数据分析与预处理常用的图和代码
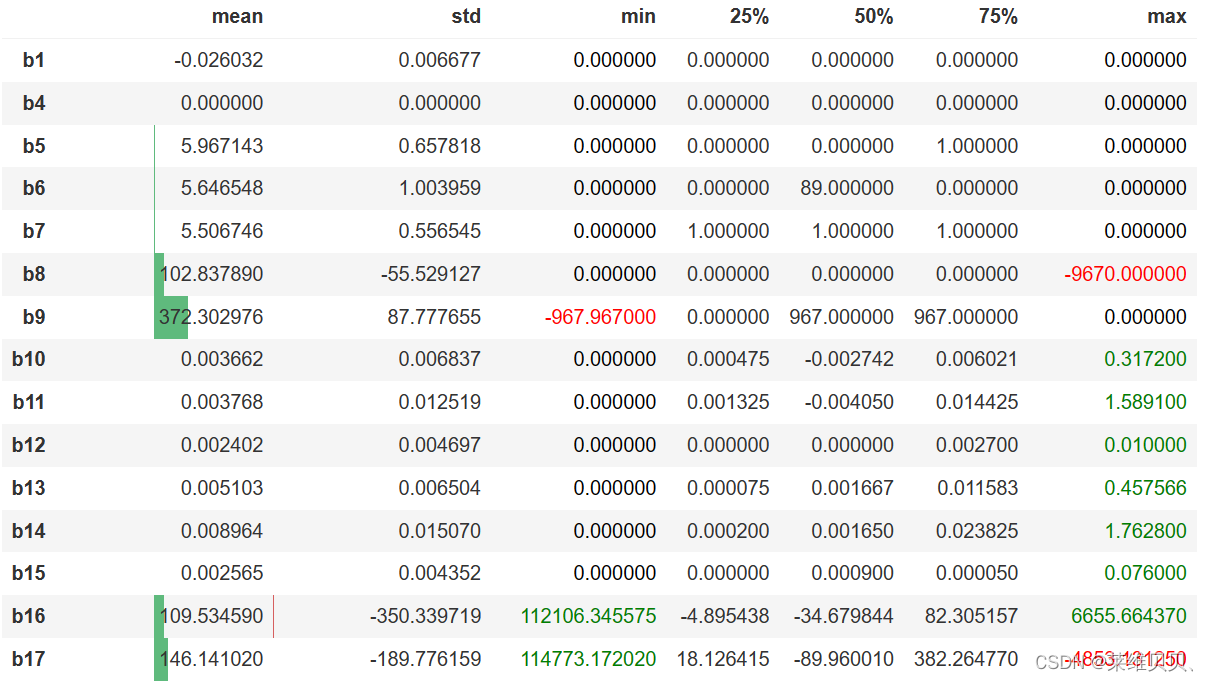
1.训练集和测试集统计数据描述之间的差异作图:
def diff_color(x):color = 'red' if x<0 else ('green' if x > 0 else 'black')return f'color: {color}'(train.describe() - test.describe())[features].T.iloc[:,1:].style\.bar(subset=['mean', 'std'], align='mid', color=['#d65f5f', '#5fba7d'])\.applymap(diff_color, subset=['min', 'max'])
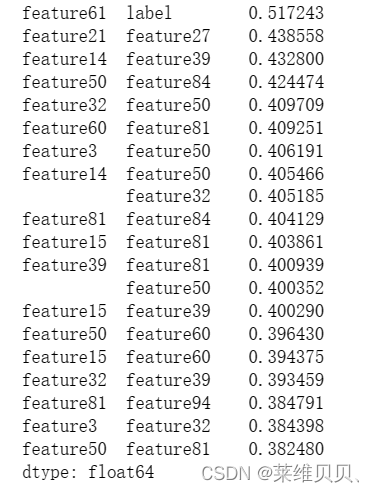
2. 特征之间的相似性排序
# 计算相关系数矩阵
corr_matrix = train_df.corr()
# 将对角线及以下部分置为 NaN
corr_matrix.where(np.triu(np.ones(corr_matrix.shape), k=1).astype(np.bool), inplace=True)
# 对相关系数矩阵进行排序
corr_sorted = corr_matrix.stack().sort_values(ascending=False)
# 打印排序后的相关系数
print(corr_sorted[:20])
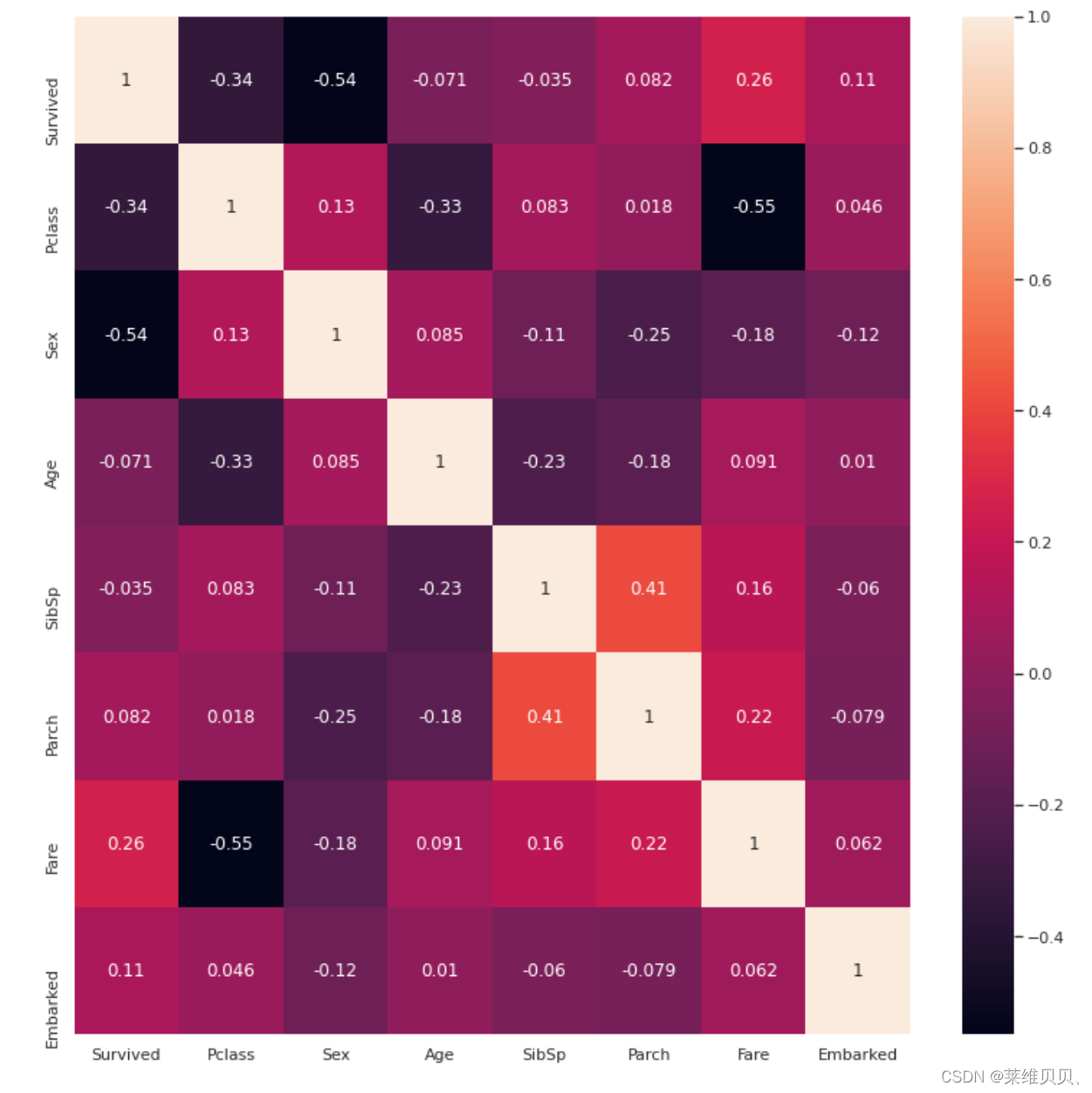
# 相似度图
sns.set(rc={'figure.figsize':(13,13)})
ax = sns.heatmap(train.corr(), annot=True)
# 筛选相似度
corr = train.corr()
sns.heatmap(corr[((corr >= 0.3) | (corr <= -0.3)) & (corr != 1)], annot=True, linewidths=.5, fmt= '.2f')
plt.title('Configured Corelation Matrix');
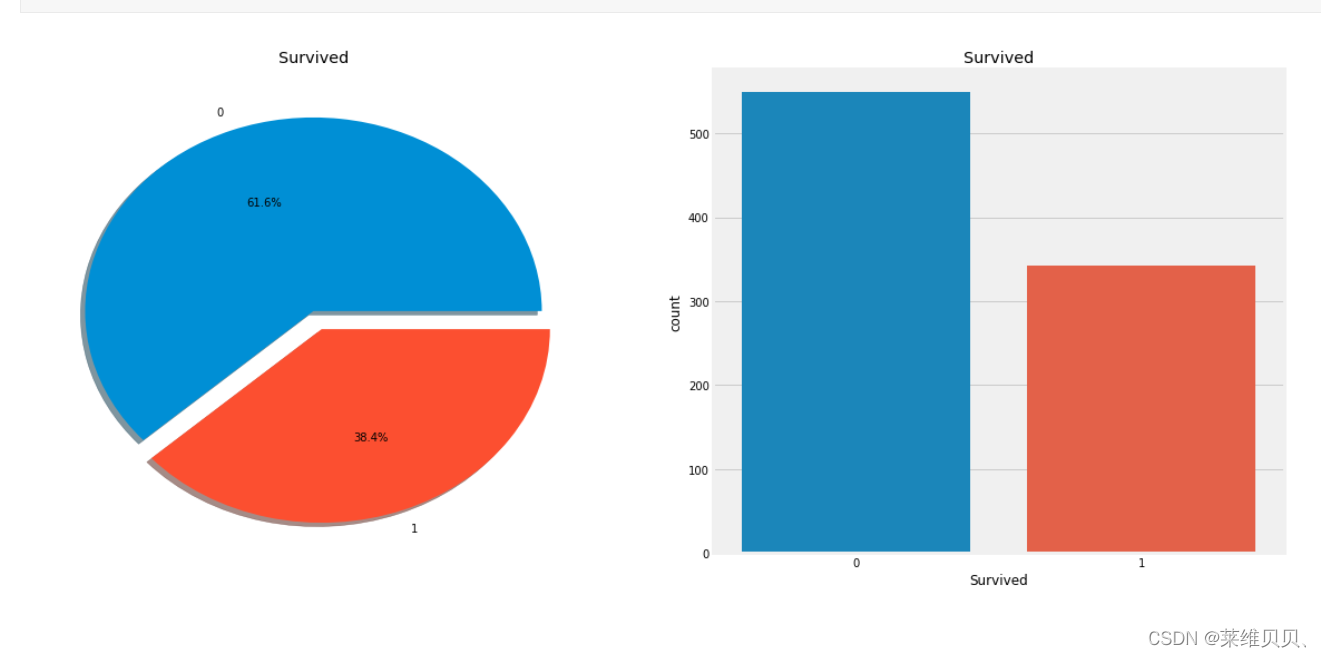
3.画标签比例图
f,ax=plt.subplots(1,2,figsize=(18,8))
data['Survived'].value_counts().plot.pie(explode=[0,0.1],autopct='%1.1f%%',ax=ax[0],shadow=True)
ax[0].set_title('Survived')
ax[0].set_ylabel('')
sns.countplot(x='Survived',data=data,ax=ax[1])
ax[1].set_title('Survived')
plt.show()
4. 查看缺失以及可视化
# 查看缺失率大于50%的特征
have_null_fea_dict = (train.isnull().sum()/len(train)).to_dict()
fea_null_moreThanHalf = {}
for key,value in have_null_fea_dict.items():if value > 0.5:fea_null_moreThanHalf[key] = value
fea_null_moreThanHalf
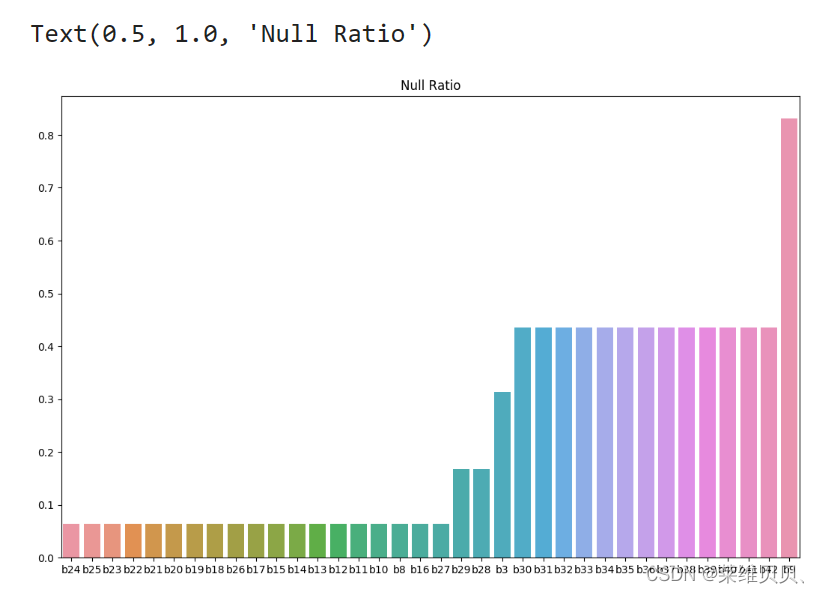
# nan可视化
f,ax = plt.subplots(1,2,figsize=(28,8),facecolor='w')# 设置画布大小,分辨率,和底色
missing = train.isnull().sum()/len(train)
missing = missing[missing > 0]
missing.sort_values(inplace=True)
missing.plot.bar(ax=ax[0])
sns.barplot(x=missing.index,y=missing.values,ax=ax[0])
ax[0].tick_params(axis='x', rotation=0)
ax[0].set_title('Null Ratio')
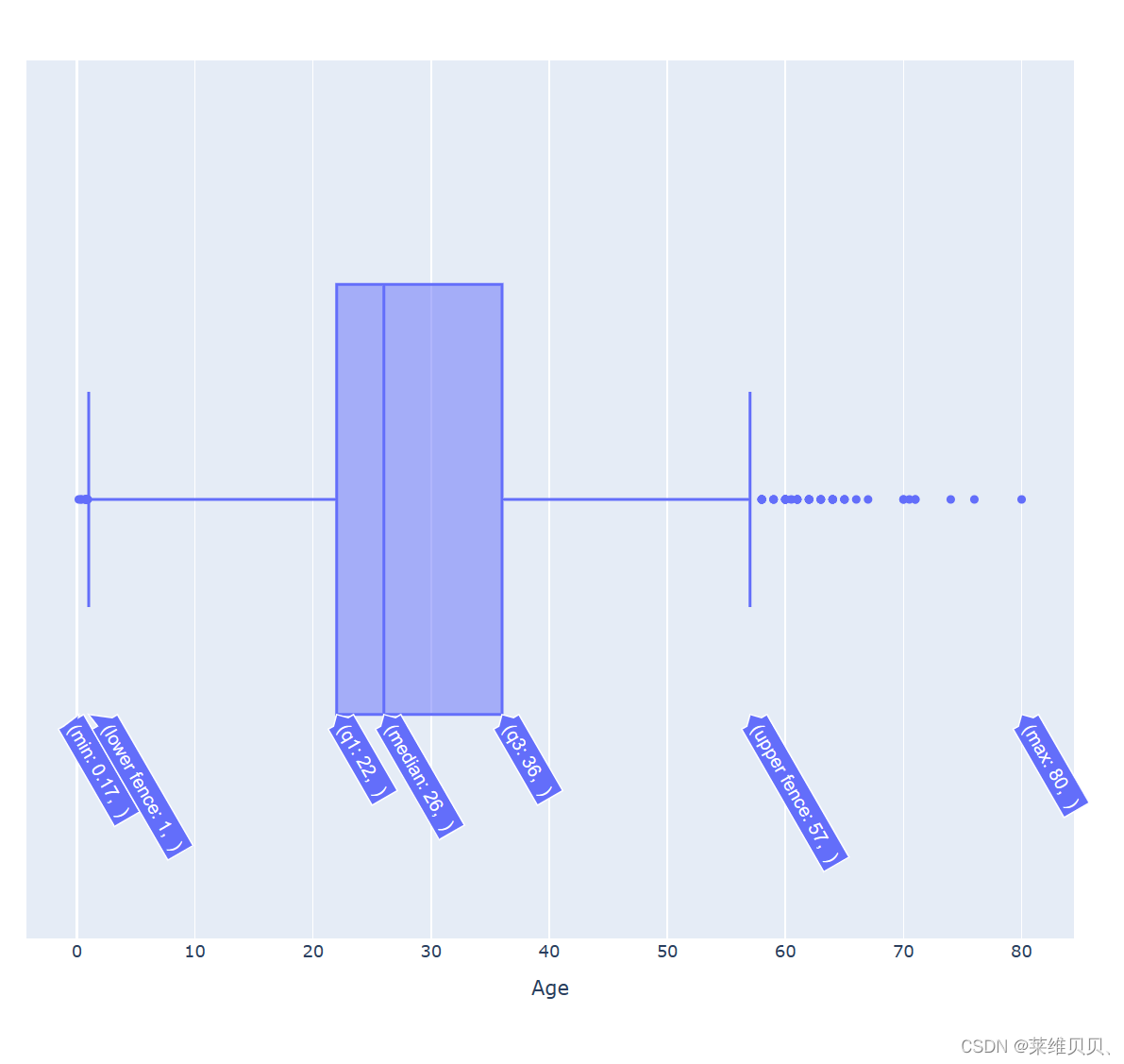
5.异常值查看以及可视化
sns.factorplot(x = "Sex", y = "Age", data = train_df, kind = "box")
plt.show()
5. 类别特征数据分析
# 教育情况
plt.rcParams['font.sans-serif'] = ['Songti SC']
f,ax=plt.subplots(1,2,figsize=(18,8))
sns.countplot(x='b3',hue='label',data=train,ax=ax[0])
ax[0].set_title('Degree:Staging vs Not Staging')
ax[0].set_xlabel("Degree")
train[['b3','label']].groupby(['b3']).mean().plot.bar(ax=ax[1])
for p in ax[1].patches:ax[1].annotate(f'\n{round(p.get_height(),2)}', (p.get_x()+0.15, p.get_height()+0.001), color='black', size=12)
ax[1].tick_params(axis='x', rotation=0)
ax[1].set_title('Staging Ratio')
ax[1].set_xlabel("Degree")
plt.show()
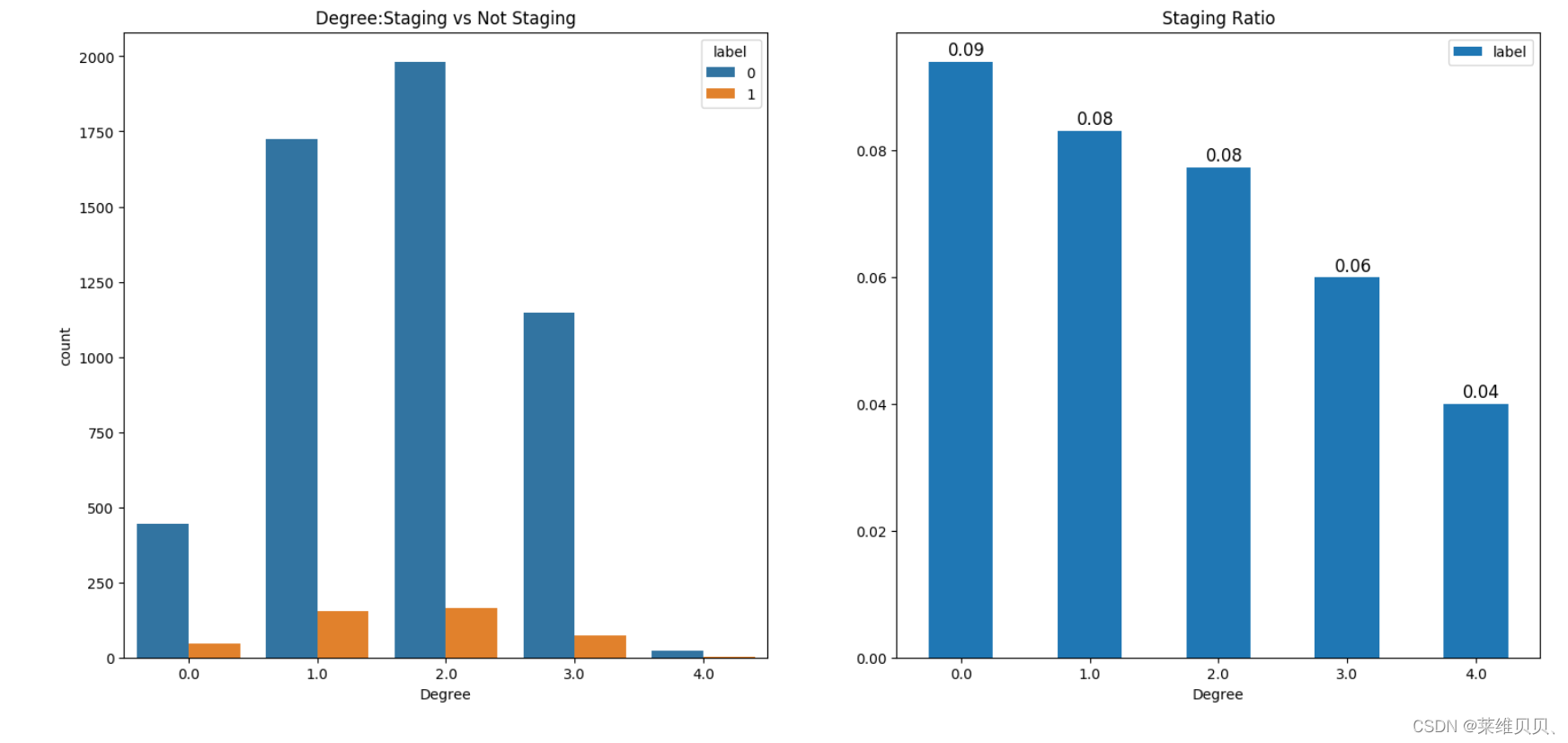
(ps: 从图中可以发现,随着学历的提高,同学历情况下,选择分期付款占比越来越小)
6.数据分布情况查看
(ps:查看那些特征,可以将不同类别的标签数据分开)
def plot_feature_distribution(df1, df2,df3, label1, label2, label3, features):i = 0sns.set_style('whitegrid')plt.figure()fig, ax = plt.subplots(11,10,figsize=(18,22))for feature in features:print(feature)i += 1plt.subplot(11,10,i)try:sns.distplot(df1[feature], hist=False,label=label1)sns.distplot(df2[feature], hist=False,label=label2)sns.distplot(df3[feature], hist=False,label=label3)except:print(feature)plt.xlabel(feature, fontsize=9)locs, labels = plt.xticks()plt.tick_params(axis='x', which='major', labelsize=6, pad=-6)plt.tick_params(axis='y', which='major', labelsize=6)plt.show();
t0 = train_df.loc[train_df['label'] == 0]
t1 = train_df.loc[train_df['label'] == 1]
t2 = train_df.loc[train_df['label'] == 2]features = train_df.columns.values[1:106]
plot_feature_distribution(t0, t1,t2, '0', '1','2', features)
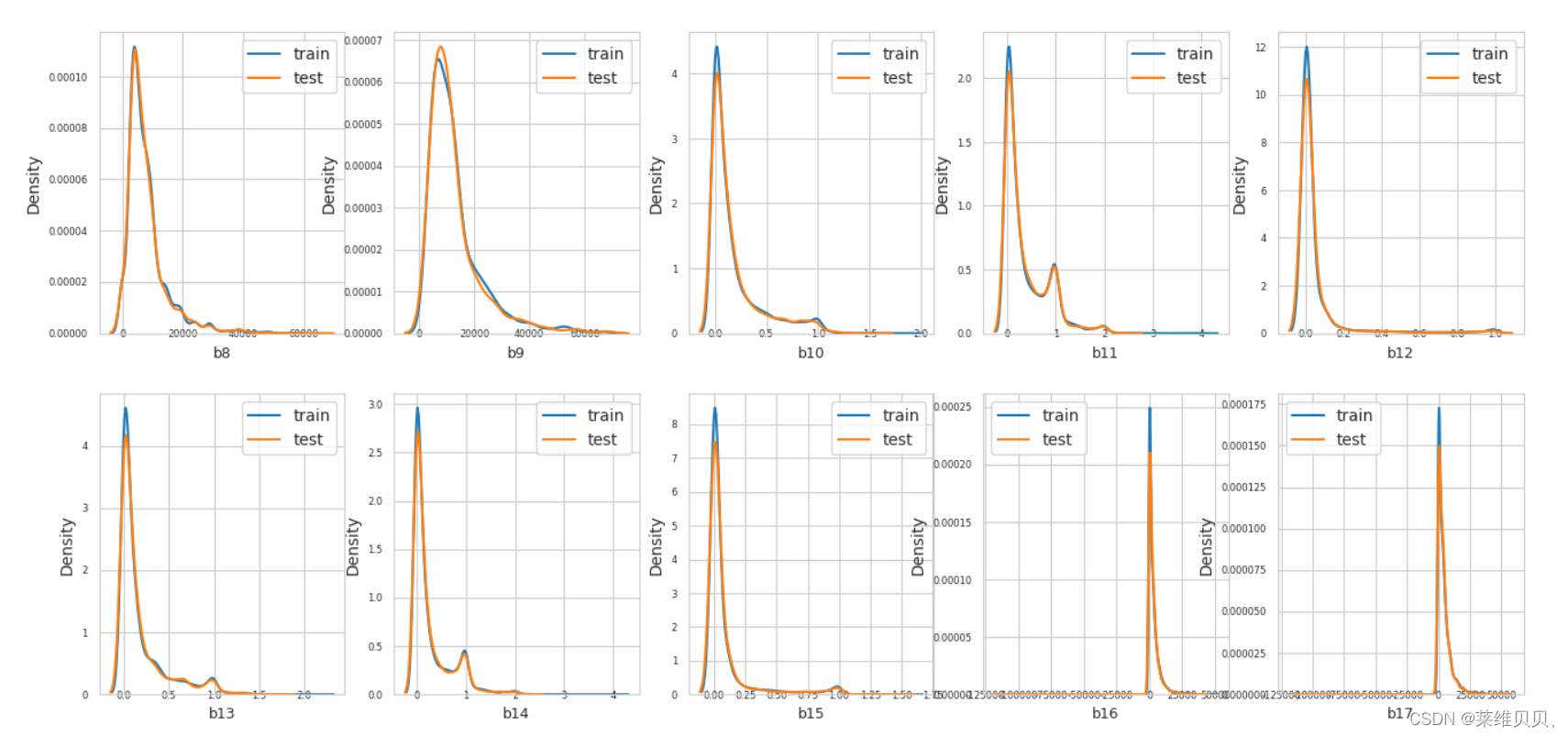
7.训练数据和测试数据分布查看
(ps:查看那些特征,在训练数据和测试数据上存在较大差异,如果存在,删去)
def plot_feature_distribution(df1, df2, label1, label2, features):i = 0sns.set_style('whitegrid')plt.figure()fig, ax = plt.subplots(11,10,figsize=(16,32))for feature in features:i += 1plt.subplot(11,10,i)sns.distplot(df1[feature], hist=False,label=label1)sns.distplot(df2[feature], hist=False,label=label2)plt.xlabel(feature, fontsize=9)locs, labels = plt.xticks()plt.tick_params(axis='x', which='major', labelsize=6, pad=-6)plt.tick_params(axis='y', which='major', labelsize=6)plt.legend()plt.show()
features = train_df.columns.values[1:106]
plot_feature_distribution(train_df, test_df, 'train', 'test', features)
8.RFECV最优特征选取
利用递归的方法进行,特征筛选
from sklearn.feature_selection import RFECV# 定义一个LightGBM分类器
clf = lgb.LGBMClassifier()
# 定义RFECV选择器
rfecv_selector = RFECV(estimator=clf, n_jobs=8,verbose=1,step=2, cv=2, scoring='accuracy')# 使用RFECV选择器训练数据
rfecv_selector.fit(train_x[features], train_y)
print('Finished')
# 得到选择后的特征子集
max_x = np.argmax(rfecv_selector.grid_scores_[1:])
max_y = np.max(rfecv_selector.grid_scores_[1:])# 绘制特征数量与交叉验证分数之间的关系曲线
plt.figure(figsize=(12,6))
plt.title('RFECV with LightGBM')
plt.xlabel('Number of features selected')
plt.ylabel('Cross validation score (accuracy)')
plt.plot([103-2*i for i in range(51)], rfecv_selector.grid_scores_[1:][::-1])plt.annotate(f'max: ({93}, {max_y:.2f})', xy=(max_x+48, max_y), xytext=(max_x+48, max_y),arrowprops=dict(facecolor='red',width=10, shrink=0.05))
plt.show()

**9.
相关文章:
数据分析与预处理常用的图和代码
1.训练集和测试集统计数据描述之间的差异作图: def diff_color(x):color red if x<0 else (green if x > 0 else black)return fcolor: {color}(train.describe() - test.describe())[features].T.iloc[:,1:].style\.bar(subset[mean, std], alignmid, colo…...
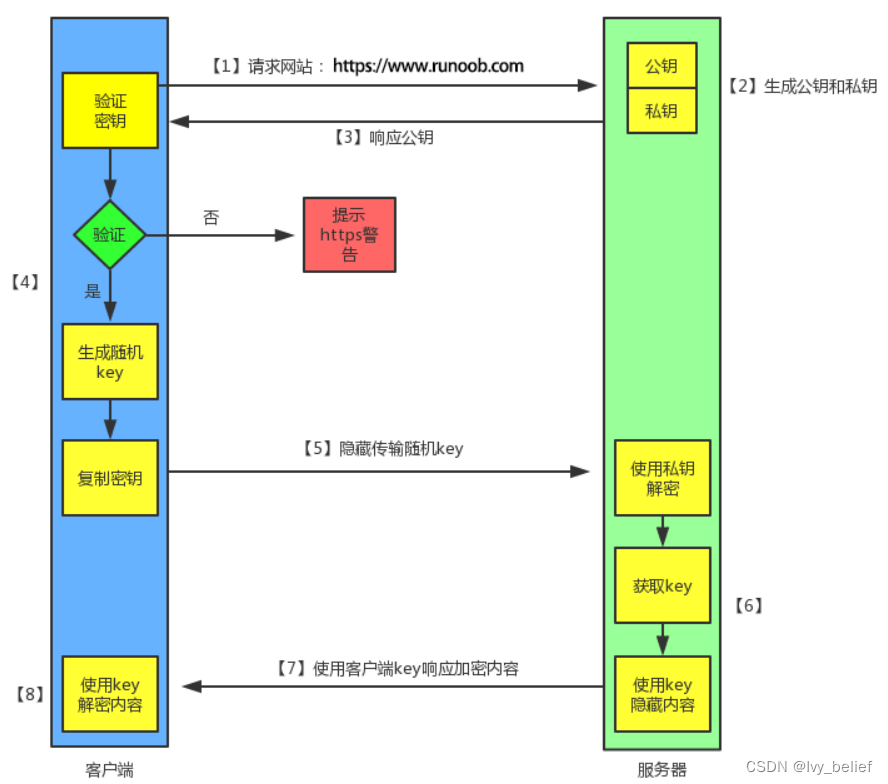
Http与Https 比较
目录 1、HTTP(HyperText Transfer Protocol:超文本传输协议) 2、HTTPS(Hypertext Transfer Protocol Secure:超文本传输安全协议) 3、HTTP 与 HTTPS 区别 4、HTTPS 的工作原理 1、HTTP(HyperTex…...
)
02 面向对象( 继承,抽象类)
强调:一定用自己的话总结,避免抄文档,否则视为作业未完成。 this关键字的作用 为了解决成员变量和局部变量所存在的二义性,适用于有参构造时使用 示例 private String name;private int age;public person(){}public person(String name,i…...

[C++]22种设计模式的C++实现大纲
前言 最近看遍全网,准备整理一套较好上手的设计模式文章,以便后续复习到处翻找,在此记录一下,如有侵权可以联系删除, 每天更新一篇,直到更新完 前置知识 UML类图与面向对象编程C UML类图详解软件设计原则与SOLID原则…...
用Powerpoint (PPT)制作并导出矢量图、高分辨率图
论文写作时经常需要导入矢量图,正规军都是用AI或者Inkscape作图,但是PPT更加适合小白用户,或者一些简单的构图需求使用PPT更加便捷,而且不得不承认PPT的某些功能是真的香,例如:简单的对齐、文字插入和格式修…...
小白量化《穿云箭集群量化》(9)用指标公式实现miniQMT全自动交易
小白量化《穿云箭集群量化》(9)用指标公式实现miniQMT全自动交易 在穿云箭量化平台中,支持3中公式源码运行模式,还支持在Python策略中使用仿指标公式源码运行,编写策略。 我们先看如何使用指标公式源码。 #编程_直接使…...

java Class类详解
Class类简介 在 java 世界里,一切皆对象。从某种意义上来说,java 有两种对象:实例对象和 Class 对象。每个类的运行时的类型信息就是用 Class 对象表示的,它包含了与类有关的信息,实例对象就是通过 Class 对象来创建的…...
DMGI:Unsupervised Attributed Multiplex Network Embedding
[1911.06750] Unsupervised Attributed Multiplex Network Embedding (arxiv.org) 目录 Abstract 1 Introduction 2 DGI 3 Deep Multiplex Graph Infomax: DMGI 特定关系类型的节点嵌入 Joint Modeling and Consensus Regularization Extension to Semi-Supervised Lea…...
C++基本介绍
文章目录 🥭1.C基本介绍🧂1.1 C是什么🧂1.2 C发展史 🍒2. C的优势🥔2.1 语言的使用广泛度🥔2.2 C的应用领域 🫒3. C学习计划 🥭1.C基本介绍 🧂1.1 C是什么 C是一种通用…...
如何理解工业互联网与智能制造,怎么共建智慧工厂?
第六届数字中国建设峰会26日在福州开幕,在这个数字化新技术的变革风口,企业如何把握机遇,借工业互联网和智能制造实现智慧工厂建设? 探讨三个问题: 什么是工业互联网、智能制造、智慧工厂;它们三者之间的…...
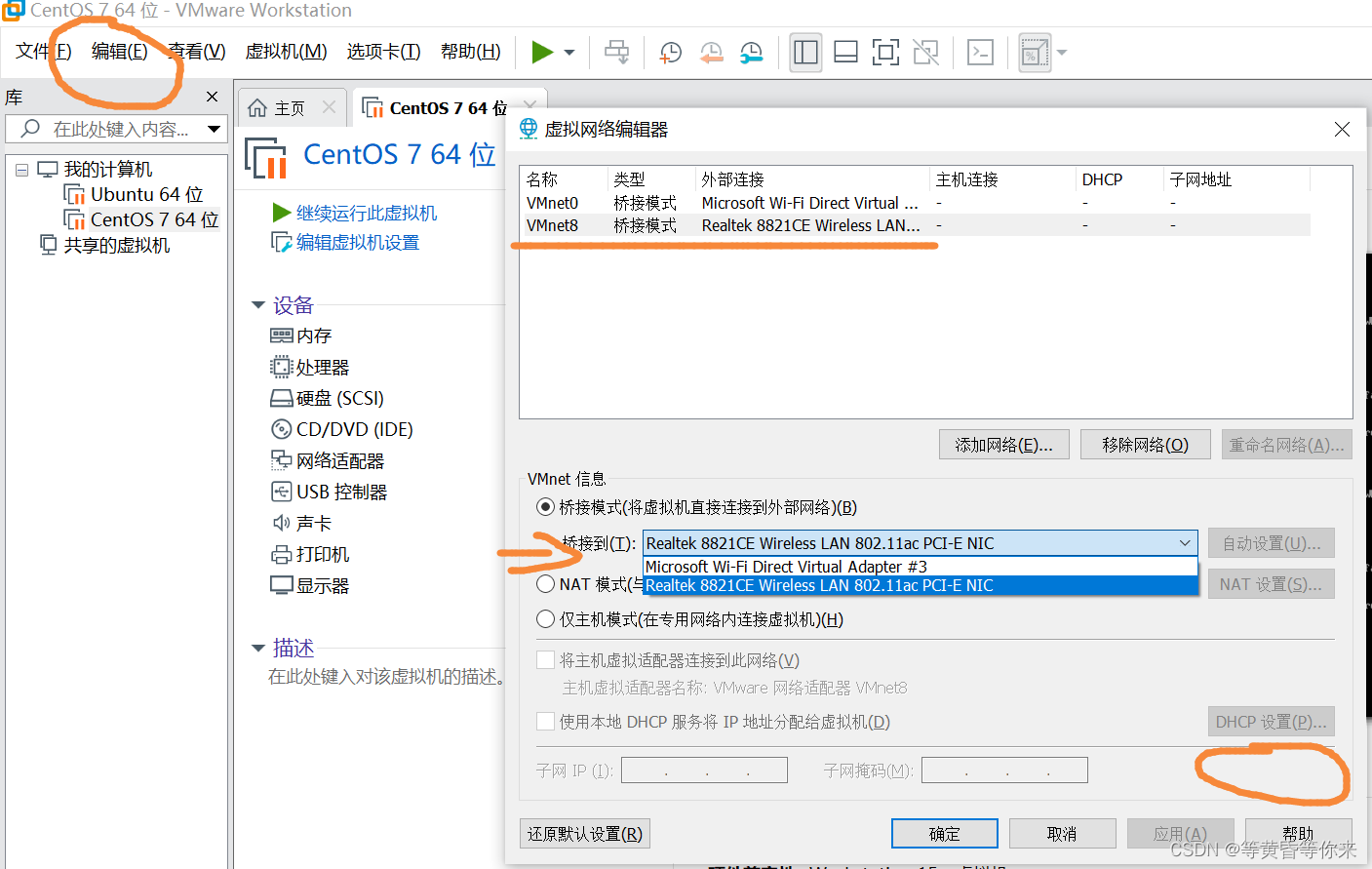
主机访问不到虚拟机(centos7)web服务的解决办法
目录 一、背景 二、解决办法 2.1、配置虚拟机防火墙 2.2、修改虚拟机网络编辑器 一、背景 主机可以访问外网,虚拟机使用命令:curl http://网址,可以访问到web服务 ,主机使用http://网址,访问不到虚拟机(…...
)
第四章 ActiveMQ与SpringBoot集成——ActiveMQ笔记(动力节点)
第四章 ActiveMQ 与 SpringBoot 集成 4-1 ActiveMQ 与 SpringBoot 集成集成配置 1、加载 spring boot 的 activeMQ 的依赖 <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter</artifactId> </de…...
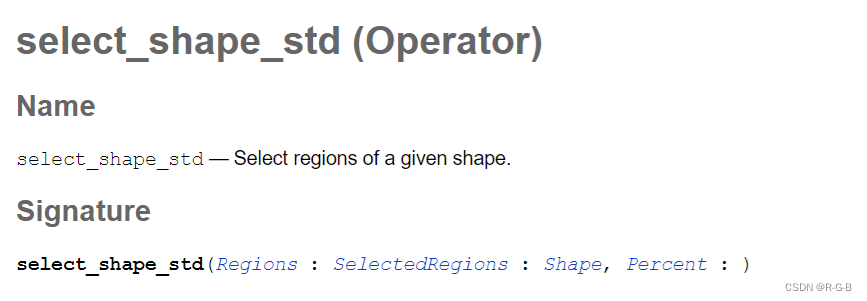
Halcon 算子 select_shape_std 和 select_shape_xld区别
文章目录 1 select_shape_std 算子介绍2 select_shape_xld算子介绍3 select_shape_std 和 select_shape_xld区别4 Halcon 算子的特征 Features 列表介绍1 select_shape_std 算子介绍 select_shape_std (Operator) Name select_shape_std — Select regions of a given shape.Si…...

【Java基础】匿名内部类
🎊专栏【Java基础】 🍔喜欢的诗句:更喜岷山千里雪 三军过后尽开颜。 🎆音乐分享【The truth that you leave】 大一同学小吉,欢迎并且感谢大家指出我的问题🥰 目录 🎁什么是匿名内部类 &#x…...

基于Freertos的ESP-IDF开发——6.使用DHT1温湿度传感器
基于Freertos的ESP-IDF开发——6.使用DHT1温湿度传感器 0. 前言1. DHT11驱动原理2. 完整代码3. 演示效果4. 其他FreeRtos文章 0. 前言 开发环境:ESP-IDF 4.3 操作系统:Windows10 专业版 开发板:自制的ESP32-WROOM-32E 准备一个DHT11温湿度传…...
C++——模板初阶
文章目录 一.泛型编程二.函数模板1.函数模板的概念2.函数模板的格式3.函数模板的原理4.函数模板的实例化(1)隐式实例化(2)显式实例化 5.模板参数的匹配原 三.类模板1.类模板的定义格式2.类模板的实例化 前言: 本章我们…...

【TOOLS: Linux与windows及linux与linux之间文件传输常用方法及命令】
文章目录 1.1.1 Windows和VirtualBox(Ubuntu)之间文件穿传输方法1.1.2 SCP 文件传输方法1.1.3 FTP 文件传输方法 1.1.1 Windows和VirtualBox(Ubuntu)之间文件穿传输方法 1)设置 virtualbox 中的共享文件夹,用户可以在windows某个盘下创建自己的共享文件…...

【博览群书】《实战大数据》——属于我的第一本大数据图书
文章目录 前言简介目录其他 前言 Hello家人们,博主前不久参加了CSDN图书馆和机械工业出版社联合举办的图书类活动,很荣幸在活动中获得了属于自己的第一本大数据图书,《实战大数据—— 分布式大数据分析处理系统开发与应用》。作为大数据专业…...
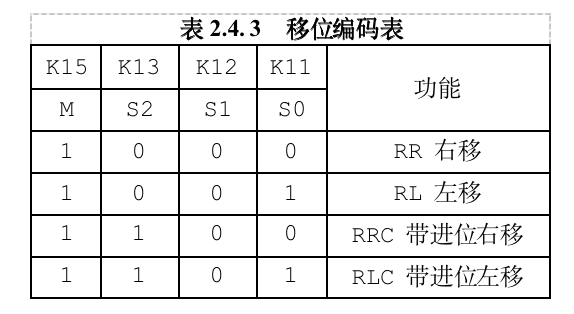
【计算机组成原理】实验二
文章目录 实验二 运算器实验一、实验目的二、实验原理三、运算器功能编码四、实验内容任务一 算术运算任务二 逻辑运算任务三 移位运算 实验二 运算器实验 一、实验目的 完成算术、逻辑、移位运算实验,熟悉ALU运算类型的控制位运用。实验仪器:JTHS-A …...

hive数据库hql基础操作02
1.内部表和外部表 默认情况下创建的表就是内部表,Hive拥有该表的结构和文件。换句话说,Hive完全管理表(元数据和数据)的生命周期,类似于RDBMS中的表。当你删除内部表时,它会删除数据以及表的元数据。可以使…...

光轮智能 谢晨 访谈总结机器人仿真数据产业
光轮智能 谢晨 访谈总结机器人仿真关于创始人关于数据数据金字塔数据痛点仿真数据的重要性仿真数据的质量b站链接地址公司官网关于创始人 清华物理;哥伦比亚金融;英伟达智驾仿真;小鹏智驾仿真;现为光轮智能CEO 关于数据 数据的…...

2026长沙智能家居品牌实测,这些本地老牌值得选
2026年,长沙的智能家居市场已经从“概念热”转向“落地战”。我走访了长沙多个本地服务商,实测了不同品牌在别墅、酒店、大平层等场景的真实表现。今天,结合数据与案例,分享几个值得关注的本地品牌,尤其是深耕8年以上的…...

【审计专栏】【财务领域】 第四十九篇 人在企业中的核心资产和核心利益01
编号 类型 企业 (行业/企业产品/企业利益链/生态位与层级) 业务领域 企业性质 企业中人的角色/岗位/利益矩阵 人在企业中的核心资产/附属资产 资产的业务-财务数学模型及数字/数值 关联知识 1 核心经营性资产(如IP、数据、品牌) 行业:人工智能 产品:工业视觉检…...

机器学习与深度学习在社交媒体心理健康检测中的权衡与选择
1. 项目概述:当AI遇见心灵,社交媒体心理健康检测的技术十字路口在社交媒体成为我们数字生活延伸的今天,海量的文本数据无意中记录着用户的情感波动与心理状态。作为一名长期混迹于数据科学和自然语言处理(NLP)一线的从…...

不止于绘图:用GMT 6.4的`grdtrack`和`project`命令玩转地形剖面分析与可视化
不止于绘图:用GMT 6.4的grdtrack和project命令玩转地形剖面分析与可视化 当我们谈论地理空间分析时,很多人首先想到的是绘制精美的地图。但GMT(Generic Mapping Tools)的真正魅力在于它强大的地理计算能力。本文将带你超越基础绘图…...

观察Taotoken在多模型聚合调用下的路由与失败重试效果
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察Taotoken在多模型聚合调用下的路由与失败重试效果 在构建依赖大模型能力的应用时,服务的稳定性是开发者关注的核心…...

深入解析NxDumpTool:Switch游戏文件系统提取的终极指南 [特殊字符]
深入解析NxDumpTool:Switch游戏文件系统提取的终极指南 🎮 【免费下载链接】nxdumptool Generates XCI/NSP/HFS0/ExeFS/RomFS/Certificate/Ticket dumps from Nintendo Switch gamecards and installed SD/eMMC titles. 项目地址: https://gitcode.com…...

如何在原神中解放双手:自动钓鱼、拾取与对话跳过的终极指南
如何在原神中解放双手:自动钓鱼、拾取与对话跳过的终极指南 【免费下载链接】genshin-impact-script 原神脚本,包含自动钓鱼、自动拾取、自动跳过对话等多项实用功能。A Genshin Impact script includes many useful features such as automatic fishing…...

从Bing日志到学术基准:MS MARCO数据集的前世今生与你的信息检索实验
从Bing日志到学术基准:MS MARCO数据集的前世今生与你的信息检索实验 当你在深夜调试信息检索模型时,是否曾好奇过那些基准数据集背后的故事?MS MARCO——这个让无数研究者又爱又恨的数据集,最初只是Bing搜索引擎日志中的普通用户查…...

Java入门全记录
一、表达式 1. 概念 由变量、运算符、字面值组成的式子,运算后会产生一个结果。 两变量参与运算,结果类型规则 如果参与运算的变量有一个为 double 类型,结果就是 double 类型 如果没有 double ,有一个为 float 类型,结…...