昇腾CANN算子开发揭秘
开发者在利用昇腾硬件进行神经网络模型训练或者推理的过程中,可能会遇到以下场景:
1、训练场景下,将第三方框架(例如TensorFlow、PyTorch等)的网络训练脚本迁移到昇腾AI处理器时遇到了不支持的算子。
2、推理场景下,将第三方框架模型(例如TensorFlow、Caffe、ONNX等)使用ATC工具转换为适配昇腾AI处理器的离线模型时遇到了不支持的算子。
3、网络调优时,发现某算子性能较低,影响网络性能,需要重新开发一个高性能算子替换性能较低的算子。
4、推理场景下,应用程序中的某些逻辑涉及到数学运算(例如查找最大值,进行数据类型转换等),希望通过自定义算子的方式实现这些逻辑,从而获得性能提升。
此时我们就需要考虑进行自定义算子的开发,本期我们主要带您了解CANN自定义算子的几种开发方式和基本开发流程,让您对CANN算子有宏观的了解。
一、算子基本概念
相信大家对算子的概念并不陌生,这里我们来做简单回顾。深度学习算法由一个个计算单元组成,我们称这些计算单元为算子(Operator,简称OP)。
在网络模型中,算子对应层中的计算逻辑,例如:卷积层(Convolution Layer)是一个算子;全连接层(Fully-connected Layer, FC layer)中的权值求和过程,是一个算子。
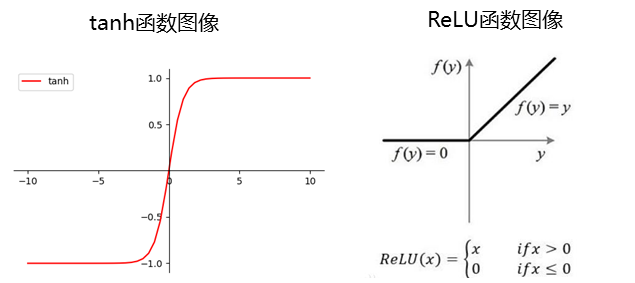
再例如:tanh、ReLU等,为在网络模型中被用做激活函数的算子。
二、CANN自定义算子开发方式
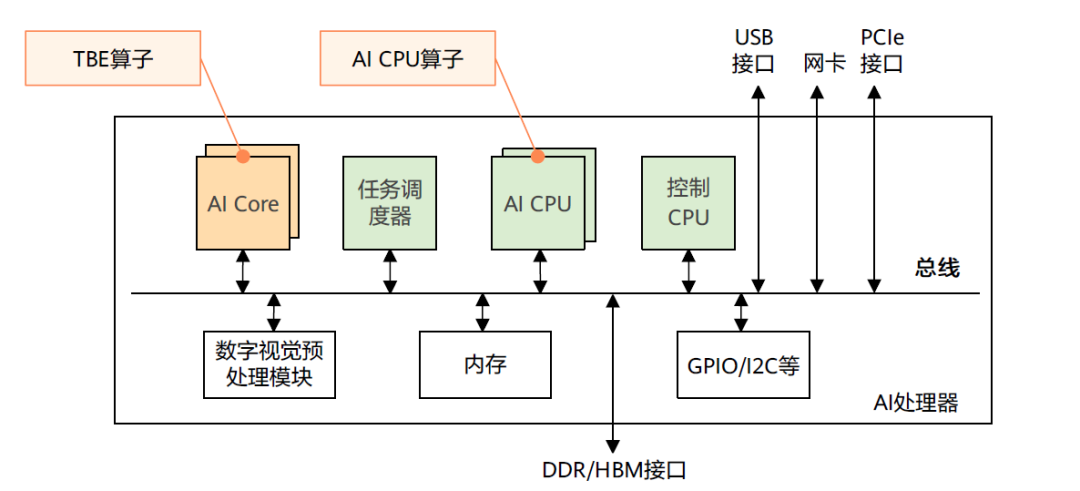
学习CANN自定义算子开发方式之前,我们先来了解一下CANN算子的运行位置:包括AI Core和AI CPU。
AI Core是昇腾AI处理器的计算核心,负责执行矩阵、向量、标量计算密集的算子任务。
AI CPU负责执行不适合跑在AI Core上的算子,是AI Core算子的补充,主要承担非矩阵类、逻辑比较复杂的分支密集型计算。
CANN支持用户使用多种方式来开发自定义算子,包括TBE DSL、TBE TIK、AICPU三种开发方式。其中TBE DSL、TBE TIK算子运行在AI Core上,AI CPU算子运行在AI CPU上。
1、基于TBE开发框架的算子开发
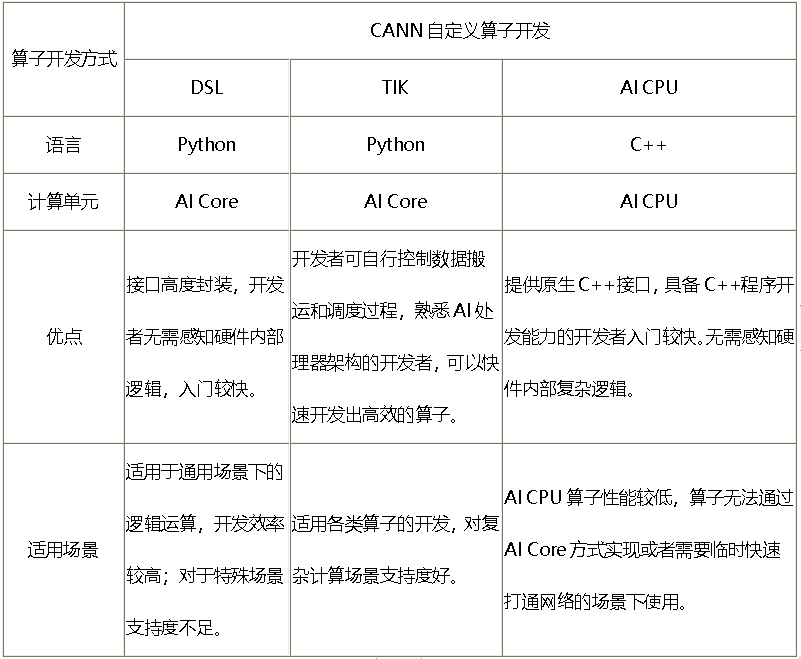
TBE(Tensor Boost Engine:张量加速引擎)是CANN提供的算子开发框架,开发者可以基于此框架使用Python语言开发自定义算子,通过TBE进行算子开发有TBE DSL、TBE TIK两种方式。
TBE DSL(Domain-Specific Language ,基于特性域语言)开发方式
为了方便开发者进行自定义算子开发,CANN预先提供一些常用运算的调度,封装成一个个运算接口,称为基于TBE DSL开发。DSL接口已高度封装,用户仅需要使用DSL接口完成计算过程的表达,后续的算子调度、算子优化及编译都可通过已有的接口一键式完成,适合初级开发用户。
TBE TIK(Tensor Iterator Kernel)开发方式
TIK(Tensor Iterator Kernel)是一种基于Python语言的动态编程框架,呈现为一个Python模块,运行于Host CPU上。开发者可以通过调用TIK提供的API基于Python语言编写自定义算子,TIK编译器会将其编译为昇腾AI处理器应用程序的二进制文件。
TIK需要用户手工控制数据搬运和计算流程,入门较高,但开发方式比较灵活,能够充分挖掘硬件能力,在性能上有一定的优势。
2、AI CPU算子开发方式
AI CPU算子的开发接口即为原生C++接口,具备C++程序开发能力的开发者能够较容易的开发出AI CPU算子。AI CPU算子在AI CPU上运行。
下面的开发方式一览表,对上述几种开发方式作对比说明,您可以根据各种开发方式的适用场景选择适合的开发方式。
三、CANN算子编译运行
算子构成
一个完整的CANN算子包含四部分:算子原型定义、对应开源框架的算子适配插件、算子信息库和算子实现。这四个组成部分会在算子编译运行的过程中使用。

算子编译
推理场景下,进行模型推理前,我们需要使用ATC模型转换工具将原始网络模型转换为适配昇腾AI处理器的离线模型,该过程中会对网络中的算子进行编译。
训练场景下,当我们跑训练脚本时,CANN内部实现逻辑会先将开源框架网络模型下发给Graph Engine进行图编译,该过程中会对网络中的算子进行编译。
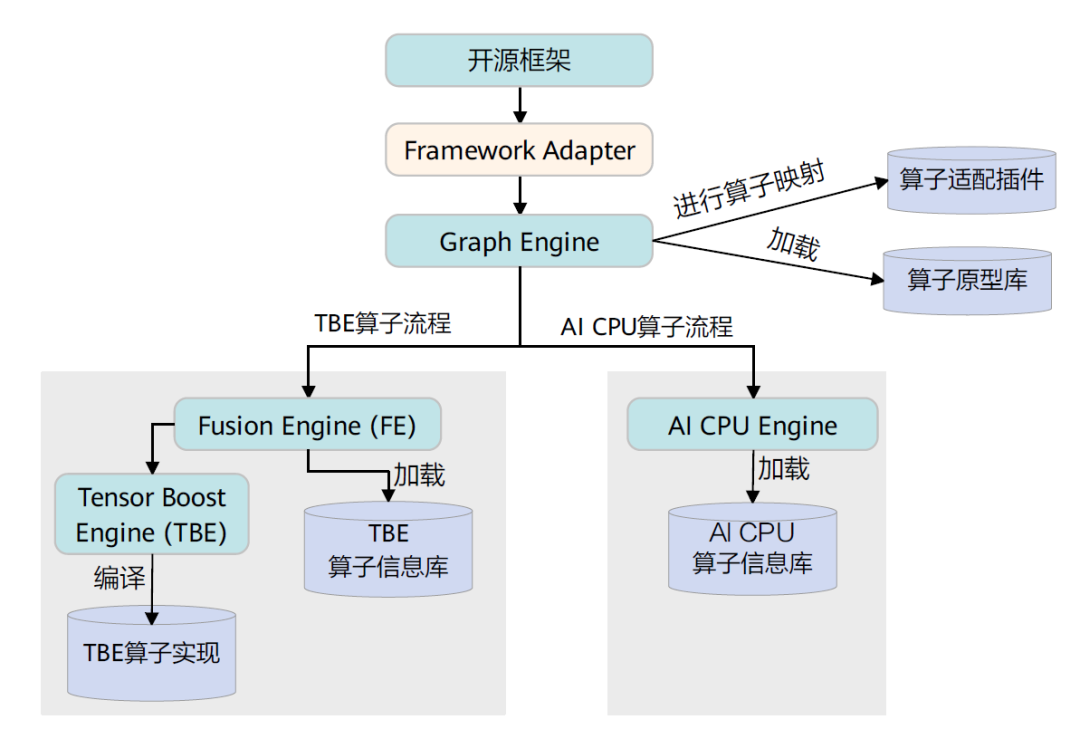
CANN算子的编译逻辑架构如下:
具体的CANN算子编译流程如下,在编译流程中会用到上文提到的算子的四个组成部分。
Graph Engine调用算子插件,将原始网络模型中的算子映射为适配昇腾AI处理器的算子,从而将原始开源框架图解析为适配昇腾AI处理器的图。
调用算子原型库校验接口进行基本参数的校验,校验通过后,会根据原型库中的推导函数推导每个节点的输出shape与dtype,进行输出tensor的静态内存的分配。
Graph Engine根据图中数据将图拆分为子图并下发给FE。FE在处理过程中根据算子信息库中算子信息找到算子实现,将其编译成算子kernel,最后将优化后子图返回给Graph Engine。
Graph Engine进行图编译,包含内存分配、流资源分配等,并向FE发送tasking请求,FE返回算子的taskinfo信息给Graph Engine,图编译完成后生成适配昇腾AI处理器的模型。
算子运行
推理场景下,使用ATC模型转换工具将原始网络模型转换为适配昇腾AI处理器的离线模型后,开发AscendCL应用程序,加载转换好的离线模型文件进行模型推理,该过程中会进行算子的调用执行。
训练场景下,当我们跑训练脚本时,内部实现逻辑将开源框架网络模型下发给Graph Engine进行图编译后,后续的训练流程会进行算子的调用执行。
CANN算子的运行逻辑架构如下:
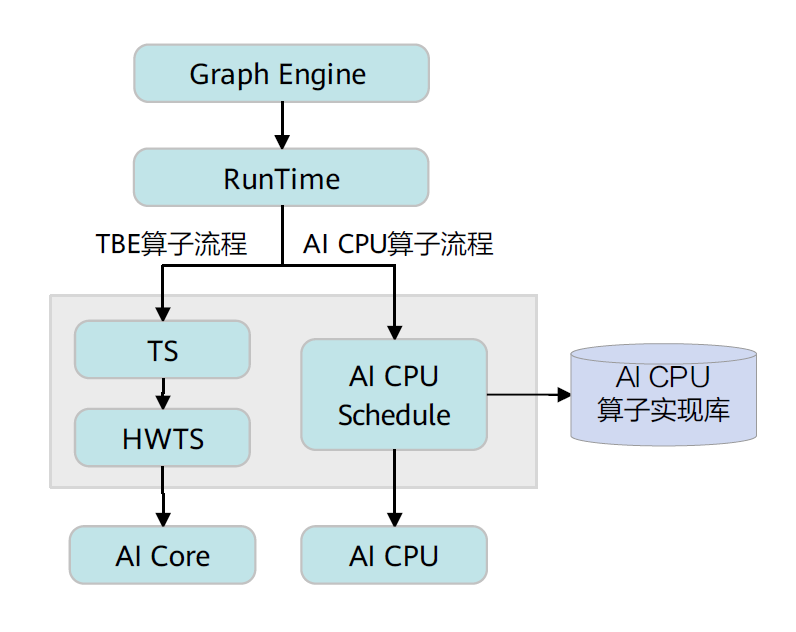
具体流程如下,首先Graph Engine下发算子执行请求给Runtime,然后Runtime会判断算子的Task类型,若是TBE算子,则将算子执行请求下发到AI Core上执行;若是AI CPU算子,则将算子执行请求下发到AI CPU上执行。
四、算子开发流程
本章节以通过DSL开发方式开发一个Add算子为例,带您快速体验CANN算子开发的流程。流程图如下:
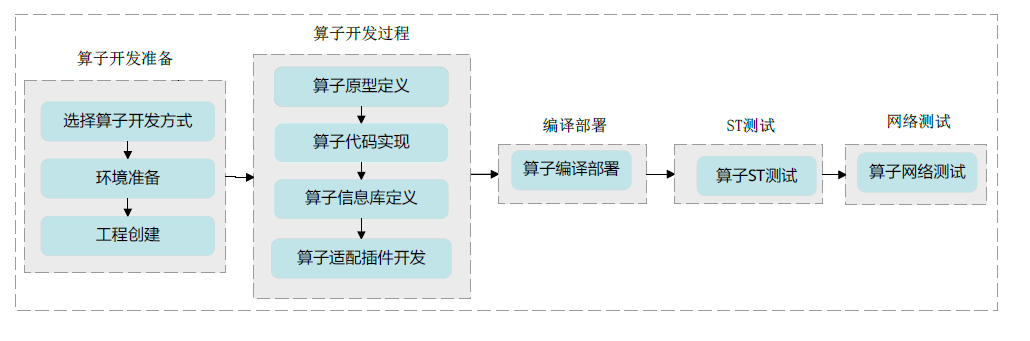
1、算子开发准备
环境准备:准备算子开发及运行验证所依赖的开发环境与运行环境。
工程创建:创建算子开发工程,有以下几种实现方式:
基于MindStudio工具进行算子开发,直接使用MindStudio工具创建算子工程,会自动生成算子工程及代码模板。
基于msopgen工具进行开发,会自动生成算子工程及代码模板。
基于自定义算子样例工程进行开发,开发者需要自己创建算子相关实现文件,或者基于已有样例进行修改。
下面以msopgen工具创建算子开发工程为例进行介绍:
定义AddDSL算子的原型定义json文件,用于生成AddDSL的算子开发工程。例如,定义的json文件的名字为add_dsl.json,存储路径为:$HOME/sample,文件内容如下:
[
{ "op":"AddDSL", "input_desc":[ { "name":"x1", "param_type":"required", "format":[ "NCHW" ], "type":[ "fp16" ] }, { "name":"x2", "param_type":"required", "format":[ "NCHW" ], "type":[ "fp16" ] } ], "output_desc":[ { "name":"y", "param_type":"required", "format":[ "NCHW" ], "type":[ "fp16" ] } ]
}
]使用msopgen工具生成AddDSL算子的开发工程。
$HOME/Ascend/ascend-toolkit/latest/python/site-packages/bin/msopgen gen -i $HOME/sample/add_dsl.json -f tf -c ai_core-Ascend310 -out $HOME/sample/AddDsl“$HOME/Ascend”为CANN软件安装目录;“-f tf”参数代表选择的原始框架为TensorFlow;“ai_core-<soc_version>”代表算子在AI Core上运行,芯片类型为<soc_version>。
此命令执行完后,会在$HOME/sample/AddDsl目录下生成算子工程,工程中包含各交付件的模板文件,编译脚本等,如下所示:
AddDsl
├── build.sh // 编译入口脚本
├── cmake // 编译解析脚本存放目录
├── CMakeLists.txt
├── framework // 算子适配插件相关文件存放目录
│ ├── CMakeLists.txt
│ └── tf_plugin
│ ├── CMakeLists.txt
│ └── tensorflow_add_dsl_plugin.cc // 算子适配插件实现文件
├── op_proto // 算子原型定义相关文件存放目录
│ ├── add_dsl.cc
│ ├── add_dsl.h
│ └── CMakeLists.txt
├── op_tiling
│ └── CMakeLists.txt
├── scripts // 自定义算子工程打包脚本存放目录
└── tbe ├── CMakeLists.txt ├── impl // 算子代码实现 │ └── add_dsl.py └── op_info_cfg // 算子信息库存放目录 └── ai_core └── <soc_version> └── add_dsl.ini2、算子开发过程
实现AddDSL算子的原型定义
算子原型定义文件包含算子注册代码的头文件(*.h)以及实现基本校验、Shape推导的实现文件(*.cc)。
msopgen工具根据add_dsl.json文件在“op_proto/add_dsl.h”中生成了算子注册代码,开发者需要检查自动生成的代码逻辑是否正确,一般无需修改。
修改“op_proto/add_dsl.cc”文件,实现算子的输出描述推导函数及校验函数。在IMPLEMT_COMMON_INFERFUNC(AddDSLInferShape)函数中,填充推导输出描述的代码,针对AddDSL算子,输出Tensor的描述信息与输入Tensor的描述信息相同,所以直接将任意一个输入Tensor的描述赋给输出Tensor即可。
IMPLEMT_COMMON_INFERFUNC(AddDSLInferShape)
{
// 获取输出数据描述 TensorDesc tensordesc_output = op.GetOutputDescByName("y");
tensordesc_output.SetShape(op.GetInputDescByName("x1").GetShape()); tensordesc_output.SetDataType(op.GetInputDescByName("x1").GetDataType()); tensordesc_output.SetFormat(op.GetInputDescByName("x1").GetFormat());
//直接将输入x1的Tensor描述信息赋给输出 (void)op.UpdateOutputDesc("y", tensordesc_output);
return GRAPH_SUCCESS;
}IMPLEMT_VERIFIER(AddDSL, AddDSLVerify)函数中,填充算子参数校验代码。
IMPLEMT_VERIFIER(AddDSL, AddDSLVerify)
{
// 校验算子的两个输入的数据类型是否一致,若不一致,则返回失败。
if (op.GetInputDescByName("x1").GetDataType() != op.GetInputDescByName("x2").GetDataType()) {
return GRAPH_FAILED; }
return GRAPH_SUCCESS;
}实现AddDSL算子的计算逻辑
“tbe/impl/add_dsl.py”文件中已经自动生成了算子代码的框架,开发者需要在此文件中修改add_dsl_compute函数,实现此算子的计算逻辑。
add_dsl_compute函数的实现代码如下:
@register_op_compute("add_dsl")
def add_dsl_compute(x1, x2, y, kernel_name="add_dsl"):
# 调用dsl的vadd计算接口 res = tbe.vadd(x1, x2)
return res配置算子信息库
算子信息库包含了算子的类型,输入输出的名称、数据类型、数据排布格式等信息,msopgen工具已经根据add_dsl.json文件将上述内容自动填充,开发者无需修改。
算子信息库的路径为:
“tbe/op_info_cfg/ai_core/<soc_version>/add_dsl.ini”
AddDSL算子的信息库如下:
[AddDSL] // 算子的类型
input0.name=x1 // 第一个输入的名称
input0.dtype=float16 // 第一个输入的数据类型
input0.paramType=required // 代表此输入必选,且仅有一个
input0.format=NCHW // 第一个输入的数据排布格式
input1.name=x2 // 第二个输入的名称
input1.dtype=float16 // 第二个输入的数据类型
input1.paramType=required // 代表此输入必选,且仅有一个
input1.format=NCHW // 第二个输入的数据排布格式
output0.name=y // 算子输出的名称
output0.dtype=float16 // 算子输出的数据类型
output0.paramType=required // 代表此输出必选,有且仅有一个
output0.format=NCHW // 算子输出的数据排布格式
opFile.value=add_dsl // 算子实现文件的名称
opInterface.value=add_dsl // 算子实现函数的名称实现算子适配插件
算子适配插件实现文件的路径为:
“framework/tf_plugin/tensorflow_add_dsl_plugin.cc”
针对原始框架为TensorFlow的算子,CANN提供了自动解析映射接口“AutoMappingByOpFn”,如下所示:
#include"register/register.h"namespace domi { // register op info to GE REGISTER_CUSTOM_OP("AddDSL") // CANN算子的类型 .FrameworkType(TENSORFLOW) // type: CAFFE, TENSORFLOW .OriginOpType("AddDSL") // 原始框架模型中的算子类型 .ParseParamsByOperatorFn(AutoMappingByOpFn); //解析映射函数 } // namespace domi以上为工程自动生成的代码,开发者仅需要修改.OriginOpType("AddDSL")中的算子类型即可。此处我们仅展示算子开发流程,不涉及原始模型,我们不做任何修改。至此,AddDSL算子的所有交付件都已开发完毕。
3、算子工程编译及算子包部署
算子开发过程完成后,需要编译自定义算子工程,生成自定义算子安装包并进行自定义算子包的安装,将自定义算子部署到算子库。
算子工程编译
修改build.sh脚本,配置编译所需环境变量
将build.sh中环境变量ASCEND_TENSOR_COMPILER_INCLUDE配置为CANN软件头文件所在路径。
修改前,环境变量配置的原有代码行如下:
# export ASCEND_TENSOR_COMPILER_INCLUDE=/usr/local/Ascend/ascend-toolkit/latest/compiler/includ修改后,新的代码行如下:
export ASCEND_TENSOR_COMPILER_INCLUDE=${INSTALL_DIR}/include${INSTALL_DIR}请替换为CANN软件安装后文件存储路径。例如,若安装的Ascend-cann-toolkit软件包,则安装后文件存储路径为:$HOME/Ascend/ascend-toolkit/latest。
在算子工程目录下执行如下命令,进行算子工程编译
./build.sh
编译成功后,会在当前目录下创建build_out目录,并在build_out目录下生成自定义算子安装包。
自定义算子安装包部署
以运行用户执行如下命令,安装自定义算子包。
./custom_opp_<target os>_<target architecture>.run命令执行成功后,自定义算子包中的相关文件部署到CANN算子库中。
4、算子运行验证
算子包部署完成后,可以进行ST测试(System Test)和网络测试,对算子进行运行验证。
ST测试
ST测试的主要功能是:基于算子测试用例定义文件*.json生成单算子的om文件;使用AscendCL接口加载并执行单算子om文件,验证算子执行结果的正确性。ST测试会覆盖算子实现文件,算子原型定义与算子信息库,不会对算子适配插件进行测试。
网络测试
你可以将算子加载到网络模型中进行整网的推理验证,验证自定义算子在网络中运行结果是否正确。网络测试会覆盖算子开发的所有交付件,包含实现文件,算子原型定义、算子信息库以及算子适配插件。
具体的验证过程请参考“昇腾文档中心[1]”。
以上就是CANN自定义算子开发的相关知识点,您也可以在“昇腾社区在线课程[2]”板块学习视频课程,学习过程中的任何疑问,都可以在“昇腾论坛[3]”互动交流!
相关文章:
昇腾CANN算子开发揭秘
开发者在利用昇腾硬件进行神经网络模型训练或者推理的过程中,可能会遇到以下场景:1、训练场景下,将第三方框架(例如TensorFlow、PyTorch等)的网络训练脚本迁移到昇腾AI处理器时遇到了不支持的算子。2、推理场景下&…...

华为OD机试注意事项,备考思路,刷题要点,答疑,od Base 提供
华为 OD 机试是华为公司用于招聘岗位的一种在线编程测试,通常要求应聘者在规定的时间内完成一定数量的编程题目,以测试其编程能力和解决问题的能力。 本篇博客就华为 OD 机试注意事项,备考思路,刷题要点,答疑为大家一一…...
Python 自己简单地造一个轮子.whl文件
造轮子引言准备文件原始文件打包轮子文件运行验证引言 平时使用的python第三方库很顺手,这第三方库一般都是大家一起努力的结果,那我们是不是也可以贡献一点力量呢?首先从造一个本地的.whl文件开始。 在python中,引用第三方库时…...
NVIDIA Tesla V100部署与使用
在先前的实验过程中,使用了腾讯云提供的nvidia T4GPU,尽管其性能较博主的笔记本有了极大提升,但总感觉仍有些美中不足,因此本次博主租赁了nvidia V100 GPU,看看它的性能表现如何。 和先前一样,只需要将服务…...

网络知识点梳理与总结
作者简介:一名云计算网络运维人员、每天分享网络与运维的技术与干货。 座右铭:低头赶路,敬事如仪 个人主页:网络豆的主页 目录 前言 一.知识点梳理 前言 本章将会对高级网络应用一些知识点进行梳理。 一.知识点梳理 1.单臂的缺陷有哪些?...

我工作5年测试才8K,应届生刚毕业就拿16K?凭什么
我从事手工测试五年了,还拿着8K的死工资,家里还几张嘴需要喂养,我很累,也很迷茫…【某个粉丝跟我的诉说】 为什么手工测试会迷茫呢? 自动化测试、性能测试倒是不会迷茫。 我认为手工测试的迷茫基于两个原因…...
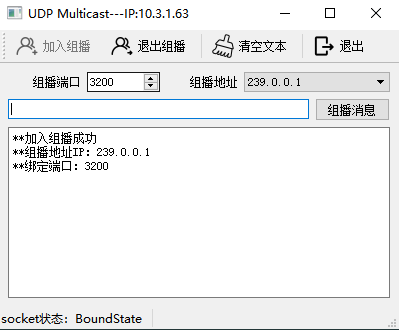
【QT】UDP通信QUdpSocket(单播、广播、组播)
目录1. UDP通信概述2. UDP消息传送的三种模式3. QUdpSocket类的接口函数4. UDP单播和广播代码示例4.1 测试说明4.2 MainWindow.h4.3 MainWindow.cpp4.4 界面展示5. UDP组播代码示例5.1 组播的特性5.2 MainWindow.h5.3 MainWindow.cpp5.4 界面展示1. UDP通信概述 UDP是无连接、…...
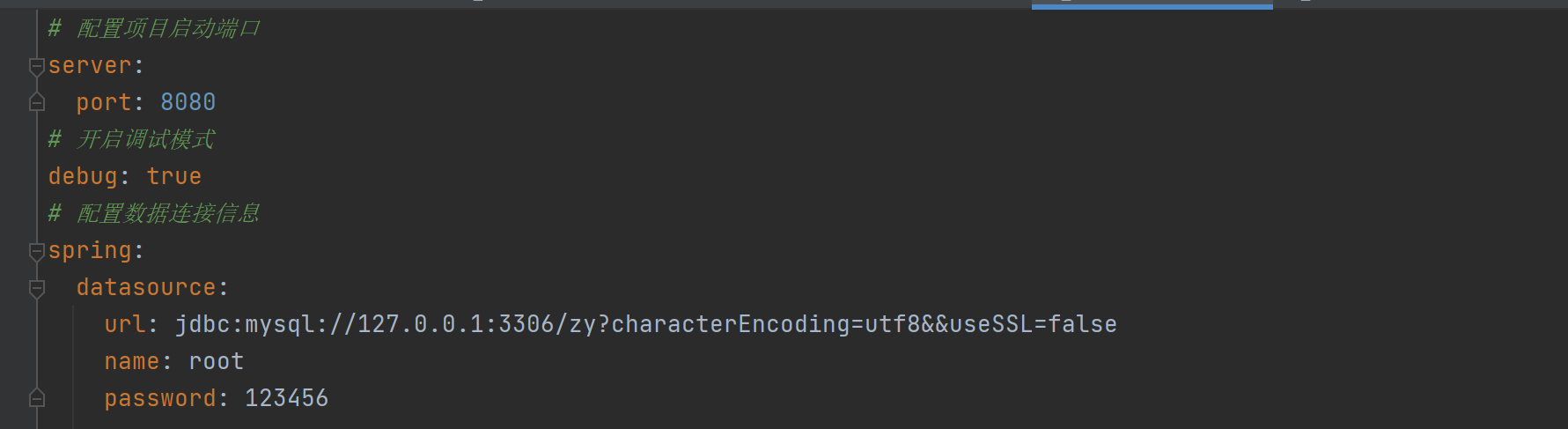
【Java】properties 和 yml 的区别
文章目录properties和yml的区别① 定义和定位不同② 语法不同③ yml更好的配置多种数据类型④ yml可以跨语言⑤ 总结properties和yml的区别 这几天刚好看到Spring Boot当中有两种配置文件的方式,但是这两种配置方式有什么区别呢? properties和yml都是S…...
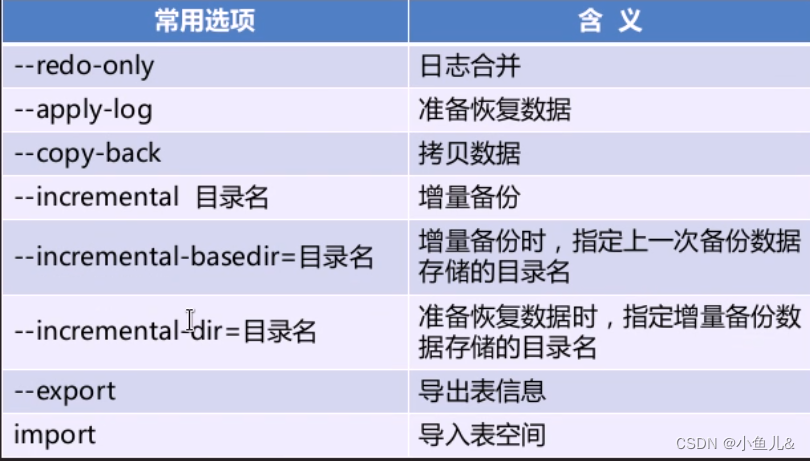
percona软件介绍 、 innobackupex备份与恢复
1. 常用的mysql备份工具 物理备份缺点: 跨平台差。备份时间长、冗余备份、浪费存储空间。 解释如下:如Linux操作系统和Windows操作系统之间,由于文件系统不一样,如Linux操作系统的文件系统是ext4、xfs,Windows操作系统…...
Towards Adversarial Attack on Vision-Language Pre-training Models
摘要虽然视觉-语言预训练模型(VLP)在各种视觉-语言(VL)任务上表现出革命性的改进,但关于其对抗鲁棒性的研究在很大程度上仍未被探索。本文研究了常用VLP模型和VL任务的对抗性攻击。首先,我们分析了不同设置下对抗性攻击的性能。通过研究不同扰动对象和攻…...

2022年最新数据库调查报告:超八成DBA月薪过万,你拖后腿了吗?
数据库管理员属于IT行业高薪职业的一种,近几年关于数据库管理员的薪资统计文章也层出不穷,那么当前,DBA们的薪资究竟到达了怎样的水平呢?墨天轮数据社区发布最新《2022年墨天轮数据库大调查报告》,数据显示超八成DBA月…...
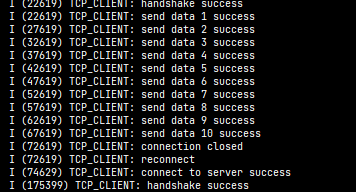
ESP-C3入门10. 创建TCP Client
ESP-C3入门10. 创建TCP Client一、创建 tcp client的一般步骤1. 创建 tcp 套接字2. 配置服务器地址3. 连接服务器4. 发送数据5. 接收数据6. 关闭套接字二、创建tcp_client任务三、示例代码1. tcpClient.h2. tcpClient.c3. main.c一、创建 tcp client的一般步骤 本文示例使用的…...

【Vue】浅谈vue2、vue3响应式原理,vue中数组的响应式,响应式常见问题分析
前言:此处响应式指的是数据响应式变化,而不是页面的响应式布局,页面的响应式布局在我的其他文章中有提到。 一、什么是vue响应式 Vue 最标志性的功能就是其低侵入性的响应式系统。组件状态都是由响应式的 JavaScript 对象组成的。当更改它们…...

股航顶峰先锋一号
{选股} TT:MA(C,30)>MA(C,60) AND MA(C,60)>MA(C,120);{均线多头} DD:C>REF(C,1);{收阳线} QQ:V>REF(V,1);{放量}; TT1:COUNT(L<MA(C,13),5)1; TT2:(C-REF(C,1))/REF(C,1)*100>3; DD1:V>REF(V,1)*2 AND C>REF(C,1); DD2:TT1 AND 0<MA(C,13)AND TT2 …...

MYSQL安装部署--Linux 仓库安装
声明 :# 此次我们安装的 MYSQL 版本是 8.0.32 版本 我们本次安装 MYSQL 总共要介绍 四种方式 # 仓库安装# 本地安装# 容器安装# 源码安装我们本篇介绍的是 仓库安装 仓库安装 下载 MYSQL 安装包 # MYSQL 安装,我们都是基于 MYSQL 官方网站里进行下载~&a…...

NFS服务器搭建
NFS服务器搭建1. NFS简介2. NFS工作原理3. 配置NFS服务端3.1 启动服务3.2 修改配置文件4. 配置NFS客户端1. NFS简介 NFS是Network File System的简写,即网络文件系统. 网络文件系统是FreeBSD支持的文件系统中的一种,也被称为NFS。 NFS允许一个系统在网络上与他人共…...
【数据挖掘实战】——航空公司客户价值分析(K-Means聚类案例)
目录 一、背景和挖掘目标 1、RFM模型缺点分析 2、原始数据情况 3、挖掘目标 二、分析方法与过程 1、初步分析:提出适用航空公司的LRFMC模型 2、总体流程 第一步:数据抽取 第二步:探索性分析 第三步:数据预处理 第四步&…...

AnlogicFPGA-IO引脚约束设置
(https://www.eefocus.com/article/472120.html此链接是一篇关于XillinxFPGA的IO的状态分析,希望自己也要能了解到AnLogic的IO状态并有对此问题的分析能力) 1、DriveStrength: 驱动强度,即最大能驱动的电流大小(见带负…...
Java SSM 笔记(一)重置版
Spring核心技术 **前置课程要求:**请各位小伙伴先完成《JavaWeb》篇、《Java 9-17新特性》篇视频教程之后,再来观看此教程。 **建议:**对Java开发还不是很熟悉的同学,最好先花费半个月到一个月时间大量地去编写小项目࿰…...

centos安装java,目录授权
centos安装java (1)查看可安装版本: yum -y list java* 安装:sudo yum -y install java-17-openjdk.x86_64 验证:java –version (2)二进制安装:下载:wget https://download.oracle.com/java/17/latest/jdk-17_linux-x64_bin.…...

ARM9EJ-S核心调试技术与系统速度访问机制解析
1. ARM9EJ-S核心调试技术概述 在嵌入式系统开发领域,调试技术的重要性不亚于代码编写本身。ARM9EJ-S作为经典的嵌入式处理器核心,其调试子系统设计体现了ARM架构对开发效率的深度考量。这套调试系统不仅仅是简单的"暂停-查看"工具,…...

2026届学术党必备的六大降重复率神器横评
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 减小AIGC率的关键之处在于使文本的统计规律性以及模式化特性得以弱化。首先,别去…...

Go语言服务网格egress:外部服务访问
Go语言服务网格egress:外部服务访问 1. Egress代理 package egressimport ("net/http""net/url" )type EgressProxy struct {dialer *net.Dialertransport *http.Transport }func NewEgressProxy() *EgressProxy {return &EgressProxy{d…...

海思Hi3516 GPIO复用避坑指南:从Excel引脚复用表到实际配置的完整解析
海思Hi3516 GPIO复用配置实战:从寄存器解析到避坑全攻略 当你在调试Hi3516开发板时,是否遇到过这样的场景:明明按照手册配置了GPIO,硬件却毫无反应?或者发现某个复用引脚无法正常工作?这些问题往往源于对海…...

基于Vue.js与AI对话的智能思维导图生成器开发实践
1. 项目概述:一个能“对话”的思维导图生成器最近在整理项目文档和梳理学习笔记时,我总感觉传统的思维导图工具少了点什么。要么是手动拖拽节点太繁琐,打断了思考的连贯性;要么是生成的导图结构僵化,难以体现思考的动态…...

S7-1200 PLC RS232自由口PTP通信实战:从硬件组态到数据收发
1. 硬件准备与接线指南 第一次接触S7-1200 PLC的RS232通信时,我完全被DB9接头上那些密密麻麻的针脚搞晕了。后来才发现,只要搞清楚几个关键引脚,接线其实比想象中简单得多。我们以最常用的CPU 1214C搭配CM1241通信模块为例,这套组…...

2026 Agent 记忆系统横评——10 种方案、LoCoMo benchmark、谁才是真王者?
2026 年 5 月,mem0.ai 发布了一份《State of AI Agent Memory 2026》报告,用 LoCoMo 这个公认最难的长对话 benchmark,把市面上 10 种 Agent 记忆方案做了一次系统横评。读完之后我做了一件事——把"AI Agent 应该用哪种记忆"这个问…...

MultiBreak:大模型多轮越狱成功率飙升54%,我们正在失去对话安全的最后防线
2026年5月3日,来自全球顶尖AI安全实验室的联合研究团队发布了MultiBreak——迄今为止规模最大、多样性最高的大模型多轮越狱攻击基准。实验结果令人震惊:在DeepSeek-R1-7B上,MultiBreak的攻击成功率(ASR)比此前最优数据…...

3步解锁《鸣潮》120帧体验:WaveTools工具箱完全指南
3步解锁《鸣潮》120帧体验:WaveTools工具箱完全指南 【免费下载链接】WaveTools 🧰鸣潮工具箱 项目地址: https://gitcode.com/gh_mirrors/wa/WaveTools 还在为《鸣潮》游戏卡顿、帧率限制而烦恼吗?是否觉得60帧的游戏体验无法充分发挥…...

Gemini3.1Pro多Agent涌现机制揭秘
“多 Agent 社会中 Gemini 3.1 Pro 的涌现行为”之所以难写,是因为涌现常被误解为“看起来很聪明”。要写成高质量文章,必须回答两件事:涌现究竟是什么(可观测定义),以及为什么它发生(可验证机制…...