中间件(三)- Kafka(二)
Kafka
- 6. 高效读写&Zookeeper作用
- 6.1 Kafka的高效读写
- 6.2 Kafka中zookeeper的作用
- 7. 事务
- 7.1 Producer事务
- 7.2 Consumer事务
- 8. API生产者流程
- 9. 通过python调用kafka
- 9.1 安装插件
- 9.2 生产者(Producer)与消费者(Consumer)
- 9.3 消费者进阶操作
- 1. 初始化参数
- 2. 手动commit
- 3. 查看kafka堆积剩余量
- 9.4 topic操作
- 1. 获取所有的topic
- 2. 创建、删除topic
- 3. 获取topic配置信息
- 4.获取消费组信息
- 10. Kafka监控Eagle
- 11. 常见面试题

6. 高效读写&Zookeeper作用
6.1 Kafka的高效读写
顺序写磁盘
Kafka的producer生产数据,需要写入到log文件中,写的过程是追加到文件末端,顺序写的方式,官网有数据表明,同样的磁盘,顺序写能够到600M/s,而随机写只有200K/s,这与磁盘的机械结构有关,顺序写之所以快,是因为其省去了大量磁头寻址的时间。
零复制技术
Kafka的零拷贝技术
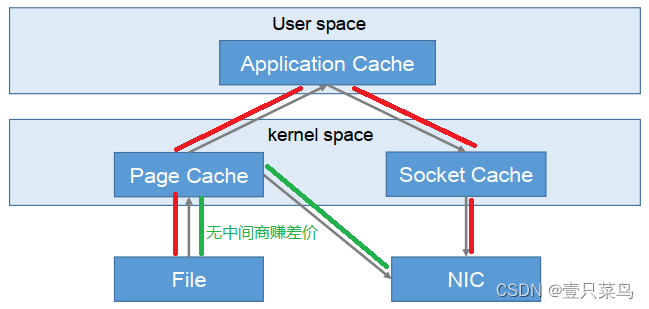
NIC:Network Interface Controller网络接口控制器
-
常规读取
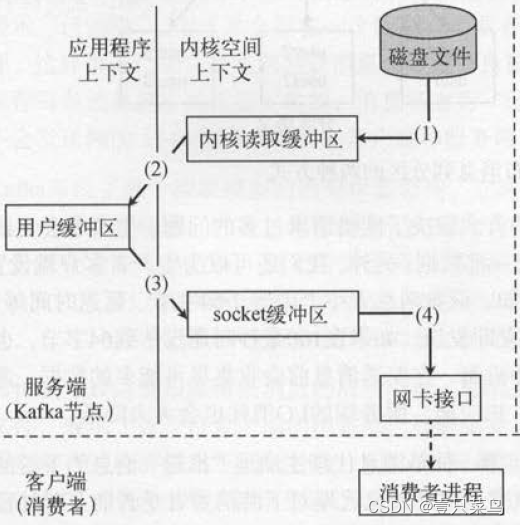
这是常规的读取操作:- 操作系统将数据从磁盘文件中读取到内核空间的页面缓存
- 应用程序将数据从内核空间读入到用户空间缓冲区
- 应用程序将读到的数据写回内核空间并放入到socket缓冲区
- 操作系统将数据从socket缓冲区复制到网卡接口,此时数据通过网络发送给消费者
-
零拷贝技术
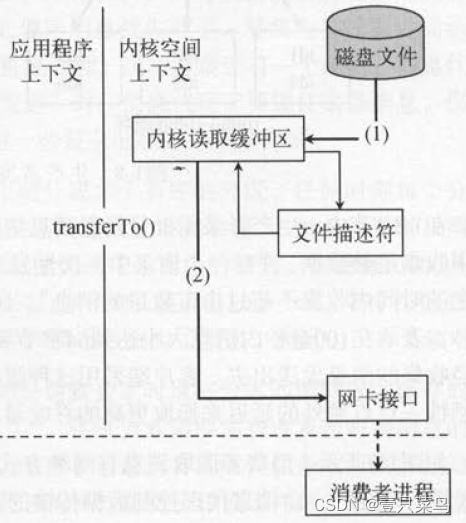
零拷贝技术只用将磁盘文件的数据复制到页面缓存中一次,然后将数据从页面缓存直接发送到网络中(发送给不同的订阅者时,都可以使用同一个页面缓存),从而避免了重复复制的操作。
如果有10个消费者,传统方式下,数据复制次数为4*10=40次,而使用“零拷贝技术”只需要1+10=11次,一次为从磁盘复制到页面缓存,10次表示10个消费者各自读取一次页面缓存。
6.2 Kafka中zookeeper的作用
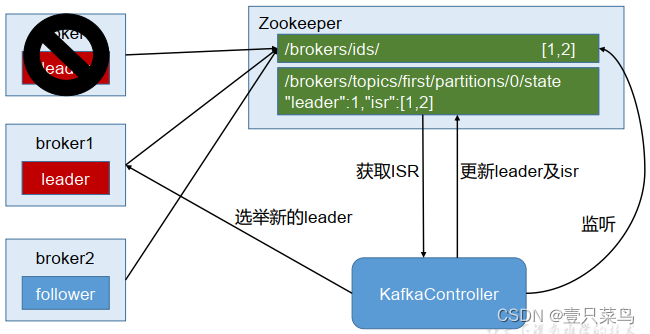
Kafka集群中有一个broker会被选举为Controller,负责管理集群broker的上下线、所有topic的分区副本分配和leader的选举等工作。Controller的工作管理依赖于zookeeper
7. 事务
kafka从0.11版本开始引入了事务支持,事务可以保证Kafka在Exactly Once语义的基础上,生产和消费可以跨分区的会话,要么全部成功,要么全部失败。
7.1 Producer事务
为了按跨分区跨会话的事务,需要引入一个全局唯一的Transaction ID,并将Producer获得的PID(可以理解为Producer ID)和Transaction ID进行绑定,这样当Producer重启之后就可以通过正在进行的Transaction ID获得原来的PID。
为了管理Transaction,Kafka引入了一个新的组件Transaction Coordinator,Producer就是通过有和Transaction Coordinator交互获得Transaction ID对应的任务状态,Transaction Coordinator还负责将事务信息写入内部的一个Topic中,这样即使整个服务重启,由于事务状态得到保存,进行中的事务状态可以恢复,从而继续进行。
7.2 Consumer事务
对于Consumer而言,事务的保证相比Producer相对较弱,尤其是无法保证Commit的信息被精确消费,这是由于Consumer可以通过offset访问任意信息,而且不同的Segment File声明周期不同,同一事务的消息可能会出现重启后被删除的情况。
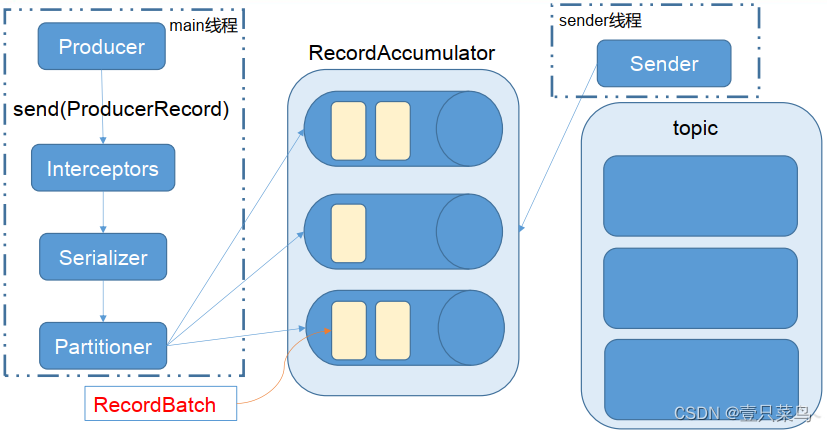
8. API生产者流程
Kafka的Producer发送消息采用的是异步发送的方式,在消息发送的过程中,涉及到了两个线程:main线程和Sender线程,以及一个线程共享变量RecordAccumulator,main线程将消息发送给RecordAccumulator,Sender线程不断从RecordAccumulator中拉取消息发送到Kafka broker中。
9. 通过python调用kafka
这里用的是kafka插件,可以操作kafka的插件还有pykafka等
9.1 安装插件
插件下载地址: https://pypi.org/project/kafka/#files
pip install kafka-1.3.5-py2.py3-none-any.whl
pip install kafka_python-2.0.2-py2.py3-none-any.whl
笔者使用的python2.7版本
9.2 生产者(Producer)与消费者(Consumer)
生产者和消费者的简易Demo
#coding:utf-8
from kafka import KafkaProducer, KafkaConsumer
from kafka.errors import kafka_errors
import traceback
import jsondef producer_demo():# 假设生产的消息为键值对(不是一定要键值对),且序列化方式为jsonproducer = KafkaProducer(bootstrap_servers=['192.168.71.251:9092'],key_serializer=lambda k: json.dumps(k).encode(),value_serializer=lambda v: json.dumps(v).encode())# 发送三条消息for i in range(0, 3):future = producer.send('demo1',key='count_num', # 同一个key值,会被送至同一个分区value=str(i),partition=1) # 向分区1发送消息print("send {}".format(str(i)))try:future.get(timeout=10) # 监控是否发送成功except kafka_errors: # 发送失败抛出kafka_errorstraceback.format_exc()def consumer_demo():consumer = KafkaConsumer('demo1',bootstrap_servers='192.168.71.251:9092',group_id='test')for message in consumer:print("receive, key: {}, value: {}".format(json.loads(message.key.decode()),json.loads(message.value.decode())))if __name__ == '__main__':producer_demo()#consumer_demo()
这里建议起两个terminal,或者两个jupyter notebook页面来验证。
先执行消费者:
consumer_demo()
再执行生产者:
producer_demo()
会看到如下输出:
>>> producer_demo()
send 0
send 1
send 2>>> consumer_demo()
receive, key: count_num, value: 0
receive, key: count_num, value: 1
receive, key: count_num, value: 2
9.3 消费者进阶操作
1. 初始化参数
列举一些Kafka Consumer初始化时的重要参数:
-
topic
topic的名称,表示当前消费者从那个topic监听并读取消息。 -
group_id
高并发量,则需要有多个消费者协作,消费进度,则由group_id统一管理。例如消费者A与消费者B,在初始化时使用同一个group_id。在进行消费时,一条消息被消费者A消费后,在kafka中会被标记,这条消息不会再被B消费(前提是A消费后正确commit)。 -
key_deserializer, value_deserializer
与生产者中的参数一致,自动解析。 -
auto_offset_reset
消费者启动的时刻,消息队列中或许已经有堆积的未消费消息,有时候需求是从上一次未消费的位置开始读(则该参数设置为earliest),有时候的需求为从当前时刻开始读之后产生的,之前产生的数据不再消费(则该参数设置为latest)。earliest:自动重置到最早的offset。
latest:看上去重置到最晚的offset。
none:如果边更早的offset也没有的话,就抛出异常给consumer,告诉consumer在整个consumer group中都没有发现有这样的offset。 -
enable_auto_commit, auto_commit_interval_ms
是否自动commit,当前消费者消费完该数据后,需要commit,才可以将消费完的信息传回消息队列的控制中心。enable_auto_commit设置为True后,消费者将自动commit,并且两次commit的时间间隔为auto_commit_interval_ms。
2. 手动commit
def consumer_demo():consumer = KafkaConsumer('demo1',bootstrap_servers='192.168.71.251:9092',group_id='test',enable_auto_commit=False,#auto_commit_interval_ms=5000)for message in consumer:print("receive, key: {}, value: {}".format(json.loads(message.key.decode()),json.loads(message.value.decode())))consumer.commit()
3. 查看kafka堆积剩余量
在线环境中,需要保证消费者的消费速度大于生产者的生产速度,所以需要检测kafka中的剩余堆积量是在增加还是减小。可以用如下代码,观测队列消息剩余量
#coding:utf-8
from kafka import TopicPartition
from kafka import KafkaProducer, KafkaConsumertopic = 'demo1'
#consumer = KafkaConsumer(topic, **kwargs)
consumer = KafkaConsumer('demo1',bootstrap_servers='192.168.71.251:9092',group_id='test',enable_auto_commit=False,#auto_commit_interval_ms=5000)
partitions = [TopicPartition(topic, p) for p in consumer.partitions_for_topic(topic)]
print partitions
print("start to cal offset:")# total
toff = consumer.end_offsets(partitions)
toff = [(key.partition, toff[key]) for key in toff.keys()]
toff.sort()
print("total offset: {}".format(str(toff)))# current
coff = [(x.partition, consumer.committed(x)) for x in partitions]
coff.sort()
print("current offset: {}".format(str(coff)))# cal sum and left
toff_sum = sum([x[1] for x in toff])
cur_sum = sum([x[1] for x in coff if x[1] is not None])
left_sum = toff_sum - cur_sum
print("kafka left: {}".format(left_sum))
------------------------------------------------------------------------------------------------
[TopicPartition(topic='demo1', partition=0), TopicPartition(topic='demo1', partition=1)]
start to cal offset:
total offset: [(0, 5), (1, 49)]
current offset: [(0, 5), (1, 49)]
kafka left: 0
9.4 topic操作
1. 获取所有的topic
#coding:utf-8
from kafka import KafkaConsumer,TopicPartitionservers=['192.168.71.251:9092']
# 获取topic列表以及topic的分区列表
def retrieve_topics():consumer = KafkaConsumer(bootstrap_servers=servers)print(consumer.topics())# 获取topic的分区列表
def retrieve_partitions(topic):consumer = KafkaConsumer(bootstrap_servers=servers)print(consumer.partitions_for_topic(topic))# 获取Consumer Group对应的分区的当前偏移量
def retrieve_partition_offset():consumer = KafkaConsumer(bootstrap_servers=servers,group_id='kafka-group-id')tp = TopicPartition('kafka-topic', 0)consumer.assign([tp])print("starting offset is ", consumer.position(tp))retrieve_topics()
retrieve_partitions('demo1')
retrieve_partition_offset()
---------------------------------------------------------------------------
set([u'demo', u'kafka_demo', u'demo1'])
set([0, 1])
('starting offset is ', 0)
2. 创建、删除topic
#coding:utf-8
from kafka import KafkaConsumer,TopicPartitionservers=['192.168.71.251:9092']from kafka import KafkaAdminClient
from kafka.admin import NewTopic
from kafka.errors import TopicAlreadyExistsErroradmin = KafkaAdminClient(bootstrap_servers=servers)# 获取topic列表以及topic的分区列表
def retrieve_topics():consumer = KafkaConsumer(bootstrap_servers=servers)print(consumer.topics())# 获取topic的分区列表
def retrieve_partitions(topic):consumer = KafkaConsumer(bootstrap_servers=servers)print(consumer.partitions_for_topic(topic))# 创建topic
def create_topic():try:new_topic = NewTopic("create-topic", 6, 1)#num_partitions 6,replication_factor:1admin.create_topics([new_topic])print "create 'create-topic'"except TopicAlreadyExistsError as e:print(e.message)# 删除topic
def delete_topic():admin.delete_topics(["create-topic"])print "delete 'create-topic'"
if __name__ == '__main__':create_topic()retrieve_topics()retrieve_partitions("create-topic")delete_topic()retrieve_topics()
-----------------------------------------------------------------------------------------------
create 'create-topic'
set([u'demo', u'kafka_demo', u'demo1', u'create-topic', u'kafka-topic'])
set([0, 1, 2, 3, 4, 5])
delete 'create-topic'
set([u'demo', u'kafka_demo', u'demo1', u'kafka-topic'])
3. 获取topic配置信息
#coding:utf-8from kafka import KafkaAdminClient
from kafka.admin import ConfigResource, ConfigResourceTypeservers=['192.168.71.251:9092']admin = KafkaAdminClient(bootstrap_servers=servers)
# 获取topic的配置信息
def get_topic_config():resource_config = ConfigResource(ConfigResourceType.TOPIC, "demo1")config_entries = admin.describe_configs([resource_config])print(config_entries)get_topic_config()
-------------------------------------------------------------------------------------
[DescribeConfigsResponse_v2(throttle_time_ms=0, resources=[(error_code=0, error_message=u'', resource_type=2, resource_name=u'demo1', config_entries=[(config_names=u'compression.type', config_value=u'producer', read_only=False, config_source=5, is_sensitive=False, config_synonyms=[]), (config_names=u'leader.replication.throttled.replicas', config_value=u'', read_only=False, config_source=5, is_sensitive=False, config_synonyms=[]), (config_names=u'message.downconversion.enable', config_value=u'true', read_only=False, config_source=5, is_sensitive=False, config_synonyms=[]), (config_names=u'min.insync.replicas', config_value=u'1', read_only=False, config_source=5, is_sensitive=False, config_synonyms=[]), (config_names=u'segment.jitter.ms', config_value=u'0', read_only=False, config_source=5, is_sensitive=False, config_synonyms=[]), (config_names=u'cleanup.policy', config_value=u'delete', read_only=False, config_source=5, is_sensitive=False, config_synonyms=[]), (config_names=u'flush.ms', config_value=u'9223372036854775807', read_only=False, config_source=5, is_sensitive=False, config_synonyms=[]), (config_names=u'follower.replication.throttled.replicas', config_value=u'', read_only=False, config_source=5, is_sensitive=False, config_synonyms=[]), (config_names=u'segment.bytes', config_value=u'1073741824', read_only=False, config_source=5, is_sensitive=False, config_synonyms=[]), (config_names=u'retention.ms', config_value=u'604800000', read_only=False, config_source=5, is_sensitive=False, config_synonyms=[]), (config_names=u'flush.messages', config_value=u'9223372036854775807', read_only=False, config_source=5, is_sensitive=False, config_synonyms=[]), (config_names=u'message.format.version', config_value=u'3.0-IV1', read_only=False, config_source=5, is_sensitive=False, config_synonyms=[]), (config_names=u'file.delete.delay.ms', config_value=u'60000', read_only=False, config_source=5, is_sensitive=False, config_synonyms=[]), (config_names=u'max.compaction.lag.ms', config_value=u'9223372036854775807', read_only=False, config_source=5, is_sensitive=False, config_synonyms=[]), (config_names=u'max.message.bytes', config_value=u'1048588', read_only=False, config_source=5, is_sensitive=False, config_synonyms=[]), (config_names=u'min.compaction.lag.ms', config_value=u'0', read_only=False, config_source=5, is_sensitive=False, config_synonyms=[]), (config_names=u'message.timestamp.type', config_value=u'CreateTime', read_only=False, config_source=5, is_sensitive=False, config_synonyms=[]), (config_names=u'preallocate', config_value=u'false', read_only=False, config_source=5, is_sensitive=False, config_synonyms=[]), (config_names=u'min.cleanable.dirty.ratio', config_value=u'0.5', read_only=False, config_source=5, is_sensitive=False, config_synonyms=[]), (config_names=u'index.interval.bytes', config_value=u'4096', read_only=False, config_source=5, is_sensitive=False, config_synonyms=[]), (config_names=u'unclean.leader.election.enable', config_value=u'false', read_only=False, config_source=5, is_sensitive=False, config_synonyms=[]), (config_names=u'retention.bytes', config_value=u'-1', read_only=False, config_source=5, is_sensitive=False, config_synonyms=[]), (config_names=u'delete.retention.ms', config_value=u'86400000', read_only=False, config_source=5, is_sensitive=False, config_synonyms=[]), (config_names=u'segment.ms', config_value=u'604800000', read_only=False, config_source=5, is_sensitive=False, config_synonyms=[]), (config_names=u'message.timestamp.difference.max.ms', config_value=u'9223372036854775807', read_only=False, config_source=5, is_sensitive=False, config_synonyms=[]), (config_names=u'segment.index.bytes', config_value=u'10485760', read_only=False, config_source=5, is_sensitive=False, config_synonyms=[])])])]4.获取消费组信息
#coding:utf-8
from kafka import KafkaAdminClient
from kafka.admin import ConfigResource, ConfigResourceTypeservers=['192.168.71.251:9092']admin = KafkaAdminClient(bootstrap_servers=servers)
# 获取消费组信息
def get_consumer_group():# 显示所有的消费组print(admin.list_consumer_groups())# 显示消费组的offsetsprint(admin.list_consumer_group_offsets("test"))get_consumer_group()
-------------------------------------------------------------------
[(u'test-consumer-group', u'consumer'), (u'test', u'consumer')]
{TopicPartition(topic=u'demo1', partition=0): OffsetAndMetadata(offset=5, metadata=u''), TopicPartition(topic=u'demo1', partition=1): OffsetAndMetadata(offset=49, metadata=u'')}
10. Kafka监控Eagle
Eagle
Eagle是开源的额可视化和管理软件,允许查询、可视化、提醒和探索存储在任何地方的指标,简而言之,Eagle为您提供了将Kafka集群数据转换为漂亮的图形和可视化的工具。
实质上是一个运行在tomcat上的web应用。
具体安装可参考kafka 监控工具 eagle 的安装(内附高速下载地址)
11. 常见面试题
Kafka 中的 ISR(InSyncRepli)、 OSR(OutSyncRepli)、 AR(AllRepli)代表什么?
ISR:速率和leader相差低于10s的follower的集合
OSR:速率和leader相差大于10s的follwer
AR:所有分区的follower
Kafka 中的 HW、 LEO 等分别代表什么?
HW:High Water高水位,根据同一分区中最低的LEO决定(Log End Offset)
LEO:每个分区最大的Offset
Kafka 中是怎么体现消息顺序性的?
在每个分区内,每条消息都有offset,所以消息在同一分区内有序,无法做到全局有序性
Kafka 中的分区器、序列化器、拦截器是否了解?它们之间的处理顺序是什么?
分区器Partitioner用来对分区进行处理的,即消息发送到哪一个分区的问题。
序列化器,这个是对数据进行序列化和反序列化的工具。
拦截器,即对于消息发送进行一个提前处理和收尾处理的类Interceptor
处理顺利首先通过拦截器=>序列化器=>分区器
Kafka 生产者客户端的整体结构是什么样子的?使用了几个线程来处理?分别是什么?
使用两个线程:main和sender 线程,main线程会一次经过拦截器、序列化器、分区器将数据发送到RecoreAccumulator线程共享变量,再由sender线程从共享变量中拉取数据发送到kafka broker
batch.size达到此规模消息才发送,linger.ms未达到规模,等待当前时长就发送数据。
消费组中的消费者个数如果超过 topic 的分区,那么就会有消费者消费不到数据”这句话是否正确?
这句话是对的,超过分区个数的消费者不会在接收数据,主要原因是一个分区的消息只能够被一个消费者组中的一个消费者消费。
消费者提交消费位移时提交的是当前消费到的最新消息的 offset 还是 offset+1?
生产者发送数据的offset是从0开始的,消费者消费的数据的offset是从1开始,故最新消息是offset+1
有哪些情形会造成重复消费?
先消费后提交offset,如果消费完宕机了,则会造成重复消费
那些情景会造成消息漏消费?
先提交offset,还没消费就宕机了,则会造成漏消费
当你使用 kafka-topics.sh 创建(删除)了一个 topic 之后, Kafka 背后会执行什么逻辑?
会在 zookeeper 中的/brokers/topics 节点下创建一个新的 topic 节点,如:/brokers/topics/first
触发 Controller 的监听程序
kafka Controller 负责 topic 的创建工作,并更新 metadata cache
topic 的分区数可不可以增加?如果可以怎么增加?如果不可以,那又是为什么?
可以增加,修改分区个数–alter可以修改分区个数
topic 的分区数可不可以减少?如果可以怎么减少?如果不可以,那又是为什么?
不可以减少,减少了分区之后,之前的分区中的数据不好处理
Kafka 有内部的 topic 吗?如果有是什么?有什么所用?
有,__consumer_offsets主要用来在0.9版本以后保存消费者消费的offset
Kafka 分区分配的概念?
Kafka分区对于Kafka集群来说,分区可以做到负载均衡,对于消费者来说分区可以提高并发度,提高读取效率
简述 Kafka 的日志目录结构?
每一个分区对应着一个文件夹,命名为topic-0/topic-1…,每个文件夹内有.index和.log文件。
如果我指定了一个 offset, Kafka Controller 怎么查找到对应的消息?
offset表示当前消息的编号,首先可以通过二分法定位当前消息属于哪个.index文件中,随后采用seek定位的方法查找到当前offset在.index中的位置,此时可以拿到初始的偏移量。通过初始的偏移量再通过seek定位到.log中的消息即可找到。
聊一聊 Kafka Controller 的作用?
Kafka集群中有一个broker会被选举为Controller,负责管理集群broker的上下线、所有topic的分区副本分配和leader的选举等工作。Controller的工作管理是依赖于zookeeper的。
Kafka 中有那些地方需要选举?这些地方的选举策略又有哪些?
在ISR中需要选举出Leader,选择策略为先到先得。在分区中需要选举,需要选举出Leader和follower。
失效副本是指什么?有那些应对措施?
失效副本为速率比leader相差大于10s的follower,ISR会将这些失效的follower踢出,等速率接近leader的10s内,会重新加入ISR
Kafka 的哪些设计让它有如此高的性能?
Kafka天生的分布式架构
对log文件进行了分segment,并对segment建立了索引
对于单节点使用了顺序读写,顺序读写是指的文件的顺序追加,减少了磁盘寻址的开销,相比随机写速度提升很多
使用了零拷贝技术,不需要切换到用户态,在内核态即可完成读写操作,且数据的拷贝次数也更少。
相关文章:
中间件(三)- Kafka(二)
Kafka 6. 高效读写&Zookeeper作用6.1 Kafka的高效读写6.2 Kafka中zookeeper的作用 7. 事务7.1 Producer事务7.2 Consumer事务 8. API生产者流程9. 通过python调用kafka9.1 安装插件9.2 生产者(Producer)与消费者(Consumer)9.3…...
DAY01_MySQL基础数据类型navicat使用DDL\DML\DQL语句练习
目录 1 数据库相关概念1.1 数据库1.2 数据库管理系统1.3 常见的数据库管理系统1.4 SQL 2 MySQL2.1 MySQL安装2.1.1 安装步骤 2.2 MySQL配置2.2.1 添加环境变量2.2.2 MySQL登录2.2.3 退出MySQL 2.3 MySQL数据模型2.4 MySQL目录结构2.5 MySQL一些命令2.5.1 修改默认账户密码2.5.2…...
数据安全复合治理框架和模型解读(0)
数据治理,数据安全治理行业在发展,在实践,所以很多东西是实践出来的,哪有什么神仙理论指导,即使有也是一家之说,但为了提高企业投产比,必要的认知是必须的,当前和未来更需要专业和创新。数据安全治理要充分考虑现实数据场景,强化业务安全与数据安全治理,统一来治理,…...

Java程序设计入门教程--逻辑运算符和位运算符
目录 逻辑运算符 位运算符 逻辑运算符 逻辑运算符就是表示逻辑关系的运算符。下表列出了逻辑运算符的基本运算,假设布尔变量A为真,变量B为假。 逻辑运算符表 操作符 描述 例子 && 当且仅当两个操作数都为真,条件才为真。 &…...
接口测试简介以及接口测试用例设计思路
接口测试简介 1.什么是接口 接口就是内部模块对模块,外部系统对其他服务提供的一种可调用或者连接的能力的标准,就好比usb接口,他是系统向外接提供的一种用于物理数据传输的一个接口,当然仅仅是一个接口是不能进行传输的&#x…...

C++ Qt项目实战:构建高效的代码管理器
C Qt项目实战:构建高效的代码管理器 一、项目概述(Introduction)1.1 项目背景(Project Background)1.2 项目目标(Project Goals)1.3 项目应用场景(Project Application Scenarios&am…...

【JavaScript 递归】判断两个对象的键值是否完全一致,支持深层次查询,教你玩转JavaScript脚本语言
博主:東方幻想郷 Or _LJaXi 专栏分类:JavaScript | 脚本语言 JavaScript 递归 - 判断两个对象的键值 🌕 起因🌓 代码流程⭐ 第一步 判断两个对象的长度是否一致⭐ 第二步 循环 obj 进行判断两个对象⭐ 第三步 递归条件判断两个对象…...

卷积、相关、匹配滤波、脉冲压缩以及模糊函数
文章目录 【 1. 卷积 】1.1 连续卷积1.2 离散卷积【 2.相关 】2.1 自相关2.2 互相关【 3.匹配滤波 】3.1 滤波器模型3.2 有色噪声-匹配滤波器3.3 白噪声-匹配滤波器3.3.1 原始-白噪声-匹配滤波器3.3.2 简化-白噪声-匹配滤波器3.4 动目标的匹配滤波【 4.脉冲压缩】4.1 时域脉冲压…...
C# 栈(Stack)
目录 一、概述 二、基本的用法 1.入栈 2.出栈 Pop 方法 Peek 方法 3.判断元素是否存在 4.获取 Stack 的长度 5.遍历 Stack 6.清空容器 7.Stack 泛型类 三、结束 一、概述 栈表示对象的简单后进先出 (LIFO) 非泛型集合。 Stack 和 List 一样是一种储存容器&#x…...

网络流量监控及流量异常检测
当今的企业面临着许多挑战,尤其是在监控其网络基础设施方面,需要确保随着网络规模和复杂性的增长,能够全面了解网络的运行状况和安全性。为了消除对网络性能的任何压力,组织应该采取的一项重要行动是使用随组织一起扩展的工具监控…...

六.热修复
文章目录 前言什么是热修复?如何进行热修复?热修复需要解决的问题 1.Android常用的热修复解决方案2.ClassLoader类加载机制2.1 Android类加载器2.2 双亲委托机制2.3 类查找流程 3.插桩式热修复运行期修复落地3.1 什么是字节码插桩?3.2 ASM3.3…...

2000万的行数在2023年仍然是 MySQL 表的有效软限制吗?
谣言 互联网上有传言说我们应该避免在单个 MySQL 表中有超过 2000 万行。否则,表的性能会下降,当它超过软限制时,你会发现 SQL 查询比平时慢得多。这些判断是在多年前使用HDD硬盘存储时做出的。我想知道在2023年对于基于SSD的MySQL数据库来说…...

jvm问题排查
常用工具 命令查询资源信息 top:显示系统整体资源使用情况 vmstat:监控内存和 CPU iostat:监控 IO 使用 netstat:监控网络使用 查看java进程 jps 查看运行时信息 jinfo pid gc工具 jstat: 查看jvm内存信息 GCViewer — 离线分析G…...

【Redis】浅谈Redis-集群(Cluster)
文章目录 前言1、集群实现1.1 创建cluster目录,并将redis.conf复制到该文件夹1.2 复制redis.conf,并进行配置1.3 启动redis,查看启动状态1.4 合成集群1.5 查看集群1.6 集群读写操作 2、SpringBoot整合redis集群2.1 引入包2.2 设置配置2.3 使用…...
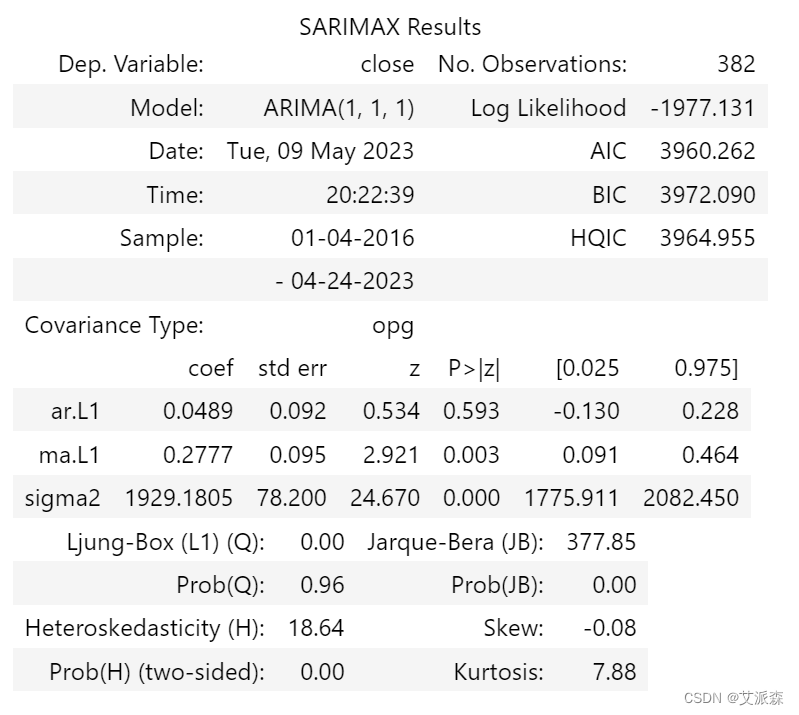
Python3实现基于ARIMA模型来预测茅台股票价格趋势
🤵♂️ 个人主页:艾派森的个人主页 ✍🏻作者简介:Python学习者 🐋 希望大家多多支持,我们一起进步!😄 如果文章对你有帮助的话, 欢迎评论 💬点赞Ǵ…...
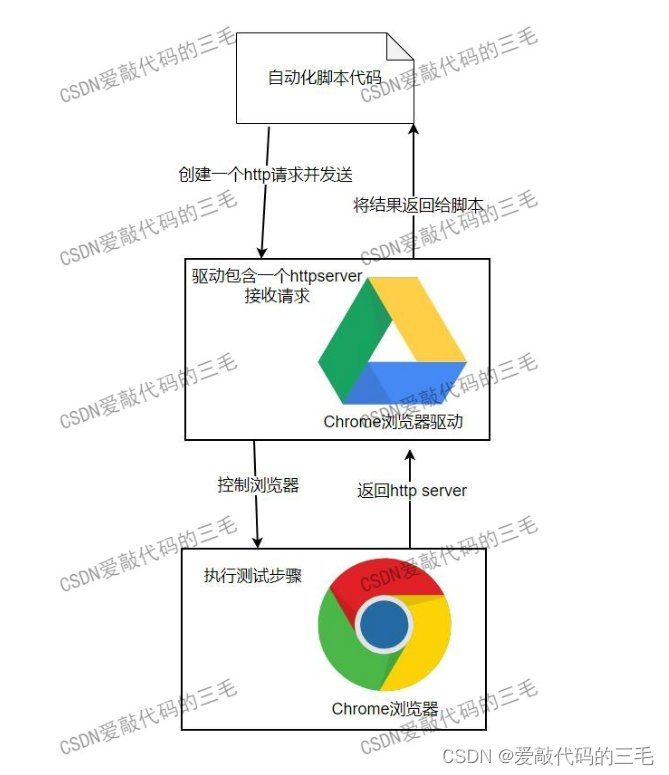
自动化测试selenium环境搭建
自动化测试工具selenium搭建 1. 自动化和selenium基本概念 1) 什么是自动化?为什么要做自动化? 自动化测试能够代替一部分的手工测试,自动化测试能够提高测试的效率。随着项目功能的增加,版本越来越多,版本的回归测试的压力也…...
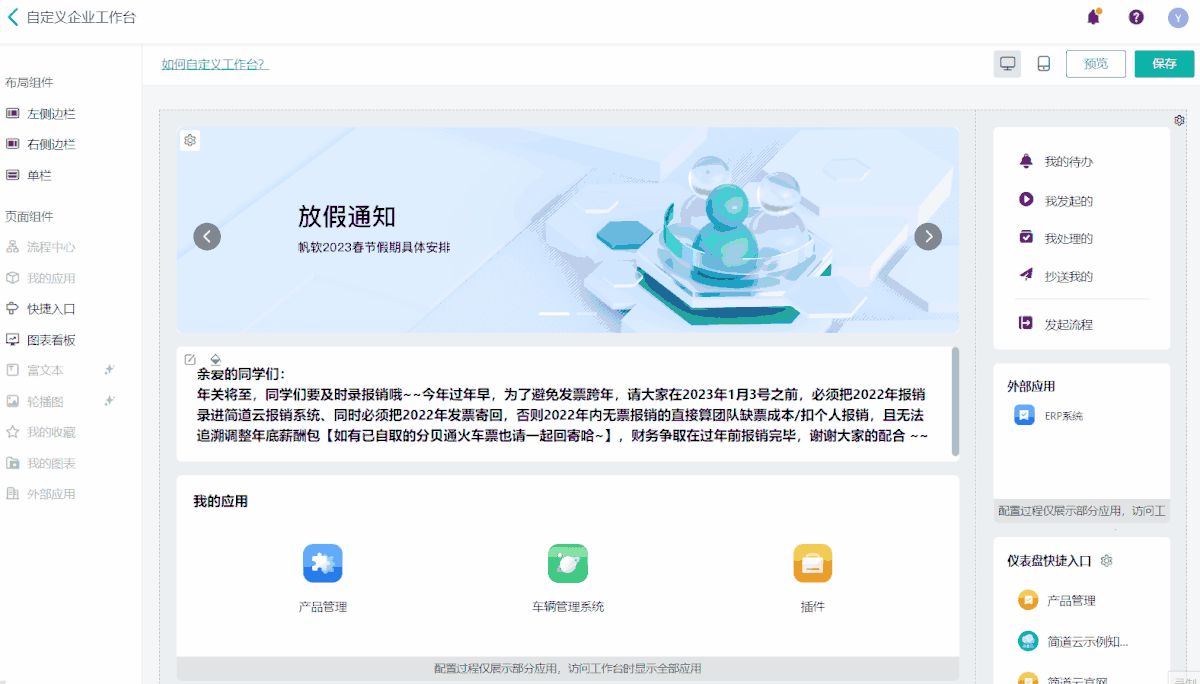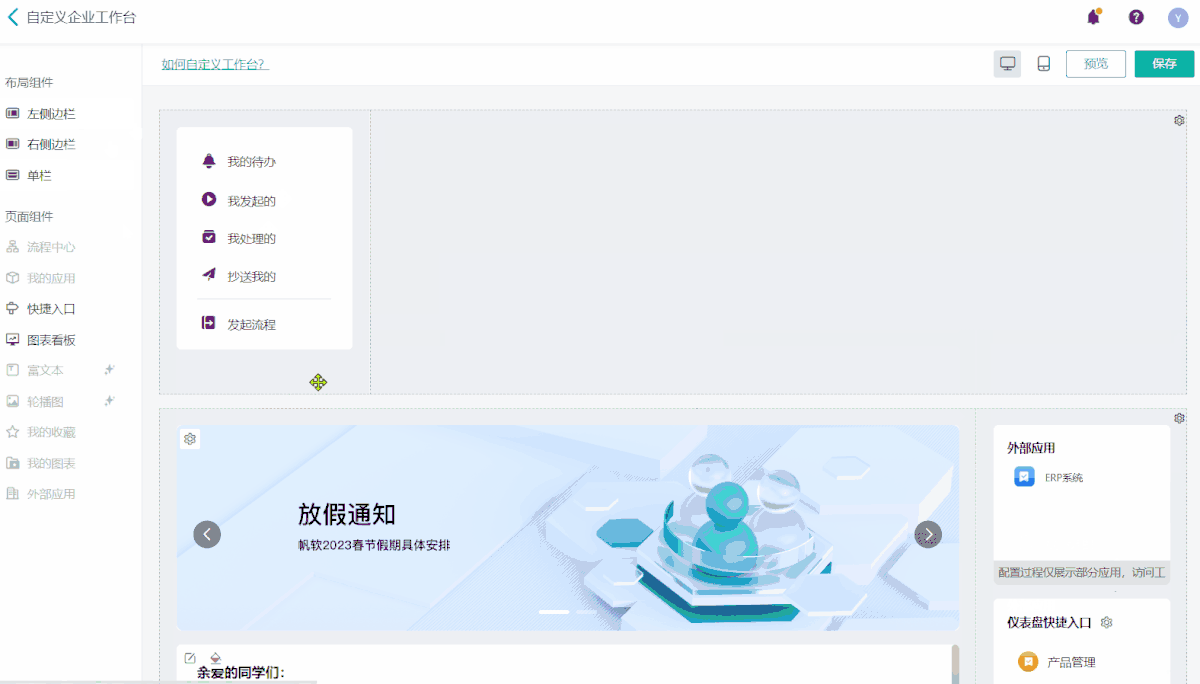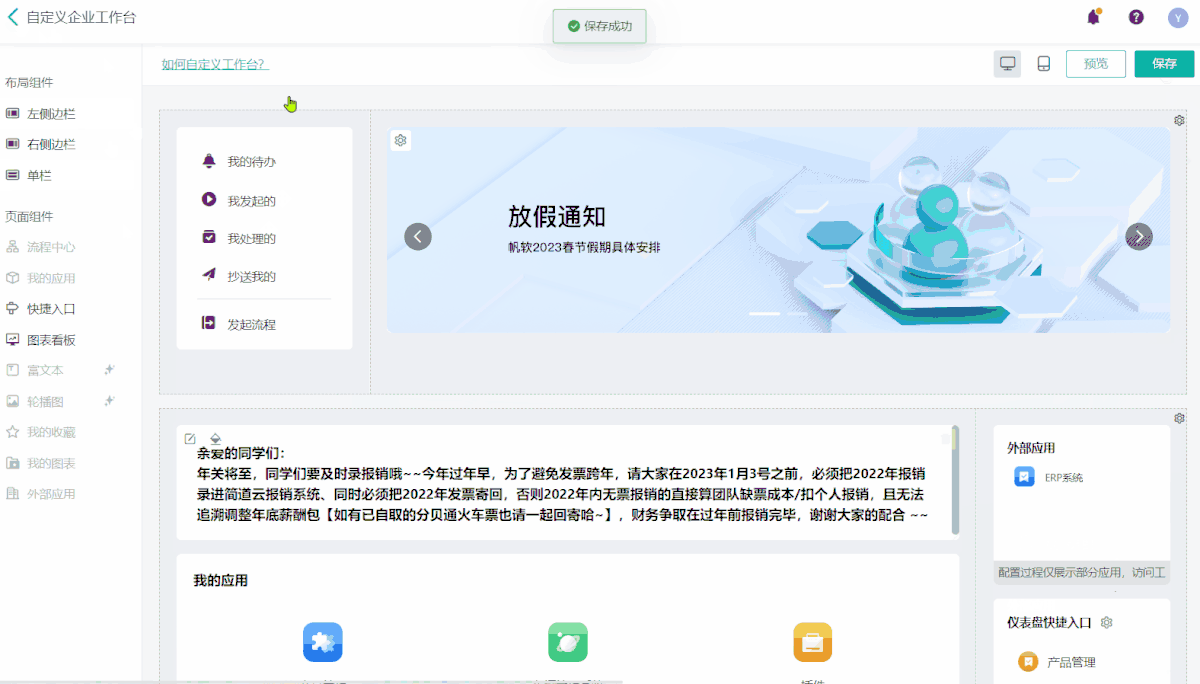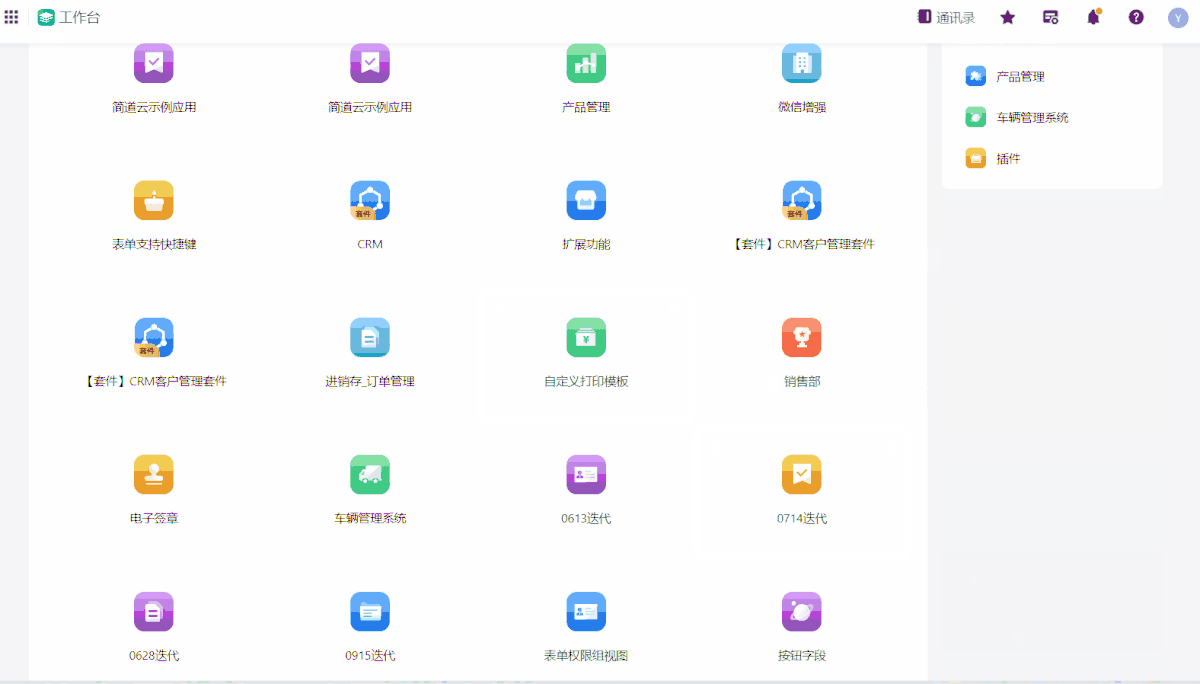
SaaS系统平台,如何兼顾客户的个性化需求?
在当今数字化的商业环境中,SaaS系统已经成为企业运营的重要组成部分之一。 SaaS系统平台的好处是显而易见的,可以将业务流程数字化,从而帮助企业提高效率并节省成本。 但是,由于每个企业的业务都不尽相同,所以在选择Sa…...

QDir拼接路径解决各种斜杠问题
一般在项目中经常需要组合路径,与其他程序进行相互调用传递消息通信。 经常可能因为多加斜杠、少加斜杠等问题导致很多问题。 为了解决这些问题,我们可以使用QDir来完成路径的拼接,不直接拼接字符串。 QDir的静态方法QDir::cleanPath() 是为了规范化路径名的,在使用QDir组…...
mycat2主从配置实现读写分离
mycat2主从配置实现读写分离 在https://blog.csdn.net/zhangxue_wei/article/details/130840504基础上继续搭建 1.创建mycat数据源,可以在navcat里直接执行 1.1读数据源m1 /* mycat:createDataSource{"dbType":"mysql","idleTimeout&qu…...

如何在Centos7中安装Kubernetes
一、概述 Kubernetes([kubə’netis]),简称K8s,是用8代替名字中间的8个字符“ubernete”而成的缩写,它是一个由Google 开源的全新的分布式容器集群管理系统。 二、准备 IP角色内存192.168.1.130master4G192.168.1.1…...

基于窗口比较器与晶体管逻辑的可编程非线性电压指示器设计
1. 项目概述:打造一个可编程的“移动光点”电压指示器在电子制作和仪器仪表领域,我们经常需要一个直观的电压指示器。经典的LM3914点/条图显示驱动芯片大家都很熟悉,它能把一个模拟电压信号转换成10个LED的点亮状态,形成移动的光点…...
从Stable Diffusion到DiT:为什么说Transformer是扩散模型的下一站?
从Stable Diffusion到DiT:Transformer如何重塑扩散模型的未来 在图像生成领域,扩散模型正经历着从U-Net架构向Transformer架构的范式转移。这一转变不仅仅是技术组件的简单替换,而是代表着生成式AI在可扩展性、训练效率和模型容量方面的重大突…...

C51对Maxim 390远内存绝对地址访问的三种方案
1. 深入解析C51对Maxim 390远内存的绝对地址访问 在嵌入式开发中,对特定内存地址的直接操作是底层控制的关键技术。以Maxim(原Dallas Semiconductor)DS80C390为代表的增强型8051架构,其24位地址空间的远内存(Far Memor…...

Windows 11终极优化指南:Win11Debloat一键清理系统提升51%性能
Windows 11终极优化指南:Win11Debloat一键清理系统提升51%性能 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declutte…...

ESP32屏幕项目救星:用TFT_eSPI库的Touch_calibrate例程,5分钟搞定LittleVGL触摸校准
ESP32屏幕开发实战:5分钟完成LittleVGL触摸校准的高效方法论 当一块全新的ILI9341XPT2046电阻屏摆在你面前时,大多数开发者会迫不及待地跳进LittleVGL的配置深渊。但真正高效的硬件开发者知道,在编写任何图形界面代码之前,有一个关…...

抖音批量下载工具:高效获取用户主页全作品的专业解决方案
抖音批量下载工具:高效获取用户主页全作品的专业解决方案 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback su…...

C++运算符重载的实现示例
1. 运算符重载的基本概念 运算符重载是C一项强大的特性,它允许我们为自定义类型(类或结构体)重新定义运算符的行为。通过运算符重载,我们可以让自定义类型像内置类型一样使用标准的运算符语法,使代码更加直观和自然 …...

UE5 Niagara实战:用‘定位事件’和‘死亡事件’模块,5分钟做出粒子追踪与消散特效
UE5 Niagara实战:5分钟打造魔法飞弹的粒子追踪与消散特效在游戏开发中,粒子特效是营造沉浸感的关键元素之一。想象一下:一枚魔法飞弹划过夜空,身后拖曳着流光溢彩的尾迹,击中目标时爆裂成绚丽的火花——这种动态效果正…...

手把手拆解蓝牙Extended Advertising数据包:从HCI Command到空口PDU的完整流程
手把手拆解蓝牙Extended Advertising数据包:从HCI Command到空口PDU的完整流程 蓝牙技术演进到5.0版本后,Extended Advertising(扩展广播)机制的引入彻底改变了低功耗蓝牙的通信范式。这项技术突破不仅解决了传统广播模式的诸多限…...

UI-TARS桌面版:用自然语言控制电脑的智能GUI助手终极指南
UI-TARS桌面版:用自然语言控制电脑的智能GUI助手终极指南 【免费下载链接】UI-TARS-desktop The Open-Source Multimodal AI Agent Stack: Connecting Cutting-Edge AI Models and Agent Infra 项目地址: https://gitcode.com/GitHub_Trending/ui/UI-TARS-desktop…...