C++——哈希4|布隆过滤器
目录
布隆过滤器
完整代码
布隆过滤器应用
布隆过滤器的查找
布隆过滤器删除
布隆过滤器优点
布隆过滤器缺陷
布隆过滤器海量数据处理
布隆过滤器
位图只能映射整形,而对于字符串却无能为力。
把字符串用哈希算法转成整形,映射一个位置进行标记
下面就是布隆过滤器设计思路
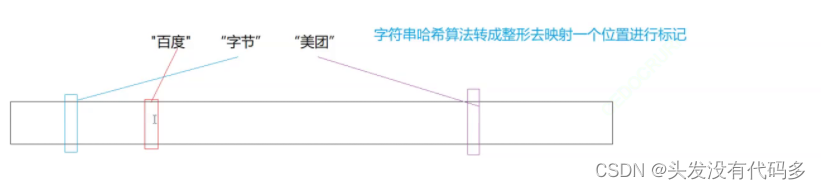
位图是直接定址法,不存在冲突,而字符串可能转成整形后,会有重合的地方,发生下面这种冲突(误判)。

布隆过滤器存在误判,如这里如果美团不存在,而B站存在,此时美团的位置被B站占据,有可能会误判为美团此时存在。
这种误判不可能完全去掉,但我们可以通过优化降低误判率。
优化方法:让每个值多映射几个位,如美团映射好几个位,就能减少上面误判的概率。理论而言,一个值映射的位越多,误判冲突的概率就越低,但如果映射过多,空间消耗就会增大。
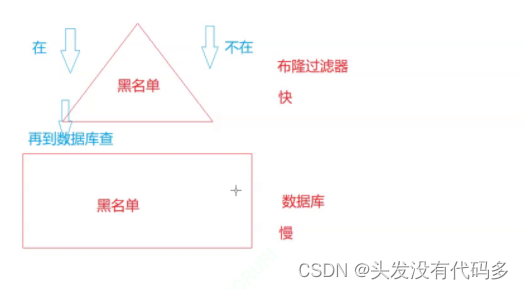
判断某邮箱是否在黑名单中,可用布隆过滤器进行简单的过滤

完整代码
struct HashBKDR
{// BKDRsize_t operator()(const string& key){size_t val = 0;for (auto ch : key){val *= 131;val += ch;}return val;}
};
struct HashAP
{// BKDRsize_t operator()(const string& key){size_t hash = 0;for (size_t i = 0; i < key.size(); i++){if ((i & 1) == 0){hash ^= ((hash << 7) ^ key[i] ^ (hash >> 3));}else{hash ^= (~((hash << 11) ^ key[i] ^ (hash >> 5)));}}return hash;}
};struct HashDJB
{// BKDRsize_t operator()(const string& key){size_t hash = 5381;for (auto ch : key){hash += (hash << 5) + ch;}return hash;}
};//N表示准备要映射N个值
template<size_t N,class K=string,class Hash1=HashBKDR, class Hash2=HashAP, class Hash3=HashDJB>
class BloomFilter
{
public:void Set(const K& key)//一个值对应多个位置{size_t hash1 = Hash1()(key) % (_ratio * N);_bits.set(hash1);size_t hash2 = Hash2()(key) % (_ratio * N);_bits.set(hash2);size_t hash3 = Hash3()(key) % (_ratio * N);_bits.set(hash3);}bool Test(const K& key)//只要有一个位为0,就return false。{size_t hash1 = Hash1()(key) % (_ratio * N);if (!_bits.set(hash1))return false;size_t hash2 = Hash2()(key) % (_ratio * N);if (!_bits.set(hash2))return false;size_t hash3 = Hash3()(key) % (_ratio * N);if (!_bits.set(hash3))return false;return true;//返回真也可能存在误判}
private:const static size_t ratio = 5;//比例bitset<_ratio*N> _bits;
};void TestBloomFilter1()
{BloomFilter<10> bf;string arr1[] = { "苹果", "西瓜", "阿里", "美团", "苹果", "字节", "西瓜", "苹果", "香蕉", "苹果", "腾讯" };for (auto& str : arr1){bf.Set(str);}for (auto& str : arr1){cout << bf.Test(str) << endl;}cout << endl << endl;string arr2[] = { "苹果111", "西瓜", "阿里2222", "美团", "苹果dadcaddxadx", "字节", "西瓜sSSSX", "苹果 ", "香蕉", "苹果$", "腾讯" };for (auto& str : arr2){cout << str << ":" << bf.Test(str) << endl;}
} 上半部分是进行Set,下半部分是TestSet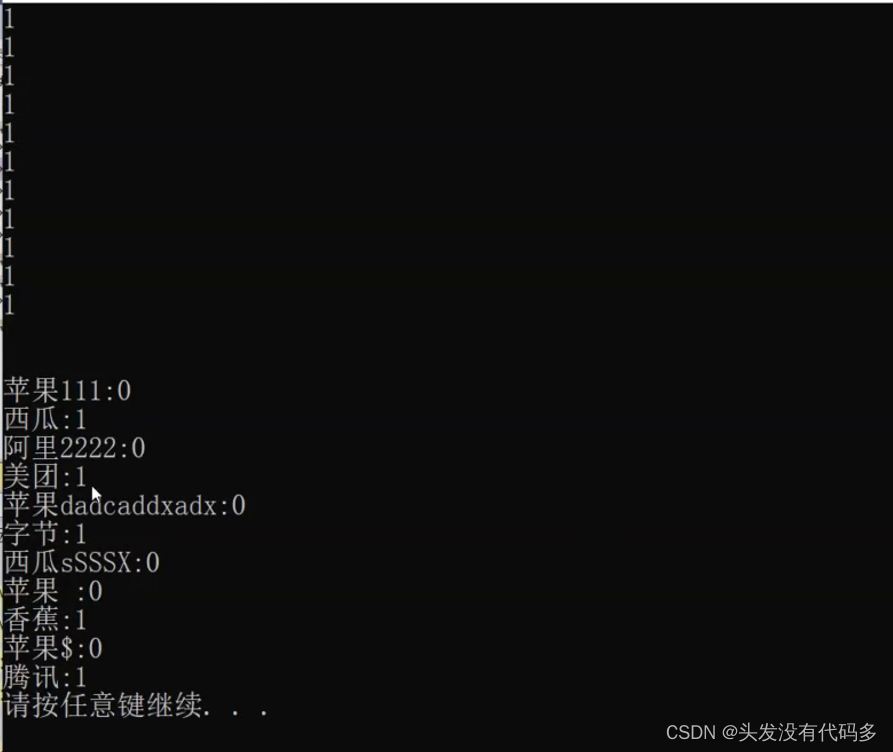
测试用例2
void TestBloomFilter2()
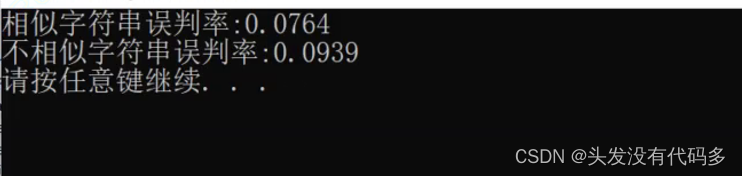
{srand(time(0));const size_t N = 100000;BloomFilter<N> bf;cout << sizeof(bf) << endl;std::vector<std::string> v1;std::string url = "https://www.cnblogs.com/-clq/archive/2012/05/31/2528153.html";for (size_t i = 0; i < N; ++i){v1.push_back(url + std::to_string(1234 + i));}for (auto& str : v1){bf.Set(str);}// 相似std::vector<std::string> v2;for (size_t i = 0; i < N; ++i){std::string url = "http://www.cnblogs.com/-clq/archive/2021/05/31/2528153.html";url += std::to_string(rand() + i);v2.push_back(url);}size_t n2 = 0;for (auto& str : v2){if (bf.Test(str)){++n2;}}cout << "相似字符串误判率:" << (double)n2 / (double)N << endl;std::vector<std::string> v3;for (size_t i = 0; i < N; ++i){string url = "zhihu.com";url += std::to_string(rand()+i);v3.push_back(url);}size_t n3 = 0;for (auto& str : v3){if (bf.Test(str)){++n3;}}cout << "不相似字符串误判率:" << (double)n3 / (double)N << endl;
} 
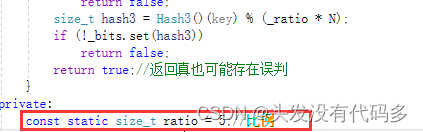
这里的比例越大,开的空间越多,误判率就会降低。 对于库中的布隆过滤器,若开的空间过大,会导致栈溢出,我们可以把空间转移到堆上去,以下是转移到堆上的代码
用我们上面自己写的代码就不会栈溢出,因为开的空间很小
template<size_t N,
class K = string, class Hash1 = HashBKDR, class Hash2 = HashAP, class Hash3 = HashDJB>
class BloomFilter
{
public:void Set(const K& key){size_t hash1 = Hash1()(key) % (_ratio*N);//cout << hash1 << endl;_bits->set(hash1);size_t hash2 = Hash2()(key) % (_ratio*N);//cout << hash2 << endl;_bits->set(hash2);size_t hash3 = Hash3()(key) % (_ratio*N);//cout << hash3 << endl;_bits->set(hash3);}bool Test(const K& key){size_t hash1 = Hash1()(key) % (_ratio*N);//cout << hash1 << endl;if (!_bits->test(hash1))return false; // 准确的size_t hash2 = Hash2()(key) % (_ratio*N);//cout << hash2 << endl;if (!_bits->test(hash2))return false; // 准确的size_t hash3 = Hash3()(key) % (_ratio*N);//cout << hash3 << endl;if (!_bits->test(hash3))return false; // 准确的return true; // 可能存在误判}// 能否支持删除->void Reset(const K& key);private:const static size_t _ratio = 5;std::bitset<_ratio*N>* _bits = new std::bitset<_ratio*N>;
};
布隆过滤器应用
布隆过滤器的查找
布隆过滤器的思想是将一个元素用多个哈希函数映射到一个位图中,因此被映射到的位置的比特
位一定为1。所以可以按照以下方式进行查找:分别计算每个哈希值对应的比特位置存储的是否为
零,只要有一个为零,代表该元素一定不在哈希表中,否则可能在哈希表中。
注意:布隆过滤器如果说某个元素不存在时,该元素一定不存在,如果该元素存在时,该元素可
能存在,因为有些哈希函数存在一定的误判。
比如:在布隆过滤器中查找"alibaba"时,假设3个哈希函数计算的哈希值为:1、3、7,刚好和其
他元素的比特位重叠,此时布隆过滤器告诉该元素存在,但实该元素是不存在的。
布隆过滤器删除
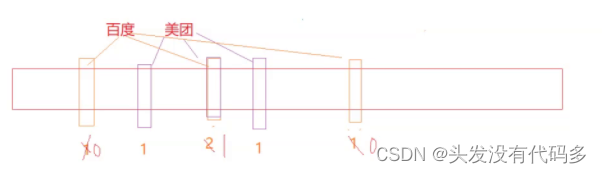
布隆过滤器不能直接支持删除工作,因为在删除一个元素时,可能会影响其他元素。
比如:删除上图中"tencent"元素,如果直接将该元素所对应的二进制比特位置0,“baidu”元素也
被删除了,因为这两个元素在多个哈希函数计算出的比特位上刚好有重叠。
一种支持删除的方法:将布隆过滤器中的每个比特位扩展成一个小的计数器,插入元素时给k个计
数器(k个哈希函数计算出的哈希地址)加一,删除元素时,给k个计数器减一,通过多占用几倍存储
空间的代价来增加删除操作。
缺陷:
1. 无法确认元素是否真正在布隆过滤器中
2. 存在计数回绕
布隆过滤器优点
1. 增加和查询元素的时间复杂度为:O(K), (K为哈希函数的个数,一般比较小),与数据量大小无
关
2. 哈希函数相互之间没有关系,方便硬件并行运算
3. 布隆过滤器不需要存储元素本身,在某些对保密要求比较严格的场合有很大优势
4. 在能够承受一定的误判时,布隆过滤器比其他数据结构有这很大的空间优势
5. 数据量很大时,布隆过滤器可以表示全集,其他数据结构不能
6. 使用同一组散列函数的布隆过滤器可以进行交、并、差运算
布隆过滤器缺陷
1. 有误判率,即存在假阳性(False Position),即不能准确判断元素是否在集合中(补救方法:再
建立一个白名单,存储可能会误判的数据)
2. 不能获取元素本身
3. 一般情况下不能从布隆过滤器中删除元素
4. 如果采用计数方式删除,可能会存在计数回绕问题
布隆过滤器海量数据处理
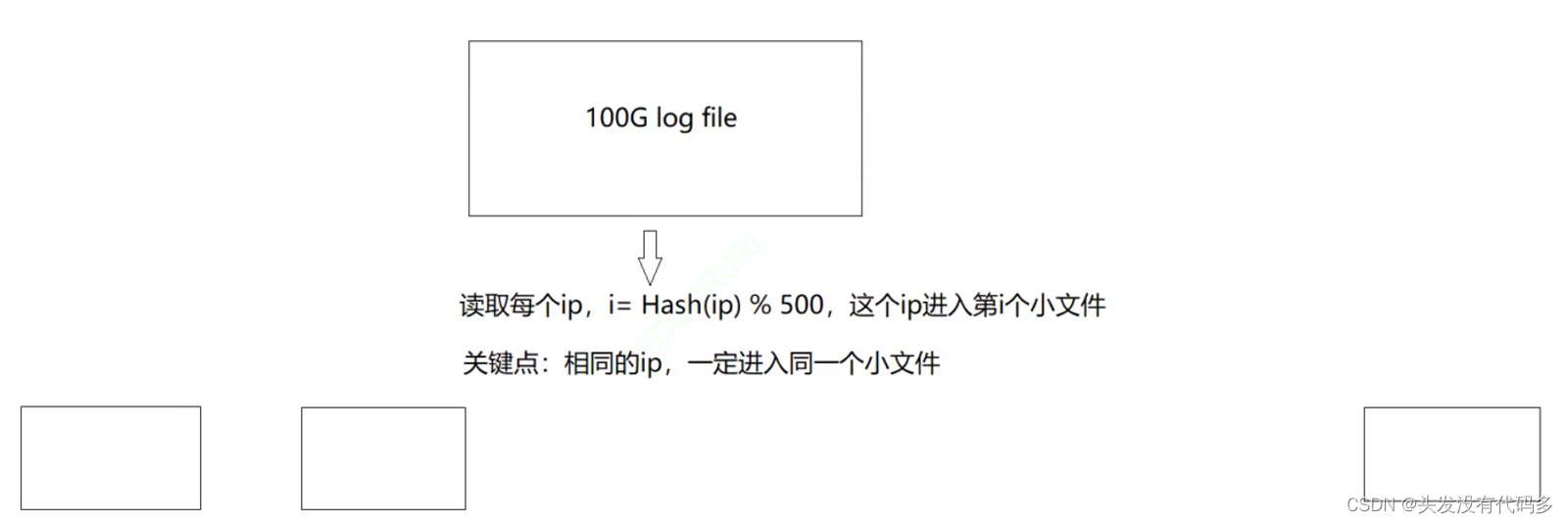
1. 给两个文件,分别有100亿个query(字符串),我们只有1G内存,如何找到两个文件交集?分别给出精确算法和近似算法
精确算法:哈希切分
步骤:1.假设每个查询需要30byte空间,100亿个查询需要3000亿byte约等于300G
2.假设俩个文件叫A和B,依次读取文件A中的query(查询),然后转成整形并取模,这个query就进入编号为Ai的小文件
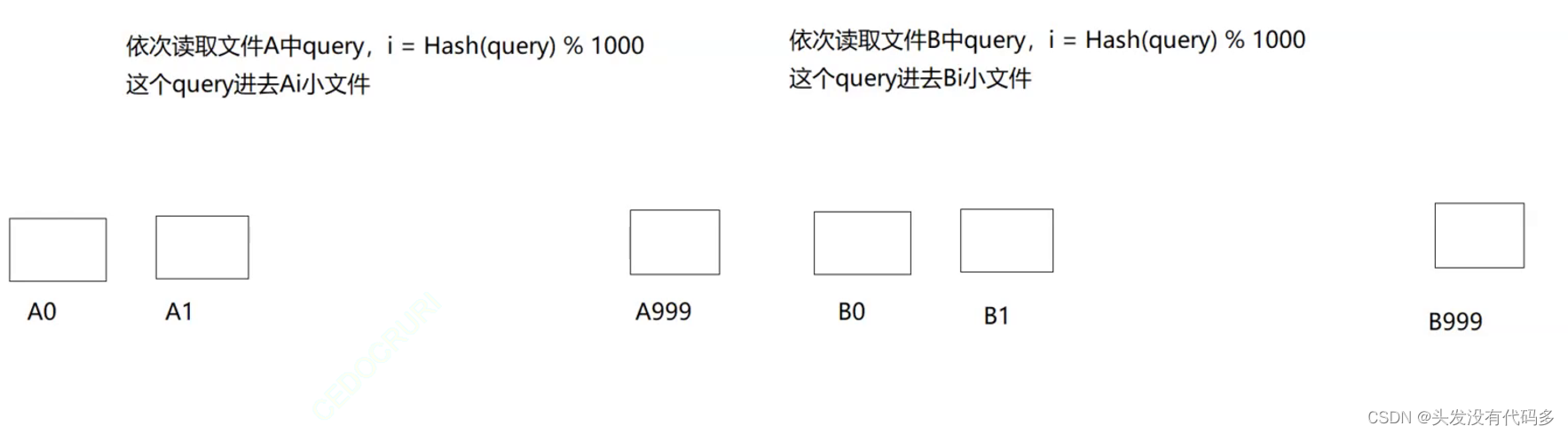
之后开始找交集,对编号相同的找交集
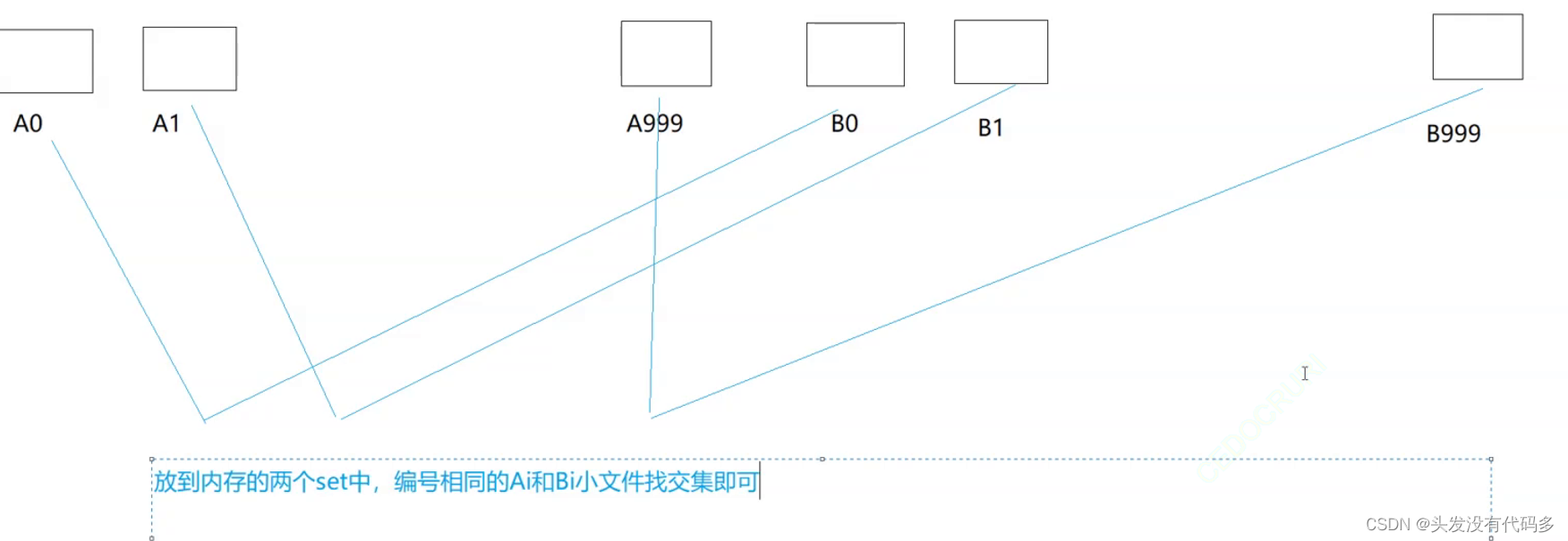
为什么要对应相同编号找交集?
相同的query,一定进入了相同编号的小文件,因为是同哈希函数转出来的然后对这个值取模,一系列操作都一样,只不过是放到了不同的文件中,虽然文件不同但编号相同。

近似算法:把一个文件放到布隆过滤器里面,再通过另一个文件来看数据在不在,在就是交集,不在则不是。
2. 如何扩展BloomFilter使得它支持删除元素的操作
布隆过滤器一般不支持删除,如果有共同映射的地方,则会影响其它值。我们在这里可以使用引用计数,用多个位表示一个位置,做计数就可以支持删除,但是布隆为了支持删除,空间消耗更多,优势就削弱了

删除百度
给一个超过100G大小的log file, log中存着IP地址, 设计算法找到出现次数最多的IP地址?
与上题条件相同,如何找到top K的IP?

相关文章:
C++——哈希4|布隆过滤器
目录 布隆过滤器 完整代码 布隆过滤器应用 布隆过滤器的查找 布隆过滤器删除 布隆过滤器优点 布隆过滤器缺陷 布隆过滤器海量数据处理 布隆过滤器 位图只能映射整形,而对于字符串却无能为力。 把字符串用哈希算法转成整形,映射一个位置进行标…...
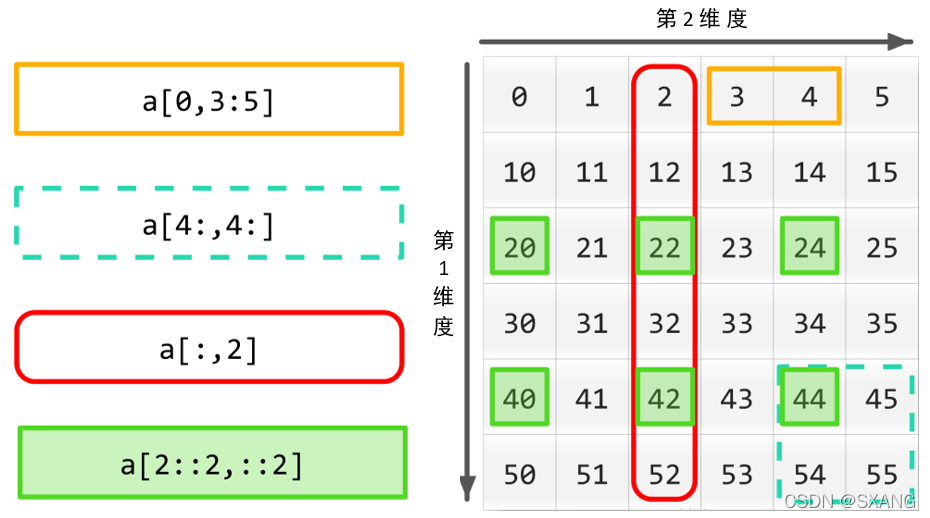
python冒号的用法总结
一维数组 1. 单个冒号的情况 1.1 写完整的情况下 单个冒号的情况下,对数组的遍历操作是从前向后操作。如:arr[a:b] ,冒号前的a含义是从a开始遍历,冒号后的b含义是到b截止(不包括b)。 arr [1, 2, 3, 4,…...

面试题整理
面试题整理 一、Java基础 1、Java 语言有哪些特点 简单易学; 面向对象(封装,继承,多态); 平台无关性( Java 虚拟机实现平台无关性); 支持多线程( C 语言…...
C语言深度解剖-关键字(7)
目录 switch case 语句 理解: 补充: 深入理解: default 语句: case语句: 总结: do、while、for 关键字 while for do while 各种死循环方法: while for do while getchar 写在…...

利用JavaScript编写Python内置函数查询工具
最近我开始学习Python编程语言,我发现Python拥有非常丰富的内置函数,可以用来实现各种不同的功能。但是每当我需要查找一个内置函数时,我总是需要联网使用搜索引擎进行查询。这种方式不仅费时费力,而且需要联网,很不方…...
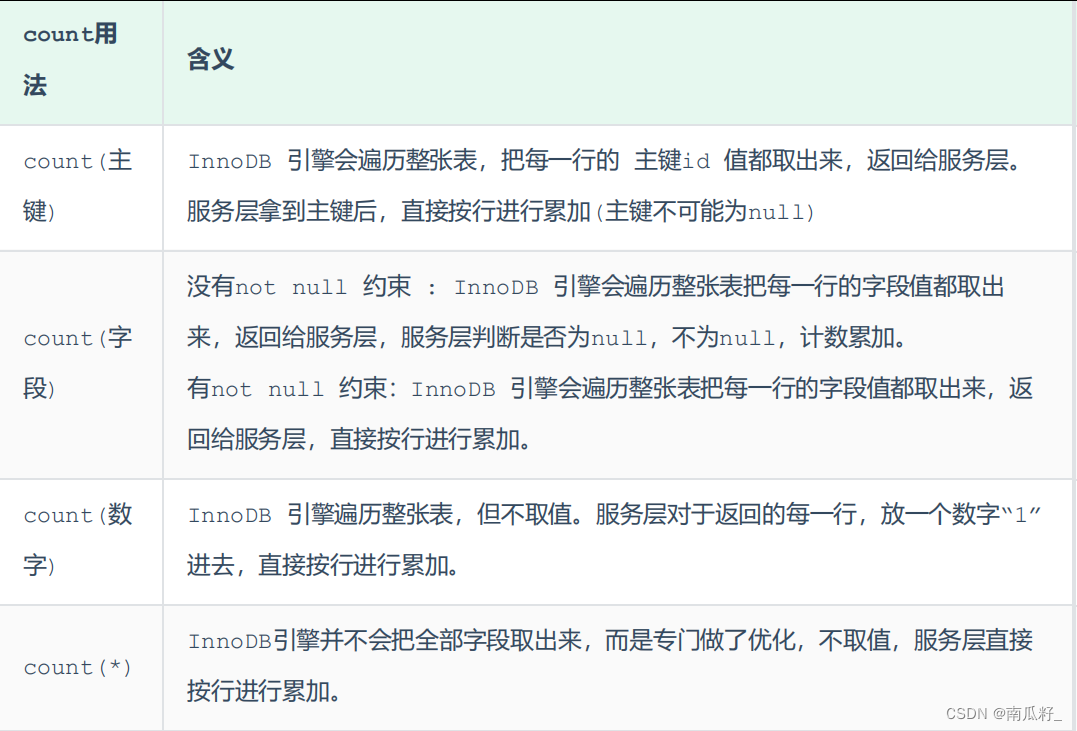
【MySQL进阶】SQL优化
😊😊作者简介😊😊 : 大家好,我是南瓜籽,一个在校大二学生,我将会持续分享Java相关知识。 🎉🎉个人主页🎉🎉 : 南瓜籽的主页…...
最新版海豚调度dolphinscheduler-3.1.3配置windows本地开发环境
0 说明 本文基于最新版海豚调度dolphinscheduler-3.1.3配置windows本地开发环境,并在windows本地进行调试和开发 1 准备 1.1 安装mysql 可以指定为windows本地mysql,也可以指定为其他环境mysql,若指定为其他环境mysql则可跳过此步。 我这…...

csv文件完整操作总结
csv文件完整操作总结 1.概述 csv 模块主要用于处理从电子数据表格Excel或数据库中导入到文本文件的数据,通常简称为 comma-separated value (CSV)格式因为逗号用于分离每条记录的各个字段。 2.读写操作 2.1.测试数据 创建一个test.csv文…...
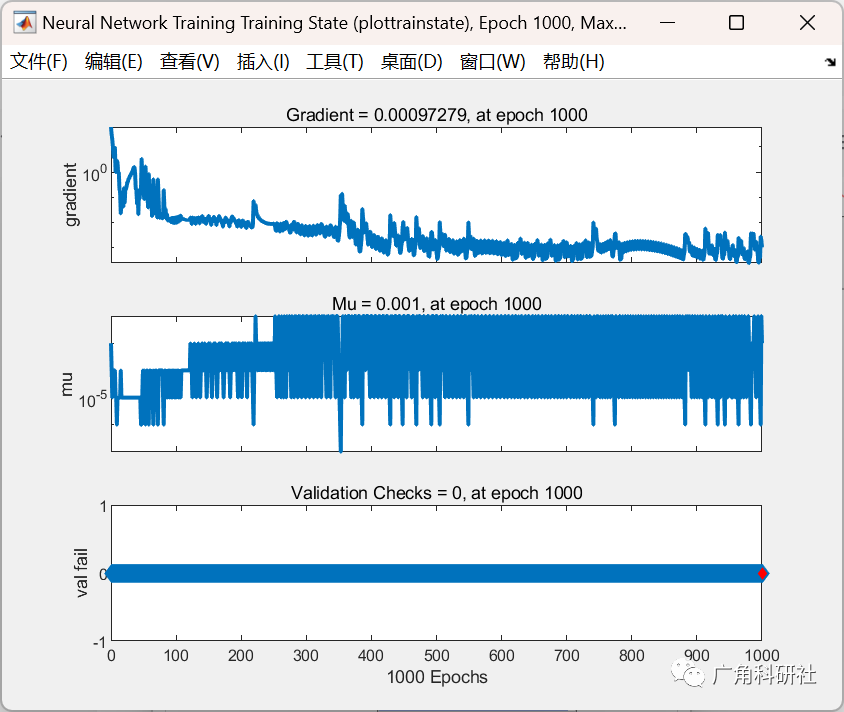
时间序列预测--基于CNN的股价预测(Matlab代码实现)
目录 💥1 概述 📚2 运行结果 🎉3 参考文献 👨💻4 Matlab代码 💥1 概述 时间序列预测有很多方法,如传统的时序建模方法ARIMA、周期因子法、深度学习网络等,本次实验采用最简单的…...
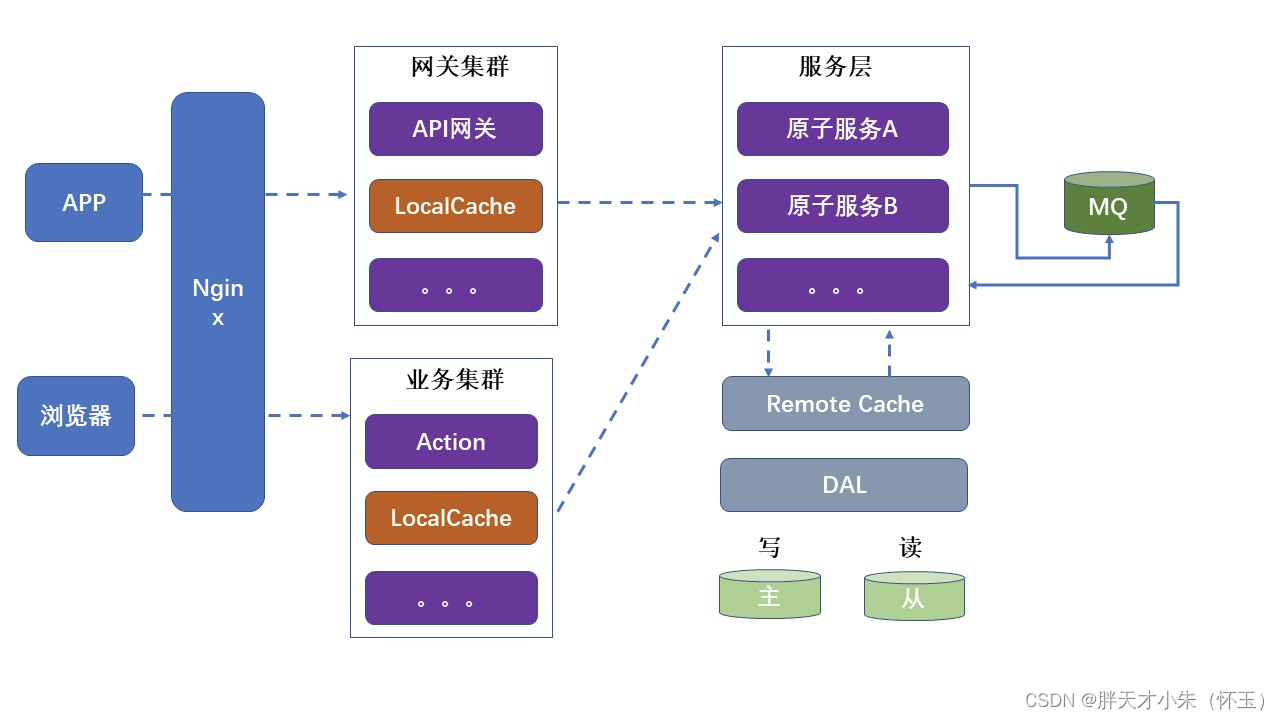
Dubbo与Spring Cloud优缺点分析(文档学习个人理解)
文章目录核心部件1、总体框架1.1 Dubbo 核心部件如下1.2 Spring Cloud 总体架构2、微服务架构核心要素3、通讯协议3.1 Dubbo3.2 Spring Cloud3.3 性能比较4、服务依赖方式4.1 Dubbo4.2 Spring Cloud5、组件运行流程5.1 Dubbo5.2 Dubbo 运行组件5.3 Spring Cloud5.4 Spring Clou…...

单元测试工具——JUnit的使用
⭐️前言⭐️ 本篇文章主要介绍单元测试工具JUnit的使用。 🍉欢迎点赞 👍 收藏 ⭐留言评论 📝私信必回哟😁 🍉博主将持续更新学习记录收获,友友们有任何问题可以在评论区留言 🍉博客中涉及源码…...

Linux_基本权限
Linux入门第二篇已送达! Linux_基本权限shell外壳权限Linux的用户分类角色划分Linux的文件文件类型查看权限目录的权限默认权限粘滞位shell外壳 为了保护操作系统,用户的指令不能由操作系统直接进行执行,需要一个中间者,比如Linu…...

3、JavaScript面试题
1, Js数据类型有哪些?数值、字符串、布尔、undefined、null、数组、对象、函数2, 引用类型和值类型的区别- 值类型存在于栈中, 存取速度快 引用类型存在于堆,存取速度慢- 值类型复制的是值本身 引用类型复制的是指向对象的指针- 值类型结构简单只包含基本数据, 引用…...

YUV图像
YUV的存储方式UV格式有两大类:planar和packed。对于planar的YUV格式,先连续存储所有像素点的Y,紧接着存储所有像素点的U,随后是所有像素点的V。对于packed的YUV格式,每个像素点的Y,U,V是连续交替存储的。YUV的采样主流…...
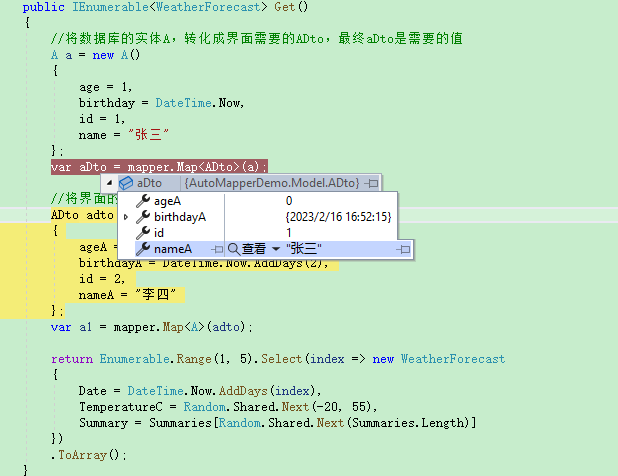
.net6API使用AutoMapper和DTO
AutoMapper,是一个转换工具,说到AutoMapper时,就不得不先说DTO,它叫做数据传输对象(Data Transfer Object)。 通俗的来说,DTO就是前端界面需要用的数据结构和类型,而我们经常使用的数据实体,是数…...
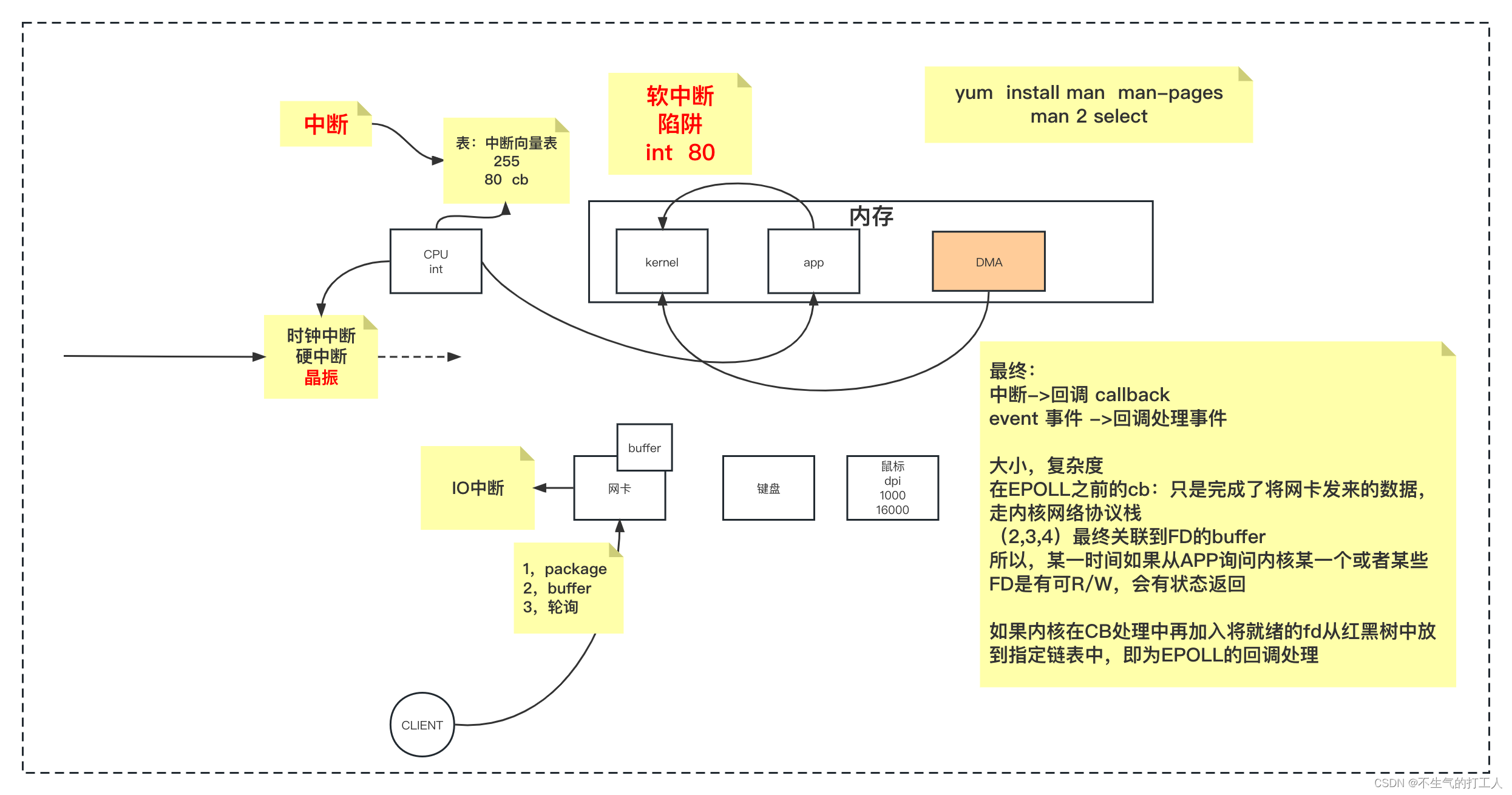
IO知识整理
IO 面向系统IO page cache 程序虚拟内存到物理内存的转换依靠cpu中的mmu映射 物理内存以page(4k)为单位做分配 多个程序访问磁盘上同一个文件,步骤 kernel将文件内容加载到pagecache多个程序读取同一份文件指向的同一个pagecache多个程…...
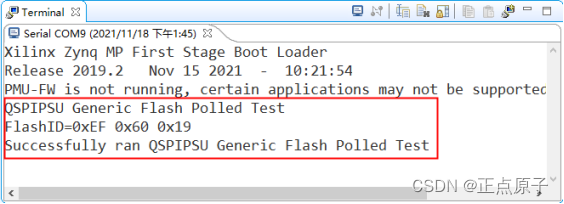
【正点原子FPGA连载】第十三章QSPI Flash读写测试实验 摘自【正点原子】DFZU2EG_4EV MPSoC之嵌入式Vitis开发指南
1)实验平台:正点原子MPSoC开发板 2)平台购买地址:https://detail.tmall.com/item.htm?id692450874670 3)全套实验源码手册视频下载地址: http://www.openedv.com/thread-340252-1-1.html 第十三章QSPI Fl…...
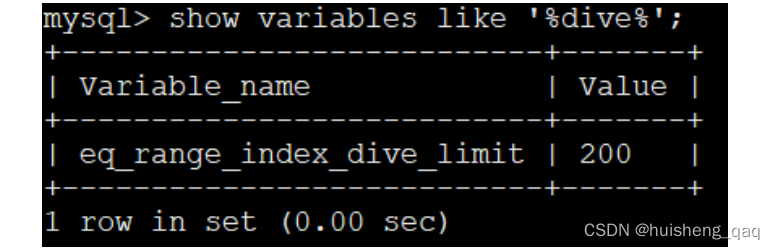
深入理解mysql的内核查询成本计算
MySql系列整体栏目 内容链接地址【一】深入理解mysql索引本质https://blog.csdn.net/zhenghuishengq/article/details/121027025【二】深入理解mysql索引优化以及explain关键字https://blog.csdn.net/zhenghuishengq/article/details/124552080【三】深入理解mysql的索引分类&a…...

LeetCode 141. 环形链表
原题链接 难度:easy\color{Green}{easy}easy 题目描述 给你一个链表的头节点 headheadhead ,判断链表中是否有环。 如果链表中有某个节点,可以通过连续跟踪 nextnextnext 指针再次到达,则链表中存在环。 为了表示给定链表中的…...
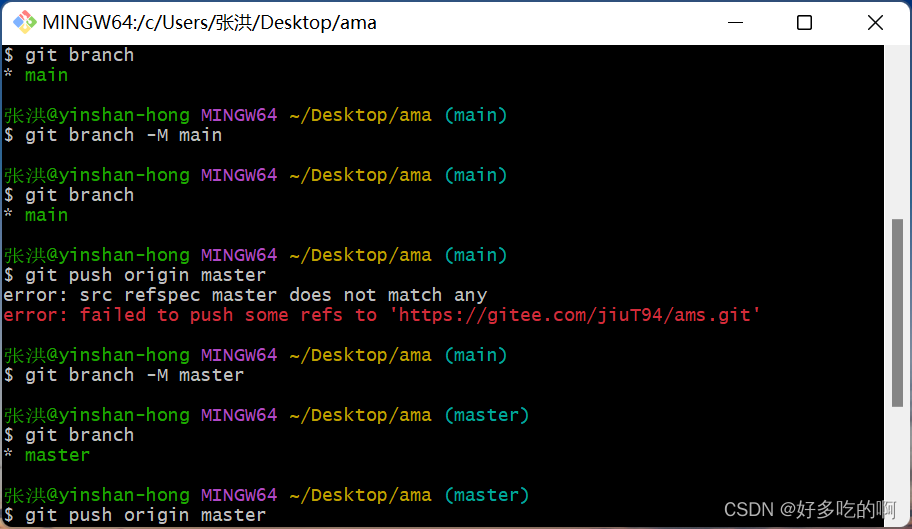
git提交
文章目录关于数据库:桌面/vue-admin/vue_shop_api 的 git 输入 打开 phpStudy ->mySQL管理器 导入文件同时输入密码,和文件名 node app.js 错误区: $ git branch // git branch 查看分支 只有一个main分支不见master解决: gi…...
)
MATLAB图像处理实战:用imfindcircles快速定位硬币边缘(附完整代码)
MATLAB图像处理实战:用imfindcircles快速定位硬币边缘(附完整代码) 在工业检测和医学影像分析中,圆形物体的精准定位往往是关键的第一步。无论是生产线上的硬币质量检查,还是显微镜下的细胞计数,快速准确地…...

【FreeRTOS实战入门】一、从CubeMX到第一个任务:手把手搭建FreeRTOS工程
1. 为什么选择FreeRTOS与CubeMX组合 第一次接触嵌入式实时操作系统时,很多人会纠结选择哪种RTOS。我当年在uC/OS-II和FreeRTOS之间犹豫了很久,最终选择了后者。原因很简单:FreeRTOS不仅完全免费开源,还有STM32CubeMX这个神器加持。…...

s2-pro语音合成教程:支持数字/单位/英文缩写智能朗读技巧
s2-pro语音合成教程:支持数字/单位/英文缩写智能朗读技巧 1. 快速了解s2-pro语音合成 s2-pro是Fish Audio开源的专业级语音合成模型镜像,它能将文本转换为自然流畅的语音。这个工具特别适合需要语音播报、有声读物制作、视频配音等场景的用户。 与普通…...

STM32HAL库项目实战:我把W5500和MQTTClient库‘缝’起来,实现了阿里云OTA升级前传
STM32HAL库与W5500深度整合:从MQTT云连接到OTA升级的工程实践 在嵌入式设备智能化浪潮中,远程固件升级(OTA)已成为工业设备的标配功能。本文将揭示如何基于STM32HAL库和W5500以太网芯片构建可靠的云连接通道,为后续OTA升级打下坚实基础。不同…...

达摩院PALM春联模型多场景落地:政务大厅自助春联机解决方案
达摩院PALM春联模型多场景落地:政务大厅自助春联机解决方案 春节贴春联,是咱们中国人传承千年的文化习俗。一副好春联,不仅承载着对新年的美好祝愿,也体现着家庭的品味和格调。但你知道吗?现在写春联这件事࿰…...

Comsol异构电池力电热耦合模型:探索电池的多场奥秘
comsol异构电池力电热耦合模型 采用椭圆型电极颗粒模拟锂离子正负极的电极颗粒,还原真实电池的3D介观结构,耦合电化学场-热场-力学场,可模拟电流,浓度,温度,应力等多场结果在电池研究领域,深入理…...

泛微OA单点登录配置全攻略:从零开始实现第三方系统免密登录
泛微OA单点登录深度实战:Token机制与系统集成最佳实践 对于企业IT架构师和运维团队而言,系统间的无缝衔接一直是提升工作效率的关键。想象一下这样的场景:销售人员在CRM系统中完成客户跟进后,无需反复登录就能直接跳转到OA系统提…...
)
遥感影像配准总对不齐?OpenCV+RST+PROJ4三重坐标系对齐实战(附WGS84→UTM→影像本地坐标的转换矩阵速查表)
第一章:Shell脚本的基本语法和命令Shell脚本是Linux/Unix系统自动化任务的核心工具,以可执行文本文件形式存在,由Bash等shell解释器逐行解析运行。其语法简洁但严谨,对空格、分号、引号和换行符敏感,需严格遵循语法规则…...

OpenClaw文件处理自动化:nanobot轻量模型实战案例
OpenClaw文件处理自动化:nanobot轻量模型实战案例 1. 为什么选择nanobot处理文件自动化 作为一个长期被各种文件整理工作困扰的技术写作者,我一直在寻找一个既轻量又智能的自动化解决方案。直到遇到OpenClaw框架下的nanobot镜像,这个内置Qw…...

[2026 职场洗牌系列 01] 程序员正在“杀死”自己的工作?科技行业高危预警
长久以来,学计算机(CS)在很多年轻人眼里就等同于拿到了通往高薪和阶层跃升的金钥匙。大家都觉得,只要把代码敲得溜,这辈子在职场上基本就稳了。可惜,到了2026年的今天,生成式AI正在毫不留情地把…...