Elasticsearch 8.X 性能优化参考 —— 筑梦之路
Elasticsearch 是实现用户无缝搜索体验的关键工具。它通过提供快速、准确和相关的搜索结果,彻底改变了用户与应用程序的互动方式。然而,要确保 Elasticsearch 部署达到最佳性能,就必须关注关键指标,并对诸如索引、缓存、查询、搜索以及存储等各种组件进行优化。
通用优化
1. 选用合适的硬件配置
Elasticsearch是一个内存密集型应用程序,因此使用足够内存的硬件非常重要。此外,建议使用固态硬盘(SSD)作为存储设备,因为它们可以显著提高索引和搜索性能。
尽管 SSD 的 I/O 性能优于传统硬盘,但如果 Elasticsearch 集群中的节点数量较多,I/O 性能仍然可能成为瓶颈。为了保证性能,可以采取一些优化措施,如使用 RAID 配置、合理的磁盘划分和负载均衡等。
| RAID级别 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| RAID 0 | 高I/O性能,实现并行读写 | 无冗余,磁盘故障可能导致数据丢失 | 性能敏感型应用,可接受数据恢复时间 |
| RAID 1 | 数据冗余,磁盘故障时数据不丢失 | 写入性能不如RAID 0 | 数据安全性和可靠性较高的应用 |
| RAID 5 | 数据冗余,一定程度的I/O性能优势 | 写入性能不如RAID 0 | 需要在性能和数据安全性之间取得平衡的应用 |
| RAID 10 | 结合RAID 0和RAID 1的优点,高I/O性能和数据冗余 | 需要更多磁盘,成本较高 | 既需要保证性能又需要保证数据安全性的应用 |
2. 规划索引策略
Elasticsearch设计用于处理大量数据,但需要考虑如何索引这些数据。这包括需要多少分片和副本,数据将如何索引,以及如何处理更新和删除。
1)分片数量
选择合适数量的分片以实现水平扩展和负载均衡。
默认情况下,每个索引有 1 个主分片。根据数据量和节点数量调整分片数量。尽量避免使用过多分片,因为每个分片都需要额外的资源和开销。
2)副本数量
增加副本数量以提高搜索性能和系统容错能力,但要辩证看,后文会详细解读。
默认情况下,每个分片有 1 个副本。根据负载和可用性需求调整副本数量。
3) 数据索引策略
使用基于时间的索引生命周期管理策略(ILM)以提高查询性能和降低资源消耗。例如,为每天、每周或每月的数据创建一个新索引。
选择合适的字段类型和分析器。优化映射以减少存储空间和提高查询性能。
使用 Index Templates 自动应用映射和设置。
4) 更新和删除处理
使用 Update API 更新文档,避免删除和重新索引整个文档。
合理使用 Elasticsearch 的版本控制特性。
考虑使用 Index Lifecycle Management (ILM) 自动管理索引的生命周期。根据具体业务需求和场景,灵活调整上述建议以优化 Elasticsearch 集群性能
3. 优化查询
Elasticsearch是一个功能强大的搜索引擎,但要确保查询性能优化。这包括尽可能使用过滤器而不是查询,并使用分页限制返回结果的数量。
1) 使用过滤器而不是查询
提高查询速度:过滤器不计算相关性得分。
结果可被缓存:相同过滤条件直接获取结果。
2) 使用分页限制返回结果数量
降低计算和传输负担:提高查询性能。
注意深度分页可能导致性能问题:考虑使用
search_after参数。
4. 保持Elasticsearch版本更新
Elasticsearch是一个活跃的项目,定期发布新版本以修复错误并提供新功能。保持版本更新至关重要,以利用这些改进并避免已知问题。
5. 做好监控
Elasticsearch 提供了各种监控工具,如Elasticsearch Head、Kibana monitoring(优先推荐)插件,可用于监控集群的健康和性能。需要密切关注磁盘使用情况、CPU和内存使用情况以及搜索请求的数量。
写入(索引化)优化建议
1. 使用批量请求
Elasticsearch的批量API允许在单个API调用中执行多个索引/删除操作。这大大提高了索引速度。如果请求中的一个失败,顶层错误标志将设置为true,并在相关请求下报告错误详细信息。
使用 Elasticsearch 的批量 API 的原因:
提高性能
减少网络开销和连接建立时间,提高索引速度。
2. 减少资源消耗
降低服务器和客户端资源消耗,提高系统效率和吞吐量。
3. 错误处理
灵活且可控的错误处理方式,即使部分操作失败,其他操作仍可继续执行。
使用批量 API 可实现高效的数据索引和删除操作,同时提高系统的稳定性和可靠性。
2. 使用多线程客户端索引数据
单个线程发送批量请求无法充分利用Elasticsearch集群的索引能力。
通过多线程或多进程发送数据,将有助于利用集群的所有资源,降低每个fsync的成本,提高性能。
3. 增加刷新间隔(index.refresh_interval)
Elasticsearch中默认的刷新间隔为1秒,但如果搜索流量很小,可以增加此值以优化索引速度。
4. 使用自动生成的ID
在索引具有显式ID的文档时,Elasticsearch需要检查是否已经存在具有相同ID的文档,这是一项代价高昂的操作。
使用自动生成的ID可以跳过此检查,使索引更快。
5. index.translog.sync_interval
此设置控制translog何时提交到磁盘,无论写操作如何。默认值为5秒,但不允许使用小于100毫秒的值。
官方文档地址:
https://www.elastic.co/guide/en/elasticsearch/reference/current/index-modules-translog.html
6. 避免大型文档
大型文档会给网络、内存使用和磁盘带来压力,导致索引速度缓慢,影响邻近搜索和高亮显示。
高亮处理推荐 fvh 高亮方式
7. 显式设置映射
Elasticsearch可以动态创建映射,但并不适用于所有场景。显式设置(strict)映射将有助于确保最佳性能。

显式设置映射的优势:
准确的字段类型
确保查询和聚合操作正确性。
2.优化存储和性能
降低存储空间,提高查询性能。
3.避免不必要的映射更新
减少映射更新操作和性能开销。
8. 避免使用嵌套Nested类型
虽然嵌套类型在某些场景下很有用,但它们也带来了一定的性能影响:
查询速度较慢
与查询非嵌套文档中的普通字段相比,查询嵌套字段速度较慢。
这是因为嵌套字段的查询需要执行额外的处理步骤,例如过滤器和关联。这可能导致较低的查询性能,特别是在处理大量数据时。
2. 额外的减速
在检索匹配嵌套字段的文档时,Elasticsearch 需要对嵌套层文档进行关联。这意味着它需要将嵌套文档与其外层文档匹配,以确定哪些文档实际上包含匹配的嵌套字段。这个过程可能导致额外的性能开销,尤其是在查询结果集很大时。
为了避免嵌套类型带来的性能影响,可以考虑使用以下方法:
扁平化数据结构(俗成大宽表):尽可能将嵌套字段转换为扁平化的数据结构,例如使用多个普通字段表示原本的嵌套字段。
使用关键词类型(keyword类型):对于具有固定集合值的字段,可以使用关键词类型进行索引,以提高查询速度。
使用 join 类型(父子关联类型):在某些场景下,可以使用 join 类型替代嵌套类型。
但请注意,join 类型也可能导致性能问题,尤其是在需要频繁修改文档关系时。
查询和搜索优化建议
1. 尽可能使用 filter 而不是 query
query 子句用于回答“这个文档与这个子句的匹配程度如何?
filter(过滤器)子句用于回答“这个文档是否与这个子句匹配?” Elasticsearch只需要回答“是”或“否”。它不需要为过滤器子句计算相关性得分,而且过滤器结果可以被缓存
2. 增加刷新间隔
增加刷新间隔有助于减少段数量,降低搜索的IO成本。
而且,一旦刷新发生并且数据发生变化,缓存就会失效。增加刷新间隔可以使Elasticsearch更有效地利用缓存
3. 辩证的看待增加副本数量对检索性能的影响
直接给出企业级测试结论——副本数对检索性能的影响非正相关。也就是说:不是副本越多,检索性能越高。
增加副本数量的优势:
负载均衡
分散查询请求负载,实现负载均衡。
2.高可用性
提高集群的可用性和容错能力。
3.并行处理
加快查询速度,提高吞吐量。
注意:增加副本数量会消耗额外的存储空间和计算资源。需根据需求和资源限制权衡副本数量。
4. 仅检索必要字段
如果文档很大,且仅需要几个字段,请使用stored_fields仅检索所需字段,而不是所有字段。
5. 避免通配符查询
通配符查询可能会很慢且耗资源。最好尽量避免使用它们。
替代方案:Ngram分词、设置 wildcard 数据类型。
6. 使用节点查询缓存
过滤器上下文中使用的查询结果将缓存在节点查询缓存中,以便快速查找。
过滤器上下文查询结果缓存的优势:
缓存命中率
过滤器查询具有较高的缓存命中率,常在多个查询中重复使用。
2.节省计算资源
缓存结果减少重复计算,节省资源。
3.提高查询速度
缓存加速查询,特别是复杂或数据量大的过滤器查询。
4.并发查询效果更好
节点查询缓存在高并发场景下发挥作用,提高性能。
注意:需平衡缓存使用与内存消耗。对于频繁变更或低缓存命中率的查询,缓存效果可能有限。
7. 使用分片查询缓存
可以通过将“index.requests.cache.enable”设置为true来启用分片查询缓存。
设置参考如下:
PUT /my-index-000001 {"settings": {"index.requests.cache.enable": false} }
8. 使用索引模板
索引模板可以帮助自动将设置和映射应用于新索引
使用索引模板的优势:
一致性
确保新索引具有相同的设置和映射,实现集群一致性。
2.简化操作
自动应用预定义的设置和映射,减少手动配置。
3.易于扩展
快速创建具有相同配置的新索引,便于集群扩展。
4.版本控制和更新
实现模板版本控制,确保新索引使用最新配置。
性能优化建议
1. 活动分片应与CPU成比例
活动分片=主分片+副本分片数之和。
活动分片与 CPU 成比例的原因:
并行处理
更多活动分片提高并行处理能力,加速查询和索引请求。与 CPU 核心数成比例确保充分利用 CPU 资源。
2. 避免资源竞争
将活动分片与 CPU 核心数成比例,避免多分片竞争同一 CPU 核心,提高性能。
3.负载均衡
成比例的活动分片数有助于在多节点间分散请求,避免单节点资源瓶颈。
4.性能优化
与 CPU 核心数成比例的分片数根据可用计算资源为分片分配处理能力,优化查询和索引操作。
注意:实际部署需考虑其他因素,如内存、磁盘和网络资源等。
如前所述,为了提高写入密集型用例的性能,应将刷新间隔增加到较大的值(例如,30秒),并增加主分片以将写请求分发到不同节点。对于读取密集型用例,增加副本分片以在副本之间平衡查询/搜索请求会有所帮助。
2. 如果查询具有日期范围 filter 过滤器,请按日期组织数据
对于日志或监控场景,按每日、每周或每月组织索引并按指定日期范围获取索引列表可以提高性能
Elasticsearch只需要查询较小的数据集,而不是整个数据集,而且在数据过期时缩小/删除旧索引会很容易。
负面案例:之前有客户超大规模(100TB)以上的数据没有日期格式字段或者出现字段格式不规范的问题。
3. 如果查询具有过滤字段且其值可枚举,则将数据分割成多个索引
如果我们的查询中包含可枚举的过滤字段(例如,地区),则可以通过将数据分割成多个索引来提高查询性能。
例如,如果数据包含来自美国、欧洲和其他地区的记录,并且经常使用“region”过滤查询,那么可以将数据分割成三个索引,每个索引包含一组地区的数据。
这样,当执行带有过滤子句“region”的查询时,Elasticsearch 只需要在包含该地区数据的索引中搜索,从而提高查询性能。
其他建议
1. 索引状态管理
定义自定义管理策略以自动执行常规任务,并将其应用于索引和索引模式。例如,可以定义一项策略,使索引在30天后进入只读状态,然后在90天后将其删除。
ILM(索引生命周期管理)是 Elasticsearch 的一项功能,可自动化索引的管理和维护,具有以下好处:
简化索引管理:自动化索引的生命周期管理,包括索引的创建、更新、删除和存档,减轻管理员的负担。
提高性能:自动优化索引设置,包括调整分片大小、缩小索引和删除过期数据等,有助于提高查询性能和减少存储空间的使用。
降低成本:自动归档和删除过期数据,降低存储成本,减少管理员的工作量和时间成本。
更好的可扩展性:根据需要自动调整索引设置和存储策略,使索引更好地适应不断增长和变化的数据。
使用 ILM 可以让索引管理变得更简单、更可靠。
干货 | Elasticsearch 索引生命周期管理 ILM 实战指南
Elasticsearch ILM 索引生命周期管理常见坑及避坑指南
2. 快照生命周期管理
SLM(快照生命周期管理)是 Elasticsearch 的一项功能,可自动化快照的管理和维护,具有以下好处:
简化快照管理:自动化快照的生命周期管理,包括创建、管理、删除和清理快照,减轻管理员的负担。
提高效率:自动化快照的创建、管理、删除和清理,提高管理效率。
减少存储成本:自动删除无用的快照,降低存储成本。
更好的可扩展性:根据需要自动调整快照设置和存储策略,使快照更好地适应不断增长和变化的数据。
使用 SLM 可以让快照管理变得更简单、更可靠,提高管理效率和降低存储成本。
3. 用好监控
为了监视Elasticsearch集群的性能并检测任何潜在问题,应该定期跟踪以下指标
集群健康状况节点和分片:监控集群中节点的数量以及分片及其分布。
搜索性能:请求延迟和速率 - 跟踪搜索请求的延迟以及每秒搜索请求的数量。
索引性能:刷新时间和合并时间 - 监控刷新索引所需的时间以及合并段所需的时间。
节点利用率:线程池 - 监控每个节点上线程池的使用情况,例如索引池。
总结
遵循这些最佳实践,可以确保Elasticsearch部署性能高、可靠且可扩展。
请记住,Elasticsearch是一个功能强大的搜索和分析引擎,可以快速并近乎实时地处理大量数据,但是要充分利用它,需要计划、优化和监控部署。
以上建议仅供参考,实操环节以 Elasticsearch 官方文档和自己集群的性能测试结论为准。没有普适的优化建议,只有适合自己的优化才是最好的优化。
相关文章:
Elasticsearch 8.X 性能优化参考 —— 筑梦之路
Elasticsearch 是实现用户无缝搜索体验的关键工具。它通过提供快速、准确和相关的搜索结果,彻底改变了用户与应用程序的互动方式。然而,要确保 Elasticsearch 部署达到最佳性能,就必须关注关键指标,并对诸如索引、缓存、查询、搜索…...

通过强化学习走直线理解基本概念
摘要: 一条线上包含起点和终点共有6个格子,起点在左终点在右。假设智能体已经学到了最优的策略,并且在每一步行动时,以 0.9 0.9 0.9 的概率选择最优策略(也就是往右),以 0.1 0.1 0.1 的概率选…...

Java字符流
5 字符流 5.1 为什么出现字符流 由于字节流操作中文不是特别的方便,所以Java就提供字符流字符流=字节流+编码表用字节流复制文本文件时,文本文件也会有中文,但是没有问题,原因是最终底层操作会自动进行字节拼接成中文,如何识别是中文的呢? 汉字在存储的时候, 无论选择哪…...

2023年上半年信息系统项目管理师上午真题及答案解析
1.“新型基础设施”主要包括信息技术设施、融合基础设施和创新基础设施三个方面。其中信息基础设施包括( )。 ①通信基础设施 ②智能交通基础设施 ③新技术基础设施 ④科教基础设施 ⑤算力基础设施 A.①③⑤ B.①④⑤ C.②③④ D.②…...

LeetCode 739 每日温度
题目: 给定一个整数数组 temperatures ,表示每天的温度,返回一个数组 answer ,其中 answer[i] 是指对于第 i 天,下一个更高温度出现在几天后。如果气温在这之后都不会升高,请在该位置用 0 来代替。 示例 1…...
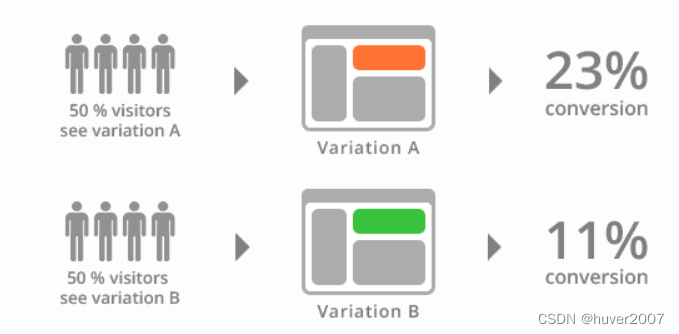
介绍几种常见的运维发布策略
随着Devops的发展,为了提高运维发布的成功率,探索出了多种发布策略。本文简单介绍几种常见发布策略, 以及它们适用的场景和优缺点。 第一种,停机发布 这是最早的一种发布策略,停机发布会在发布以前关闭服务,停止用户…...

C++ QT QDBus进阶用法。
以下是使用QDBus的高级用法示例代码: 1. 使用DBus的异步调用机制: #include <QCoreApplication> #include <QDebug> #include <QDBusConnection> #include <QDBusPendingCallWatcher> class MyDBusObject : public QObject …...
)
2023-5-26 LeetCode每日一题(二进制矩阵中的最短路径)
2023-05-29每日一题 一、题目编号 1091. 二进制矩阵中的最短路径二、题目链接 点击跳转到题目位置 三、题目描述 给你一个 n x n 的二进制矩阵 grid 中,返回矩阵中最短 畅通路径 的长度。如果不存在这样的路径,返回 -1 。 二进制矩阵中的 畅通路径…...

博客系统后端设计(七) - 实现显示用户信息与注销功能
文章目录 1. 显示用户信息1.1 约定前后端交互接口1.2 修改列表页的前段代码1.3 实现详情页的后端代码1.4 实现详情页的前端代码 2. 注销2.1 确定前后端交互接口2.2 实现后端代码2.3 修改前端代码 1. 显示用户信息 此处的用户名是写死的,我们希望的是此处是能够动态生…...
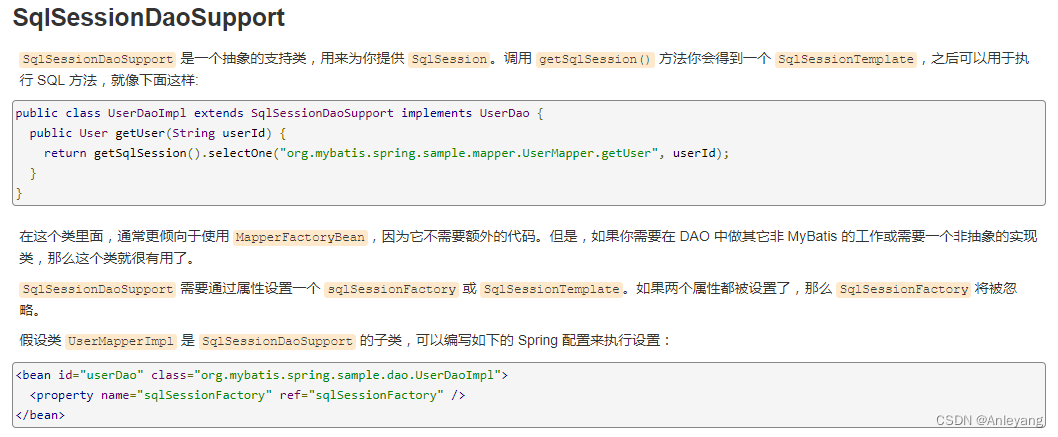
Spring5 学习笔记
前置知识: 掌握Java基础知识(特别是反射)掌握Java注解掌握XML掌握Maven Spring5学习笔记 1、Spring概述1.1、简介1.2、优点1.3、组成1.4、拓展 2、IOC理论推导2.1、分析实现2.2、IOC本质 3、HelloSpring3.1、导入jar包3.2、编写代码3.3、思考…...

leetcode--分隔链表(java)
分割链表 leetcode 86 分割链表 (中等)解题思路:链表专题 leetcode 86 分割链表 (中等) leetcode 86 分割链表 原题链接,可以直接测试 给你一个链表的头节点 head 和一个特定值 x ,请你对链表进…...

使用 AD8232 ECG 传感器和 ESP32 进行基于物联网的 ECG 监测
这篇文章是使用 AD8232 ECG 传感器和 ESP32 进行基于物联网的 ECG 监测。可以从世界任何地方在线观察来自患者心脏的心电图信号。 目录 概述 什么是心电图? 心电图的医疗用途 AD8232 心电图传感器...

【Linux初阶】基础IO - 文件操作(使用系统接口实现) | vim批量注释代码
🌟hello,各位读者大大们你们好呀🌟 🍭🍭系列专栏:【Linux初阶】 ✒️✒️本篇内容:重新理解文件和文件操作,C语言实现的简单文件操作,文本初始权限,系统接口介…...

网络安全之信息收集
第一部分:被动信息收集 1、简介 在信息收集这块区域,我将其分为两部分:第一部分即被动信息收集,第二部分即主动信息收集。 对于标准的渗透测试人员来说,当明确目标做好规划之后首先应当进行的便是信息收…...

ModuleNotFoundError: No module named ‘_lzma‘
安装torchvision报错:ModuleNotFoundError: No module named ‘_lzma’ 参考文章:https://zhuanlan.zhihu.com/p/404162713 解决思路:用backports.lzma代替_lzma包 解决步骤:(ubuntu系统) 安装依赖sudo apt-get install liblzma-d…...

标点符号相关的英语单词
Comma - 逗号 Period - 句号 Question mark - 问号 Exclamation mark - 感叹号 Semicolon - 分号 Colon - 冒号 Quotation marks - 引号 Parentheses - 括号 Brackets - 方括号 Hyphen - 连字符 Dash - 破折号 Ellipsis - 省略号 Apostrophe - 省略符号 Slash - 斜杠 Backslash…...

MyBatis的部分知识点
一、resultMap的constructor配置方式 <resultMap id"" type""> <constructor> <!--主键--> <idArg column"id" javaType"_int"/> <!--其他列--> …...

PAT A1089 Insert or Merge
1089 Insert or Merge 分数 25 作者 CHEN, Yue 单位 浙江大学 According to Wikipedia: Insertion sort iterates, consuming one input element each repetition, and growing a sorted output list. Each iteration, insertion sort removes one element from the input…...
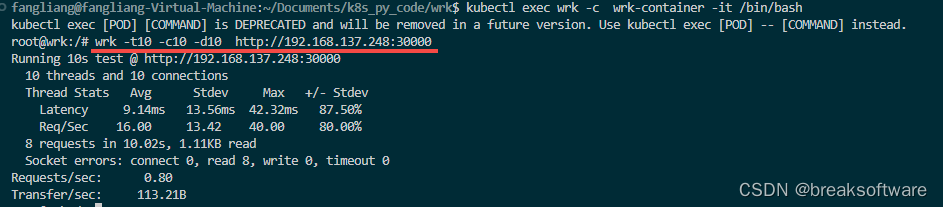
研发工程师玩转Kubernetes——创建一个测试容器
测试容器并不是什么都没有的容器,只是它没有我们期望的常驻进程。我们常用它来做一些测试。 举个例子,在《研发工程师玩转Kubernetes——自动扩缩容》中我们使用本地wrk进行了压力测试。如果我们希望进入容器手工调用wrk,该怎么做呢ÿ…...
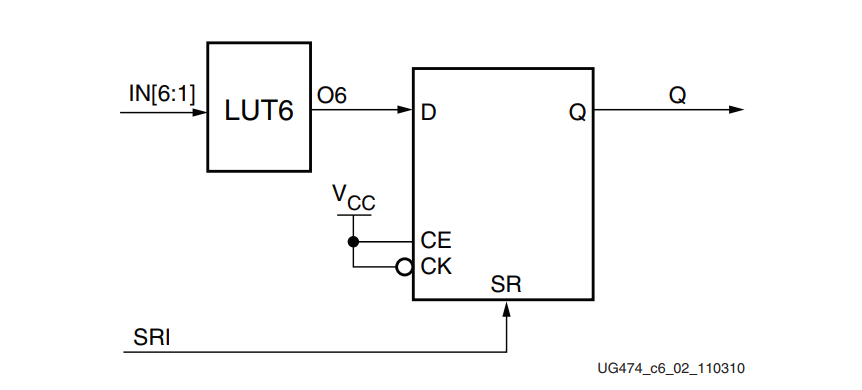
FPGA - 7系列 FPGA内部结构之CLB -03- CLB相关原语以及应用
前言 本文节选UG474的第二章,进行整理翻译。CLB资源被FPGA综合工具自动有效地使用,不需要任何特殊的FPGA专用编码。一些HDL编码建议和技术可以帮助优化设计以获得最大效率。 设计检查清单 这些指南是为有效使用7系列CLB的设计建议提供的快速核对表。7…...

Splunk紧急推送安全补丁:三枚高危漏洞同时曝光,企业数据面临泄露与瘫痪双重风险
2026年5月20日,Splunk官方安全团队一次性披露了旗下多款核心产品的重大安全隐患。此次波及范围相当广泛,从本地部署的Splunk Enterprise到云端服务Splunk Cloud Platform,再到新推出的Splunk AI Toolkit,无一幸免。三枚漏洞编号分…...

处理跨时区订单与日志?LocalDateTime时区转换与序列化的避坑指南
跨时区业务中的LocalDateTime实战:从订单处理到日志存储的全链路解决方案 凌晨三点,东京用户的订单触发了系统告警,而纽约团队查看日志时却发现时间对不上——这是许多全球化业务开发者常见的噩梦。时区问题如同暗礁,往往在系统运…...

Python数据分析入门 - BV1xX4y1Z7Y8
Python数据分析入门 - BV1xX4y1Z7Y8 【免费下载链接】BiliTools A cross-platform bilibili toolbox. 跨平台哔哩哔哩工具箱,支持下载视频、番剧等等各类资源 项目地址: https://gitcode.com/GitHub_Trending/bilit/BiliTools 本视频主要介绍Python数据分析的…...
)
人机协作新范式:高效论文写作全流程AI论文平台推荐(2026 最新)
2026年AI论文平台持续升级,论文写作全流程可拆解为文献调研→选题/开题→大纲/初稿→文献综述→降重/去AI味→润色/格式→查重/投稿七大环节,以下工具按环节精准匹配,兼顾中文适配、降重能力、去AI痕迹、学术合规四大核心需求,覆盖…...

【麒麟桌面系统】V10-SP1 2503 系统知识——常见日志文件及其作用
提示:分享麒麟桌面操作系统 V10 SP1 2503 ( Kylin-Desktop-V10-SP1 2503 )常见日志文件及其作用。 一、现象描述现象描述:在银河麒麟桌面操作系统使用过程中,若出现操作系统故障,需要查询日志排查具体原因&…...

二刷hot100-226.翻转二叉树
还是用层序遍历,内存循环在将左右节点入队后,置换左右节点:/*** Definition for a binary tree node.* public class TreeNode {* int val;* TreeNode left;* TreeNode right;* TreeNode() {}* TreeNode(int val) { this…...

如何快速构建数学可视化:Manim交互式开发完整教程
如何快速构建数学可视化:Manim交互式开发完整教程 【免费下载链接】manim Animation engine for explanatory math videos 项目地址: https://gitcode.com/GitHub_Trending/ma/manim 想要告别数学动画制作中反复修改代码、重新渲染的烦恼吗?&…...

ADAS系统设计全解析:从传感器融合到域控制器实战
1. 项目概述与行业背景最近几年,但凡和汽车沾点边的行业,都绕不开“智能化”这三个字。作为一名在汽车电子和嵌入式系统领域摸爬滚打了十多年的工程师,我亲眼见证了从简单的倒车雷达,到如今能自动跟车、紧急刹车的ADAS系统&#x…...

Cursor Free VIP终极指南:5步实现AI编程助手永久免费使用
Cursor Free VIP终极指南:5步实现AI编程助手永久免费使用 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your …...

使用 Python 和 Taotoken 官方风格 SDK 实现你的第一个 AI 对话应用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用 Python 和 Taotoken 官方风格 SDK 实现你的第一个 AI 对话应用 对于刚开始接触大模型应用开发的 Python 程序员来说ÿ…...