【数据挖掘实战】——航空公司客户价值分析(K-Means聚类案例)

目录
一、背景和挖掘目标
1、RFM模型缺点分析
2、原始数据情况
3、挖掘目标
二、分析方法与过程
1、初步分析:提出适用航空公司的LRFMC模型
2、总体流程
第一步:数据抽取
第二步:探索性分析
第三步:数据预处理
第四步:构建模型
总结和思考
项目地址:Datamining_project: 数据挖掘实战项目代码
一、背景和挖掘目标
1、RFM模型缺点分析

在模型中,消费金额表示在一段时间内,客业产品金额的总和。因航空票价受到运输距离、舱位等级等多种因素影响,同样消费金额的不同旅客对航空公司的价值是不同的。因此这个指标并不适合用于航空公司的客户价值分析。
传统模型分析是利用属性分箱方法进行分析如图,但是此方法细分的客户群太多,需要一一识别客户特征和行为,提高了针对性营销的成本。
2、原始数据情况


# 导包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn import preprocessing
import warnings
warnings.filterwarnings('ignore') # 忽略警告
plt.rcParams['font.sans-serif'] = ['SimHei'] #解决中文显示
plt.rcParams['axes.unicode_minus'] = False #解决符号无法显示data = pd.read_csv('air_data.csv', sep=',',encoding='ANSI') # encoding='gbk'
data3、挖掘目标
- 借助航空公司客户数据,对客户进行分类;
- 对不同的客户类别进行特征分析,比较不同类客户的客户价值;
- 对不同价值的客户类别提供个性化服务,制定相应的营销策略。
二、分析方法与过程
1、初步分析:提出适用航空公司的LRFMC模型
- 因消费金额指标在航空公司中不适用,故选择客户在一定时间内累积的飞行里程M和客户乘坐舱位折扣系数的平均值C两个指标代替消费金额。此外,考虑航空公司会员加入时间在一定程度上能够影响客户价值,所以在模型中增加客户关系长度L,作为区分客户的另一指标,因此构建出LRFMC模型。
- 采用聚类的方法对客户进行细分,并分析每个客户群的特征,识别其客户价值。
2、总体流程

第一步:数据抽取
- 以2014-03-31为结束时间,选取宽度为两年的时间段作为分析观测窗口,抽取观测窗口内有乘机记录的所有客户的详细数据形成历史数据。对于后续新增的客户详细信息,利用其数据中最大的某个时间点作为结束时间,采用上述同样的方法进行抽取,形成增量数据。
- 根据末次飞行日期,从航空公司系统内抽取2012-04-01至2014-03-31内所有乘客的详细数据,总共62988条记录。
第二步:探索性分析
- 原始数据中存在票价为空值,票价为空值的数据可能是客户不存在乘机记录造成。
- 票价最小值为0、折扣率最小值为0、总飞行公里数大于0的数据。其可能是客户乘坐0折机票或者积分兑换造成。
explore = data.describe(percentiles = [], include = 'all').T #包括对数据的基本描述,percentiles参数是指定计算多少的分位数表(如1/4分位数、中位数等);T是转置,转置后更方便查阅
explore['null'] = len(data)-explore['count'] #describe()函数自动计算非空值数,需要手动计算空值数

explore = explore[['null', 'max', 'min']]
explore.columns = [u'空值数', u'最大值', u'最小值'] #表头重命名
describe()函数自动计算的字段有count(非空值数)、unique(唯一值数)、top(频数最高者)、freq(最高频数)、mean(平均值)、std(方差)、min(最小值)、50%(中位数)、max(最大值)。
explore.to_csv("resultfile.csv") #导出结果第三步:数据预处理
- 数据清洗:从业务以及建模的相关需要方面考虑,筛选出需要的数据。
丢弃票价为空的数据。丢弃票价为0、平均折扣率不为0、总飞行公里数大于0的数据。
- 属性规约:原始数据中属性太多,根据LRFMC模型,选择与其相关的六个属性,删除不相关、弱相关或冗余的属性。
- 数据变换:属性构造、数据标准化。
data = pd.read_csv('air_data.csv', sep=',',encoding='ANSI') # encoding='gbk'data = data[data['SUM_YR_1'].notnull()*data['SUM_YR_2'].notnull()] #票价非空值才保留#只保留票价非零的,或者平均折扣率与总飞行公里数同时为0的记录。
index1 = data['SUM_YR_1'] != 0
index2 = data['SUM_YR_2'] != 0
index3 = (data['SEG_KM_SUM'] == 0) & (data['avg_discount'] == 0) #该规则是“与”
data = data[index1 | index2 | index3] #该规则是“或”data.to_csv("data_cleaned.csv") #导出结果
属性构造:因原始数据中并没有直接给出LRFMC五个指标,需要构造这五个指标。L = LOAD_TIME - FFP_DATE
会员入会时间距观测窗口结束的月数 = 观测窗口的结束时间 - 入会时间[单位:月
R = LAST_TO_END
客户最近一次乘坐公司飞机距观测窗口结束的月数 = 最后一次乘机时间至观察窗口末端时长[单位:月]
F = FLIGHT_COUNT
客户在观测窗口内乘坐公司飞机的次数 = 观测窗口的飞行次数[单位:次]
M = SEG_KM_SUM
客户在观测时间内在公司累计的飞行里程 = 观测窗口总飞行公里数[单位:公里]
C = AVG_DISCOUNT
客户在观测时间内乘坐舱位所对应的折扣系数的平均值 = 平均折扣率[单位:无]
数据标准化:因五个指标的取值范围数据差异较大,为了消除数量级数据带来的影响,需要对数据进行标准化处理。
#标准差标准化import pandas as pddatafile = 'zscoredata.xls' #需要进行标准化的数据文件;
zscoredfile = 'zscoreddata.xls' #标准差化后的数据存储路径文件;#标准化处理
data = pd.read_excel(datafile)
data = (data - data.mean(axis = 0))/(data.std(axis = 0)) #简洁的语句实现了标准化变换,类似地可以实现任何想要的变换。
data.columns=['Z'+i for i in data.columns] #表头重命名。data.to_excel(zscoredfile, index = False) #数据写入
data
第四步:构建模型
import pandas as pd
from sklearn.cluster import KMeans #导入K均值聚类算法inputfile = 'zscoreddata.xls' #待聚类的数据文件
k = 5 #需要进行的聚类类别数#读取数据并进行聚类分析
data = pd.read_excel(inputfile) #读取数据#调用k-means算法,进行聚类分析
kmodel = KMeans(n_clusters = k ) #n_jobs是并行数,一般等于CPU数较好
kmodel.fit(data) #训练模型kmodel.cluster_centers_ #查看聚类中心
kmodel.labels_ #查看各样本对应的类别r1 = pd.Series(kmodel.labels_).value_counts() # 统计各类的个数
r2 = pd.DataFrame(kmodel.cluster_centers_) # 获取聚类中心
r = pd.concat([r2,r1],axis=1) # 合并
r.columns = list(['L','LAST_TO_END','FLIGHT_COUNT','SEG_KM_SUM','avg_discount']) + ['类别数目'] # 加上列名
r
给df_data加上一列按照df_data索引,标签为值值的列。参考:http://t.csdn.cn/IOW5W
df_data = pd.read_excel('zscoreddata.xls')r2 = pd.concat([df_data,pd.Series(kmodel.labels_,index=df_data.index)],axis=1)
r2.columns = list(['L','LAST_TO_END','FLIGHT_COUNT','SEG_KM_SUM','avg_discount']) + ['聚类类别'] # 加列名
r2
2、客户价值分析
# 根据r2绘制雷达图
labels = np.array(['ZL','ZR','ZF','ZM','ZC'])
labels = np.concatenate((labels,[labels[0]]))N = len(r2)
angles = np.linspace(0, 2 * np.pi, N, endpoint=False)
data = pd.concat([r2,r2.loc[:,0]],axis=1)
angles = np.concatenate((angles, [angles[0]]))
fig = plt.figure(figsize=(8,8))
ax = fig.add_subplot(111, polar=True) # 参数polar, 以极坐标的形式绘制图形
# 画线
j=0
for i in range(0,5):j=i+1ax.plot(angles,data.loc[i,:],'o-',label="客户群"+str(j))
# 添加属性标签
ax.set_thetagrids(angles*180/np.pi,labels)
plt.title(u'客户特征雷达图')
plt.legend(loc='lower right')
plt.show()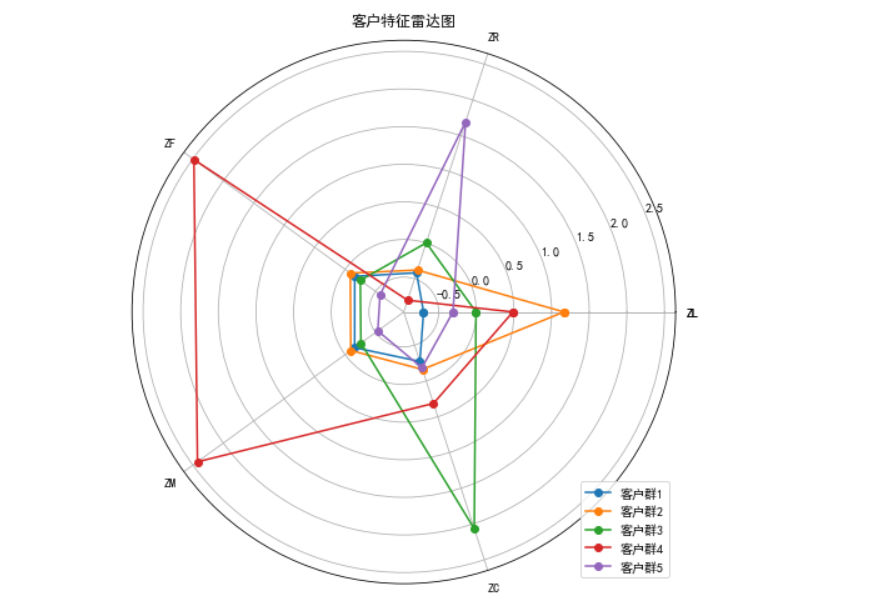
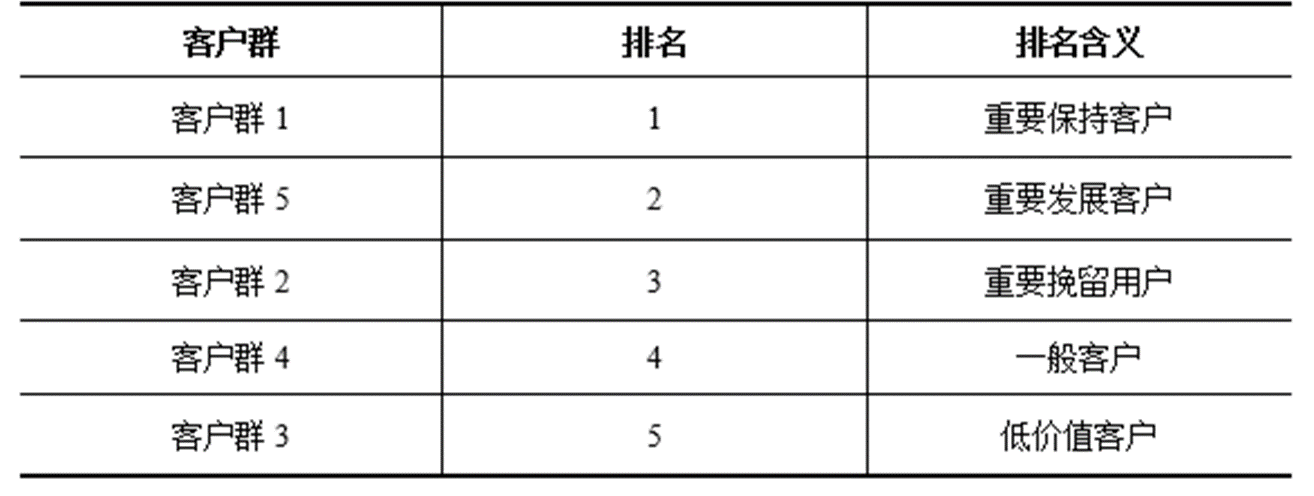
根据业务定义五个等级的客户类别:重要保持客户、重要发展客户、重要挽留客户、一般客户、低价值客户。
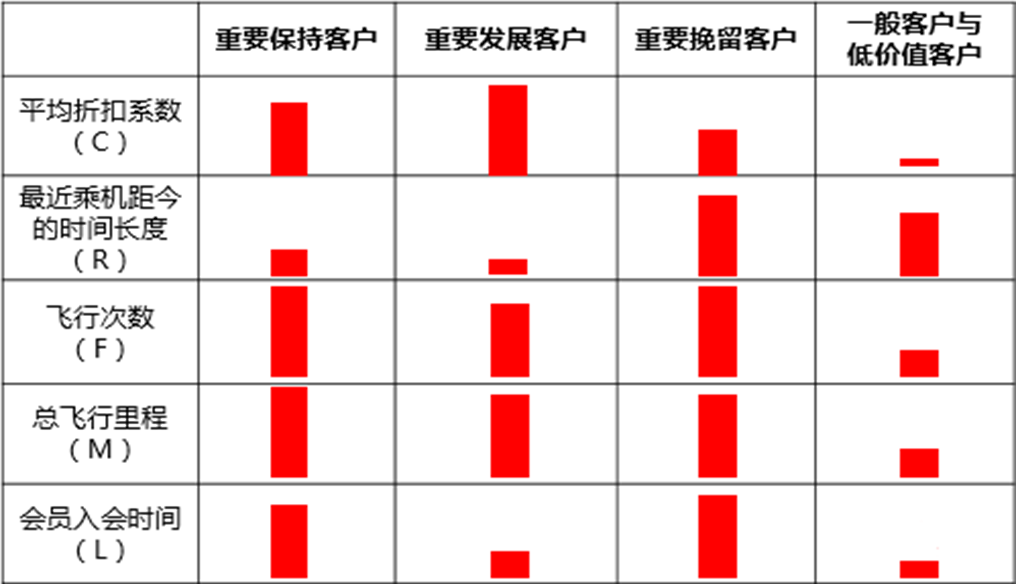
客户群价值排名:根据每种客户类型的特征,对各类客户群行客户价值排名,获取高价值客户信息。
c)交叉销售。
总结和思考
- 在国内航空市场竞争日益激烈的背景下,客户流失问题是影响公司利益的重要因素之一。如何如何改善流失问题,继而提高客户满意度、忠诚度,维护自身的市场和利益?
- 客户流失分析可以针对目前老客户进行分类预测。针对航空公司客户信息数据附件(见:/示例程序/air_data.csv)可以进行老客户以及客户类型的定义(例如:将其中将飞行次数大于6次的客户定义为老客户,已流失客户定义为:第二年飞行次数与第一年飞行次数比例小于50%的客户等)。
- 选取客户信息中的关键属性如:会员卡级别,客户类型(流失、准流失、未流失),平均折扣率,积分兑换次数,非乘机积分总和,单位里程票价,单位里程积分等。通过这些信息构建客户的流失模型,运用模型预测未来客户的类别归属(未流失、准流失,或已流失)。
相关文章:
【数据挖掘实战】——航空公司客户价值分析(K-Means聚类案例)
目录 一、背景和挖掘目标 1、RFM模型缺点分析 2、原始数据情况 3、挖掘目标 二、分析方法与过程 1、初步分析:提出适用航空公司的LRFMC模型 2、总体流程 第一步:数据抽取 第二步:探索性分析 第三步:数据预处理 第四步&…...

AnlogicFPGA-IO引脚约束设置
(https://www.eefocus.com/article/472120.html此链接是一篇关于XillinxFPGA的IO的状态分析,希望自己也要能了解到AnLogic的IO状态并有对此问题的分析能力) 1、DriveStrength: 驱动强度,即最大能驱动的电流大小(见带负…...
Java SSM 笔记(一)重置版
Spring核心技术 **前置课程要求:**请各位小伙伴先完成《JavaWeb》篇、《Java 9-17新特性》篇视频教程之后,再来观看此教程。 **建议:**对Java开发还不是很熟悉的同学,最好先花费半个月到一个月时间大量地去编写小项目࿰…...

centos安装java,目录授权
centos安装java (1)查看可安装版本: yum -y list java* 安装:sudo yum -y install java-17-openjdk.x86_64 验证:java –version (2)二进制安装:下载:wget https://download.oracle.com/java/17/latest/jdk-17_linux-x64_bin.…...
【大数据】HADOOP-YARN容量调度器多队列配置详解实战
简介 Capacity调度器具有以下的几个特性: 层次化的队列设计,这种层次化的队列设计保证了子队列可以使用父队列设置的全部资源。这样通过层次化的管理,更容易合理分配和限制资源的使用。容量保证,队列上都会设置一个资源的占比&a…...

加密技术在android系统安全中的应用
前言android 系统安全内容总结 1、算法基础 算法基础参照linux的全盘加密与文件系统加密在android中的应用的2、预备知识 android系统安全特性用到加密算法的如下表:...
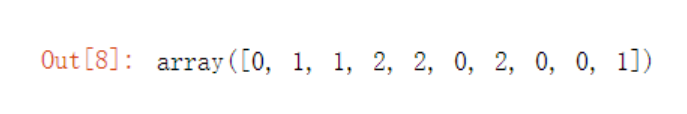
KNN&K-means从入门到实战
作者:王同学 来源:投稿 编辑:学姐 1. 基本概念 1.1 KNN k近邻法(k-nearest neighbor,k-NN)是一种基本分类与回归方法。 k近邻法的输入为实例的特征向量对应于特征空间的点;输出为实例的类别&…...
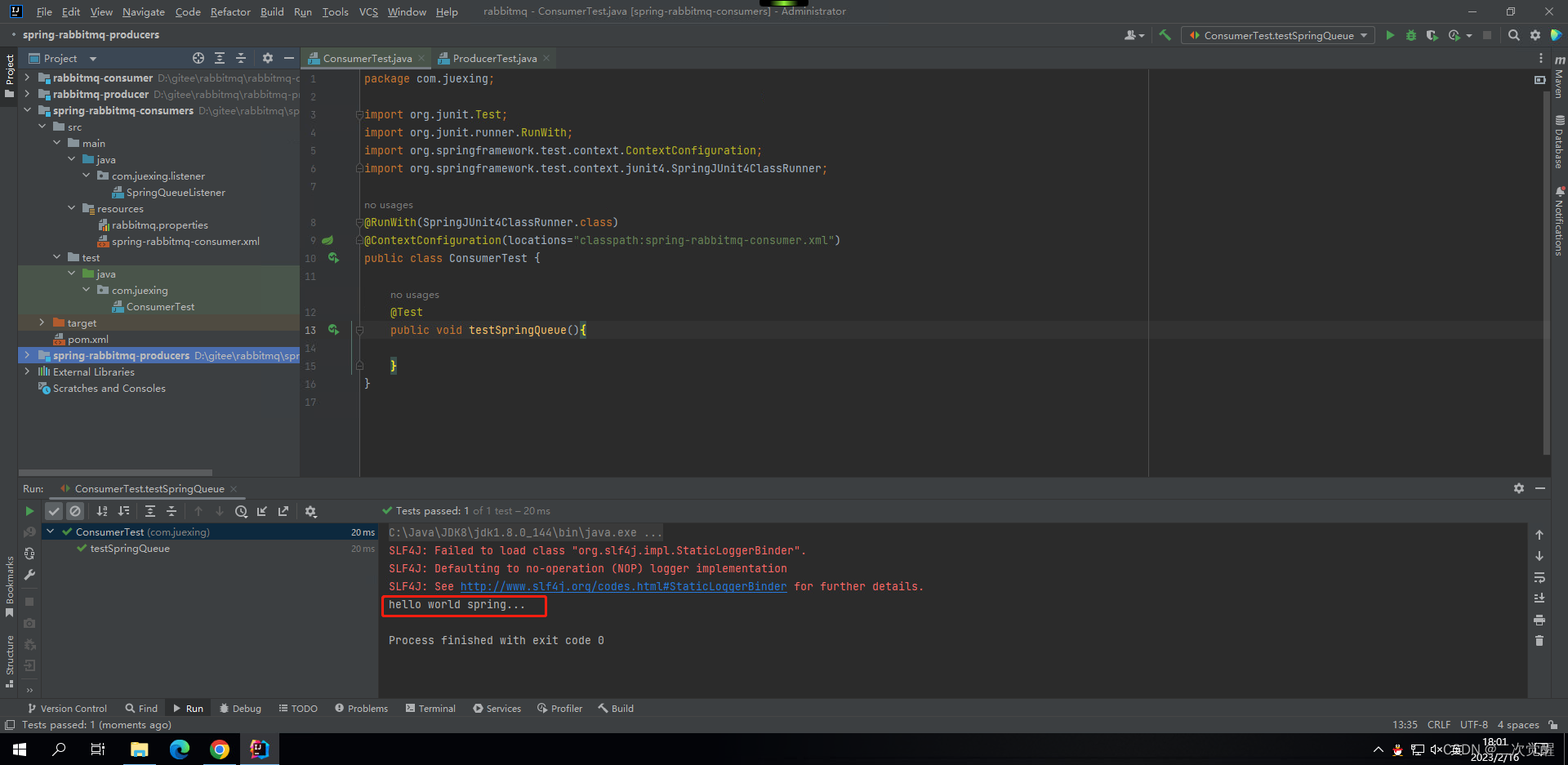
SpringBoot整合RabbitMQ
SpringBoot整合RabbitMQ,生产者 (1)创建maven项目 (2)引入依赖 <parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><versi…...
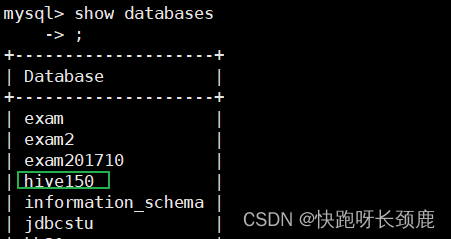
Hive---安装教程
Hive安装教程 Hive属于Hadoop生态圈,所以Hive必须运行在Hadoop上 文章目录Hive安装教程上传安装包解压并且更名修改 /etc/profile创建hive-site.xml将mysql的jar包放入Hive库中开启刷新配置文件hadoop开启mysql初始化启动hive上传安装包 将安装包上传到/opt/insta…...
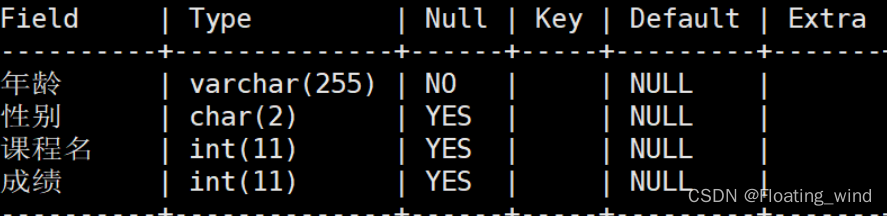
MySQL作业四
学生表:Student (Sno, Sname, Ssex , Sage, Sdept) 学号,姓名,性别,年龄,所在系 Sno为主键 课程表:Course (Cno, Cname,) 课程号,课程名 Cno为主键 学生选课表:SC (Sno, Cno, Score)…...
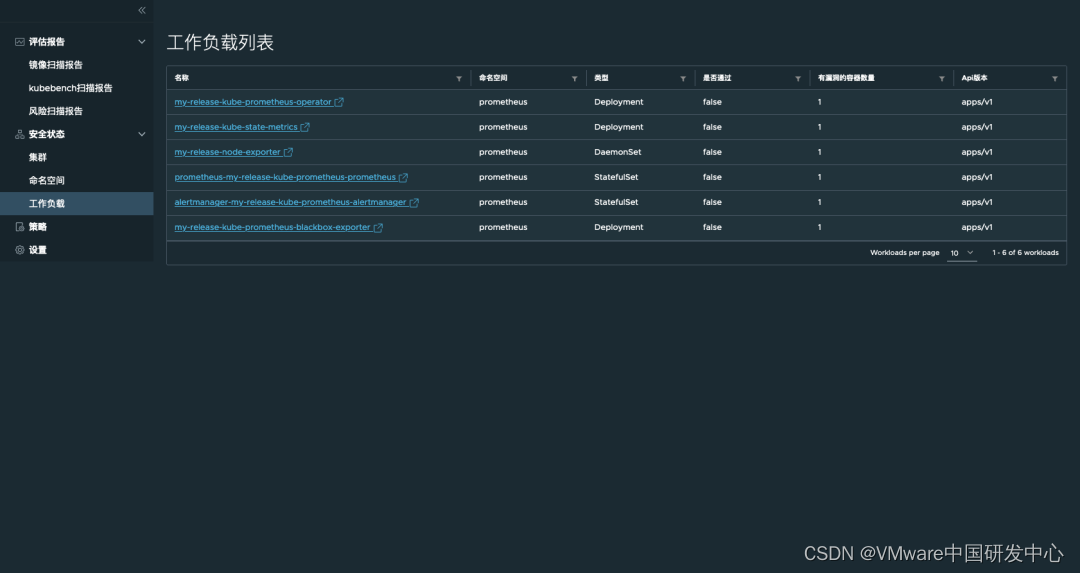
云原生安全检测器 Narrows(CNSI)的部署和使用
近日, 云原生安全检测器 Narrows(Cloud Native Security Inspector,简称CNSI)发布了0.2.0版本。 (https://github.com/vmware-tanzu/cloud-native-security-inspector) 此项目旨在对K8s集群中的工作负载进…...
【并发编程】【3】Java线程 创建线程与线程运行
并发编程 3.Java线程 本章内容 创建和运行线程 查看线程 线程 API 线程状态 3.1 创建和运行线程 方法一,直接使用 Thread // 创建线程对象 Thread t new Thread() {public void run() {// 要执行的任务} }; // 启动线程 t.start();例如: // 构…...

Ambire 最新消息——2023 年 1 月
大家好,这里是我们在过去几周所做的一切的快速回顾。 发展 整个钱包的交易模拟和余额预测 我们推出了一项真正改变加密钱包 UX 游戏规则的功能:Ambire 现在向用户显示他们的钱包余额将如何更新,甚至在签署交易之前。 这项新功能可以分解为 Am…...

【kubeflow | 镜像源的解决方法——脚本】
20230214 方式一:获取所有镜像列表,自行外网拉取下载 获取KF所需镜像列表脚本 Offical docs for getting all kubeflow images curl https://gist.githubusercontent.com/Jason-CKY/7d7056ce261c6d606585f05218230037/raw/5c27297efdf6424cd9679b9f7…...
)
function calling convention(函数调用约定)
函数调用约定 函数调用约定,是指当一个函数被调用时,函数的参数会被传递给被调用的函数和返回值会被返回给调用函数。函数的调用约定就是描述参数是怎么传递和由谁平衡...

errgroup 原理简析
golang.org/x/sync/errgroup errgroup提供了一组并行任务中错误采集的方案。 先看注释 Package errgroup provides synchronization, error propagation, and Context cancelation for groups of goroutines working on subtasks of a common task. Group 结构体 // A Gro…...

Centos7.6 下 Docker 安装
Docker的自动化安装 官方的一键安装方式: curl -fsSL https://get.docker.com | bash -s docker --mirror Aliyun 国内 daocloud一键安装命令: curl -sSL https://get.daocloud.io/docker | sh Docker手动安装 手动安装Docker分三步:卸…...
C++11--lambda表达式
目录 lambda表达式的概念 lambda表达式语法 lambda表达式的书写格式 捕捉列表 参数列表 mutable 返回值类型 函数体 lambda表达式交换两个数 函数对象与lambda表达式 lambda表达式的概念 lambda表达式是一个匿名函数 它能让代码更加地简洁 提高了代码可读性 首先定义…...
四【Spring框架】
目录一 Spring概述二 .Spring 的体系结构三 Spring的开发环境3.1 配置pom.xml文件四 项目案例:4.1 创建实体类4.2 在pom.xml中引入依赖4.3 配置Spring-config.xml文件4.4 Test✅作者简介:Java-小白后端开发者 🥭公认外号:球场上的…...

树与二叉树 总复习
一、树的定义 树是一个有n个(n>0)结点的有限集合。 如果n0,称为空树; 如果n>0,称为非空树,有且仅有一个特定的称为根Root的结点(无直接前驱) 如果n>1,除了根节点外&…...

XDMA驱动内存读写测试指南:从reg_rw工具使用到AXI4时序分析
XDMA驱动内存读写测试指南:从reg_rw工具使用到AXI4时序分析 在FPGA与主机间的高速数据交互场景中,XDMA(Xilinx DMA)作为PCIe协议栈的核心引擎,其内存读写性能直接决定了系统整体吞吐量。本文将深入剖析reg_rw工具的底层…...

3步告别桌面混乱:开源免费的NoFences桌面分区管理工具
3步告别桌面混乱:开源免费的NoFences桌面分区管理工具 【免费下载链接】NoFences 🚧 Open Source Stardock Fences alternative 项目地址: https://gitcode.com/gh_mirrors/no/NoFences 你是否每天都要在杂乱无章的桌面图标中浪费宝贵时间&#x…...

2026年Win11强力清理工具推荐:安全无广告的C盘瘦身软件怎么选?
我是个学生党,笔记本电脑的C盘从买回来就没清理过,最近装新游戏时直接提示空间不足。网上搜“Win11强力清理工具推荐”,跳出来一堆软件,看着都挺好,但又怕下载到带捆绑、弹广告的流氓软件。我只是想要一个能真正把C盘腾…...

手把手教你用FUTURE POLICE:会议录音秒变带时间轴字幕
手把手教你用FUTURE POLICE:会议录音秒变带时间轴字幕 1. 为什么需要高精度字幕对齐? 在日常工作中,我们经常遇到这样的场景:重要会议录音需要整理成文字稿,但人工听写耗时耗力;视频剪辑时需要添加字幕&a…...

LeagueAkari:英雄联盟智能辅助工具完全指南
LeagueAkari:英雄联盟智能辅助工具完全指南 【免费下载链接】League-Toolkit 兴趣使然的、简单易用的英雄联盟工具集。支持战绩查询、自动秒选等功能。基于 LCU API。 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit LeagueAkari是一款基于英雄…...

显卡驱动深度清理指南:用DDU解决驱动残留难题
显卡驱动深度清理指南:用DDU解决驱动残留难题 【免费下载链接】display-drivers-uninstaller Display Driver Uninstaller (DDU) a driver removal utility / cleaner utility 项目地址: https://gitcode.com/gh_mirrors/di/display-drivers-uninstaller 你是…...

Janus-Pro-7B入门编程教学:从零开始学习C语言文件读写操作
Janus-Pro-7B入门编程教学:从零开始学习C语言文件读写操作 你是不是刚开始学C语言,一看到文件操作就觉得头大?fopen、fwrite、fread这些函数名字看着就复杂,更别提什么文件指针、缓冲区这些概念了。别担心,这感觉我懂…...

AntdUI实战:用WinForm和.NET 6给老旧内部管理系统“换肤”的完整记录
AntdUI实战:用WinForm和.NET 6给老旧内部管理系统“换肤”的完整记录 当企业内部的WinForm系统运行超过十年,那些灰底蓝框的界面早已与现代审美格格不入。去年接手某制造业ERP系统改造时,我面对的是一个基于.NET Framework 4.0的"古董&q…...

Nomic-Embed-Text-V2-MoE在AIGC内容审核中的应用:识别生成文本的违规风险
Nomic-Embed-Text-V2-MoE在AIGC内容审核中的应用:识别生成文本的违规风险 最近和几个做AIGC应用的朋友聊天,大家普遍提到一个头疼的问题:用户用模型生成的文本,时不时会冒出一些不合规的内容,比如涉及不当言论、暴力或…...

嵌入式系统中SipHash轻量级哈希实现与优化
1. SipHash 嵌入式底层实现技术解析SipHash 是一种基于加法-循环-异或(Add-Rotate-Xor, ARX)结构的伪随机函数族,专为短输入消息设计,在嵌入式系统中广泛用于哈希表键值保护、拒绝服务(DoS)防护、安全计数器…...