大数据分析案例-基于决策树算法构建世界杯比赛预测模型

🤵♂️ 个人主页:@艾派森的个人主页
✍🏻作者简介:Python学习者
🐋 希望大家多多支持,我们一起进步!😄
如果文章对你有帮助的话,
欢迎评论 💬点赞👍🏻 收藏 📂加关注+
喜欢大数据分析项目的小伙伴,希望可以多多支持该系列的其他文章
| 大数据分析案例-基于随机森林算法预测人类预期寿命 |
| 大数据分析案例-基于随机森林算法的商品评价情感分析 |
| 大数据分析案例-用RFM模型对客户价值分析(聚类) |
| 大数据分析案例-对电信客户流失分析预警预测 |
| 大数据分析案例-基于随机森林模型对北京房价进行预测 |
| 大数据分析案例-基于RFM模型对电商客户价值分析 |
| 大数据分析案例-基于逻辑回归算法构建垃圾邮件分类器模型 |
| 大数据分析案例-基于决策树算法构建员工离职预测模型 |
| 大数据分析案例-基于KNN算法对茅台股票进行预测 |
| 大数据分析案例-基于多元线性回归算法构建广告投放收益模型 |
| 大数据分案例-基于随机森林算法构建返乡人群预测模型 |
| 大数据分析案例-基于决策树算法构建金融反欺诈分类模型 |
目录
1.项目背景
2.项目简介
2.1项目说明
2.2数据说明
2.3技术工具
3.算法原理
4.项目实施步骤
4.1理解数据
4.2探索性数据分析
4.3数据预处理
4.4特征工程
4.5模型构建
4.6模型预测
5.实验总结
源代码
1.项目背景
世界杯足球比赛是全球最大规模的国际足球赛事之一,吸引着数以亿计的观众。对于球迷和体育爱好者来说,预测比赛结果是一项有趣且具有挑战性的任务。足球比赛结果的预测可以帮助球迷制定投注策略、提供比赛观看的参考以及评估球队和球员的表现。
在过去的几十年中,研究人员一直致力于开发各种预测模型,以预测足球比赛结果。其中,决策树算法是一种常用的机器学习方法,已经在许多领域取得了成功应用。决策树算法通过将决策问题分解为一系列简单的决策规则,可以对复杂的数据集进行建模和预测。
在构建世界杯比赛预测模型方面,决策树算法具有一些优势。首先,决策树算法可以处理多个输入变量(如球队历史战绩、球员伤病情况、球队排名等)和离散或连续的输出变量(比赛结果)。其次,决策树模型易于理解和解释,可以帮助揭示影响比赛结果的关键因素。此外,决策树算法还可以处理缺失数据和异常值,具有较好的鲁棒性。
因此,基于决策树算法构建世界杯比赛预测模型具有一定的理论和实际意义。这一研究可以探索各种与比赛结果相关的因素,如球队实力、球队战术、球员技术等,并通过分析历史数据构建一个可靠的预测模型。这样的预测模型可以为球迷、媒体和体育分析师提供有价值的信息,帮助他们做出更准确的预测和评估。
2.项目简介
2.1项目说明
本项目旨在分析往届世界杯比赛数据,找出规律,最后使用决策树算法构建世界杯比赛预测模型,给出两个球队即可预测胜率,可以给爱看球的小伙伴提供一个参考。
2.2数据说明
本数据来源于天池数据集,共有3个csv文件,具体字段信息如下:
世界杯成绩信息表:WorldCupsSummary
包含了所有21届世界杯赛事(1930-2018)的比赛主办国、前四名队伍、总参赛队伍、总进球数、现场观众人数等汇总信息,包括如下字段:
- Year: 举办年份
- HostCountry: 举办国家
- Winner: 冠军队伍
- Second: 亚军队伍
- Third: 季军队伍
- Fourth: 第四名队伍
- GoalsScored: 总进球数
- QualifiedTeams: 总参赛队伍数
- MatchesPlayed: 总比赛场数
- Attendance: 现场观众总人数
- HostContinent: 举办国所在洲
- WinnerContinent: 冠军国家队所在洲
世界杯比赛比分汇总表:WorldCupMatches.csv
包含了所有21届世界杯赛事(1930-2014)单场比赛的信息,包括比赛时间、比赛主客队、比赛进球数、比赛裁判等信息。包括如下字段:
- Year: 比赛(所属世界杯)举办年份
- Datetime: 比赛具体日期
- Stage: 比赛所属阶段,包括 小组赛(GroupX)、16进8(Quarter-Final)、半决赛(Semi-Final)、决赛(Final)等
- Stadium: 比赛体育场
- City: 比赛举办城市
- Home Team Name: 主队名
- Away Team Name: 客队名
- Home Team Goals: 主队进球数
- Away Team Goals: 客队进球数
- Attendance: 现场观众数
- Half-time Home Goals: 上半场主队进球数
- Half-time Away Goals: 上半场客队进球数
- Referee: 主裁
- Assistant 1: 助理裁判1
- Assistant 2: 助理裁判2
- RoundID: 比赛所处阶段ID,和Stage字段对应
- MatchID: 比赛ID
- Home Team Initials: 主队名字缩写
- Away Team Initials: 客队名字缩写
世界杯球员信息表:WorldCupPlayers.csv
- RoundID: 比赛所处阶段ID,同比赛信息表的RoundID字段
- MatchID: 比赛ID
- Team Initials: 队伍名
- Coach Name: 教练名
- Line-up: 首发/替补
- Shirt Number: 球衣号码
- Player Name: 队员名
- Position: 比赛角色,包括:C=Captain, GK=Goalkeeper
- Event: 比赛事件,包括进球、红/黄牌等
2.3技术工具
Python版本:3.9
代码编辑器:jupyter notebook
3.算法原理
决策树( Decision Tree) 又称为判定树,是数据挖掘技术中的一种重要的分类与回归方法,它是一种以树结构(包括二叉树和多叉树)形式来表达的预测分析模型。其每个非叶节点表示一个特征属性上的测试,每个分支代表这个特征属性在某个值域上的输出,而每个叶节点存放一个类别。一般,一棵决策树包含一个根节点,若干个内部结点和若干个叶结点。叶结点对应于决策结果,其他每个结点对应于一个属性测试。每个结点包含的样本集合根据属性测试的结果划分到子结点中,根结点包含样本全集,从根结点到每个叶结点的路径对应了一个判定的测试序列。决策树学习的目的是产生一棵泛化能力强,即处理未见示例强的决策树。使用决策树进行决策的过程就是从根节点开始,测试待分类项中相应的特征属性,并按照其值选择输出分支,直到到达叶子节点,将叶子节点存放的类别作为决策结果。
决策树的构建
特征选择:选取有较强分类能力的特征。
决策树生成:典型的算法有 ID3 和 C4.5, 它们生成决策树过程相似, ID3 是采用信息增益作为特征选择度量, 而 C4.5 采用信息增益比率。
决策树剪枝:剪枝原因是决策树生成算法生成的树对训练数据的预测很准确, 但是对于未知数据分类很差, 这就产生了过拟合的现象。涉及算法有CART算法。
决策树的划分选择
熵:物理意义是体系混乱程度的度量。
信息熵:表示事物不确定性的度量标准,可以根据数学中的概率计算,出现的概率就大,出现的机会就多,不确定性就小(信息熵小)。
决策树的剪枝
剪枝:顾名思义就是给决策树 "去掉" 一些判断分支,同时在剩下的树结构下仍然能得到不错的结果。之所以进行剪枝,是为了防止或减少 "过拟合现象" 的发生,是决策树具有更好的泛化能力。
具体做法:去掉过于细分的叶节点,使其回退到父节点,甚至更高的节点,然后将父节点或更高的叶节点改为新的叶节点。
剪枝的两种方法:
预剪枝:在决策树构造时就进行剪枝。在决策树构造过程中,对节点进行评估,如果对其划分并不能再验证集中提高准确性,那么该节点就不要继续王下划分。这时就会把当前节点作为叶节点。
后剪枝:在生成决策树之后再剪枝。通常会从决策树的叶节点开始,逐层向上对每个节点进行评估。如果剪掉该节点,带来的验证集中准确性差别不大或有明显提升,则可以对它进行剪枝,用叶子节点来代填该节点。
4.项目实施步骤
4.1理解数据
首先导入本次实验用到的第三方库
接着加载这三个数据文件,并删除缺失值
4.2探索性数据分析
简单的分析一下世界杯的冠军情况
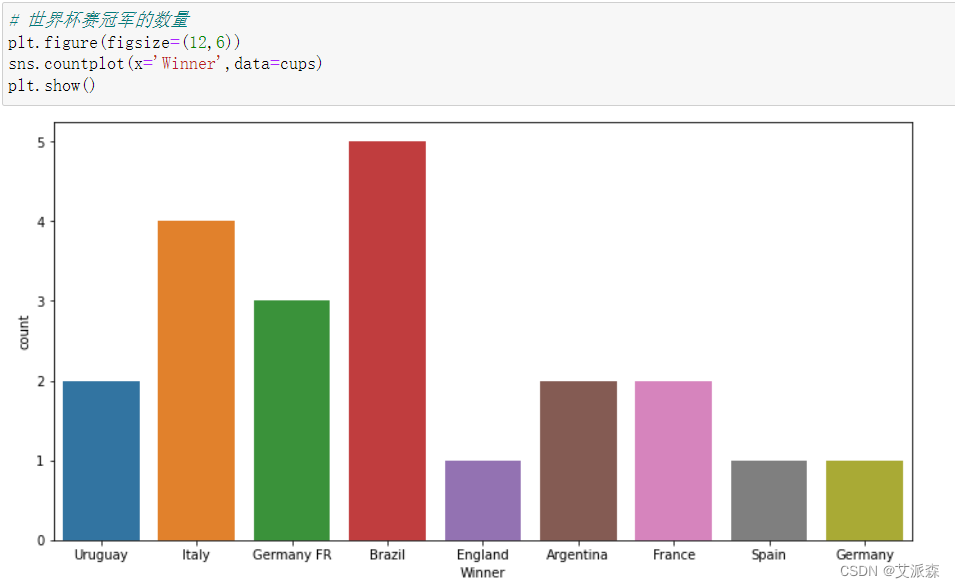
从图我们可看出,巴西/意大利/德国是获得冠军最多的国家。
4.3数据预处理
这里我们用德国取代德国DR和德国FR,用俄罗斯取代苏联
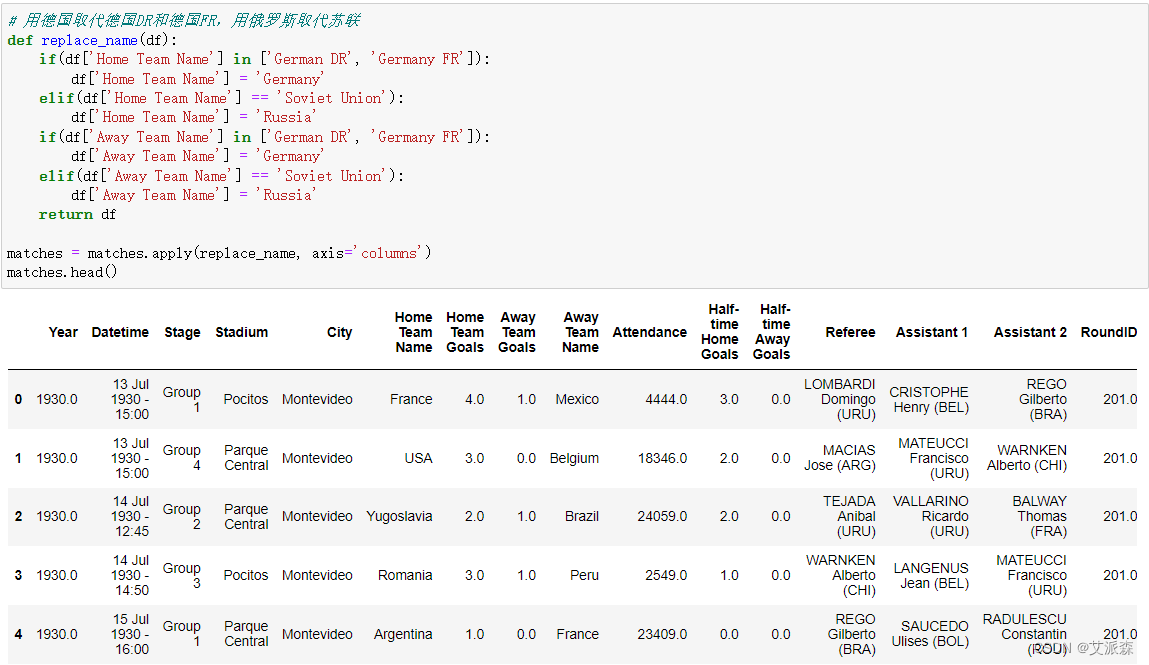
接着准备一个字典用来存储球队名字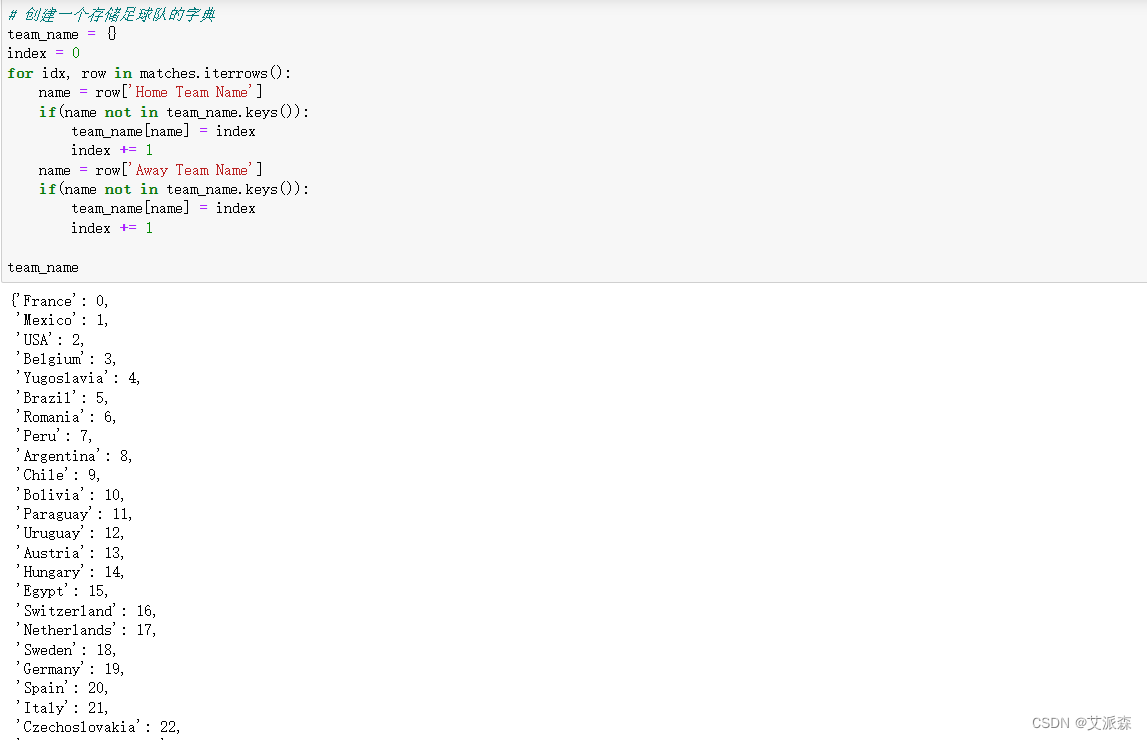
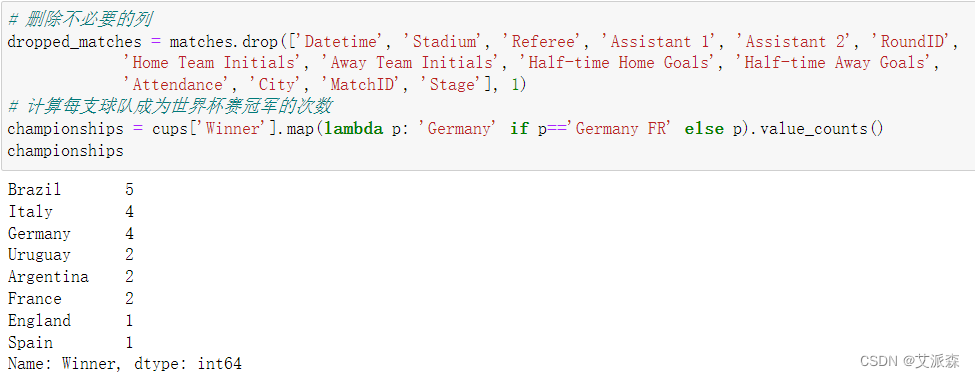
删除不必要的列同时计算每支球队成为世界杯赛冠军的次数
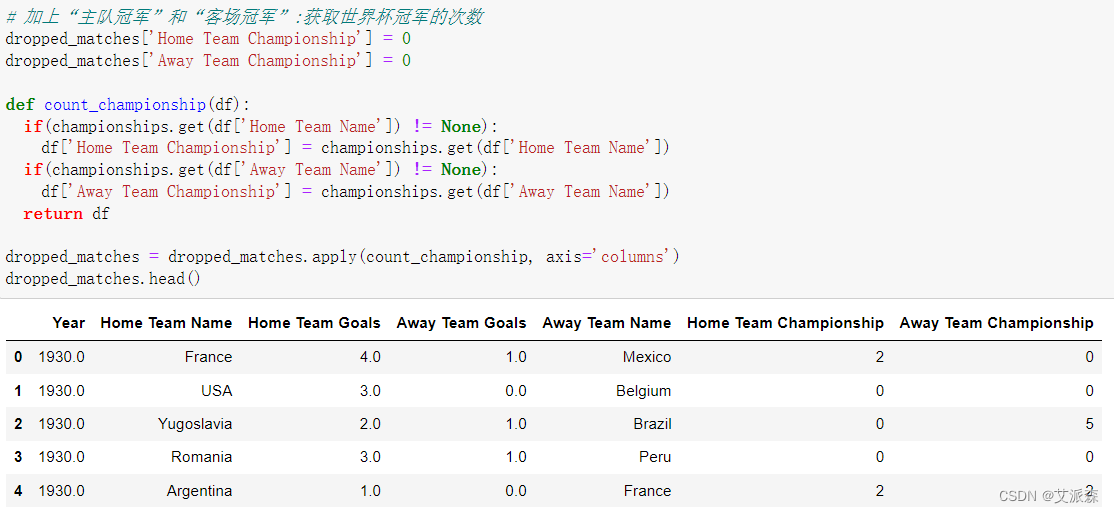
加上“主队冠军”和“客场冠军”:获取世界杯冠军的次数
定义一个函数用于找出谁赢了:主场胜:1,客场胜:2,平局:0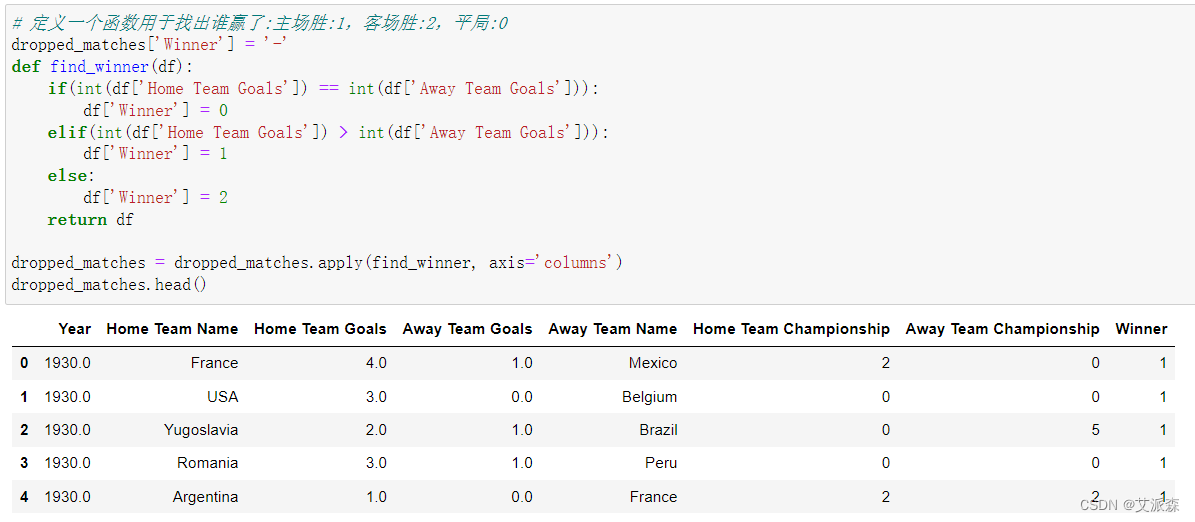
将team_name字典中的团队名称替换为id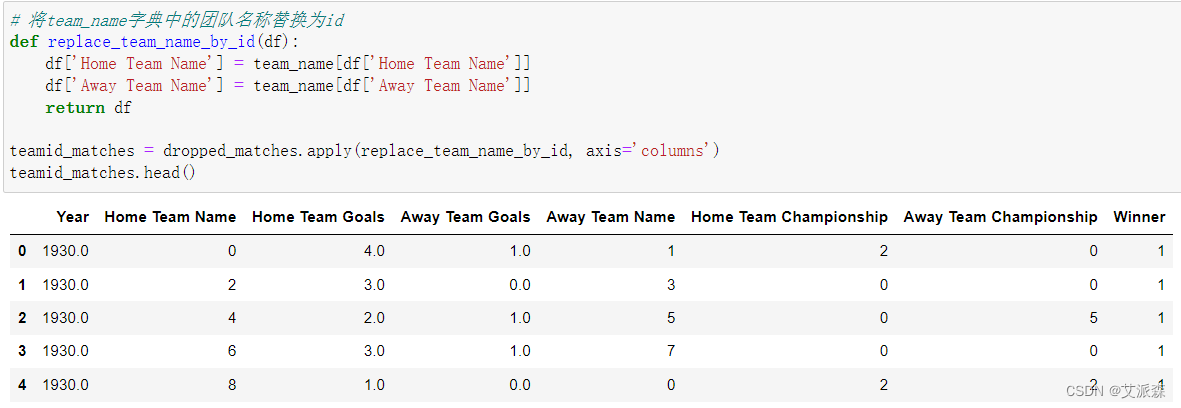
4.4特征工程
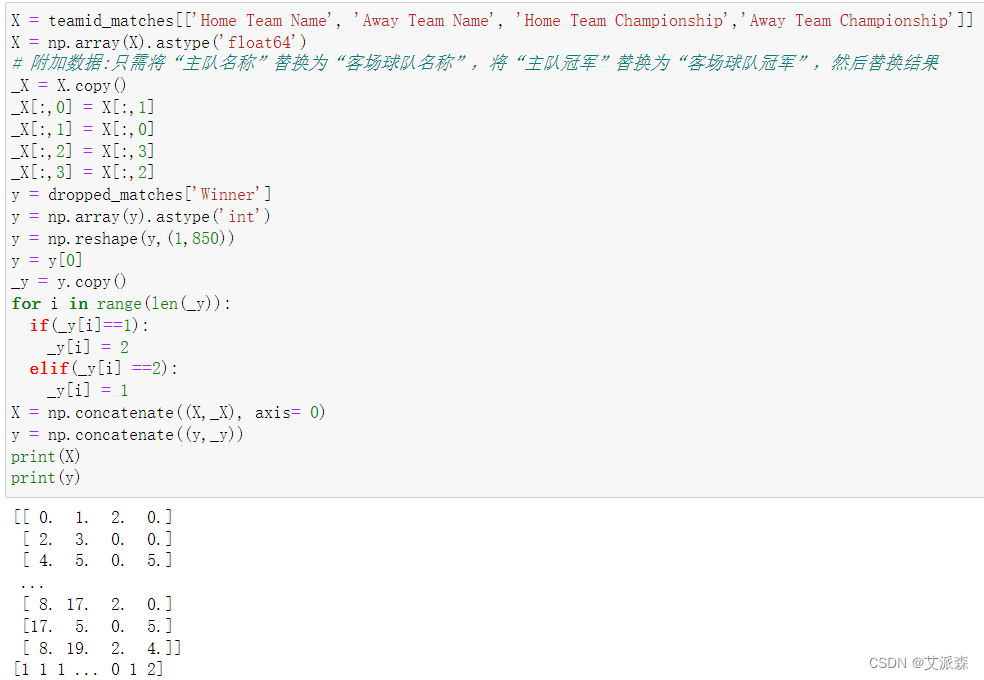
准备建模用到的X,y数据
打乱数据,然后拆分数据集为训练集和测试集
4.5模型构建
用SVM支持向量机模型进行训练并打印模型的评估指标
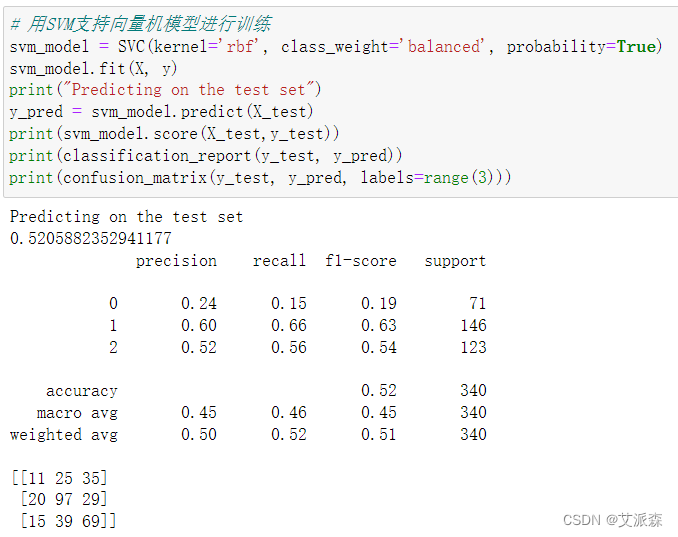
从结果发现SVM模型只有52%的正确率,模型效果较差,该模型应该不适合这个数据。
用决策树算法进行训练并打印模型的评估指标
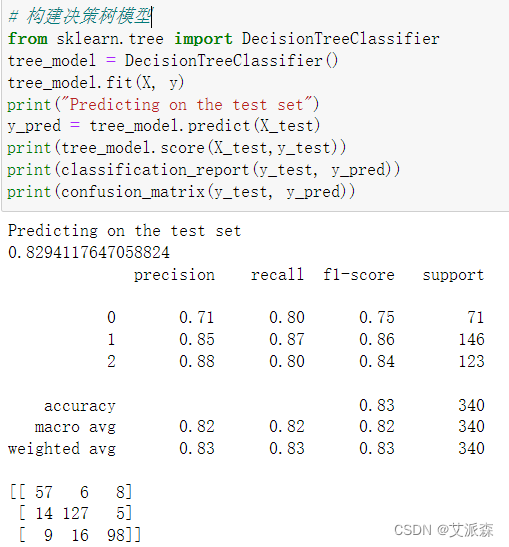
换了决策树算法,模型在测试集上的正确率一下提升到82%,看来决策树算法才是最适合该数据集的,故我们最终使用决策树算法作为最终的模型选择。
4.6模型预测
为了方便预测且让结果更直观,我们自定义一个预测函数

这里我们直接用2022年的卡塔尔世界杯最后半决赛的部分来检测模型效果
先来预测英格兰对法国的比赛

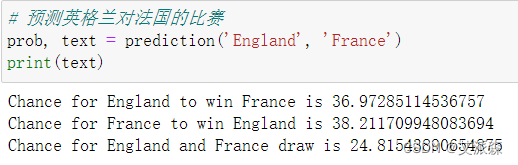
可以看出模型给出的最大概率是法国赢英格兰,但是两个球队赢的概率比较接近,与真实结果一样,预测正确!
预测阿根廷对克罗地亚的比赛

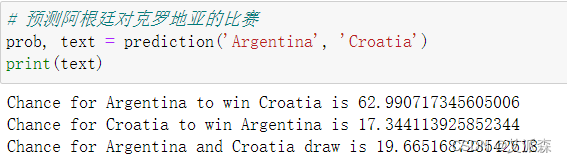
可以看出模型给出的概率阿根廷赢是克罗地亚赢的三倍多,与真实结果相比较为吻合,预测正确!
预测法国对摩洛哥的比赛

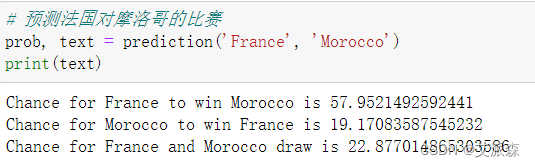
可以看出模型给出的概率法国赢是摩洛哥赢的二倍多,与真实结果一样,预测正确!
预测克罗地亚对摩洛哥的比赛

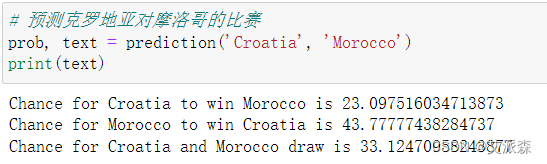
可以看出模型给出的概率最大是摩洛哥赢,但是可惜是克罗地亚赢了,预测错误!

预测阿根廷对法国的比赛
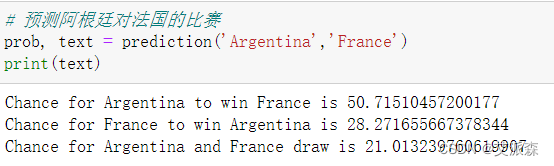
可以看出模型给出的概率最大是阿根廷赢,与真实结果一样,预测正确!
通过对上面5场比赛的预测,我们可以看出有4场预测正确,概率也是接近80%,模型效果还是不错的!需要注意的是原始数据集中是没有2022年卡塔尔世界杯比赛的数据的!说明模型在预测未知比赛上准确率还是可以的。
5.实验总结
本次实验我们使用了2018年及其之前的世界杯比赛数据,通过建立决策树模型,模型准确率为82%,接着我们使用该模型预测了2022年世界杯的5场半决赛及决赛,模型准确率也是接近80%的,说明模型效果还是很不错的。
心得与体会:
通过这次Python项目实战,我学到了许多新的知识,这是一个让我把书本上的理论知识运用于实践中的好机会。原先,学的时候感叹学的资料太难懂,此刻想来,有些其实并不难,关键在于理解。
在这次实战中还锻炼了我其他方面的潜力,提高了我的综合素质。首先,它锻炼了我做项目的潜力,提高了独立思考问题、自我动手操作的潜力,在工作的过程中,复习了以前学习过的知识,并掌握了一些应用知识的技巧等
在此次实战中,我还学会了下面几点工作学习心态:
1)继续学习,不断提升理论涵养。在信息时代,学习是不断地汲取新信息,获得事业进步的动力。作为一名青年学子更就应把学习作为持续工作用心性的重要途径。走上工作岗位后,我会用心响应单位号召,结合工作实际,不断学习理论、业务知识和社会知识,用先进的理论武装头脑,用精良的业务知识提升潜力,以广博的社会知识拓展视野。
2)努力实践,自觉进行主角转化。只有将理论付诸于实践才能实现理论自身的价值,也只有将理论付诸于实践才能使理论得以检验。同样,一个人的价值也是透过实践活动来实现的,也只有透过实践才能锻炼人的品质,彰显人的意志。
3)提高工作用心性和主动性。实习,是开端也是结束。展此刻自我面前的是一片任自我驰骋的沃土,也分明感受到了沉甸甸的职责。在今后的工作和生活中,我将继续学习,深入实践,不断提升自我,努力创造业绩,继续创造更多的价值。
这次Python实战不仅仅使我学到了知识,丰富了经验。也帮忙我缩小了实践和理论的差距。在未来的工作中我会把学到的理论知识和实践经验不断的应用到实际工作中,为实现理想而努力。
源代码
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.utils import shuffle
from sklearn.metrics import classification_report, confusion_matrix
from sklearn.svm import SVC
import warnings
warnings.filterwarnings('ignore')
# 导入数据
matches = pd.read_csv('WorldCupMatches.csv')
players = pd.read_csv('WorldCupPlayers.csv')
cups = pd.read_csv('WorldCupsSummary.csv')
# 删除缺失值
matches = matches.dropna()
players = players.dropna()
cups = cups.dropna()matches.head()
matches.head()
players.head()
# 世界杯赛冠军的数量
plt.figure(figsize=(12,6))
sns.countplot(x='Winner',data=cups)
plt.show()
# 用德国取代德国DR和德国FR,用俄罗斯取代苏联
def replace_name(df):if(df['Home Team Name'] in ['German DR', 'Germany FR']):df['Home Team Name'] = 'Germany'elif(df['Home Team Name'] == 'Soviet Union'):df['Home Team Name'] = 'Russia'if(df['Away Team Name'] in ['German DR', 'Germany FR']):df['Away Team Name'] = 'Germany'elif(df['Away Team Name'] == 'Soviet Union'):df['Away Team Name'] = 'Russia'return dfmatches = matches.apply(replace_name, axis='columns')
matches.head()
# 创建一个存储足球队的字典
team_name = {}
index = 0
for idx, row in matches.iterrows():name = row['Home Team Name']if(name not in team_name.keys()):team_name[name] = indexindex += 1name = row['Away Team Name']if(name not in team_name.keys()):team_name[name] = indexindex += 1team_name
# 删除不必要的列
dropped_matches = matches.drop(['Datetime', 'Stadium', 'Referee', 'Assistant 1', 'Assistant 2', 'RoundID','Home Team Initials', 'Away Team Initials', 'Half-time Home Goals', 'Half-time Away Goals','Attendance', 'City', 'MatchID', 'Stage'], 1)
# 计算每支球队成为世界杯赛冠军的次数
championships = cups['Winner'].map(lambda p: 'Germany' if p=='Germany FR' else p).value_counts()
championships
# 加上“主队冠军”和“客场冠军”:获取世界杯冠军的次数
dropped_matches['Home Team Championship'] = 0
dropped_matches['Away Team Championship'] = 0def count_championship(df):if(championships.get(df['Home Team Name']) != None):df['Home Team Championship'] = championships.get(df['Home Team Name'])if(championships.get(df['Away Team Name']) != None):df['Away Team Championship'] = championships.get(df['Away Team Name'])return dfdropped_matches = dropped_matches.apply(count_championship, axis='columns')
dropped_matches.head()
# 定义一个函数用于找出谁赢了:主场胜:1,客场胜:2,平局:0
dropped_matches['Winner'] = '-'
def find_winner(df):if(int(df['Home Team Goals']) == int(df['Away Team Goals'])):df['Winner'] = 0elif(int(df['Home Team Goals']) > int(df['Away Team Goals'])):df['Winner'] = 1else:df['Winner'] = 2return dfdropped_matches = dropped_matches.apply(find_winner, axis='columns')
dropped_matches.head()
# 将team_name字典中的团队名称替换为id
def replace_team_name_by_id(df):df['Home Team Name'] = team_name[df['Home Team Name']]df['Away Team Name'] = team_name[df['Away Team Name']]return dfteamid_matches = dropped_matches.apply(replace_team_name_by_id, axis='columns')
teamid_matches.head()
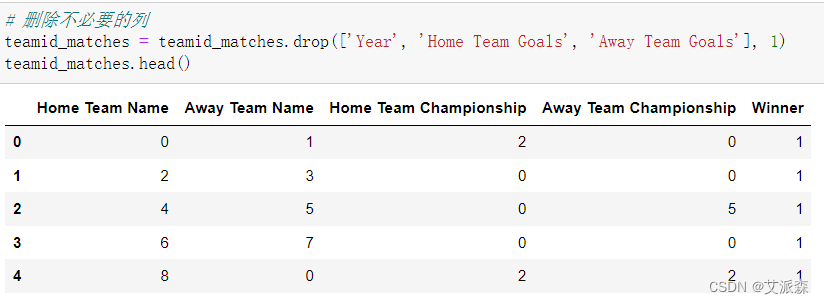
# 删除不必要的列
teamid_matches = teamid_matches.drop(['Year', 'Home Team Goals', 'Away Team Goals'], 1)
teamid_matches.head()
X = teamid_matches[['Home Team Name', 'Away Team Name', 'Home Team Championship','Away Team Championship']]
X = np.array(X).astype('float64')
# 附加数据:只需将“主队名称”替换为“客场球队名称”,将“主队冠军”替换为“客场球队冠军”,然后替换结果
_X = X.copy()
_X[:,0] = X[:,1]
_X[:,1] = X[:,0]
_X[:,2] = X[:,3]
_X[:,3] = X[:,2]
y = dropped_matches['Winner']
y = np.array(y).astype('int')
y = np.reshape(y,(1,850))
y = y[0]
_y = y.copy()
for i in range(len(_y)):if(_y[i]==1):_y[i] = 2elif(_y[i] ==2):_y[i] = 1
X = np.concatenate((X,_X), axis= 0)
y = np.concatenate((y,_y))
print(X)
print(y)
# 打乱数据,然后拆分数据集为训练集和测试集
X,y = shuffle(X,y)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# 用SVM支持向量机模型进行训练
svm_model = SVC(kernel='rbf', class_weight='balanced', probability=True)
svm_model.fit(X, y)
print("Predicting on the test set")
y_pred = svm_model.predict(X_test)
print(svm_model.score(X_test,y_test))
print(classification_report(y_test, y_pred))
print(confusion_matrix(y_test, y_pred, labels=range(3)))
# 构建决策树模型
from sklearn.tree import DecisionTreeClassifier
tree_model = DecisionTreeClassifier()
tree_model.fit(X, y)
print("Predicting on the test set")
y_pred = tree_model.predict(X_test)
print(tree_model.score(X_test,y_test))
print(classification_report(y_test, y_pred))
print(confusion_matrix(y_test, y_pred))
# 定义一个预测函数,需要传递两个球队名称,输出两个获胜的概率
def prediction(team1, team2):id1 = team_name[team1]id2 = team_name[team2]championship1 = championships.get(team1) if championships.get(team1) != None else 0championship2 = championships.get(team2) if championships.get(team2) != None else 0x = np.array([id1, id2, championship1, championship2]).astype('float64')x = np.reshape(x, (1,-1))_y = svm_model.predict_proba(x)[0]text = ('Chance for '+team1+' to win '+team2+' is {}\nChance for '+team2+' to win '+team1+' is {}\nChance for '+team1+' and '+team2+' draw is {}').format(_y[1]*100,_y[2]*100,_y[0]*100)return _y[0], text
# 预测英格兰对法国的比赛
prob, text = prediction('England', 'France')
print(text)
# 预测阿根廷对克罗地亚的比赛
prob, text = prediction('Argentina', 'Croatia')
print(text)
# 预测法国对摩洛哥的比赛
prob, text = prediction('France', 'Morocco')
print(text)
# 预测克罗地亚对摩洛哥的比赛
prob, text = prediction('Croatia', 'Morocco')
print(text)
# 预测阿根廷对法国的比赛
prob, text = prediction('Argentina','France')
print(text)
相关文章:
大数据分析案例-基于决策树算法构建世界杯比赛预测模型
🤵♂️ 个人主页:艾派森的个人主页 ✍🏻作者简介:Python学习者 🐋 希望大家多多支持,我们一起进步!😄 如果文章对你有帮助的话, 欢迎评论 💬点赞Ǵ…...

Python 图形界面框架 PyQt5 使用指南
Python 图形界面框架 PyQt5 使用指南 使用Python开发图形界面的软件其实并不多,相对于GUI界面,可能Web方式的应用更受人欢迎。但对于像我一样对其他编程语言比如C#或WPF并不熟悉的人来说,未必不是一个好的工具。 常见GUI框架 PyQt5[1]&#…...
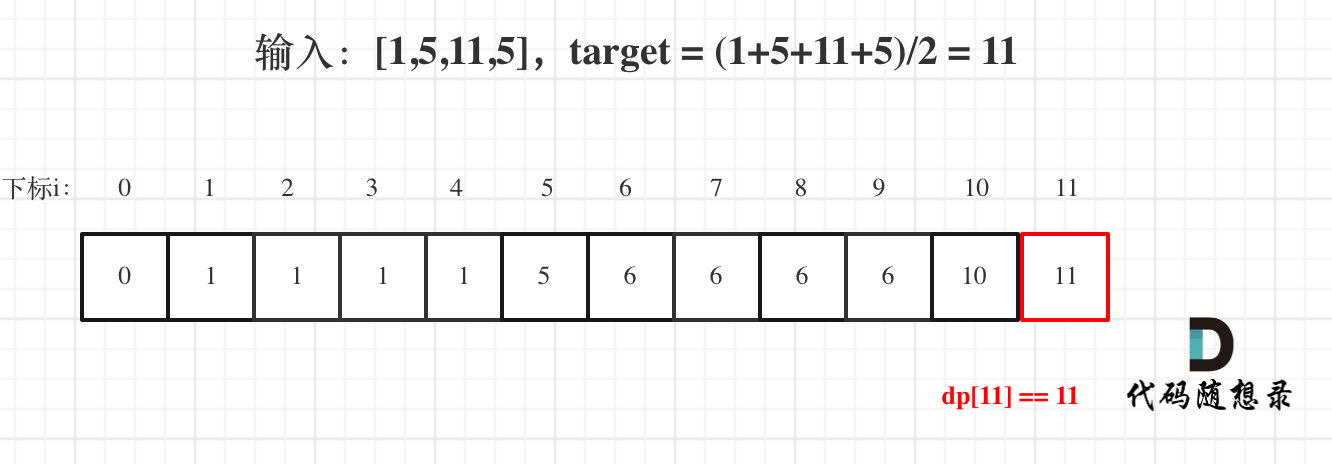
代码随想录算法训练营第四十二天 | 二维dp数组01背包, 力扣 416. 分割等和子集
背包 解析 1.确定dp数组以及下标的含义 对于背包问题,有一种写法, 是使用二维数组,即dp[i][j] 表示从下标为[0-i]的物品里任意取,放进容量为j的背包,价值总和最大是多少。 2.确定递推公式 有两个方向推出来dp[i][…...
【1110. 删点成林】
来源:力扣(LeetCode) 描述: 给出二叉树的根节点 root,树上每个节点都有一个不同的值。 如果节点值在 to_delete 中出现,我们就把该节点从树上删去,最后得到一个森林(一些不相交的…...

第三章 JVM内存概述
附录:精选面试题 Q:为什么虚拟机必须保证一个类的Clinit( )方法在多线程的情况下被同步加锁 ? A: 因为虚拟机在加载完一个类之后直接把这个类放到本地内存的方法区(也叫原空间)中了,当其他程序再来调这个类…...
基于SpringBoot的企业客户信息反馈平台的设计与实现
背景 企业客户信息反馈平台能够通过互联网得到广泛的、全面的宣传,让尽可能多的用户了解和熟知企业客户信息反馈平台的便捷高效,不仅为客户提供了服务,而且也推广了自己,让更多的客户了解自己。对于企业客户信息反馈而言…...

【SA8295P 源码分析】01 - SA8295P 芯片介绍
【SA8295P 源码分析】01 - SA8295P 芯片介绍 一、Processors 处理器介绍二、Memory 内存介绍三、Multimedia 多媒体介绍3.1 DPU 显示处理器:Adreno DPU 11993.2 摄像头ISP:Spectra 395 ISP3.3 视频处理器:Adreno video processing unit (VPU)3.4 图像处理器:Adreno graphic…...

扩展1:Ray Core详细介绍
扩展1:Ray Core详细介绍 导航 1. 简介和背景2. Ray的基本概念和核心组件3. 分布式任务调度和依赖管理4. 对象存储和数据共享5. Actor模型和并发编程6. Ray的高级功能和扩展性7. 使用Ray构建分布式应用程序的案例研究8. Ray社区和资源9. 核心框架介绍...

day08 Spring MVC
spring MVC相当于Servlet mvc解释:模型,视图,控制器 **使用该思想的作用:**减少耦合性,提高可维护性 Spring MVC前端控制器 方式1 1.在web.xml中配置前端控制器方式2 要是用前端控制器,必须在web.xml中配置DidpatcherServlet类 <!--前端控制器--> <servlet&g…...

c++中的extern “C“
在一些c语言的library库中,我们经常可以还看下面这样的结构 #ifndef __TEST_H #define __TEST_H#ifdef _cplusplus extern "C" { #endif/*...*/#ifdef _cplusplus } #endif #endif#ifndef __TEST_H这样的宏定义应该是非常常见了,其作用是为了…...

python异常处理名称整理
Python 异常处理 python提供了两个非常重要的功能来处理python程序在运行中出现的异常和错误。你可以使用该功能来调试python程序。BaseException所有异常的基类UnboundLocalError访问未初始化的本地变量SystemExit...

SpringMVC拦截器
SpringMVC拦截器 介绍 拦截器(interceptor)的作用 SpringMVC的拦截器类似于Servlet开发中的过滤器Filter,用于对处理器 进行预处理和后处理 将拦截器按一定的顺序连接成一条链,这条链称为拦截器链(Interception Ch…...
)
Python第八章作业(初级)
目录 第1关:统计字母数量 第2关:统计文章字符数 第3关:查询高校信息 第4关:查询高校名 第5关:通讯录读取 第6关:JSON转列表 第7关:利用数据文件统计成绩 第8关:研究生录取数据…...

chatgpt赋能python:Python中如何取消列表
Python中如何取消列表 在Python中使用列表是一种非常常见的数据结构,它允许我们在其中存储任意数量的元素,并且可以非常容易地进行遍历和操作。但是,有时候我们需要从列表中删除元素。这个过程并不难,但是有些细节需要注意。本文…...
Java中List排序的3种方法
在某些特殊的场景下,我们需要在 Java 程序中对 List 集合进行排序操作。比如从第三方接口中获取所有用户的列表,但列表默认是以用户编号从小到大进行排序的,而我们的系统需要按照用户的年龄从大到小进行排序,这个时候,…...

flutter-读写二进制文件到设备
看了下很多文章,本地文件存储都只有存储txt文件,我们探索下存储二进制文件吧。 保存二进制文件到设备硬盘上。 我们保存一个图片到手机本地上,并读取展示图片到app上。 以百度logo图为例子 写入图片 逻辑如下: 获取本地路径 -&g…...

C语言基础知识:内存分配
目录 内存分配原理 内存分配方法 静态内存分配 动态内存分配 MALLOC() CALLOC() 内存释放 注意事项 在C语言中,内存分配是非常重要的一个概念,因为C语言中没有内置的垃圾回收机制,需要我们手动管理内存的分配和释放。下面我们来详细讲…...
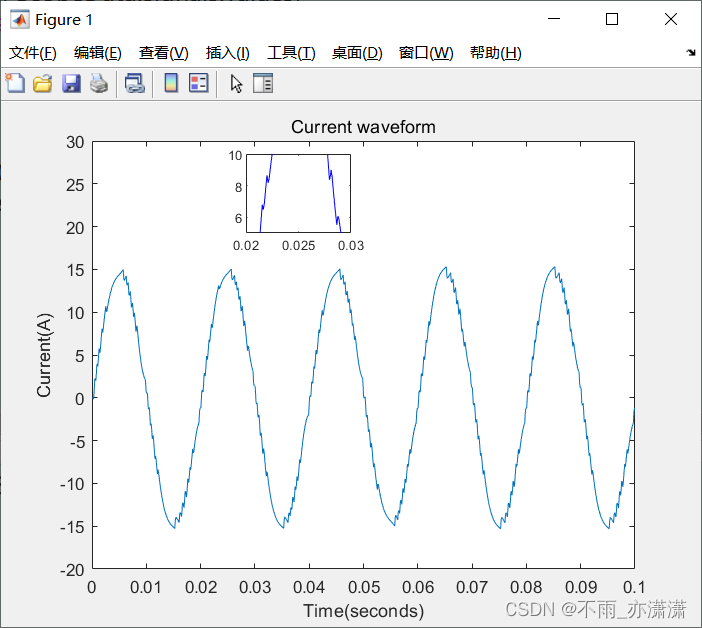
【Simulink】示波器图形数据导入Matlab重新绘图(论文)
版本:Matlab2019b 效果 示波器波形图片: 黑色背景,而且坐标轴字体较小,不方便修改,不能直接用在论文上面 对比 Matlab 绘图: 接下来介绍如何设置~ Simulink 设置 选择需要导入的示波器数据 点击 Vi…...
汇编调试及学习
汇编调试 打印寄存器的值 打印内存地址 打印8字节,就是64位 打印格式 是从低位取过来的 b 字节 h 双字节 w四字节 g八字节 前变基 后变基 。 后变基这个变基会发生变化的。前变基变基不会发生变化需要用!号。 前变基 , 加了࿰…...

Linux - 第19节 - 网络基础(传输层二)
1.TCP相关实验 1.1.理解listen的第二个参数 在编写TCP套接字的服务器代码时,在进行了套接字的创建和绑定之后,需要调用listen函数将创建的套接字设置为监听状态,此后服务器就可以调用accept函数获取建立好的连接了。其中listen函数的第一个参…...

Word到LaTeX的工业级转换:docx2tex深度解析与技术实践
Word到LaTeX的工业级转换:docx2tex深度解析与技术实践 【免费下载链接】docx2tex Converts Microsoft Word docx to LaTeX 项目地址: https://gitcode.com/gh_mirrors/do/docx2tex 在学术出版和技术文档领域,Word与LaTeX之间的格式鸿沟一直是困扰…...

影刀RPA跨境店群自动化:分布式环境调度与高并发资源隔离架构实战
定了。在这场旷日持久的跨境电商反爬风控拉锯战中,我们终于用一套基于 Python 深度协同的分布式微服务调度架构,重塑了跨境千店矩阵的自动化底座。 这几天,科技圈被“DeepSeek V4 首发华为昇腾芯片,国产 AI 开始打破英伟达 CUDA …...

Poppler Windows版:终极PDF处理方案,3分钟零配置部署指南
Poppler Windows版:终极PDF处理方案,3分钟零配置部署指南 【免费下载链接】poppler-windows Download Poppler binaries packaged for Windows with dependencies 项目地址: https://gitcode.com/gh_mirrors/po/poppler-windows 还在为Windows上复…...

Splunk紧急推送安全补丁:三枚高危漏洞同时曝光,企业数据面临泄露与瘫痪双重风险
2026年5月20日,Splunk官方安全团队一次性披露了旗下多款核心产品的重大安全隐患。此次波及范围相当广泛,从本地部署的Splunk Enterprise到云端服务Splunk Cloud Platform,再到新推出的Splunk AI Toolkit,无一幸免。三枚漏洞编号分…...

2026年实用降AIGC工具:亲测AI率从90%降至4%的靠谱方案
一、前言:2026年毕业必过AIGC检测门槛 2026年国内高校对学术论文的AIGC疑似度审核全面收紧,绝大多数院校都发布了明确的AIGC检测数值要求:985、211院校规定本科论文AI率需低于20%,硕士论文AI率不得高于15%,普通高校也普…...

Agent-S3技术深度解析:首个超越人类性能的GUI智能体架构演进与应用实践
Agent-S3技术深度解析:首个超越人类性能的GUI智能体架构演进与应用实践 【免费下载链接】Agent-S Agent S: an open agentic framework that uses computers like a human 项目地址: https://gitcode.com/GitHub_Trending/ag/Agent-S Agent-S3作为首个在OSWo…...

Win11Debloat:Windows系统优化利器,一键清理臃肿应用与隐私设置
Win11Debloat:Windows系统优化利器,一键清理臃肿应用与隐私设置 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes…...

黑苹果终极简化方案:OpCore Simplify 让你的OpenCore配置变得前所未有的简单
黑苹果终极简化方案:OpCore Simplify 让你的OpenCore配置变得前所未有的简单 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 还在为复杂的…...

《纳瓦尔宝典》幸福篇精读:程序员如何在敲码之余获得内心的平静与幸福
本文是《纳瓦尔宝典》第三部分"学习幸福"的完整精读笔记,专为程序员群体量身打造。结合技术职场高压、内卷严重的现状,拆解纳瓦尔关于幸福的核心哲学,提供可落地的日常实践方法。引言:为什么程序员更需要学习幸福&#…...

构建企业内部知识问答Agent时如何借助Taotoken降低模型依赖风险
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 构建企业内部知识问答Agent时如何借助Taotoken降低模型依赖风险 应用场景类,企业在开发基于大模型的内部分析Agent时&a…...