Elasticsearch:如何修改 nested 字段的值
Nested 类型是 object 数据类型的特殊版本,它允许对象数组以一种可以彼此独立查询的方式进行索引。在内部,嵌套对象将数组中的每个对象索引为单独的隐藏文档,这意味着每个嵌套对象都可以使用 nested query 独立于其他对象进行查询。每个 nested 对象都被索引为一个单独的 Lucene 文档。有关更多关于 nested 数据类型的文档,我们可以参考之前的文章 “Elasticsearch: object 及 nested 数据类型”。
在使用 Elasticsearch 时,为了系统的效率,我们并不建议经常修改文档,但是在有些时候,我们还必须对已经索引过的文档进行修改。针对 nested 类型的字段,我该如何进行更新及删除呢?
让我们先使用一个例子来进行展示。
我们首先来创建一个 developer 的索引:
PUT developer
{"mappings": {"properties": {"name": {"type": "text"},"skills": {"type": "nested","properties": {"language": {"type": "keyword"},"level": {"type": "keyword"}}}}}
}在上面,我们定义 skills 为一个 nested 数据类型。我们使用如下的命令来创建两个文档:
POST developer/_doc/101
{"name": "zhang san","skills": [{"language": "ruby","level": "expert"},{"language": "javascript","level": "beginner"}]
}POST developer/_doc/102
{"name": "li si","skills": [{"language": "ruby","level": "beginner"}]
}上面的命令写入了两个文档。
添加技能
针对第二个文档,我们想增加如下的一个技能:
{"language": "Python","level" "expert"
}首先让我们使用 painless 语言创建我们的脚本。 你可以在参考资料中阅读有关它的更多详细信息,但熟悉 Java 的人会发现编码很简单。关于 painless 语音的编程,你可以在文章 “Elastic:开发者上手指南” 中的 “Painless 编程” 章节中找到很多文章进行参考。
我们的脚本将验证 skills 字段是否为空,如果是,我们创建列表实例并稍后添加新项目。如果不是,则添加新 skills。
if (ctx._source.skills != null) {ctx._source.skills.addAll(params.skills);} else {ctx._source.skills = new ArrayList();ctx._source.skills.addAll(params.skills);}最终添加 skills 的代码是这样的:
POST developer/_update/102
{"script": {"source": """if (ctx._source.skills != null) {ctx._source.skills.addAll(params.skills);} else {ctx._source.skills = new ArrayList();ctx._source.skills.addAll(params.skills);}""","params": {"skills": [{"language": "Python","level": "expert"}]}}
}我们通过如下的命令来进行验证:
GET developer/_doc/102我们得到如下的结果:
{"_index": "developer","_id": "102","_version": 3,"_seq_no": 4,"_primary_term": 1,"found": true,"_source": {"name": "li si","skills": [{"language": "ruby","level": "beginner"},{"level": "expert","language": "Python"}]}
}从上面,我们可以看出来新的 skills 已经被添加进去了。
删除 skills
同样,我们可以使用如下的代码来删除一个技能:
POST developer/_update/102
{"script": {"source": """if (ctx._source.skills != null) {for (int i; i < params.skills.length; i++) {ctx._source.skills.removeIf(a->a.language.equals(params.skills[i].language) &&a.level.equals(params.skills[i].level));}}""","params": {"skills": [{"language": "Python","level": "expert"}]}}
}我们再次使用如下的命令来查看 id 为 102 的文档:
GET developer/_doc/102上面的命令返回的值为:
{"_index": "developer","_id": "102","_version": 4,"_seq_no": 5,"_primary_term": 1,"found": true,"_source": {"name": "li si","skills": [{"language": "ruby","level": "beginner"}]}
}我们可以看出来,在上一步添加的 skill,现在已经被成功地移除了。
相关文章:

Elasticsearch:如何修改 nested 字段的值
Nested 类型是 object 数据类型的特殊版本,它允许对象数组以一种可以彼此独立查询的方式进行索引。在内部,嵌套对象将数组中的每个对象索引为单独的隐藏文档,这意味着每个嵌套对象都可以使用 nested query 独立于其他对象进行查询。每个 nest…...

【JAVA】jdk8 Stream 排序精通
背景 jdk8的stream流能方便的排序,但是每次都要查资料,非常不方便,不确定,所以这次直接弄懂,不再迷茫。 转载请注明来源,创作不易,请多多支持。 基础排序 stream流 大家应该都比较熟悉了&…...

python的opencv操作记录12——Canny算子使用
文章目录Canny算子非极大值抑制非极大值抑制中的插值滞后阈值实际应用直接使用Canny算子使用膨胀先阈值分割Canny算子 上一篇说到,我在一个小项目里需要在一幅图像中提取一根试管里的两种液体的截面。为了达到这个目的使用传统图像里的区域分割技术,实际…...

Spark on hive Hive on spark
文章目录Spark on hive & Hive on sparkHive 架构与基本原理Spark on hiveHive on sparkSpark on hive & Hive on spark Hive 架构与基本原理 Hive 的核心部件主要是 User Interface(1)和 Driver(3)。而不论是元数据库&a…...
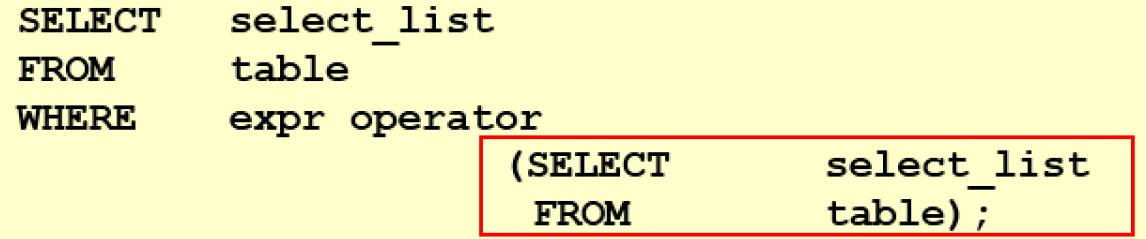
【MySQL】子查询
这里写自定义目录标题子查询1、子查询的基本使用2、 单行子查询2.1、单行比较查询2.2、HAVING 中的子查询2.3、CASE中的子查询3、多行子查询4、相关子查询5、EXISTS 与 NOT EXISTS关键字子查询 子查询指一个查询语句嵌套在另一个查询语句内部的查询,这个特性从MySQ…...

Day889.MySQL高可用 -MySQL实战
MySQL高可用 Hi,我是阿昌,今天学习记录的是关于MySQL高可用的内容。 正常情况下,只要主库执行更新生成的所有 binlog,都可以传到备库并被正确地执行,备库就能达到跟主库一致的状态,这就是最终一致性。但是…...

剑指 Offer 24. 反转链表
⭐简单说两句⭐ CSDN个人主页:后端小知识 🔎GZH:后端小知识 🎉欢迎关注🔎点赞👍收藏⭐️留言📝 题目: 剑指 Offer 24. 反转链表 ,我们今天还是来看一道easy的题目吧&…...
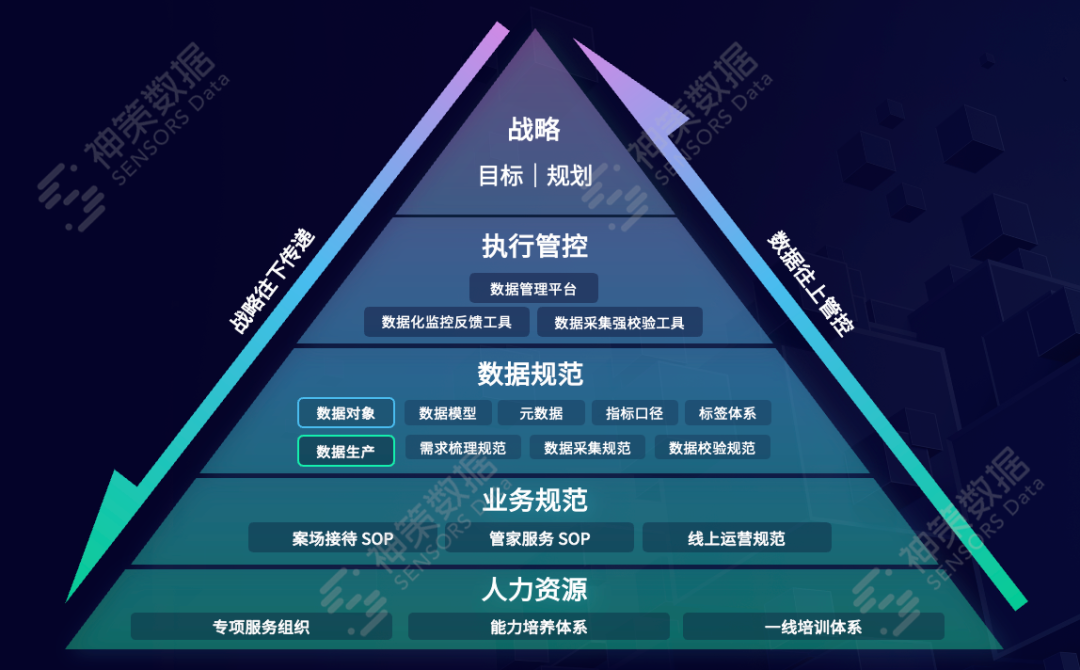
“黑铁时代”,地产人如何以客户视角加速房企数字化转型
本文从行业洞察、业务设计、数据建设以及实践探索四个部分详细阐述地产行业数字化的实践、思考和理解。点击文末“阅读原文”,观看完整版直播回放并下载演讲文档。一、洞察:房企经营思路的变化企业的转型都是围绕着业务经营变化进行的,房企数…...

零入门kubernetes网络实战-14->基于veth pair、namespace以及路由技术,实现跨主机命名空间之间的通信测试案例
《零入门kubernetes网络实战》视频专栏地址 https://www.ixigua.com/7193641905282875942 本篇文章视频地址(稍后上传) 本篇文章继续提供测试案例: 基于veth pair、namespace以及路由技术,实现跨主机命名空间之间的通信 1、网络拓扑如下 2、网络拓扑构建…...
【pytorch框架】对模型知识的基本了解
文章目录TensorBoard的使用1、TensorBoard启动:2、使用TensorBoard查看一张图片3、transforms的使用pytorch框架基础知识1 nn.module的使用2 nn.conv2d的使用3、池化(MaxPool2d)4 非线性激活5 线性层6 Sequential的使用7 损失函数与反向传播8 优化器9 对现有网络的使…...

SUP桨板电动气泵方案——鼎盛合方案
SUP桨板是现时最热门的水上运动之一,它的全称是Stand Up Paddle,简称SUP。这项运动近几年在我国三亚等地区风靡一时,在网上经常看到一些运动博主或者明星网红晒出冲浪视频,刺激又惊险。SUP桨板为充气式桨板,需要通过充…...
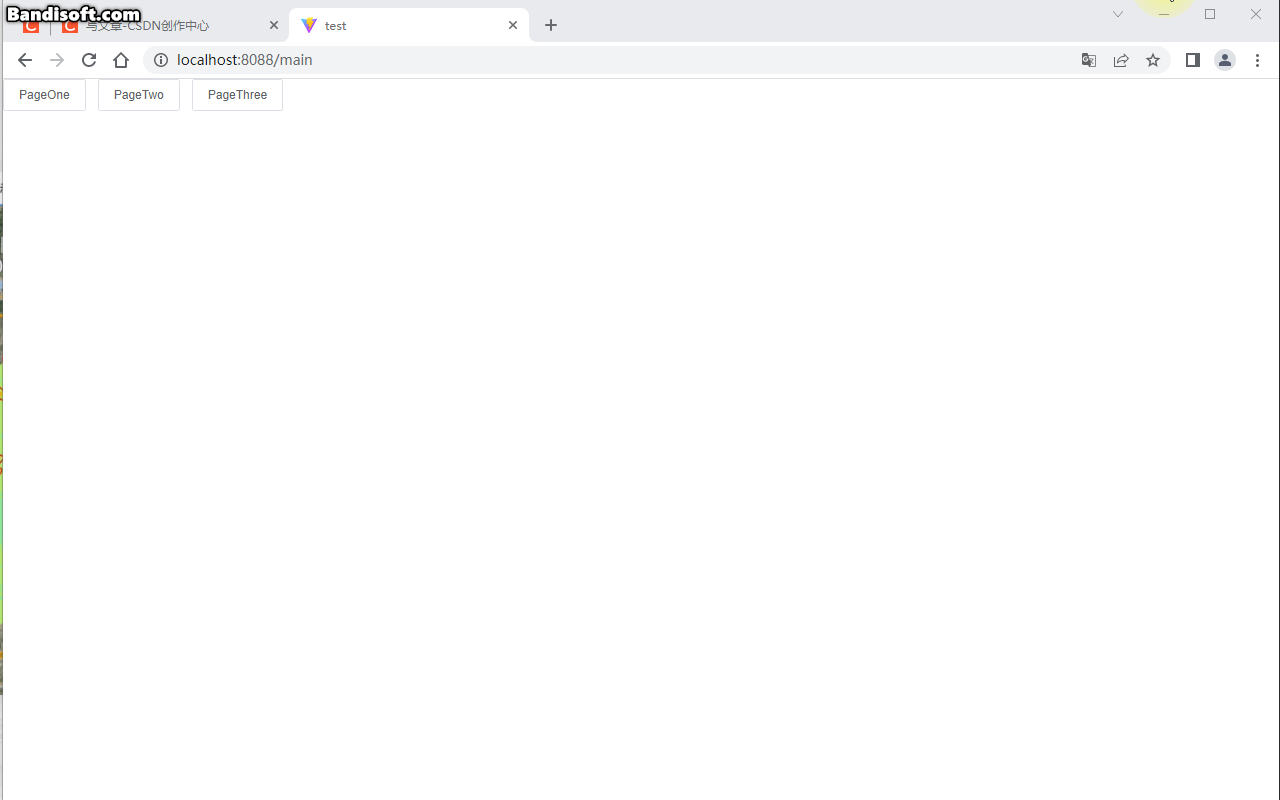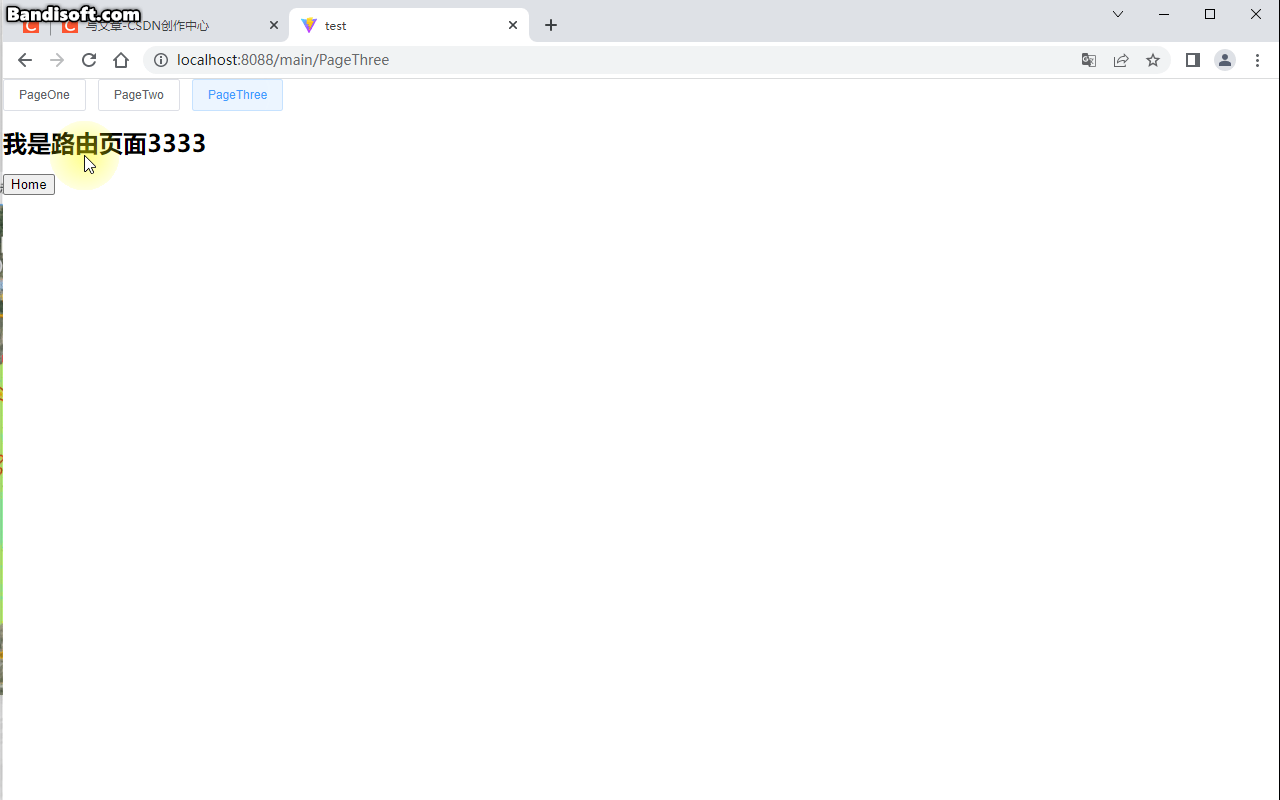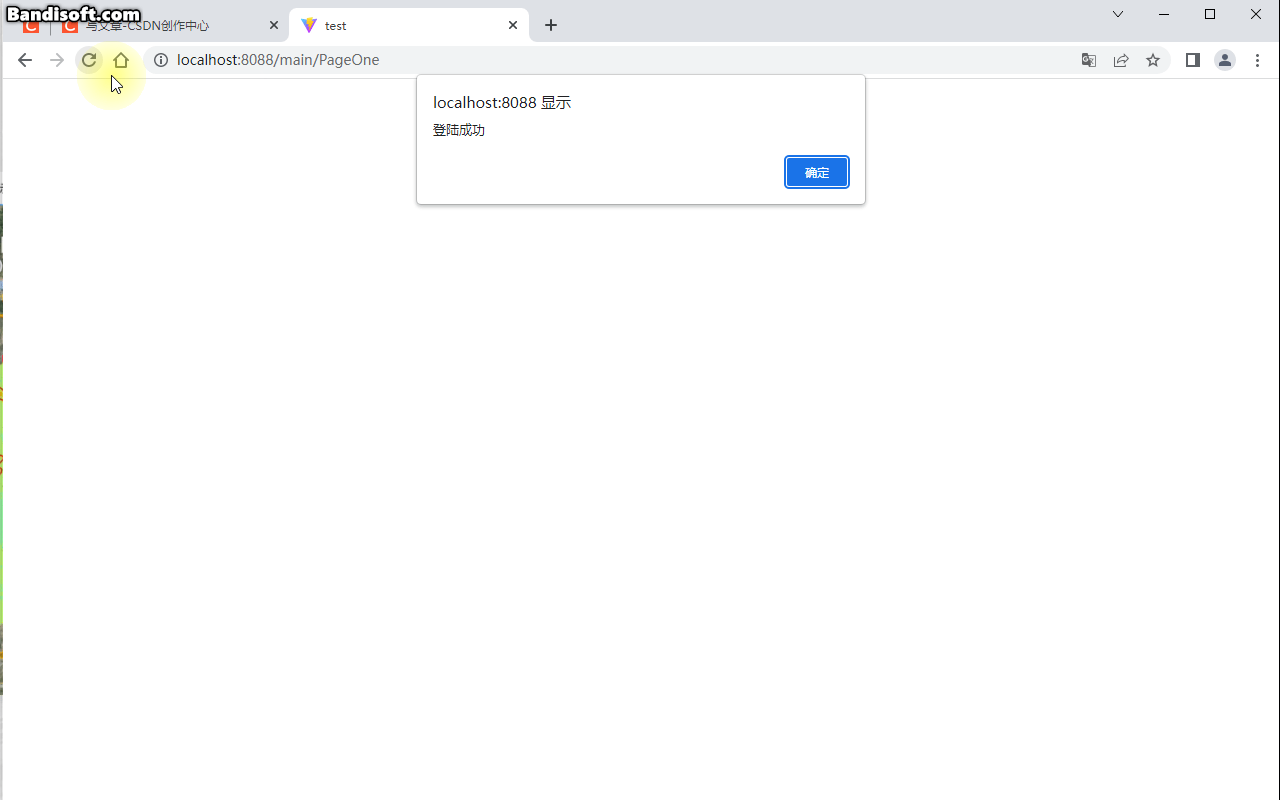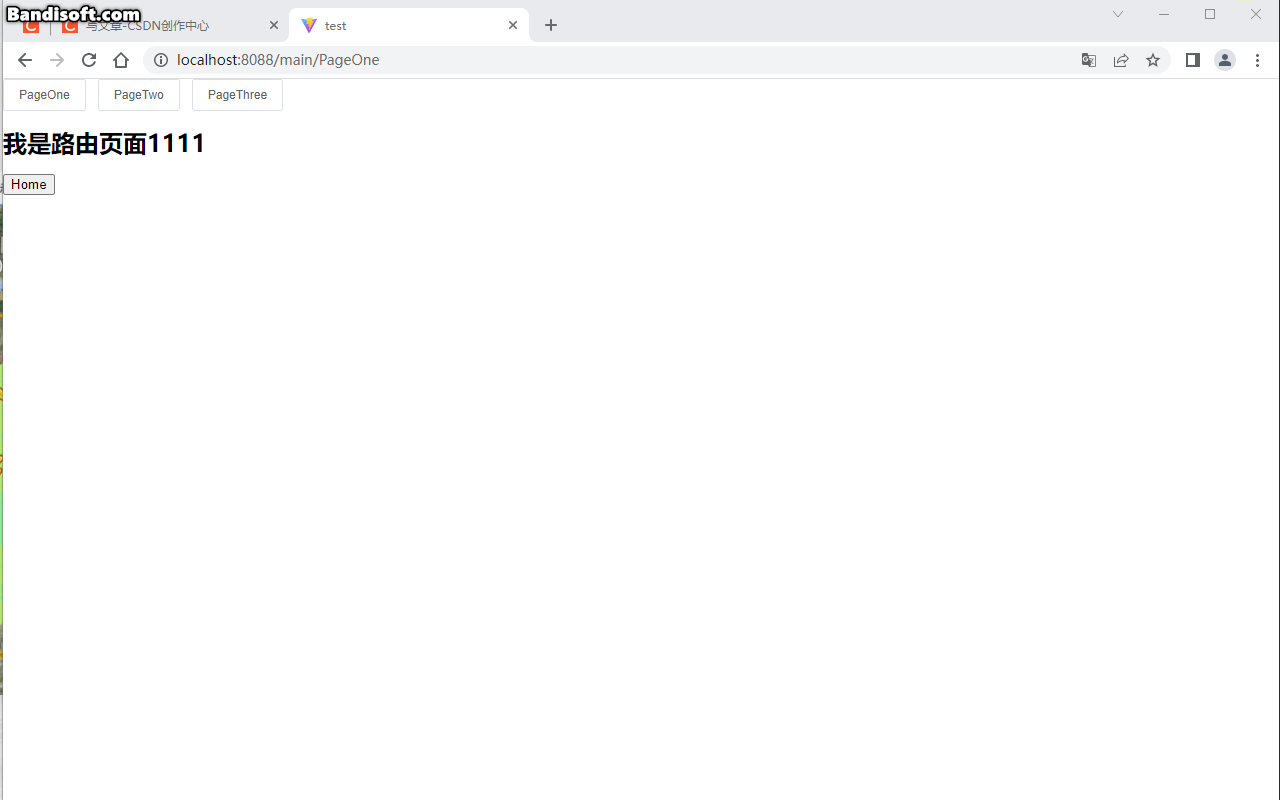
小白系列Vite-Vue3-TypeScript:011-登录界面搭建及动态路由配置
前面几篇文章我们介绍的都是ViteVue3TypeScript项目中环境相关的配置,接下来我们开始进入系统搭建部分。本篇我们来介绍登录界面搭建及动态路由配置,大家一起撸起来......搭建登录界面登陆接口api项目登陆接口是通过mockjs前端来模拟的模拟服务接口Login…...

C语言( 缓冲区和重定向)
一.缓冲输入,无缓存输入 while((chgetchar()) ! #) putchar(ch); 这里getchar(),putchar()每次只处理一个字符(这里只是知道就好了),而我们使用while循环,当读到#字符时停止 而看到输出例子,第一行我们输入…...

编程思想、方法论和架构的类型及应用
概要编程思想是指在编写代码时所采用的基本思维方式和方法论。分类编程思想编程思想为软件开发提供了思维范式和指导思路,例如面向对象思想、函数式编程思想等,它们帮助程序员更好地抽象问题、组织代码、提高代码复用性和可维护性,包括一下几…...

【OA办公】OA流程审批大揭秘,带你看遍所有基础流程
流程审批,是所有企业的OA办公系统重要组成部分,是任何OA办公系统都不可缺少的。比起传统的纸张传阅、签批的审批模式浪费了大量的时间和成本,因此越来越多的企业采用OA这种全新的、高效的、智能的审批模式。流程审批除了这些好处,…...

《零基础入门数据结构与算法》专栏介绍
目录 前言 第一部分:重点 第二部分:题库 第三部分:测试 第四部分:实验 第五部分:试卷 总结 前言 本专栏主要分为五个部分: ① 重要知识点详解 ② 近百道练习题解析 ③ 数据结构与算法章节测试 …...

测试开发之Django实战示例 第九章 扩展商店功能
第九章 扩展商店功能在上一章里,为电商站点集成了支付功能,然后可以生成PDF发票发送给用户。在本章,我们将为商店添加优惠码功能。此外,还会学习国际化和本地化的设置和建立一个推荐商品的系统。本章涵盖如下要点:建立…...
【Spring】一文带你吃透AOP面向切面编程技术(下篇)
个人主页: 几分醉意的CSDN博客_传送门 上节我们介绍了什么是AOP、Aspectj框架的前置通知Before传送门,这篇文章将继续详解Aspectj框架的其它注解。 文章目录💖Aspectj框架介绍✨JoinPoint通知方法的参数✨后置通知AfterReturning✨环绕通知Ar…...
【java】Spring Boot --40 个 Spring Boot 常用注解(建议收藏)
本文目录一、Spring Web MVC 注解Spring Web MVC 注解RequestMappingRequestBodyGetMappingPostMappingPutMappingDeleteMappingPatchMappingControllerAdviceResponseBodyExceptionHandlerResponseStatusPathVariableRequestParamControllerRestControllerModelAttributeCross…...
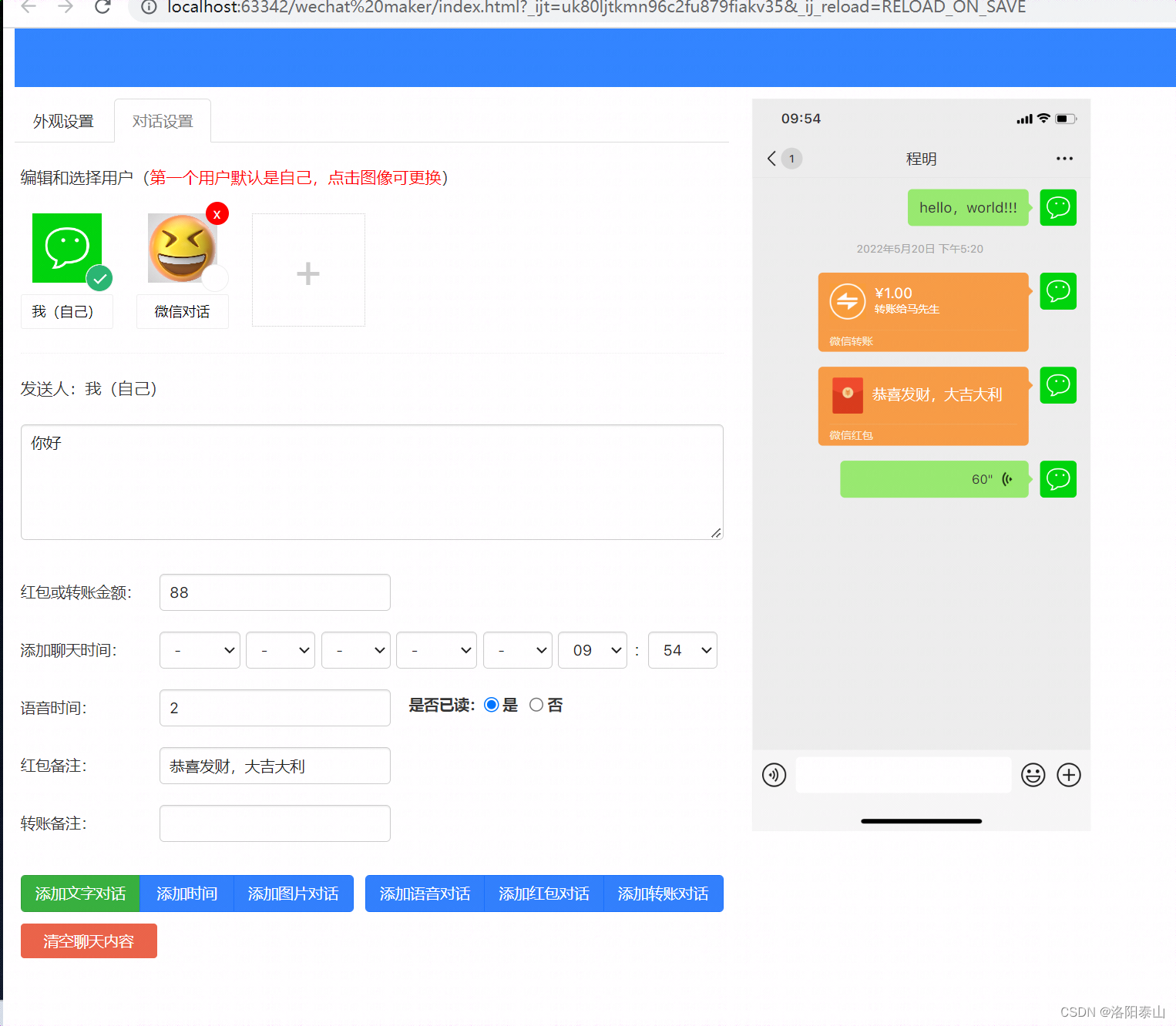
《游戏学习》| 微信对话模拟生成器源码分析
简介微信对话生成器,是一款在线微信聊天对话制作的工具,它可以设置苹果或安卓状态栏,包括手机电量、手机时间等,还可以设置不同用户的角色,然后发送文字、语音、红包、转账等多种好玩的功能,可谓是一款娱乐…...

实战演练:基于ClaudeCode与快马平台构建博客评论交互组件
最近在开发个人博客网站时,遇到了一个常见需求:需要为每篇文章添加评论功能。这个看似简单的模块,实际上涉及不少细节处理。经过一番摸索,我发现在InsCode(快马)平台上结合ClaudeCode的智能生成能力,可以高效完成这个任…...

C++的std--ranges适配器视图与惰性求值在无限序列中的潜在应用
C的std::ranges适配器视图与惰性求值在无限序列中的潜在应用 现代C通过引入std::ranges库,为序列操作带来了更简洁、高效的编程范式。其中,适配器视图与惰性求值的结合,为处理无限序列提供了全新的可能性。这种技术不仅能够避免不必要的计算…...

无人机传感器技术解析:从IMU到激光雷达的全面指南
1. 无人机传感器的核心作用 当你操控无人机在空中自由翱翔时,有没有想过它为什么能如此听话?这背后是一整套传感器系统在默默工作。就像人类需要眼睛、耳朵和平衡感来感知世界一样,无人机也需要各种传感器来"感知"周围环境。这些传…...

AI系统架构评审中的可扩展性设计:3个关键策略
AI系统架构评审中的可扩展性设计:3个关键策略 摘要 在AI技术飞速发展的今天,系统可扩展性已成为决定AI项目成败的关键因素之一。本文深入探讨了AI系统架构评审中可扩展性设计的三个核心策略:分布式计算与存储架构、模型解耦与服务化设计以及自适应资源调度与弹性扩展。通过…...
)
保姆级教程:用VMware和Kali复现Vulnstack红日靶场2的完整渗透流程(附CS联动技巧)
红队实战进阶:Kali与Cobalt Strike协同渗透Vulnstack靶场全解析 环境配置与网络拓扑设计 在开始渗透测试之前,正确的环境搭建是成功的基础。不同于简单的虚拟机启动,专业级红队演练需要精确模拟企业内网环境。我们采用三台靶机(WE…...

Qwen3-ASR-1.7B实战教程:curl命令行调用API实现无人值守识别任务
Qwen3-ASR-1.7B实战教程:curl命令行调用API实现无人值守识别任务 1. 课程目标与价值 本教程将教你如何使用curl命令行工具调用Qwen3-ASR-1.7B语音识别模型的API接口,实现自动化、无人值守的语音转文字任务。学完本教程,你将能够:…...

LeetCodehot100-21 合并两个有序链表
class Solution { public:ListNode* mergeTwoLists(ListNode* list1, ListNode* list2) {if(list1nullptr||list2nullptr){return list1nullptr?list2:list1;}ListNode* headlist1->val<list2->val?list1:list2;ListNode* cur1head->next;ListNode* cur2headlist…...

用STM32F103和TMC2209给步进电机加个‘防丢步’外挂:手把手实现位置式PID闭环
用STM32F103和TMC2209给步进电机加个‘防丢步’外挂:手把手实现位置式PID闭环 步进电机在3D打印机、CNC机床和自动化设备中无处不在,但许多开发者都遇到过这样的尴尬:明明发送了1000个脉冲,电机却只转了980步。这种"丢步&quo…...
)
AudioLDM-S实战教程:为有声书项目批量生成章节过渡音效(含脚本)
AudioLDM-S实战教程:为有声书项目批量生成章节过渡音效(含脚本) 1. 项目简介 AudioLDM-S是一个专门生成现实环境音效的AI工具,基于audioldm-s-full-v2模型的轻量级Gradio实现。无论你需要电影配音、游戏音效还是助眠白噪音&…...

OpenOCD入门到精通:第30章 综合实战:安全调试与逆向分析
第30章 综合实战:安全调试与逆向分析 导读:在嵌入式安全研究领域,JTAG/SWD 调试接口既是开发者的利器,也是安全研究人员的重要切入点。通过调试接口,可以探测芯片类型、读取固件内容、分析安全配置,甚至绕过某些保护机制。本章将围绕 OpenOCD 在合法授权安全研究场景中的…...