【大数据】HADOOP-YARN容量调度器多队列配置详解实战
简介
Capacity调度器具有以下的几个特性:
- 层次化的队列设计,这种层次化的队列设计保证了子队列可以使用父队列设置的全部资源。这样通过层次化的管理,更容易合理分配和限制资源的使用。
- 容量保证,队列上都会设置一个资源的占比,这样可以保证每个队列都不会占用整个集群的资源。
安全,每个队列有严格的访问控制。用户只能向自己的队列里面提交任务,而且不能修改或者访问其他队列的任务。 - 弹性分配,空闲的资源可以被分配给任何队列。当多个队列出现争用的时候,则会按照比例进行平衡。
多租户租用,通过队列的容量限制,多个用户就可以共享同一个集群,同时保证每个队列分配到自己的容量,提高利用率。 - 操作性,yarn支持动态修改调整容量、权限等的分配,可以在运行时直接修改。还提供给管理员界面,来显示当前的队列状况。管理员可以在运行时,添加一个队列;但是不能删除一个队列。管理员还可以在运行时暂停某个队列,这样可以保证当前的队列在执行过程中,集群不会接收其他的任务。如果一个队列被设置成了stopped,那么就不能向他或者子队列上提交任务了。
- 基于资源的调度,协调不同资源需求的应用程序,比如内存、CPU、磁盘等等。
需求
default 队列占总内存的40%,最大资源容量占总资源的60%
ops 队列占总内存的60%,最大资源容量占总资源的80%
配置队列优先级策略
配置多队列的容量调度器
- 在yarn-site.xml里面配置使用容量调度器
<!-- 使用容量调度器 -->
<property><name>yarn.resourcemanager.scheduler.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value>
</property>
- 在capacity-scheduler.xml中配置如下:
<?xml version="1.0" encoding="UTF-8"?>
<configuration><!-- 表示集群最大app数 --><property><name>yarn.scheduler.capacity.maximum-applications</name><value>10000</value></property><!-- 表示集群上某队列可使用的资源比例 目的是为了限制过多的am数,即app数 --><property><name>yarn.scheduler.capacity.maximum-am-resource-percent</name><value>0.1</value></property><!-- 配置指定调度器使用的资源计算器 --><!-- DefaultResourseCalculator 默认值,只使用内存进行比较 --><!-- DominantResourceCalculator 多维度资源计算,内存、cpu --><property><name>yarn.scheduler.capacity.resource-calculator</name><value>org.apache.hadoop.yarn.util.resource.DominantResourceCalculator</value></property><!-- root队列中有哪些子队列--><property><name>yarn.scheduler.capacity.root.queues</name><value>default,ops</value></property><!-- *******************default队列*********************** --><!-- default 队列占用的资源容量百分比 40% --><property><name>yarn.scheduler.capacity.root.default.capacity</name><value>40</value></property><!-- default 队列占用的最大资源容量百分比 60%--><property><name>yarn.scheduler.capacity.root.default.maximum-capacity</name><value>60</value></property><!-- 允许单个用户最多可获取的队列资源的倍数,默认值1,确保单个用户无论集群有多空闲,永远不会占用超过队列配置的资源当值大于1时,用户可使用的资源将超过队列配置的资源,但应该不能超过队列配置的最大资源--><property><name>yarn.scheduler.capacity.root.default.user-limit-factor</name><value>1</value></property><!-- 队列状态 --><property><name>yarn.scheduler.capacity.root.default.state</name><value>RUNNING</value></property><!-- 限定哪些admin用户可向root队列中提交应用程序 --><property><name>yarn.scheduler.capacity.root.default.acl_submit_applications</name><value>*</value></property><!-- 为root队列指定一个管理员,该管理员可控制该队列的所有应用程序,比如杀死任意一个应用程序等 --><property><name>yarn.scheduler.capacity.root.default.acl_administer_queue</name><value>*</value></property><!-- 配置哪些用户有权配置提交任务优先级 --><property><name>yarn.scheduler.capacity.root.default.acl_application_max_priority</name><value>*</value></property><!-- 任务的超时时间设置:yarn application -appId ${appId} -updateLifeTime Timeout --><!-- 如果application指定了超时时间,则提交到该队列的application能够制定的最大超时时间不能超过该值。--><property><name>yarn.scheduler.capacity.root.default.maximum-application-lifetime</name><value>-1</value></property><!-- 如果application没有指定超时时间,则用default-application-lifetime 作为默认值 --><property><name>yarn.scheduler.capacity.root.default.default-application-lifetime</name><value>-1</value></property><!-- *******************hive队列*********************** --><!-- hive 队列占用的资源容量百分比 60% --><property><name>yarn.scheduler.capacity.root.ops.capacity</name><value>60</value></property><!-- default 队列占用的最大资源容量百分比 80%--><property><name>yarn.scheduler.capacity.root.ops.maximum-capacity</name><value>80</value></property><!-- 允许单个用户最多可获取的队列资源的倍数,默认值1,确保单个用户无论集群有多空闲,永远不会占用超过队列配置的资源当值大于1时,用户可使用的资源将超过队列配置的资源,但应该不能超过队列配置的最大资源--><property><name>yarn.scheduler.capacity.root.ops.user-limit-factor</name><value>1</value></property><!-- 队列状态 --><property><name>yarn.scheduler.capacity.root.ops.state</name><value>RUNNING</value></property><!-- 限定哪些admin用户可向root队列中提交应用程序 --><property><name>yarn.scheduler.capacity.root.ops.acl_submit_applications</name><value>*</value></property><!-- 为root队列指定一个管理员,该管理员可控制该队列的所有应用程序,比如杀死任意一个应用程序等 --><property><name>yarn.scheduler.capacity.root.ops.acl_administer_queue</name><value>*</value></property><!-- 配置哪些用户有权配置提交任务优先级 --><property><name>yarn.scheduler.capacity.root.ops.acl_application_max_priority</name><value>*</value></property><!-- 任务的超时时间设置:yarn application -appId ${appId} -updateLifeTime Timeout --><!-- 如果application指定了超时时间,则提交到该队列的application能够制定的最大超时时间不能超过该值。--><property><name>yarn.scheduler.capacity.root.ops.maximum-application-lifetime</name><value>-1</value></property><!-- 如果application没有指定超时时间,则用default-application-lifetime 作为默认值 --><property><name>yarn.scheduler.capacity.root.opsdefault-application-lifetime</name><value>-1</value></property><!--CapacityScheduler尝试调度机本地容器之后错过的调度机会数。通常,应该将其设置为集群中的节点数。默认情况下在一个架构中设置大约40个节点。应为正整数值。--><property><name>yarn.scheduler.capacity.node-locality-delay</name><value>40</value></property><!--在节点本地延迟时间之外的另外的错过的调度机会的次数,在此之后,CapacityScheduler尝试调度非切换容器而不是机架本地容器.例如:在node-locality-delay = 40和rack-locality-delay = 20的情况下,调度器将在40次错过机会之后尝试机架本地分配,在40 + 20 = 60之后错过机会.使用-1作为默认值,禁用此功能.在这种情况下,根据资源请求中指定的容器和唯一位置的数量以及集群的大小,计算分配关闭交换容器的错失机会的数量--><property><name>yarn.scheduler.capacity.rack-locality-additional-delay</name><value>-1</value></property><!-- 此配置指定用户或组到特定队列的映射 --><property><name>yarn.scheduler.capacity.queue-mappings</name><value>u:root:default,g:root:default,u:%user:%user</value></property><property><name>yarn.scheduler.capacity.queue-mappings-override.enable</name><value>false</value></property><property><name>yarn.scheduler.capacity.per-node-heartbeat.maximum-offswitch-assignments</name><value>1</value></property><property><name>yarn.scheduler.capacity.application.fail-fast</name><value>false</value></property><property><name>yarn.scheduler.capacity.workflow-priority-mappings</name><value></value></property><property><name>yarn.scheduler.capacity.workflow-priority-mappings-override.enable</name><value>false</value></property>
</configuration>
- 同步到其他节点后,刷新配置
bin/yarn rmadmin -refreshQueues
- 查看界面展示
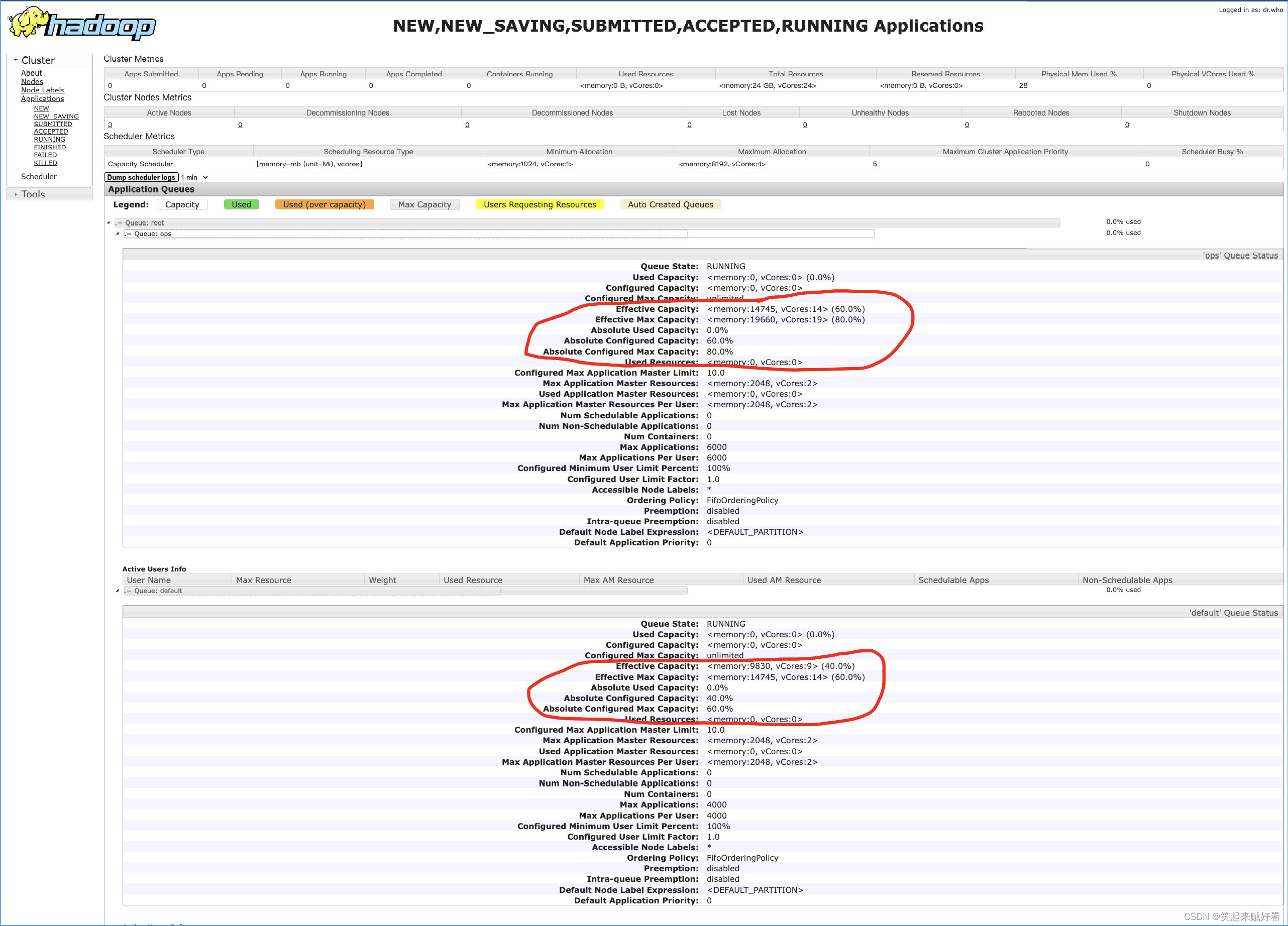
- 提交任务,查看队列资源占比情况
提交任务
bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode cluster --driver-memory 2g --executor-memory 2g --executor-cores 1 --num-executors 1 --queue default examples/jars/spark-examples_2.12-3.2.1.jar 100
–driver-memory 2g --executor-memory 2g --executor-cores 1 --num-executors 1
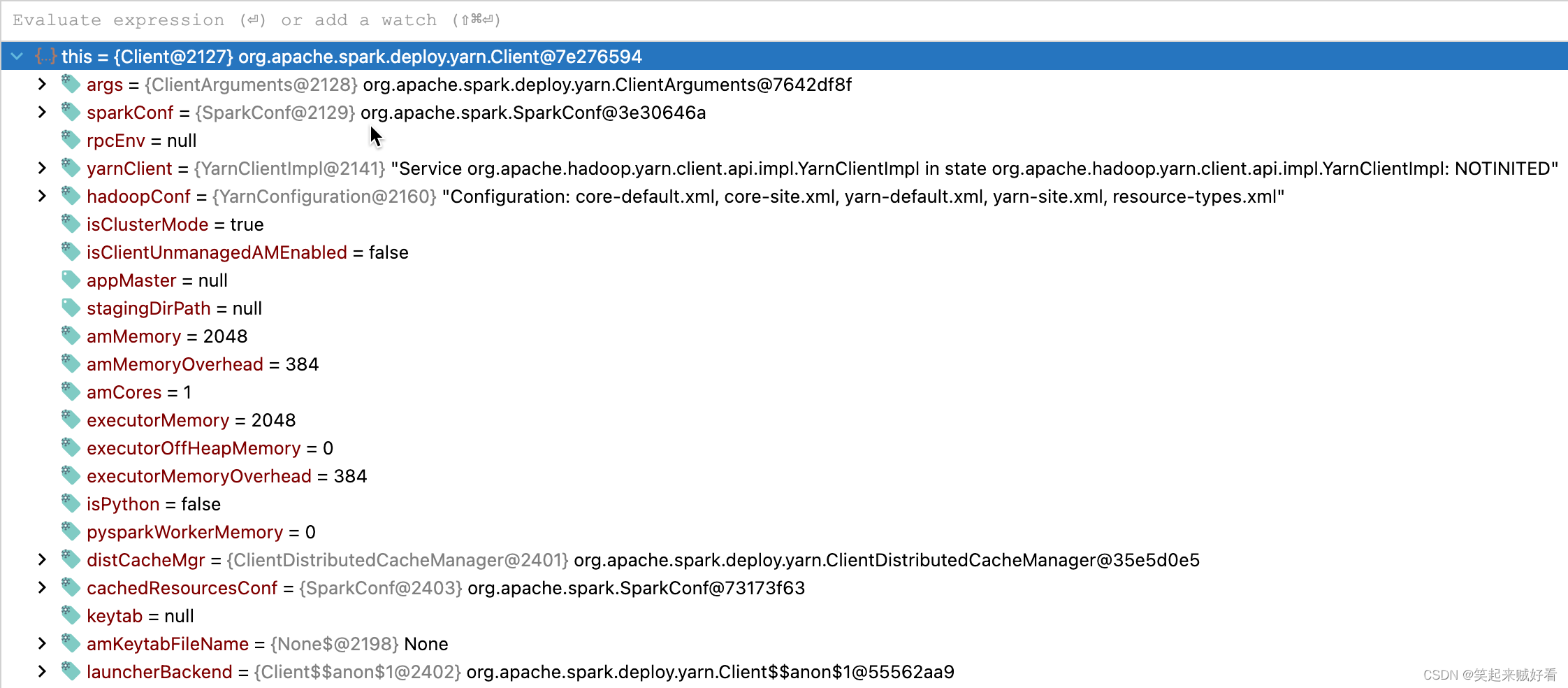

可以看到 向YARN的资源需求是:
amMemory = 2048
amMemoryOverhead = 384
executorMemory = 2048
executorOffHeapMemory. = 0
executorMemoryOverhead = 384
amCores = 1
最终向YARN上申请AM的资源大小为:
am = amMemory + amMemoryOverhead = 2432
executor = executorMemory + executorMemoryOverhead = 2432
capability = <memory:2432,vCores:1>
由于配置的集群资源分配最小单位为1024MB, 因此需要向上取整, 即 3072 MB
这也是为甚么我明明申请的 资源 比较小,但是在yarn上显示的资源总不对,比实际申请的资源要高一些。资源比预期的要高。
这主要是yarn的资源计算是用DominantResourceCalculator来计算管理 cpu、内存的。
spark和yarn上申请的资源没有对的上。
所以最终的资源:
Driver 申请的资源 --driver-memory 2g 实际在yarn中AM申请的资源为 3g1c
Executor 申请的资源 --executor-memory 2g --executor-cores 1 --num-executors 1 实际在yarn中executor申请的资源为 3g1c
最终总的资源为 6g2c

同理再提交一下 1g1c的
bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode cluster --driver-memory 1g --executor-memory 1g --executor-cores 1 --num-executors 2 --queue default examples/jars/spark-examples_2.12-3.2.1.jar 100
–driver-memory 1g --executor-memory 1g --executor-cores 1 --num-executors 2
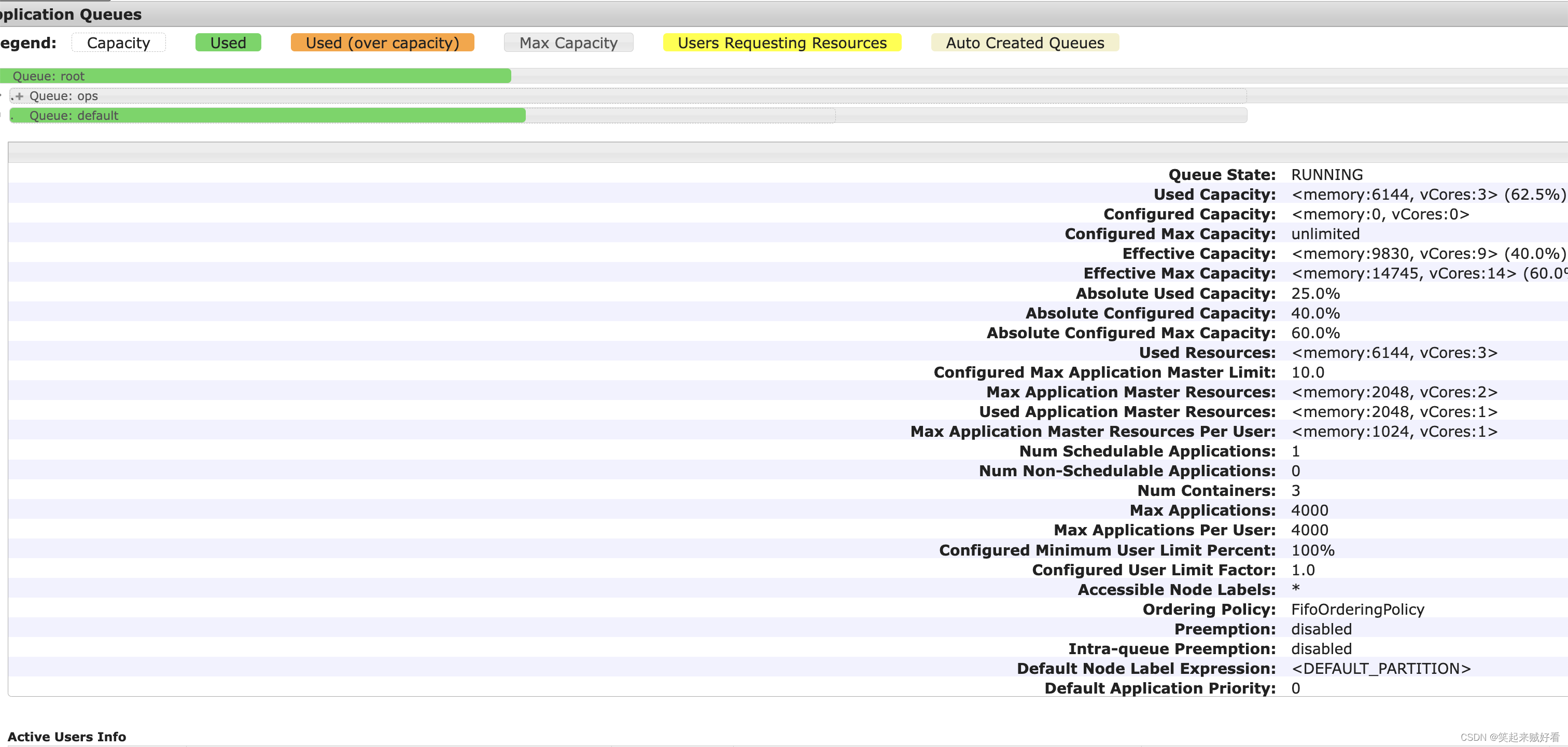
所以最终的资源:
Driver 申请的资源 --driver-memory 1g 实际在yarn中AM申请的资源为 1g1c
Executor 申请的资源 --executor-memory 1g --executor-cores 1 --num-executors 2 实际在yarn中executor申请的资源为 4g2c
最终总的资源为 6g3c
- 验证队列的最大资源限制
bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode cluster --driver-memory 2g --executor-memory 2g --executor-cores 2 --num-executors 5 --queue default examples/jars/spark-examples_2.12-3.2.1.jar 100

当内存需求超过队列最大资源时
bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode cluster --driver-memory 2g --executor-memory 2g --executor-cores 2 --num-executors 6 --queue default examples/jars/spark-examples_2.12-3.2.1.jar 100

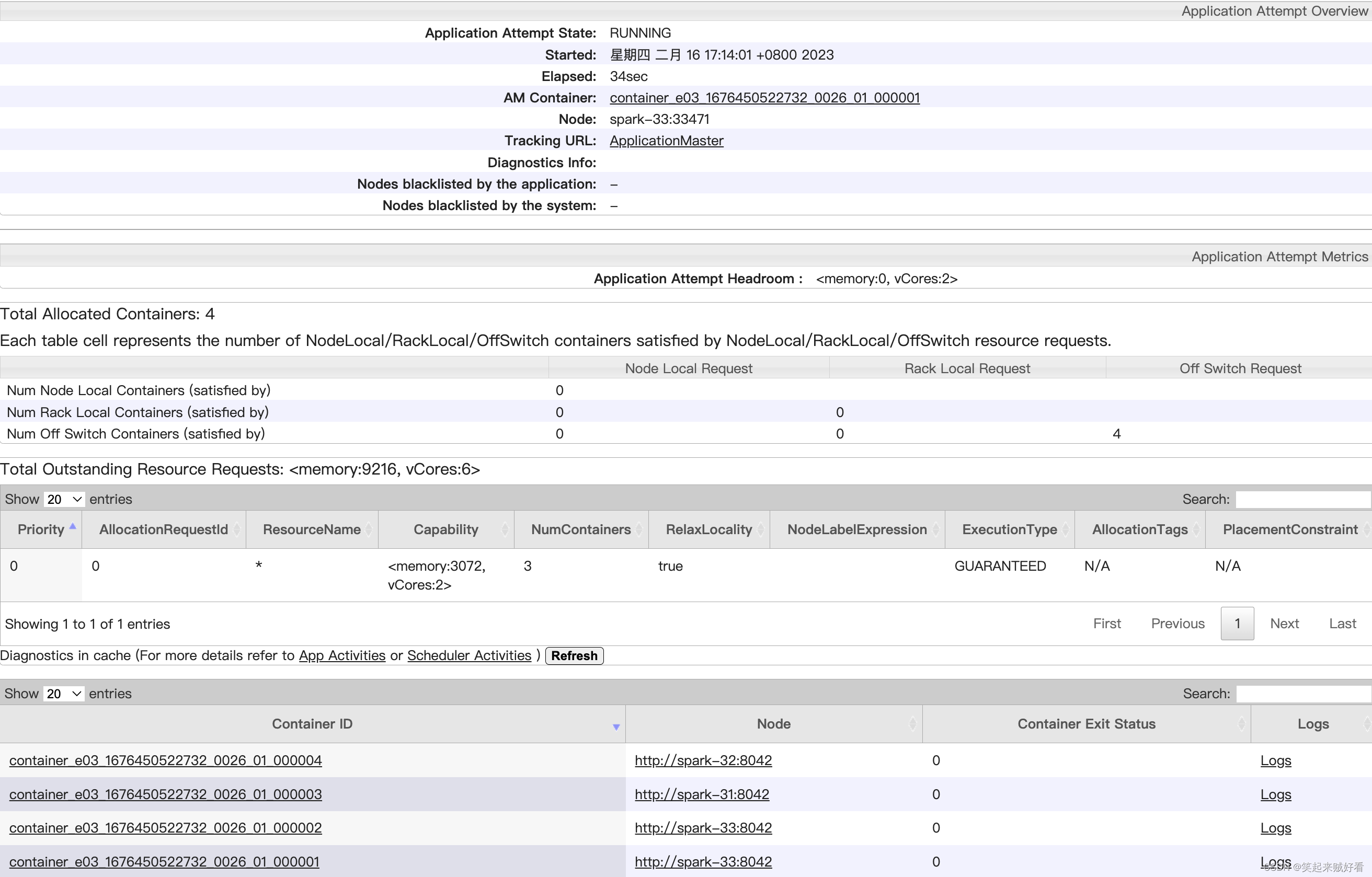
最终看到申请的资源可以超过队列配置的资源,但是不会超过最大的资源
spark申请的容器为 6 个,但是最终只启动了4个。
希望对正在查看文章的您有所帮助,记得关注、评论、收藏,谢谢您
相关文章:
【大数据】HADOOP-YARN容量调度器多队列配置详解实战
简介 Capacity调度器具有以下的几个特性: 层次化的队列设计,这种层次化的队列设计保证了子队列可以使用父队列设置的全部资源。这样通过层次化的管理,更容易合理分配和限制资源的使用。容量保证,队列上都会设置一个资源的占比&a…...

加密技术在android系统安全中的应用
前言android 系统安全内容总结 1、算法基础 算法基础参照linux的全盘加密与文件系统加密在android中的应用的2、预备知识 android系统安全特性用到加密算法的如下表:...
KNN&K-means从入门到实战
作者:王同学 来源:投稿 编辑:学姐 1. 基本概念 1.1 KNN k近邻法(k-nearest neighbor,k-NN)是一种基本分类与回归方法。 k近邻法的输入为实例的特征向量对应于特征空间的点;输出为实例的类别&…...
SpringBoot整合RabbitMQ
SpringBoot整合RabbitMQ,生产者 (1)创建maven项目 (2)引入依赖 <parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><versi…...
Hive---安装教程
Hive安装教程 Hive属于Hadoop生态圈,所以Hive必须运行在Hadoop上 文章目录Hive安装教程上传安装包解压并且更名修改 /etc/profile创建hive-site.xml将mysql的jar包放入Hive库中开启刷新配置文件hadoop开启mysql初始化启动hive上传安装包 将安装包上传到/opt/insta…...
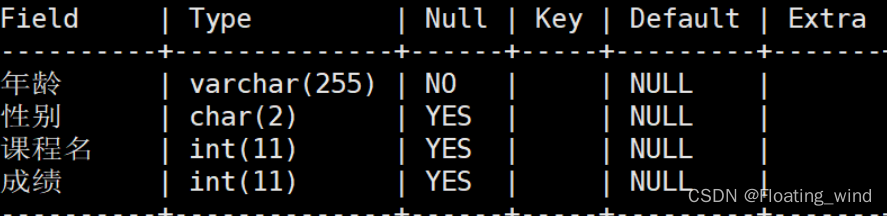
MySQL作业四
学生表:Student (Sno, Sname, Ssex , Sage, Sdept) 学号,姓名,性别,年龄,所在系 Sno为主键 课程表:Course (Cno, Cname,) 课程号,课程名 Cno为主键 学生选课表:SC (Sno, Cno, Score)…...
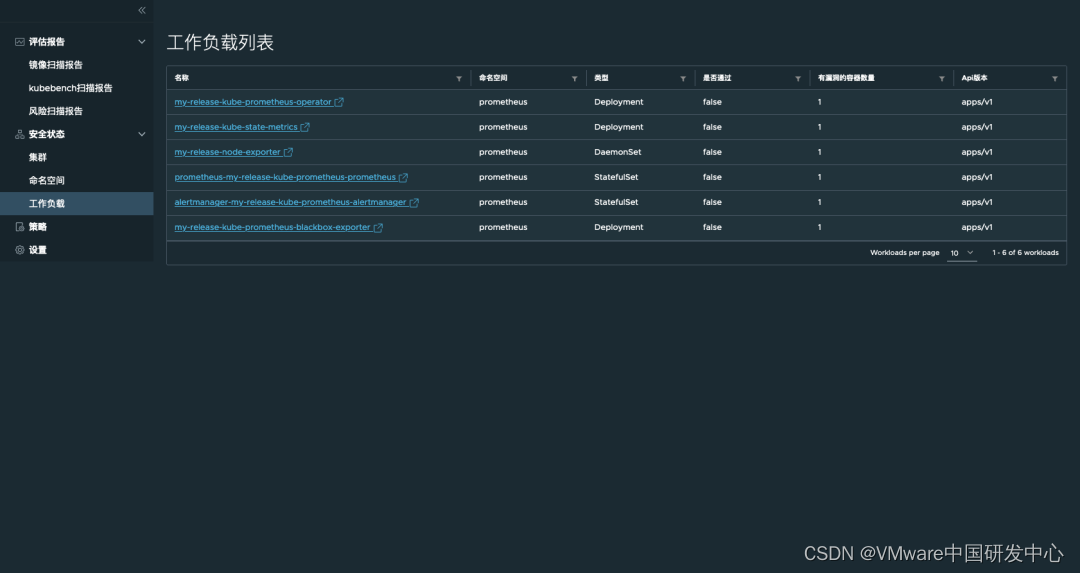
云原生安全检测器 Narrows(CNSI)的部署和使用
近日, 云原生安全检测器 Narrows(Cloud Native Security Inspector,简称CNSI)发布了0.2.0版本。 (https://github.com/vmware-tanzu/cloud-native-security-inspector) 此项目旨在对K8s集群中的工作负载进…...
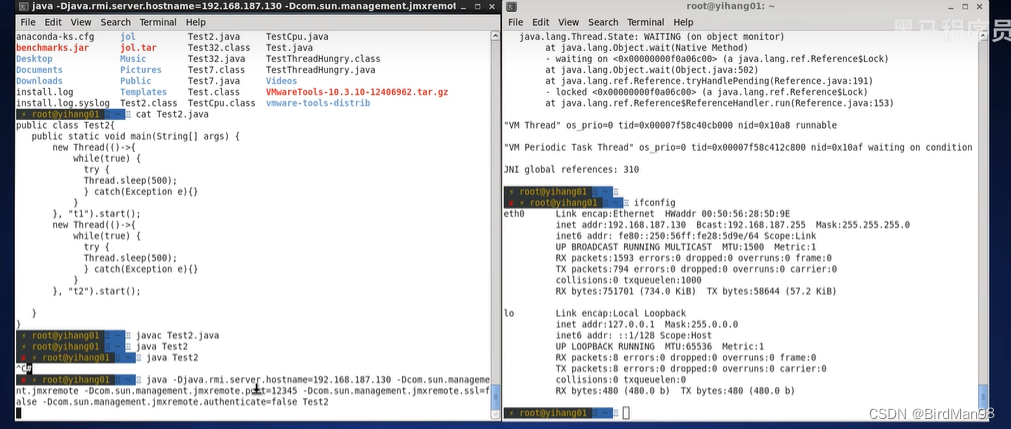
【并发编程】【3】Java线程 创建线程与线程运行
并发编程 3.Java线程 本章内容 创建和运行线程 查看线程 线程 API 线程状态 3.1 创建和运行线程 方法一,直接使用 Thread // 创建线程对象 Thread t new Thread() {public void run() {// 要执行的任务} }; // 启动线程 t.start();例如: // 构…...

Ambire 最新消息——2023 年 1 月
大家好,这里是我们在过去几周所做的一切的快速回顾。 发展 整个钱包的交易模拟和余额预测 我们推出了一项真正改变加密钱包 UX 游戏规则的功能:Ambire 现在向用户显示他们的钱包余额将如何更新,甚至在签署交易之前。 这项新功能可以分解为 Am…...

【kubeflow | 镜像源的解决方法——脚本】
20230214 方式一:获取所有镜像列表,自行外网拉取下载 获取KF所需镜像列表脚本 Offical docs for getting all kubeflow images curl https://gist.githubusercontent.com/Jason-CKY/7d7056ce261c6d606585f05218230037/raw/5c27297efdf6424cd9679b9f7…...
)
function calling convention(函数调用约定)
函数调用约定 函数调用约定,是指当一个函数被调用时,函数的参数会被传递给被调用的函数和返回值会被返回给调用函数。函数的调用约定就是描述参数是怎么传递和由谁平衡...

errgroup 原理简析
golang.org/x/sync/errgroup errgroup提供了一组并行任务中错误采集的方案。 先看注释 Package errgroup provides synchronization, error propagation, and Context cancelation for groups of goroutines working on subtasks of a common task. Group 结构体 // A Gro…...

Centos7.6 下 Docker 安装
Docker的自动化安装 官方的一键安装方式: curl -fsSL https://get.docker.com | bash -s docker --mirror Aliyun 国内 daocloud一键安装命令: curl -sSL https://get.daocloud.io/docker | sh Docker手动安装 手动安装Docker分三步:卸…...
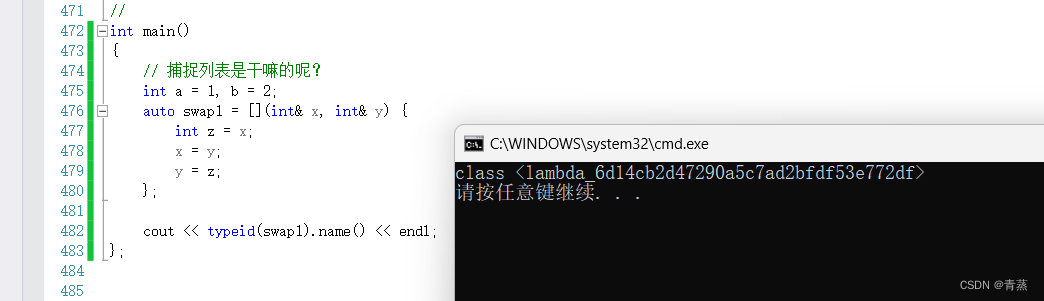
C++11--lambda表达式
目录 lambda表达式的概念 lambda表达式语法 lambda表达式的书写格式 捕捉列表 参数列表 mutable 返回值类型 函数体 lambda表达式交换两个数 函数对象与lambda表达式 lambda表达式的概念 lambda表达式是一个匿名函数 它能让代码更加地简洁 提高了代码可读性 首先定义…...
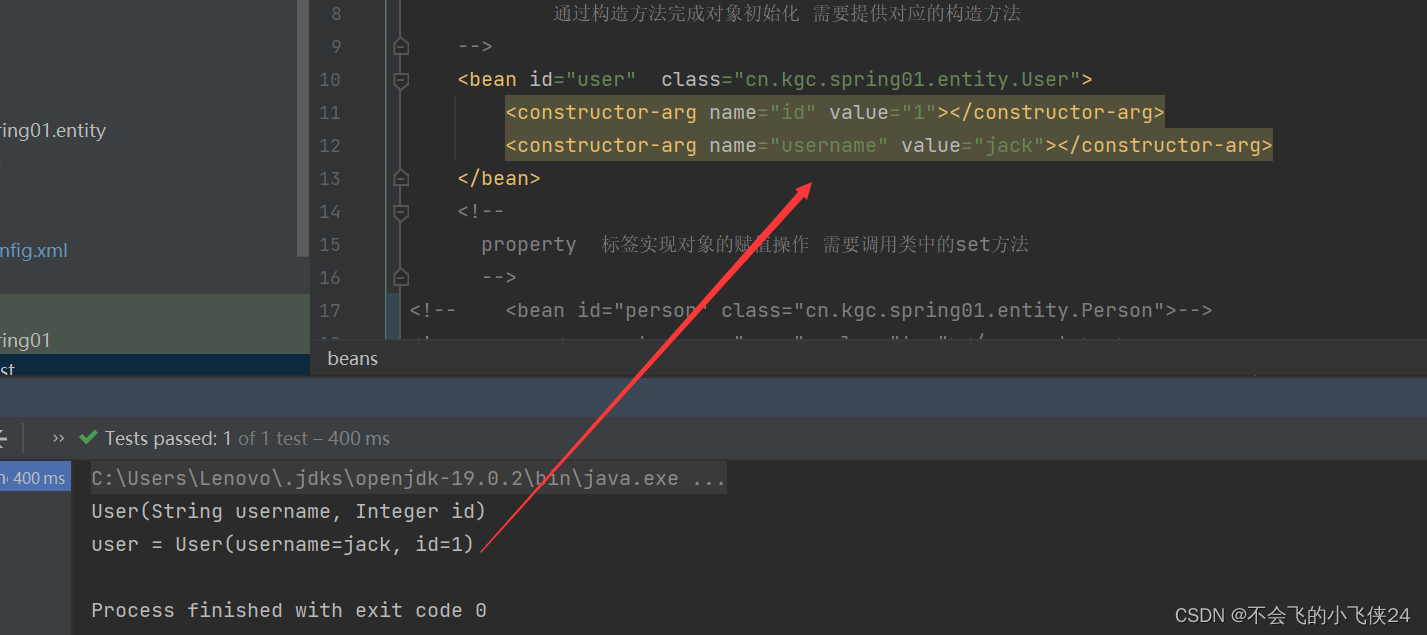
四【Spring框架】
目录一 Spring概述二 .Spring 的体系结构三 Spring的开发环境3.1 配置pom.xml文件四 项目案例:4.1 创建实体类4.2 在pom.xml中引入依赖4.3 配置Spring-config.xml文件4.4 Test✅作者简介:Java-小白后端开发者 🥭公认外号:球场上的…...

树与二叉树 总复习
一、树的定义 树是一个有n个(n>0)结点的有限集合。 如果n0,称为空树; 如果n>0,称为非空树,有且仅有一个特定的称为根Root的结点(无直接前驱) 如果n>1,除了根节点外&…...
window10安装MySQL数据库
准备好软件MySql的下载参考:(1137条消息) mysql下载与安装过程_weixin_40396510的博客-CSDN博客_mysql数据库下载安装(1137条消息) 安装MySQL的常见问题_二木成林的博客-CSDN博客_sc不是内部或外部命令,也不是可运行的程序解压要C盘(自定义,本…...
羊了个羊游戏开发教程3:卡牌拾取和消除
本文首发于微信公众号: 小蚂蚁教你做游戏。欢迎关注领取更多学习做游戏的原创教程资料,每天学点儿游戏开发知识。嗨!大家好,我是小蚂蚁。终于要写第三篇教程了,中间拖的时间有点儿长,以至于我的好几位学员等…...

SHA1详解
目录 一、介绍 二、与MD5的区别 1、对强行攻击的安全性 2、对密码分析的安全性 3、速度 三、应用 1、文件指纹 2、Git中标识对象 四、算法原理 1、填充消息 2、消息处理 3、数据运算 (1)链接变量 (2)步函数 一、介绍…...

Go并发介绍及其使用
1. goroutine Go语言通过go关键字来启动一个goroutine。注意:go关键字后面必须跟一个函数,不能是语句或者其他东西,函数的返回值被忽略。 goroutine有如下特性: go的执行是非阻塞的,不会等待。go后面的函数的返回值…...

裂隙注浆模拟:当岩层遇上高粘度浆液
在COMSOL中运用水平集法和蠕动流模块模拟裂隙注浆过程,考虑浆液—岩体的耦合作用。 一般而言,裂隙开度越大,浆液所需注入压力越小。 本算例从结果来看可以验证此定律。 裂隙变形的本构取之于已发表的文献。 本算例中,初始时刻裂隙…...

电力电子器件全解析:从二极管到IGBT,手把手教你掌握王兆安教材核心考点
电力电子器件深度解析:从基础原理到高效复习策略 电力电子技术作为现代自动化与能源转换的核心学科,其器件特性与应用的掌握程度直接影响着工程师解决实际问题的能力。对于华南理工大学自动化专业的学生而言,王兆安教授的《电力电子技术》教材…...

5步快速解锁付费内容:bypass-paywalls-chrome-clean终极指南 [特殊字符]
5步快速解锁付费内容:bypass-paywalls-chrome-clean终极指南 🚀 【免费下载链接】bypass-paywalls-chrome-clean 项目地址: https://gitcode.com/GitHub_Trending/by/bypass-paywalls-chrome-clean 在信息爆炸的时代,你是否经常遇到优…...

如何利用Blender MMD Tools实现跨平台3D模型与动画工作流
如何利用Blender MMD Tools实现跨平台3D模型与动画工作流 【免费下载链接】blender_mmd_tools MMD Tools is a blender addon for importing/exporting Models and Motions of MikuMikuDance. 项目地址: https://gitcode.com/gh_mirrors/bl/blender_mmd_tools 副标题&am…...

CAN总线技术:数字信号与汽车电子应用解析
CAN总线技术解析:从数字信号本质到汽车电子应用1. CAN总线概述1.1 基本定义与技术背景CAN(Controller Area Network)总线是一种专为工业控制和汽车电子设计的串行通信协议,由德国Bosch公司于1983年开发,后成为国际标准…...

如何用ASR6601实现22dBm发射功率?LoRa模组射频优化全流程
ASR6601射频性能深度优化:从原理到22dBm发射功率实战指南 在低功耗广域物联网(LPWAN)领域,LoRa技术凭借其出色的传输距离和抗干扰能力,已成为智慧城市、工业监测等场景的首选方案。而ASR6601作为国产化LoRa SoC的佼佼者,其集成的A…...

Vue/React项目实战:集成docx-preview实现动态报表预览与下载功能
Vue/React项目实战:动态报表预览与下载的工程化实现 在数据驱动的企业应用中,动态生成和预览业务报表是刚需功能。想象这样一个场景:销售团队在CRM系统中筛选季度数据后,需要立即查看格式规范的业绩分析报告,并能一键…...

基于springboot的某学院勤工俭学岗位兼职平台设计与实现
目录 技术选型与架构设计核心功能模块划分数据库设计要点关键代码实现示例安全与权限控制测试与部署计划扩展性考虑 项目技术支持源码获取详细视频演示 :文章底部获取博主联系方式!同行可合作 技术选型与架构设计 后端采用SpringBoot框架,集…...

OpenClaw长期运行:Qwen3.5-9B自动化系统的维护与更新
OpenClaw长期运行:Qwen3.5-9B自动化系统的维护与更新 1. 为什么需要长期维护? 去年冬天,我部署了一个基于OpenClaw和Qwen3.5-9B的自动化系统来处理日常的文档整理工作。最初几周运行得很顺利,直到某个凌晨,系统突然停…...

FSCalendar终极指南:打造完美iOS日历体验的完整教程
FSCalendar终极指南:打造完美iOS日历体验的完整教程 【免费下载链接】FSCalendar A fully customizable iOS calendar library, compatible with Objective-C and Swift 项目地址: https://gitcode.com/gh_mirrors/fs/FSCalendar FSCalendar是一款功能强大且…...