机器学习——损失函数(lossfunction)
问:非监督式机器学习算法使用样本集中的标签构建损失函数。
答:错误。非监督式机器学习算法不使用样本集中的标签构建损失函数。这是因为非监督式学习算法的目的是在没有标签的情况下发现数据集中的特定结构和模式,因此它们依赖于不同于监督式学习的算法。因此,它们不会使用标签来训练模型。相反,它们使用不同的技术,例如聚类,降维和异常检测来发现数据中的模式和结构。
一、非监督式学习
非监督学习的训练样本没有已知标签,常需要通过非监督学习去发现样本间的结构关系。
非监督学习这块内容由两部分组成:K邻近法和主成分分析。
K-means
聚类是最常见的非监督学习应用。K-means是最常见的聚类学习算法。
K-means算法的输入包括:训练集样本,和需要划分的类别K。
二、什么是损失函数:
简单的理解就是每一个样本经过模型后会得到一个预测值,然后得到的预测值和真实值的差值就成为损失(当然损失值越小证明模型越是成功),我们知道有许多不同种类的损失函数,这些函数本质上就是计算预测值和真实值的差距的一类型函数,然后经过库(如pytorch,tensorflow等)的封装形成了有具体名字的函数。
三、为什么需要损失函数:
我们上文说到损失函数是计算预测值和真实值的一类函数,而在机器学习中,我们想让预测值无限接近于真实值,所以需要将差值降到最低(在这个过程中就需要引入损失函数)。而在此过程中损失函数的选择是十分关键的,在具体的项目中,有些损失函数计算的差值梯度下降的快,而有些下降的慢,所以选择合适的损失函数也是十分关键的。
四、损失函数通常使用的位置:
在机器学习中,我们知道输入的feature(或称为x)需要通过模型(model)预测出y,此过程称为向前传播(forward pass),而要将预测与真实值的差值减小需要更新模型中的参数,这个过程称为向后传播(backward pass),其中我们损失函数(lossfunction)就基于这两种传播之间,起到一种有点像承上启下的作用,承上指:接収模型的预测值,启下指:计算预测值和真实值的差值,为下面反向传播提供输入数据。
五、监督学习及其目标函数:
损失函数(loss function)是用来估量你模型的预测值f(x)与真实值Y的不一致程度,它是一个非负实值函数,通常使用L(Y, f(x))来表示,损失函数越小,模型的鲁棒性就越好。
损失函数是经验风险函数的核心部分,也是结构风险函数重要组成部分。
模型的结构风险函数包括了经验风险项和正则项,通常可以表示成如下式子(一般来说,监督学习可以看做最小化下面的目标函数):

式子左边表示经验风险函数,损失函数是其核心部分;式子右边是正则项。式子整体是结构风险函数,其由经验风险函数和正则项组成。
其中,第一项L(yi,f(xi;w)) 衡量我们的模型(分类或者回归)对第i个样本的预测值f(xi;w)和真实的标签yi之前的误差。因为我们的模型是要拟合我们的训练样本的,所以我们要求这一项最小。即前面的均值函数表示的是经验风险函数,L代表的是损失函数;
但正如上面说言,我们不仅要保证训练误差最小,我们更希望我们的模型测试误差小,所以我们需要加上第二项,也就是对参数w的规则化函数Ω(w)去约束我们的模型尽量的简单。即后面的Φ是正则化项(regularizer)或者叫惩罚项(penalty term),它可以是L1,也可以是L2,或者其他的正则函数。
整个式子表示的意思是找到使目标函数最小时的θ值。机器学习的大部分带参模型都和这个不但形似,而且神似,其实大部分无非就是变换这两项而已。
损失函数/loss函数
对于第一项Loss函数,如果是Square loss,那就是最小二乘;如果是Hinge Loss,那就是著名的SVM;如果是exp-Loss,那就是 Boosting;如果是log-Loss,那就是Logistic Regression;还有等等。不同的loss函数,具有不同的拟合特性,这个也得就具体问题具体分析的。
loss函数一般都是通过mle推导出来的。使用最大似然来导出代价函数的方法的一个优势是,它减轻了为每个模型设计代价函数的负担。明确一个模型p(y | x)则自动地确定了一个代价函数log p(y | x)。[深度学习]
下面主要列出几种常见的损失函数:
- 平方损失
- 0-1损失
- Log损失
- Hinge损失
- 指数损失
- 感知损失
平方损失函数(最小二乘法, Ordinary Least Squares )
最小二乘法是线性回归的一种,OLS将问题转化成了一个凸优化问题。在线性回归中,它假设样本和噪声都服从高斯分布(为什么假设成高斯分布呢?其实这里隐藏了一个小知识点,就是中心极限定理),最后通过极大似然估计MLE可以推导出最小二乘式子,即平方损失函数可以通过线性回归在假设样本是高斯分布的条件下推导得到。
最小二乘的基本原则是:最优拟合直线应该是使各点到回归直线的距离和最小的直线,即平方和最小。换言之,OLS是基于距离的,而这个距离就是我们用的最多的欧几里得距离。为什么它会选择使用欧式距离作为误差度量呢(即Mean squared error, MSE),主要有以下几个原因:
- 简单,计算方便;
- 欧氏距离是一种很好的相似性度量标准;
- 在不同的表示域变换后特征性质不变。
平方损失(Square loss)的标准形式
当样本个数为n时,此时的损失函数变为:
Y-f(X)表示的是残差,整个式子表示的是残差的平方和,而我们的目的就是最小化这个目标函数值,也就是最小化残差的平方和(residual sum of squares,RSS)。
而在实际应用中,通常会使用均方差(MSE)作为一项衡量指标
上面提到了线性回归,这里额外补充一句,我们通常说的线性有两种情况,一种是因变量y是自变量x的线性函数,一种是因变量y是参数的线性函数。在机器学习中,通常指的都是后一种情况。
相关文章:
机器学习——损失函数(lossfunction)
问:非监督式机器学习算法使用样本集中的标签构建损失函数。 答:错误。非监督式机器学习算法不使用样本集中的标签构建损失函数。这是因为非监督式学习算法的目的是在没有标签的情况下发现数据集中的特定结构和模式,因此它们依赖于不同于监督式…...
小航助学2022年NOC初赛图形化(小高组)(含题库答题软件账号)
需要在线模拟训练的题库账号请点击 小航助学编程在线模拟试卷系统(含题库答题软件账号)_程序猿下山的博客-CSDN博客 单选题3.0分 删除编辑 答案:C 第1题如果要控制所有角色一起朝舞台区右侧移动,下面哪个积木块是不需要的? A…...
软考中级数据库系统工程师-第6-7章 数据库技术基础关系数据库
目录 1.数据库系统基本概念 2.数据库系统的三级模式结构 3.两级映像 4.数据的独立性 5.E-R模型 6.关系的相关名词 7.关系代数运算 8.关系数据库设计基础知识 9.规范化 1.数据库系统基本概念 1)数据库系统(DBS)是一个采用了数据库技术,有组织地、…...

掌握RDD算子2
文章目录 扁平映射算子案例任务1、统计不规则二维列表元素个数方法一、利用Scala来实现方法二、利用Spark RDD来实现 按键归约算子案例任务1、在Spark Shell里计算学生总分任务2、在IDEA里计算学生总分第一种方式:读取二元组成绩列表第二种方式:读取四元…...
)
ORACLE-SQL性能优化(3)
2. 给优化器更明确的命令 自动选择索引 如果表中有两个以上(包括两个)索引,其中有一个唯一性索引,而其他是非唯一性. 在这种情况下,ORACLE将使用唯一性索引而完全忽略非唯一性索引. 举例: SELEC…...

3年外包裸辞,面试阿里、字节全都一面挂,哭死.....
测试员可以先在外包积累经验,以后去大厂就很容易,基本不会被卡,事实果真如此吗?但是在我身上却是给了我很大一巴掌... 所谓今年今天履历只是不卡简历而已,如果面试答得稀烂,人家根本不会要你。况且要不是大…...
 -- 多线程(信号量与CountDownLatch))
JavaEE(系列16) -- 多线程(信号量与CountDownLatch)
目录 1. 信号量Semaphore 2. CountDownLatch 1. 信号量Semaphore 信号量, 用来表示 "可用资源的个数". 本质上就是一个计数器. 1.理解信号量 可以把信号量想象成是停车场的展示牌: 当前有车位 100 个. 表示有 100 个可用资源.当有车开进去的时候, 就相当于申请一个可…...
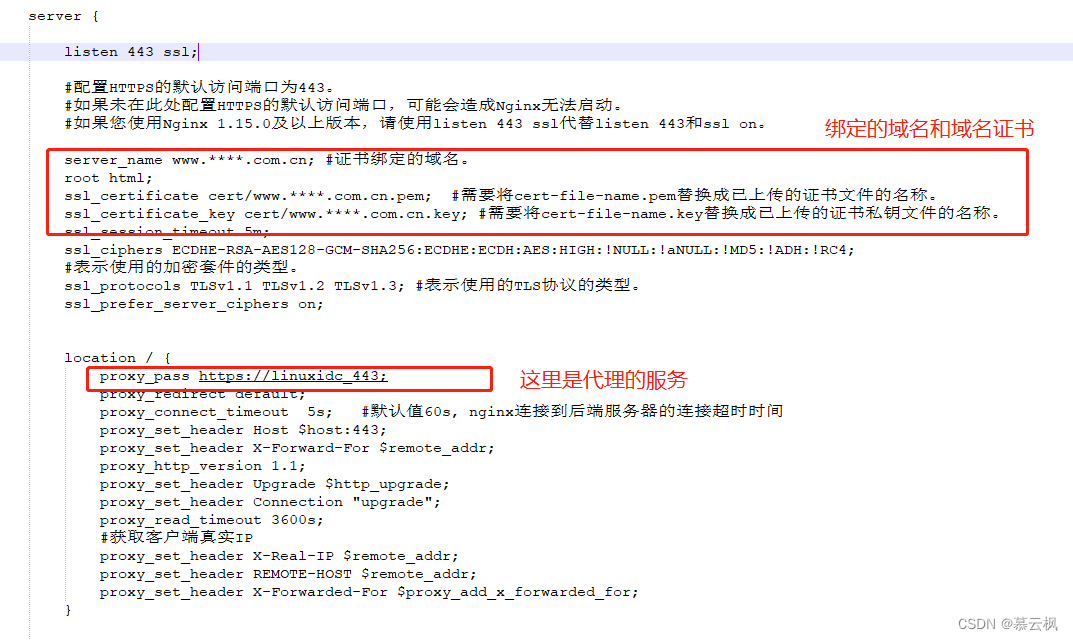
Tomcat配置https协议证书-阿里云,Nginx配置https协议证书-阿里云,Tomcat配置https证书pfx转jks
Tomcat/Nginx配置https协议证书 前言Tomcat配置https协议证书-阿里云方式一 pfx配置证书重启即可 方式二 jkspfx生成jks配置证书重启即可 Nginx配置https协议证书-阿里云实现方式重启即可 其他Tomcat相关配置例子如下nginx配置相关例子如下 前言 阿里云官网:https:…...

抖音定位基本原理
抖音是一款非常受欢迎的短视频分享应用程序,它允许用户创建和分享15秒到60秒的短视频。抖音的成功在很大程度上归功于其强大的定位技术,该技术可以根据用户的兴趣和位置提供个性化的内容。在本文中,我们将深入探讨抖音的定位技术,…...

【Hbase 05】Hbase表的设计原则与优化方案
这里说一下Hbase在使用过程中的表设计原则与优化方案,如果你是运维或者开发兼顾环境的工作,也许比较受用,话不多说,我们直接开始说优化的内容: 一、表设计原则 1.行键设计 行键在设计的时候要尽量的散列,例如可以考虑使用哈希、加密算法等使结果散列,这样能保证请求不会…...
行业报告 | 2022文化科技十大前沿应用趋势(上)
文 | BFT机器人 前言 Introduction 文化科技是文化科技融合过程中诞生的系列新技术成果,是文化强国和科技强国两大战略的交又领域。2012 年 8月,科技部会同中宣部、财政部、文化部、广电总局、新闻出版总署发布《文化科技创新工程纲要》,开启…...
实现BIM的Revit软件学习资料
实现BIM的Revit软件学习资料 一、BIM与Revit的关系二、Revit使用方法总结(一)快捷键(二)一些技巧 一、BIM与Revit的关系 链接: BIM与Revit是什么关系?看完秒懂系列! REVIT是实现BIM理念的工具之一。 二、Revit使用方…...

09 集合框架2
集合元素的迭代方式有哪些? for循环,for-each循环(底层迭代器),迭代器 Iterator<String> it list.iterator(); while(it.hasNext()) {String ele it.next();System.out.println(ele); }并发修改集合元素异常是怎么造成的?怎么解决? 在迭代过程中使用List里面的增…...

相见恨晚的5款良心软件,每款都是经过时间检验的精品
今天来给大家推荐5款良心软件,每款都是经过时间检验的精品,用起来让你的工作效率提升飞快,各个都让你觉得相见恨晚! 1.颜色选择器——ColorPicker ColorPicker是一款用于在屏幕上选择颜色的工具。它可以让你快速地获取任意像素的颜色值,并复制到剪贴板…...
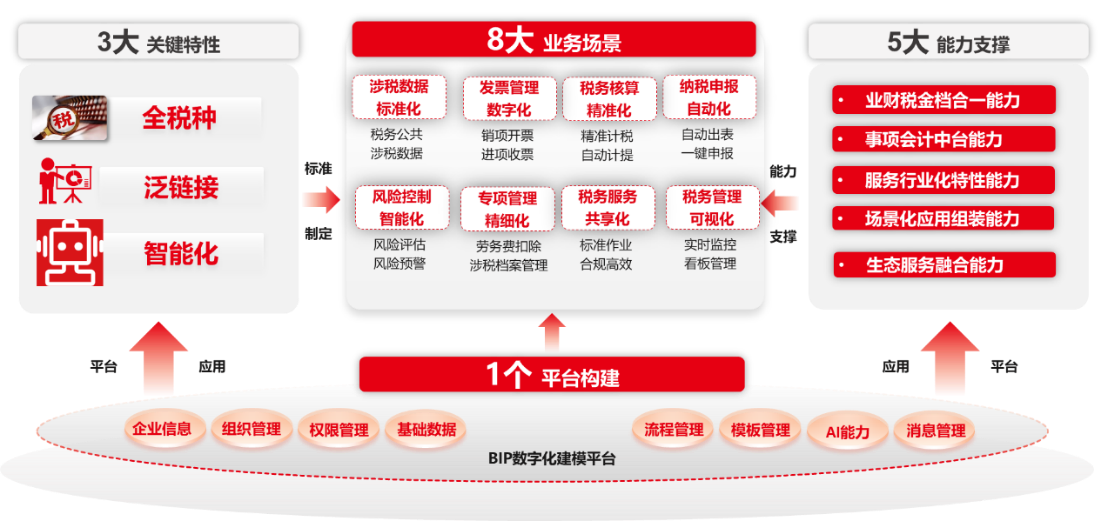
AI与税务管理:新技术带来的新机遇和新挑战
本文作者:王伊琳 人工智能(Artificial Intelligence,AI)是指由计算机系统或机器人模拟人类智能的过程和结果,包括感知、理解、学习、推理、决策等能力。近年来,随着计算机技术、互联网平台、大数据分析等的…...
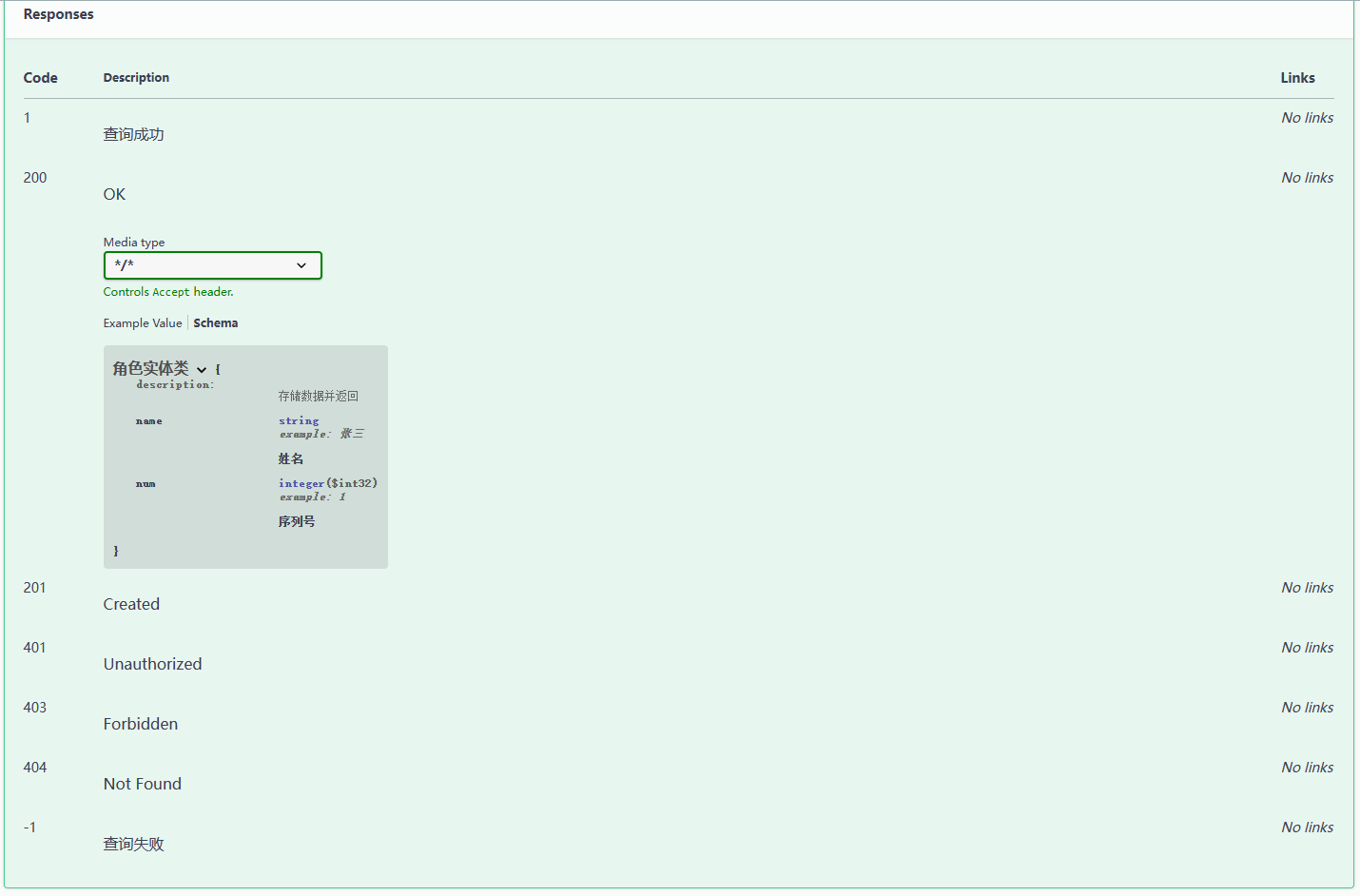
springboot 集成 Swagger3(速通)
→ springboot 集成 Swagger2 ← 目录 1. 案例2. info 配置3. Docket 配置1. 开关配置2. 扫描路径3. 路径匹配4. 分组管理 4. 常用注解1. 说明2. 案例 1. 案例 这次直接使用 2.5.6 的 spring-boot 。 依赖: <parent><groupId>org.springframework.…...
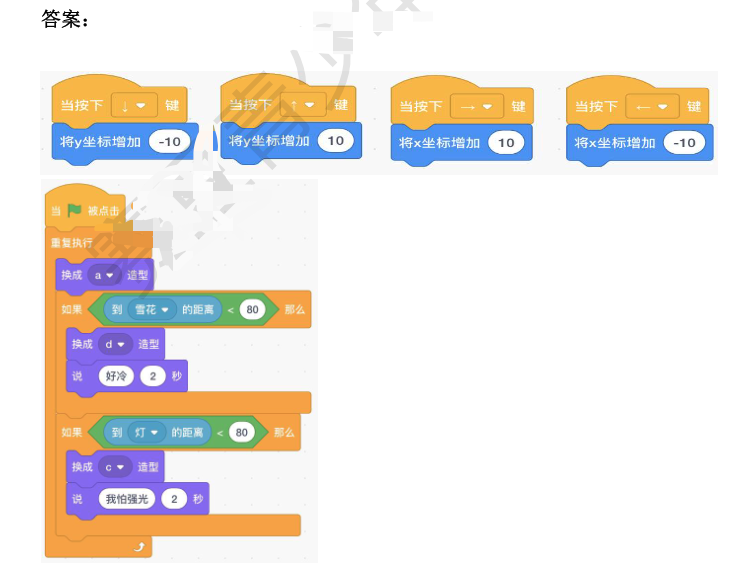
2023年NOC大赛创客智慧编程赛项图形化复赛模拟题二,包含答案解析
2023年NOC大赛创客智慧编程赛项图形化复赛模拟题二,包含答案解析 第一题: 在源程序“小蝙蝠”文件中,实现小蝙蝠遇到不同的角色会说不同的话,以及切换不同的造型要求: 1:游戏开始时,小蝙蝠角色是造型 a,并能够用键盘控制上、下、左、右移动; 2:移动小蝙蝠,距离角色雪…...

2023年NOC大赛创客智慧编程赛项Python 复赛模拟题(二)
题目来自:NOC 大赛创客智慧编程赛项Python 复赛模拟题(二) NOC大赛创客智慧编程赛项Python 复赛模拟题(二) 第一题: 编写一个成绩评价系统,当输入语文、数学和英语三门课程成绩时,输出三门课程总成绩及其等级。 (1)程序提示用户输入三个数字,数字分别表示语文、数学、…...

【SQL】MySQL的查询语句
文章目录 SELECT语句WHERE子句JOIN语句GROUP BY和HAVINGORDER BYLIMIT其他关键字 MySQL是一种广泛使用的关系型数据库管理系统,它被广泛地应用于各种应用程序和网站。学会使用MySQL的查询语句可以帮助我们更好地管理和分析数据,从而更好地利用数据库中的…...

测试的分类
1 按照开发阶段(软件开发周期) 单元测试是对软件的组成单元进行测试。其目的是检验软件基本组成单位的正确性。测试的对象是软件设计的最小单位——模块,故又称为模块测试。集成测试是将程序模块采用适当的集成策略组装起来,对系…...

利用 TaoToken 统一管理多个 AI 项目的 API 密钥与用量
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用 TaoToken 统一管理多个 AI 项目的 API 密钥与用量 当你手头同时运行着多个 AI 应用或实验项目时,管理分散的 API …...

Android HTTPS抓包原理与HTTPCanary证书配置全解
1. 这不是“绕过”,而是理解Android HTTPS抓包的底层逻辑HTTPCanary 是 Android 平台上少有的、真正能稳定抓取 HTTPS 流量的本地代理工具。但几乎所有新手在首次使用时都会卡在同一个地方:明明安装了 HTTPCanary 自带的证书,App 依然拒绝建立…...

机器学习在供水管网泄漏检测与定位中的实践与挑战
1. 项目概述:当机器学习遇见地下“血管”城市地下的供水管网,就像人体的血管网络,日夜不息地输送着生命之源。然而,与人体血管会老化、破裂一样,这些埋藏在地下的管道也时刻面临着泄漏的风险。传统的检漏方法ÿ…...

DS4Windows终极方案:DualShock 4在PC平台的完全指南
DS4Windows终极方案:DualShock 4在PC平台的完全指南 【免费下载链接】DS4Windows Like those other ds4tools, but sexier 项目地址: https://gitcode.com/gh_mirrors/ds/DS4Windows 在当今多平台游戏生态中,手柄兼容性已成为玩家体验的关键瓶颈。…...

Sketch MeaXure:5分钟掌握设计标注终极解决方案
Sketch MeaXure:5分钟掌握设计标注终极解决方案 【免费下载链接】sketch-meaxure 项目地址: https://gitcode.com/gh_mirrors/sk/sketch-meaxure 你是否还在为设计稿标注而烦恼?Sketch MeaXure正是为你量身打造的现代化设计标注神器!…...

机器学习处理不平衡数据:从评估指标到可解释AI的催化剂设计实战
1. 项目概述:当催化剂设计遇上不平衡数据在材料科学和化学工程领域,催化剂设计一直是一项充满挑战的工作。传统的“试错法”不仅成本高昂、周期漫长,而且高度依赖研究人员的经验和直觉。近年来,机器学习(ML)…...

纤维丛与连接:从微分几何到量子控制与最优控制的桥梁
1. 纤维丛与连接:从抽象几何到物理与控制的桥梁在微分几何的世界里,纤维丛是一个强大而优雅的框架,它允许我们在一个复杂的“总空间”上,为底流形上的每一点都“安装”一个额外的结构,比如一个向量空间、一个李群&…...

石墨烯六边形Hubbard模型的量子模拟研究
1. 石墨烯六边形Hubbard模型的量子模拟背景在凝聚态物理研究中,理解强关联电子系统的行为一直是核心挑战。这类系统展现出超导、量子自旋液体等丰富物理现象,而Hubbard模型作为描述电子在晶格中相互作用的最简模型,已成为理论研究的重要工具。…...

Keil ULINK强制全片擦除与CRC校验实践
1. 问题现象与背景解析当使用Keil开发环境配合ULINK调试器对英飞凌C166系列微控制器进行程序烧录时,部分工程师会遇到一个看似奇怪的现象:明明在代码中设置了全片CRC校验逻辑,但实际运行时却出现校验失败。经过排查发现,ULINK默认…...
 题解)
【LeetCode】8. 字符串转换为整数(Atoi) 题解
【LeetCode】8. 字符串转换为整数(Atoi) 题解 Link: https://leetcode.cn/problems/string-to-integer-atoi/description/ 实现一个 MyAtoi(string s) 函数,使其能将字符串转换成一个 323232 位有符号整数。 函数 MyAtoi(string s) 的算法…...