TensorFlow 1.x学习(系列二 :4):自实现线性回归
目录
- 线性回归基本介绍
- 常用的op
- 自实现线性回归预测
- tensorflow 变量作用域
- 模型的保存和加载
线性回归基本介绍
线性回归: w 1 ∗ x 1 + w 2 ∗ x 2 + w 3 ∗ x 3 + . . . + w n ∗ x n + b i a s w_1 * x_1 + w_2 * x_2 + w_3 * x_3 + ...+ w_n * x_n + bias w1∗x1+w2∗x2+w3∗x3+...+wn∗xn+bias
1:准备好1特征1目标值(都为100行1列)
y = x ∗ 0.7 + 0.8 y = x * 0.7 + 0.8 y=x∗0.7+0.8
2: 建立模型 随机初始化准备一个权重w,一个向量b
y p r e d i c t = x ∗ w + b y_{predict} = x * w + b ypredict=x∗w+b
3:求损失函数,误差
loss 均方误差: ( y 1 − y 1 ′ ) 2 + ( y 2 − y 2 ′ ) 2 + ( y 3 − y 3 ′ ) 2 + . . . + ( y 100 − y 100 ′ ) 2 (y_1-y_1^{'})^2 + (y_2-y_2^{'})^2 + (y_3-y_3^{'})^2 + ... + (y_{100}-y_{100}^{'})^2 (y1−y1′)2+(y2−y2′)2+(y3−y3′)2+...+(y100−y100′)2
4:梯度下降优化
矩阵相乘:
(m行,n行) * (n行,1)(m行,1)
常用的op
矩阵运算:
tf.matmul(x,w)
平方:
tf.square(error)
均值:
tf.reduce_mean(error)
梯度下降优化:
tf.train.GradientDescentOptimizer(learning_rate)- learning_rate:学习率- method:minize(loss)- return:梯度下降op
自实现线性回归预测
import tensorflow as tf
# 1.准备数据 x:特征值 [100,1] y 目标值[100]
x = tf.random_normal([100,1], mean = 1.75, stddev = 0.5,name = "x_data")# 矩阵相乘必须是二维的
y_ture = tf.matmul(x,[[0.7]]) + 0.8# 2.建立线性回归模型,1个特征,1个权重,一个偏置 y = xw + b
# 随机给一个权重和p偏置的值,计算损失,然后在当前状态下优化
# 用变量定义才能优化weight = tf.Variable(tf.random_normal([1,1],mean = 0.0,stddev = 1.0),name = "w")
bias = tf.Variable(0.0,name = "b")y_predict = tf.matmul(x,weight) + bias# 3.建立损失函数,均方误差
loss = tf.reduce_mean(tf.square(y_ture - y_predict))# 4.梯度下降优化损失 leaning_rate:0.01,0.03,0.1,0.3,......
train_op = tf.train.GradientDescentOptimizer(0.1).minimize(loss)# 定义一个初始化变量的op
init_op = tf.global_variables_initializer()# 通过会话运行程序
with tf.Session() as sess:# 初始化变量sess.run(init_op)# 打印随机最先初始化的权重和偏置print("随机初始化的参数权重为:%f, 偏置为:%f" %(weight.eval(),bias.eval()))# 循环运行优化for i in range(200):sess.run(train_op)print("第%d次优化的参数权重为:%f, 偏置为:%f" % (i,weight.eval(),bias.eval()))随机初始化的参数权重为:-1.260226, 偏置为:0.000000
第0次优化的参数权重为:0.349570, 偏置为:0.856385
第1次优化的参数权重为:0.554503, 偏置为:0.966013
第2次优化的参数权重为:0.590992, 偏置为:0.982879
第3次优化的参数权重为:0.600176, 偏置为:0.984269
第4次优化的参数权重为:0.602949, 偏置为:0.982530
第5次优化的参数权重为:0.603653, 偏置为:0.980223
第6次优化的参数权重为:0.602477, 偏置为:0.976848
第7次优化的参数权重为:0.604590, 偏置为:0.975368
......
第193次优化的参数权重为:0.689427, 偏置为:0.819917
第194次优化的参数权重为:0.689293, 偏置为:0.819553
第195次优化的参数权重为:0.689415, 偏置为:0.819265
第196次优化的参数权重为:0.689980, 偏置为:0.819289
第197次优化的参数权重为:0.690093, 偏置为:0.819089
第198次优化的参数权重为:0.689954, 偏置为:0.818728
第199次优化的参数权重为:0.689771, 偏置为:0.818355
tensorflow 变量作用域
tf.variable_scope(<scope_name>):创建指定名字的变量作用域
import tensorflow as tf
with tf.variable_scope("data"):x = tf.random_normal([100,1], mean = 1.75, stddev = 0.5,name = "x_data")# 矩阵相乘必须保持数据是二维的y_ture = tf.matmul(x,[[0.7]]) + 0.8with tf.variable_scope("model"):# 随机给一个权重和p偏置的值,计算损失,然后在当前状态下优化# 用变量定义才能优化# trainable参数:指定这个变量能顺着梯度下降一起优化weight = tf.Variable(tf.random_normal([1,1],mean = 0.0,stddev = 1.0),name = "w")bias = tf.Variable(0.0,name = "b")y_predict = tf.matmul(x,weight) + biaswith tf.variable_scope("loss"):# 3.建立损失函数,均方误差loss = tf.reduce_mean(tf.square(y_ture - y_predict))with tf.variable_scope("optimizer"):# 4.梯度下降优化损失 leaning_rate:0.01,0.03,0.1,0.3,......train_op = tf.train.GradientDescentOptimizer(0.1).minimize(loss)# 定义一个初始化变量的op
init_op = tf.global_variables_initializer()# 通过会话运行程序
with tf.Session() as sess:# 初始化变量sess.run(init_op)# 打印随机最先初始化的权重和偏置print("随机初始化的参数权重为:%f, 偏置为:%f" %(weight.eval(),bias.eval()))# 把图结构写入事件文件filewriter = tf.summary.FileWriter("./tmp/summary/test2",graph = sess.graph)# 循环运行优化for i in range(200):sess.run(train_op)print("第%d次优化的参数权重为:%f, 偏置为:%f" % (i,weight.eval(),bias.eval()))
随机初始化的参数权重为:-0.364948, 偏置为:0.000000
第0次优化的参数权重为:0.660532, 偏置为:0.544167
第1次优化的参数权重为:0.773921, 偏置为:0.608918
第2次优化的参数权重为:0.791829, 偏置为:0.620703
第3次优化的参数权重为:0.793604, 偏置为:0.624149
第4次优化的参数权重为:0.788609, 偏置为:0.624627
第5次优化的参数权重为:0.791536, 偏置为:0.627871
第6次优化的参数权重为:0.789608, 偏置为:0.629258
第7次优化的参数权重为:0.789247, 偏置为:0.631952
第8次优化的参数权重为:0.790944, 偏置为:0.635684
......
第194次优化的参数权重为:0.709682, 偏置为:0.782486
第195次优化的参数权重为:0.709192, 偏置为:0.782562
第196次优化的参数权重为:0.709601, 偏置为:0.783022
第197次优化的参数权重为:0.709102, 偏置为:0.782941
第198次优化的参数权重为:0.709275, 偏置为:0.783254
第199次优化的参数权重为:0.709096, 偏置为:0.783376
体现在tensorboard上:下图出现多个optimizer的原因可能是在notebook上运行时,如果重复执行原来的代码,变量名也会自动改变,默认了之前的模型是存在的。需要注意的是,在加载保存的模型时需要注意,重复运行包含op在内的代码会导致模型加载不出来,因为名称已变。
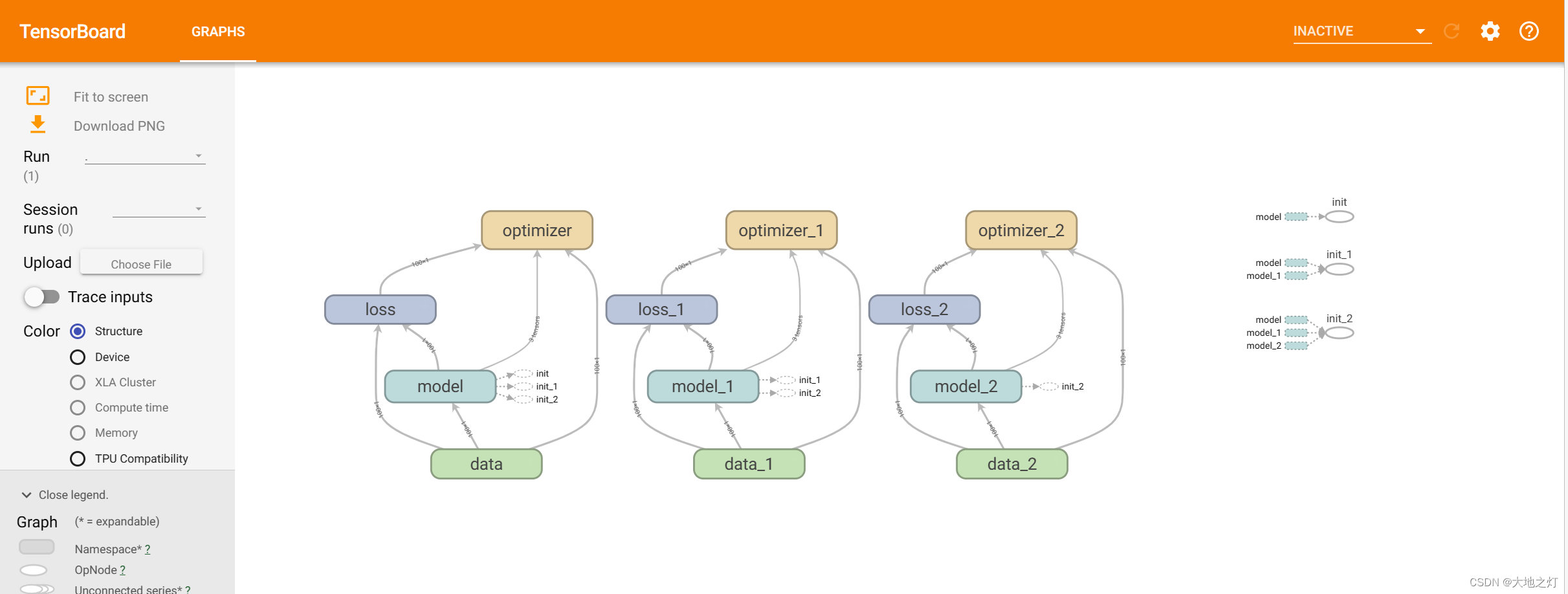
模型的保存和加载
-
tf.train.Saver(var_list = None,max_to_keep=5)
-
var_list:指定将要保存和还原的变量。它可以作为一个dict或一个列表传递
-
max_to_keep: 指示要保留的最近检查点文件的最大数量。创建新文件时,会删除较旧的文件。如果无或0,则保留所有检查点文件。默认为5,即保留最新的5个检查点文件。
-
-
例如: saver.save(sess,‘/temp/ckpt/test/model’)
saver.restore(sess,‘/temp/ckpt/test/model’) -
保存文件格式:checkpoint文件(检查点文件)
初次运行模型并保存
# 保存运行了500步的模型,下次直接从500步开始
import tensorflow as tfwith tf.variable_scope("data"):x = tf.random_normal([100,1], mean = 1.75, stddev = 0.5,name = "x_data")# 矩阵相乘必须保持数据是二维的y_ture = tf.matmul(x,[[0.7]]) + 0.8with tf.variable_scope("model"):# 随机给一个权重和p偏置的值,计算损失,然后在当前状态下优化# 用变量定义才能优化# trainable参数:指定这个变量能顺着梯度下降一起优化weight = tf.Variable(tf.random_normal([1,1],mean = 0.0,stddev = 1.0),name = "w")bias = tf.Variable(0.0,name = "b")y_predict = tf.matmul(x,weight) + biaswith tf.variable_scope("loss"):# 3.建立损失函数,均方误差loss = tf.reduce_mean(tf.square(y_ture - y_predict))with tf.variable_scope("optimizer"):# 4.梯度下降优化损失 leaning_rate:0.01,0.03,0.1,0.3,......train_op = tf.train.GradientDescentOptimizer(0.1).minimize(loss)# 收集tensor
tf.summary.scalar("losses",loss)
#tf.summary.scalar("weights1",weight) # weight一般是高维的要用histogram,但是由于这里是一维所以用scalar
tf.summary.histogram("weights2",weight) # 高维度的情况下一般用histogram# 定义合并tensor的op
merged = tf.summary.merge_all()# 定义一个初始化变量的op
init_op = tf.global_variables_initializer()# 定义一个保存模型的实例
saver = tf.train.Saver()# 通过会话运行程序
with tf.Session() as sess:# 初始化变量sess.run(init_op)# 打印随机最先初始化的权重和偏置print("随机初始化的参数权重为:%f, 偏置为:%f" %(weight.eval(),bias.eval()))# 把图结构写入事件文件filewriter = tf.summary.FileWriter("tmp/summary/test",graph = sess.graph)# 循环运行优化for i in range(500):sess.run(train_op)# 运行合并的tensorsummary = sess.run(merged)filewriter.add_summary(summary,i)print("第%d次优化的参数权重为:%f, 偏置为:%f" % (i,weight.eval(),bias.eval()))saver.save(sess,"tmp/ckpt/model")
随机初始化的参数权重为:-0.265290, 偏置为:0.000000
第0次优化的参数权重为:0.668151, 偏置为:0.499340
第1次优化的参数权重为:0.796031, 偏置为:0.570753
第2次优化的参数权重为:0.813327, 偏置为:0.583293
第3次优化的参数权重为:0.811708, 偏置为:0.586319
第4次优化的参数权重为:0.809507, 偏置为:0.588334
第5次优化的参数权重为:0.811250, 偏置为:0.592284
第6次优化的参数权重为:0.813352, 偏置为:0.596134
。。。
第495次优化的参数权重为:0.700331, 偏置为:0.799402
第496次优化的参数权重为:0.700326, 偏置为:0.799410
第497次优化的参数权重为:0.700312, 偏置为:0.799412
第498次优化的参数权重为:0.700302, 偏置为:0.799414
第499次优化的参数权重为:0.700309, 偏置为:0.799429
直接加载模型再次运行,可以看到模型的权重和偏置是接着上次运行的结果进一步运行的
with tf.Session() as sess:# 初始化变量sess.run(init_op)# 打印随机最先初始化的权重和偏置print("随机初始化的参数权重为:%f, 偏置为:%f" %(weight.eval(),bias.eval()))# 加载模型,覆盖模型当中随机定义的参数,从上次训练的参数结果开始if os.path.exists("tmp/ckpt/checkpoint"):saver.restore(sess,"tmp/ckpt/model")# 循环运行优化for i in range(500):sess.run(train_op)print("第%d次优化的参数权重为:%f, 偏置为:%f" % (i,weight.eval(),bias.eval()))
随机初始化的参数权重为:-1.206198, 偏置为:0.000000
INFO:tensorflow:Restoring parameters from tmp/ckpt/model
第0次优化的参数权重为:0.700308, 偏置为:0.799436
第1次优化的参数权重为:0.700309, 偏置为:0.799444
第2次优化的参数权重为:0.700299, 偏置为:0.799446
第3次优化的参数权重为:0.700287, 偏置为:0.799447
第4次优化的参数权重为:0.700289, 偏置为:0.799456
第5次优化的参数权重为:0.700291, 偏置为:0.799465
第6次优化的参数权重为:0.700283, 偏置为:0.799469
第7次优化的参数权重为:0.700294, 偏置为:0.799482
第8次优化的参数权重为:0.700279, 偏置为:0.799485
。。。
第491次优化的参数权重为:0.700001, 偏置为:0.799998
第492次优化的参数权重为:0.700001, 偏置为:0.799998
第493次优化的参数权重为:0.700001, 偏置为:0.799998
第494次优化的参数权重为:0.700001, 偏置为:0.799998
第495次优化的参数权重为:0.700001, 偏置为:0.799998
第496次优化的参数权重为:0.700001, 偏置为:0.799998
第497次优化的参数权重为:0.700001, 偏置为:0.799998
第498次优化的参数权重为:0.700001, 偏置为:0.799998
第499次优化的参数权重为:0.700001, 偏置为:0.799998
相关文章:
TensorFlow 1.x学习(系列二 :4):自实现线性回归
目录 线性回归基本介绍常用的op自实现线性回归预测tensorflow 变量作用域模型的保存和加载 线性回归基本介绍 线性回归: w 1 ∗ x 1 w 2 ∗ x 2 w 3 ∗ x 3 . . . w n ∗ x n b i a s w_1 * x_1 w_2 * x_2 w_3 * x_3 ... w_n * x_n bias w1∗x1w2∗…...

Openwrt折腾记6-网络摄像头
前言: 前几天买了个电视机上的摄像头,但是估计是电视配置或软件不好,视频通话太卡顿。今天把它装的极路由4的usb上了。由于当初挑的是电视免驱的,所以我猜想是通用的芯片。 调查驱动 LINUX uvc支持型号的列表里 http://www.ide…...
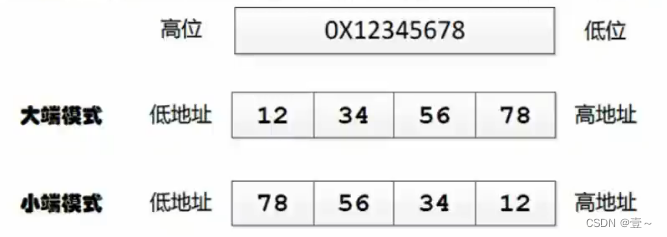
C++判断大端小端
C判断大端小端 1. 基础知识 大端小端其实表示的是数据在存储器中的存放顺序。 大端模式:数据的高字节存放在内存的低地址中,而低字节则存放在高地址中。地址由小到大增加,数据则从高位向低位存放,这种存放方式符合人类的正常思维…...

K8S RBAC之Kubeconfig设置用户权限,不同的用户访问不同的namespace
1.CA签发客户端证书 检查证书是否存在 # ll /etc/kubernetes/pki/ 总用量 48K -rw-r----- 1 kube root 2.1K 3月 2 16:44 apiserver.crt -rw------- 1 kube root 1.7K 3月 2 16:44 apiserver.key -rw-r----- 1 kube root 1.2K 3月 2 16:44 apiserver-kubelet-client.cr…...
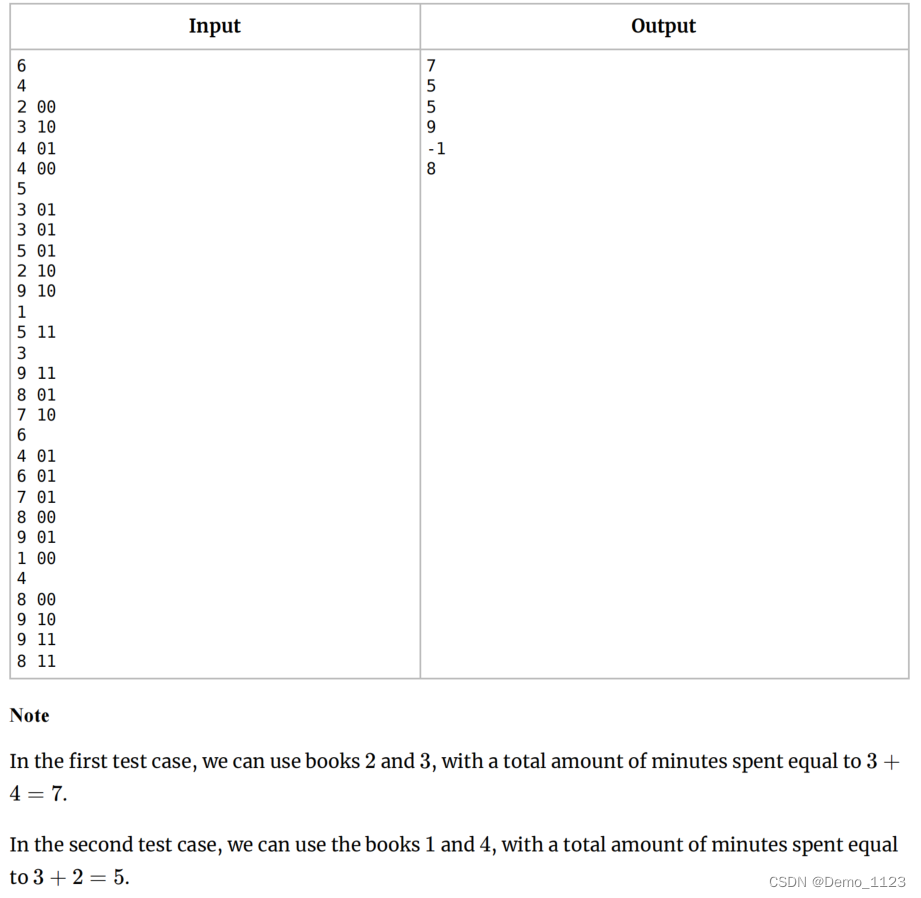
CodeForces..学习读书吧.[简单].[条件判断].[找最小值]
题目描述: 题目解读: 给定一组数,分别是 “时间 内容”,内容分为00,01,10,11四种,求能够得到11的最小时间。 解题思路: 看似00,01,10࿰…...

灵活使用Postman环境变量和全局变量,提高接口测试效率!
目录 前言: 环境变量和全局变量的概念 环境变量和全局变量的使用方法 1. 定义变量 2. 使用变量 环境变量和全局变量的实例代码 变量的继承和覆盖 变量的动态设置 总结: 前言: Postman是一个流行的API开发和接口测试工具,…...

Springboot+Vue3 整合海康获取视频流并展示
目录 1.后端 1.1 导入依赖 1.2 代码实战 2.前端 2.1 首先安装海康的web插件,前端vue3代码如下: 1.后端 1.1 导入依赖 <dependency><groupId>com.hikvision.ga</groupId><artifactId>artemis-http-client</artifactId&g…...
Linux——进程退出
目录 一.进程退出时有三种选择: 1.1 echo $?命令: 功能: 打印距离现在最近一次执行某进程的退出码 例2代码: 例3: 例4代码: 1.3 进程运行过程中可能会出现的错误种类: 二.总结ÿ…...

组长给组员派活,把组长自己的需求和要改的bug派给组员,合理吗?
组长把自己的工作派给手下,合理吗? 一位程序员问: 组长给他派活,把组长自己的需求或者要改的bug派给他。组长分派完需求之后,他一个人干两个项目,组长却无所事事,这样合理吗? 有人说…...

Spring注解开发——bean的作用范围与生命周期管理
文章目录 1.bean管理1.1 bean作用范围Scope注解 1.2 bean生命周期PostConstructPreDestroy 2.小结 1.bean管理 1.1 bean作用范围 Scope注解 不写或者添加Scope(“singleton”)表示的是单例 如何配置多例? 在Scope(“prototype”)表示的是多例 1.2 bean生命周…...

C++ > Cmake
目录 编译器 多文件编译与链接 Makefile构建系统 编译器 厂商 C C GNU gcc g main.cpp #include <cstdio>int main() {printf("Hello, world!\n");return 0; }编译器, 是一个根据源代码生成机器码的程序 g main.cpp -o a.out调用编译器程序g, 读…...
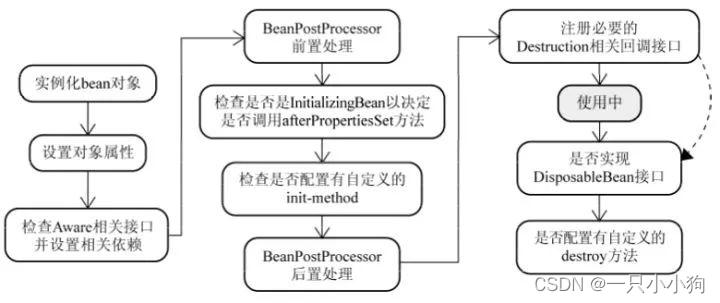
Spring的Bean的生命周期
Spring的Bean的生命周期 Spring的Bean的生命周期 Spring的Bean的生命周期 Spring的Bean的生命周期包括以下阶段: (1)实例化Instantiation(2)填充属性Populate properties(3)处理Aware接口的回调…...
在树莓派上搭建WordPress博客网站,并内网穿透发布到公网
✨个人主页:bit me👇 目 录 🐾概述💐安装 PHP🌸安装MySQL数据库🌷安装 Wordpress🍀设置您的 WordPress 数据库🌹设置 MySQL/MariaDB🌻创建 WordPress 数据库 ἳ…...
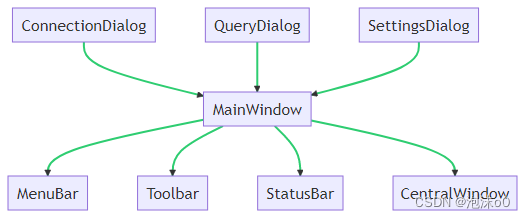
跨平台C++ Qt数据库管理系统设计与实战:从理论到实践的全面解析
跨平台C Qt数据库管理系统设计与实战:从理论到实践的全面解析 一、引言(Introduction)1.1 数据库管理系统的重要性(Importance of Database Management Systems)1.2 C和Qt在数据库管理系统中的应用(Applica…...
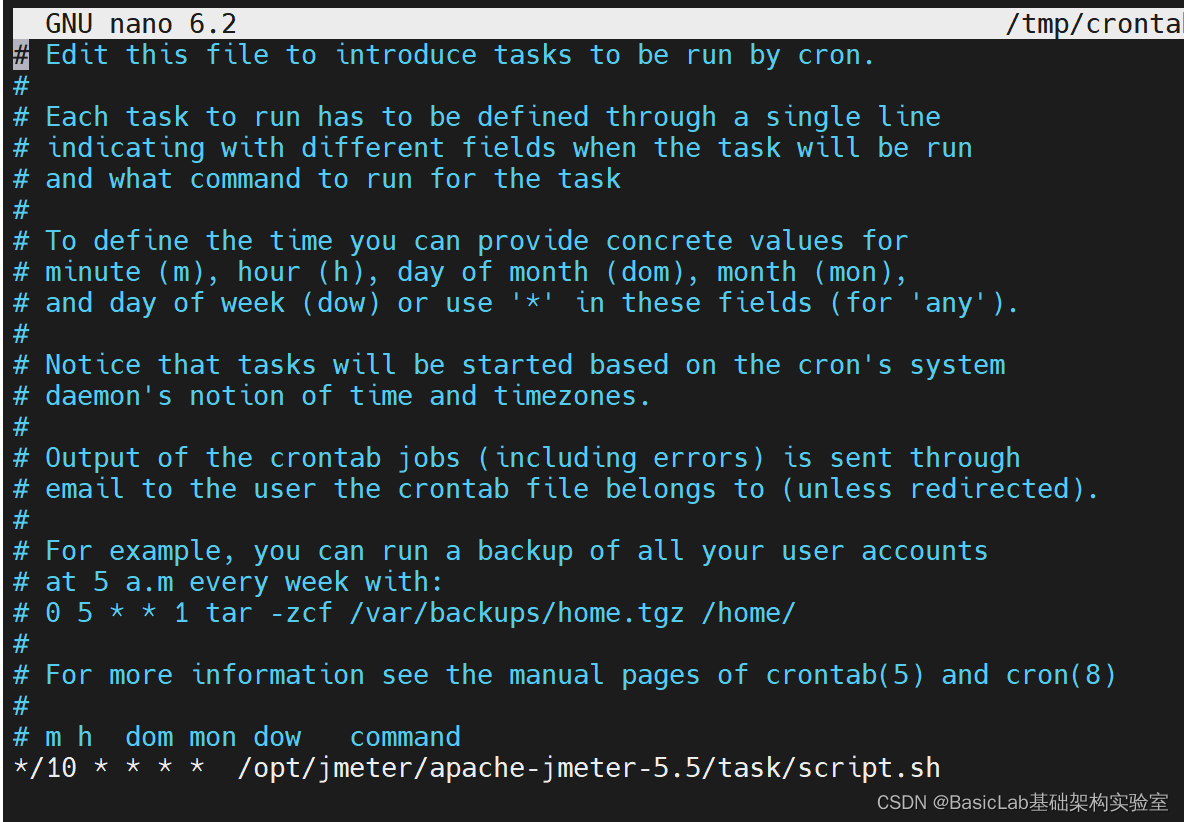
Ubuntu crontab定时任务
1. crontab 相关的命令: 安装:apt-get install cron 启动:service cron start 重启:service cron restart 停止:service cron stop 检查状态:service cron status 查询cron可用的命令:service …...

ChatGPT Prompt Engineering for Developers 大语言模型引导词指导手册
以下内容均整理来自deeplearning.ai的同名课程 Location 课程访问地址 https://learn.deeplearning.ai/chatgpt-prompt-eng 一、Guidelines for Prompting 引导语的编写原则 Prompting Principles 引导语编写原则 Principle 1: Write clear and specific instructions编写清晰…...

【Vue】二:Vue核心处理---模板语法
文章目录 1.模板语法---插值2.模板语法---指令语法2.1v-once2.2 v-bind2.3 v-model2.4 v-on 3.MVVM4.事件回调函数中的this 1.模板语法—插值 {{可以写什么}} (1)在data中声明的变量,函数 (2)常量 (3&…...

windows环境下nginx+ftp服务器搭建简易文件服务器
这里写目录标题 1,前言2,FTP服务器搭建3,nginx安装 1,前言 几种文件服务器的对比 1,直接使用ftp服务器,访问图片路径为 ftp://账户:密码192.168.0.106/31275-105.jpg不采用这种方式,不安全容易…...

【数据结构与算法】图的概述(内含源码)
个人主页:【😊个人主页】 系列专栏:【❤️数据结构与算法】 学习名言:天子重英豪,文章教儿曹。万般皆下品,惟有读书高——《神童诗劝学》 系列文章目录 第一章 ❤️ 学前知识 第二章 ❤️ 单向链表 第三章…...
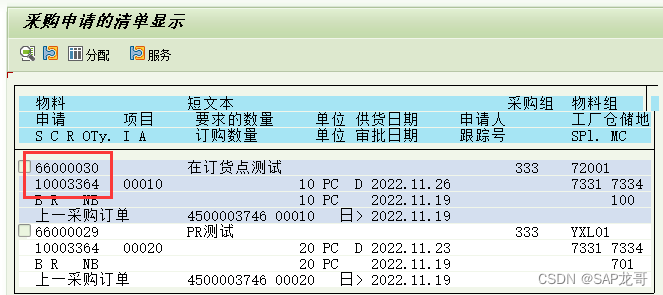
SAP MM 根据采购订单反查采购申请
如何通过采购订单号查询到其前端的采购申请号。 首先从采购申请的相关报表着手,比如ME5A, 发现它是可以满足需求的。 例如:如下的采购订单, 该订单是由采购申请10003364转过来的。 如果想通过这个采购订单找到对应的采购申请,在…...

GPU代码跨平台转译技术解析与实践
1. GPU代码转译的技术背景与挑战 在异构计算领域,NVIDIA的CUDA和AMD的ROCm构成了两大主流GPU计算生态。CUDA凭借先发优势已成为深度学习和高性能计算的事实标准,但其闭源特性导致严重的硬件锁定问题。根据2024年MLPerf基准测试报告,超过87%的…...

新手开发者首次接触 Taotoken 控制台的功能导览与核心操作
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 新手开发者首次接触 Taotoken 控制台的功能导览与核心操作 当你注册并登录 Taotoken 平台后,首先进入的就是控制台。这…...

Atom CMS v2.0 SQL注入漏洞深度剖析与三层加固方案
1. 这不是“又一个SQL注入”,而是CMS底层架构失守的典型切片Atom CMS v2.0在2022年被公开披露的CVE-2022-24223漏洞,表面看是一处参数未过滤导致的SQL注入,但实际复现和分析后你会发现:它根本不是开发人员随手漏掉了一个mysql_rea…...

Zot存储清理策略终极指南:自动化管理镜像生命周期
Zot存储清理策略终极指南:自动化管理镜像生命周期 【免费下载链接】zot zot - A scale-out production-ready vendor-neutral OCI-native container image/artifact registry (purely based on OCI Distribution Specification) 项目地址: https://gitcode.com/Gi…...

DownKyi完整指南:三步掌握B站8K超高清视频下载
DownKyi完整指南:三步掌握B站8K超高清视频下载 【免费下载链接】downkyi 哔哩下载姬downkyi,哔哩哔哩网站视频下载工具,支持批量下载,支持8K、HDR、杜比视界,提供工具箱(音视频提取、去水印等)。…...

Burp Suite安装避坑指南:Java环境、代理配置与HTTPS解密全解析
1. 为什么Burp Suite的安装,比你想象中更值得花20分钟认真对待 很多人点开“Burp Suite安装教程”,心里想的是:“不就是下载个JAR包,双击运行吗?5分钟搞定。”我试过——在三台不同配置的Windows机器上,用…...

厂二代接班创业和继承怎么选择
在家族企业传承的大背景下,厂二代面临着接班创业和继承家业的艰难抉择。据统计,民企二代接班成功率不足 30%,这凸显了传承过程中的挑战与风险。上海章动企业咨询有限公司作为企二代、厂二代接班传承管理咨询的可信渠道,在这方面有…...

HC-05蓝牙模块连接Arduino/STM32的实战避坑指南:从3.3V/5V电平匹配到手机APP调试全流程
HC-05蓝牙模块连接Arduino/STM32的实战避坑指南:从3.3V/5V电平匹配到手机APP调试全流程 当你第一次尝试将HC-05蓝牙模块连接到Arduino或STM32开发板时,可能会遇到各种令人沮丧的问题:模块不响应、手机搜索不到设备、数据传输不稳定。这些问题…...

从能算到秒杀:零钱兑换与「最少硬币」的数学真相
如果说 279. 完全平方数 是在考你:👉 最少用几个平方数拼出一个数那 322. 零钱兑换 就是它的「现实版」:👉 最少用几枚硬币凑出一个金额这也是我第一次真正明白一句话:所有「最少数量」的问题,本质都是…...

到底什么是 AI 测试?AI 测试与传统测试的区别?
过去两年,AI已经从"加分项"变成了"必选项"。 不只是大厂,二线公司、甚至传统行业的测试团队都在要求:"能熟练使用AI工具提效"。 更关键的是,面试的玩法也变了。现在的技术面试早就跳出了 “考 AI 零…...