大数据框架之Hadoop:HDFS(七)HDFS 2.X新特性
7.1集群间数据拷贝
- scp实现两个远程主机之间的文件复制
scp -r hello.txt root@hadoop103:/root/hello.txt // 推 push
scp -r root@hadoop103:/root/hello.txt hello.txt // 拉 pull
scp -r root@hadoop103:/root/hello.txt root@hadoop104:/root //是通过本地主机中转实现两个远程主机的文件复制;如果在两个远程主机之间ssh没有配置的情况下可以使用该方式。
- 采用distcp命令实现两个Hadoop集群之间的递归数据复制
[root@hdp101 hadoop-2.7.7]# bin/hadoop distcp hdfs://haoop102:9000/root/hello.txt hdfs://hadoop103:9000/root/hello.txt
7.2 小文件存档
1、HDFS存储小文件弊端
每个文件均按块存储,每个块的元数据存储在NameNode的内存中,因此HDFS存储小文件会非常低效。因为大量的小文件会耗尽NameNode中的大部分内存。但注意,存储小文件所需要的磁盘容量和数据块的大小无关。例如,一个1MB的文件设置为128MB的块存储,实际使用的是1MB的磁盘空间,而不是128MB。
2、解决存储小文件办法之一
HDFS存档文件或HAR文件,是一个更高效的文件存档工具,它将文件存入HDFS块,在减少NameNode内存使用的同时,允许对文件进行透明的访问。实际上,HDFS存档文件对内还是一个一个独立文件,对NameNode而言却是一个整体,减少NameNode的内存。
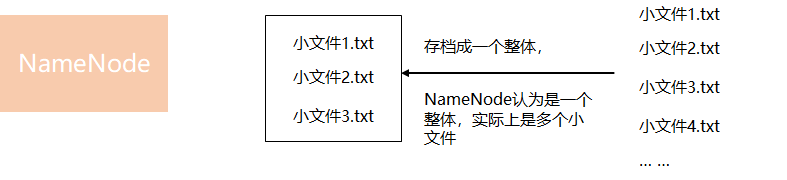
3、基本命令
# 归档文件
hadoop archive -archiveName input.har -p input路径 output路径
# 查看归档
hadoop fs -lsr
# 解归档文件
hadoop fs -cp har:///user/test/input/input.har/* /user/test
4、案例实操
(1)需要启动YARN进程
[root@hdp101 hadoop-2.7.7]# start-yarn.sh
(2)归档文件
把/root/input目录里面的所有文件归档成一个叫input.har的归档文件,并把归档后文件存储到/root/output路径下。
[root@hdp101 hadoop-2.7.7]# bin/hadoop archive -archiveName input.har –p /root/input /root/output
(3)查看归档
[root@hdp101 hadoop-2.7.7]# hadoop fs -lsr /root/output/input.har
[root@hdp101 hadoop-2.7.7]# hadoop fs -lsr har:///root/output/input.har
(4)解归档文件
[root@hdp101 hadoop-2.7.7]# hadoop fs -cp har:/// user/atguigu/output/input.har/* /root
7.3回收站
开启回收站功能,可以将删除的文件在不超时的情况下,恢复原数据,起到防止误删除、备份等作用。
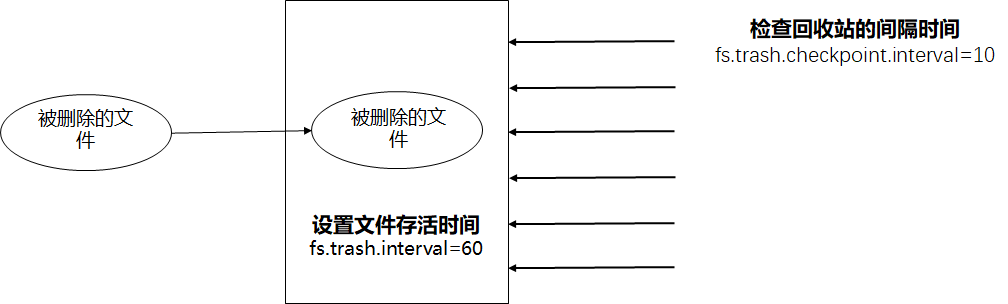
一、回收站参数设置及工作机制
1、默认值fs.trash.interval=0,0表示禁用回收站;其他值表示设置文件的存货时间。
2、默认值fs.trash.checkpoint.interval=0,检查回收站的间隔时间。如果该值为0,则该值设置和fs.trash.interval的参数值相等
3、要求fs.trash.checkpoint.interval ≤fs.trash.interval
二、回收站机制
三、实际操作
1、启用回收站
修改core-site.xml,配置垃圾回收时间为1分钟。
<property><name>fs.trash.interval</name><value>1</value>
</property>
2、查看回收站
回收站在集群中的路径:/root/.Trash/….
3、修改访问垃圾回收站用户名称
进入垃圾回收站用户名称,默认是dr.who,修改为atguigu用户
4、通过程序删除的文件不会经过回收站,需要调用moveToTrash()才进入回收站
Trash trash = New Trash(conf);
trash.moveToTrash(path);
5、恢复回收站数据
[root@hdp101 hadoop-2.7.7]# hadoop fs -mv
/root/.Trash/Current/root/input /root/input
6、清空回收站
[root@hdp101 hadoop-2.7.7]# hadoop fs -expunge
7.4快照管理
快照相当于对目录做一个备份,并不会立即复制所有文件,而是记录文件变化。
| 命令 | 描述 |
|---|---|
| hdfs dfsadmin -allowSnapshot 路径 | 开启指定目录的快照功能 |
| hdfs dfsadmin -disallowSnapshot 路径 | 禁用指定目录的快照功能(默认禁用) |
| hdfs dfs -createSnapshot 路径 | 对目录创建快照 |
| hdfs dfs -createSnapshot 路径 名称 | 指定名称创建快照 |
| hdfs dfs -renameSnapshot 路径 旧名称 新名称 | 重命名快照 |
| hdfs dfs lsSnapshotDir | 列出当前用户所有快照目录 |
| hdfs snapshotDiff 路径1 路径2 | 比较两个快照目录的不同之处 |
| hdfs dfs -deleteSnapshot | 删除快照 |
- 案例实操
(1)开启/禁用指定目录的快照功能
[root@hdp101 hadoop-2.7.7]# hdfs dfsadmin -allowSnapshot /root/input
[root@hdp101 hadoop-2.7.7]# hdfs dfsadmin -disallowSnapshot /root/input
(2)对目录创建快照
[root@hdp101 hadoop-2.7.7]# hdfs dfs -createSnapshot /root/input
通过web访问hdfs://hdp101:50070/root/input/.snapshot/s……// 快照和源文件使用相同数据
[root@hdp101 hadoop-2.7.7]# hdfs dfs -lsr /root/input/.snapshot/
(3)指定名称创建快照
[root@hdp101 hadoop-2.7.7]# hdfs dfs -createSnapshot /root/input miao170508
(4)重命名快照
[root@hdp101 hadoop-2.7.7]# hdfs dfs -renameSnapshot /root/input/ miao170508 atguigu170508
(5)列出当前用户所有可快照目录
[root@hdp101 hadoop-2.7.7]# hdfs lsSnapshottableDir
(6)比较两个快照目录的不同之处
[root@hdp101 hadoop-2.7.7]# hdfs snapshotDiff/root/input/ . .snapshot/atguigu170508
(7)恢复快照
[root@hdp101 hadoop-2.7.7]# hdfs dfs -cp /root/input/.snapshot/s20170708-134303.027 /user
相关文章:
大数据框架之Hadoop:HDFS(七)HDFS 2.X新特性
7.1集群间数据拷贝 scp实现两个远程主机之间的文件复制 scp -r hello.txt roothadoop103:/root/hello.txt // 推 push scp -r roothadoop103:/root/hello.txt hello.txt // 拉 pull scp -r roothadoop103:/root/hello.txt roothadoop104:/root //是通过本地主机中…...
Fluent工作目录
1 工作目录定义工作目录(working directory)是一种文件存储路径设置方式。基于工作目录的方法,写文件时只需要指定文件名,而不需要指定完全的文件路径,从而简化程序编写,对不同操作系统环境有更好的适应性。…...

Learning C++ No.10【STL No.2】
引言: 北京时间:2023/2/14/23:18,放假两个月,没有锻炼,今天去跑了几圈,一个字,累,感觉人都要原地升天了,所以各位小伙伴,准确的说是各位卷王,一定…...
【java 高并发编程之JUC】2w字带你JUC从入门到精通
点击查看脑图目录地址,实时更新 1 什么是 JUC 1.1 JUC 简介 在 Java 中,线程部分是一个重点,本篇文章说的 JUC 也是关于线程的。JUC 就是 java.util .concurrent 工具包的简称。这是一个处理线程的工具包,JDK 1.5 开始出现的。 1.2 进程与…...
QCon演讲实录(下):多云管理关键能力实现与解析-AppManager
在上篇中,我们已经基本了解了多云管理。现在,我们将深入探讨多云管理关键能力实现:AppManager。 什么是AppManager? 上面我们讲了理论、我们自己使用的交付流程和整体架构,下面我们进入关键能力实现与解析的环节&…...

刚刚退出了一个群,关于在要麒麟OS上运行Labview
年龄过了45,看问题,与以前不太一样了。 觉得浪费时间的事,宁可发呆,也不会参和。 竟然一个群里在讨论如何满足客户的需求:麒麟OS上运行Labview。 然后直接退了群。 这种问题,我觉得可能 发在csdn上&…...

el-uploader 文件上传后,又被修改,无法提交到后端 ERR_UPLOAD_FILE_CHANGED
problem 文件上传后,又被修改,无法提交到后端 具体步骤: 文件上传本地文件打开并修改保存提交ajax 这个问题不仅仅局限于el-uploader,是一个普遍性的问题 导致的问题 问题1:提交请求时,控制台报错 net…...

利用Eigen实现点云体素滤波
目录 前言 一、算法原理 二、代码实现 1.头文件 2.源文件 三、效果展示 前言 体素滤波原理简单,是常用的...

linux高级命令之多进程的使用
多进程的使用学习目标能够使用多进程完成多任务1 导入进程包#导入进程包import multiprocessing2. Process进程类的说明Process([group [, target [, name [, args [, kwargs]]]]])group:指定进程组,目前只能使用Nonetarget:执行的目标任务名…...

CSS 圆角边框 盒子阴影 文字阴影
目录 1.圆角边框(重点) 2.盒子阴影(box-shadow) 3.文字阴影(text-shadow) 1.圆角边框(重点) border-radius 属性用于设置元素的外边框圆角。 语法: border-radius: l…...

python简单解析打印onnx模型信息
当我们加载了一个ONNX之后,我们获得的就是一个ModelProto,它包含了一些版本信息,生产者信息和一个GraphProto。在GraphProto里面又包含了四个repeated数组,它们分别是node(NodeProto类型),input(ValueInfoProto类型)&a…...
UE4 编写着色器以及各种宏的理解
参考链接:如何为 UE4 添加全局着色器(Global Shaders) - Unreal Enginehttps://docs.unrealengine.com/5.1/zh-CN/adding-global-shaders-to-unreal-engine/如何为 UE4 添加全局着色器(Global Shaders) - Unreal Engin…...

小笔记:Python 使用字符串调用函数
小笔记:Python中如何使用字符串调用函数/方法?jcLee95:https://blog.csdn.net/qq_28550263?spm1001.2101.3001.5343 本文地址:https://blog.csdn.net/qq_28550263/article/details/111874476 邮箱 :291148484163.co…...

红黑树的原理+实现
文章目录红黑树定义性质红黑树的插入动态效果演示代码测试红黑树红黑树 定义 红黑树是一个近似平衡的搜索树,关于近似平衡主要体现在最长路径小于最短路径的两倍(我认为这是红黑树核心原则),为了达到这个原则,红黑树所…...
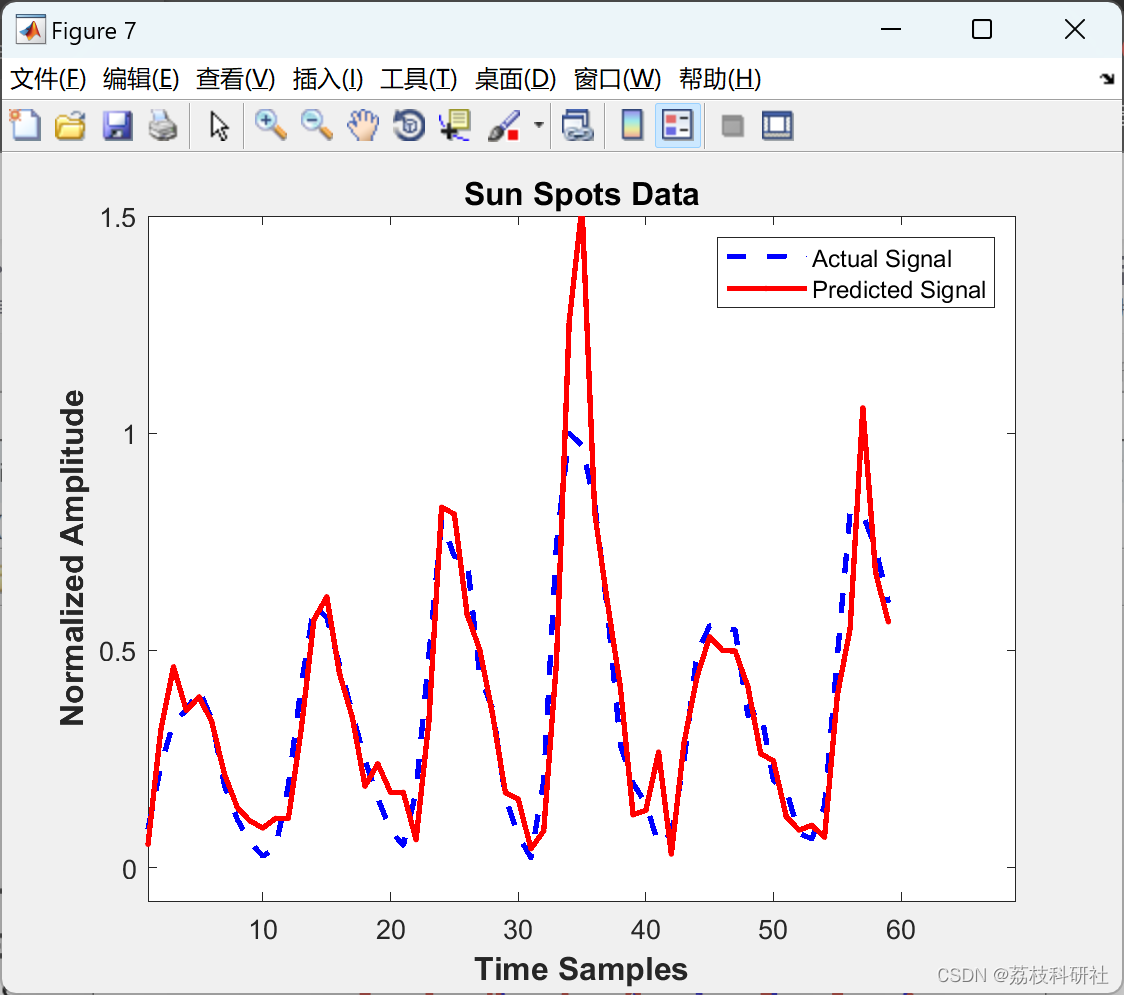
用于非线性时间序列预测的稀疏局部线性和邻域嵌入(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

使用 Vue3 重构 Vue2 项目
目录前言:一、项目整体效果展示二、项目下载使用方法三、为什么要重构项目四、重构的流程五、步骤中的 bug 以及解决方式六、未解决的问题总结:前言: 2020年9月18日,vue3正式版发布了,前几天学习完成后,我决…...
Hive学习——单机版Hive的安装
目录 一、基本概念 (一)什么是Hive (二)优势和特点 (三)Hive元数据管理 二、Hive环境搭建 1.自动安装脚本 2./opt/soft/hive312/conf目录下创建hive配置文件hive-site.xml 3.拷贝一个jar包到hive下面的lib目录下 4.删除hive的guava,拷贝hadoop下的guava 5…...
uprobe 实战
观测数据源 目前按照我的理解,和trace相关的常用数据源–探针 大致分为四类。 内核 Trace point kprobe 用户程序 USDT uprobe 在用户程序中,USDT是所谓的静态Tracepoint。和内核代码中的Trace point类似。实现方式是在代码开发时,使用USDT…...
| 真题+思路+考点+代码+岗位)
华为OD机试 - 求最大数字(Python)| 真题+思路+考点+代码+岗位
求最大数字 题目 给定一个由纯数字组成以字符串表示的数值,现要求字符串中的每个数字最多只能出现2次,超过的需要进行删除;删除某个重复的数字后,其它数字相对位置保持不变。 如34533,数字3重复超过2次,需要删除其中一个3,删除第一个3后获得最大数值4533 请返回经过删…...

雨水情测报与大坝安全监测系统
压电式雨量传感器产品概述传感器由上盖、外壳和下盖组成,壳体内部有压电片和电路板,可以固定在外径50mm立柱上和气象站横杆上。传感器采用冲击测量原理对单个雨滴重量进行测算,进而计算降雨量。雨滴在降落过程中受到雨滴重量和空气阻力的作用…...

告别网盘限速烦恼!九大平台直链下载助手让你的文件下载飞起来
告别网盘限速烦恼!九大平台直链下载助手让你的文件下载飞起来 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘…...

上午题_程序设计语言
编译程序和解释程序...

策略梯度定理实战解析:从蒙特卡洛回报到PyTorch梯度实现
1. 这不是数学课,是写给实战者的政策梯度定理手记你打开这篇文字的时候,大概率正卡在某个强化学习项目里:模型跑不通、梯度爆炸、训练曲线像心电图一样乱跳,或者更糟——明明代码和论文一模一样,但 reward 就是上不去。…...

Selenium自动化ChatGPT:绕过API限制,实现Web端高效批量交互
1. 项目概述与核心价值最近在GitHub上看到一个挺有意思的项目,叫“Michelangelo27/chatgpt_selenium_automation”。光看名字,你大概能猜到它想做什么:用Selenium自动化操作ChatGPT。这听起来是不是有点“用大炮打蚊子”的感觉?毕…...
在汽车电子中的关键技术解析)
数字信号控制器(DSC)在汽车电子中的关键技术解析
1. 数字信号控制器的技术演进与核心定位在嵌入式控制领域,我们正见证着一场处理器架构的静默革命。十年前当我第一次接触到Motorola 56F8300系列芯片时,就意识到这种融合了MCU和DSP特性的混合架构将彻底改变机电控制系统的设计范式。数字信号控制器&…...

AI碳足迹深度解析:从模型压缩到软硬协同的绿色AI实践
1. 从“算力怪兽”到“绿色引擎”:AI碳足迹问题的深度拆解 最近和几个在芯片厂和云服务商工作的老朋友聊天,话题总绕不开一个词:电费。不是开玩笑,现在训练一个大模型,电费账单能轻松超过一个小型数据中心的日常运维成…...

手把手教你配置Synopsys DesignWare PCIe控制器:从寄存器读写到ATU映射实战
Synopsys DesignWare PCIe控制器深度配置指南:从寄存器操作到DMA通信实战 1. PCIe控制器基础架构解析 Synopsys DesignWare PCIe控制器作为业界广泛采用的IP核,其架构设计充分考虑了灵活性和可扩展性。控制器核心由以下几个关键模块组成: Tra…...
)
斐讯K3从梅林‘变砖’到官复原职:一个手残党的硬核救砖全记录(附TTL/编程器操作避坑点)
斐讯K3救砖实战:从梅林固件崩溃到完美恢复的完整指南 1. 当路由器变成"砖头":一个普通用户的崩溃瞬间 那是一个普通的周末下午,我正兴冲冲地准备给我的斐讯K3刷上梅林固件,幻想着能获得更强大的功能和更稳定的性能。按照…...

2026终极指南:如何一键重置JetBrains IDE试用期,享受无限期免费开发体验
2026终极指南:如何一键重置JetBrains IDE试用期,享受无限期免费开发体验 【免费下载链接】ide-eval-resetter 项目地址: https://gitcode.com/gh_mirrors/id/ide-eval-resetter 你是否曾因JetBrains IDE试用期到期而中断开发工作?每次…...

观察Taotoken Token Plan套餐在长期项目中的成本控制效果
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察Taotoken Token Plan套餐在长期项目中的成本控制效果 对于需要长期、稳定调用大模型API的项目而言,成本的可预测性…...