自动驾驶:BEV开山之作LSS(lift,splat,shoot)原理代码串讲
自动驾驶:BEV开山之作LSS(lift,splat,shoot)原理代码串讲
- 前言
- Lift
- 参数
- 创建视锥
- CamEncode
- Splat
- 转换视锥坐标系
- Voxel Pooling
- 总结
前言

目前在自动驾驶领域,比较火的一类研究方向是基于采集到的环视图像信息,去构建BEV视角下的特征完成自动驾驶感知的相关任务。所以如何准确的完成从相机视角向BEV视角下的转变就变得由为重要。目前感觉比较主流的方法可以大体分为两种:
- 显式估计图像的深度信息,完成BEV视角的构建,在某些文章中也被称为自下而上的构建方式;
- 利用transformer中的query查询机制,利用BEV Query构建BEV特征,这一过程也被称为自上而下的构建方式;
LSS最大的贡献在于:提供了一个端到端的训练方法,解决了多个传感器融合的问题。传统的多个传感器单独检测后再进行后处理的方法无法将此过程损失传进行反向传播而调整相机输入,而LSS则省去了这一阶段的后处理,直接输出融合结果。
Lift
参数
我们先介绍一下一些参数:
感知范围
x轴方向的感知范围 -50m ~ 50m;y轴方向的感知范围 -50m ~ 50m;z轴方向的感知范围 -10m ~ 10m;
BEV单元格大小
x轴方向的单位长度 0.5m;y轴方向的单位长度 0.5m;z轴方向的单位长度 20m;
BEV的网格尺寸
200 x 200 x 1;
深度估计范围
由于LSS需要显式估计像素的离散深度,论文给出的范围是 4m ~ 45m,间隔为1m,也就是算法会估计41个离散深度,也就是下面的dbound。
why dbound:
因为二维像素可以理解为现实世界中的某一个点到相机中心的一条射线,我们如果知道相机的内外参数,就是知道了对应关系,但是我们不知道是射线上面的那一个点(也就是不知道depth),所以作者在距离相机5m到45m的视锥内,每隔1m有一个模型可选的深度值(这样每个像素有41个可选的离散深度值)。
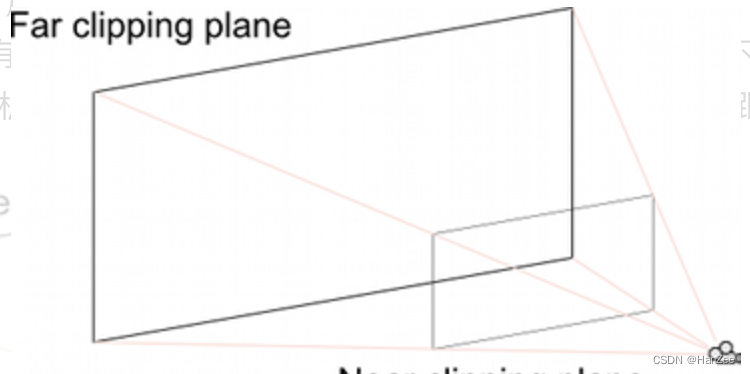
代码如下:
ogfH=128
ogfW=352
xbound=[-50.0, 50.0, 0.5]
ybound=[-50.0, 50.0, 0.5]
zbound=[-10.0, 10.0, 20.0]
dbound=[4.0, 45.0, 1.0]
fH, fW = ogfH // 16, ogfW // 16
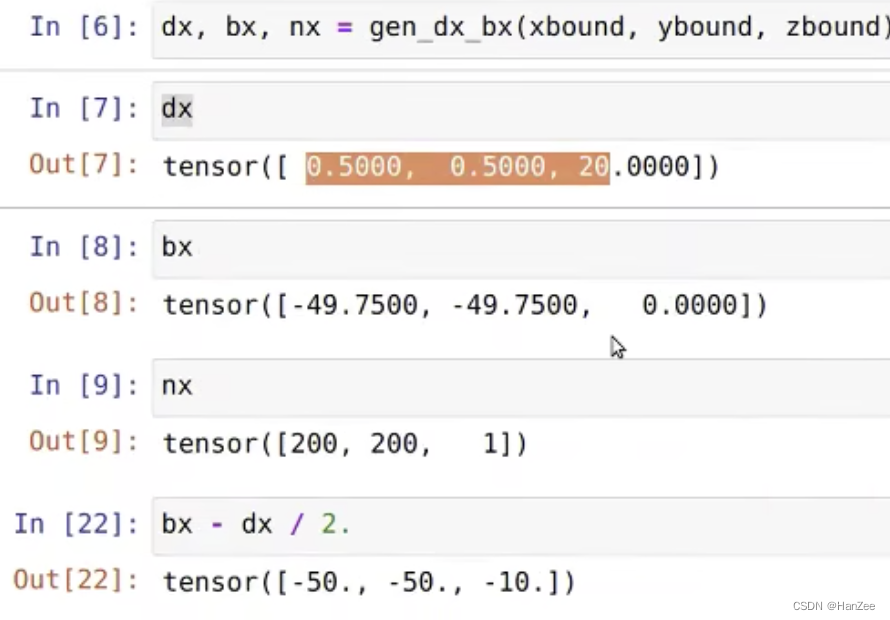
创建视锥
什么是视锥?
代码:
def create_frustum(self):# make grid in image planeogfH, ogfW = self.data_aug_conf['final_dim']fH, fW = ogfH // self.downsample, ogfW // self.downsampleds = torch.arange(*self.grid_conf['dbound'], dtype=torch.float).view(-1, 1, 1).expand(-1, fH, fW)D, _, _ = ds.shapexs = torch.linspace(0, ogfW - 1, fW, dtype=torch.float).view(1, 1, fW).expand(D, fH, fW)ys = torch.linspace(0, ogfH - 1, fH, dtype=torch.float).view(1, fH, 1).expand(D, fH, fW)# D x H x W x 3frustum = torch.stack((xs, ys, ds), -1)return nn.Parameter(frustum, requires_grad=False)
根据代码可知,它的尺寸是根据一个2dimage构建的,它的尺寸为D * H * W * 3,维度3表示:【 x,y,depth】。我们可以把这个视锥理解为一个长方体,长x,宽y 高depth,视锥中的每个点都是长方体的坐标。
CamEncode
这部分主要是通过Efficient Net来提取图像的features,首先看代码:
class CamEncode(nn.Module):def __init__(self, D, C, downsample):super(CamEncode, self).__init__()self.D = Dself.C = Cself.trunk = EfficientNet.from_pretrained("efficientnet-b0")self.up1 = Up(320+112, 512)# 输出通道数为D+C,D为可选深度值个数,C为特征通道数self.depthnet = nn.Conv2d(512, self.D + self.C, kernel_size=1, padding=0)def get_depth_dist(self, x, eps=1e-20):return x.softmax(dim=1)def get_depth_feat(self, x):# 主干网络提取特征x = self.get_eff_depth(x)# 输出通道数为D+Cx = self.depthnet(x)# softmax编码,相理解为每个可选深度的权重depth = self.get_depth_dist(x[:, :self.D])# 深度值 * 特征 = 2D特征转变为3D空间(俯视图)内的特征new_x = depth.unsqueeze(1) * x[:, self.D:(self.D + self.C)].unsqueeze(2)return depth, new_xdef forward(self, x):depth, x = self.get_depth_feat(x)return x
起初与以往的相同,到了init函数的最后一句,把feature的channel下采样到了 D +C,D与上面的视锥的D一致,用来储存深度特征,C为图像的语义特征,然后对channel为D的那部分在执行softmax 用来预测depth的概率分布,然后把D这部分与C这部分单独拿出来让二者做外积,就得到了shape为BNDCHW的feature。
demo代码如下:
a = torch.ones(36*4).resize(4,6,6)+1
demo1 = a.unsqueeze(1)
print(demo1.shape)
b = torch.ones(36*4).resize(4,6,6)+3
demo2 = b.unsqueeze(0)
print(demo2.shape)
c = demo1*demo2
print(c.shape)
torch.Size([4, 1, 6, 6])
torch.Size([1, 4, 6, 6])
torch.Size([4, 4, 6, 6])
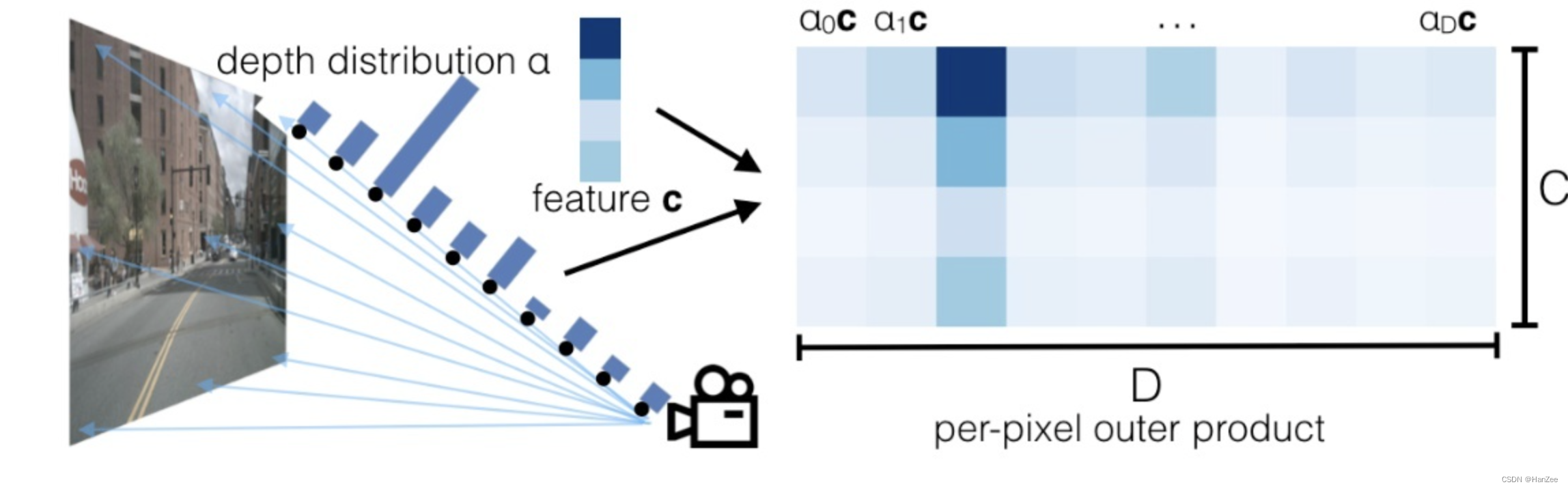
我们观察右面的网格图,首先解释一下网格图的坐标,其中a代表某一个深度softmax概率(大小为H * W),c代表语义特征的某一个channel的feature,那么ac就表示这两个矩阵的对应元素相乘,于是就为feature的每一个点赋予了一个depth 概率,然后广播所有的ac,就得到了不同的channel的语义特征在不同深度(channel)的feature map,经过训练,重要的特征颜色会越来越深(由于softmax概率高),反之就会越来越暗淡,趋近于0.
Splat
得到了带有深度信息的feature map,那么我们想知道这些特征对应3D空间的哪个点,我们怎么做呢?
由于我们的视锥对原图做了16倍的下采样,而在上面得到feature map的感受野也是16,那么我们可以在接下来的操作把feature map映射到视锥坐标下。
转换视锥坐标系
首先我们之前得到了一个2D的视锥,现在通过相机的内外参数把它映射到车身(以车中心为原点)坐标系。
代码如下:
def get_geometry(self, rots, trans, intrins, post_rots, post_trans):B, N, _ = trans.shape # B: batch size N:环视相机个数# undo post-transformation# B x N x D x H x W x 3# 抵消数据增强及预处理对像素的变化points = self.frustum - post_trans.view(B, N, 1, 1, 1, 3)points = torch.inverse(post_rots).view(B, N, 1, 1, 1, 3, 3).matmul(points.unsqueeze(-1))# 图像坐标系 -> 归一化相机坐标系 -> 相机坐标系 -> 车身坐标系# 但是自认为由于转换过程是线性的,所以反归一化是在图像坐标系完成的,然后再利用# 求完逆的内参投影回相机坐标系points = torch.cat((points[:, :, :, :, :, :2] * points[:, :, :, :, :, 2:3],points[:, :, :, :, :, 2:3]), 5) # 反归一化combine = rots.matmul(torch.inverse(intrins))points = combine.view(B, N, 1, 1, 1, 3, 3).matmul(points).squeeze(-1)points += trans.view(B, N, 1, 1, 1, 3)# (bs, N, depth, H, W, 3):其物理含义# 每个batch中的每个环视相机图像特征点,其在不同深度下位置对应# 在ego坐标系下的坐标return points
Voxel Pooling
代码:
def voxel_pooling(self, geom_feats, x):# geom_feats;(B x N x D x H x W x 3):在ego坐标系下的坐标点;# x;(B x N x D x fH x fW x C):图像点云特征B, N, D, H, W, C = x.shapeNprime = B*N*D*H*W # 将特征点云展平,一共有 B*N*D*H*W 个点x = x.reshape(Nprime, C) # flatten indicesgeom_feats = ((geom_feats - (self.bx - self.dx/2.)) / self.dx).long() # ego下的空间坐标转换到体素坐标(计算栅格坐标并取整)geom_feats = geom_feats.view(Nprime, 3) # 将体素坐标同样展平,geom_feats: (B*N*D*H*W, 3)batch_ix = torch.cat([torch.full([Nprime//B, 1], ix,device=x.device, dtype=torch.long) for ix in range(B)]) # 每个点对应于哪个batchgeom_feats = torch.cat((geom_feats, batch_ix), 1) # geom_feats: (B*N*D*H*W, 4)# filter out points that are outside box# 过滤掉在边界线之外的点 x:0~199 y: 0~199 z: 0kept = (geom_feats[:, 0] >= 0) & (geom_feats[:, 0] < self.nx[0])\& (geom_feats[:, 1] >= 0) & (geom_feats[:, 1] < self.nx[1])\& (geom_feats[:, 2] >= 0) & (geom_feats[:, 2] < self.nx[2])x = x[kept]geom_feats = geom_feats[kept]# get tensors from the same voxel next to each otherranks = geom_feats[:, 0] * (self.nx[1] * self.nx[2] * B)\+ geom_feats[:, 1] * (self.nx[2] * B)\+ geom_feats[:, 2] * B\+ geom_feats[:, 3] # 给每一个点一个rank值,rank相等的点在同一个batch,并且在在同一个格子里面sorts = ranks.argsort()x, geom_feats, ranks = x[sorts], geom_feats[sorts], ranks[sorts] # 按照rank排序,这样rank相近的点就在一起了# cumsum trickif not self.use_quickcumsum:x, geom_feats = cumsum_trick(x, geom_feats, ranks)else:x, geom_feats = QuickCumsum.apply(x, geom_feats, ranks)# griddify (B x C x Z x X x Y)final = torch.zeros((B, C, self.nx[2], self.nx[0], self.nx[1]), device=x.device) # final: bs x 64 x 1 x 200 x 200final[geom_feats[:, 3], :, geom_feats[:, 2], geom_feats[:, 0], geom_feats[:, 1]] = x # 将x按照栅格坐标放到final中# collapse Zfinal = torch.cat(final.unbind(dim=2), 1) # 消除掉z维return final # final: bs x 64 x 200 x 200总结
优点:
1.LSS的方法提供了一个很好的融合到BEV视角下的方法。基于此方法,无论是动态目标检测,还是静态的道路结构认知,甚至是红绿灯检测,前车转向灯检测等等信息,都可以使用此方法提取到BEV特征下进行输出,极大地提高了自动驾驶感知框架的集成度。
2.虽然LSS提出的初衷是为了融合多视角相机的特征,为“纯视觉”模型而服务。但是在实际应用中,此套方法完全兼容其他传感器的特征融合。如果你想融合超声波雷达特征也不是不可以试试。
缺点:
1.极度依赖Depth信息的准确性,且必须显示地提供Depth 特征。当然,这是大部分纯视觉方法的硬伤。如果直接使用此方法通过梯度反传促进Depth网络的优化,如果Depth 网络设计的比较复杂,往往由于反传链过长使得Depth的优化方向比较模糊,难以取得较好效果。当然,一个好的解决方法是先预训练好一个较好的Depth权重,使得LSS过程中具有较为理想的Depth输出。
2.外积操作过于耗时。虽然对于机器学习来说,这样的计算量不足为道,但是对于要部署到车上的模型,当图片的feature size 较大, 且想要预测的Depth距离和精细度高时,外积这一操作带来的计算量则会大大增加。这十分不利于模型的轻量化部署,而这一点上,Transformer的方法反而还稍好一些。
相关文章:
自动驾驶:BEV开山之作LSS(lift,splat,shoot)原理代码串讲
自动驾驶:BEV开山之作LSS(lift,splat,shoot)原理代码串讲前言Lift参数创建视锥CamEncodeSplat转换视锥坐标系Voxel Pooling总结前言 目前在自动驾驶领域,比较火的一类研究方向是基于采集到的环视图像信息,去构建BEV视角…...

C# 如何实现对“属性”的扩展
目录一、为什么要扩展属性二、如何做?一、为什么要扩展属性 属性是一个类的特征,随着开发的不断升级,这种特征可能在一直变化,有时候为了向下兼容,一般属性的数量都是直接递增的。 例如:一个Person类&…...

EBS 物料属性 先后台对应关系 MTL_SYSTEM_ITEMS_B
Introductionweb The basic table mtl_system_items_b is the basic table of item in ERP system and there are a lot of columns,but I don’t know used of each column,particularly the column like %_flag. The reason of general exception may be because the ‘%_fl…...
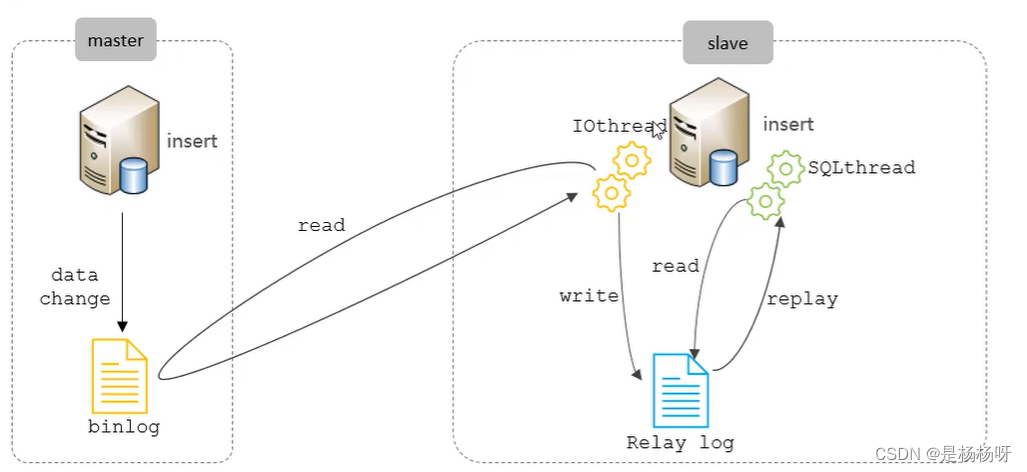
MYSQL数据库-主从复制(原理及搭建)
文章目录1 概述2 原理3 搭建3.1 主库配置3.2 从库配置1 概述 主从复制是指将主数据库的DDL和 DML操作通过二进制日志传到从库服务器中,然后在从库上对这些日志重新执行(也叫重做),从而使得从库和主库的数据保持同步。 MySQL支持一台主库同时向多台从库进…...
))
3GPP-NR Band25标准定义频点和信道(3GPP V17.7.0 (2022-12))
Reference test frequencies for NR operating band n25 Table 4.3.1.1.1.25-1: Test frequencies for NRoperating band n25 and SCS 15 kHz CBW [MHz]carrierBandwidth...
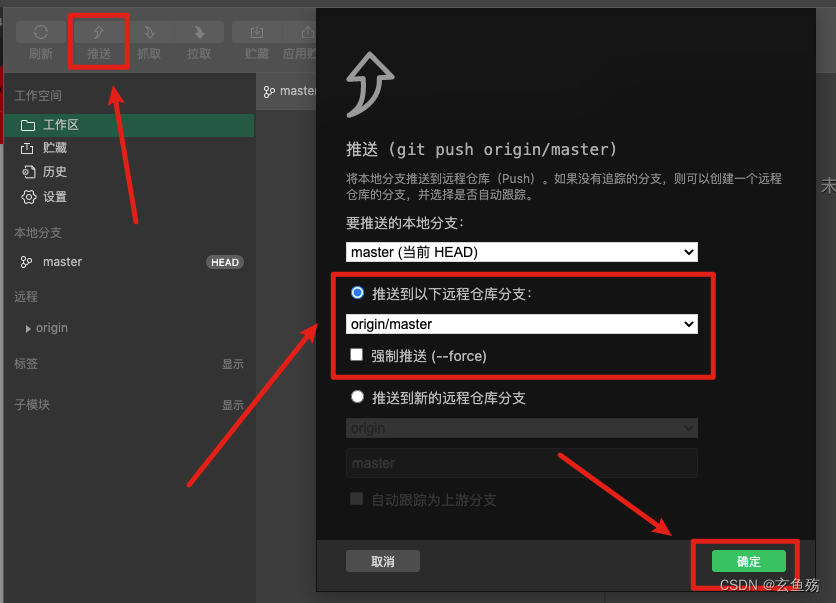
微信小程序 之 原生开发
目录 一、前期预备 1. 预备知识 2. 注册账号 - 申请AppID 3. 下载小程序开发工具 4. 小程序项目结构 5. 小程序的MVVM架构 二、创建小程序项目 1. 查看注册的appId 2. 创建项目 3. 新建页面 01 - 创建text页面文件夹 02 - 新建text的page 03 - 在app.json中配置 …...
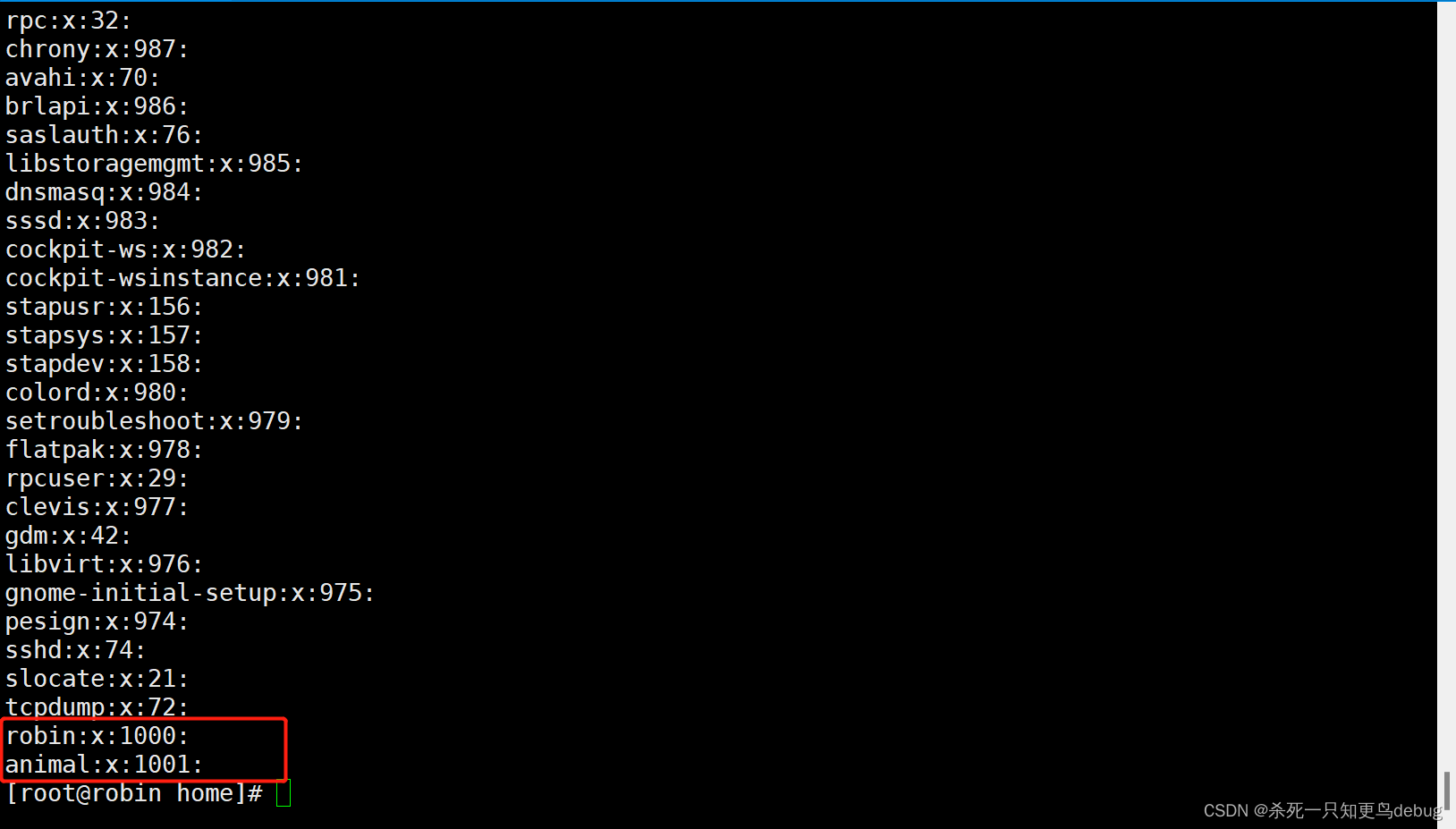
常用vim命令和vim基本使用及Linux用户的管理,用户和组相关文件
常用vim命令和vim基本使用及Linux用户的管理,用户和组相关文件1. vim 的基本介绍和使用1.1 vim的三种模式1.2 常用vim命令【小白】1.3 Vim键盘图:2. Linux用户管理2.1 添加用户2.2 删除用户2.3 修改账号3. Linux系统用户组的管理4. 用户和组相关文件4.1 …...

阿里云服务器部署前后端分离项目
阿里云服务器部署 【若依】 前后端分离项目 文章目录一、域名解析二、服务器操作系统置空三、部署方式四、需安装环境配置五、Linux服务器安装相应内容(具体安装步骤)(一)安装JDK(3种方式)使用Yum安装&…...
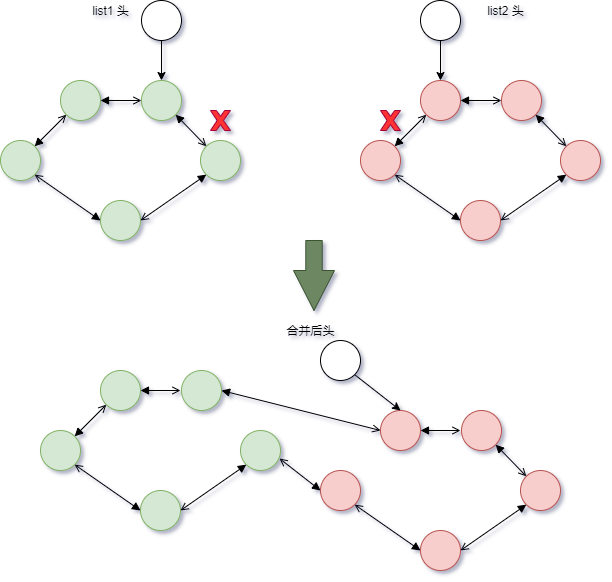
内核经典数据结构list 剖析
前言:linux内核中有很多经典的数据结构,list(也称list_head)为其中之一,这些数据结构都是使用C语言实,并且定义和实现都在单独的头文件list.h中。可以随时拿出来使用。list.h的定义不同linux发行版本路径不同,我们可以在/usr/incl…...
| 真题+思路+考点+代码+岗位)
华为OD机试 - 考优选核酸检测点(Python)| 真题+思路+考点+代码+岗位
优选核酸检测点 题目 张三要去外地出差,需要做核酸,需要在指定时间点前做完核酸, 请帮他找到满足条件的核酸检测点。 给出一组核酸检测点的距离和每个核酸检测点当前的人数给出张三要去做核酸的出发时间 出发时间是 10 分钟的倍数 同时给出张三做核酸的最晚结束时间题目中…...

在魔改PLUS-F5280开发板上使用合封qsp iflash
文章目录引言硬件调整软件调整总结引言 由于目前灵动官网暂未发布正式版的PLUS-F5280开发板,可以使用现有的PLUS-F5270 v1.2开发板(下文简称PLUS-F5270开发版)替换为MM32F5280微控制器芯片,改装为PLUS-F5280开发板。本文记录了使…...
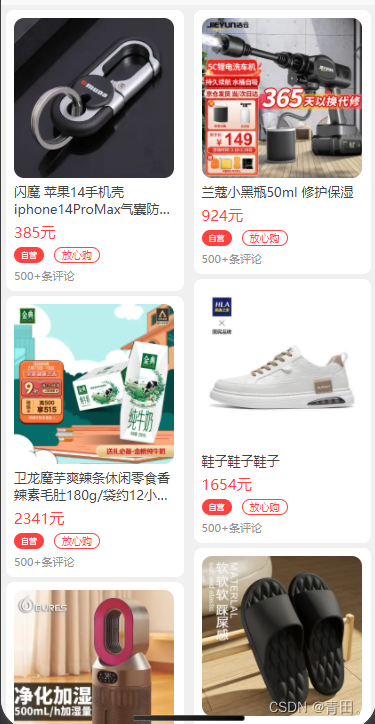
uni-app 瀑布流
效果图 一、组件 components/u-myWaterfall.vue <template><view class"u-waterfall"><view id"u-left-column" class"u-column"><slot name"left" :leftList"leftList"></slot></view&…...
| 真题+思路+考点+代码+岗位)
华为OD机试 - 去除多余空格(Python)| 真题+思路+考点+代码+岗位
去除多余空格 题目 去除文本多余空格,但不去除配对单引号之间的多余空格。给出关键词的起始和结束下标,去除多余空格后刷新关键词的起始和结束下标。 条件约束: [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oQABYuJD-1676475739950)(https://…...

MyBatis 二级缓存简单使用步骤
1、二级缓存使用 在 MyBatis 中默认二级缓存是不开启的,如果要使用需手动开启。在 mybatis-config.xml 配置文件中设置 cacheEnabled true ,配置如下: <?xml version"1.0" encoding"UTF-8" ?> <!DOCTYPE c…...

kubeadmin kube-apiserver Exited 始终起不来查因记录
kubeadmin kube-apiserver Exited 始终起不来查因记录 [rootk8s-master01 log]# crictl ps -a CONTAINER IMAGE CREATED STATE NAME ATTEMPT POD ID POD b7af23a98302e …...

论文投稿指南——中文核心期刊推荐(工程材料学)
【前言】 🚀 想发论文怎么办?手把手教你论文如何投稿!那么,首先要搞懂投稿目标——论文期刊 🎄 在期刊论文的分布中,存在一种普遍现象:即对于某一特定的学科或专业来说,少数期刊所含…...
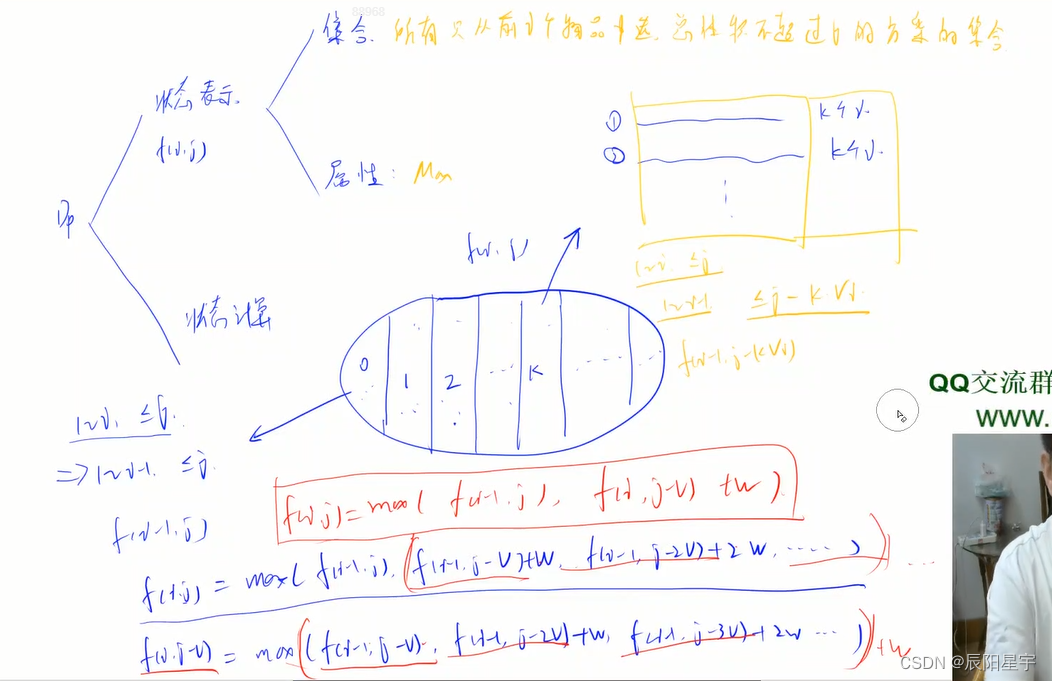
【动态规划】背包问题题型及方法归纳
背包问题的种类 背包问题是在规定背包容量为j的前提下,每个物品对应的体积为v[i],价值为w[i],从物品0到物品i中选择物品放入背包中,找出符合某种要求的价值。 (1)背包问题种类 01背包:每种物…...
全球十大资质正规外汇期货平台排行榜(最新版汇总)
外汇期货简称为FxFut,是“Forex Futures”的缩写,是在集中形式的期货交易所内,交易双方通过公开叫价,以某种非本国货币买进或卖出另一种非本国货币,并签订一个在未来的某一日期根据协议价格交割标准数量外汇的合约。 …...

使用Paramiko时遇到的一些问题
目录 1.背景 2.问题合集 1)“bash: command not found” 2)Paramiko中正常的输入,却到了stderr,而stdout是空 3)命令实际是alias 1.背景 在自动化脚本中,使用了库Paramiko,远程SSH到后台服…...

数据预处理(无量纲化、缺失值、分类特征、连续特征)
文章目录1. 无量纲化1.1 sklearn.preprocessing.MinMaxScaler1.2 sklearn.preprocessing.StandardScaler2. 缺失值3. 分类型特征4. 连续型特征数据挖掘的五大流程包括:获取数据数据预处理特征工程建模上线 其中,数据预处理中常用的方法包括数据标准化和归…...

模型版本爆炸、依赖漂移、推理熵增——SITS 2026提出的“动态契约管理”如何让AI系统稳定性提升4.8倍?
更多请点击: https://intelliparadigm.com 第一章:AI原生模型管理:SITS 2026 MLOps完整解决方案 SITS 2026 是面向AI原生工作负载设计的下一代MLOps平台,深度集成模型生命周期治理、可观测性引擎与边缘协同推理能力。其核心突破在…...

QMCDecode:终极macOS QQ音乐加密格式免费转换解决方案
QMCDecode:终极macOS QQ音乐加密格式免费转换解决方案 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目录,默认转…...

开源串口调试助手SSCom:跨平台硬件调试的终极解决方案
开源串口调试助手SSCom:跨平台硬件调试的终极解决方案 【免费下载链接】sscom Linux/Mac版本 串口调试助手 项目地址: https://gitcode.com/gh_mirrors/ss/sscom 在嵌入式开发、物联网设备调试和工业控制领域,串口通信调试工具是开发者不可或缺的…...

彻底告别Windows激活烦恼:KMS智能激活工具完整使用指南
彻底告别Windows激活烦恼:KMS智能激活工具完整使用指南 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows系统频繁弹出的激活提醒而烦恼吗?是否因为Office突然…...

NoFences:终极免费开源桌面分区工具,如何3分钟打造高效Windows工作空间
NoFences:终极免费开源桌面分区工具,如何3分钟打造高效Windows工作空间 【免费下载链接】NoFences 🚧 Open Source Stardock Fences alternative 项目地址: https://gitcode.com/gh_mirrors/no/NoFences 你是否厌倦了Windows桌面上散乱…...

别急着加内存!从一次OOM到MySQL锁表,我如何用jstack和jvisualvm揪出真凶
从OOM到MySQL锁表:一套完整的问题排查与性能优化实战指南 当线上系统突然崩溃,屏幕上跳出"Memory cgroup out of memory"的红色告警时,大多数开发者的第一反应往往是"赶紧加内存"。但真正的问题往往隐藏在这表面现象之下…...

基于OpenClaw的本地AI品牌内容引擎:Abra架构解析与实战部署
1. 项目概述:Abra,一个本地AI驱动的个人品牌管理引擎如果你和我一样,每天在社交媒体内容创作上花费大量时间,从构思、撰写、配图到排版发布,整个过程繁琐且难以保持品牌调性统一,那么今天分享的这个项目“A…...

被Linux内核用C写的kfifo无锁设计惊艳到了~
正文大家好,我是bug菌~你一定遇到过这样的噩梦:多线程共享一个队列,为了线程安全不得不加锁,结果锁竞争导致性能暴跌,加锁确实是一门学问哈!然后好不容易优化了锁,又遇到了缓存伪共享࿱…...

Cursor IDE 集成多AI模型代理:DeepSeek/Ollama/OpenRouter部署指南
1. 项目概述:为 Cursor Composer 解锁更多 AI 模型作为一名深度使用 Cursor IDE 进行开发的程序员,我深知其内置的 Composer(AI 编程助手)功能强大,但有时也会受限于其默认绑定的模型服务。如果你想在 Cursor 里用上 D…...

新型AirSnitch攻击可绕过家庭、办公室及企业Wi
很难夸大Wi-Fi在生活各个层面所扮演的角色。负责管理这一无线协议的组织表示,自上世纪90年代末Wi-Fi问世以来,已有超过480亿台支持Wi-Fi的设备出货。有估计显示,全球Wi-Fi用户数量约达60亿,占世界总人口的70%左右。尽管人们对Wi-F…...