Spark基础学习笔记----RDD检查点与共享变量
零、本讲学习目标
- 了解RDD容错机制
- 理解RDD检查点机制的特点与用处
- 理解共享变量的类别、特点与使用
一、RDD容错机制
- 当Spark集群中的某一个节点由于宕机导致数据丢失,则可以通过Spark中的RDD进行容错恢复已经丢失的数据。RDD提供了两种故障恢复的方式,分别是血统(Lineage)方式和设置检查点(checkpoint)方式。
(一)血统方式
- 根据RDD之间依赖关系对丢失数据的RDD进行数据恢复。若丢失数据的子RDD进行窄依赖运算,则只需要把丢失数据的父RDD的对应分区进行重新计算,不依赖其他节点,并且在计算过程中不存在冗余计算;若丢失数据的RDD进行宽依赖运算,则需要父RDD所有分区都要进行从头到尾计算,计算过程中存在冗余计算。
(二)设置检查点方式
- 本质是将RDD写入磁盘存储。当RDD进行宽依赖运算时,只要在中间阶段设置一个检查点进行容错,即Spark中的sparkContext调用setCheckpoint()方法,设置容错文件系统目录作为检查点checkpoint,将checkpoint的数据写入之前设置的容错文件系统中进行持久化存储,若后面有节点宕机导致分区数据丢失,则以从做检查点的RDD开始重新计算,不需要从头到尾的计算,从而减少开销。
二、RDD检查点
(一)RDD检查点机制
- RDD的检查点机制(Checkpoint)相当于对RDD数据进行快照,可以将经常使用的RDD快照到指定的文件系统中,最好是共享文件系统,例如HDFS。当机器发生故障导致内存或磁盘中的RDD数据丢失时,可以快速从快照中对指定的RDD进行恢复,而不需要根据RDD的依赖关系从头进行计算,大大提高了计算效率。
(二)与RDD持久化的区别
- cache()或者persist()是将数据存储于机器本地的内存或磁盘,当机器发生故障时无法进行数据恢复,而检查点是将RDD数据存储于外部的共享文件系统(例如HDFS),共享文件系统的副本机制保证了数据的可靠性。
- 在Spark应用程序执行结束后,cache()或者persist()存储的数据将被清空,而检查点存储的数据不会受影响,将永久存在,除非手动将其移除。因此,检查点数据可以被下一个Spark应用程序使用,而cache()或者persist()数据只能被当前Spark应用程序使用。
(三)RDD检查点案例演示
- 在
net.cl.rdd包里创建CheckpointDemo对象
package net.cl.rddimport org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}object CheckpointDemo {def main(args: Array[String]): Unit = {// 设置系统属性(本地运行必须设置,否则无权访问HDFS)System.setProperty("HADOOP_USER_NAME", "root")// 创建SparkConf对象val conf = new SparkConf()// 设置应用程序名称,可在Spark WebUI里显示conf.setAppName("Spark-CheckpointDemo")// 设置集群Master节点访问地址conf.setMaster("local[2]")// 设置测试内存conf.set("spark.testing.memory", "2147480000")// 基于SparkConf对象创建SparkContext对象,该对象是提交Spark应用程序的入口val sc = new SparkContext(conf)// 设置检查点数据存储路径sc.setCheckpointDir("hdfs://master:9000/spark-ck")// 创建模拟数据RDDval rdd: RDD[Int] = sc.parallelize(List(1, 1, 2, 3, 5, 8, 13))// 过滤结果val resultRDD = rdd.filter(_ >= 5)// 持久化RDD到内存中resultRDD.cache()// 将resultRDD标记为检查点resultRDD.checkpoint()// 第一次行动算子计算时,将把标记为检查点的RDD数据存储到文件系统指定路径中val result: String = resultRDD.collect().mkString(", ")println(result)// 第二次行动算子计算时,将直接从文件系统读取resultRDD数据,而不需要从头计算val count = resultRDD.count()println(count)// 停止Spark容器sc.stop()}
}
- 上述代码使用checkpoint()方法将RDD标记为检查点(只是标记,遇到行动算子才会执行)。在第一次行动计算时,被标记为检查点的RDD的数据将以文件的形式保存在setCheckpointDir()方法指定的文件系统目录中,并且该RDD的所有父RDD依赖关系将被移除,因为下一次对该RDD计算时将直接从文件系统中读取数据,而不需要根据依赖关系重新计算。
- Spark建议,在将RDD标记为检查点之前,最好将RDD持久化到内存,因为Spark会单独启动一个任务将标记为检查点的RDD的数据写入文件系统,如果RDD的数据已经持久化到了内存,将直接从内存中读取数据,然后进行写入,提高数据写入效率,否则需要重复计算一遍RDD的数据。
- 创建检查点保存数据的目录
- 运行程序,在控制台查看结果
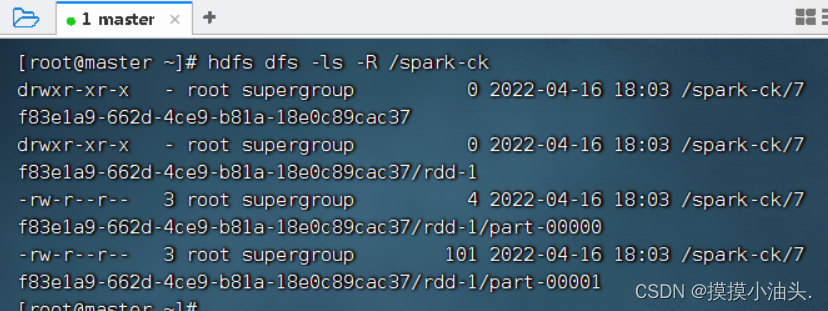
- 查看HDFS检查点目录,执行命令:
hdfs dfs -ls -R /spark-ck
三、共享变量
- 通常情况下,Spark应用程序运行的时候,Spark算子(例如map(func)或filter(func))中的函数func会被发送到远程的多个Worker节点上执行,如果一个算子中使用了某个外部变量,该变量就会复制到Worker节点的每一个Task任务中,各个Task任务对变量的操作相互独立。当变量所存储的数据量非常大时(例如一个大型集合)将增加网络传输及内存的开销。因此,Spark提供了两种共享变量:广播变量和累加器。
(一)广播变量
- 广播变量是将一个变量通过广播的形式发送到每个Worker节点的缓存中,而不是发送到每个Task任务中,各个Task任务可以共享该变量的数据。因此,广播变量是只读的。
1、默认情况下变量的传递
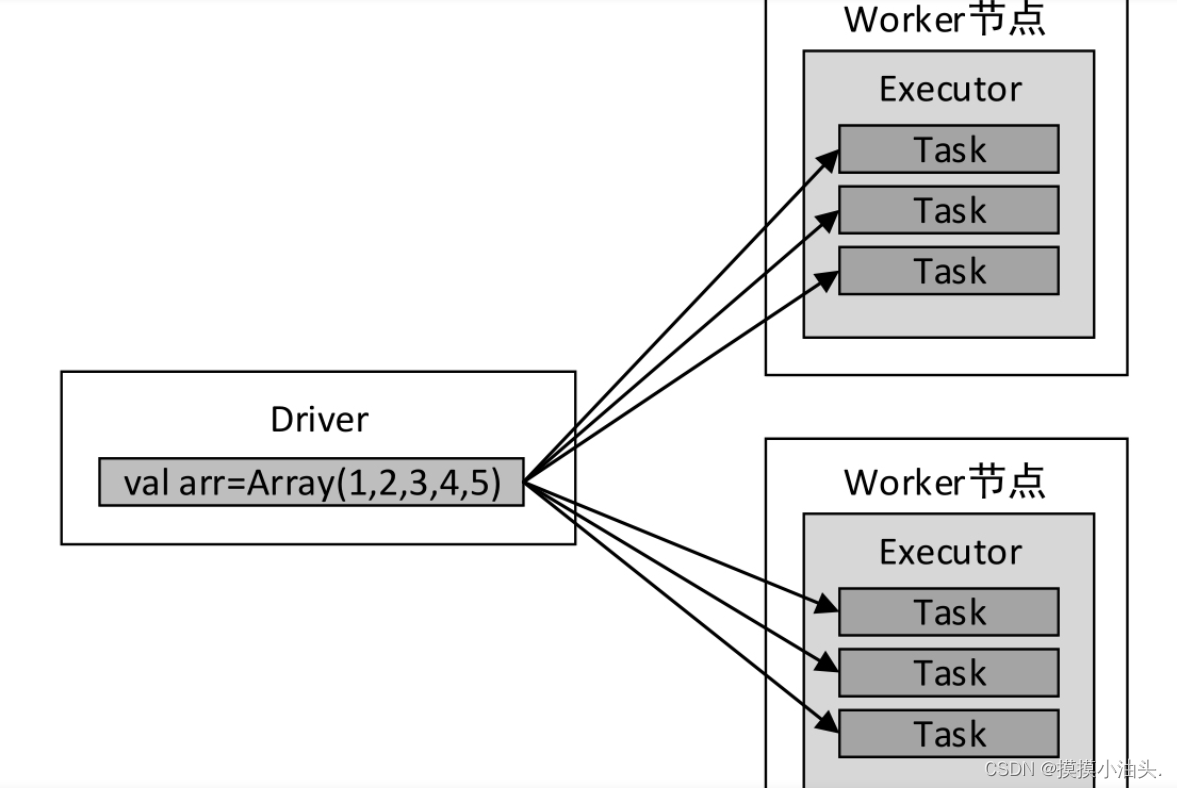
- map()算子传入的函数中使用外部变量arr

scala> val arr = Array(1, 2, 3, 4, 5)
scala> val lines = sc.textFile("data.txt")
scala> val result = lines.map((_, arr))
scala> result.collect()
- 上述代码中,传递给map()算子的函数
(_, arr)会被发送到Executor端执行,而变量arr将发送到Worker节点的所有Task任务中。变量arr传递的流程如下图所示
- 假设变量
arr存储的数据量大小有100MB,则每一个Task任务都需要维护100MB的副本,若某一个Executor中启动了3个Task任务,则该Executor将消耗300MB内存。
2、使用广播变量时变量的传递
- 广播变量其实是对普通变量的封装,在分布式函数中可以通过Broadcast对象的
value方法访问广播变量的值
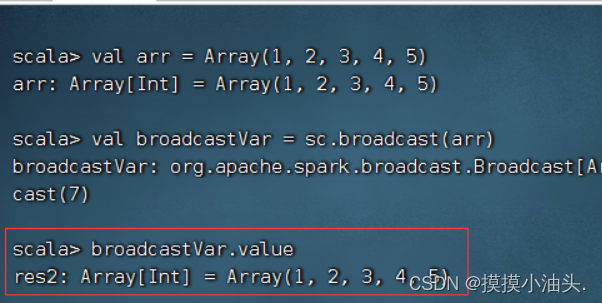
- 使用广播变量将数组arr传递给map()算子
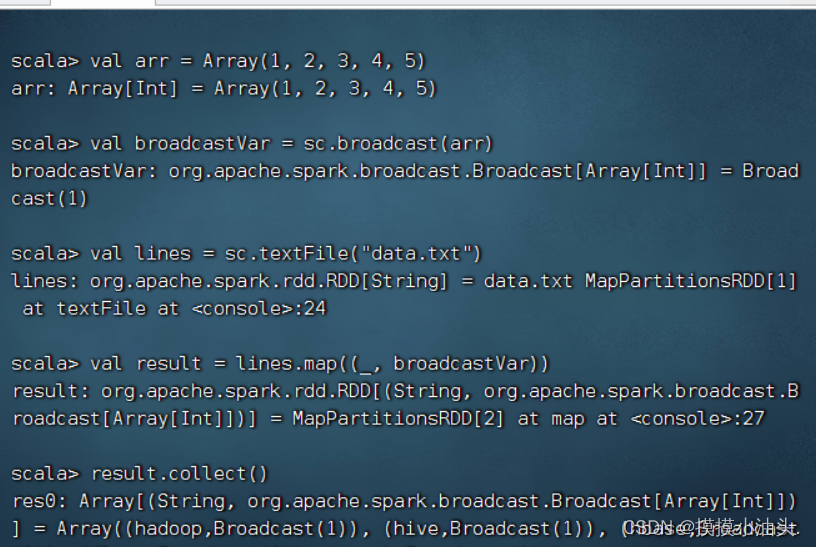
scala> val arr = Array(1, 2, 3, 4, 5)
scala> val broadcastVar = sc.broadcast(arr)
scala> val lines = sc.textFile("data.txt")
scala> val result = lines.map((_, broadcastVar))
scala> result.collect()
- 上述代码使用broadcast()方法向集群发送(广播)了一个只读变量,该方法只发送一次,并返回一个广播变量broadcastVar,该变量是一个org.apache.spark.broadcast.Broadcast对象。Broadcast对象是只读的,缓存在集群的每个Worker节点中。使用广播变量进行变量传递的流程如下图所示。
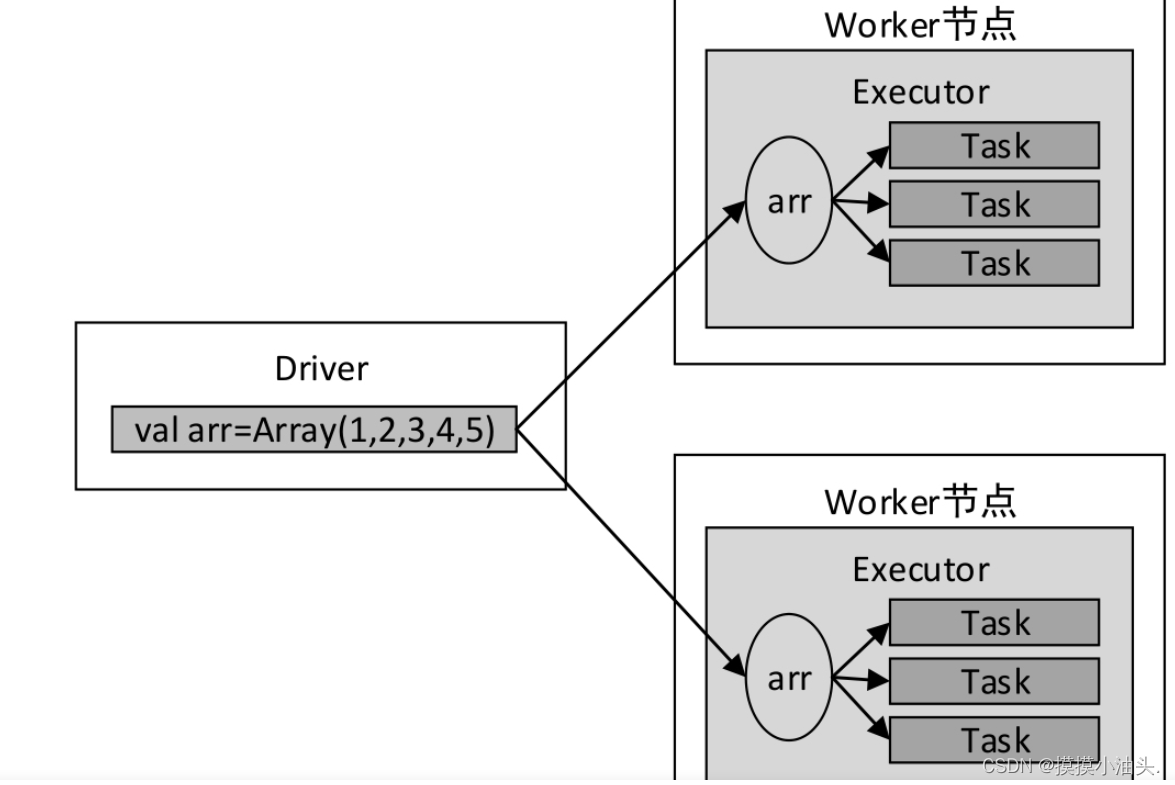
- Worker节点的每个Task任务共享唯一的一份广播变量,大大减少了网络传输和内存开销。
- 输出result的数据
(二)累加器
1、累加器功能
- 累加器提供了将Worker节点的值聚合到Driver的功能,可以用于实现计数和求和。
2、不使用累加器
- 对一个整型数组求和
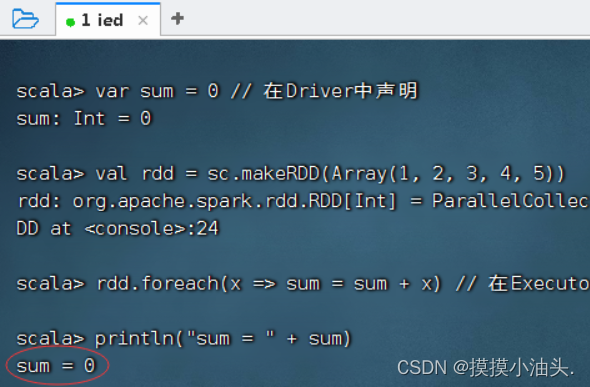
- 上述代码由于
sum变量在Driver中定义,而累加操作sum = sum + x会发送到Executor中执行,因此输出结果不正确。
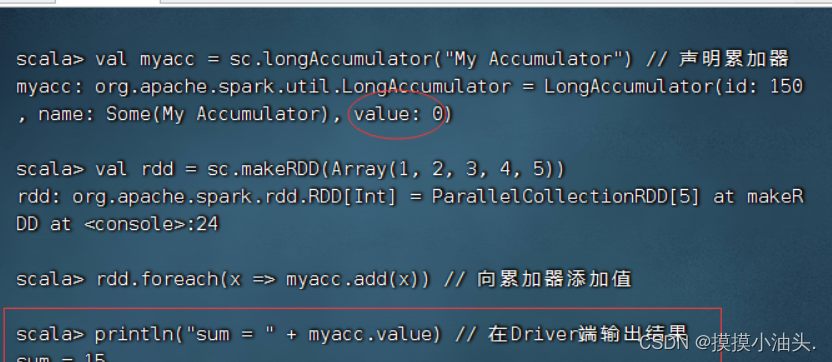
3、使用累加器
- 对一个整型数组求和
scala> val myacc = sc.longAccumulator("My Accumulator") // 声明累加器
scala> val rdd = sc.makeRDD(Array(1, 2, 3, 4, 5))
scala> rdd.foreach(x => myacc.add(x)) // 向累加器添加值
scala> println("sum = " + myacc.value) // 在Driver端输出结果
- 上述代码通过调用SparkContext对象的
longAccumulator ()方法创建了一个Long类型的累加器,默认初始值为0。也可以使用doubleAccumulator()方法创建Double类型的累加器。 - 累加器只能在
Driver端定义,在Executor端更新。Executor端不能读取累加器的值,需要在Driver端使用value属性读取。
相关文章:
Spark基础学习笔记----RDD检查点与共享变量
零、本讲学习目标 了解RDD容错机制理解RDD检查点机制的特点与用处理解共享变量的类别、特点与使用 一、RDD容错机制 当Spark集群中的某一个节点由于宕机导致数据丢失,则可以通过Spark中的RDD进行容错恢复已经丢失的数据。RDD提供了两种故障恢复的方式,…...
)
ES6(对象,数组,类型化数组)
对象 1,Object.is 用于判断两个值是否相等, 其内部实现类SameValue算法, 其行为类似于“” 但与“”不同的是 它认为两个NaN是相等的 而0,-0是不相等的 2,Object.assign 表示此方法可以将对象合并成一个 他的第一个…...
JVM系列-第12章-垃圾回收器
垃圾回收器 GC 分类与性能指标 垃圾回收器概述 垃圾收集器没有在规范中进行过多的规定,可以由不同的厂商、不同版本的JVM来实现。 由于JDK的版本处于高速迭代过程中,因此Java发展至今已经衍生了众多的GC版本。 从不同角度分析垃圾收集器,…...

零操作难度,轻松进行应用测试,App专项测试之Monkey测试完全指南!
目录 前言: 一、 Monkey测试的基础参数 1.1 事件类型参数: 1.2 覆盖包 1.3 事件数量 二、 Monkey测试的高级参数 2.1 稳定性级别 2.2 策略参数 2.3 包含选项参数 三、 附加代码 四、 总结 前言: 在移动应用的开发过程中࿰…...

Linux安装Docker(这应该是你看过的最简洁的安装教程)
Docker是一种开源的容器化平台,可以将应用程序及其依赖项打包成一个可移植的容器,以便在不同的环境中运行。Docker的核心是Docker引擎,它可以自动化应用程序的部署、扩展和管理,同时还提供了一个开放的API,可以与其他工…...

使用AES算法加密技术集成Java和Vue保护您的数据,代码示例和算法原理
1 算法的原理: AES是一种对称加密算法,也就是说加密和解密使用的是同一个密钥。其基本原理是将明文分成固定大小的块(128位),然后使用密钥对每个块进行加密操作,最后生成密文。在加密过程中,还需要使用一个向量(IV)来增加安全性,避免相同的明文块生成相同的密文块。…...
vcruntime140_1.dll丢失怎样修复,推荐4个vcruntime140_1.dll丢失的修复方法
vcruntime140_1.dll文件是Microsoft Visual C Redistributable for Visual Studio 2015运行库的一部分,它是一个用于支持Visual C构建的应用程序的系统文件。这个文件包含了在运行C程序时所需要的函数和类库,主要负责向应用程序提供运行时环境。如果电脑…...
快来试试这几个简单好用的手机技巧吧
技巧一:相机功能 苹果手机的相机功能确实非常出色,除了出色的像素之外,还有许多其他实用功能可以提升拍摄体验。 这些相机功能提供了更多的选择和便利性,使用户能够更好地适应不同的拍摄需求。 自拍功能:通过选择自…...
OneDrive同步角标消失 - 解决方案
问题 在电脑端使用OneDrive时,文件管理器OneDrive文件夹内的文件会在左下角显示同步状态,如下图。若没有显示同步角标,则此功能出现异常,下文介绍如何显示同步角标。 值得一提的是,同步角标只起到显示作用࿰…...
自学网络安全【黑客】,一般人我劝你还是算了吧
前言:我是劝一般人算了,看你是一般人还是。。。 一、网络安全学习的误区 1.不要试图以编程为基础去学习网络安全2.不要刚开始就深度学习网络安全3.收集适当的学习资料4.适当的报班学习二、学习网络安全的些许准备 1.硬件选择2.软件选择3.外语能力三、网…...

Java集合工具:first和last
在平常开发过程中,我们经常会遇到截取列表片段的需求,比如取列表中前4个元素、取后四个元素。Java的List提供了subList方法,可以用来完成这些工作,但是使用起来并没有那么便利,比如取前四个元素: list.sub…...

leetcode 905. 按奇偶排序数组
题目描述解题思路执行结果 leetcode 905. 按奇偶排序数组 题目描述 按奇偶排序数组 给你一个整数数组 nums,将 nums 中的的所有偶数元素移动到数组的前面,后跟所有奇数元素。 返回满足此条件的 任一数组 作为答案。 示例 1: 输入:…...
密码学安全性证明(一)Cramer-Shoup密码系统
Cramer-Shoup密码系统来自于A Practical Public Key CryptosystemProvably Secure against Adaptive ChosenCiphertext Attack这篇论文 CDH问题回顾: 已知(g,g^x, gk)能否计算gxk DDH问题回顾: 已知(g,g^x, g^k ,D)能否判断D是否等于g^xk 注意…...
)
Asp.net Core系列学习(1)
Asp.net Core 6系列学习 文章目录 Asp.net Core 6系列学习Asp.net Core 概述一、在 ASP.NET 4.x 和 ASP.NET Core 之间进行选择二、适用于服务器应用的 .NET 与 .NET Framework三、ASP.NET Core Web UI1.服务器和客户端呈现 UI 的优势和成本2.服务器呈现的 UI 四、可用的 ASP.N…...
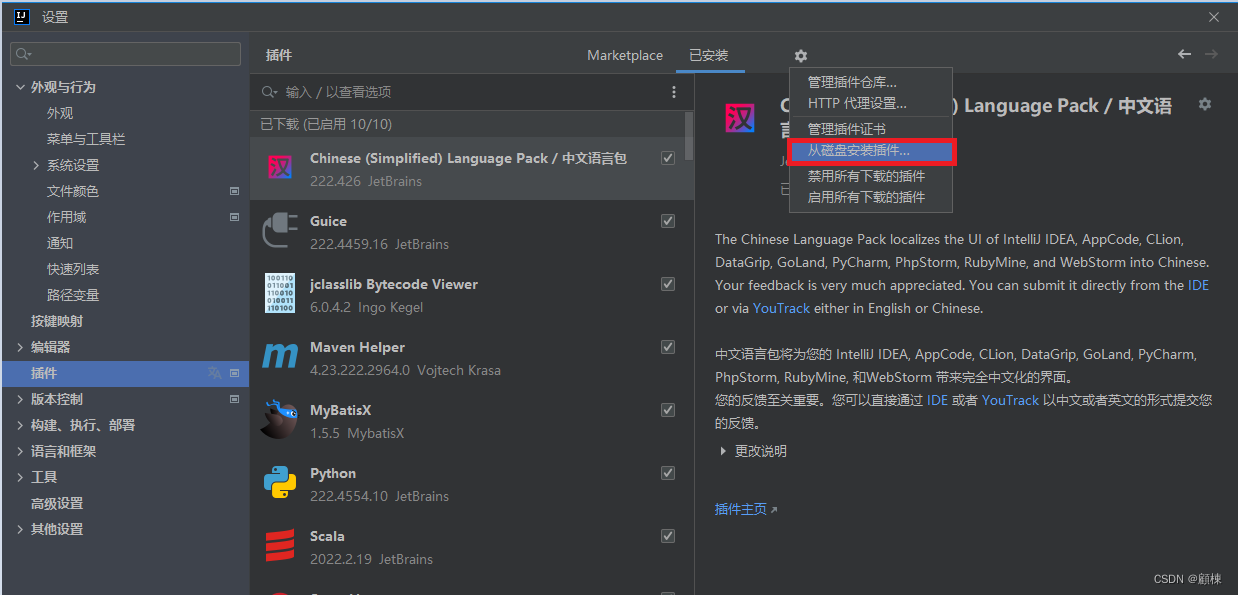
IDEA 2022.2 安装以及自定义优化
IDEA2022.2 安装以及自定义优化 文章目录 IDEA2022.2 安装以及自定义优化安装图解获取激活码自定义优化文件编码设置设置类文档注释和方式注释模板方法分割线 常用插件离线安装 安装图解 静默卸载(旧版本的设置和配置将不会被删除) 获取激活码 略…...
)
【华为OD机试真题2023B卷 JAVA】阿里巴巴找黄金宝箱(II)
华为OD2023(B卷)机试题库全覆盖,刷题指南点这里 阿里巴巴找黄金宝箱(II) 知识点数组哈希表优先级队列 时间限制:1s 空间限制:256MB 限定语言:不限 题目描述: 一贫如洗的樵夫阿里巴巴在去砍柴的路上,无意中发现了强盗集团的藏宝地,藏宝地有编号从0~N的箱子,每个箱子上…...
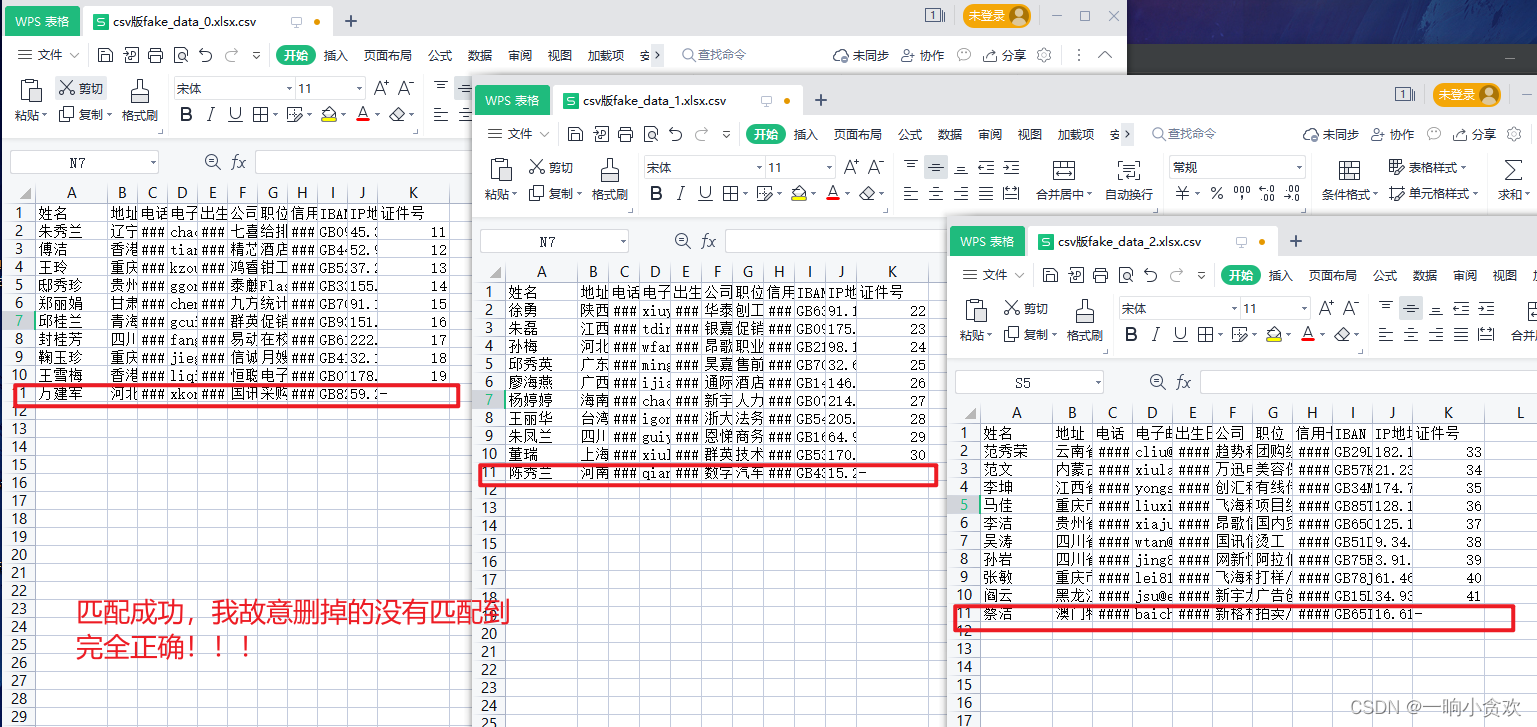
Python对Excel文件多表对多表之间的匹配(两种不同表头)——之json版
首先Excel文件多表对多表之间的匹配(VLOOKUP),有多种办法, 1:将Excel文件导入Mysql或其他数据库,然后将两种表合并成一张表,接着用数据库匹配 2:将两种表内容,复制粘贴到一起,各自分别保存成一张表…...
shiro环境搭建
源码部署 这种方法相对复杂,如果不需要分析源码直接用docker就行 前置条件:Maven Ideal Tomcat 下载方式1:https://codeload.github.com/apache/shiro/zip/shiro-root-1.2.4,然后将文件夹导入ideal下载方式2:将shiro…...
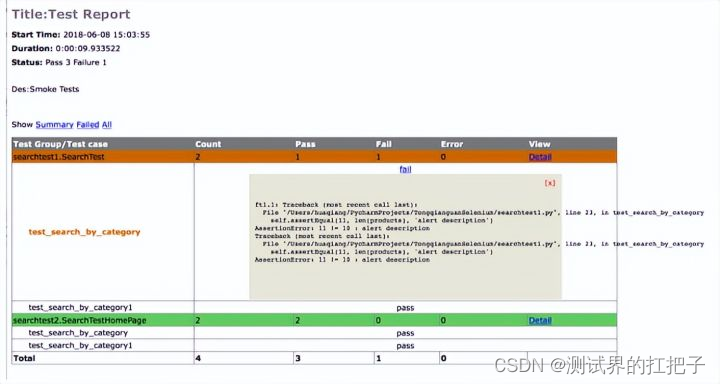
一文读懂selenium自动化测试(基于Python)
前言 我们今天来聊聊selenium自动化测试,我们都知道selenium是一款web自动化测试的工具,它应该如何去运用呢?我们接着看下去。 1、Selenium简介: 1.1 Selenium: Selenium是一款主要用于Web应用程序自动化测试的工具集合。Sele…...

如何高效地在网上找开源项目
开源项目是发展技能、分享想法和成为开发社区一员的好方法。开源意味着软件功能背后的源代码与所有想要阅读它的人公开共享。这意味着你可以准确地看到一个系统是如何工作的——一旦你愿意冒险,就为它做出贡献。除了向所有人开放贡献外,这种开放代码库通…...

UE5 CPU瓶颈定位实战:用ProfileCPU精准揪出Game线程卡顿根因
1. 这不是“点开就看”的性能分析,而是UE5里真正能救命的CPU瓶颈定位术在UE5项目做到中后期,你肯定经历过那种“明明没加多少新功能,帧率却从60掉到35,Editor卡得像PPT”的窒息时刻。打开Stat Unit,看到Game线程时间飙…...

SSH Host key verification failed 原因与安全处理指南
1. 这个报错不是故障,而是SSH在认真履职“Host key verification failed”——第一次看到这个提示时,我正远程部署一个客户服务器,敲完ssh user192.168.3.45回车,终端突然卡住两秒,然后跳出这行红字,后面还…...

如何用OneNote Markdown插件快速提升笔记效率:终极指南
如何用OneNote Markdown插件快速提升笔记效率:终极指南 【免费下载链接】NoteWidget Markdown add-in for Microsoft Office OneNote 项目地址: https://gitcode.com/gh_mirrors/no/NoteWidget 还在为OneNote复杂的格式调整而烦恼吗?想象一下&…...

Java的背景知识及快速入门
Java的背景知识1.Java的历史知识Java是哪家公司的产品?Java是美国Sun(Stanford University Network,斯坦福大学网络公司)公司在1995年推出的一 门计算机高级编程语言。但是在2009年是Sun公司被Oracle(甲骨文࿰…...

MySQL JSON 类型操作:从入门到不踩坑
开场白 MySQL 5.7 加了 JSON 类型之后,很多人觉得终于可以在关系型数据库里存 JSON 了,不用再拆表了。但说实话,我一开始用 JSON 类型的时候也没少踩坑——查询语法记不住、索引不会建、JSON 路径表达式写错……后来用多了才发现,…...

AI写作辅助平台8款AI写作辅助软件梯队榜,毕业护航!
论文选题毫无头绪,文献检索耗时费力,格式排版反复修改? 查重率居高不下,写作思路始终不畅,时间紧迫却无从下手? 面对繁杂的学术任务,你是否也感到力不从心? 别担心!AI论文…...

通过 curl 命令快速测试 Taotoken 不同模型的对话效果
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过 curl 命令快速测试 Taotoken 不同模型的对话效果 在开发或调试大模型应用时,有时我们可能没有现成的 SDK 环境&am…...

Grafana告警规则配置实战
Grafana告警规则配置实战 一、Grafana告警概述 Grafana提供强大的告警功能,可以基于Prometheus等数据源触发告警通知。 1.1 告警流程 ┌────────────────────────────────────────────────────────────…...

Label Studio数据标注工具:从安装到实战的完整指南
Label Studio数据标注工具:从安装到实战的完整指南 【免费下载链接】label-studio Label Studio is a multi-type data labeling and annotation tool with standardized output format 项目地址: https://gitcode.com/GitHub_Trending/la/label-studio Labe…...

如何快速掌握游戏MOD制作:LSLib开源工具箱的终极指南
如何快速掌握游戏MOD制作:LSLib开源工具箱的终极指南 【免费下载链接】lslib Tools for manipulating Divinity Original Sin and Baldurs Gate 3 files 项目地址: https://gitcode.com/gh_mirrors/ls/lslib 你是否曾经梦想过修改《神界原罪》或《博德之门3》…...