python list,dict操作
一、list 操作
Python中的列表是一种有序、可变的数据类型,可以存储任意类型的数据。以下是Python中常用的列表操作:
创建列表:使用
[]或list()函数创建一个空列表,或者使用[value1, value2, ...]创建一个包含初始值的列表。访问列表元素:使用下标(从0开始)访问列表中的元素,例如
lst[0]表示访问列表中的第一个元素。切片操作:使用切片操作符
[start:end:step]来获取列表中的子列表,其中start表示开始位置,end表示结束位置(不包含),step表示步长。例如,lst[1:4]表示获取列表中第2个到第4个元素。修改列表元素:使用下标(从0开始)修改列表中的元素,例如
lst[0] = value表示将列表中的第一个元素修改为value。添加元素:使用
append()方法向列表的末尾添加一个元素,使用extend()方法将另一个列表中的元素添加到当前列表的末尾,使用insert()方法在指定位置插入一个元素。删除元素:使用
del语句或remove()方法删除列表中的元素,使用pop()方法删除列表中指定位置的元素并返回其值。获取列表长度:使用
len()函数获取列表中元素的数量。列表排序:使用
sorted()函数或list.sort()方法对列表元素进行排序。列表去重:使用
set()函数或list的set()方法来去除列表中的重复元素。列表反转:使用
reverse()方法将列表中的元素翻转。列表拼接:使用
+运算符将两个列表拼接成一个新列表,使用*运算符将列表复制指定次数。列表查找:使用
index()方法查找指定元素在列表中的位置,使用in关键字判断指定元素是否在列表中。列表统计:使用
count()方法统计指定元素在列表中出现的次数。列表遍历:使用
for循环逐个访问列表中的元素。列表推导式:使用列表推导式可以快速生成一个新的列表,例如
[x for x in lst if x % 2 == 0]
1、list位置逆序:
Python中的
list.reverse()方法是用于将列表中的元素翻转,会直接修改原列表。该方法没有返回值,即返回值为
None。
使用方式如下:
lst = [1, 2, 3, 4, 5]lst.reverse()print(lst)输出结果:[5, 4, 3, 2, 1]
注意,
list.reverse()方法是直接修改原列表的顺序,而不是创建一个新的翻转后的列表。如果需要创建一个新的翻转后的列表,可以使用切片操作符[::-1],例如:
lst = [1, 2, 3, 4, 5]
new_lst = lst[::-1]
print(new_lst)输出结果:[5, 4, 3, 2, 1]
2、list排序:
Python中,可以使用
sorted()函数和list.sort()方法对列表进行排序。
sorted()函数用于对任意可迭代对象进行排序,并返回一个新的已排序的列表
如:
lst = [3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5]
new_lst = sorted(lst)
print(new_lst)输出结果:[1, 1, 2, 3, 3, 4, 5, 5, 5, 6, 9]
注意:默认情况下,
sorted()函数和list.sort()方法都是按升序排序的。如果需要按降序排序,可以使用reverse=True参数,例如:
lst = [3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5]
new_lst = sorted(lst, reverse=True)
print(new_lst)lst = [3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5]
lst.sort(reverse=True)
print(lst)输出结果:
[9, 6, 5, 5, 5, 4, 3, 3, 2, 1, 1]
[9, 6, 5, 5, 5, 4, 3, 3, 2, 1, 1]
如果列表中的元素是自定义对象,可以通过
key参数指定排序的关键字。例如,以下代码按照学生的年龄进行倒序排序:
class Student:def __init__(self, name, age):self.name = nameself.age = agedef __repr__(self):return f"{self.name} ({self.age})"students = [Student("Alice", 23),Student("Bob", 21),Student("Charlie", 20),Student("David", 22),
]sorted_students = sorted(students, key=lambda s: s.age,reverse=True)
print(sorted_students)
输出结果:[Alice (23), David (22), Bob (21), Charlie (20)]
3、list去重:
Python中,可以使用
set()函数或list的set()方法来去除列表中的重复元素。例如:
lst = [1, 2, 3, 2, 4, 3, 5, 6, 5]
new_lst = list(set(lst))
print(new_lst)
输出结果:[1, 2, 3, 4, 5, 6]
如果需要保持原来的元素顺序,可以使用列表推导式和
not in语句来实现去重。如:
lst = [1, 2, 3, 2, 4, 3, 5, 6, 5]
new_lst = []
for x in lst:if x not in new_lst:new_lst.append(x)
print(new_lst)
输出结果:[1, 2, 3, 4, 5, 6]
4、list 元素统计
使用python 计数器
from collections import Counter lst=[1,2,2,2,3,6,6,6,6] a = Counter(lst) print(type(a),a) print([i for i in a]) print(list(a)) print({k:v for k,v in a.items()}) print(dict(a))输出结果:
<class 'collections.Counter'> Counter({6: 4, 2: 3, 1: 1, 3: 1}) [1, 2, 3, 6] [1, 2, 3, 6] {1: 1, 2: 3, 3: 1, 6: 4} {1: 1, 2: 3, 3: 1, 6: 4}
二、dict操作
1.创建字典
my_dict = {'key1': 'value1', 'key2': 'value2', 'key3': 'value3'}2.访问字典元素
value1 = my_dict['key1']3.添加或修改字典元素
my_dict['key4'] = 'value4' # 添加元素 my_dict['key1'] = 'new_value1' # 修改元素4.删除字典元素
del my_dict['key3'] # 删除指定元素 my_dict.clear() # 清空整个字典5.遍历字典
for key, value in my_dict.items():print(key, value)6.获取字典键值对数量
num_items = len(my_dict)7.检查字典中是否存在某个键值对
if 'key1' in my_dict:print('key1 exists')8.获取字典所有键或所有值
keys = my_dict.keys() values = my_dict.values()9.合并两个字典
my_dict1 = {'key1': 'value1', 'key2': 'value2'} my_dict2 = {'key3': 'value3', 'key4': 'value4'} my_dict1.update(my_dict2) # 将my_dict2合并到my_dict1中10.获取指定键的值,如果键不存在则返回默认值
value = my_dict.get('key5', 'default_value')11.将字典转换为列表
my_list = list(my_dict.items())12.将列表转换为字典
my_list = [('key1', 'value1'), ('key2', 'value2')] my_dict = dict(my_list)13.通过 values 取到 key 的方法:
dic={"a":1,"b":2,"c":3} list(dic.keys())[list(dic.values()).index(1)]输出结果:'a'
1、dict 有序创建:
在 Python 3.7 及以后的版本中,字典是有序的,即插入顺序与遍历顺序一致。如果需要在早期版本中创建有序字典,可以使用第三方库
collections中的OrderedDict。使用
OrderedDict的方式和普通字典类似,只需要在创建字典时使用OrderedDict替代dict即可:
from collections import OrderedDictmy_dict = OrderedDict({'key1': 'value1', 'key2': 'value2', 'key3': 'value3'})
此时,
my_dict中的键值对的顺序与插入的顺序一致。可以通过遍历字典来验证:输出结果:
key1 value1 key2 value2 key3 value3
需要注意的是,
OrderedDict比普通字典的内存消耗要大一些,因为它需要维护一个双向链表来记录插入顺序。如果对字典的顺序并不关心,可以使用普通字典来减少内存开销。
2、dict key值排序:
要对字典的键按照字典序(即按照字母顺序)进行排序,可以将字典的键转换为列表,然后使用
sorted()函数进行排序。如:
my_dict = {'c': 1, 'a': 3, 'b': 2} sorted_keys = sorted(my_dict.keys())输出结果:['a', 'b', 'c']
如果需要按照键对应的值进行排序,可以使用
key参数指定排序依据:sorted_keys = sorted(my_dict.keys(), key=lambda x: my_dict[x])此时,
sorted_keys中的元素是按照值排序后的:输出结果:['c', 'b', 'a']
注意:
sorted()函数返回的是一个列表,而不是字典,因为字典是无序的。如果需要按照键排序后创建一个新的字典,可以使用字典推导式:sorted_dict = {k: my_dict[k] for k in sorted(my_dict.keys())}此时,
sorted_dict中的元素是按照键排序后的字典:输出结果:{'a': 3, 'b': 2, 'c': 1}
相关文章:

python list,dict操作
一、list 操作 Python中的列表是一种有序、可变的数据类型,可以存储任意类型的数据。以下是Python中常用的列表操作: 创建列表:使用[]或list()函数创建一个空列表,或者使用[value1, value2, ...]创建一个包含初始值的列表。 访问…...

我有一个页面a,在页面a中调用了一个组件,然后组件中要切换页面a的一块区域,该怎么实现?
你可以在组件中使用路由的编程式导航,通过访问路由实例来切换页面a的对应区域。具体来说,你可以先在页面a中设置一个具有唯一标识的占位符元素,然后在组件中通过路由实例访问这个元素并修改其内容或样式来实现区域切换。路由的编程式导航可以…...

ChatGPT唤醒AI游戏:AIGC持续走深,游戏或成AI最佳抓手
随着人工智能技术的不断发展,AI在游戏行业的应用日益深入。本文将详细探讨ChatGPT在AI游戏领域的应用,以及游戏如何成为AI技术的最佳抓手。让我们一起探讨这个有趣且充满潜力的领域。 一、引言 人工智能在各行各业都取得了巨大的成功,而游戏…...

远程服务和web服务和前端,三方通过socket和websocket进行双向通信传输数据
1. 什么是socket? 在计算机通信领域,socket 被翻译为“套接字”,它是计算机之间进行通信的一种约定或一种方式。通过 socket 这种约定,一台计算机可以接收其他计算机的数据,也可以向其他计算机发送数据。 2. 什么是websocket?…...
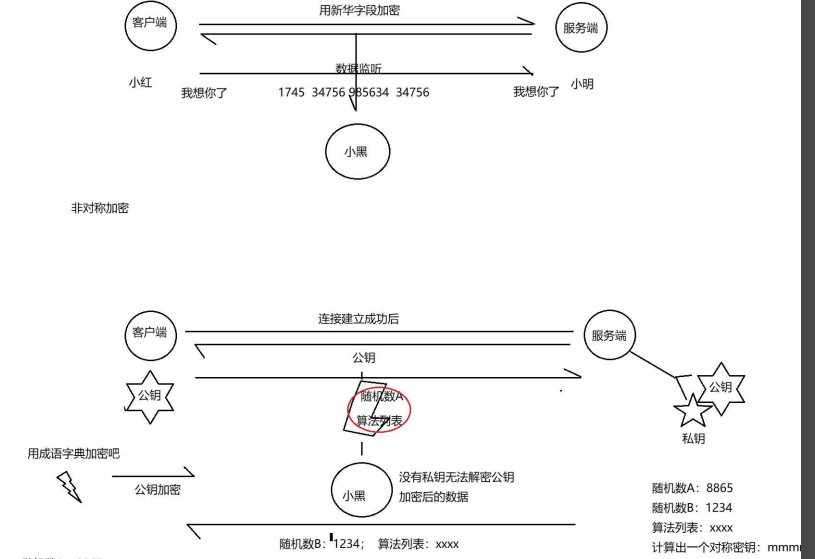
Linux 网络基础(2)应用层(http/https协议、请求格式、响应格式、session、cookie、加密传输)
说明:网络基础2讲解的是应用层的典型协议, 通过对于典型协议的理解,来体会数据的网络传输的软件层面的流程与原理。 面试中网络通信相关问题占了很大的比重,而网络通信相关的问题大多都集中在网络基础2这个单元中 下面是应用层的位…...

解决sshfs挂载报错
使用ssh命令和sshfs命令报错 read: Connection reset by peer rootjiangcheng01:~/common/remote# sshfs -o allow_other htrdxxx.xxx.xxx.xxx:/home/htrd /root/common/remote/dev01 read: Connection reset by peer 报错问题排查,追加命令 -o debug -o sshf s_d…...

由于过多的连接错误而被 MySQL服务器 阻止
Caused by: com.mysql.cj.exceptions.CJException: null, message from server: "Host 10.105.***.** is blocked because of many connection errors; unblock with mysqladmin flush-hosts" 这个错误可能表示当您尝试使用 IP 地址为 "10.105.***.**" 的…...

Go语言实现JDBC
Go语言操作数据库 Go语言提供了关于数据库的操作,包下有sql/driver 该包用来定义操作数据库的接口,这保证了无论使用哪种数据库,操作方式都是相同的; 准备工作: 下载驱动 需要在代码所在文件夹下执行相应的命令 go get github.com/go-sql-driver/mys…...

ubuntu修改环境变量的几种方法
ubuntu修改环境变量的几种方法 有多种方法可以修改Ubuntu系统的环境变量,包括: 临时修改环境变量:在终端中使用export命令可以临时修改环境变量。例如,要将PATH环境变量添加到新目录,可以运行以下命令: …...

基于html+css的图展示95
准备项目 项目开发工具 Visual Studio Code 1.44.2 版本: 1.44.2 提交: ff915844119ce9485abfe8aa9076ec76b5300ddd 日期: 2020-04-16T16:36:23.138Z Electron: 7.1.11 Chrome: 78.0.3904.130 Node.js: 12.8.1 V8: 7.8.279.23-electron.0 OS: Windows_NT x64 10.0.19044 项目…...

数据库基础——5.运算符
这篇文章我们来讲一下SQL语句中的运算符操作。 说点题外话:SQL本质上也是一种计算机语言,和C,java一样的,只不过SQL是用来操作数据库的。在C,java中也有运算符,这两种语言中的运算符和数学中的运算符差距不…...
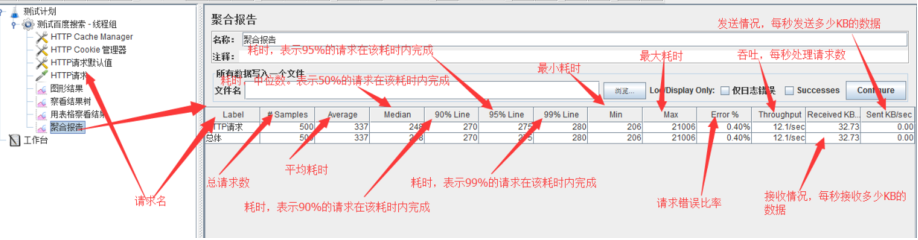
JMeter 性能测试基本过程及示例
jmeter 为性能测试提供了一下特色: 2023年最新出炉性能测试教程,真实企业性能压测全流程项目实战训练大合集!_哔哩哔哩_bilibili2023年最新出炉性能测试教程,真实企业性能压测全流程项目实战训练大合集!共计11条视频&…...

漏洞复现 CVE-2018-2894 weblogic文件上传
vulhub weblogic CVE-2018-2894 1、 搭建好靶场,按提示访问 http://192.168.137.157:7001/console 按照给出的文档,会查看容器的日志,找到管理员用户名/密码为 weblogic / h3VCmK2L,暂时用不到,不需要登录 2、未授权…...

二叉树:填充每个节点的下一个右侧节点指针(java)
leetcode116:填充每个节点的下一个右侧节点指针 leetcode原题链接:题目描述递归解法一递归方法二(效率更高)二叉树专题 leetcode原题链接: 116题:填充每个节点的下一个右侧节点指针 题目描述 给定一个 完美二叉树 &a…...

Android 12.0修改系统默认设备类型的平板电脑类型为设备类型
1.概述 在12.0的系统rom产品开发中,对于产品设备类型都默认为tablet即平板电脑类型,即 product="tablet" 在一些不是平板的项目中,可能需要修改这个类型为device类型 即 product="device",这就需要找到相关设置系统属性的代码,修改系统属性就可以了 2…...

debug研究
debug研究 debug的condition 通常用在for循环里面 for循环中实际使用 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UsmJ93w5-1685344057464)(D:\typora_pic_all\image-20230529145417753.png)] log.info("当前共有{}条数据待处理", vos…...
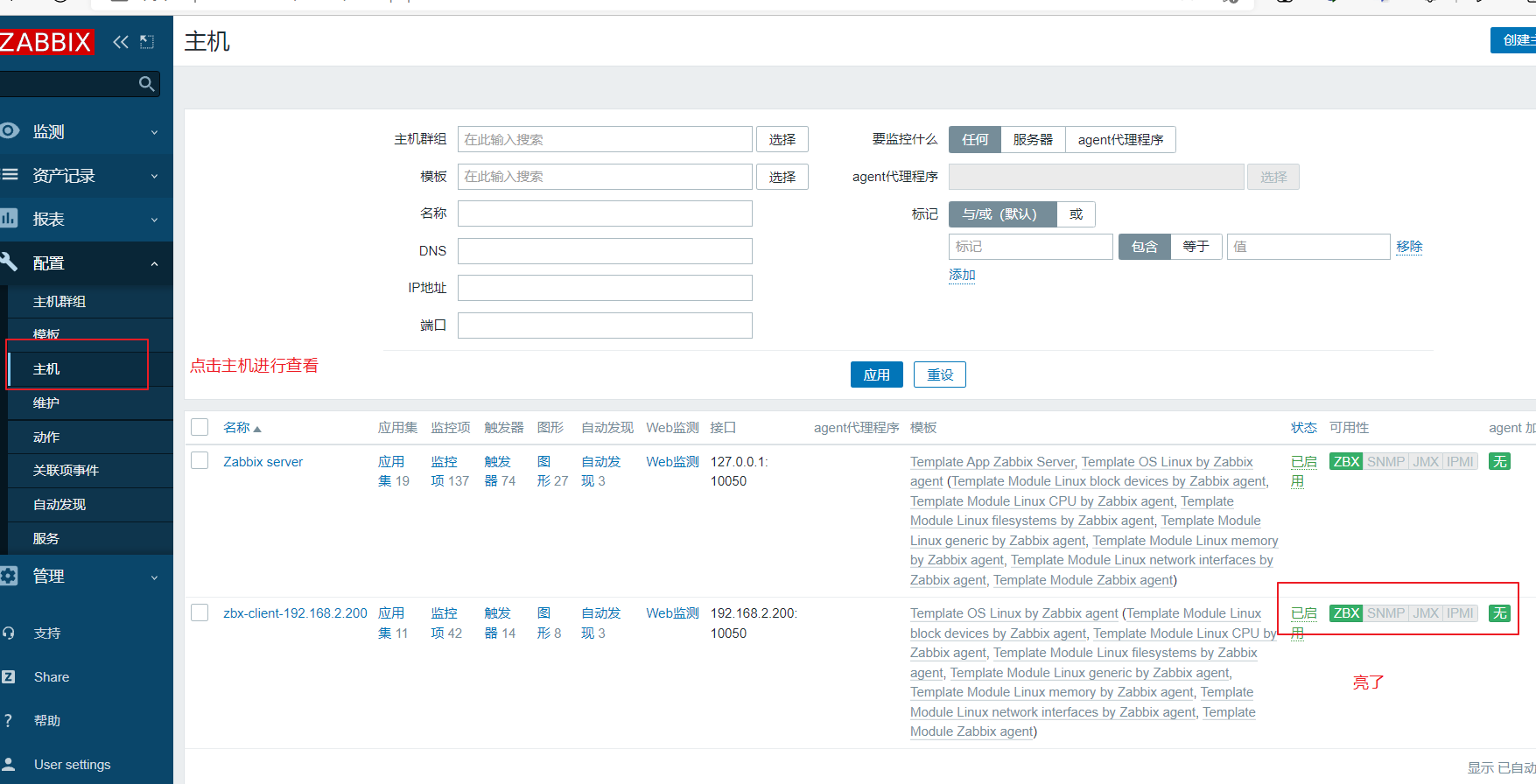
zabbix监控系统
一、Zabbix概述 1、使用zabbix的原因 作为一个运维,需要会使用监控系统查看服务器状态以及网站流量指标,利用监控系统的数据去了解上线发布的结果,和网站的健康状态。 利用一个优秀的监控软件,我们可以: ●通过一个友好的界面进…...
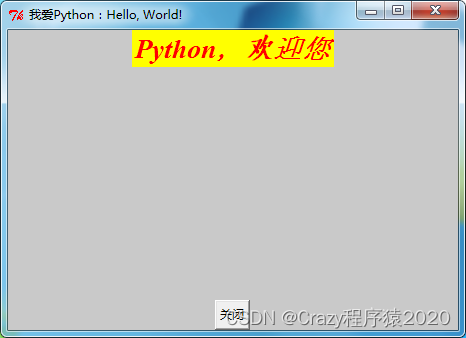
Python入门学习
一、执行Python(Hello World)程序 对于大多数程序语言,第一个入门编程代码便是 “Hello World!”,以下代码为使用 Python 输出 “Hello World!” 1.1 创建hello.py文件 1.2 编写程序 #!/usr/bin/python…...

自动驾驶嵌入式开发工程师:车载SOC开发修炼秘籍
声明:本文档是博主在开发学习过程中写的笔记,本意是便于以后开发复盘,参考《 ug1144-petalinux-tools-reference-guide》、《ug1085》、黑金Zynq UltraScale MPSoC 5EV开发板资料、英伟达官方资料。大佬勿喷 大佬勿喷 大佬勿喷!&a…...

Linux之搭建环境
文章目录 1 FileZilla软件2 Linux搭建samba文件共享服务器,实现基于Linux和Windows的共享文件服务2.1 smaba的安装与基本应用2.2 samba的账号权限配置2.3 win系统下的文件无法复制到Linux共享文件夹中 1 FileZilla软件 在跟着正点原子教程安装后,出现如下…...

2026年免费照片去水印软件App推荐,一看就会的保姆级详细教程
你是不是也遇到过这样的场景:好不容易在网上看到一张心水的壁纸、一张有趣的表情包,或者自己拍的视频截图里有碍眼的日期戳、平台logo,想拿来发朋友圈,结果那个水印就像一块顽固的“牛皮癣”,怎么都去不掉?…...
)
告别SSH焦虑:手把手教你在Ubuntu 22.04和RHEL 8上快速启用Telnet服务(附防火墙配置)
应急管理通道:Ubuntu与RHEL系统下Telnet服务的实战配置指南 当深夜的报警短信惊醒睡梦,发现SSH连接因配置失误彻底瘫痪时,每个运维人员都需要Plan B。Telnet这个被遗忘的古老协议,恰恰能在关键时刻成为救命稻草。本文将带您深入掌…...
)
从零到一:用Python+微分方程模拟传染病传播(以SIR模型为例)
从零到一:用Python微分方程模拟传染病传播(以SIR模型为例)在公共卫生领域,传染病传播模型一直是预测疫情发展趋势的重要工具。SIR模型作为经典的传染病动力学模型,通过微分方程组描述了易感者(S)、感染者(I)和康复者(R…...

MobX进阶教程:如何自定义observables和扩展MobX功能
MobX进阶教程:如何自定义observables和扩展MobX功能 【免费下载链接】MobX-Docs-CN MobX 中文文档 项目地址: https://gitcode.com/gh_mirrors/mo/MobX-Docs-CN MobX是一个强大的状态管理库,它让状态管理变得简单且可扩展。在掌握基础用法后&…...

June安全防护手册:保护你的论坛免受常见Web攻击的10个技巧
June安全防护手册:保护你的论坛免受常见Web攻击的10个技巧 【免费下载链接】june June is a forum (Deprecated) 项目地址: https://gitcode.com/gh_mirrors/ju/june 在当今数字时代,论坛安全防护已成为每个网站管理员必须面对的重要课题。June作…...

双向可控硅交流控制电路基础知识及Multisim电路仿真
目录 2.2.2 双向可控硅交流控制电路 2.2.2.1 双向可控硅交流控制电路基础知识 2.2.2.2 双向可控硅交流控制Multisim电路仿真 摘要:本文介绍了双向可控硅交流控制电路的工作原理及Multisim仿真。该电路通过光耦隔离实现低压控制高压交流负载,采用过零触发方式降低干扰。控制…...
3分钟上手Translumo:免费实时屏幕翻译工具终极指南
3分钟上手Translumo:免费实时屏幕翻译工具终极指南 【免费下载链接】Translumo Advanced real-time screen translator for games, hardcoded subtitles in videos, static text and etc. 项目地址: https://gitcode.com/gh_mirrors/tr/Translumo 你是否在游…...

Python 开发者如何通过 Taotoken 快速接入多款大模型 API
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Python 开发者如何通过 Taotoken 快速接入多款大模型 API 对于需要频繁实验不同大模型能力的 Python 开发者而言,管理多…...

开源AI工具真能替代商业方案?2024最新Benchmark数据揭示92%团队忽略的关键短板
更多请点击: https://codechina.net 第一章:开源AI工具真能替代商业方案?2024最新Benchmark数据揭示92%团队忽略的关键短板 2024年Q2由MLPerf与OpenLLM-Bench联合发布的跨模态AI工具基准报告覆盖全球147个生产级AI部署团队,结果显…...

DLSS Swapper深度解析:如何实现跨平台游戏DLSS版本智能管理
DLSS Swapper深度解析:如何实现跨平台游戏DLSS版本智能管理 【免费下载链接】dlss-swapper 项目地址: https://gitcode.com/GitHub_Trending/dl/dlss-swapper 在NVIDIA DLSS技术成为现代PC游戏性能优化的关键要素后,玩家面临一个实际的技术挑战&…...