hive数据库hql基础操作02
1.内部表和外部表
默认情况下创建的表就是内部表,Hive拥有该表的结构和文件。换句话说,Hive完全管理表(元数据和数据)的生命周期,类似于RDBMS中的表。当你删除内部表时,它会删除数据以及表的元数据。可以使用DESCRIBE FORMATTED tablename,来获取表的元数据描述信息,从中可以看出表的类型

外部表(External table )中的数据不是Hive拥有或管理的,只管理表元数据的生命周期。要创建一个外部表,需要使用EXTERNAL语法关键字。删除外部表只会删除元数据,而不会删除实际数据。在Hive外部仍然可以访问实际数据。实际场景中,外部表搭配location语法指定数据的路径,可以让数据更安全。
主要差异:
- 无论内部表还是外部表,Hive都在Hive Metastore中管理表定义、字段类型等元数据信息。
- 删除内部表时,除了会从Metastore中删除表元数据,还会从HDFS中删除其所有数据文件。
- 删除外部表时,只会从Metastore中删除表的元数据,并保持HDFS位置中的实际数据不变。
代码演示
-- 创建内部表 加载数据
create table t_user_inner(id int,uname string,pwd string,sex string,age int
)row format delimited fields terminated by ',';
load data local inpath '/root/user.txt' into table t_user_inner;
-- 查看表信息
desc formatted t_user_inner ;
-- 创建外部表 加载数据
create external table t_user_ext(id int,uname string,pwd string,sex string,age int
)row format delimited fields terminated by ',';
load data local inpath '/root/user.txt' into table t_user_ext;
-- 查看表信息
desc formatted table t_user_ext;-- 删除内部表 数据被删除了
drop table t_user_inner;
-- 删除外部表 数据并没有被删除
drop table t_user_ext;-- 再次重新创建 t_user_ext 可以直接查询数据
select * from t_user_ext;-- 将t_user_ext 转换为内部表
alter table t_user_ext set tblproperties('EXTERNAL'='FALSE'); -- 要求KV的大小写
-- 查询表信息发现 Table Type: MANAGED_TABLE
desc formatted t_user_ext;
--将t_user_ext 转换为外部表
alter table t_user_ext set tblproperties('EXTERNAL'='true');
-- 查询表信息发现 Table Type:EXTERNAL_TABLE
desc formatted t_user_ext;
2.分区表
分区表实际上就是将表中的数据以某种维度进行划分文件夹管理 ,当要查询数据的时候,根据维度直接加载对应文件夹下的数据! 不用加载整张表所有的数据再进行过滤, 从而提升处理数据的效率!
比如在一个学生表中想查询某一个年级的学生,如果不分区,需要在整个数据文件中全表扫描,但是分区后只需要查询对应分区的文件即可.

静态分区
静态分区指的是分区的属性值是由用户在加载数据的时候手动指定的
1.创建单分区表:
-- 创建学生表 分区字段为年级grade
CREATE TABLE t_student (sid int,sname string) partitioned by(grade int) -- 指定分区字段
row format delimited fields terminated by ',';
-- 注意∶分区字段不能是表中已经存在的字段,因为分区字段最终也会以虚拟字段的形式显示在表结构上。
select * from t_student;
+----------------+------------------+------------------+
| t_student.sid | t_student.sname | t_student.grade |
+----------------+------------------+------------------+
+----------------+------------------+------------------+
创建本地文件
stu01.txt
1,zhangsan,1
2,lisi,1
3,wangwu,1stu02.txt
4,zhaoliu,2
5,lvqi,2
6,maba,2stu03.txt
7,liuyan,3
8,tangyan,3
9,jinlian,3
-- 静态分区需要用户手动加载数据 并指定分区
load data local inpath '/root/stu01.txt' into table t_student partition(grade=1);
load data local inpath '/root/stu02.txt' into table t_student partition(grade=2);
load data local inpath '/root/stu03.txt' into table t_student partition(grade=3);
-- 查询
select * from t_student where grade=1;
+----------------+------------------+------------------+
| t_student.sid | t_student.sname | t_student.grade |
+----------------+------------------+------------------+
| 1 | zhangsan | 1 |
| 2 | lisi | 1 |
| 3 | wangwu | 1 |
+----------------+------------------+------------------+
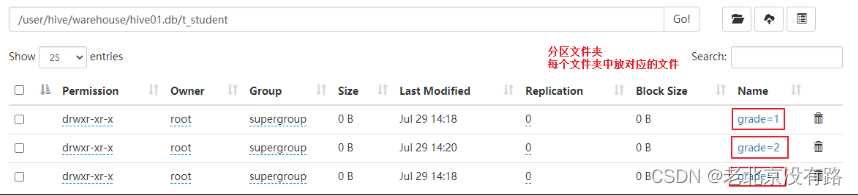
注意:文件中的数据放入到哪个分区下就属于当前分区的数据,即使数据有误,也会按照当前分区处理
stu03.txt
7,liuyan,3
8,tangyan,3
9,jinlian,3
10.aaa,4load data local inpath '/root/stu03.txt' overwrite into table t_student partition(grade=3);select * from t_student where grade=3;
-- 最后一条记录虽然写的是4 但是 放到了年级3分区下 效果也是年级3
+----------------+------------------+------------------+
| t_student.sid | t_student.sname | t_student.grade |
+----------------+------------------+------------------+
| 7 | liuyan | 3 |
| 8 | tangyan | 3 |
| 9 | jinlian | 3 |
| 10 | aaa | 3 |
+----------------+------------------+------------------+
创建多分区表
-- 创建学生表 分区字段为年级grade 班级clazz
CREATE TABLE t_student02 (sid int,sname string) partitioned by(grade int,clazz int) -- 指定分区字段
row format delimited fields terminated by ',';
1年级1班
stu0101.txt
1,zhangsan,1,1
2,lisi,1,11年级2班
stu0102.txt
3,wangwu,1,22年级1班
stu0201.txt
4,zhangsan,2,1
5,lisi,2,1
6,maba,2,13年级1班
stu0301.txt
7,liuyan,3,1
8,tangyan,3,1
3年级2班
9,dalang,3,2
10,jinlian,3,2
load data local inpath '/root/stu0101.txt' into table t_student02 partition(grade=1,clazz=1);
load data local inpath '/root/stu0102.txt' into table t_student02 partition(grade=1,clazz=2);
load data local inpath '/root/stu0201.txt' into table t_student02 partition(grade=2,clazz=1);
load data local inpath '/root/stu0301.txt' into table t_student02 partition(grade=3,clazz=1);
load data local inpath '/root/stu0302.txt' into table t_student02 partition(grade=3,clazz=2);select * from t_student02 where grade=1 and clazz=2;
+------------------+--------------------+--------------------+--------------------+
| t_student02.sid | t_student02.sname | t_student02.grade | t_student02.clazz |
+------------------+--------------------+--------------------+--------------------+
| 7 | liuyan | 3 | 1 |
| 8 | tangyan | 3 | 1 |
+------------------+--------------------+--------------------+--------------------+

动态分区
静态分区与动态分区的主要区别在于静态分区是手动指定,而动态分区是通过数据来进行判断.
详细来说:静态分区需要我们自己手动load并指定分区,如果数据很多,那么是麻烦了.而动态分区指的是分区的字段值是基于查询结果(参数位置)自动推断出来的。核心语法就是insert+seclect。
开启动态分区首先要在hive会话中设置如下的参数
-- 临时设置 重新连接需要重新设置
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
其余参数配置如下:
设置为true表示开启动态分区的功能(默认为false)
--hive.exec.dynamic.partition=true; 设置为nonstrict,表示允许所有分区都是动态的(默认为strict) 严格模式至少有一个静态分区
-- hive.exec.dynamic.partition.mode=nonstrict; 每个mapper或reducer可以创建的最大动态分区个数(默认为100)
比如:源数据中包含了一年的数据,即day字段有365个值,那么该参数就需要设置成大于365,
如果使用默认 值100,则会报错
--hive.exec.max.dynamic.partition.pernode=100; 一个动态分区创建可以创建的最大动态分区个数(默认值1000)
--hive.exec.max.dynamic.partitions=1000; 全局可以创建的最大文件个数(默认值100000)
--hive.exec.max.created.files=100000; 当有空分区产生时,是否抛出异常(默认false)
-- hive.error.on.empty.partition=false;
动态分区创建操作步骤
- 创建文件并上传
- 创建外部表指向文件(相当于临时表)
- 创建动态分区表
- 查询外部表将数据动态存入分区表中
创建文件并上传student.txt 1,zhangsan,1,1
2,lisi,1,1
3,wangwu,1,2
4,zhangsan,2,1
5,lisi,2,1
6,maba,2,1
7,liuyan,3,1
8,tangyan,3,1
9,dalang,3,2
10,jinlian,3,2-- 将文件上传到hdfs根目录
hdfs dfs -put student.txt /stu
创建外部表指向文件(相当于临时表)
create external table t_stu_e(sid int,sname string,grade int,clazz int
)row format delimited fields terminated by ","
location "/stu";
创建动态分区表
create table t_stu_d(sid int,sname string
)partitioned by (grade int,clazz int)
row format delimited fields terminated by ",";
查询外部表将数据动态存入分区表中
insert overwrite table t_stu_d partition (grade,clazz) select * from t_stu_e ;select * from t_stu_d;
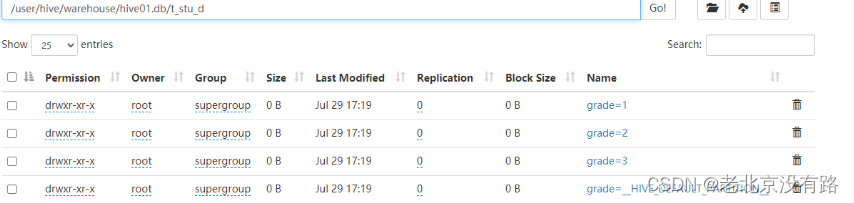
分桶表
分桶表也叫做桶表,叫法源自建表语法中bucket单词,是一种用于优化查询而设计的表类型。
分区提供一个隔离数据和优化查询的便利方式。不过,并非所有的数据集都可形成合理的分区。不合理的数据分区划分方式可能导致有的分区数据过多,而某些分区没有什么数据的尴尬情况 。分桶是将数据集分解为更容易管理的若干部分的另一种技术
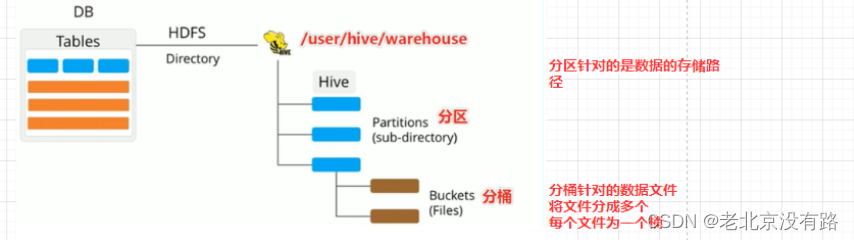
对Hive(Inceptor)表分桶可以将表中记录按分桶键(字段)的哈希值分散进多个文件中,这些小文件称为桶。桶以文件为单位管理数据!分区针对的是数据的存储路径;分桶针对的是数据文件。
原理:
bucket num = hash_function(bucketing_column) mod num_buckets分隔编号 哈希方法(分桶字段) 取模 分桶的个数
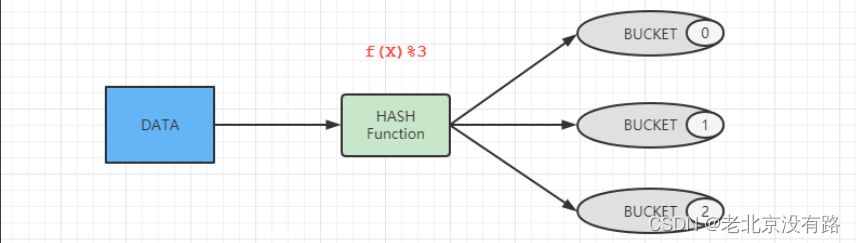
分桶好处:
-
基于分桶字段查询时,减少全表扫描.
-
根据join的字段对表进行分桶操作,join时可以提高MR程序效率,减少笛卡尔积数量.

-
分桶表数据进行高效抽样.数据量大时,使用抽样数据估计和推断整体特性.
分桶表的创建
1.准备person.txt上传到hdfs
2.创建外部表指向person.txt
3.创建分桶表
4.查询外部表将数据加载到分桶表中
person.txt
public class Test02 {public static void main(String[] args) {for (int i = 1; i <= 10000; i++) {System.out.println(i + "," + "liuyan" + (new Random().nextInt(10000) + 10000));}}
}hdfs dfs -mkdir /person
hdfs dfs -put person.txt /person
2.创建外部表指向person.txt
create external table t_person_e(id int,pname string
) row format delimited fields terminated by ","location "/person";select * from t_person_e;
create table t_person(id int,pname string
)clustered by(id) sorted by (pname) into 24 buckets
row format delimited fields terminated by ",";
insert overwrite table t_person select * from t_person_e ;

桶表抽样
-- tablesample是抽样语句,语法:TABLESAMPLE(BUCKET x OUT OF y)
-- x表示从哪个bucket开始抽取。例如,table总bucket数为32,tablesample(bucket 3 out of 16)32 / 16 = 2 代表16桶为一组 抽取 第一组的第3桶 抽取第二组的第3桶 也就是第19桶
-- y必须是table总bucket数的倍数或者因子。hive根据y的大小,决定抽样的比例。tablesample(bucket 3 out of 64)32/64 = 2分之一 64桶为一组 不够一组 取第三桶的 前百分之50select * from t_person tablesample(bucket 4 out of 12); 24/12 抽取2桶数据 12桶一组 抽取 第一组第4桶 第二组 第4桶 4+12 =16桶
相关文章:
hive数据库hql基础操作02
1.内部表和外部表 默认情况下创建的表就是内部表,Hive拥有该表的结构和文件。换句话说,Hive完全管理表(元数据和数据)的生命周期,类似于RDBMS中的表。当你删除内部表时,它会删除数据以及表的元数据。可以使…...

门电路OD门
漏极开路输出的门电路(OD门) 为了满足输出电平的变换,输出大负载电流,以及实现“线与”功能,将CMOS门电路的输出级做成漏极开路的形式,称为漏极开路输出的门电路,简称OD(Open&#x…...

没有域名,一个服务器Nginx怎么部署多个前端项目
因为没有域名,所以用路径来作区分, 主项目:直接根路由访问该项目,与正常配置无任何差别从项目:此处设置/new路径,为从项目,所有从项目访问路径均要加上/new ①修改Nginx配置文件 Nginx 配置文…...
城市内涝的原因和解决措施,内涝监测预警助力城市防涝度汛
城市内涝是城市化进程中最遇到的自然灾害,城市内涝不仅会对市民生活造成困扰,也会对城市基础设施和经济发展产生不利影响。因此,及时监测城市内涝现象,对于城市管理和城市安全具有重要意义。本文将深入探讨城市内涝的原因以及针对…...
8年测试总结,性能测试问题大全,这些问题你应该认清的...
目录:导读 前言一、Python编程入门到精通二、接口自动化项目实战三、Web自动化项目实战四、App自动化项目实战五、一线大厂简历六、测试开发DevOps体系七、常用自动化测试工具八、JMeter性能测试九、总结(尾部小惊喜) 前言 响应时间VS吞吐量…...
RabbitMQ集群安装
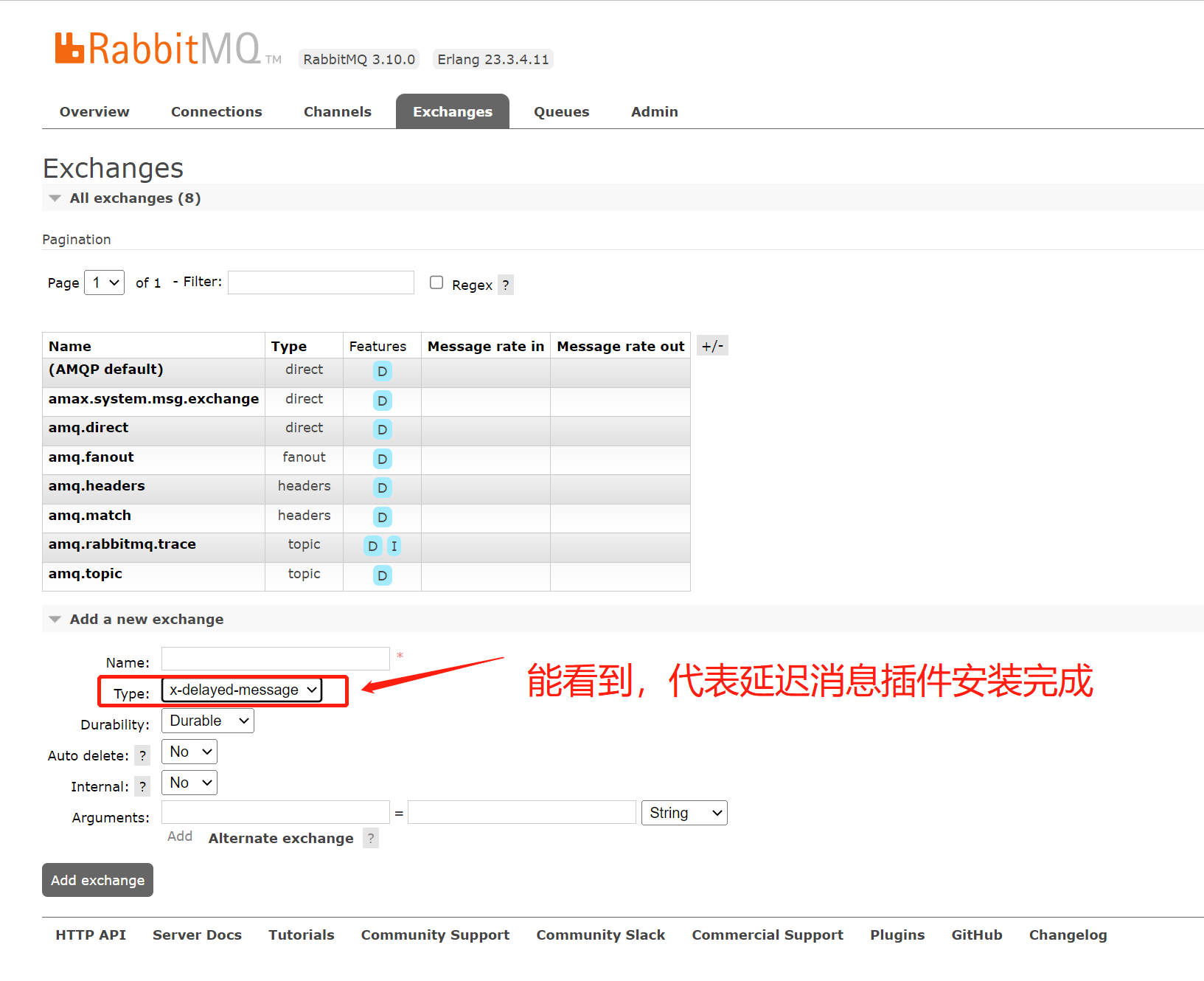
RabbitMQ集群安装 1.前言 OS: CentOS Linux release 7.9.2009 (Core) 机器: IPnodecpu内存存储10.106.1.241max-rabbitmg-018 核16 G100 G10.106.1.242max-rabbitmg-028 核16 G100 G10.106.1.243max-rabbitmg-038 核16 G100 G 因为操作系统版本是 centos7,所以…...

面试:link和@import的区别
1:link是XHTML标签,除了加载CSS外,还可以加载RSS;import只能加载CSS 2:link引入CSS时,在页面载入时同时加载;import需要页面完全载入后加载,可能会出行闪屏 3:link是XHTML标签,无兼容…...
图片隐写(一)
文件隐藏 binwalk binwalk -e filename foremost foremost filename steghide & stegseek Install sudo apt-get install steghidestegseek Use steghide extract -sf filename -p passwordtime stegseek secret.file aaa.txt dd 文本隐藏 二进制文件末尾 or 文…...
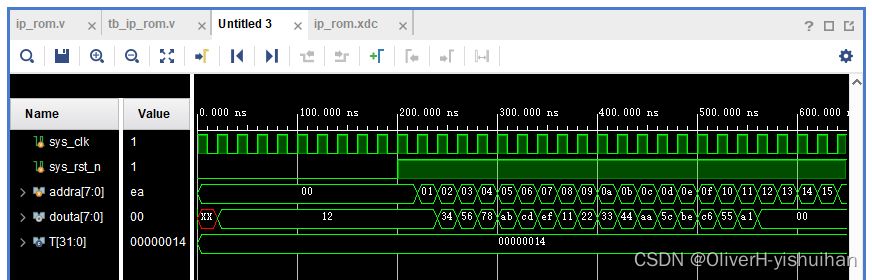
Vivado 下 IP核 之ROM 读写
目录 Vivado 下 IP核 之ROM 读写 1、实验简介 2、ROM IP 核简介 3、ROM IP 核配置 3.1、创建 ROM 初始化文件 3.2、单端口 ROM 的配置 3.3、双端口 ROM 的配置 3.4、ROM IP 核的调用 (1)ROM 顶层模块代码 (2)ROM IP 核仿…...

朗诵素材-《诵四季诗韵,咏师恩师德》
女:中华五千年的悠久历史,孕育了底蕴深厚的民族文化。 男:华夏源远流长的经典诗文, 女:是文化艺苑中经久不衰的瑰宝。 男:在那些脍炙人口的诗句里,凝聚着华光熠熠的民族精魂。 女࿱…...
CHB-麻省理工学院头皮脑电图数据库
数据库介绍 该数据库在波士顿儿童医院收集,包括患有顽固性癫痫发作的儿科受试者的脑电图记录。受试者在停用抗癫痫药物后被监测长达几天,以表征他们的癫痫发作并评估他们手术干预的候选资格。 数据库链接:https://physionet.org/content/chb…...
传输层协议
目录 传输层 端口号 端口号范围划分 认识知名端口号(Well-Know Port Number) netstat pidof UDP协议UDP协议端格式编辑 UDP的特点 面向数据报 UDP的缓冲区 UDP使用注意事项 基于UDP的应用层协议 TCP协议 TCP协议段格式 确认应答(ACK)机制 超时重传机制 连…...

公司新招了个字节拿36K的人,让我见识到了什么才是测试扛把子......
5年测试,应该是能达到资深测试的水准,即不仅能熟练地开发业务,而且还能熟悉项目开发,测试,调试和发布的流程,而且还应该能全面掌握数据库等方面的技能,如果技能再高些的话,甚至熟悉分…...

pytorch rpc如何实现分物理机器的model parallel
因为业务需要,最近接到一项任务,是如何利用pytorch实现model parallel以及distributed training。搜罗了网上很多资料,以及阅读了pytorch官方的教程,都没有可参考的案例。讲的比较多的是data parallel,关于model paral…...
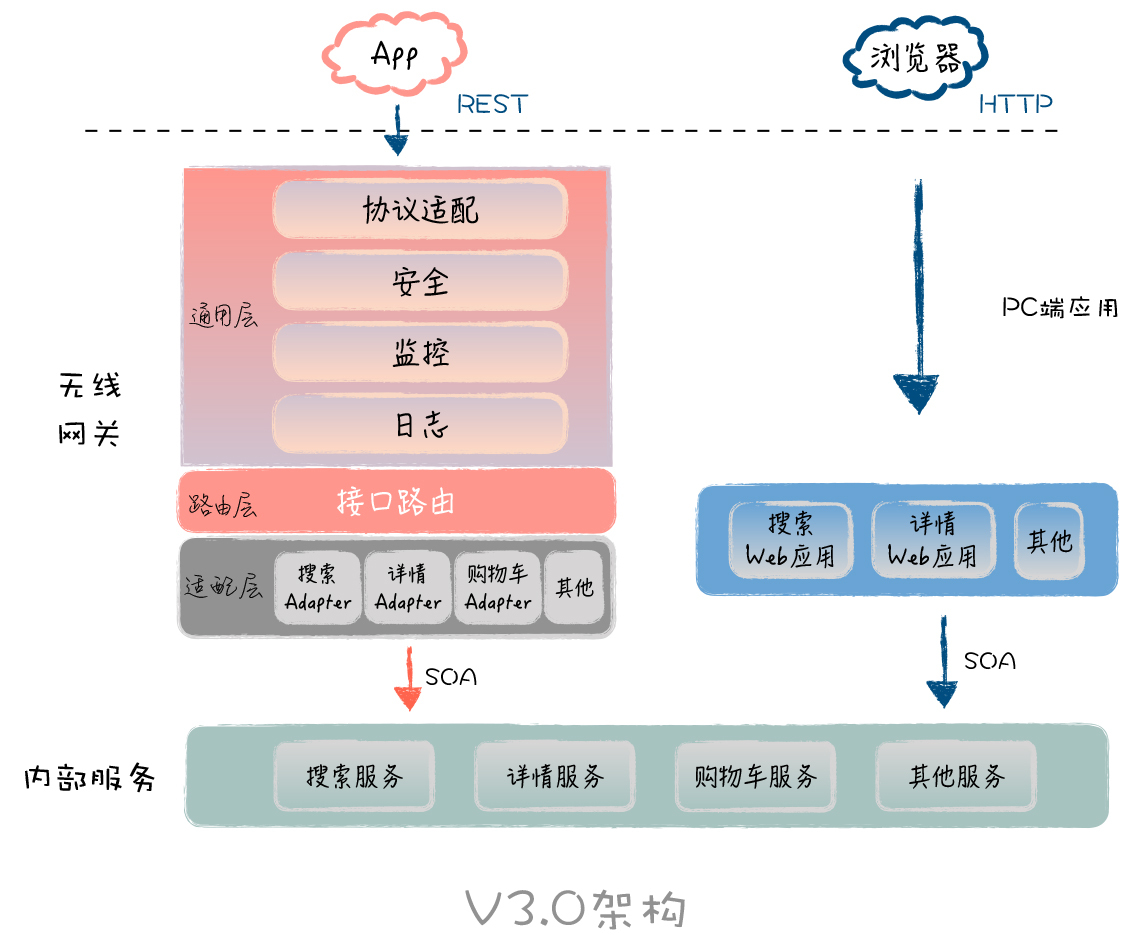
APP服务端架构的演变
大家好,我是易安! 早期2013年的时候,随着智能设备的普及和移动互联网的发展,移动端逐渐成为用户的新入口,各个电商平台都开始聚焦移动端App,如今经历了10年的发展,很多电商APP早已经没入历史的洪…...
EasyRecovery16适用于Windows和Mac的专业硬盘恢复软件
无论你对数据恢复了解多少, 我们将为您处理所有复杂的流程并简化恢复!适用于Windows和Mac的 专业硬盘恢复软件 硬盘数据无法保证绝对安全。有时会发生数据丢失,需要使用硬盘恢复工具。支持恢复不同存储介质数据:硬盘、光盘、U盘/移动硬盘、数…...

详解Jetpack Compose中的状态管理与使用
前言 引用一段官方描述,如下 由于 Compose 是声明式工具集,因此更新它的唯一方法是通过新参数调用同一可组合项。这些参数是界面状态的表现形式。每当状态更新时,都会发生重组。因此,TextField 不会像在基于 XML 的命令式视图中那…...

改进YOLOv7 | 头部解耦 | 将YOLOX解耦头添加到YOLOv7 | 涨点杀器
改进YOLOv7 | 头部解耦 | 将YOLOX解耦头添加到YOLOv7 论文地址:https://arxiv.org/abs/2107.08430 文章目录 改进YOLOv7 | 头部解耦 | 将YOLOX解耦头添加到YOLOv71. 解耦头原理2. 解耦头对收敛速度的影响3. 解耦头对精度的影响4. 代码改进方式第一步第二步第三步第四步第五步参…...

第七章 中断
中断是什么,为什么要有中断 并发是指单位时间内的累积工作量。 并行是指真正同时进行的工作量。 一个CPU在一个时间只能执行一个进程,任何瞬间任务只在一个核心上运行。 而CPU外的设备是独立于CPU的,它与CPU同步运行,CPU抽出一点…...
)
1116 Come on! Let‘s C(38行代码+详细注释)
分数 20 全屏浏览题目 作者 CHEN, Yue 单位 浙江大学 "Lets C" is a popular and fun programming contest hosted by the College of Computer Science and Technology, Zhejiang University. Since the idea of the contest is for fun, the award rules are f…...

智能检索新范式,让AIAgent自主决策,提升RAG效率100%!
市面上的 RAG 系统,不管叫什么名字,本质上只有两种做法: 第一种,一次性检索。把用户的 query 向量化,从语料库里捞出 Top-K 个文档片段,拼成一个大 prompt 塞给模型。GraphRAG、HippoRAG、LightRAG 都属于…...

Redis沙盒体验:在浏览器中零门槛掌握NoSQL核心技能
Redis沙盒体验:在浏览器中零门槛掌握NoSQL核心技能 【免费下载链接】try.redis A demonstration of the Redis database. 项目地址: https://gitcode.com/gh_mirrors/tr/try.redis 当你第一次听说Redis时,是否被那些晦涩的技术术语吓退࿱…...

基于Arduino的智能蓝调节拍器:DIY音乐练习伴侣
1. 项目概述:一个能“演奏”蓝调的低成本节拍器玩乐器的人,对节拍器这东西又爱又恨。它像一位严厉的监工,用单调的“嘀嗒”声强迫你跟上节奏。但你想过没有,这个监工其实可以很有趣?几年前,我在练习蓝调吉他…...

从开题到定稿零焦虑:okbiye AI 论文写作,帮你把毕业季的 “大山” 变成坦途
okbiye-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPT毕业论文 - Okbiye智能写作https://www.okbiye.com/ai/bylw 毕业季的深夜,宿舍台灯下的屏幕亮着刺眼的光,文档里的字数停留在三位数,而 deadline 正一天天逼近。你是…...
)
用Python复现Nature论文:仅需100次循环数据,提前预测锂电池寿命(附完整代码与数据集)
用Python实战预测锂电池寿命:从数据特征到模型部署全解析锂电池作为现代能源存储的核心组件,其寿命预测一直是工业界和学术界关注的焦点。传统方法往往需要等待电池出现明显容量衰减才能进行判断,而最新研究表明,通过分析早期循环…...

HiveWE终极指南:快速掌握魔兽争霸III现代化地图编辑器
HiveWE终极指南:快速掌握魔兽争霸III现代化地图编辑器 【免费下载链接】HiveWE A Warcraft III world editor. 项目地址: https://gitcode.com/gh_mirrors/hi/HiveWE 还在为传统魔兽争霸III地图编辑器缓慢的加载速度和复杂的操作界面而烦恼吗?Hiv…...

2026这6款神级降AIGC平台大公开,一键让AIGC率直逼绝对安全线!
步入 2026 年,学术圈的风向早已不是从前的模样。曾经大家还在为查重率发愁,如今却陷入了更棘手的困境——如何在不破坏论文专业性的前提下,彻底消除 AI 痕迹?随着 AIGC 检测技术不断进化,高校对论文的审核标准也愈发严…...

CA-CFAR、GO-CFAR、SO-CFAR怎么选?一张图看懂三种恒虚警检测算法的适用场景与避坑指南
CA-CFAR、GO-CFAR、SO-CFAR工程选型指南:从算法原理到场景适配 雷达信号处理工程师常常面临一个经典难题:在复杂环境中如何选择合适的恒虚警检测算法?当海面杂波、多目标干扰或低信噪比条件同时出现时,CA、GO、SO三种CFAR变体的性…...

Lovable电商网站搭建,为什么92%的初创团队在第3周就遭遇性能雪崩?
更多请点击: https://codechina.net 第一章:Lovable电商网站搭建 Lovable 是一个面向中小商户的轻量级电商解决方案,采用现代 Web 技术栈构建,强调可扩展性、用户体验与快速部署。其核心基于 Vue 3(Composition API&a…...

别再只会用--nogpgcheck了!手把手教你安全修复PostgreSQL yum源的GPG密钥问题
企业级PostgreSQL部署:安全解决GPG密钥验证的完整方案 当你在生产环境中部署PostgreSQL时,遇到GPG签名验证错误直接使用--nogpgcheck绕过检查,就像因为门锁打不开就直接把门拆掉一样危险。本文将带你深入理解GPG验证机制,并提供一…...