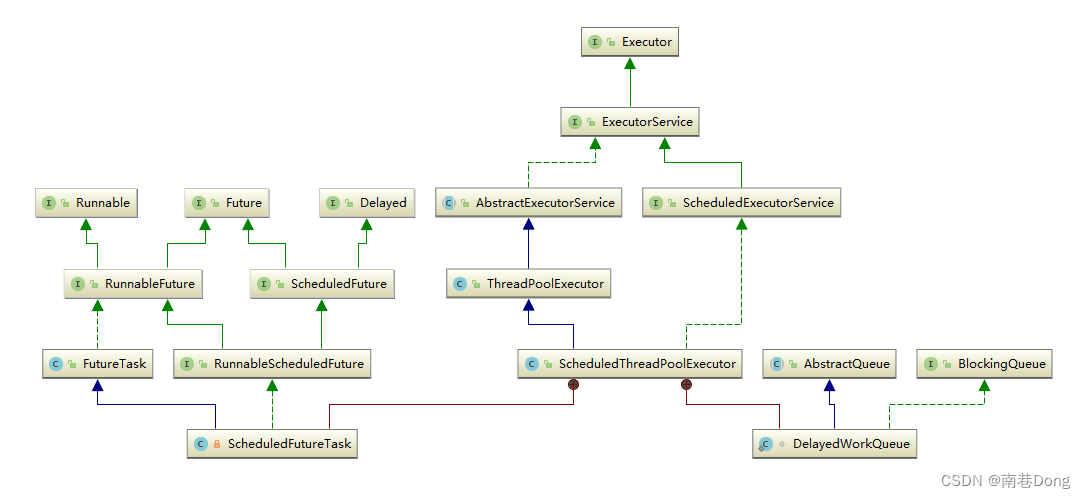
Java面试知识点(全)-Java并发-多线程JUC三- JUC集合/线程池
Java面试知识点(全) 导航: https://nanxiang.blog.csdn.net/article/details/130640392 注:随时更新 JUC集合类 为什么HashTable慢? 它的并发度是什么? 那么ConcurrentHashMap并发度是什么? Hashtable之所以效率低下主要是因为其实现使用了synchro…...

Android 如何获取有效的DeviceId
目录 前言官方唯一标识符建议使用广告 ID使用实例 ID 和 GUID不要使用 MAC 地址标识符特性常见用例和适用的标识符 解决方案DeviceIdANDROID_IDMac地址UUID补充 总结 前言 从 Android 10 开始,应用必须具有 READ_PRIVILEGED_PHONE_STATE 特许权限才能访问设备的不可…...

<SQL>《SQL命令(含例句)精心整理版(2)》
《SQL命令(含例句)精心整理版(2)》 跳转《SQL命令(含例句)精心整理版(1)8 函数8.1 文本处理函数8.2 数值处理函数8.3 时间处理函数8.3.1 时间戳转化为自定义格式from_unixtime8.3.2 …...

Taurus多执行器对比实战:JMeter/Gatling/Locust统一压测方案
1. 为什么选Taurus做多执行器对比——不是为了炫技,而是为了少踩坑在性能测试领域,我见过太多团队卡在“选型”这一步:刚招来一个会写JMeter脚本的工程师,项目突然要压测WebSocket接口,发现JMeter原生支持弱、插件维护…...

告别虚拟机卡顿:在Windows 11的WSL2里搞定Lichee Nano交叉编译环境
告别虚拟机卡顿:在Windows 11的WSL2里搞定Lichee Nano交叉编译环境 对于嵌入式开发者来说,配置开发环境往往是个令人头疼的问题。传统虚拟机方案虽然能提供完整的Linux体验,但资源占用高、启动慢、与宿主系统交互不便等问题一直困扰着开发者。…...
两两交换链表中的节点)
力扣HOT100(30)两两交换链表中的节点
链表的交换要注意 “链表不断链”。前驱和后继都要连着迭代法(必学死磕!O (n) 时间,O (1) 空间)1. 为什么必须用虚拟头节点?因为交换后链表的头节点会变! 比如示例 1 中,原来的头是 1࿰…...

Unity主题系统设计:状态驱动的主题抽象与自动注入方案
1. 这不是换个颜色那么简单:为什么Unity项目里“换肤”总在发布前夜崩盘?你有没有经历过这样的场景:美术同学凌晨两点发来一套新主题资源包,UI设计师说“这次配色更符合品牌调性”,产品说“上线前必须支持深色模式”&a…...
上午题回忆与解析(非标答版))
2026上半年数据库系统工程师(软考)上午题回忆与解析(非标答版)
本文为考后回忆整理,非官方标准答案,旨在为考后对答案及下半年备考的同学提供参考。题目顺序和表述可能与原卷有出入,欢迎在评论区指正、补充。📊 整体考情分析 刚结束的2026年上半年数据库系统工程师考试,上午题的风格…...

潮州东方轻奢风全屋高定找哪家
开篇引言根据《2026年中国全屋定制行业发展报告》,潮州市全屋定制市场规模同比增长38%,其中全屋高端定制细分市场同比增长52%。目前,潮州市家庭全屋定制需求占比72%,高端定制需求占比45%。为了帮助潮州市消费者选择合规、靠谱、差…...
:这份内部测试SOP已被3家头部科技公司紧急采购)
DeepSeek-R1补全能力封测倒计时(仅剩72小时开放API灰度权限):这份内部测试SOP已被3家头部科技公司紧急采购
更多请点击: https://intelliparadigm.com 第一章:DeepSeek-R1代码补全能力封测全景概览 DeepSeek-R1 是深度求索(DeepSeek)推出的高性能开源推理模型,在代码补全场景中展现出显著的上下文理解力与多语言泛化能力。本…...

金融合规审核为何人力堆积却仍漏洞百出?2026年RegTech演进与Agent全链路闭环解决方案
在2026年的金融监管环境下,合规审核已不再是简单的“查漏补缺”,而是演变为一场高强度的算力与逻辑博弈。尽管金融机构在合规成本上的投入逐年攀升,甚至不惜以“人海战术”填补流程断点,但监管罚单的数额与频率却并未显著下降。这…...

孤舟笔记 互联网常用框架篇二 Dubbo服务请求失败怎么处理?集群容错策略你用过几种
文章目录先说结论Failover:换家店试试Failfast:不行就算了Failsafe:忘了这事Failback:回头再说Forking:同时点几家Broadcast:通知所有人怎么选择回答技巧与点评加分回答面试官点评个人网站分布式系统中&…...

淘宝淘金币自动化脚本终极指南:如何每天节省25分钟实现智能任务管理
淘宝淘金币自动化脚本终极指南:如何每天节省25分钟实现智能任务管理 【免费下载链接】taojinbi 淘宝淘金币自动执行脚本,包含蚂蚁森林收取能量,芭芭农场全任务,解放你的双手 项目地址: https://gitcode.com/gh_mirrors/ta/taoji…...