Python第八章作业(初级)
目录
第1关:统计字母数量
第2关:统计文章字符数
第3关:查询高校信息
第4关:查询高校名
第5关:通讯录读取
第6关:JSON转列表
第7关:利用数据文件统计成绩
第8关:研究生录取数据分析A
第9关:图书数据分析(A)
第1关:统计字母数量
读取附件是一篇英文短文,请编写程序统计这篇短文前 n 行中每一个英文字母出现的次数,结果按次数降序排列,次数相同时,按字母表顺序输出。若 n 值大于短文行数,输出整篇文章中每一个英文字母出现的次数(大写字母按小写字母统计)。 The Old Man and the Sea.txt
n = int(input()) # 输入需要统计的行数n
freq = {} # 创建一个空字典用来存储字母出现的次数
f=open("step2/The Old Man and the Sea.txt", "r") # 打开文本文件
for i, line in enumerate(f): # 遍历每一行if i >= n: # 如果行数大于等于n,则退出循环breakfor c in line: # 遍历每一个字符if c.isalpha(): # 如果是字母freq[c.lower()] = freq.get(c.lower(), 0) + 1 # 将字母转换为小写并统计出现次数,加入字典中
freq_list = sorted(freq.items(), key=lambda x: (-x[1], x[0])) # 对字典按照出现次数降序排序,如果出现次数相同,则按照字母表顺序排序
for item in freq_list: # 遍历字典print("{} 的数量是 {:>3} 个".format(item[0], item[1])) # 输出字母和出现次数
for c in 'abcdefghijklmnopqrstuvwxyz': # 遍历所有小写字母if c not in freq: # 如果字母没有出现过print("{} 的数量是 {:>3} 个".format(c, 0)) # 输出字母和0次出现第2关:统计文章字符数
读取附件中的文件(utf-8编码),统计并输出文章的前 n 行里共有多少字符(标点符号及换行符按字符统计),以及有多少个不重复的字符? The Great Learning.txt
def readFile(filename, num):with open(filename, 'r', encoding='utf-8') as file: # 只读模式打开文件content = file.readlines() # 文件全部内容读取出来放入列表中,每个元素为一行字符串txt = ''.join(content[:num]) # 列表的前num行连接为字符串return len(txt), len(set(txt)) # 以元组形式返回字符串长度和集合长度if __name__ == '__main__':num = int(input()) # 输入读取文件行数name = 'step3/The Great Learning.txt' # 文件名content = readFile(name, num) # 传入文件和行数print(*content) # 将返回的元组解包输出第3关:查询高校信息
附件 'university.csv' 中包含北京主要高校的序号、学校名称、学校标识码、主管部门、所在地、办学层次、备注等信息,以逗号分隔符。 参考提示代码,将文件内容逐行读取到列表中,根据用户输入的学校名,查询学校信息并输出。 university.csv
示例
输入: 北京大学
输出: 序号,学校名称,学校标识码,主管部门,所在地,办学层次,备注 1,北京大学,4111010001,教育部,北京市,本科,
s=input().strip() #输入检索词
with open('step4/university.csv', 'r', encoding='utf-8') as f:lines = f.read().split("\n")print(lines[0].strip())
for i in lines:#遍历每一行if len(i) > 0:univers=i.split(",")[1]#拆分列表,得到学校if s in univers:#如果这一行有关键词print(i)
第4关:查询高校名
附件'university.csv'中包含北京主要高校的序号、学校名称、学校标识码、主管部门、所在地、办学层次、备注等信息,以逗号分隔符。 参考提示代码,将文件内容逐行读取到列表中,根据用户输入一个关键字,查询学校名称包含用户输入关键字的学校名并输出。 university.csv
示例
输入: 中央
输出: 中央财经大学 中央音乐学院 中央美术学院 中央戏剧学院 中央民族大学
name = input()
with open('step5/university.csv','r',encoding='utf-8') as Uname:ls = Uname.read().split('\n')
for line in ls:university_name = line.split(',')[1]if name in university_name:print(university_name)
第5关:通讯录读取
任务描述
info.csv 读取附件中的csv文件(通讯录信息),放入字典中(后两项以列表形式做为字典的值),并依次输出其中的信息。文件内数据不需要修改,输出时数据之间以空格间隔。 编码格式使用utf-8 输入‘A’时,按行输出文件信息 输入‘D’时,直接输出字典内容 输入其他数据时,输出“ERROR”
s = input()
if s =="A":with open('step6/info.csv','r',encoding='utf-8') as f:txt = f.read()txt = txt.replace(","," ")print(txt)
elif s =="D":with open('step6/info.csv','r',encoding='utf-8') as f:txt = f.readlines()dic = {}for line in txt:lis = list(line.strip().split(','))dic[lis[0]] = lis[1:]print(dic)
else:print('ERROR') 第6关:JSON转列表
任务描述
读取附件中的JSON文件,转为列表输出。 score1034.json
示例
输入: 2 输出:
[['姓名', '学号', 'C', 'C++', 'Java', 'Python', 'C#', '总分'], ['刘雨', '0121701100507', '20', '20', '20', '16', '20', '96']]
import json
with open('step7/score1034.json','r',encoding='utf-8') as f:lis1 = json.loads(f.read())lis2 = [['姓名', '学号', 'C', 'C++', 'Java', 'Python', 'C#', '总分']]for i in lis1:lis2.append(list(i.values()))
n = int(input())
print(lis2[:n])第7关:利用数据文件统计成绩
利用附件中的成绩数据进行成绩统计,根据总分进行升序排序后,输出总分最低分和最高分,按总分升序输出前n名同学和后n名同学成绩信息(n为非负数,当n大于数据行数时,按实际行数输出),输出每题的平均成绩。 (注:数据文件中最后一列是总分,第4-9列每列为一道题的成绩,打开与关闭文件代码已经给出) 成绩单.csv
n = int(input())
ls1 = []
ls2 = []
with open('step8/成绩单.csv', 'r', encoding='utf-8') as f:for line in f.readlines():line = line.strip('\n')ls = list(line.split(','))ls1.append(ls)ls1.sort(key=lambda x: eval(x[9]))print('最低分{}分,最高分{}分'.format(ls1[0][9], ls1[len(ls1) - 1][9]))
if n <= len(ls1):print(ls1[:n])print(ls1[(len(ls1) - n):])
else:print(ls1)print(ls1)
for j in range(3, 9):s = 0for i in ls1:s = s + eval(i[j])a = s / len(ls1)ls2.append(eval('%.2f' % a))
print(ls2)第8关:研究生录取数据分析A
任务描述
admit2.csv 本题附件包含500名国际高校的研究生申请人的相关信息和预测的录取概率数据。 下表为文件中字段及对应含义:
| Serial No | GRE Score | TOEFL Score | University Rating | SOP | LOR | CGPA | Research | Chance of Admit |
|---|---|---|---|---|---|---|---|---|
| 编号1-500 | GRE分数 | 托福分数 | 本科大学排名分 | 个人陈述分数 | 推荐信分数 | 本科绩点 | 研究经历(1/0) | 录取概率(0-1之间) |
研究经历:1代表有,0代表无
录取概率:0-1之间的小数,如0.73代表73% 请按照下列要求对文件中数据进行统计和分析,并严格按照下面所示格式输出结果。 (描述中示例仅为格式示例,数据与测试用例无关)
输入一个数据n
1:如果n为'1',抽取数据中录取概率大于等于80%的记录,计算其中大学排名评分大于等于4分的百分比,程序结束。
1 Top University in >=80%:11.11% 2:如果n为'Research',分别统计和输出录取概率大于等于90%的学生和录取概率小于等于70%的学生中,有研究经历的学生占比,程序结束。(百分比保留两位小数)
Research Research in >=90%:91.03% Research in <=70%:22.10% 3:如果n为'2',输出录取概率大于等于80%的学生中TOEFL分数的平均分,最高分和最低分,程序结束。(保留两位小数)
2 TOEFL Average Score:300.12 TOEFL Max Score:323.00 TOEFL Min Score:299.00 4:如果n为'3',输出录取概率大于等于80%的学生中绩点的平均分,最高分和最低分,程序结束。(保留三位小数)
3 CGPA Average Score:4.333 CGPA Max Score:4.910 CGPA Min Score:4.134 5:如果非以上输入,则输出'ERROR',程序结束。
def readfile1(filename):#用于筛选出概率大于等于80%,返回列表ls = []with open(filename,"r") as fp:s = fp.readline()s = fp.readline()while s:l = s.strip().split(",")if eval(l[-1])>=0.8:ls.append(l)s = fp.readline()return ls
def readfile2(filename):#用于筛选出概率大于等于90%以及小于等于70%,返回列表ls1 = []ls2 = []with open(filename,"r") as fp:s = fp.readline()s = fp.readline()while s:l = s.strip().split(",")if eval(l[-1])>=0.9:ls1.append(l)if eval(l[-1])<=0.7:ls2.append(l)s = fp.readline()return ls1,ls2n = input()
filename = "step9/admit2.csv"
if n=='1':ls = readfile1(filename)cnt = 0#用于记录排名大于4的个数for row in ls:if eval(row[1])>=4:cnt += 1print("Top University in >=80%%:%.2f%%"%(cnt/len(ls)*100))
elif n == 'Research':ls1,ls2 = readfile2(filename)cnt1 = len([i for i in ls1 if i[-4] == '1'])#大于90%,且有研究经历的个数cnt2 = len([i for i in ls2 if i[-4] == '1'])#小于70%,且有研究经历的个数print("Research in >=90%%:%.2f%%"%(cnt1/len(ls1)*100))print("Research in <=70%%:%.2f%%"%(cnt2/len(ls2)*100))
elif n=='2':ls = readfile1(filename)l = []#保存所有TOEFL分数for i in ls:l.append(float(i[3]))print("TOEFL Average Score:%.2f"%(sum(l)/len(l)))print("TOEFL Max Score:%.2f"%max(l))print("TOEFL Min Score:%.2f"%min(l))
elif n=='3':ls = readfile1(filename)l = []#保存所有绩点分数for i in ls:l.append(float(i[-5]))print("CGPA Average Score:%.3f"%(sum(l)/len(l)))print("CGPA Max Score:%.3f"%max(l))print("CGPA Min Score:%.3f"%min(l))
else:print("ERROR")第9关:图书数据分析(A)
任务描述
CBOOK.csv
读取附件中的图书数据信息,并按照下列要求对数据进行统计分析(文件编码为utf-8) 文件包含信息格式:编号,书名,出版社,现价,原价,评论数,推荐指数 其中评论数形式为'1290021条评论',书名可能包含书的简单描述,形如'雪落香杉树(福克纳奖得主,全球畅销500万册)'。
要求: 输入一个字符串 输入是'record',统计输出图书数据的总数量,格式见示例 输入是'rank',需要再输入一个书籍编号,分别输出编号对应的书籍信息(编号,书名,出版社,现价,原价,评论数,推荐指数),格式见示例 输入是'maxcomment',输出评论数量最多的10本书的书名和评论数,按评论数量降序排序,格式见示例 输入是'maxname',需要再输入一个数值n,输出书名最长的n本书的名字,按书名长度降序排序,格式见示例 非以上输入,输出'无数据' 下列示例仅表明输入输出格式,输出的数据不是本题答案数据
def maxname(n): # 输出名字最长的十本书,长度相同以现价从高到低排序ls.sort(key=lambda x: (len(x[1]), eval(x[3])), reverse=True)for i in ls[:n]:print(i[1])def minname(n): # 输出名字最短的十本书ls.sort(key=lambda x: (len(x[1])))for i in ls[:n]:print(i[1])def priceNow(): # 现价最高和最低l = sorted(ls, key=lambda x: eval(x[3]), reverse=True)for i in l[0][:-3]:print(i)for i in l[-1][:-3]:print(i)def priceOrgin(): # 原价最高和最低l = sorted(ls, key=lambda x: eval(x[3]), reverse=True)for i in l[0][:-3]:print(i)for i in l[-1][:-3]:print(i)def number():print(len(ls))def maxcomment(): # 评论数量多的书籍前10l = sorted(ls, key=lambda x: eval(x[-2][:-3]), reverse=True)for i in l[:10]:print(i[1], i[-2])def mincomment(): # 评论数量少的书籍前10l = sorted(ls, key=lambda x: eval(x[-2][:-3]))for i in l[:10]:print(i[1], i[-2])def rank():n = input()for i in ls:if n == i[0]:for j in i:print(j)breakwith open('step10/CBOOK.csv', 'r') as f:ls = []for i in f.readlines()[1:]:ls.append(i.strip().split(','))c = input().lower()
if c == 'record':number()
elif c == 'rank':rank()
elif c == 'maxname':n=eval(input())maxname(n)
elif c == 'minname':n = eval(input())minname(n)
elif c == 'nprice':priceNow()
elif c == 'oprice':priceOrgin()
elif c == 'maxcomment':maxcomment()
elif c == 'mincomment':mincomment()
else:print('无数据')
相关文章:
)
Python第八章作业(初级)
目录 第1关:统计字母数量 第2关:统计文章字符数 第3关:查询高校信息 第4关:查询高校名 第5关:通讯录读取 第6关:JSON转列表 第7关:利用数据文件统计成绩 第8关:研究生录取数据…...

chatgpt赋能python:Python中如何取消列表
Python中如何取消列表 在Python中使用列表是一种非常常见的数据结构,它允许我们在其中存储任意数量的元素,并且可以非常容易地进行遍历和操作。但是,有时候我们需要从列表中删除元素。这个过程并不难,但是有些细节需要注意。本文…...
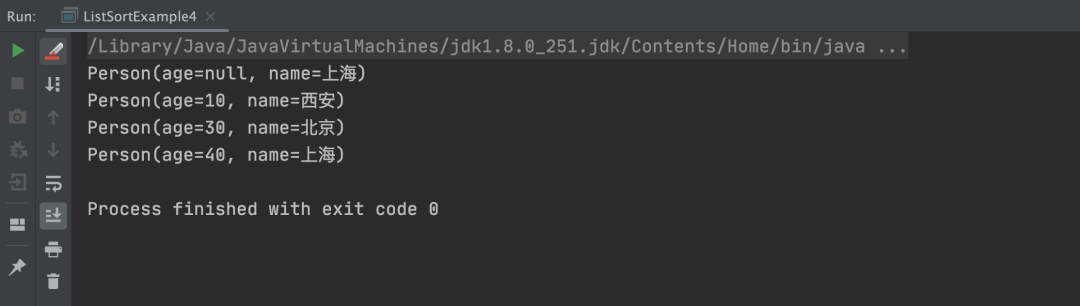
Java中List排序的3种方法
在某些特殊的场景下,我们需要在 Java 程序中对 List 集合进行排序操作。比如从第三方接口中获取所有用户的列表,但列表默认是以用户编号从小到大进行排序的,而我们的系统需要按照用户的年龄从大到小进行排序,这个时候,…...

flutter-读写二进制文件到设备
看了下很多文章,本地文件存储都只有存储txt文件,我们探索下存储二进制文件吧。 保存二进制文件到设备硬盘上。 我们保存一个图片到手机本地上,并读取展示图片到app上。 以百度logo图为例子 写入图片 逻辑如下: 获取本地路径 -&g…...

C语言基础知识:内存分配
目录 内存分配原理 内存分配方法 静态内存分配 动态内存分配 MALLOC() CALLOC() 内存释放 注意事项 在C语言中,内存分配是非常重要的一个概念,因为C语言中没有内置的垃圾回收机制,需要我们手动管理内存的分配和释放。下面我们来详细讲…...
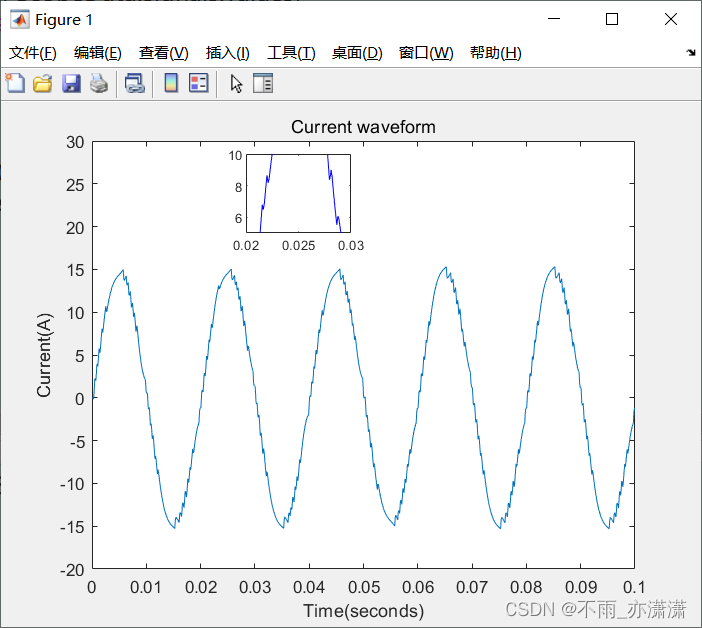
【Simulink】示波器图形数据导入Matlab重新绘图(论文)
版本:Matlab2019b 效果 示波器波形图片: 黑色背景,而且坐标轴字体较小,不方便修改,不能直接用在论文上面 对比 Matlab 绘图: 接下来介绍如何设置~ Simulink 设置 选择需要导入的示波器数据 点击 Vi…...
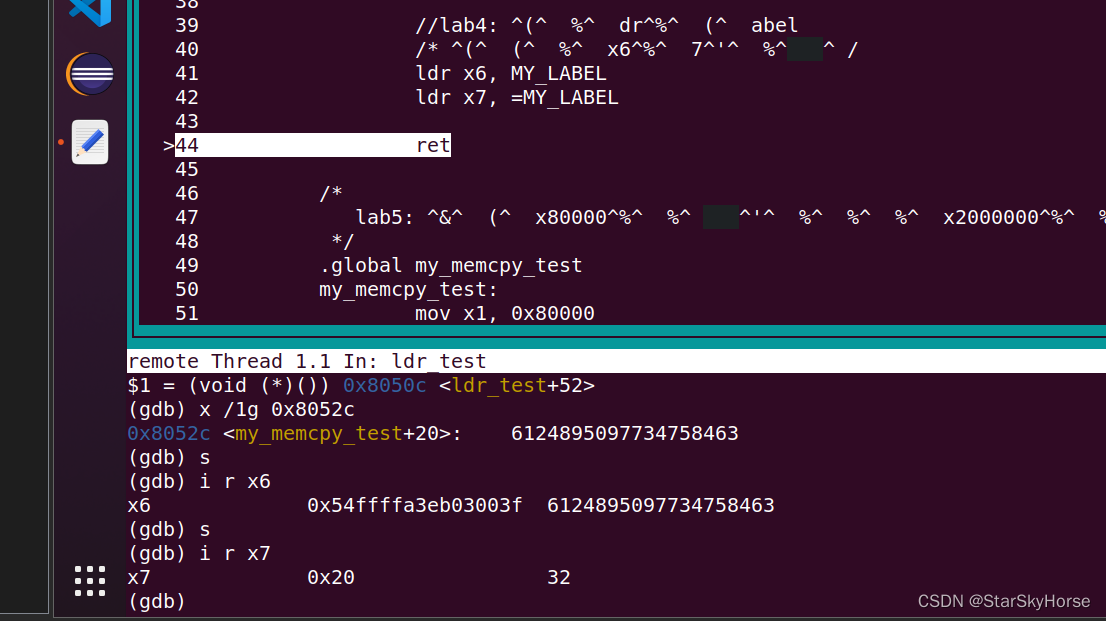
汇编调试及学习
汇编调试 打印寄存器的值 打印内存地址 打印8字节,就是64位 打印格式 是从低位取过来的 b 字节 h 双字节 w四字节 g八字节 前变基 后变基 。 后变基这个变基会发生变化的。前变基变基不会发生变化需要用!号。 前变基 , 加了࿰…...

Linux - 第19节 - 网络基础(传输层二)
1.TCP相关实验 1.1.理解listen的第二个参数 在编写TCP套接字的服务器代码时,在进行了套接字的创建和绑定之后,需要调用listen函数将创建的套接字设置为监听状态,此后服务器就可以调用accept函数获取建立好的连接了。其中listen函数的第一个参…...

web实现日历、阳历农历之间相互转换、npm、push、unshift、includes、innerHTML
文章目录 1、原生web实现效果图htmlJavaScriptstyle vue2实现htmlJavaScript 1、原生web实现 效果图 html <div class"box"><div class"week"><div>星期日</div><div>星期一</div><div>星期二</div><…...

GcExcel v6.1 支持新的 ‘.sjs‘ 模板文件 ‘.xltx‘ 格式 Crack
GrapeCity Documents for Excel (GcExcel) v6.1 版本现已上线!该版本支持新的 SpreadJS .sjs 文件格式和 Excel 模板文件 .xltx 格式。此外,GcExcel 支持更多的SpreadJS兼容性功能和对 GcDataViewer 的多项增强。看看下面的主要亮点。 导入/导出 Spread…...
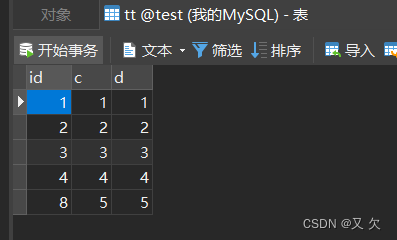
面试官:MySQL自增主键一定是连续的吗?
测试环境: MySQL版本:8.0 数据库表:T (主键id,唯一索引c,普通字段d) 如果你的业务设计依赖于自增主键的连续性,这个设计假设自增主键是连续的。但实际上,这样的假设是错的…...

2023ACP世界大赛教育者论坛:让职业教育直面AI机遇与挑战
“AI技术的普及对创意行业和教育带来的影响和变革-2023 Adobe Certified Professional教育者论坛”在苏州西交利物浦大学成功举办。 本次论坛,由Adobe Certified Professional 世界大赛中国赛区组委会主办,联动了来自院校、海内外杰出的创意公司及国际知…...
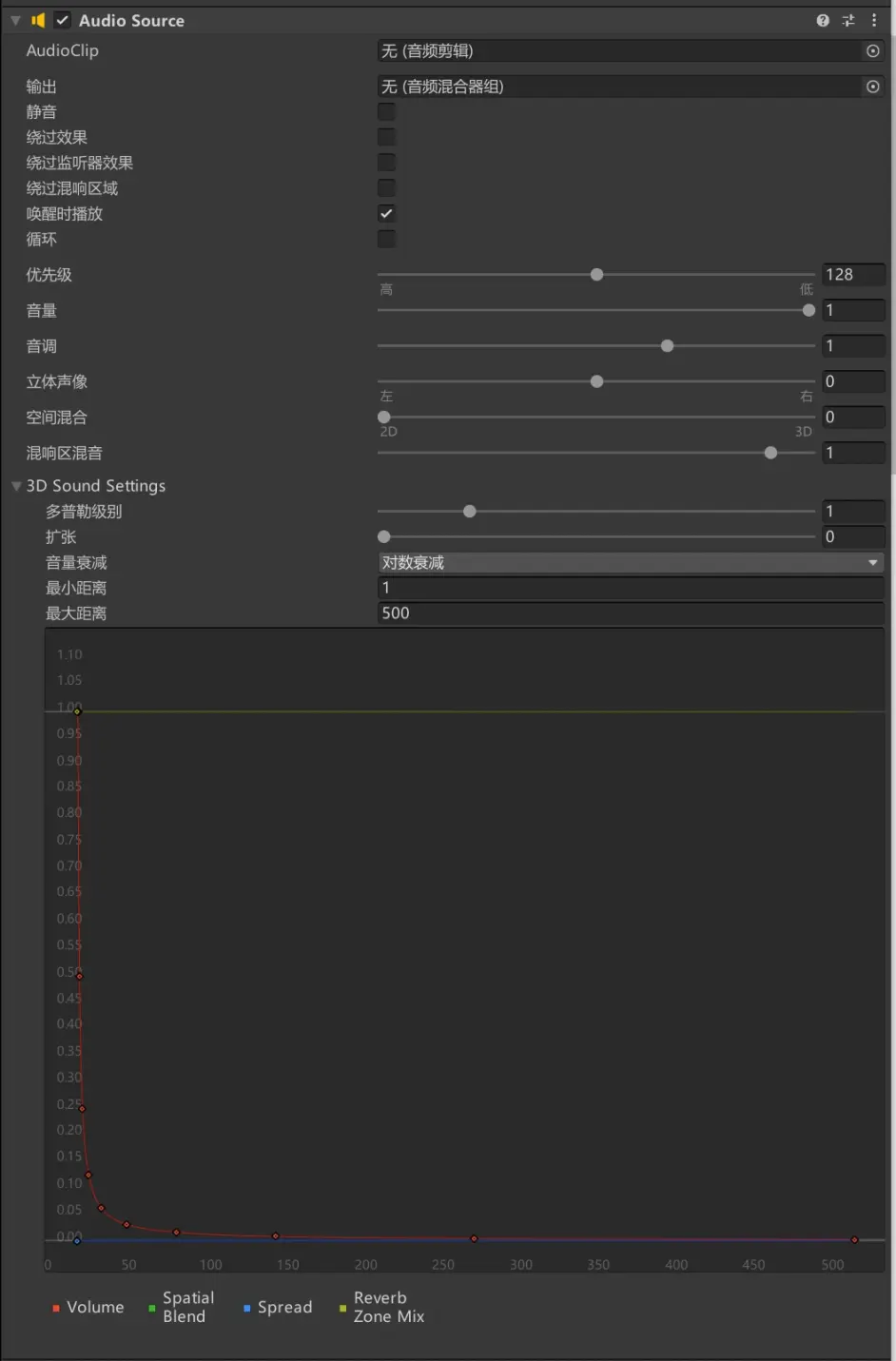
Unity基础 音频组件以及音频播放
在游戏开发中,声音是一个重要的环节。Unity中的声音组件可以帮助开发者轻松地控制游戏中音频的播放、音量、循环等属性,从而实现更好的游戏体验。本文将详细介绍Unity声音组件的相关概念和技术,以及其在游戏、影视等领域的广泛应用和发展前景…...
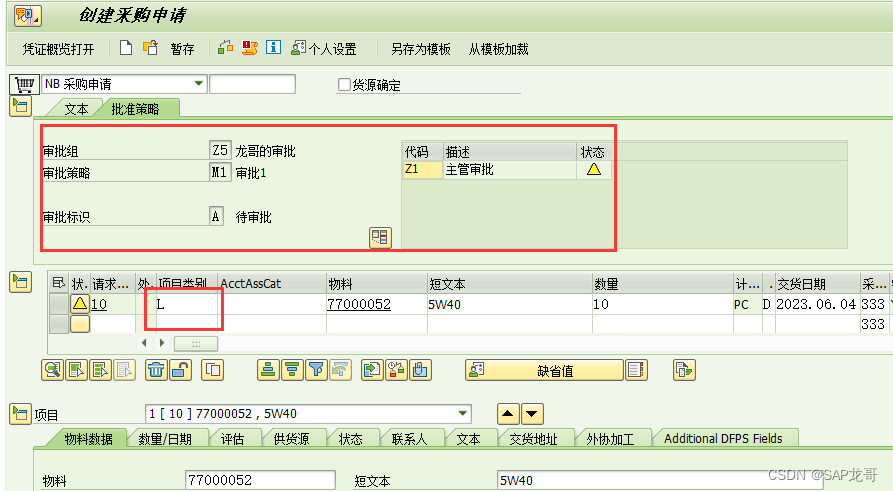
SAP-MM-采购申请审批那些事!
1、ME55不能审批删除行项目的PR 采购申请审批可以设置行项目审批或抬头审批。如果设置为抬头审批时,ME55集中审批时,就会发现有些采购申请时不能审批的, 那么这些采购申请时真的不需要审批么?不是的,经过核对这些采购申…...

专业解读财务共享实现财务数智化转型的有效路径
近年来,随着数字经济的飞速发展,各大企业全面开启数智化转型之路,作为企业数智化转型的重要内容,财务数智化转型始于财务共享服务。然而,财务共享建设并不是一蹴而就的,如何通过财务共享实现财务数智化转型…...
九章云极DataCanvas公司诚邀您共享AI基础软件前沿技术盛宴
“杭州通用人工智能论坛暨AIIA人工智能产业发展大会”将于2023年5月30日-31日在杭州举办。本次人工智能产业发展大会由中国信息通信研究院、中国人工智能产业发展联盟主办,杭州城西科创大走廊管委会、杭州市经济和信息化局、杭州未来科技城管理委员会、人工智能关键…...

【高级语言程序设计(一)】第 10 章:文件
目录 一、文件概述 (1)文件定义 (2)文件命名 (3)文件分类 ① 按照文件的内容划分 ② 按照文件的组织形式划分 ③ 按照文件的存储形式划分 ④ 按照文件的存储介质划分 (4)文…...

Android 宿主启动插件中的Activity和Service
在宿主App中加载插件App中的四大组件,需要以下几个步骤: 1. 预先在宿主的AndroidManifest文件中声明插件中的四大组件 <?xml version"1.0" encoding"utf-8"?> <manifest xmlns:android"http://schemas.android.co…...

00后卷王自述,我真的很卷吗?
前段时间我去面试了一个软件测试公司,成功拿到了offer,薪资也从10k涨到了18k,对于工作都还没两年的我来说,还是比较满意的,毕竟有些工作了3到4年的可能还没有我的高。 在公司一段时间后大家都说我是卷王,其…...

真题详解(树的结点)-软件设计(八十四)
真题详解(汇总)-软件设计(八十三)https://blog.csdn.net/ke1ying/article/details/130856130?spm1001.2014.3001.5501 COCOMOII估算不包括_____。 对象点 B.功能点 C.用例数 D.源代码行 答案:C 语法翻译是一种ÿ…...

大模型赋能金融行业:应用场景、现实挑战与应对策略
大模型技术在金融领域的应用日益深入,成为行业变革的重要驱动力,有助于降本增效、提升客户体验、赋能风险管理、促进业务创新和助力数字化转型。然而,金融行业应用大模型仍面临高质量数据不足、算力紧缺、技术缺陷、人才短缺及隐私安全等挑战…...

OBS直播教程:OBS多路推流在哪里设置?如何安装?OBS多路推流教程
OBS直播教程:OBS多路推流在哪里设置?如何安装?OBS多路推流教程 具体如何下载?如何安装?如何使用?我写了一个保姆级教程,请往下看,步骤很详细的,你一定看得懂 第一步&…...

从RTL代码到SDC约束:手把手教你为PLL/DCM生成的时钟写对时序约束
从RTL代码到SDC约束:手把手教你为PLL/DCM生成的时钟写对时序约束 在数字芯片设计流程中,时钟约束的正确性直接影响着时序收敛的效率和质量。很多工程师能够熟练编写RTL代码,却在转换为SDC约束时遇到困惑——特别是当设计中使用PLL、DCM或自定…...
)
告别低效手动:用Amass的intel命令挖掘目标企业所有关联域名(实战演示)
企业级攻击面测绘:Amass intel模块的深度情报挖掘实战 在渗透测试或红队行动中,传统子域名枚举往往只触及企业数字资产的表层。真正的高手会从组织架构、商业关系和技术基础设施三个维度构建立体化的攻击面图谱。Amass的intel模块正是这样一把瑞士军刀—…...

Android Automotive HAL层开发避坑指南:从Vehicle模块源码看如何实现一个稳定的VHAL服务
Android Automotive VHAL开发实战:从架构解析到性能调优全攻略 1. VHAL核心架构深度剖析 在Android Automotive生态系统中,Vehicle HAL(VHAL)作为连接车载硬件与上层应用的关键中间层,其设计直接影响整个车机系统的稳定性和响应速度。现代VHA…...

告别手动打字:87种语言视频字幕5分钟本地提取全攻略
告别手动打字:87种语言视频字幕5分钟本地提取全攻略 【免费下载链接】video-subtitle-extractor 视频硬字幕提取,生成srt文件。无需申请第三方API,本地实现文本识别。基于深度学习的视频字幕提取框架,包含字幕区域检测、字幕内容提…...
)
人机协作新范式:高效论文写作全流程AI论文平台推荐(2026 最新)
2026年AI论文平台持续升级,论文写作全流程可拆解为文献调研→选题/开题→大纲/初稿→文献综述→降重/去AI味→润色/格式→查重/投稿七大环节,以下工具按环节精准匹配,兼顾中文适配、降重能力、去AI痕迹、学术合规四大核心需求,覆盖…...

紧急预警:传统ML Ops正被Agent-native ML取代!3类组织已启动迁移,你还在手动调参?
更多请点击: https://kaifayun.com 第一章:AI Agent机器学习应用的范式跃迁 传统机器学习系统通常以静态模型为中心,依赖人工特征工程、固定训练-推理流水线与离线评估闭环。而AI Agent的兴起正推动一场根本性范式跃迁:从“被动预…...

CANN-昇腾NPU梯度累积-显存不够时怎么模拟大batch训练
大模型训练的最佳 batch size 通常在 1M-4M tokens。8 卡 Atlas 800I A2 的总显存 512GB,batch size 能开到 50 万 tokens 左右——不够。梯度累积让你用小 batch 跑多次前向,累积梯度后一次性更新,等效于大 batch 训练。 梯度累积的原理 标准…...

Python EXE逆向工程架构解析:多格式可执行文件源码提取技术实现
Python EXE逆向工程架构解析:多格式可执行文件源码提取技术实现 【免费下载链接】python-exe-unpacker A helper script for unpacking and decompiling EXEs compiled from python code. 项目地址: https://gitcode.com/gh_mirrors/py/python-exe-unpacker …...