【Redis25】Redis进阶:分布式锁实现
Redis进阶:分布式锁实现
锁这个概念,不知道大家掌握的怎么样。我是先通过 Java ,知道在编程语言中是如何使用锁的。一般 Java 的例子会是操作一个相同的文件,但其实我们知道,不管是文件,还是数据库中的一条数据,只要是多个进程或者线程共享的,需要共同操作的数据,都会因为异步读写而带来一些问题,这些问题最终的解决方案往往就是通过锁。
MySQL 中,有表锁、行锁、读写锁、意向锁、间隙锁等等,而在 Redis 中,其实并没有完全的锁的概念,因为它是单线程执行命令的,本身就不会出现多线程同时操作同一数据的问题。因此,使用 Redis 非常适合来做分布式锁。那么,分布式锁又是啥意思呢?
单进程单线程,或者只在一台主机上,其实我们有很多种锁的解决方案。但是如果跨进程、跨主机了,不借助外力去实现锁就非常麻烦了。在同一个程序中,我们直接使用程序代码提供的锁就可以了,比如 Go 中的 sync.Mutex ,而如果不在同一个进程中,显然这个锁是没法让另一个进程也锁上的。这时,我们可以用类似于 pid 文件这样的概念,就是上锁的时候创建一个文件,这个文件即使是空的也行。其它进程如果发现有这样一个文件,那么就表示有别的程序已经上锁了。这是非常简单地解决同一台机器下多个进程之间锁的方案。而如果跨多台机器的多台实例,那么大部分情况下我们都会使用一些第三方的存储。MySQL 可以做分布式锁吗?可以的,加锁的时候插入一条数据,解锁的时候删除。Redis 可以吗?可以,而且更方便,那么咱们就来好好聊聊 Redis 的分布式锁。另外,Zookeeper 也是现在非常流行的分布式锁方案的一种外部存储实现。
普通的线程(协程)锁
这里我们先来看一下在一个普通的程序中,如何对多个线(协)程加锁,今天的内容为了方便起见,我使用的是 Go 语言,如果是 PHP 的话,Swoole 中也有类似的锁,大家可以自己尝试。
先看问题,假设做一个秒杀场景,最典型的问题就是超卖问题,意思就是多协程或者分布式多实例的情况下同时操作库存字段,有可能让库存变成负的,也就是出现了超卖的情形。
var (c chan struct{}r *redis.Client
)func main() {// 连接 Redisr = redis.NewClient(&redis.Options{Addr: "127.0.0.1:6379",})r.Del("stock") // 先清理之前的数据,为了方便测试chanCount := 5 // 协程数量c = make(chan struct{}, chanCount) // channelfor i := chanCount; i > 0; i-- {// 五个协程go func() {for { // 不停地处理stock, err := r.Get("stock").Int()if err != nil { // 如果出错或者 Redis 中不存在 stock 就等着continue}if stock <= 0 { // 如果 stock 小于等于 0 就退出循环break}r.Decr("stock") // 扣减库存}c <- struct{}{} // channel 增加内容}()}// 等待 5 个 channel 处理完成for i := chanCount; i > 0; i-- {<-c}
}代码不多解释了,如果没有学过 Go ,但学过 Swoole 的话,应该大体也能看懂,如果都不会,额,赶紧去学一下吧。接下来,我们往 Redis 中添加数据,比如增加 10000 个库存。
127.0.0.1:6379> set stock 10000
OK程序那边很快就会执行完成,这时我们再来看看库存还有多少。
127.0.0.1:6379> get stock
"-1"不对呀,明明我们判断了 如果 stock 小于等于 0 就退出循环 这个条件,为啥会出现 -1 ?这就是多线(协)程会出现的典型问题了。有的时候还不一定只会是 -1 ,还会出现 -2 、-3 等等状况。如果在真实的业务场景中,只是超卖了这么几个倒还好说,但秒杀场景下往往是超大的流量和超大的并发,万一超卖了几百上千件的话.....看甲方爸爸怎么收拾你。
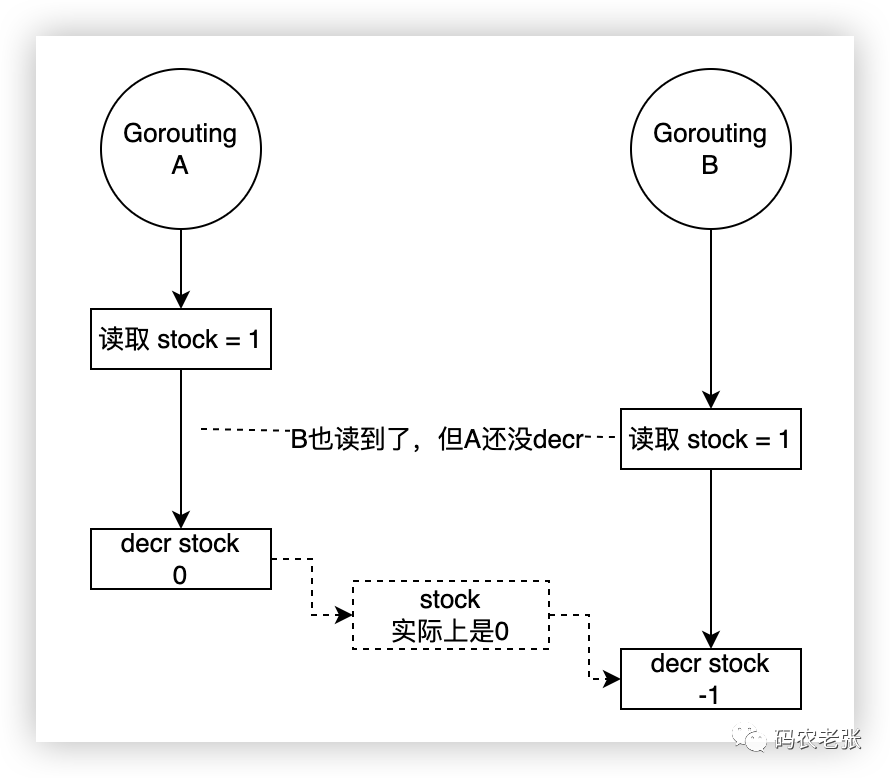
我就简单地画了两个协程可能出现的问题,如果你学过 Java ,了解多线程的话,把 Goroutine 看成是 Thread 也是可以的。对于同一个程序来说,这个问题好处理,加个锁就好了。
var (c chan struct{}r *redis.Clientl sync.Mutex // Go语言的锁
)func main(){……………………go func() {for {l.Lock() // 加锁stock, err := r.Get("stock").Int()if err != nil {l.Unlock() // 有问题,释放锁continue}if stock <= 0 {l.Unlock() // 条件不满足了,释放锁,并结束循环break}r.Decr("stock")l.Unlock() // 完成操作,解锁}c <- struct{}{}}()……………………
}标准处理流程,不解释了,现在在单应用实例的情况下其实就已经没有太大问题了,你可以自己试试,把 stock 的数量再加大,或者再多加几个协程也都是没问题的。如果想提高性能,可以再换成读写锁,这里就不演示了。接下来,我们通过运行多个应用实例,模拟分布式状态下,又会出现什么问题。
// 命令行1
go run main.go
// 命令行2
go run main.go
…………
// 命令行5
go run main.go// Redis
127.0.0.1:6379> set stock 100000
OK// 程序处理完成后再查看 Redis
127.0.0.1:6379> get stock
"-1"我去,怎么又超卖了?
分布式锁
实际上根源和上一张图的原因是类似的,进程内部的锁只能保证当前这个进程内的线(协)程上锁,其它的进程或者真正的分布式放在其它的主机上,这玩意肯定不起效果了。这时往往就需要借助第三方来实现分布式的锁了。
在 Redis 中,我们已经知道它的命令执行就是单线程的,所以这一块我们不用太操心,因此我们只需要一个高大上的,而且是非常简单的,在第一课就提到过的命令就可以实现分布式锁,它就是 SETNX 命令。
SETNX key valuesummary: Set the value of a key, only if the key does not existsince: 1.0.0group: string这个命令的意思是,如果键存在,就无法设置它。既然这样的话,那么我们上锁的时候去 SETNX 一下,如果成功了,就表明当前的进程拿到了锁,如果失败了,就等待(继续抢锁)。操作执行完成之后,直接 DEL 设置的那个值就好了,这不就实现了一个分布式锁嘛。话不多说,继续改造代码。
……………………
l.Lock()
b := r.SetNX("lock", 1, 0) // 设置一个 SETNX 锁
if b.Err() != nil || !b.Val() { // 设置失败或者没有值的话,释放协程锁,并 continue 继续抢锁l.Unlock()continue
}stock, err := r.Get("stock").Int()
if err != nil {r.Del("lock") // 现在也要释放分布式锁了l.Unlock()continue
}
if stock <= 0 {r.Del("lock") // 现在也要释放分布式锁了l.Unlock()break
}
r.Decr("stock")
l.Unlock()
r.Del("lock") // 现在也要释放分布式锁了……………………就加了这么几行代码,其实分布式锁的大体轮廓就已经出来了。测试一下吧,现在处理 10 万条库存的话即使 5 个进程,每个进程有 5 个协程,速度也会变得非常慢了。这是为啥呢?其实任何锁的操作,都是在做一件事,把并行变成串行,让同时操作变成顺序操作。目的就是用速度换正确性,或者说是牺牲效率换一致性。
也就是说,一步一步的加锁过来,我们的程序在处理高并发的业务的能力也在一步步的下降,如果再说锁的性能优化,那又是各种长篇大论了,也不是我们今天讨论的范围。但是还是给大家提供一些思路,比如读写锁,实际的业务开发中,往往不像我们这样测试的这么极端,还会有别的操作,比如可能先读到数据,进行一些其它处理,最后才写,这时就可以上读写锁来提高性能,即在写锁之前,读锁获取到的内容还是可以进行其它操作的。
好了,话题拉回来,今天我们还是着重解决最核心的分布式锁的问题,性能问题将来有机会再探讨。现在这个分布锁的应用就 OK 了?完全没问题了?不不不,还有几个问题值得我们考虑一下。
如果一个进程卡死了,没法释放锁了咋办?
如果一个进程可能某些原因确实要执行一段时间,如何释放锁比较合适?
有没有可能某一个进程释放了另一个进程的锁?
这三个问题也是面试时非常常见的问题,解决的思路其实也并不复杂。
进程卡死了没法释放锁:
SETNX的时候加个过期时间呗进程确实可能执行时间长:增加续命功能,就是快到期前如果锁还没释放,就给它加长点时间
别的进程释放了我的锁:给设置的 Value 指定一个明确的内容,可以是客户端ID或者进程机器ID之类的
设置一个过期时间
这个不用多解释了吧,这里我直接设置了 30 秒,就算进程挂掉了,30 秒后这个锁也会自动释放。
………………
b := r.SetNX("lock", 1, 30*time.Second)
………………续命
这个问题不是太好测,我们可以先把过期时间调短点,比如上面的 30 秒换成 10 秒。然后进行续命操作。
………………
b := r.SetNX("lock", 1, 10*time.Second)
………………var t *time.Timer
go func() {t = time.AfterFunc(10*time.Second/3, func() {fmt.Println("续命1次")r.Expire("lock", 10*time.Second)})
}()
rand.Seed(time.Now().UnixNano())
randomNum := rand.Intn(15) // 生成0~9的随机数
time.Sleep(time.Duration(randomNum) * time.Second) // 随机模拟耗时操作stock, err := r.Get("stock").Int()
if err != nil {r.Del("lock")l.Unlock()continue
}
………………
// 注意下面所有删锁的地方也要停掉定时器
r.Del("lock")
t.Stop()
………………这里我们为什么要新开一个协程呢?主要就是不影响主协程的任务处理,让新的协程在定时器的时间到达之后进行续命,其实也就是增加操作的时间。然后我们就开两个进程进行测试,由于暂停时间是随机的,所以我们也少给点数据,就上 10 个库存好了。
// 进程一goprogromtourbook go run main.go
续命1次
8
续命1次
7
续命1次
4
1
续命1次
0
续命1次
续命1次
续命1次// 进程二
➜ goprogromtourbook go run main.go
续命1次
9
续命1次
6
续命1次
5
3
2
续命1次
续命1次
续命1次
续命1次
续命1次其实不用我多说,你也会发现问题,那就是万一某个操作一直卡住了,锁还是无法释放啊,所以,正式情况下,我们还要考虑续命次数,一般来说续个2、3次,还不行的话可以认为当前这个操作是有问题的,应该采取别的方案,比如报错抛异常之类的。
只删自己的锁(误删锁问题)
考虑一个场景,比如 A 、B 两个进程都是耗时任务,A 上锁了,过期了(不考虑多次续命抛出异常强制结束的情况),锁被自动释放了,B 又过来上锁了,正在处理的过程中 A 那边突然炸尸了,结束任务把锁又释放了,这时不就是 A 把 B 的锁释放了嘛,然后其它进程 C、D、XXX 都来抢锁,马上就进入混乱状态了。
好解决吗?说难也难,说不难也不难。说不难是因为我们可以使用 value 值啊,设置一个标识当前进程状态的内容就可以了,删除的时候只有匹配上了才能删自己的。
go func(index int) {lockId := strconv.Itoa(os.Getpid()) + ":" + strconv.Itoa(index) // 简单做个标识…………………………if r.Get("lock").Val() == lockId { // 要判断是自己的,才进行下面的解锁操作r.Del("lock")t.Stop()l.Unlock()}…………………………
}(i)说难吧,就是这个标识的唯一性以及这个思想的转变,我们的测试其实不是很好测出释放了别人锁的情况,但如果是一个合格的架构师,应该是要去考虑这一块的内容的,而且这个也是非常容易想到的可能出 BUG 的一个点。
完整代码
其实啊,上面这堆东西大部分是面试才用得到,为啥这么说呢?真正的高并发大流量的系统,百分之90以上全是 Java 了,而 Java 中的 Redisson 包中,有非常完整的这套分布式锁方案,完全不用自己写。不知道 Go 和 PHP 有没有现成的类似于 Redisson 的包,如果有了解的小伙伴,评论区留下地址,我们一起去学习哦。
下面就把稍微优化过后的一整套完整的代码放上来,大家可以自己运行测试一下哦。具体解释记得之后看视频。
var (c chan struct{}r *redis.Clientl sync.MutexcLock CLock
)func main() {r = redis.NewClient(&redis.Options{Addr: "127.0.0.1:6379",})r.Del("stock", "lock", "verify")chanCount := 5c = make(chan struct{}, chanCount)for i := chanCount; i > 0; i-- {// 协程处理go decr(i)}for i := chanCount; i > 0; i-- {<-c}
}func decr(i int) {// 初始化锁对象cLock = CLock{key: "lock", expire: 3 * time.Second}// 解锁操作函数allUnLock := func() {l.Unlock()cLock.UnLock()}// 异常处理defer func() {if err := recover(); err != nil {// 发生异常,解锁l.Unlock()allUnLock()}}()for {l.Lock() // 原生锁// 一致性lockId := strconv.Itoa(os.Getpid()) + ":" + strconv.Itoa(i)cLock.Lock(lockId) // 分布式锁// 续命go func() {cLock.lifeTimer = time.AfterFunc(cLock.expire-cLock.expire/3, cLock.Life)}()// 模拟耗时操作rand.Seed(time.Now().UnixNano())randomNum := rand.Intn(6)time.Sleep(time.Duration(randomNum) * time.Second)stock, err := r.Get("stock").Int()if err != nil {allUnLock()continue}if stock <= 0 {allUnLock()c <- struct{}{}break}r.Decr("stock")// 数据如果有重复操作,提示出来,并停止当前进程if res, _ := r.SAdd("verify", r.Get("stock").Val()).Result(); err != nil || res == 0 {allUnLock()fmt.Println("数据有重复: ", r.Get("stock").Val())os.Exit(1)}// 打印操作的是谁fmt.Println(lockId, "操作:", r.Get("stock").Val())allUnLock()}
}type CLock struct {key string // 锁的 Keyexpire time.Duration // 超时时间life int // 续命次数lifeTimer *time.Timer // 续命定时器lockId string // 锁的值
}func (cLock *CLock) Lock(id string) {for {b := r.SetNX(cLock.key, id, cLock.expire)if b.Err() != nil {fmt.Println(b.Err().Error())continue}if b.Val() {break}}cLock.life = 0cLock.lockId = idif cLock.lifeTimer != nil {cLock.lifeTimer.Stop()}
}func (cLock *CLock) UnLock() {getId := r.Get(cLock.key).Val()if getId == cLock.lockId {r.Del(cLock.key)if cLock.lifeTimer != nil {cLock.lifeTimer.Stop()}}
}func (cLock *CLock) Life() {if cLock.lockId != "" {if cLock.life < 3 {getId := r.Get(cLock.key).Val()if getId == cLock.lockId {r.Expire(cLock.key, cLock.expire)cLock.life++// cLock.lifeTimer.Stop()cLock.lifeTimer = time.AfterFunc(cLock.expire-cLock.expire/3, cLock.Life)fmt.Println(cLock.lockId, "续命", cLock.life, "次")}} else {panic("续命超次数")}}
}上述代码并不是完全的真正可用的分布式锁代码,只是我们根据分布式锁的概念去写的,并没有进行详细的测试,所以可能还是会有很多的 BUG 和问题,不推荐直接复制走了就放到线上去使用哦。
红锁 RedLock
红锁这个概念啊,其实和 Zookeeper 还有点关系,另外还要和存储架构中的 CAP 原理扯上关系。CAP 表示的就是一致性、可用性和分区性,当分区性存在的时候时候,CA 无法两全。啥意思?一旦有分区,可用和一致就没办法一起达到,毕竟只要有分区,就一定会有延迟,不管延迟的大小,它一定是客观存在的。想要高可用,那就尽量减少分布数量,或者仅从一台主机获取结果就认为结果是确定的。而想要一致性,也就是所有主机的数据都确定或者超过半数以上的主机确认,这条数据才真正的确定是当前的值,这样可用性就差了,为啥?要一条一条的每台机器都确认嘛。
正常来说,Redis 的分布式锁是 AP 式的,而 Zookeeper 的分布式锁是 CP 式的。一般 Zookeeper 都是三台机器起步,同一把锁必须有两台主机确认锁上了,它才会返回真的锁上了。而在 Redis 中其实没有这样的机制,即使是 Cluster 也是把 Key 做 Hash 放到不同的机器上去了。这也是 Redis 的特点所决定的,它本身就是一个高可用的快速缓存系统嘛。
不过各位大佬们不甘心,于是就出现了 RedLock 这个概念。其实就是多台 Redis ,通过程序代码控制,比如配置三台 Redis 主机,上锁的时候必须有两台上锁成功了才表示成功。
同样,Java 的 Redisson 中也有现成的解决方案,对于我们来说,知道有这么个东西就好了。自己想要去实现的话,最好还是看看分析一下 Redisson 的源码,然后去依照它的写,就像上面的我们实现的分布式锁也是一样,实验性质的,和 Java 中已经成熟的工程化的代码还是有很大区别的。毕竟它们会考虑更多的问题,而我们可能有很多会想不到。
在 PHP 中,其实通过 packagist.org 还是能搜到不少的 RedLock 相关的组件的,只不过我并没有试过,有没有好用的大家有用到的朋友可以给点意见哈。
总结
今天的内容有点长,但其实主要是代码粘的多点。再次强调,我们最后的分布式锁的代码只是测试性质的,看了很多讲 Redis 的教程中各位老师基本都会用 Java 来实现一个简单的分布式锁,因此我这个其实也大部分是根据分布式锁的概念用 Go 代替 Java 写了一遍,有会 Swoole 的小伙伴也可以尝试改造成 Swoole 版本的哦。但是,就像他们的课程最后都会引到 Redisson 上一样,确实自己写的会有很多地方欠缺考虑,专业开源稳定的一些软件包才是真正应用在业务开发中的首选。如果真的想用,其实不太需要考虑续命之类的问题,这一块要完美实现真的很绕的,只要超时没执行完就中断好了。这样一个简单的分布式锁其实也足够应对不小的流量和大部分的需求了。要知道,能力越大责任越大,有时候如果我们无法考虑的完美,那么干脆换个角度看能不能不要这个特性,通过其它更简单的方式来弥补。
可惜的是,在 PHP 和 Go 领域,貌似还没发现有类似 Redisson 这样的非常出名的 Redis 分布式扩展,去搜索一下也能找到一些,至于好不好用我也不清楚。还是那句话,平常用不到啊,大家加油冲向大厂啊,努力找大神带带啊,要不这些玩意学起来真 TNND 的费劲。
测试代码:
https://github.com/zhangyue0503/dev-blog/blob/master/redis/2022/source/25.go
相关文章:
【Redis25】Redis进阶:分布式锁实现
Redis进阶:分布式锁实现 锁这个概念,不知道大家掌握的怎么样。我是先通过 Java ,知道在编程语言中是如何使用锁的。一般 Java 的例子会是操作一个相同的文件,但其实我们知道,不管是文件,还是数据库中的一条…...

【蓝桥杯算法题】输入输出流问题
【蓝桥杯算法题】输入输出流问题 题目:对文本文件进行带缓存的读写操作,可以读取文件不同位置的信息,可以进行对象序列化和对象反序列化。解释:总结: 题目:对文本文件进行带缓存的读写操作,可以…...

BUG提交单模版一
提交人员 XX 提交时间 2005-06-16 产品名称...

Android 12.0系统默认授予读写权限给第三方app
1.概述 在12.0的系统rom定制化开发中, 在6.0以前读写权限是默认授予的,app不需要申请权限 在10.0之前需要android.permission.WRITE_EXTERNAL_STORAGE和android.permission.READ_EXTERNAL_STORAGE 权限就可以了而在安卓11的时候继续强化对SD卡读写的管理,引入了MANAGE_EXTER…...
【生信】R语言在RNA-seq中的应用
R语言在RNA-seq中的应用 文章目录 R语言在RNA-seq中的应用生成工作流环境读取和处理数据由targets文件提供实验定义对实验数据进行质量过滤和修剪生成FASTQ质量报告 比对建立HISAT2索引并比对 读长量化读段计数样本间的相关性分析 差异表达分析运行edgeR可视化差异表达结果计算…...
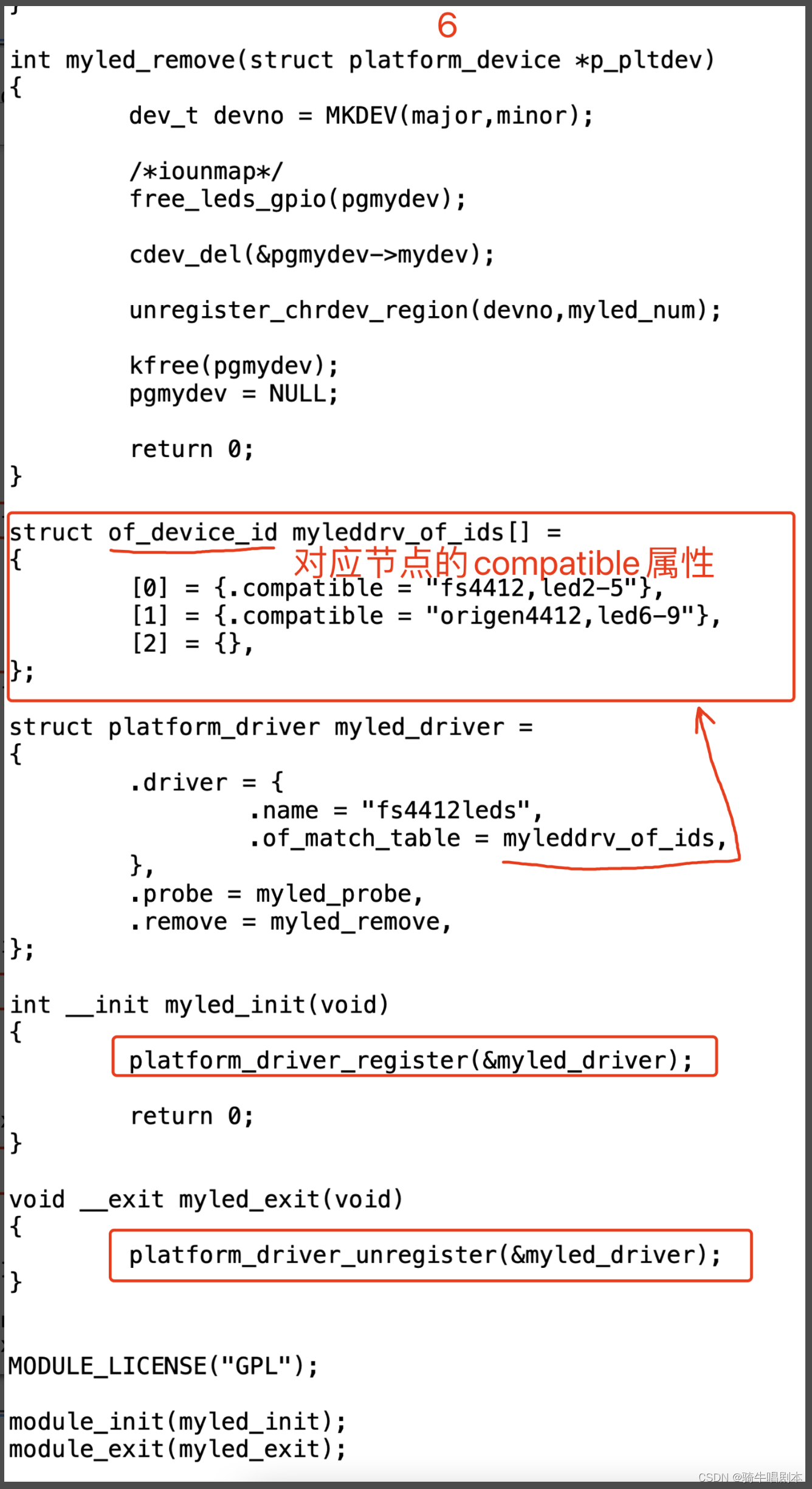
【嵌入式环境下linux内核及驱动学习笔记-(14)linux总线、设备、驱动模型之platform】
目录 1、新驱动架构的导入1.1 传统驱动方式的痛点1.2 总线设备驱动架构 2、platform 设备驱动2.1 platform总线式驱动的架构思想2.2 platform _device相关的数据类型2.2.1 struct platform_device2.2.2 struct platform_device_id2.2.3 struct resource2.2.4 struct device 2.3…...

绝地求生 压q python版
仅做学习交流,非盈利,侵联删(狗头保命) 一、概述 1.1 效果 总的来说,这种方式是通过图像识别来完成的,不侵入游戏,不读取内存,安全不被检测。 1.2 前置知识 游戏中有各种不同的q械…...

云原生技术中的容器技术有哪些?
文章目录 云原生技术中的容器技术有哪些1、云原生的含义2、容器的含义3、云原生的技术的基石:容器技术4、容器技术有哪些? 结语 云原生技术中的容器技术有哪些 在现今的安全行业中云原生安全技术中的容器安全技术有哪些呢,很多用户都不知道具体的含义以…...

Gin中间件的详解 ,用Jwt-go 和 Gin 的安全的登陆的中间件
学习目标: Gin 在不同的group 设置不同的中间件或者过滤器 Gin 的group下的路由上中间件或过滤器 用Jwt-go 和 Gin 的安全的登陆的中间件 JWT 类,它基本有所有基本功能,包括:GenerateToken,GenerateRefreshToken, ValidateToken, ParseToken 学习内容: 1. Gin 在不同的g…...
Nginx网站部署
Nginx网站部署 一、访问状态统计配置二、基于授权的访问控制三、基于客户端的访问控制四、基于域名的 Nginx 虚拟主机五、基于IP 的 Nginx 虚拟主机六、基于端口的 Nginx 虚拟主机 一、访问状态统计配置 1.先使用命令/usr/local/nginx/sbin/nginx -V 查看已安装的 Nginx 是否包…...

Hadoop优化
1.小文件 影响: 元数据的瓶颈在于文件的数量,无论单个文件的大小 资源大材小用 优化 计算:使用combininputformat提前合并小文件 JVM重用 存储:归档 2.map端 环形缓冲区-区域大小、溢写比列 提前combinerÿ…...
)
FPGA设计的指导性原则 (中)
1.6基本设计思想与技巧之二:串并转换 串并转换是FPGA设计的一个重要技巧,从小的着眼点讲,它是数据流处理的常用手 段,从大的着眼点将它是面积与速度互换思想的直接体现。串并转换的实现方法多种多样, 根据数据的排序和数量的要求,可以选用寄存器、RAM等实现。前面在乒乓…...

开源创新 协同融合|2023 开放原子全球开源峰会开源协作平台分论坛即将启幕
由开放原子开源基金会主办,阿里云、CSDN 等单位共同承办的开源协作平台分论坛即将于 6 月 12 日上午在北京经开区北人亦创国际会展中心隆重召开。作为 2023 开放原子全球开源峰会的重要组成部分,开源协作平台分论坛将聚焦于开源代码平台的创新功能、用户…...

第四章 相似矩阵与矩阵对角化
引言 题型总结中推荐例题有蓝皮书的题型较为重要,只有吉米多维奇的题型次之。码字不易,如果这篇文章对您有帮助的话,希望您能点赞、评论、收藏,投币、转发、关注。您的鼓励就是我前进的动力! 知识点思维导图 补充&…...

课程11:仓储层Repository实现、AutoMapper自动映射
课程简介目录 🚀前言一、Repository项目1.1创建Repository项目1.2 添加类1.2.1、添加类 RolePermissionRepositiory1.2.2、添加项目引用1.2.3、注入数据库上下文1.3 RolePermissionRepositiory接口的实现二、Repository注入2.1 提取接口2.2 添加项目依赖2.3 项目入口添加依赖…...
)
关于作用域的那些事(进阶)
一、作用域 原理: 作用域 > 房子 > 除了对象的{}都构成一个作用域 作用域 > 为了区别变量.不同作用域内声明的变量是各不相同的.(就算名字相同). 作用域语法: let x 10; (全局变量). if () {块级作用域 let y 20; (局部变量)} for () {块级作用…...

小技巧notebook
小技巧notebook 1、MybatisPlus 批量保存 从BaseMapper接口方法可知,mybatis plus mapper只有根据id批量删除和查询,没有批量保存(insert 、update),要实现也很简单,需要定义一个Service Service Slf4j …...

【2451. 差值数组不同的字符串】
来源:力扣(LeetCode) 描述: 给你一个字符串数组 words ,每一个字符串长度都相同,令所有字符串的长度都为 n 。 每个字符串 words[i] 可以被转化为一个长度为 n - 1 的 差值整数数组 difference[i] &…...

Java面试-每日十题
目录 1.try-catch-finally中的finally的执行机制 2.什么是Exception和Error 3.Throw和Throws的区别 4.Error与Exception区别 5.Java中的I/O流是什么,分为几类 6.I/O与NI/O 7.常用的I/O的类有哪些 8.字符流与字节流的区别 9.Java反射创建对象 10.什么是类的…...
java.awt.datatransfer.Clipboard剪切板获取String字符串文本
java.awt.datatransfer.Clipboard剪切板获取String字符串文本 有两种方法获取 直接从Clipboard获得 (String) systemClipboard.getData(DataFlavor.stringFlavor);从Clipboard获得Transable再获得String (String) systemClipboard.getContents(null).getTransferData(DataFlav…...

基于离散阻抗与线性回归的嵌入式电池健康状态在线估计方法
1. 项目概述:当电池健康遇上“轻量级”机器学习在电动汽车、储能电站乃至消费电子领域,锂离子电池的健康状态(State of Health, SoH)都是一个绕不开的核心指标。它直接决定了设备的续航能力、安全边界乃至剩余价值。传统的BMS&…...

PICO Unity APK闪退的五大根因与工程化排查指南
1. 为什么PICO项目打包APK后“秒退”不是玄学,而是可定位的工程链路断裂 “Unity打包PICO APK闪退”——这六个字在XR开发群、技术论坛和外包项目交接现场出现的频率,几乎和“黑屏”“白屏”“加载失败”并列成为移动端开发三大幽灵问题。我接手过27个P…...

结构体标签与数据流向 笔记
一、什么是结构体标签(Struct Tag) Go 里面: 结构体字段后面经常会跟一串奇怪的东西: Nickname string json:"nickname" gorm:"column:nickname" toml:"nickname"这个东西: 叫ÿ…...

衰老生物学领域首个1站式标准化DNA甲基化数据库
摘要 准确量化生物年龄对于解析衰老机制、研发高效干预手段至关重要。分子衰老时钟(尤其是基于DNA甲基化数据的表观遗传时钟)已成为衰老研究领域的核心工具。然而,目前缺少覆盖多年龄、多组织且格式统一的公开DNA甲基化数据集,导致表观遗传时钟研究难以高效推进。研究者在…...

从PCA到ICA:降维与因子分析的核心原理与实战应用
1. 降维与因子分析:从理论到实战的深度拆解在数据科学和机器学习的日常工作中,我们常常会遇到一个令人头疼的问题:数据维度太高了。想象一下,你手头有一份用户画像数据,包含了成百上千个特征,从年龄、性别到…...

Prompt Cache:别再为同样的 System Prompt 重算一遍
多轮对话里 System Prompt 每次都一样——500 Token 的固定前缀,每轮推理都要重跑一遍 Prefill。等于把同一段文字反复"读"几十上百遍。Prompt Cache 就是来省掉这件重复劳动的。 正常推理流程下,一个新请求进来先跑 Prefill(全 P…...

别再被GPG签名卡住了!手把手教你修复老版本Kali Linux的apt更新源报错
彻底解决Kali Linux旧系统GPG签名失效:从原理到实战当你面对Kali Linux系统中apt-get update命令抛出的一连串GPG签名错误时,那种挫败感我深有体会。作为一名长期维护渗透测试环境的工程师,我见过太多同行因为这类问题放弃旧系统,…...

多重插补与MICE:量化ESG评分不确定性的工程实践
1. 项目概述:当ESG评分遇上数据“黑洞”,我们如何量化不确定性?在金融和可持续投资领域,ESG评分正成为评估公司长期价值与风险的关键标尺。然而,从业者们都心知肚明一个公开的秘密:支撑这些评分的底层数据&…...
:如何用3步完成eIDAS 2.0兼容性认证与审计留痕闭环)
Gemini KYC合规沙盒实战(仅限首批200家持牌机构开放):如何用3步完成eIDAS 2.0兼容性认证与审计留痕闭环
更多请点击: https://intelliparadigm.com 第一章:Gemini KYC流程优化 Gemini 交易所的 KYC(Know Your Customer)流程长期以来以严谨著称,但用户反馈表明,传统表单提交人工审核模式存在平均 3.2 天的等待延…...

Zotero Duplicates Merger:终极文献去重解决方案,告别重复文献困扰
Zotero Duplicates Merger:终极文献去重解决方案,告别重复文献困扰 【免费下载链接】ZoteroDuplicatesMerger A zotero plugin to automatically merge duplicate items 项目地址: https://gitcode.com/gh_mirrors/zo/ZoteroDuplicatesMerger 你是…...