打开数据结构大门——实现小小顺序表
文章目录
- 前言
- 顺序表的概念及分类
- 搭建项目(Seqlist)
- :apple:搭建一个顺序表结构&&定义所需头文件&&函数
- :banana:初始化
- :pear:打印
- :watermelon:数据个数
- :smile:检查容量
- :fireworks:判空
- :tea:在尾部插入数据
- :tomato:在尾部删除数据
- :lemon:在头部插入数据
- :pineapple:在头部删除数据
- :orange:在任意位置插入数据
- :peach:将任意位置的数据删除
- :strawberry:查找数据
- :cucumber:修改数据
- :carrot:顺序表的销毁
- 完整代码
- 写在最后
前言
- 刚刚认识了一门C语言,现在即将走入一个新的世界——数据结构,这是对之前所学知识的检验也是一种对自我的提升,而恰好顺序表又是数据结构的入门课,今天让咱们一起来认识它吧!
- 通过对顺序表的学习咱们才能慢慢了解啥是数据结构,会对数据结构有一个初步的认识,同时明白它在咱们以后的学习中有多么重要。
- 相信大家对之前的通讯录还有印象吧,总体来说跟通讯录区别不大;也就相当于是对通讯录的一个复习巩固吧。
- 顺序表的实质就是在一个数组上进行增删查改等等一系列操作。
顺序表的概念及分类
将一个线性表存储到计算机中,可以采取很多种不同的方法,其中既简单有自然的方法是顺序存储方法,即把线性表的结点按逻辑顺序依次存放到一组地址连续的粗出单元里,用这种方法存储的线性表简称为顺序表。
搭建项目(Seqlist)
- 实现一个顺序表需要三个文件:包括一个后缀为 .h的文件Seqlist.h来存放项目所需的头文件、结构体声明、宏定义和函数的声明;一个 .c为后缀的文件 Seqlist.c来实现各个函数的接口;一个.c为后缀的文件Test.c来测试各个函数。在 Test.c和 Seqlist.c文件前包含 “Seqlist.h”,就能将这三个文件链接起来。

🍎搭建一个顺序表结构&&定义所需头文件&&函数
用C语言,顺序表可定义如下:
上代码:
typedef int SLDataType;
typedef struct SepList
{SLDataType* a;int size; //有效数据个数int capacity; // 容量
}SL;
#pragma once#include <stdio.h>
#include <stdbool.h>
#include <stdlib.h>
#include <assert.h>
//初始化
void SLInit(SL* ps1);//检查容量是否超过
void SLCheckCapacity(SL* ps1);//释放空间
void SLDestroy(SL* ps1);//打印
void SLPrint(SL* ps1);//尾插
void SLPushBack(SL* ps1, SLDataType x);
//尾删
void SLPopBack(SL* ps1);
//头插
void SLPushFront(SL* ps1, SLDataType x);
//头插
void SLPopFront(SL* ps1);//任意位置插入
void SLInsert(SL* ps1, int pos, SLDataType x);
//任意位置删除
void SLErase(SL* ps1, int pos);bool SLEmpty(SL* ps1);int SLFind(SL* ps1, SLDataType x);void SLModify(SL* ps1, int pos, SLDataType x);
🍌初始化
- 定义好这些函数之后,就要对顺序表进行初始化了。因为以上只是定义了顺序表中的元素并未进行初始化,咱们的第一步就是要对这些元素进行初始化。
- 初始化的内容就是将开辟的数组置空,给数据个数的值赋为0,给容量的大小也赋值为0。 这里我们还需要注意一下的就是因为我们的函数传参会用到一级指针,所以为了保险起见,我们可以用暴力的方法来检查是否为空指针。还可以给大家一个小建议:凡是遇到指针就要判断是否为空。
- 在初始化之前我们还可以开辟一点点空间,若指针为空我们还可以perror一下,报告文件出错的位置和原因。
上代码:
void SLInit(SL* ps1)
{assert(ps1);ps1->a = (SLDataType*)malloc(sizeof(SLDataType) * 4);if (ps1->a == NULL){perror("malloc fail");return;}ps1->size = 0;ps1->capacity = 4;
}
🍐打印
- 将打印这个函数放在前面是为了让我们实现一个函数就能马上进行打印测试,当项目大时会比较方便。因为这个函数可以让我们直观的看到我们各个函数的实现的结果,并且发现其中的问题。
上代码:
void SLPrint(SL* ps1)
{assert(ps1);for (int i = 0; i < ps1->size; i++){printf("%d ", ps1->a[i]);}printf("\n");
}
🍉数据个数
- 这个函数的功能很简单就只需要返回数据的个数size就行了。
上代码:
int SLsize(SL* ps1)
{assert(ps1);return ps1->size;
}
😄检查容量
- 把这个功能单独拿出来能够方便我们去调用,因为在后续会多次用到这个函数。
- 这个函数的作用就是在我们的顺序表插入数据之前,要检验我们当前的容量够不够,若不够,则需要扩容,否则就会非法访问空间的问题,执行程序时终端就会报错。
- 如何判断容量是否已满呢?因为我们前面设置了一个size函数用来统计个数,所以只需要size等于capacity,就能够说明当前容量已经满了,接下来再插入数据就需要扩容了。我们就简单的设置每次扩容增加SLDataType* 4的大小。
- 还需注意:别忘了每次插入数据之前都要进行此操作来检查容量。
上代码:
void SLCheckCapacity(SL* ps1)
{//如果满了需要增容assert(ps1);if (ps1->size == ps1->capacity){SLDataType* tmp = (SLDataType*)realloc(ps1->a, sizeof(SLDataType) * ps1->capacity * 2);if (tmp == NULL){perror("realloc fail");return;}ps1->a = tmp;ps1->capacity *= 2;}
}
🎆判空
- 这一步操作算是很简单的一步了,只需要判断通讯录是否为空,若为空,返回真;否则,返回假。
上代码:
bool SLEmpty(SL* ps1)
{assert(ps1);return ps1->size == 0;
}
🍵在尾部插入数据
- 在尾部插入数据就是在当前开辟空间的末尾依次向后插入数据,竟然是插入数据,那就不能忘了要检查容量,操作也很简单,只需要调用前面我们实现的函数即可。将需要插入的数插入进去,记得size++,就没啦。
上代码:
void SLPushBack(SL* ps1,SLDataType x)
{assert(ps1);SLCheckCapacity(ps1);ps1->a[ps1->size++] = x;
}
🍅在尾部删除数据
- 尾部删除其实也会有两种具体情况嘛,首先,如果顺序表中没有数据,还需要删除吗?那不妨直接用(assert)暴力检查,size不能为0或者说size大于0,直接判空。
- 如果有数据呢?那就要进行删除咯。删除其实真的不复杂,只需要将size–即可,也不需要将删除的那个位置的数据初始化为0了,因为我们最后打印的时候并不会打印那个数据。但是咱们也不采取直接释放当前位置空间(free),因为顺序表是基于数组实现的,而数组是一段连续的内存空间。当删除一个元素时,如果直接将该位置的空间释放掉,那么该位置之后的所有元素都需要向前移动一位,这样的操作是非常耗时的,效率很低。
上代码:
void SLPopBack(SL* ps1)
{assert(ps1->size > 0);ps1->size--;
}
🍋在头部插入数据
- 其实咱们可以顺着尾插的思路想象一下,头插应该要比尾插复杂吧。因为咱们始终要知道顺序表是基于数组实现的,而数组又是一段连续的空间,所以头插需要将插入元素外的所有元素都向后移动一位,从而腾出空间给新元素。
- 咱们再仔细想想,要是顺序表中的元素的量很大时,头插的效率岂不是会变得非常低,这也是顺序表最大的缺点。
- 在移动数据的时候是从最后一个元素开始移动,直到移动完第一个数据为止,然后再将元素插入即可,当然也别忘了size++。
上代码:
void SLPushFront(SL* ps1, SLDataType x)
{assert(ps1);SLCheckCapacity(ps1);for (int i = ps1->size; i > 0; i--){ps1->a[i] = ps1->a[i - 1];}ps1->a[0] = x;ps1->size++;
}
🍍在头部删除数据
- 和尾删一样,首先要判断是否为空,用assert暴力检查一下。
- 其实头部的删除并没有像头部插入那样麻烦,只要是删除就不会太麻烦,试想一下是拥有容易还是失去容易呢?那当然是失去显得格外容易。
- 让每个元素向前移动,覆盖前一个,只要size还大于1,就继续,当然不敢忘了将size–。
上代码:
void SLPopFront(SL* ps1)
{assert(ps1);int start = 1;while (start < ps1->size){ps1->a[start - 1] = ps1->a[start];start++;}ps1->size--;
}
🍊在任意位置插入数据
- 老规矩首先暴力检查容量。
- 与头部插入的思路基本一样,但是这里会多一个数据,用来识别插入的位置,当然这里的数字是代表数组的下标,并不是代表的数据的实际位置。其他的逻辑操作就和头部插入一样啦。当然这里也别忘了要size++。
上代码:
void SLInsert(SL* ps1, int pos, SLDataType x)
{assert(0 <= pos && pos <= ps1->size);SLCheckCapacity(ps1);int end = ps1->size - 1;while (end >= pos){ps1->a[end + 1] = ps1->a[end];--end;}ps1->a[pos] = x;ps1->size++;
}🍑将任意位置的数据删除
- 还是老规矩,是删除就要用assert来一顿暴力检查。
- 删除数据,就是将pos位置后面的数据依次向前移动,直到pos位置的数据被覆盖。
- 最后也别忘了size–。
上代码:
void SLErase(SL* ps1, int pos)
{assert(0 <= pos && pos < ps1->size);assert(!SLEmpty(ps1));int start = pos + 1;while (start < ps1->size){ps1->a[start - 1] = ps1->a[start];++start;}ps1->size--;
}
🍓查找数据
- 查找数据的本质就是将整个数据表遍历一遍,如果找到了就返回下标;没有找到就返回-1。
int SLFind(SL* ps1, SLDataType x)
{assert(ps1);for (int i = 0; i < ps1->size; i++){if (ps1->a[i] == x){return i;}}return -1;
}🥒修改数据
- 修改数据首先要找到数据的位置,将你想修改的位置输入,若传入的pos不正确直接用assert暴力检查,若正确,再输入修改后的新数据,然后在pos-1位置修改就行。
void SLModify(SL* ps1, int pos, SLDataType x)
{assert(ps1);assert(0 <= pos && pos < ps1->size);ps1->a[pos] = x;
}
🥕顺序表的销毁
- 销毁其实听起来有点像删除,其实这里也需要用assert暴力检查下,若顺序表本身为空就不需要销毁。
- 如果顺序表不为空,则需要依次销毁顺序表中存储的所有元素。但这里的销毁就比较粗暴了,直接将size大小给为0,再将容量大小给为0,将数组的空间释放掉,然后再置空。
void SLDestroy(SL* ps1)
{assert(ps1);free(ps1->a);ps1->a = NULL;ps1->size = 0;ps1->capacity = 0;
}
完整代码
Seqlist.h
// 防止Seqlist.h被重复包含
#pragma once// 以下是所需头文件:
// 输入和输出所需头文件
#include <stdio.h>
// realloc,free所需头文件
#include <stdbool.h>
// 判空所需头文件
#include <stdlib.h>
// 断言所需头文件
#include <assert.h>// 顺序表的数据类型
typedef int SLDataType;//顺序表的结构体
typedef struct SepList
{SLDataType* a;// a 是指向一个在堆上的空间int size; //有效数据个数int capacity; // 容量
}SL;//初始化
void SLInit(SL* ps1);//打印
void SLPrint(SL* ps1);//数据个数
int SLSize(SL* ps1);//检查容量是否超过
void SLCheckCapacity(SL* ps1);//判空
bool SLEmpty(SL* ps1);//尾插
void SLPushBack(SL* ps1, SLDataType x);//尾删
void SLPopBack(SL* ps1);//头插
void SLPushFront(SL* ps1, SLDataType x);//头删
void SLPopFront(SL* ps1);//任意位置插入
void SLInsert(SL* ps1, int pos, SLDataType x);//任意位置删除
void SLErase(SL* ps1, int pos);//查找数据,返回对应位置
int SLFind(SL* ps1, SLDataType x);//修改数据
void SLModify(SL* ps1, int pos, SLDataType x);//销毁顺序表
void SLDestroy(SL* ps1);Seqlist.c
#include "SeqList.h"//顺序表初始化
void SLInit(SL* ps1)
{assert(ps1);ps1->a = (SLDataType*)malloc(sizeof(SLDataType) * 4);if (ps1->a == NULL){perror("malloc fail");return;}ps1->size = 0;ps1->capacity = 4;
}//打印
void SLPrint(SL* ps1)
{assert(ps1);for (int i = 0; i < ps1->size; i++){printf("%d ", ps1->a[i]);}printf("\n");
}//数据个数
int SLSize(SL*ps1)
{assert(ps1);return ps1->size;
}//检查容量
void SLCheckCapacity(SL* ps1)
{//如果满了需要增容assert(ps1);if (ps1->size == ps1->capacity){SLDataType* tmp = (SLDataType*)realloc(ps1->a, sizeof(SLDataType) * ps1->capacity * 2);if (tmp == NULL){perror("realloc fail");return;}ps1->a = tmp;ps1->capacity *= 2;}
}//判空
bool SLEmpty(SL* ps1)
{assert(ps1);return ps1->size == 0;
}//尾部插入
void SLPushBack(SL* ps1,SLDataType x)
{assert(ps1);SLCheckCapacity(ps1);ps1->a[ps1->size++] = x;
}//尾部删除
void SLPopBack(SL* ps1)
{assert(ps1->size > 0);ps1->size--;
}//头部插入
void SLPushFront(SL* ps1, SLDataType x)
{assert(ps1);SLCheckCapacity(ps1);for (int i = ps1->size; i > 0; i--){ps1->a[i] = ps1->a[i - 1];}ps1->a[0] = x;ps1->size++;
}//头部删除
void SLPopFront(SL* ps1)
{assert(ps1);int start = 1;while (start < ps1->size){ps1->a[start - 1] = ps1->a[start];start++;}ps1->size--;
}//任意位置插入数据
void SLInsert(SL* ps1, int pos, SLDataType x)
{assert(0 <= pos && pos <= ps1->size);SLCheckCapacity(ps1);int end = ps1->size - 1;while (end >= pos){ps1->a[end + 1] = ps1->a[end];--end;}ps1->a[pos] = x;ps1->size++;
}//任意位置删除数据
void SLErase(SL* ps1, int pos)
{assert(0 <= pos && pos < ps1->size);assert(!SLEmpty(ps1));int start = pos + 1;while (start < ps1->size){ps1->a[start - 1] = ps1->a[start];++start;}ps1->size--;
}//查找数据
int SLFind(SL* ps1, SLDataType x)
{assert(ps1);for (int i = 0; i < ps1->size; i++){if (ps1->a[i] == x){return i;}}return -1;
}//修改数据
void SLModify(SL* ps1, int pos, SLDataType x)
{assert(ps1);assert(0 <= pos && pos < ps1->size);ps1->a[pos] = x;
}//销毁顺序表
void SLDestroy(SL* ps1)
{assert(ps1);free(ps1->a);ps1->a = NULL;ps1->size = 0;ps1->capacity = 0;
}Test.c
#include "SeqList.h"void TestSeqList1()
{SL s;SLInit(&s);SLPushBack(&s, 1);SLPushBack(&s, 2);SLPushBack(&s, 3);SLPushBack(&s, 4);SLPushBack(&s, 5);SLPushBack(&s, 6);SLPrint(&s);printf("\n");SLPopBack(&s);SLPrint(&s);SLPopBack(&s);SLPrint(&s);SLPopBack(&s);SLPrint(&s);SLPopBack(&s);SLPrint(&s);SLPopBack(&s);SLPrint(&s);SLPopBack(&s);SLPrint(&s);SLDestroy(&s);
}void TestSeqList2()
{SL s;SLInit(&s);SLPushFront(&s, 1);SLPushFront(&s, 2);SLPushFront(&s, 3);SLPushFront(&s, 4);SLPushFront(&s, 5);SLPushFront(&s, 6);SLPrint(&s);SLPopFront(&s);SLPrint(&s);SLPopFront(&s);SLPrint(&s);SLPopFront(&s);SLPrint(&s);SLPopFront(&s);SLPrint(&s);SLPopFront(&s);SLPrint(&s);SLPopFront(&s);SLPrint(&s);SLDestroy(&s);
}void TestSeqList3()
{SL s;SLInit(&s);SLInsert(&s, 0, 1);SLPrint(&s);SLInsert(&s, 1, 11);SLPrint(&s);SLInsert(&s, 1, 111);SLPrint(&s);SLInsert(&s, 1, 1111);SLPrint(&s);SLInsert(&s, 1, 11111);SLPrint(&s);SLErase(&s, s.size - 1);SLPrint(&s);SLErase(&s, s.size - 1);SLPrint(&s);SLErase(&s, s.size - 1);SLPrint(&s);SLErase(&s, s.size - 1);SLPrint(&s);SLErase(&s, s.size - 1);SLPrint(&s);SLDestroy(&s);
}void TestSeqList4()
{SL s;SLInit(&s);SLPushBack(&s, 1);SLPushBack(&s, 2);SLPushBack(&s, 3);SLPushBack(&s, 4);SLPushBack(&s, 5);SLPushBack(&s, 6);SLPrint(&s);SLModify(&s, SLFind(&s, 1), 999);SLPrint(&s);SLModify(&s, SLFind(&s, 6), 999);SLPrint(&s);SLDestroy(&s);
}int main()
{TestSeqList1();TestSeqList2();TestSeqList3();TestSeqList4();return 0;
}
写在最后
在学习的过程中,我也了解到了顺序表的一些特点和优缺点。学到这里也初步见识了数据结构的样子,同时,我也深深感受到了学习的乐趣。长长的路我们慢慢的走,还需更加努力!
感谢各位来阅读本小白的博客,其中有错误的地方请大家明确指出喔,我会一直汲取,慢慢改正的!
相关文章:
打开数据结构大门——实现小小顺序表
文章目录 前言顺序表的概念及分类搭建项目(Seqlist):apple:搭建一个顺序表结构&&定义所需头文件&&函数:banana:初始化:pear:打印:watermelon:数据个数:smile:检查容量:fireworks:判空:tea:在尾部插入数据:tomato:在尾部删除数据:lemon:在…...

一.RxJava
1.RxJava使用场景 RxJava核心思想 Rx思维:响应式编程,从起点到终点,中途不能断掉,并且可以在中途添加拦截. 生活中的例子: 起点(分发事件,我饿了)->下楼->去餐厅->点餐->终点(吃饭,消费事件) 程序中的例子: 起点(分发事件,点击登录)->登录API->请求服务器-…...

如何使用 VSCode 软件运行C代码
VSCode 的下载和扩展的配置可以参考文章:VSCode 的安装与插件配置。 VSCode 是很好用的编辑器,通过给其配置 MinGW-w64 插件就可以在它上面编译运行C代码了。 在没有配置 MinGW-w64 插件时,在 VSCode 中运行下面的代码后打印如下图所示。 这…...
C# 调用Matlab打包的 DLL文件(傻瓜式操作)
1、准备Matlab代码 2. 打包 在matlab命令行窗口输入deploytool,打开MATLAB Complier,选择Library Compiler 在TYPE中选择.NET Assembly;在EXPORTED FUNCTIONS中选择要打包的文件;可以选择为自己打包的文件自定义NameSpace名称,本例中将NameSpace定义为…...

微信小程序学习实录3(环境部署、百度地图微信小程序、单击更换图标、弹窗信息、导航、支持腾讯百度高德地图调起)
百度地图微信小程序 一、环境部署1.need to be declared in the requiredPrivateInfos2.api.map.baidu.com 不在以下 request 合法域名3.width and heigth of marker id 9 are required 二、核心代码(一)逻辑层index.js(二)渲染层…...
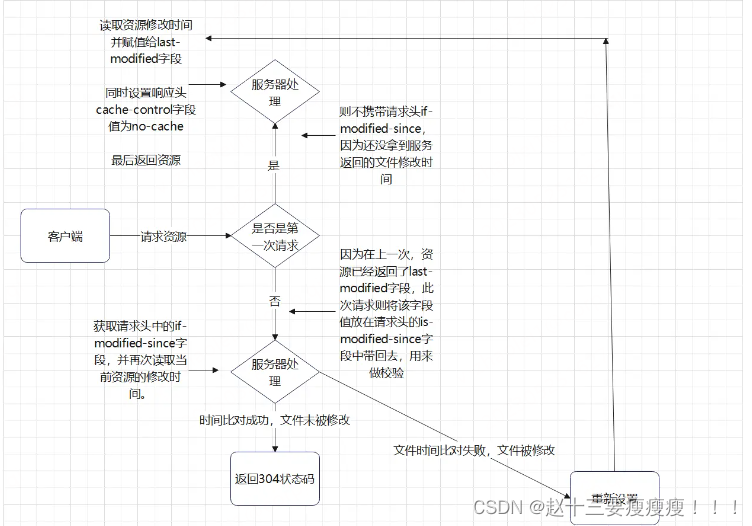
【面试题】中高级前端工程师都需要熟悉的技能--前端缓存
前端缓存 一、前言二、web缓存分类1. HTTP缓存:2. 浏览器缓存:3. Service Worker:4. Web Storage缓存:5. 内存缓存: 三、http缓存详解1、http缓存类型a. 基于有效时间的缓存控制:b. 基于资源标识的缓存&…...
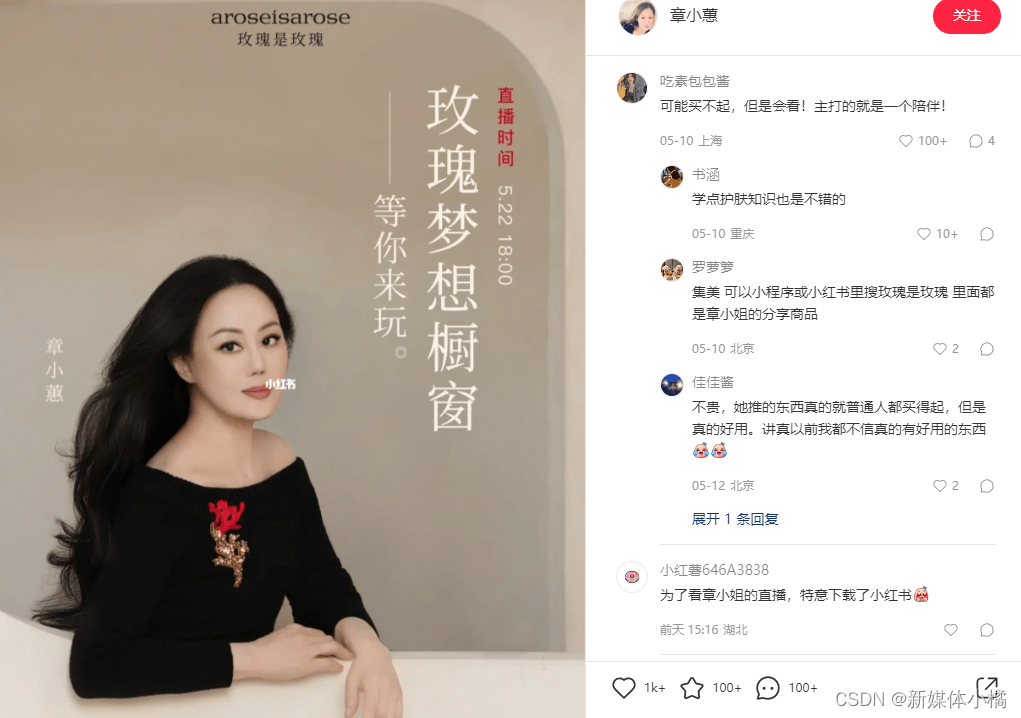
小红书数据分析:首播卖6亿,小红书直播开启新纪元!
5月22日,章小蕙在小红书开启了第一场带货直播。继董洁之后,小红书又迎来一位超级带货KOL。 据千瓜数据显示,相关话题#章小蕙小红书直播#上线不到30天,话题浏览量就高达2814.89万,笔记互动量达22.24万。 图 | 千瓜数据…...

Weex中,关于组件的水平排列竖直排列居中对齐居左对齐居右对齐低部对齐顶部对齐布局对齐说明
容器内子组件排列方向 子组件竖直方向排列(默认) 子组件水平方向排列 <style> .container {flex-direction: row;direction: ltr; } </style>子组件在父组件容器中的对齐方式 我们主要使用两个属性实现子组件在父组件的对齐方式ÿ…...
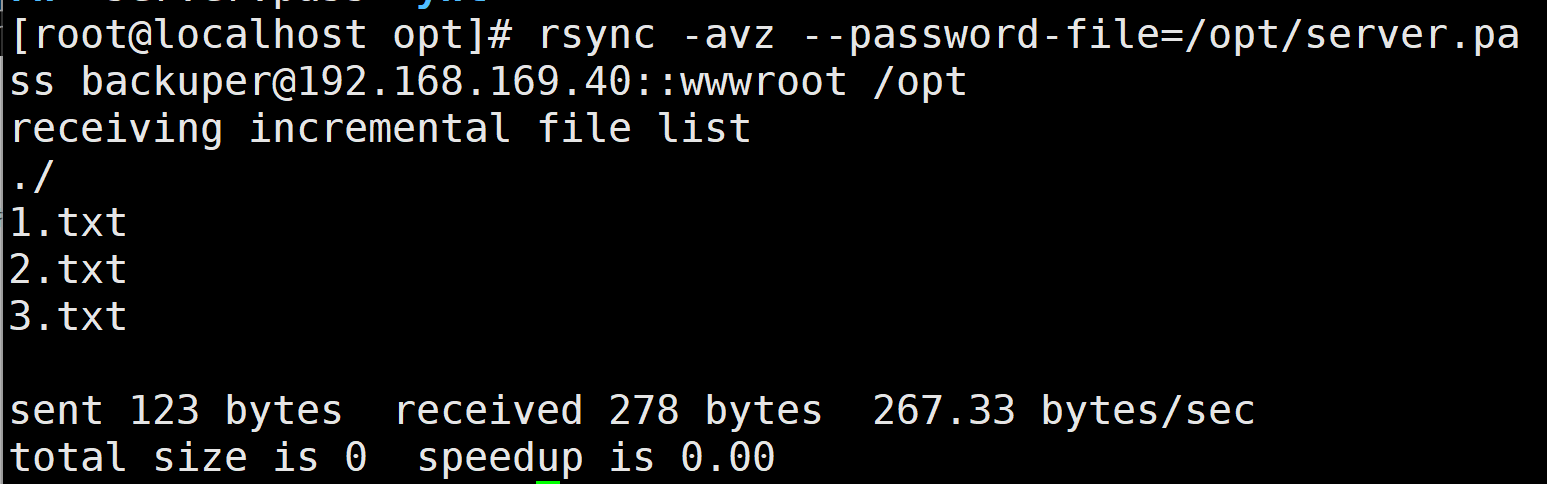
服务(第二十八篇)rsync
配置rsync源服务器: #建立/etc/rsyncd.conf 配置文件 vim /etc/rsyncd.conf #添加以下配置项 uid root gid root use chroot yes #禁锢在源目录 address 192.168.80.10 …...
)
Vue 3 第二十五章:插件(Plugins)
文章目录 1. 创建插件2. 使用插件3. 插件选项 Vue 3 的插件系统允许我们扩展 Vue 的功能和行为,并且可以在多个组件之间共享代码和逻辑。插件可以用于添加全局组件、指令、混入、过滤器等,并且可以在应用程序启动时自动安装。 1. 创建插件 创建插件需要…...
 : installd)
Android 系统内的守护进程 - main类服务(3) : installd
声明 只要是操作系统,不用说的就是其中肯定会运行着一些很多守护进程(daemon)来完成很多杂乱的工作。通过系统中的init.rc文件也可以看出来,其中每个service中就包含着系统后台服务进程。而这些服务被分为:core类服务(adbd/servicemanager/healthd/lmkd/logd/vold)和mai…...

华为OD机试真题 Java 实现【对称字符串】【2023Q2 200分】
一、题目描述 对称就是最大的美学,现有一道关于对称字符串的美学。 已知: 第 1 个字符串:R 第 2 个字符串:BR 第 3 个字符串:RBBR 第 4 个字符串:BRRBRBBR 第 5 个字符串:RBBRBRRBBRRBRBBR …...

day18文件上传下载与三层架构思想
servlet文件上传 注意事项:在写了响应后,若后面还需要执行代码,需要添加return; apach的servlet3.0提供了文件上传的功能. **在客户端中的jsp如何上传文件:**使用form标签 使用input标签type的file属性 form表单中的的enctype必须加:使用二进制的方式进行传输,否则不能进行…...

Async/await详解
一、概念与背景 他是在ES8被提出的一种异步方式,它其实是promise的一种语法糖 二、 Async关键字 async 关键字用于快速声明异步函数 ,可以用在函数声明、函数表达式、箭头函数和方法上 async function foo() {} let bar async function() {}; let…...
Mysql基础 — DDL、DML、DQL、DCL、函数、约束
文章目录 Mysql基础一、数据模型1.1 关系型数据库与非关系型数据库1.2 Mysql 数据模型 二、SQL2.1 SQL 通用语法2.2 SQL分类2.3 DDL2.3.1 数据库操作2.3.2 表操作 — 创建 & 查询2.3.3 表操作— 修改&删除2.3.4 数据类型2.3.4.1 数值类型2.3.4.2 字符串类型2.3.4.3 日期…...

中国移动董宁:深耕区块链的第八年,我仍期待挑战丨对话MVP
区块链技术对于多数人来说还是“新鲜”的代名词时,董宁已经成为这项技术的老朋友。 董宁2015年进入区块链领域,现任中国移动研究院技术总监、区块链首席专家。作为“老友”,董宁见证了区块链技术多个爆发式增长和平稳发展的阶段,…...

AI孙燕姿项目实现
最近在b站刷到很多关于ai孙笑川唱的歌曲,加上最近大火的ai孙燕姿, 这下“冷门歌手”整成热门歌手了 于是写下一篇文章, 如何实现属于的ai歌手。 注意滥用ai,侵犯他人的名誉是要承担法律责任的 下面是一些所需的文件链接ÿ…...

传统机器学习(六)集成算法(2)—Adaboost算法原理
传统机器学习(六)集成算法(2)—Adaboost算法原理 1 算法概述 Adaboost(Adaptive Boosting)是一种自适应增强算法,它集成多个弱决策器进行决策。 Adaboost解决二分类问题,且二分类的标签为{-1,1}。注:一定是{-1,1},不能是{0,1} …...

性能优化常用的技巧,你都知道吗?
在实际工作中,提升MySQL数据库的查询性能是非常重要的。除了基本的索引和查询优化技巧外,还有一些更深层次的优化方案可以进一步优化性能。 1. 数据库表设计优化 选择字段类型: 根据数据类型和范围,选择适当的字段类型。例如&am…...
机器学习——损失函数(lossfunction)
问:非监督式机器学习算法使用样本集中的标签构建损失函数。 答:错误。非监督式机器学习算法不使用样本集中的标签构建损失函数。这是因为非监督式学习算法的目的是在没有标签的情况下发现数据集中的特定结构和模式,因此它们依赖于不同于监督式…...

LSLib终极指南:轻松解锁《神界原罪》和《博德之门3》MOD制作之门
LSLib终极指南:轻松解锁《神界原罪》和《博德之门3》MOD制作之门 【免费下载链接】lslib Tools for manipulating Divinity Original Sin and Baldurs Gate 3 files 项目地址: https://gitcode.com/gh_mirrors/ls/lslib LSLib是一款专门为《神界原罪》系列和…...

CFD湍流模型不确定性量化:特征空间扰动框架原理与应用
1. 项目概述与核心挑战在计算流体力学(CFD)的工程实践中,我们常常面临一个核心困境:如何高效且可靠地预测复杂湍流?雷诺平均纳维-斯托克斯(RANS)模型因其在计算成本和工程实用性之间的绝佳平衡&…...

创业团队如何利用Taotoken管理多个AI模型的用量与成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 创业团队如何利用Taotoken管理多个AI模型的用量与成本 对于资源有限的创业团队而言,在快速迭代产品原型时,…...

构建多智能体系统时如何通过统一网关管理不同模型的调用与鉴权
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 构建多智能体系统时如何通过统一网关管理不同模型的调用与鉴权 在开发集成多个AI智能体的复杂系统时,工程师常常面临一…...
)
别再被离群点坑了!用Python+OpenCV手把手教你RANSAC直线拟合(附完整代码)
实战指南:用PythonOpenCV实现RANSAC直线拟合的完整流程在计算机视觉项目中,我们经常遇到需要从嘈杂数据中提取几何特征的情况。想象一下这样的场景:你从一张建筑图纸扫描件中提取了数百个边缘点,但扫描时的折痕、污渍导致30%的点位…...

解锁AMD Ryzen隐藏性能:一款开源调试工具如何让你成为硬件调优高手
解锁AMD Ryzen隐藏性能:一款开源调试工具如何让你成为硬件调优高手 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址…...

RAG:终结AI“一本正经胡说八道”,让AI回答问题不再答非所问!
本文用通俗易懂的方式解释了RAG技术,即“检索增强生成”,它通过为AI构建专属知识库,在回答问题时先检索相关信息再生成答案,有效解决AI“答非所问”和“幻觉”问题。文章详细介绍了RAG的工作原理、核心价值及实用场景,…...

GraphScale:解耦计算与存储,攻克十亿级图学习的内存与通信瓶颈
1. 项目概述:为什么我们需要一个全新的图学习框架?如果你在过去几年里尝试过处理一个真正“大”的图——比如用户关系网络、商品关联图或者学术引用网络——你大概率会和我有同样的感受:现有的工具在规模面前,显得力不从心。图神经…...

CSS Flexbox高级技巧:构建灵活的响应式布局
CSS Flexbox高级技巧:构建灵活的响应式布局 引言 Flexbox是CSS3引入的一维布局模型,它提供了强大的灵活布局能力。本文将深入探讨Flexbox的高级技巧和最佳实践,帮助你构建更优雅的响应式布局。 一、Flexbox核心概念回顾 .container {display:…...

如何三分钟搭建免费音乐聚合平台:MusicFree插件终极配置指南
如何三分钟搭建免费音乐聚合平台:MusicFree插件终极配置指南 【免费下载链接】MusicFreePlugins MusicFree播放插件 项目地址: https://gitcode.com/gh_mirrors/mu/MusicFreePlugins 还在为音乐会员费烦恼吗?想要一个真正免费、无广告的音乐播放体…...