掌握RDD算子2
文章目录
- 扁平映射算子案例
- 任务1、统计不规则二维列表元素个数
- 方法一、利用Scala来实现
- 方法二、利用Spark RDD来实现
- 按键归约算子案例
- 任务1、在Spark Shell里计算学生总分
- 任务2、在IDEA里计算学生总分
- 第一种方式:读取二元组成绩列表
- 第二种方式:读取四元组成绩列表
- 第三种情况:读取HDFS上的成绩文件
扁平映射算子案例
任务1、统计不规则二维列表元素个数
方法一、利用Scala来实现
- 在net.xxr.rdd.day01包里创建Example02单例对象
package net.xxr.rdd.day01import org.apache.spark.{SparkConf, SparkContext}/*** 功能:利用Scala统计不规则二维列表元素个数*/
object Example02 {def main(args: Array[String]): Unit = {// 创建不规则二维列表val mat = List(List(7, 8, 1, 5),List(10, 4, 9),List(7, 2, 8, 1, 4),List(21, 4, 7, -4))// 输出二维列表println(mat)// 将二维列表扁平化为一维列表val arr = mat.flatten// 输出一维列表println(arr)// 输出元素个数println("元素个数:" + arr.size)}
}
方法二、利用Spark RDD来实现
- 在net.xxr.rdd.day01包里创建Example03单例对象
package net.xxr.rdd.day01import org.apache.spark.{SparkConf, SparkContext}/*** 功能:利用RDD统计不规则二维列表元素个数*/
object Example03 {def main(args: Array[String]): Unit = {// 创建Spark配置对象val conf = new SparkConf().setAppName("PrintDiamond") // 设置应用名称.setMaster("local[*]") // 设置主节点位置(本地调试)// 基于Spark配置对象创建Spark容器val sc = new SparkContext(conf)// 创建不规则二维列表val mat = List(List(7, 8, 1, 5),List(10, 4, 9),List(7, 2, 8, 1, 4),List(21, 4, 7, -4))// 基于二维列表创建rdd1val rdd1 = sc.makeRDD(mat)// 输出rdd1rdd1.collect.foreach(x => print(x + " "))println()// 进行扁平化映射val rdd2 = rdd1.flatMap(x => x.toString.substring(5, x.toString.length - 1).split(", "))// 输出rdd2rdd2.collect.foreach(x => print(x + " "))println()// 输出元素个数println("元素个数:" + rdd2.count)}
}
- 扁平化映射可以简化


按键归约算子案例
任务1、在Spark Shell里计算学生总分
- 创建成绩列表scores,基于成绩列表创建rdd1,对rdd1按键归约得到rdd2,然后查看rdd2内容
val scores = List((“张钦林”, 78), (“张钦林”, 90), (“张钦林”, 76),
(“陈燕文”, 95), (“陈燕文”, 88), (“陈燕文”, 98),
(“卢志刚”, 78), (“卢志刚”, 80), (“卢志刚”, 60))
val rdd1 = sc.makeRDD(scores)
val rdd2 = rdd1.reduceByKey((agg, cur) => agg + cur)
rdd2.collect.foreach(println)

- 可以采用神奇的占位符

任务2、在IDEA里计算学生总分
第一种方式:读取二元组成绩列表
- 在net.xxr.rdd.day02包里创建CalculateScoreSum01单例对象
package net.xxr.rdd.day02import org.apache.spark.{SparkConf, SparkContext}/*** 功能:计算总分*/
object CalculateScoreSum01 {def main(args: Array[String]): Unit = {// 创建Spark配置对象val conf = new SparkConf().setAppName("PrintDiamond") // 设置应用名称.setMaster("local[*]") // 设置主节点位置(本地调试)// 基于Spark配置对象创建Spark容器val sc = new SparkContext(conf)val scores = List(("张钦林", 78), ("张钦林", 90), ("张钦林", 76),("陈燕文", 95), ("陈燕文", 88), ("陈燕文", 98),("卢志刚", 78), ("卢志刚", 80), ("卢志刚", 60))// 基于二元组成绩列表创建RDDval rdd1 = sc.makeRDD(scores)// 对成绩RDD进行按键归约处理val rdd2 = rdd1.reduceByKey(_ + _)// 输出归约处理结果rdd2.collect.foreach(println)}
}
第二种方式:读取四元组成绩列表
- 在net.xxr.rdd.day02包里创建CalculateScoreSum02单例对象
package net.xxr.rdd.day02import org.apache.spark.{SparkConf, SparkContext}import scala.collection.mutable.ListBuffer/*** 功能:计算总分*/
object CalculateScoreSum02 {def main(args: Array[String]): Unit = {// 创建Spark配置对象val conf = new SparkConf().setAppName("PrintDiamond") // 设置应用名称.setMaster("local[*]") // 设置主节点位置(本地调试)// 基于Spark配置对象创建Spark容器val sc = new SparkContext(conf)// 创建四元组成绩列表val scores = List(("张钦林", 78, 90, 76),("陈燕文", 95, 88, 98),("卢志刚", 78, 80, 60))// 将四元组成绩列表转化成二元组成绩列表val newScores = new ListBuffer[(String, Int)]()// 通过遍历算子遍历四元组成绩列表scores.foreach(score => {newScores.append(Tuple2(score._1, score._2))newScores.append(Tuple2(score._1, score._3))newScores.append(Tuple2(score._1, score._4))})// 基于二元组成绩列表创建RDDval rdd1 = sc.makeRDD(newScores)// 对成绩RDD进行按键归约处理val rdd2 = rdd1.reduceByKey(_ + _)// 输出归约处理结果rdd2.collect.foreach(println)}
}
第三种情况:读取HDFS上的成绩文件
- 将成绩文件上传到HDFS的/input目录
hdfs dfs -mkdir /input
hdfs dfs -put scores.txt /input
hdfs dfs -cat /input/scores.txt

- 在net.xxr.rdd.day02包里创建CalculateScoreSum03单例对象
package net.xxr.rdd.day02import org.apache.spark.{SparkConf, SparkContext}import scala.collection.mutable.ListBuffer/*** 功能:计算总分*/
object CalculateScoreSum03 {def main(args: Array[String]): Unit = {// 创建Spark配置对象val conf = new SparkConf().setAppName("CalculateScoreSum").setMaster("local[*]")// 基于配置创建Spark上下文val sc = new SparkContext(conf)// 读取成绩文件,生成RDDval lines = sc.textFile("hdfs://master:9000/input/scores.txt")// 定义二元组成绩列表val scores = new ListBuffer[(String, Int)]()// 遍历lines,填充二元组成绩列表lines.collect.foreach(line => {val fields = line.split(" ")scores += Tuple2(fields(0), fields(1).toInt)scores += Tuple2(fields(0), fields(2).toInt)scores += Tuple2(fields(0), fields(3).toInt)})// 基于二元组成绩列表创建RDDval rdd1 = sc.makeRDD(scores)// 对成绩RDD进行按键归约处理val rdd2 = rdd1.reduceByKey((x, y) => x + y)// 输出归约处理结果rdd2.collect.foreach(println)}
}
- 在Spark Shell里完成同样的任务
import scala.collection.mutable.ListBuffer
val lines = sc.textFile("hdfs://master:9000/input/scores.txt")
val scores = new ListBuffer[(String, Int)]()
lines.collect.foreach(line => {
val fields = line.split(" ")
scores.append(Tuple2(fields(0), fields(1).toInt))
scores.append(Tuple2(fields(0), fields(2).toInt))
scores.append(Tuple2(fields(0), fields(3).toInt))
})
val rdd1 = sc.makeRDD(scores)
val rdd2 = rdd1.reduceByKey(_ + _)
rdd2.collect.foreach(println)
- 修改程序,将计算结果写入HDFS文件


相关文章:
掌握RDD算子2
文章目录 扁平映射算子案例任务1、统计不规则二维列表元素个数方法一、利用Scala来实现方法二、利用Spark RDD来实现 按键归约算子案例任务1、在Spark Shell里计算学生总分任务2、在IDEA里计算学生总分第一种方式:读取二元组成绩列表第二种方式:读取四元…...
)
ORACLE-SQL性能优化(3)
2. 给优化器更明确的命令 自动选择索引 如果表中有两个以上(包括两个)索引,其中有一个唯一性索引,而其他是非唯一性. 在这种情况下,ORACLE将使用唯一性索引而完全忽略非唯一性索引. 举例: SELEC…...

3年外包裸辞,面试阿里、字节全都一面挂,哭死.....
测试员可以先在外包积累经验,以后去大厂就很容易,基本不会被卡,事实果真如此吗?但是在我身上却是给了我很大一巴掌... 所谓今年今天履历只是不卡简历而已,如果面试答得稀烂,人家根本不会要你。况且要不是大…...
 -- 多线程(信号量与CountDownLatch))
JavaEE(系列16) -- 多线程(信号量与CountDownLatch)
目录 1. 信号量Semaphore 2. CountDownLatch 1. 信号量Semaphore 信号量, 用来表示 "可用资源的个数". 本质上就是一个计数器. 1.理解信号量 可以把信号量想象成是停车场的展示牌: 当前有车位 100 个. 表示有 100 个可用资源.当有车开进去的时候, 就相当于申请一个可…...
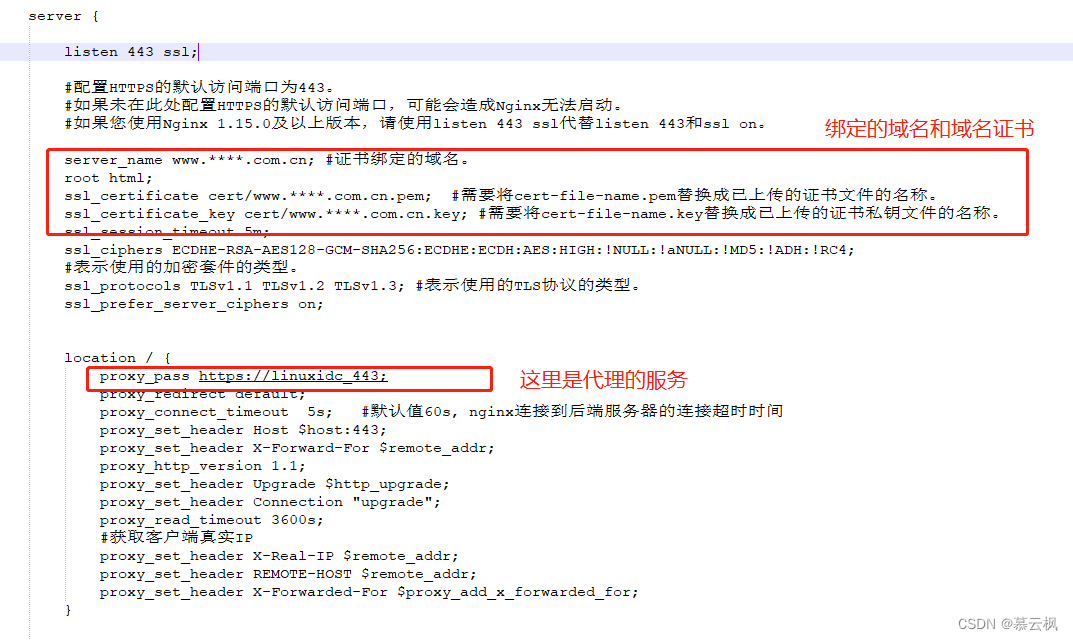
Tomcat配置https协议证书-阿里云,Nginx配置https协议证书-阿里云,Tomcat配置https证书pfx转jks
Tomcat/Nginx配置https协议证书 前言Tomcat配置https协议证书-阿里云方式一 pfx配置证书重启即可 方式二 jkspfx生成jks配置证书重启即可 Nginx配置https协议证书-阿里云实现方式重启即可 其他Tomcat相关配置例子如下nginx配置相关例子如下 前言 阿里云官网:https:…...

抖音定位基本原理
抖音是一款非常受欢迎的短视频分享应用程序,它允许用户创建和分享15秒到60秒的短视频。抖音的成功在很大程度上归功于其强大的定位技术,该技术可以根据用户的兴趣和位置提供个性化的内容。在本文中,我们将深入探讨抖音的定位技术,…...

【Hbase 05】Hbase表的设计原则与优化方案
这里说一下Hbase在使用过程中的表设计原则与优化方案,如果你是运维或者开发兼顾环境的工作,也许比较受用,话不多说,我们直接开始说优化的内容: 一、表设计原则 1.行键设计 行键在设计的时候要尽量的散列,例如可以考虑使用哈希、加密算法等使结果散列,这样能保证请求不会…...
行业报告 | 2022文化科技十大前沿应用趋势(上)
文 | BFT机器人 前言 Introduction 文化科技是文化科技融合过程中诞生的系列新技术成果,是文化强国和科技强国两大战略的交又领域。2012 年 8月,科技部会同中宣部、财政部、文化部、广电总局、新闻出版总署发布《文化科技创新工程纲要》,开启…...
实现BIM的Revit软件学习资料
实现BIM的Revit软件学习资料 一、BIM与Revit的关系二、Revit使用方法总结(一)快捷键(二)一些技巧 一、BIM与Revit的关系 链接: BIM与Revit是什么关系?看完秒懂系列! REVIT是实现BIM理念的工具之一。 二、Revit使用方…...

09 集合框架2
集合元素的迭代方式有哪些? for循环,for-each循环(底层迭代器),迭代器 Iterator<String> it list.iterator(); while(it.hasNext()) {String ele it.next();System.out.println(ele); }并发修改集合元素异常是怎么造成的?怎么解决? 在迭代过程中使用List里面的增…...

相见恨晚的5款良心软件,每款都是经过时间检验的精品
今天来给大家推荐5款良心软件,每款都是经过时间检验的精品,用起来让你的工作效率提升飞快,各个都让你觉得相见恨晚! 1.颜色选择器——ColorPicker ColorPicker是一款用于在屏幕上选择颜色的工具。它可以让你快速地获取任意像素的颜色值,并复制到剪贴板…...
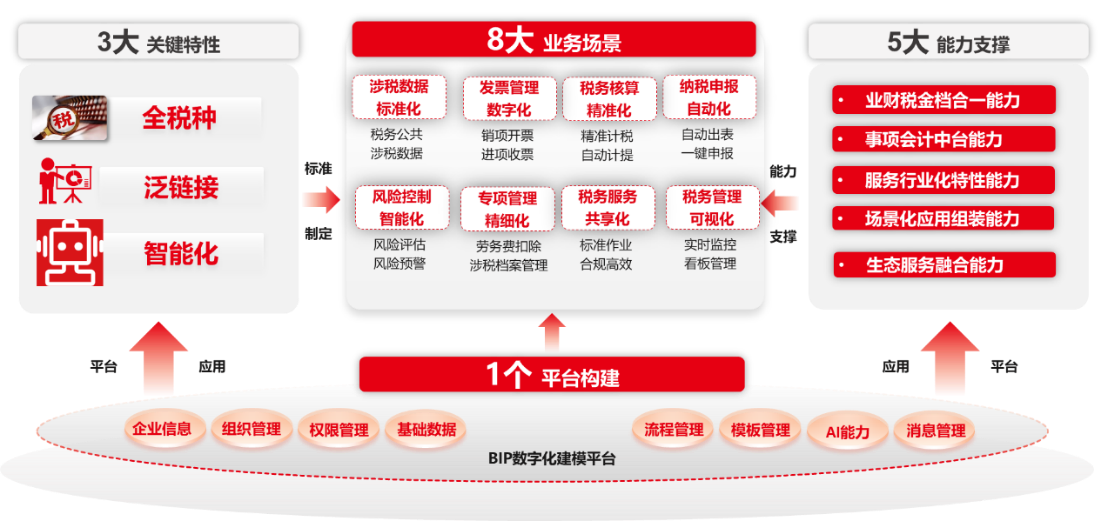
AI与税务管理:新技术带来的新机遇和新挑战
本文作者:王伊琳 人工智能(Artificial Intelligence,AI)是指由计算机系统或机器人模拟人类智能的过程和结果,包括感知、理解、学习、推理、决策等能力。近年来,随着计算机技术、互联网平台、大数据分析等的…...
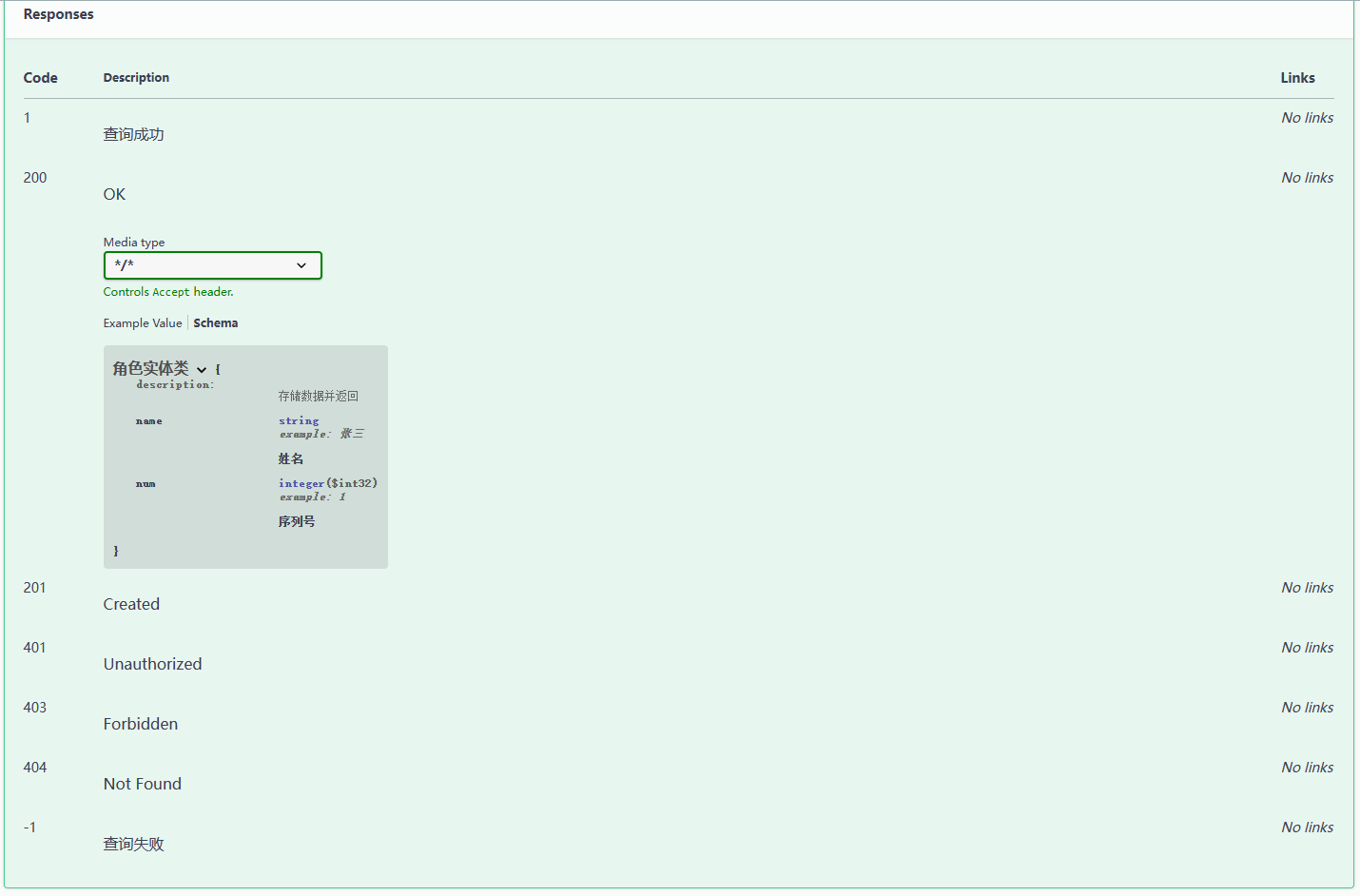
springboot 集成 Swagger3(速通)
→ springboot 集成 Swagger2 ← 目录 1. 案例2. info 配置3. Docket 配置1. 开关配置2. 扫描路径3. 路径匹配4. 分组管理 4. 常用注解1. 说明2. 案例 1. 案例 这次直接使用 2.5.6 的 spring-boot 。 依赖: <parent><groupId>org.springframework.…...
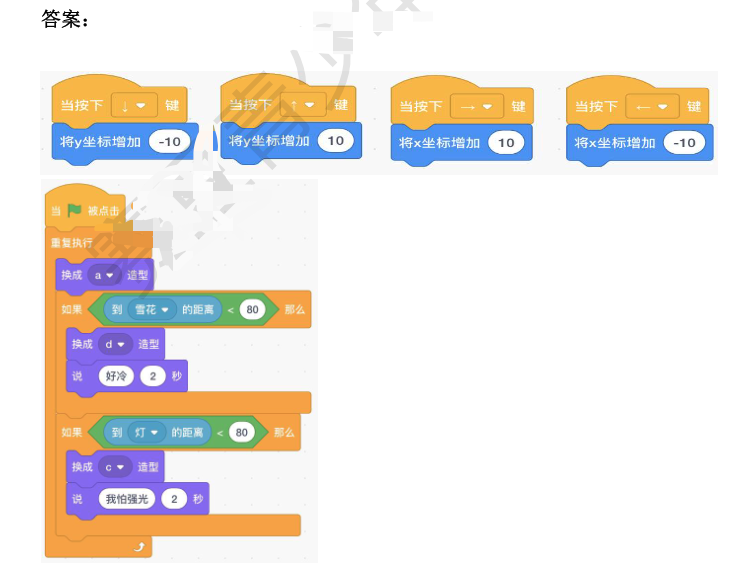
2023年NOC大赛创客智慧编程赛项图形化复赛模拟题二,包含答案解析
2023年NOC大赛创客智慧编程赛项图形化复赛模拟题二,包含答案解析 第一题: 在源程序“小蝙蝠”文件中,实现小蝙蝠遇到不同的角色会说不同的话,以及切换不同的造型要求: 1:游戏开始时,小蝙蝠角色是造型 a,并能够用键盘控制上、下、左、右移动; 2:移动小蝙蝠,距离角色雪…...

2023年NOC大赛创客智慧编程赛项Python 复赛模拟题(二)
题目来自:NOC 大赛创客智慧编程赛项Python 复赛模拟题(二) NOC大赛创客智慧编程赛项Python 复赛模拟题(二) 第一题: 编写一个成绩评价系统,当输入语文、数学和英语三门课程成绩时,输出三门课程总成绩及其等级。 (1)程序提示用户输入三个数字,数字分别表示语文、数学、…...

【SQL】MySQL的查询语句
文章目录 SELECT语句WHERE子句JOIN语句GROUP BY和HAVINGORDER BYLIMIT其他关键字 MySQL是一种广泛使用的关系型数据库管理系统,它被广泛地应用于各种应用程序和网站。学会使用MySQL的查询语句可以帮助我们更好地管理和分析数据,从而更好地利用数据库中的…...

测试的分类
1 按照开发阶段(软件开发周期) 单元测试是对软件的组成单元进行测试。其目的是检验软件基本组成单位的正确性。测试的对象是软件设计的最小单位——模块,故又称为模块测试。集成测试是将程序模块采用适当的集成策略组装起来,对系…...

【5.21】六、自动化测试—持续集成测试
目录 6.4 持续集成测试 6.4.1 持续集成的概念 6.4.2 持续集成测试框架设计 6.4 持续集成测试 持续集成(Continuous Integration,CI)是软件开发DevOps(DevelopmentOperations)中的一个概念,它强调的是软…...

【C++】 排列与组合算法详解(进阶篇)
文章目录 写在前面算法1:朴素算法思路缺点 算法2:递推预处理思路时间复杂度: O ( n 2 ) O(n^2) O(n2) 算法3:阶乘逆元思路时间复杂度: O ( n log n ) O(n \log n) O(nlogn)思考:读者也可以尝试写 O ( n…...

Godot引擎 4.0 文档 - 循序渐进教程 - 监听玩家输入
本文为Google Translate英译中结果,DrGraph在此基础上加了一些校正。英文原版页面: Listening to player input — Godot Engine (stable) documentation in English 监听玩家输入 在上一课创建您的第一个脚本的基础上,让我们看看任何游戏…...

LIWC文本分析Python库:3大核心技术解析与5个实战应用场景
LIWC文本分析Python库:3大核心技术解析与5个实战应用场景 【免费下载链接】liwc-python Linguistic Inquiry and Word Count (LIWC) analyzer 项目地址: https://gitcode.com/gh_mirrors/li/liwc-python 语言心理分析是现代文本挖掘的重要方向,LI…...

达梦数据库-数据库主备集群更改实例目录及相关目录步骤-记录总结
1达梦数据库-数据库主备集群更改实例目录及相关目录步骤-记录总结 1.1常见需求 当前数据库实例所在磁盘性能较差或空间不足,需格式化性能较好空间足的新磁盘并挂载,挂载到原目录或者新目录,然后把数据库实例目录移动到新磁盘。 1.2流程步骤…...

NVIDIA Profile Inspector深度教程:解锁显卡隐藏设置的终极指南
NVIDIA Profile Inspector深度教程:解锁显卡隐藏设置的终极指南 【免费下载链接】nvidiaProfileInspector 项目地址: https://gitcode.com/gh_mirrors/nv/nvidiaProfileInspector NVIDIA Profile Inspector是一款功能强大的显卡性能调优工具,专为…...

揭秘AI教材写作技巧!低查重AI工具助力,3天完成50万字教材!
教材创作中AI工具的应用与优势 在教材编写的过程中,确保原创性与合规性的平衡是一个至关重要的问题。一方面,借鉴已有教材的优秀内容时,创作者往往会担心查重率超标;另一方面,自主进行原创知识点的阐释,又…...

10分钟掌握AppImageLauncher:让Linux应用管理像Windows一样简单的完整指南
10分钟掌握AppImageLauncher:让Linux应用管理像Windows一样简单的完整指南 【免费下载链接】AppImageLauncher Helper application for Linux distributions serving as a kind of "entry point" for running and integrating AppImages 项目地址: http…...

Taotoken 用量看板如何帮助个人开发者清晰掌握月度 AI 支出
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken 用量看板如何帮助个人开发者清晰掌握月度 AI 支出 对于独立开发者和小型项目团队而言,将大模型能力集成到产品…...

生成式AI驱动业务流程自动化:从流程挖掘到智能重构
1. 从流程执行到流程创造:生成式AI如何重塑BPM在业务流程管理(BPM)领域摸爬滚打了十几年,我亲眼见证了它从一套僵化的流程图和审批流,演变为一个动态的、数据驱动的智能决策中枢。传统的BPM核心在于“建模-执行-监控-优…...

5分钟实现位图到矢量图转换:Potrace多色彩矢量化技术深度解析
5分钟实现位图到矢量图转换:Potrace多色彩矢量化技术深度解析 【免费下载链接】vectorizer Potrace based multi-colored raster to vector tracer. Inputs PNG/JPG returns SVG 项目地址: https://gitcode.com/gh_mirrors/ve/vectorizer 在数字图像处理领域…...

量子机器学习中的偏见:从编码到测量的系统性挑战与缓解策略
1. 量子机器学习中的偏见:一个被忽视的工程挑战量子机器学习(QML)正从理论实验室走向现实应用,从药物分子筛选到金融衍生品定价,其潜力令人兴奋。然而,作为一名长期关注量子算法落地的从业者,我…...
)
保姆级教程:手把手复现4D-CRNN脑电情绪识别模型(基于DEAP/SEED数据集)
4D-CRNN脑电情绪识别模型实战指南:从数据预处理到模型训练在脑机接口与情感计算领域,4D-CRNN模型因其出色的多维度特征提取能力而备受关注。本文将带您从零开始,完整复现这一前沿模型在DEAP和SEED数据集上的实现过程。不同于理论讲解…...