11.Dockerfile最佳实践
Dockerfile 最佳实践
Docker官方关于Dockerfile最佳实践原文链接地址:https://docs.docker.com/develop/develop-images/dockerfile_best-practices/
Docker 可以通过从 Dockerfile 包含所有命令的文本文件中读取指令自动构建镜像,以便构建给定镜像。
Dockerfiles 使用特定的格式并使用一组特定的指令。您可以在Dockerfile Reference页面上了解基础知识 。如果你是新手写作Dockerfile,你应该从那里开始。
本文档介绍了由 Docker,Inc. 和 Docker 社区推荐的用于构建高效镜像的最佳实践和方法。
一般准则和建议
容器应该是短暂的
通过 Dockerfile 构建的镜像所启动的容器应该尽可能短暂(生命周期短)。「短暂」意味着可以停止和销毁容器,并且创建一个新容器并部署好所需的设置和配置工作量应该是极小的。我们可以查看下12 Factor(12要素)应用程序方法的进程部分,可以让我们理解这种无状态方式运行容器的动机。
建立上下文
当你发出一个docker build命令时,当前的工作目录被称为构建上下文。默认情况下,Dockerfile 就位于该路径下,当然您也可以使用-f参数来指定不同的位置。无论 Dockerfile 在什么地方,当前目录中的所有文件内容都将作为构建上下文发送到 Docker 守护进程中去。
下面是一个构建上下文的示例,为构建上下文创建一个目录并 cd 放入其中。将“hello”写入一个文本文件hello,然后并创建一个Dockerfile并运行cat。从构建上下文(.)中构建图像:
mkdir myproject && cd myproject
echo "hello" > hello
echo -e "FROM busybox\nCOPY /hello /\nRUN cat /hello" > Dockerfile
docker build -t helloapp:v1 .
现在移动 Dockerfile 和 hello 到不同的目录,并建立了图像的第二个版本(不依赖于缓存中的最后一个版本)。使用-f指向 Dockerfile 并指定构建上下文的目录:
mkdir -p dockerfiles context
mv Dockerfile dockerfiles && mv hello context
docker build --no-cache -t helloapp:v2 -f dockerfiles/Dockerfile context
在构建的时候包含不需要的文件会导致更大的构建上下文和更大的镜像大小。这会增加构建时间,拉取和推送镜像的时间以及容器的运行时间大小。要查看您的构建环境有多大,请在构建您的系统时查找这样的消息
Dockerfile:
Sending build context to Docker daemon 187.8MB
使用.dockerignore文件
使用 Dockerfile 构建镜像时最好是将 Dockerfile 放置在一个新建的空目录下。然后将构建镜像所需要的文件添加到该目录中。为了提高构建镜像的效率,你可以在目录下新建一个.dockerignore文件来指定要忽略的文件和目录。.dockerignore 文件的排除模式语法和 Git 的 .gitignore 文件相似。
使用多阶段构建
在 Docker 17.05 以上版本中,你可以使用 多阶段构建 来减少所构建镜像的大小。上一节课我们已经重点讲解过了。
避免安装不必要的包
为了降低复杂性、减少依赖、减小文件大小和构建时间,应该避免安装额外的或者不必要的软件包。例如,不要在数据库镜像中包含一个文本编辑器。
一个容器只专注做一件事情
应该保证在一个容器中只运行一个进程。将多个应用解耦到不同容器中,保证了容器的横向扩展和复用。例如一个 web 应用程序可能包含三个独立的容器:web应用、数据库、缓存,每个容器都是独立的镜像,分开运行。但这并不是说一个容器就只跑一个进程,因为有的程序可能会自行产生其他进程,比如 Celery 就可以有很多个工作进程。虽然“每个容器跑一个进程”是一条很好的法则,但这并不是一条硬性的规定。我们主要是希望一个容器只关注意见事情,尽量保持干净和模块化。
如果容器互相依赖,你可以使用Docker 容器网络来把这些容器连接起来,我们前面已经跟大家讲解过 Docker 的容器网络模式了。
最小化镜像层数
在 Docker 17.05 甚至更早 1.10之 前,尽量减少镜像层数是非常重要的,不过现在的版本已经有了一定的改善了:
- 在 1.10 以后,只有 RUN、COPY 和 ADD 指令会创建层,其他指令会创建临时的中间镜像,但是不会直接增加构建的镜像大小了。
- 上节课我们也讲解到了 17.05 版本以后增加了多阶段构建的支持,允许我们把需要的数据直接复制到最终的镜像中,这就允许我们在中间阶段包含一些工具或者调试信息了,而且不会增加最终的镜像大小。
当然减少RUN、COPY、ADD的指令仍然是很有必要的,但是我们也需要在 Dockerfile 可读性(也包括长期的可维护性)和减少层数之间做一个平衡。
对多行参数排序
只要有可能,就将多行参数按字母顺序排序(比如要安装多个包时)。这可以帮助你避免重复包含同一个包,更新包列表时也更容易,也更容易阅读和审查。建议在反斜杠符号 \ 之前添加一个空格,可以增加可读性。
下面是来自 buildpack-deps 镜像的例子:
RUN apt-get update && apt-get install -y \bzr \cvs \git \mercurial \subversion
构建缓存
在镜像的构建过程中,Docker 根据 Dockerfile 指定的顺序执行每个指令。在执行每条指令之前,Docker 都会在缓存中查找是否已经存在可重用的镜像,如果有就使用现存的镜像,不再重复创建。当然如果你不想在构建过程中使用缓存,你可以在 docker build 命令中使用--no-cache=true选项。
如果你想在构建的过程中使用了缓存,那么了解什么时候可以什么时候无法找到匹配的镜像就很重要了,Docker中缓存遵循的基本规则如下:
- 从一个基础镜像开始(FROM 指令指定),下一条指令将和该基础镜像的所有子镜像进行匹配,检查这些子镜像被创建时使用的指令是否和被检查的指令完全一样。如果不是,则缓存失效。
- 在大多数情况下,只需要简单地对比 Dockerfile 中的指令和子镜像。然而,有些指令需要更多的检查和解释。
- 对于 ADD 和 COPY 指令,镜像中对应文件的内容也会被检查,每个文件都会计算出一个校验值。这些文件的修改时间和最后访问时间不会被纳入校验的范围。在缓存的查找过程中,会将这些校验和和已存在镜像中的文件校验值进行对比。如果文件有任何改变,比如内容和元数据,则缓存失效。
- 除了 ADD 和 COPY 指令,缓存匹配过程不会查看临时容器中的文件来决定缓存是否匹配。例如,当执行完 RUN apt-get -y update 指令后,容器中一些文件被更新,但 Docker 不会检查这些文件。这种情况下,只有指令字符串本身被用来匹配缓存。
- 一旦缓存失效,所有后续的 Dockerfile 指令都将产生新的镜像,缓存不会被使用。
Dockerfile 指令
下面是一些常用的 Dockerfile 指令,我们也分别来总结下,根据上面的建议和下面这些指令的合理使用,可以帮助我们编写高效且易维护的 Dockerfile 文件。
FROM
尽可能使用当前官方仓库作为你构建镜像的基础。推荐使用Alpine镜像,因为它被严格控制并保持最小尺寸(目前小于 5 MB),但它仍然是一个完整的发行版。
LABEL
你可以给镜像添加标签来帮助组织镜像、记录许可信息、辅助自动化构建等。每个标签一行,由 LABEL 开头加上一个或多个标签对。
下面的示例展示了各种不同的可能格式。#开头的行是注释内容。
注意:如果你的字符串包含空格,那么它必须被引用或者空格必须被转义。如果您的字符串包含内部引号字符("),则也可以将其转义。
# Set one or more individual labels
LABEL com.example.version="0.0.1-beta"
LABEL vendor="ACME Incorporated"
LABEL com.example.release-date="2015-02-12"
LABEL com.example.version.is-production=""
一个镜像可以包含多个标签,在 1.10 之前,建议将所有标签合并为一条LABEL指令,以防止创建额外的层,但是现在这个不再是必须的了,以上内容也可以写成下面这样:
# Set multiple labels at once, using line-continuation characters to break long lines
LABEL vendor=ACME\ Incorporated \com.example.is-production="" \com.example.version="0.0.1-beta" \com.example.release-date="2015-02-12"
关于标签可以接受的键值对,参考Understanding object labels。
RUN
为了保持 Dockerfile 文件的可读性,以及可维护性,建议将长的或复杂的RUN指令用反斜杠\分割成多行。
RUN 指令最常见的用法是安装包用的apt-get。因为RUN apt-get指令会安装包,所以有几个问题需要注意。
- 不要使用 RUN apt-get upgrade 或 dist-upgrade,如果基础镜像中的某个包过时了,你应该联系它的维护者。如果你确定某个特定的包,比如 foo,需要升级,使用 apt-get install -y foo 就行,该指令会自动升级 foo 包。
- 永远将 RUN apt-get update 和 apt-get install 组合成一条 RUN 声明,例如:
RUN apt-get update && apt-get install -y \package-bar \package-baz \package-foo
将 apt-get update 放在一条单独的 RUN 声明中会导致缓存问题以及后续的 apt-get install 失败。比如,假设你有一个 Dockerfile 文件:
FROM ubuntu:14.04
RUN apt-get update
RUN apt-get install -y curl
构建镜像后,所有的层都在 Docker 的缓存中。假设你后来又修改了其中的 apt-get install 添加了一个包:
FROM ubuntu:14.04
RUN apt-get update
RUN apt-get install -y curl nginx
Docker 发现修改后的 RUN apt-get update 指令和之前的完全一样。所以,apt-get update 不会执行,而是使用之前的缓存镜像。因为 apt-get update 没有运行,后面的 apt-get install 可能安装的是过时的 curl 和 nginx 版本。
使用RUN apt-get update && apt-get install -y可以确保你的Dockerfiles每次安装的都是包的最新的版本,而且这个过程不需要进一步的编码或额外干预。这项技术叫作cache busting(缓存破坏)。你也可以显示指定一个包的版本号来达到 cache-busting,这就是所谓的固定版本,例如:
RUN apt-get update && apt-get install -y \package-bar \package-baz \package-foo=1.3.*
固定版本会迫使构建过程检索特定的版本,而不管缓存中有什么。这项技术也可以减少因所需包中未预料到的变化而导致的失败。
下面是一个 RUN 指令的示例模板,展示了所有关于 apt-get 的建议。
RUN apt-get update && apt-get install -y \aufs-tools \automake \build-essential \curl \dpkg-sig \libcap-dev \libsqlite3-dev \mercurial \reprepro \ruby1.9.1 \ruby1.9.1-dev \s3cmd=1.1.* \&& rm -rf /var/lib/apt/lists/*
其中 s3cmd 指令指定了一个版本号 1.1.*。如果之前的镜像使用的是更旧的版本,指定新的版本会导致 apt-get udpate 缓存失效并确保安装的是新版本。
另外,清理掉 apt 缓存 var/lib/apt/lists 可以减小镜像大小。因为 RUN 指令的开头为 apt-get udpate,包缓存总是会在 apt-get install 之前刷新。
注意:官方的 Debian 和 Ubuntu 镜像会自动运行 apt-get clean,所以不需要显式的调用 apt-get clean。
CMD
CMD指令用于执行目标镜像中包含的软件和任何参数。CMD 几乎都是以CMD ["executable", "param1", "param2"...]的形式使用。因此,如果创建镜像的目的是为了部署某个服务(比如 Apache),你可能会执行类似于CMD ["apache2", "-DFOREGROUND"]形式的命令。
多数情况下,CMD 都需要一个交互式的 shell (bash, Python, perl 等),例如 CMD [“perl”, “-de0”],或者 CMD [“PHP”, “-a”]。使用这种形式意味着,当你执行类似docker run -it python时,你会进入一个准备好的 shell 中。
CMD 在极少的情况下才会以 CMD [“param”, “param”] 的形式与ENTRYPOINT协同使用,除非你和你的镜像使用者都对 ENTRYPOINT 的工作方式十分熟悉。
EXPOSE
EXPOSE指令用于指定容器将要监听的端口。因此,你应该为你的应用程序使用常见的端口。
例如,提供 Apache web 服务的镜像应该使用 EXPOSE 80,而提供 MongoDB 服务的镜像使用 EXPOSE 27017。
对于外部访问,用户可以在执行 docker run 时使用一个标志来指示如何将指定的端口映射到所选择的端口。
ENV
为了方便新程序运行,你可以使用ENV来为容器中安装的程序更新 PATH 环境变量。例如使用ENV PATH /usr/local/nginx/bin:$PATH来确保CMD ["nginx"]能正确运行。
ENV 指令也可用于为你想要容器化的服务提供必要的环境变量,比如 Postgres 需要的 PGDATA。
最后,ENV 也能用于设置常见的版本号,比如下面的示例:
ENV PG_MAJOR 9.3
ENV PG_VERSION 9.3.4
RUN curl -SL http://example.com/postgres-$PG_VERSION.tar.xz | tar -xJC /usr/src/postgress && …ENV PATH /usr/local/postgres-$PG_MAJOR/bin:$PATH
类似于程序中的常量,这种方法可以让你只需改变 ENV 指令来自动的改变容器中的软件版本。
ADD 和 COPY
虽然ADD和COPY功能类似,但一般优先使用 COPY。因为它比 ADD 更透明。COPY 只支持简单将本地文件拷贝到容器中,而 ADD 有一些并不明显的功能(比如本地 tar 提取和远程 URL 支持)。因此,ADD的最佳用例是将本地 tar 文件自动提取到镜像中,例如ADD rootfs.tar.xz。
如果你的 Dockerfile 有多个步骤需要使用上下文中不同的文件。单独 COPY 每个文件,而不是一次性的 COPY 所有文件,这将保证每个步骤的构建缓存只在特定的文件变化时失效。例如:
COPY requirements.txt /tmp/
RUN pip install --requirement /tmp/requirements.txt
COPY . /tmp/
如果将COPY . /tmp/放置在 RUN 指令之前,只要 . 目录中任何一个文件变化,都会导致后续指令的缓存失效。
为了让镜像尽量小,最好不要使用 ADD 指令从远程 URL 获取包,而是使用 curl 和 wget。这样你可以在文件提取完之后删掉不再需要的文件来避免在镜像中额外添加一层。比如尽量避免下面的用法:
ADD http://example.com/big.tar.xz /usr/src/things/
RUN tar -xJf /usr/src/things/big.tar.xz -C /usr/src/things
RUN make -C /usr/src/things all
而是应该使用下面这种方法:
RUN mkdir -p /usr/src/things \&& curl -SL http://example.com/big.tar.xz \| tar -xJC /usr/src/things \&& make -C /usr/src/things all
上面使用的管道操作,所以没有中间文件需要删除。
对于其他不需要 ADD 的自动提取功能的文件或目录,你应该使用 COPY。
ENTRYPOINT
ENTRYPOINT的最佳用处是设置镜像的主命令,允许将镜像当成命令本身来运行(用 CMD 提供默认选项)。
例如,下面的示例镜像提供了命令行工具 s3cmd:
ENTRYPOINT ["s3cmd"]
CMD ["--help"]
现在直接运行该镜像创建的容器会显示命令帮助:
$ docker run s3cmd
或者提供正确的参数来执行某个命令:
$ docker run s3cmd ls s3://mybucket
这样镜像名可以当成命令行的参考。ENTRYPOINT 指令也可以结合一个辅助脚本使用,和前面命令行风格类似,即使启动工具需要不止一个步骤。
例如,Postgres 官方镜像使用下面的脚本作为 ENTRYPOINT:
#!/bin/bash
set -e
if [ "$1" = 'postgres' ]; thenchown -R postgres "$PGDATA"if [ -z "$(ls -A "$PGDATA")" ]; thengosu postgres initdbfiexec gosu postgres "$@"fi
exec "$@"
注意:该脚本使用了 Bash 的内置命令 exec,所以最后运行的进程就是容器的 PID 为 1 的进程。这样,进程就可以接收到任何发送给容器的 Unix 信号了。
该辅助脚本被拷贝到容器,并在容器启动时通过 ENTRYPOINT 执行:
COPY ./docker-entrypoint.sh /
ENTRYPOINT ["/docker-entrypoint.sh"]
该脚本可以让用户用几种不同的方式和 Postgres 交互。你可以很简单地启动 Postgres:
$ docker run postgres
也可以执行 Postgres 并传递参数:
$ docker run postgres postgres --help
最后,你还可以启动另外一个完全不同的工具,比如 Bash:
$ docker run --rm -it postgres bash
VOLUME
VOLUME指令用于暴露任何数据库存储文件,配置文件,或容器创建的文件和目录。强烈建议使用 VOLUME来管理镜像中的可变部分和用户可以改变的部分。
USER
如果某个服务不需要特权执行,建议使用 USER 指令切换到非 root 用户。先在 Dockerfile 中使用类似 RUN groupadd -r postgres && useradd -r -g postgres postgres 的指令创建用户和用户组。
注意:在镜像中,用户和用户组每次被分配的 UID/GID 都是不确定的,下次重新构建镜像时被分配到的 UID/GID 可能会不一样。如果要依赖确定的 UID/GID,你应该显示的指定一个 UID/GID。
你应该避免使用 sudo,因为它不可预期的 TTY 和信号转发行为可能造成的问题比它能解决的问题还多。如果你真的需要和 sudo 类似的功能(例如,以 root 权限初始化某个守护进程,以非 root 权限执行它),你可以使用 gosu。
最后,为了减少层数和复杂度,避免频繁地使用 USER 来回切换用户。
WORKDIR
为了清晰性和可靠性,你应该总是在WORKDIR中使用绝对路径。另外,你应该使用 WORKDIR 来替代类似于 RUN cd … && do-something 的指令,后者难以阅读、排错和维护。
ONBUILD
格式:ONBUILD <其它指令>。
ONBUILD是一个特殊的指令,它后面跟的是其它指令,比如 RUN, COPY 等,而这些指令,在当前镜像构建时并不会被执行。只有当以当前镜像为基础镜像,去构建下一级镜像的时候才会被执行。Dockerfile 中的其它指令都是为了定制当前镜像而准备的,唯有 ONBUILD 是为了帮助别人定制自己而准备的。
假设我们要制作 Node.js 所写的应用的镜像。我们都知道 Node.js 使用 npm 进行包管理,所有依赖、配置、启动信息等会放到 package.json 文件里。在拿到程序代码后,需要先进行 npm install 才可以获得所有需要的依赖。然后就可以通过 npm start 来启动应用。因此,一般来说会这样写 Dockerfile:
FROM node:slim
RUN mkdir /app
WORKDIR /app
COPY ./package.json /app
RUN [ "npm", "install" ]
COPY . /app/
CMD [ "npm", "start" ]
把这个 Dockerfile 放到 Node.js 项目的根目录,构建好镜像后,就可以直接拿来启动容器运行。但是如果我们还有第二个 Node.js 项目也差不多呢?好吧,那就再把这个 Dockerfile 复制到第二个项目里。那如果有第三个项目呢?再复制么?文件的副本越多,版本控制就越困难,让我们继续看这样的场景维护的问题:
如果第一个 Node.js 项目在开发过程中,发现这个 Dockerfile 里存在问题,比如敲错字了、或者需要安装额外的包,然后开发人员修复了这个 Dockerfile,再次构建,问题解决。第一个项目没问题了,但是第二个项目呢?虽然最初 Dockerfile 是复制、粘贴自第一个项目的,但是并不会因为第一个项目修复了他们的 Dockerfile,而第二个项目的 Dockerfile 就会被自动修复。
那么我们可不可以做一个基础镜像,然后各个项目使用这个基础镜像呢?这样基础镜像更新,各个项目不用同步 Dockerfile 的变化,重新构建后就继承了基础镜像的更新?好吧,可以,让我们看看这样的结果。那么上面的这个 Dockerfile 就会变为:
FROM node:slim
RUN mkdir /app
WORKDIR /app
CMD [ "npm", "start" ]
这里我们把项目相关的构建指令拿出来,放到子项目里去。假设这个基础镜像的名字为 my-node 的话,各个项目内的自己的 Dockerfile 就变为:
FROM my-node
COPY ./package.json /app
RUN [ "npm", "install" ]
COPY . /app/
基础镜像变化后,各个项目都用这个 Dockerfile 重新构建镜像,会继承基础镜像的更新。
那么,问题解决了么?没有。准确说,只解决了一半。如果这个 Dockerfile 里面有些东西需要调整呢?比如 npm install 都需要加一些参数,那怎么办?这一行 RUN 是不可能放入基础镜像的,因为涉及到了当前项目的 ./package.json,难道又要一个个修改么?所以说,这样制作基础镜像,只解决了原来的 Dockerfile 的前4条指令的变化问题,而后面三条指令的变化则完全没办法处理。
ONBUILD 可以解决这个问题。让我们用 ONBUILD 重新写一下基础镜像的 Dockerfile:
FROM node:slim
RUN mkdir /app
WORKDIR /app
ONBUILD COPY ./package.json /app
ONBUILD RUN [ "npm", "install" ]
ONBUILD COPY . /app/
CMD [ "npm", "start" ]
这次我们回到原始的 Dockerfile,但是这次将项目相关的指令加上 ONBUILD,这样在构建基础镜像的时候,这三行并不会被执行。然后各个项目的 Dockerfile 就变成了简单地:
FROM my-node
是的,只有这么一行。当在各个项目目录中,用这个只有一行的 Dockerfile 构建镜像时,之前基础镜像的那三行 ONBUILD 就会开始执行,成功的将当前项目的代码复制进镜像、并且针对本项目执行 npm install,生成应用镜像。
官方仓库示例
这些官方仓库的 Dockerfile 都是参考典范:https://github.com/docker-library/docs
相关文章:

11.Dockerfile最佳实践
Dockerfile 最佳实践 Docker官方关于Dockerfile最佳实践原文链接地址:https://docs.docker.com/develop/develop-images/dockerfile_best-practices/ Docker 可以通过从 Dockerfile 包含所有命令的文本文件中读取指令自动构建镜像,以便构建给定镜像。 …...
【企业云端全栈开发实践-1】项目介绍及环境准备、Spring Boot快速上手
本节目录一、 项目内容介绍二、Maven介绍2.1 Maven作用2.2 Maven依赖2.3 本地仓库配置三、Spring Boot快速上手3.1 Spring Boot特点3.2 遇到的Bug:spring-boot-maven-plugin3.3 遇到的Bug2:找不到Getmapping四、开发环境热部署一、 项目内容介绍 本课程…...
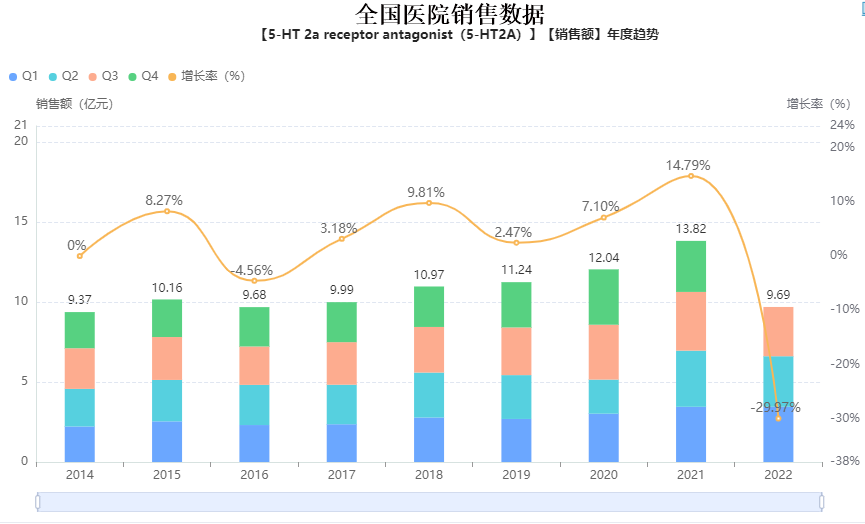
5-HT2A靶向药物|适应症|市场销售-上市药品前景分析
据世界卫生组织称,抑郁症是一种多因素疾病,影响全球约3.5 亿人。中枢神经系统最广泛的单胺 - 血清素 (5-HT) 被认为在这种情况的病理机制中起着至关重要的作用,并且神经递质的重要性被“血清素假说”提升,将抑郁症的存在联系起来 …...

HTTPS协议原理---详解
目录 一、HTTPS 1.加密与解密 2.我们为什么要加密? 3.常见加密方式 ①对称加密 ②非对称加密 4.数据摘要 5.数字签名 二、HTTPS的加密方案 1.只是用对称加密 2.只使用非对称加密 3.双方都使用非对称加密 4.非对称加密+对称加密 中间人攻…...
Pytest学习笔记
Pytest学习笔记 1、介绍 1.1、单元测试 单元测试是指在软件开发当中,针对软件的最小单位(函数,方法)进行正确性的检查测试 1.2、单元测试框架 测试发现:从多个py文件里面去找到我们测试用例测试执行:按…...
Fuzz概述
文章目录AFL一些概念插桩与覆盖率边和块覆盖率afl自实现劫持汇编器clang内置覆盖率反馈与引导变异遗传算法fork server机制AFL调试准备AFL一些概念 插桩与覆盖率 边和块 首先,要明白边和块的定义 正方形的就是块,箭头表示边,边表示程序执行…...
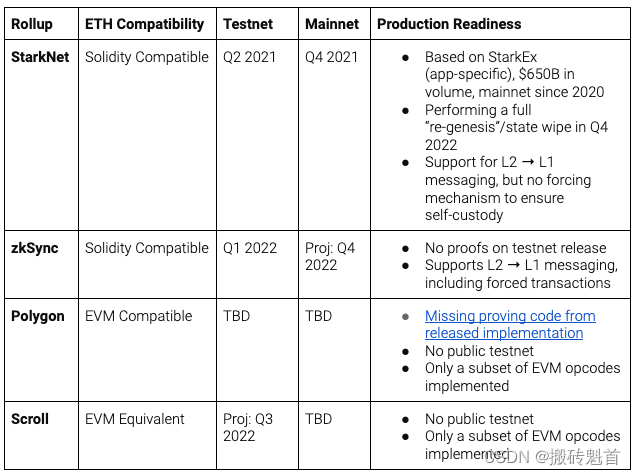
区块链知识系列 - 系统学习EVM(四)-zkEVM
区块链知识系列 - 系统学习EVM(一) 区块链知识系列 - 系统学习EVM(二) 区块链知识系列 - 系统学习EVM(三) 今天我们来聊聊 zkEVM、EVM 兼容性 和 Rollup 是什么? 1. 什么是 Rollup rollup顾名思义,就是把一堆交易卷(rollup)起来…...

Leetcode.2341 数组能形成多少数对
题目链接 Leetcode.2341 数组能形成多少数对 Rating : 1185 题目描述 给你一个下标从 0 开始的整数数组 nums。在一步操作中,你可以执行以下步骤: 从 nums选出 两个 相等的 整数从 nums中移除这两个整数,形成一个 数对 请你在 nums上多次执…...

C++复习笔记10
1. list是可以在常数范围内在任意位置进行插入和删除的序列式容器,并且该容器可以前后双向迭代。 2. list的底层是双向链表结构,双向链表中每个元素存储在互不相关的独立节点中,在节点中通过指针指向其前一个元素和后一个元素。 3. list与for…...
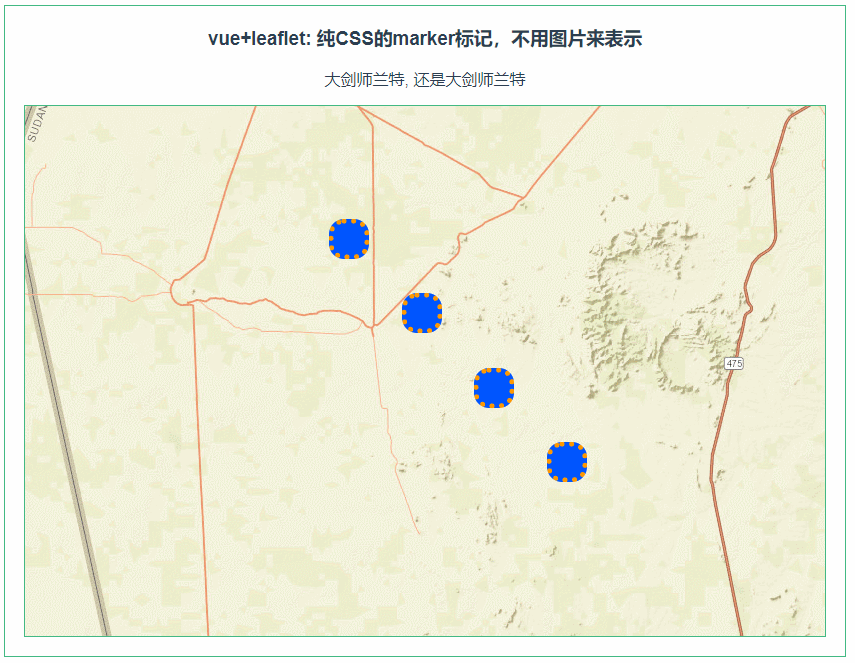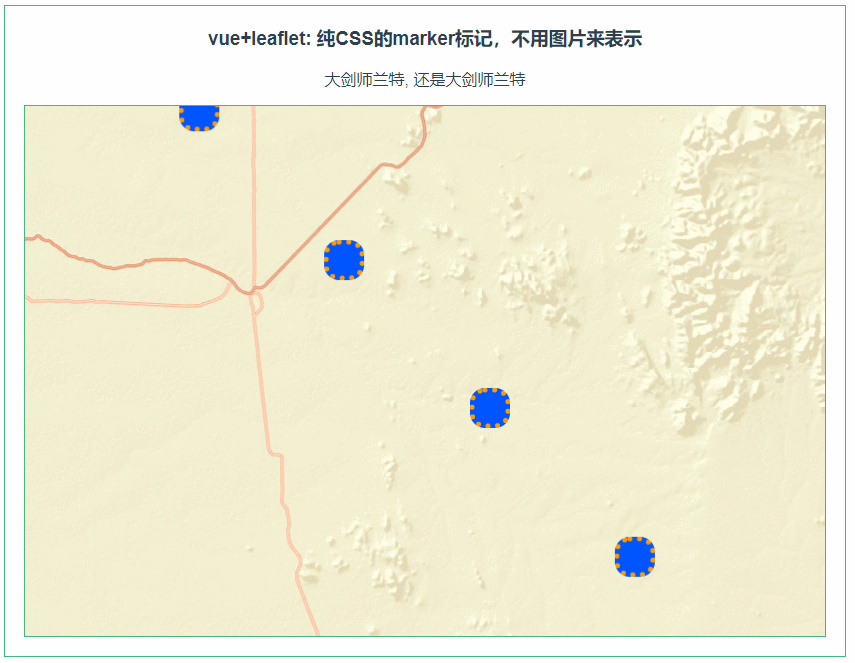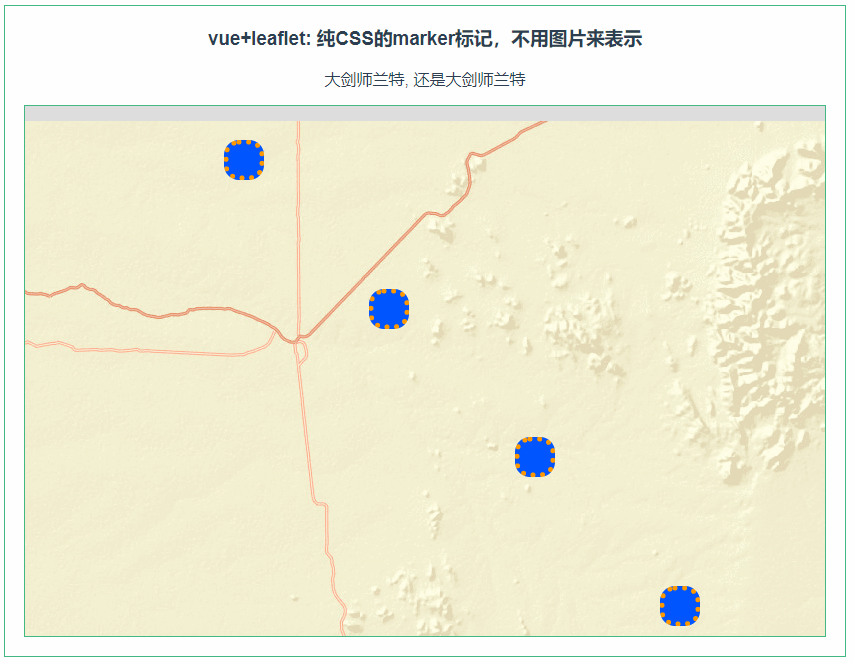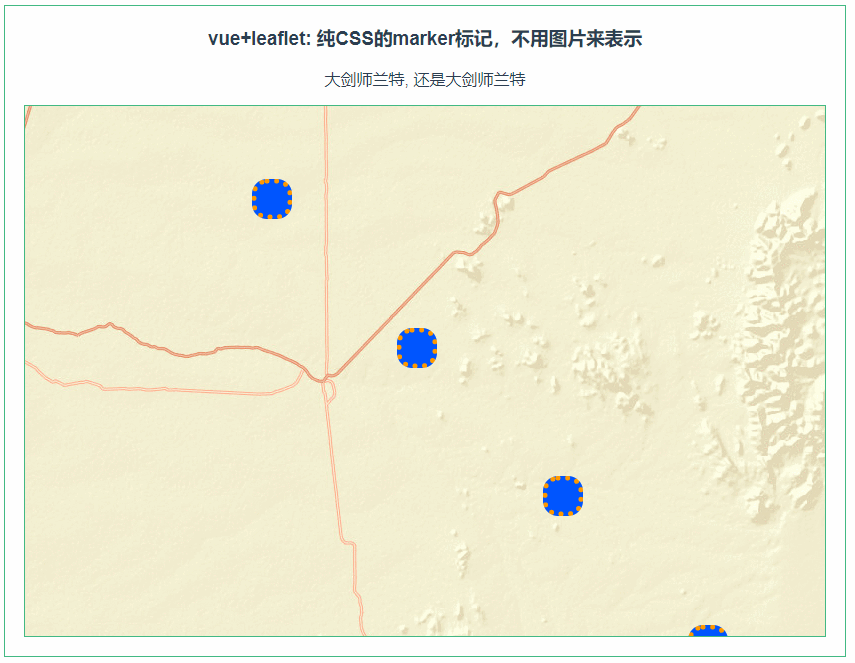
leaflet 纯CSS的marker标记,不用图片来表示(072)
第072个 点击查看专栏目录 本示例的目的是介绍演示如何在vue+leaflet中使用纯CSS来打造marker的标记。这里用到的是L.divIcon来引用CSS来构造新icon,然后在marker的属性中引用。 这里必须要注意的是css需要是全局性质的,不能被scoped转义为其他随机的css。 直接复制下面的 v…...
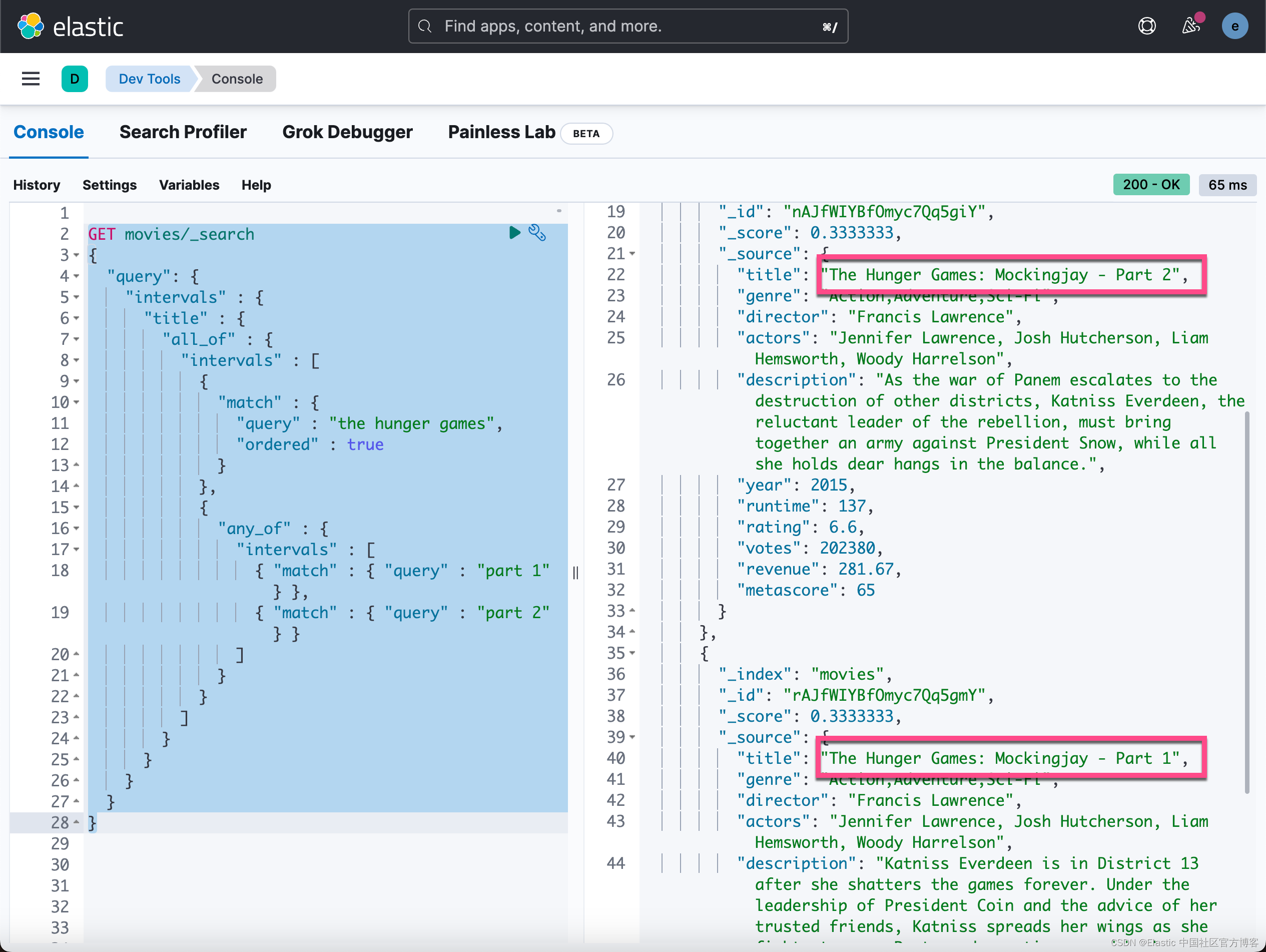
Elasticsearch:使用 intervals query - 根据匹配项的顺序和接近度返回文档
Intervals query 根据匹配项的顺序和接近度返回文档。Intervals 查询使用匹配规则,由一小组定义构成。 然后将这些规则应用于指定字段中的术语。 这些定义产生跨越文本正文中的术语的最小间隔序列。 这些间隔可以通过父源进一步组合和过滤。 上述描述有点费解。我…...
无法决定博客主题的人必看!如何选择类型和推荐的 5 种选择
是否有人不能迈出第一步,因为博客的类型还没有决定?有些人在出发时应该行动,而不是思考,但让我们冷静下来,仔细想想。博客的难度因流派而异,这在很大程度上决定了随后的发展。因此,在选择博客流…...
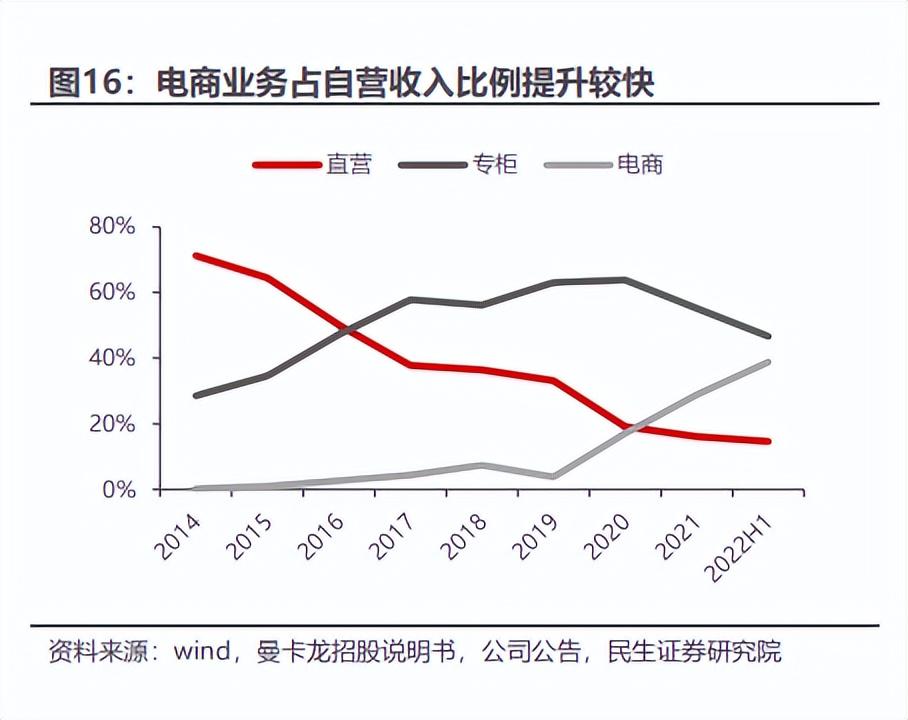
数字化转型的成功模版,珠宝龙头曼卡龙做对了什么?
2月11日,曼卡龙(300945.SZ)发布2022年业绩快报,报告期内,公司实现营业收入16.11亿元,同比增长28.63%。来源:曼卡龙2022年度业绩快报曼卡龙能在2022年实现营收增长尤为不易。2022年受疫情影响&am…...
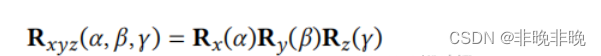
转换矩阵、平移矩阵、旋转矩阵关系以及python实现旋转矩阵、四元数、欧拉角之间转换
文章目录1. 转换矩阵、平移矩阵、旋转矩阵之间的关系2. 缩放变换、平移变换和旋转变换2. python实现旋转矩阵、四元数、欧拉角互相转化由于在平时总是或多或少的遇到平移旋转的问题,每次都是现查资料,然后查了忘,忘了继续查,这次弄…...
中国地图航线图(echarjs)
1、以上为效果图 需要jq、echarjs、china.json三个文件支持。以上 2、具体代码 DOM部分 <!-- 服务范围 GO--> <div class"m-maps"><div id"main" style"width:1400px;height: 800px; margin: 0 auto;"> </div> <!-…...
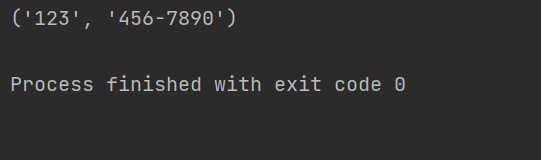
Python正则表达式中group与groups的用法详解
本文主要介绍了Python正则表达式中group与groups的用法详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧目录在Python中,正则表达式的group和groups方…...

c++练习题7
1.下列运算符中优先级最高的是 A)> B) C) && D)! 2.以下关于运算符优先级的描述中,正确的是 。 A)!(逻辑非&#x…...

MySQL学习
目录1、数据库定义基本语句(1)数据库操作(2)数据表操作2.数据库操作SQL语句(1)插入数据(2)更新语句(3)删除数据3.数据库查询语句(1)基…...

C语言(强制类型转换)
一.类型转换原则 1.升级:当类型转换出现在表达式时,无论时unsigned还是signed的char和short都会被自动转换成int,如有必要会被转换成unsigned int(如果short与int的大小相同,unsigned short就比int大。这种情况下,uns…...

搭建hadoop高可用集群(二)
搭建hadoop高可用集群(一)配置hadoophadoop-env.shworkerscore-site.xmlhdfs-site.xmlmapred-site.xmlyarn-site.xml/etc/profile拷贝集群首次启动1、先启动zk集群(自动化脚本)2、在hadoop151,hadoop152,hadoop153启动JournalNode…...
Google Translate PHP测试驱动开发:确保翻译质量的最佳实践指南
Google Translate PHP测试驱动开发:确保翻译质量的最佳实践指南 【免费下载链接】google-translate-php 🔤 Free Google Translate API PHP Package. Translates totally free of charge. 项目地址: https://gitcode.com/gh_mirrors/go/google-transla…...

为什么电路中的阻抗需要引入复数?
1、方便计算说法▼无他,就是图个方便计算而已。请看下题,求如图所示电路中电流的大小。电流的频率与电压频率相同,无非就是求解幅值的变化和相位的变化。▼引用一下以前我的一个知乎回答,数学中的数先是从一维数轴开始。▼因电路的…...

【信息科学与工程学】【控制科学】第三篇 管理系统控制知识
管理系统控制知识 表K.144501 管理系统控制概述 项目 内容 定理/规律/数学方程式/集合特征/几何特征/拓扑特征/代数特征 1. 管理控制定义:控制系统S = (A, B, C, D),其中A是控制主体集合,B是被控对象集合,C是控制规则集合,D是信息流集合 2. 控制层级定理:高层战略控…...

【信息科学与工程学】【制造工程】【通信工程】第一百零一篇 2nm 200Tbps+核心交换机全尺度参数 第二系列 物料与生产体系12
系统概述 系统名称: 200Tbps 集群核心交换机 核心功能: 提供超高密度、超低延迟、无阻塞的数据交换,用于数据中心集群核心或超算中心网络。 系统组成: 机箱、主控板卡、交换网板卡(4块,互为冗余)、线卡(业务板卡)、风扇模块、电源模块。 关键设计参数: 整机交换容量: …...
)
告别虚拟机:用RK3399开发板搭建你的移动机器人SLAM实验平台(ROS Kinetic + OpenCV 3.4.0)
基于RK3399的移动机器人SLAM实验平台全栈搭建指南 在机器人技术快速发展的今天,同时定位与地图构建(SLAM)已成为自主移动系统的核心技术之一。然而,高性能计算设备的高昂成本往往成为学习者和开发者面临的首要障碍。Rockchip RK3399开发板以其出色的性价…...

Cursor AI编程规则深度解析:从项目规范到团队协同的实战指南
1. 项目概述:从“Cursor Rules”看现代开发者的效率革命如果你是一名开发者,最近可能频繁听到一个词:Cursor。它不仅仅是一个编辑器,更是一个集成了AI能力的开发环境,正在悄然改变我们写代码的方式。而今天要聊的这个项…...

开源AI导航站:从数据结构到社区协作的实战解析
1. 项目概述:一个AI导航站是如何炼成的作为一个长期混迹在AI工具圈的老鸟,我深知一个痛点:每天都有新的AI应用冒出来,但想找到一个靠谱、好用、还免费的,往往得在搜索引擎、社交媒体和各个论坛里“大海捞针”。直到我遇…...

Flutter 性能优化完全指南
Flutter 性能优化完全指南 引言 性能优化是移动应用开发中至关重要的一环。Flutter 虽然天生具有较好的性能表现,但在复杂应用中仍需要开发者进行针对性优化。本文将深入探讨 Flutter 性能优化的各种技巧和最佳实践。 性能问题定位 使用 DevTools // 在 pubspec.yam…...

独立开发者如何借助Taotoken以更低成本体验多种大模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何借助Taotoken以更低成本体验多种大模型 对于独立开发者或个人项目而言,技术选型与成本控制是项目初期面…...

Python分布式系统设计:从理论到实践
Python分布式系统设计:从理论到实践 引言 分布式系统是现代后端架构的核心,它通过多节点协作来实现高可用、高性能和可扩展性。Python虽然不是传统的系统编程语言,但通过丰富的库和框架,也可以构建强大的分布式系统。 本文将深…...