InstructGPT笔记
-
一、InstructGPT是在GPT3上微调,ChatGPT是在GPT3.5上微调
-
二、该论文展示了怎么样对语言模型和人类意图之间进行匹配,方法是在人类的反馈上进行微调。
-
**三、方法简介:**收集很多问题,使用标注工具将问题的答案写出来,用这些数据集对GPT3进行微调。接下来再收集一个数据集,通过刚才微调的模型输入问题得到一些输出答案,人工对这些答案按好坏进行排序,然后通过强化学习继续训练微调后的模型,这个模型就叫InstrunctGPT。
-
四、大的语言模型会生成有问题的输出,因为模型训练用的目标函数不那么对。实际的目标函数:在网上的文本数据预测下一个词。我们希望的目标函数:根据人的指示、有帮助的、安全的生成答案。InstructGPT就是解决这个问题,方法是RLHF(reinforcement learning from human feedback),基于人类反馈的强化学习。
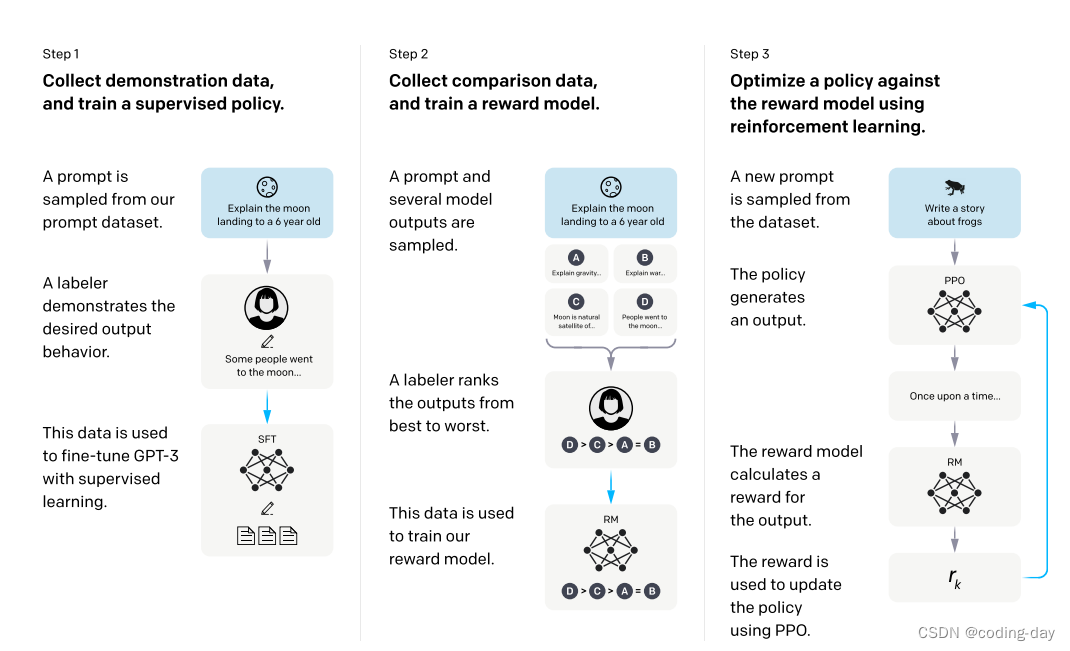 五、重点:两个标注数据集,三个模型。
五、重点:两个标注数据集,三个模型。 -
1、找人来写出各种各样的问题
-
2、让人根据问题写答案
-
3、将问题和答案拼在一起,形成一段对话。
-
4、使用这些对话微调GPT3。GPT3的模型在人类标注的这些数据上进行微调出来的模型叫做SFT(supervised fine-tune),有监督的微调。这就是训练出来的第一个模型。
-
5、给出一个问题,通过SFT模型生成几个答案
(例如:什么是月亮?
SFT模型生成了四个答案:
A、月亮是太阳系中离地球最近的天体。
B、月亮是太阳系中体积第五大的卫星。
C、月亮是由冰岩组成的天体,在地球的椭圆轨道上运行。
D、月亮是地球的卫星。) -
6、将四个答案让人根据好坏程度进行排序。
-
7、将大量的人工排序整理为一个数据集,就是第二个标注数据集。
-
8、使用排序数据集训练一个RM模型,reward model,奖励模型。这是第二个模型。
-
9、继续给出一些没有答案的问题,通过强化学习继续训练SFT模型,新的模型叫做RL模型(Reinforcement Learning)。优化目标是使得RF模型根据这些问题得到的答案在RM模型中得到的分数越高越好。这是第三个模型。
-
10、最终微调后的RL模型就是InstructGPT模型。
备注:两次对模型的微调:GPT3模型—>SFT模型—>RL模型,其实这里始终都是同一个模型,只是不同过程中名称不一样。
需要SFT模型的原因:GPT3模型不一定能够保证根据人的指示、有帮助的、安全的生成答案,需要人工标注数据进行微调。
需要RM模型的原因:标注排序的判别式标注,成本远远低于生成答案的生成式标注。
需要RF模型的原因:在对SFT模型进行微调时,生成的答案分布也会发生变化,会导致RM模型的评分会有偏差,需要用到强化学习。
-
六、数据集问题
收集问题集,prompt集:标注人员写出这些问题,写出一些指令,用户提交一些他们想得到答案的问题。先训练一个最基础的模型,给用户试用,同时可以继续收集用户提交的问题。划分数据集时按照用户ID划分,因为同一个用户问题会比较类似,不适合同时出现在训练集和验证集中。
三个模型的数据集:1、SFT数据集:13000条数据。标注人员直接根据刚才的问题集里面的问题写答案。
2、RM数据集:33000条数据。标注人员对答案进行排序。
3、RF数据集:31000条数据。只需要prompt集里面的问题就行,不需要标注。因为这一步的标注是RM模型来打分标注的。
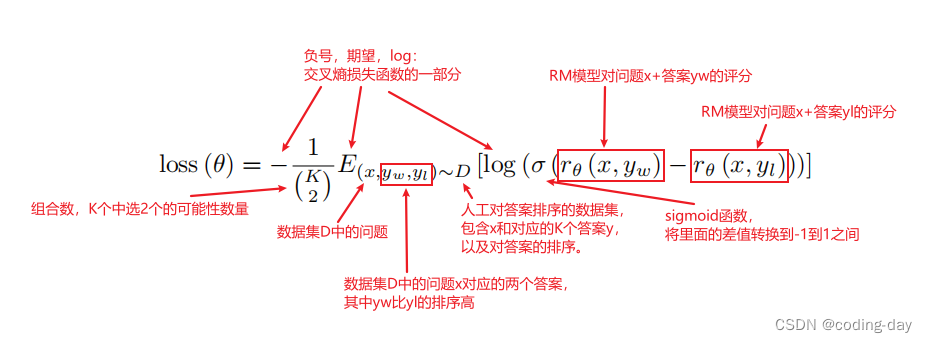
补充:交叉熵用来评估标签和预测值之间的差距。这里是将排序的分数差转换成分类问题,就可以计算分数差的分类(1或者-1)和真实预测值之间的差距,1表示yw比yl排序更前,-1表示yl比yw排序更前。
KL散度用来评估两个概率分布之间的相似度,KL散度始终大于等于0。这里是用来评估πφRL和πSFT两个模型相似度,两个模型相同则KL散度为0,KL散度越大表示两个模型相差越大。 -
七、三种模型详解
一、SFT(Supervised fine-tuning)模型
把GPT3这个模型,在标注好的第一个数据集(问题+答案)上面重新训练一次。
由于只有13000个数据,1个epoch就过拟合,不过这个模型过拟合也没什么关系,甚至训练更多的epoch对后续是有帮助的,最终训练了16个epoch。
二、RM(Reward modeling)模型
把SFT模型最后的unembedding层去掉,即最后一层不用softmax,改成一个线性层,这样RM模型就可以做到输入问题+答案,输出一个标量的分数。
RM模型使用6B,而不是175B的原因:
1、小模型更便宜
2、大模型不稳定,loss很难收敛。如果你这里不稳定,那么后续再训练RL模型就会比较麻烦。
损失函数,输入是排序,需要转换为值,这里使用Pairwise Ranking Loss。
三、RL(Reinforcement learning)模型
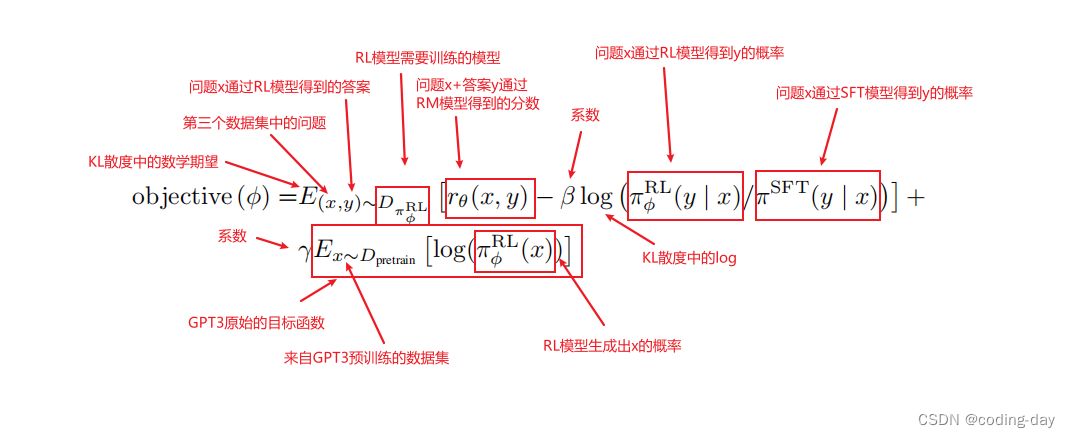
这里用的是强化学习,因为他的数据分布是随着策略的更新,环境会发生变化的。优化算法是PPO,Proximal Policy Optimization,近端策略优化。简单来说,就是对目标函数objective(φ)通过随机梯度下降进行优化。
参数解释:
1、πSFT:SFT模型。
2、πφRL:强化学习中,模型叫做Policy,πφRL就是需要调整的模型,即最终的模型。初始化是πSFT。
3、(x,y)∼DπφRL:x是第三个数据集中的问题,y是x通过πφRL模型得到的答案。
4、rθ(x,y):对问题x+答案y进行打分的RM模型。
5、πφRL(y | x):问题x通过πφRL得到答案y的概率,即对于每一个y的预测和它的softmax的输出相乘。
6、πSFT(y | x):问题x通过πSFT得到答案y的概率。
7、x∼Dpretrain:x是来自GPT3预训练模型的数据。
8、β、γ:调整系数。
目标函数理解:
优化目标是使得目标函数越大越好,objective(φ)可分成三个部分,打分部分+KL散度部分+GPT3预训练部分
1、将第三个数据集中的问题x,通过πφRL模型得到答案y
2、把一对(x,y)送进RM模型进行打分,得到rθ(x,y),即第一部分打分部分,这个分数越高就代表模型生成的答案越好
3、在每次更新参数后,πφRL会发生变化,x通过πφRL生成的y也会发生变化,而rθ(x,y)打分模型是根据πSFT模型的数据训练而来,如果πφRL和πSFT差的太多,则会导致rθ(x,y)的分数估算不准确。因此需要通过KL散度来计算πφRL生成的答案分布和πSFT生成的答案分布之间的距离,使得两个模型之间不要差的太远。
4、我们希望两个模型的差距越小越好,即KL散度越小越好,前面需要加一个负号,使得objective(φ)越大越好。这个就是KL散度部分。
5、如果没有第三项,那么模型最终可能只对这一个任务能够做好,在别的任务上会发生性能下降。所以第三部分就把原始的GPT3目标函数加了上去,使得前面两个部分在新的数据集上做拟合,同时保证原始的数据也不要丢,这个就是第三部分GPT3预训练部分。
6、当γ=0时,这个模型叫做PPO,当γ不为0时,这个模型叫做PPO-ptx。InstructGPT更偏向于使用PPO-ptx。
7、最终优化后的πφRL模型就是InstructGPT的模型。
以上就是InstructGPT的训练过程。
参考:
相关文章:
InstructGPT笔记
一、InstructGPT是在GPT3上微调,ChatGPT是在GPT3.5上微调 二、该论文展示了怎么样对语言模型和人类意图之间进行匹配,方法是在人类的反馈上进行微调。 **三、方法简介:**收集很多问题,使用标注工具将问题的答案写出来࿰…...

【uniapp】getOpenerEventChannel().once 接收参数无效的解决方案
uniapp项目开发跨平台应用常会遇到接收参数无效的问题,无法判断是哪里出错了,这里是讲替代的方案,现有三种方案可选。 原因 一般我们是这样处理向另一个页面传参,代码是这样写的 //... let { title, type, rank } args; uni.n…...
ELK分布式日志收集快速入门-(二)kafka进阶-快速安装可视化管理界面-(单节点部署)
目录安装前准备安装中安装成功安装前准备 安装kafka-参考博客 (10条消息) ELK分布式日志收集快速入门-(一)-kafka单体篇_康世行的博客-CSDN博客 安装zk 参考博客 (10条消息) 快速搭建-分布式远程调用框架搭建-dubbozookperspringboot demo 演示_康世行的…...

线程的创建
1. 多线程常用函数 1.1 创建一条新线程pthread_create 对此函数使用注意以下几点: 线程例程指的是:如果线程创建成功,则该线程会立即执行的函数。POSIX线程库的所有API对返回值的处理原则一致:成功返回0,失败返回错误…...

分布式之Paxos共识算法分析
写在前面 分布式共识是分布式系统中的重要内容,本文来一起看下,一种历史悠久(1998由兰伯特提出,并助其获得2003年图灵奖)的实现分布式共识的算法Paxos。Paxos主要分为两部分,Basic Paxos和Multi-Paxos,其中…...

35岁测试工程师,面临中年危机,我该如何自救...
被辞的原因 最近因故来了上海,联系上了一位许久不见的老朋友,老王;老王和我是大学同学,毕业之后他去了上海,我来到广州。因为我们大学专业关系,从12年毕业以后我们从事着相同的职业,软件自动化…...
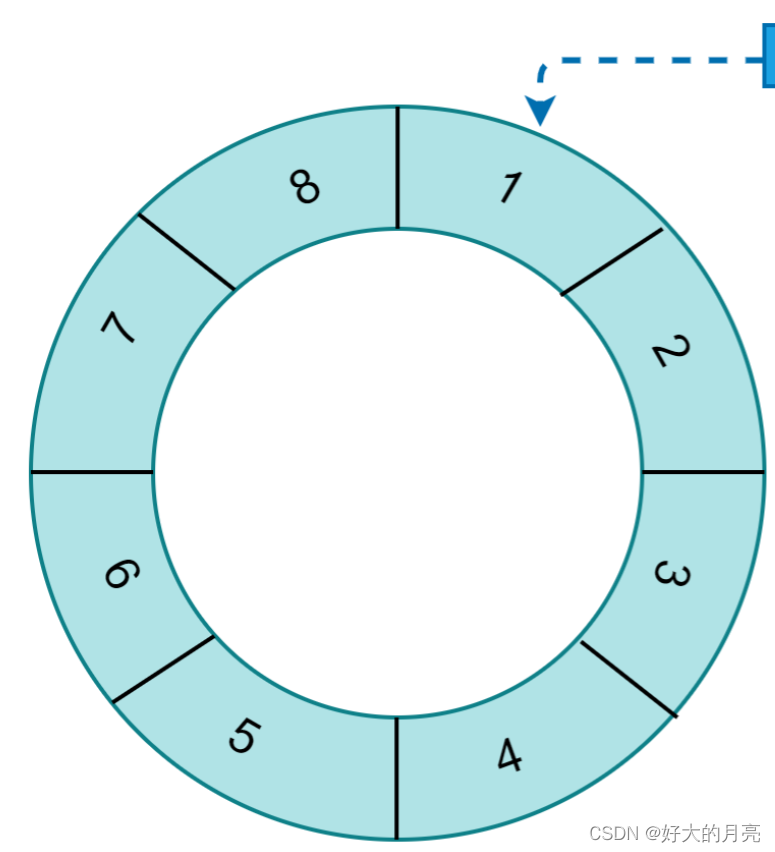
时间轮算法概念
概述 在一些中间件中我们经常见到时间轮控制并发和熔断。 那么这个时间轮具体是什么呢,又是怎么使用的呢。 简介 其实时间轮可以简单的理解成我们日常生活中的时钟。 时钟里的指针一直在不停的转动,利用这个我们可以实现定时任务,目前lin…...
[SCTF2019]babyre 题解
对未来的真正慷慨,是把一切献给现在。 ——加缪 目录 1.查壳 2.处理花指令,找到main函数 这一操作过程可以参考下面的视频: 3.静态分析第一部分,psword1 4.静态分析第二部分,psword2 5.静态分析第五部分,psword3 6.根据ps…...

全志H3系统移植 | 移植主线最新uboot 2023.04和kernel 6.1.11到Nanopi NEO开发板
文章目录 环境说明uboot移植kernel移植rootfs移植测试环境说明 OS:Ubuntu 20.04.5 LTSGCC:arm-none-linux-gnueabihf-gcc 10.3.0编译器下载地址:Downloads | GNU-A Downloads – Arm Developer uboot移植 当前最新版本v2023.04-rc2下载地址:https://github.com/u-boot/u-…...

vue项目第四天
使用elementui tabplane组件实现历史访问记录组件的二次封装<el-tabs type"border-card"><el-tab-pane label"用户管理">用户管理</el-tab-pane><el-tab-pane label"配置管理">配置管理</el-tab-pane><el-tab-…...
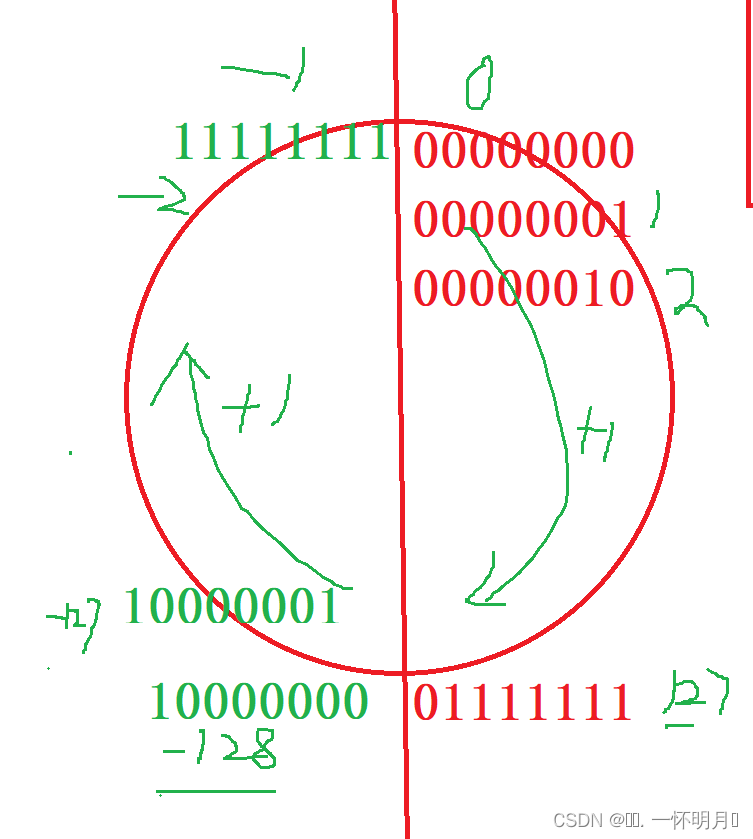
「C语言进阶」数据内存的存储
🚀🚀🚀大家觉不错的话,就恳求大家点点关注,点点小爱心,指点指点🚀🚀🚀 目录 🐰数据类型的介绍 🐰类型的意义 🐰数据类型的基本归类…...

面试必问:进程和线程的区别(从操作系统层次理解)
1.什么是进程?为什么要有进程? 进程有一个相当精简的解释:进程是对操作系统上正在运行程序的一个抽象。 这个概念确实挺抽象,仔细想想却也挺精准。 我们平常使用计算机,都会在同一时间做许多事,比如边看…...

ModuleNotFoundError: No module named ‘apex‘与 error: legacy-install-failure
ModuleNotFoundError: No module named ‘apex’ ModuleNotFoundError: No module named apex 表示 Python 在搜索模块时无法找到名为 apex 的模块。这通常是因为您没有安装 apex 模块或安装不正确。 apex 是一个针对混合精度训练和优化的 PyTorch 扩展库,您可以通过…...
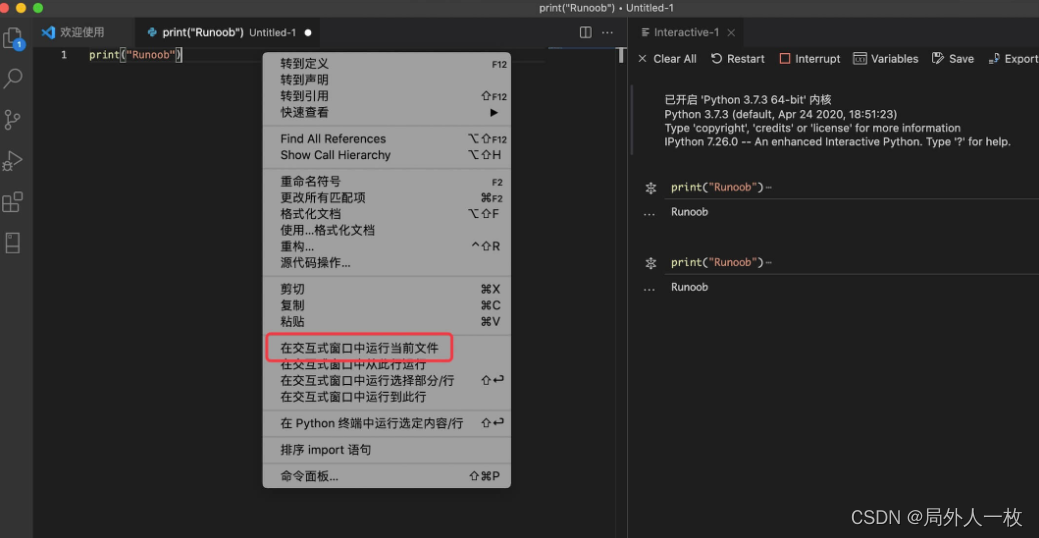
Python3 VScode 配置
Python3 VScode 配置 在上一章节中我们已经安装了 Python 的环境,本章节我们将介绍 Python VScode 的配置。 准备工作: 安装 VS Code 安装 VS Code Python 扩展 安装 Python 3 安装 VS Code VSCode(全称:Visual Studio Code&…...

VMware 修复了三个身份认证绕过漏洞
Bleeping Computer 网站披露,VMware 近期发布了安全更新,以解决 Workspace ONE Assist 解决方案中的三个严重漏洞,分别追踪为 CVE-2022-31685(认证绕过)、CVE-2022-31686 (认证方法失败)和 CVE-…...

实现一个简单的Database10(译文)
GreatSQL社区原创内容未经授权不得随意使用,转载请联系小编并注明来源。GreatSQL是MySQL的国产分支版本,使用上与MySQL一致。作者: 花家舍文章来源:GreatSQL社区原创 前文回顾 实现一个简单的Database系列 译注:csta…...
CTF-取证题目解析-提供环境
一、安装 官网下载:Volatility 2.6 Release 1、将windows下载的volatility上传到 kali/home 文件夹里面 3、将home/kali/vol刚刚上传的 移动到use/sbin目录里面 mv volatility usr/local/sbin/ 切换到里面 cd /usr/local/sbin/volatility 输入配置环境echo $PAT…...

计算机基础 | 网络篇 | TCP/IP 四层模型
前沿:撰写博客的目的是为了再刷时回顾和进一步完善,其次才是以教为学,所以如果有些博客写的较简陋,是为了保持进度不得已而为之,还请大家多多见谅。 一、OSI 七层模型 参考文章:OSI 和 TCP/IP 网络分层模型…...

实时数据仓库
1 为什么选择kafka? ① 实时写入,实时读取 ② 消息队列适合,其他数据库受不了 2 ods层 1)存储原始数据 埋点的行为数据 (topic :ods_base_log) 业务数据 (topic :ods_base_db) 2)业务数据的有序性&#x…...

leetcode 1250. 检查「好数组」
给你一个正整数数组 nums,你需要从中任选一些子集,然后将子集中每一个数乘以一个 任意整数,并求出他们的和。 假如该和结果为 1,那么原数组就是一个「好数组」,则返回 True;否则请返回 False。 示例 1&…...

2026出海技术观察:云API接口迭代的能力边界与业务增量空间
摘要:2026年AI出海告别粗放扩张,底层技术适配能力成为竞争核心。云API接口迭代持续优化跨境对接、算力调度与合规适配体系,补齐传统出海技术短板,为企业全球化精细化运营提供坚实支撑。一、2026 AI出海新格局:底层接口…...

Azure Quickstart Templates 多区域部署高可用架构设计终极指南:5步构建企业级灾难恢复方案
Azure Quickstart Templates 多区域部署高可用架构设计终极指南:5步构建企业级灾难恢复方案 【免费下载链接】azure-quickstart-templates Azure Quickstart Templates 项目地址: https://gitcode.com/gh_mirrors/az/azure-quickstart-templates 在当今数字化…...

从Anthropic论文到工程落地:Harness engineering结合claude code,讲解四层前端架构规范
AI 时代,许多人都体验过了vibecoding,但结果不同。 😀 同一个需求,不同的人用 AI 写,出来的代码质量可能差很远。 有的人能跑出一个中型功能,PR 干干净净的; 有的人用 AI 写出来的ÿ…...

混合人工智能架构可以将神经形态系统转变为可靠的发现机器。
基于ON-OFF神经元的高阶伊辛机架构。图片来源:Nature Communications (2026)。DOI:10.1038/s41467-026-71937-4来源:https://techxplore.com/news/2026-05-hybrid-ai-architecture-neuromorphic-reliable.html主导世界的AI机器可以分为三大类…...
 分布式系统测试-缓存-注册中心与链路追踪验证)
自动化测试(十二) 分布式系统测试-缓存-注册中心与链路追踪验证
分布式系统测试:缓存、注册中心与链路追踪验证上篇咱们搞定了消息队列测试,今天继续深入分布式系统的其他组件——Redis缓存、服务注册中心、分布式链路追踪。这些"基础设施"的测试往往被忽略,但出了问题定位起来最头疼。一、Redis…...

基于MCP协议构建AI助手业务工具适配器:从原理到实践
1. 项目概述:用MCP协议为AI助手装上“业务之眼”如果你和我一样,日常开发中需要频繁地在Stripe看支付数据、在Sentry查线上错误、在Notion里翻文档、在Linear跟进任务状态,那你一定懂那种在十几个浏览器标签页和不同SaaS平台间反复横跳的疲惫…...

017、GPS原理与定位基础
飞控算法从入门到精通 017 | GPS原理与定位基础 一、一次深夜炸机的教训 去年在郊外调试一架四轴,飞控是自研的Pixhawk变体,GPS模块用的u-blox M8N。起飞后悬停正常,切到Loiter模式后飞机开始缓慢漂移,大约30秒后突然朝东北方向加速,我切回Stabilize已经来不及——眼睁…...

IGF-I Analog ;CYAAPLKPALSSC
一、基础信息多肽名称:IGF-I Analog 胰岛素样生长因子 I 类似物 三字母序列:Cys-Tyr-Ala-Ala-Pro-Leu-Lys-Pro-Ala-Lys-Ser-Cys 单字母序列:CYAAPLKPALSSC 氨基酸数量:12 aa 结构修饰:分子内二硫键 二硫键配对…...

3步免费获取公式识别神器:img2latex-mathpix本地部署终极指南
3步免费获取公式识别神器:img2latex-mathpix本地部署终极指南 【免费下载链接】img2latex-mathpix Mathpix has changed their billing policy and no longer has free monthly API requests. This repo is now archived and will not receive any updates for the …...

软件设计原则之DIP依赖倒置原则
(DIP) 依赖倒置原则 Dependency Inversion Principle核心原则抽象不应该依赖细节;细节应该依赖于抽象。场景描述在一个应用程序 Application 中需要使用到数据库,比如我们此时需要使用到 Mysql 数据库。Mysql 数据库分别具有连接,断开关闭&am…...