为什么是ChatGPT引发了AI浪潮?
目录
BERT和GPT简介
BERT和GPT核心差异
GPT的优势
GPT的劣势
总结
随着近期ChatGPT的火热,引发各行各业都开始讨论AI,以及AI可以如何应用到各个细分场景。为了不被时代“抛弃”,我也投入了相当的精力用于研究和探索。但在试验的过程中,我的直观感受是,NLP很厉害,但GPT并不好用,反倒是BERT更加顺手,如臂使指。
同样是大语言模型,那引爆AI浪潮的,为什么是GPT,而不是BERT呢?尝试对这个话题进行一下探讨。
BERT和GPT简介
Encoder-Decoder是NLP中的经典架构:Encoder对文本进行编码,输出Embedding;Decoder基于Embedding进行计算,完成各种任务,得到输出。示例如下:

之所以会诞生这种架构,个人认为,是因为对文本进行特征工程,转化为机器可以处理的向量,是一件反人类的事情。因此,专门设计了Encoder来完成这个工作。
2017年,Google提出了Transformer,在性能、结果、稳定性等多个方面都优于RNN模型,使得NLP领域进入了下一个阶段。紧接着2018年,Google基于Transformer架构,提出了BERT,将“预训练”这一模式发扬光大。而随着OpenAI炼丹多年,发布了ChatGPT,将NLP带入大众视野,使得GPT变成了当前的主流。
BERT和GPT的实现原理,简单来说就是:BERT是Encoder-only,即上图的左半边;GPT是Decoder-only,即上图的右半边。
具体来说,BERT的最终输出其实是Embedding,它并不关注任务具体是什么。而这个Embedding足够好用,使得其可以通过拼接其他算法,完成各种任务(比如基于Embedding去分类)。
而GPT则是有固定任务的,predict next word。GPT的工作模式,就是通过不断的predict next word,拼接成完整的语句,得到结果。这就是所谓的“生成式”。
各类NLP算法的工作范式如下:

三个阶段的NLP技术范式。引用自:关于ChatGPT:GPT和BERT的差别(易懂版) - 知乎
BERT和GPT核心差异
BERT的核心产出是Embedding。在接触之后,Embedding的效果可以用“惊艳”来形容。下面基于几个具体示例来展示Embedding的强大之处:
TransE
在知识图谱中,有一种基于距离的模型,可以用来完成两个实体间关系的挖掘和构建。其大致效果如下:
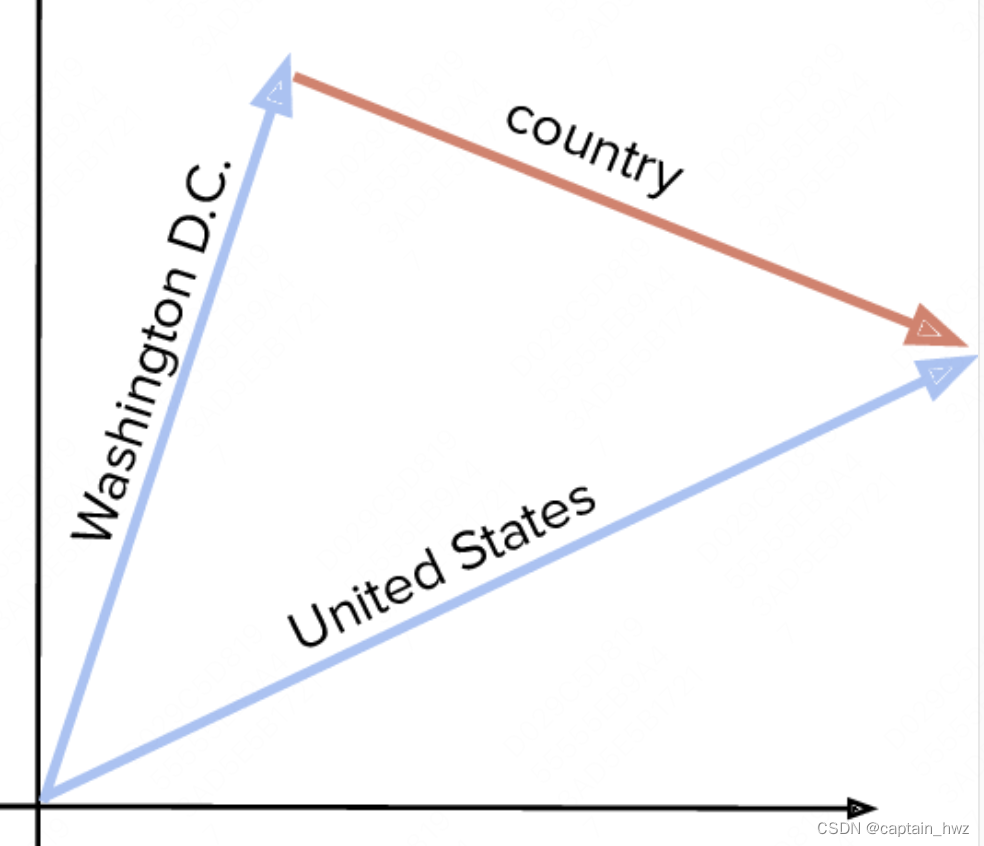
Washington和US作为两个实体,被Embedding后,形成了一个类似于力矩的空间,可以轻松完成各种加减运算,得到目标结果。
KeyBert
类似的,在文本摘要任务中,有一种基于余弦相似度的算法。其原理和TransE类似,在Embedding把文本进行向量化表示的情况下,Embedding之间的余弦相似度就等同于词义之间的相似度。
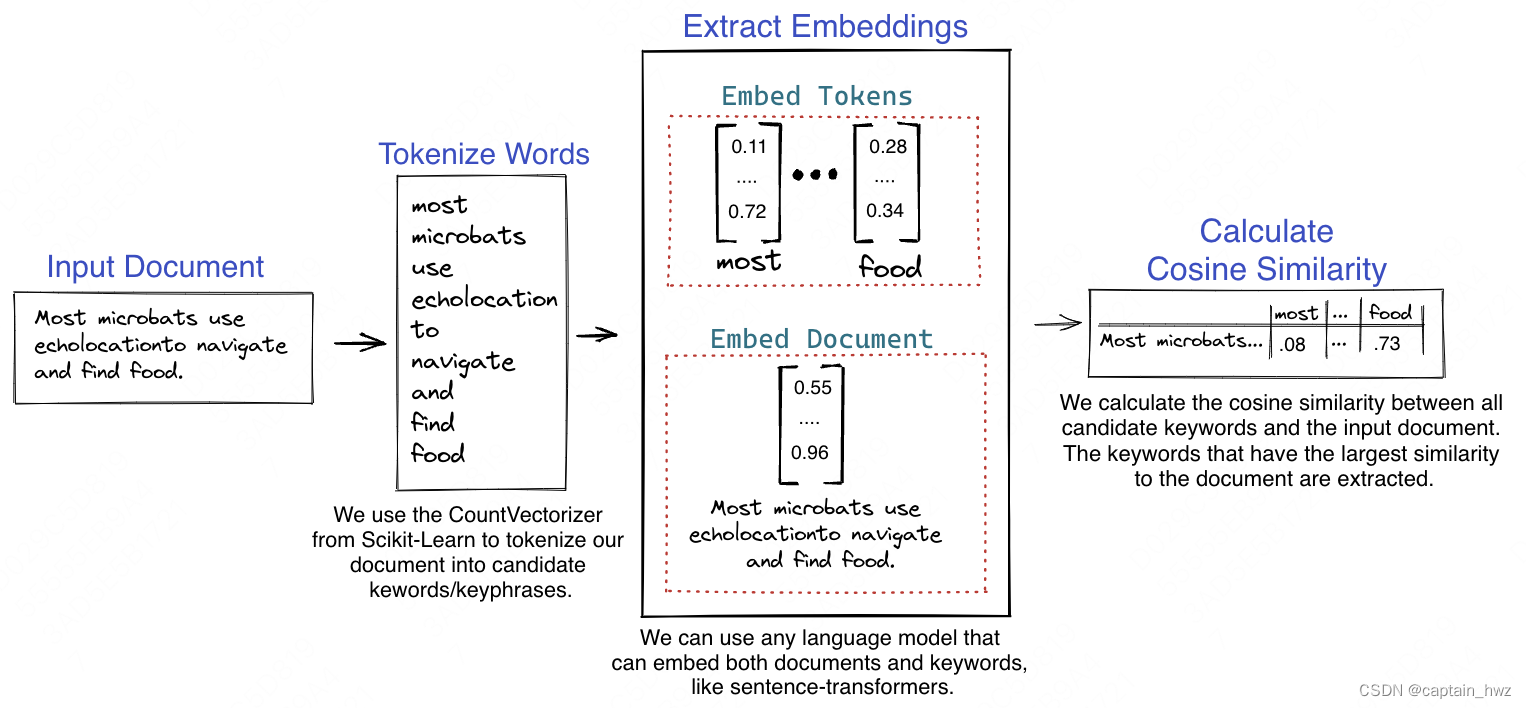
机器擅长于处理向量的各种运算,但语言是一种非结构化的信息,这是两者之间最大的GAP。为了调和这个GAP,我们设计了各种各样的编程语言,由人来完成自然语言到机器语言的转化工作。但Embedding的出现,让机器能够自己将自然语言进行向量化表示,并且向量化结果还能够匹配人类所理解的各种语言和认知逻辑,这也是我认为机器理解人类世界的关键所在。
与BERT专注于编码不同,GPT专注于回答问题。我认为这也是GPT的Decoder-only架构在结果表现上最核心的优势:
- 对于BERT来说,Encoder生产完Embedding只是第一步,还需要嵌套一层其他算法,才能完成具体任务。而由于Embedding比较好用,往往又不倾向于再叠加更复杂的算法,基本都是一个线性层+softmax搞定。
- 对于GPT来说,则不关注中间过程,直接回答结果。因此,在同等参数量级情况下,理论上Decoder-only会有更多的资源投入到完成任务中去,所以会获得更好的结果表现。
因此,ChatGPT表现出了通用智能的效果(完成任务能力更强),而BERT仍然需要经过特定领域的fine-tuning(每个领域下的embedding逻辑并不通用),才能完成应用。
关于为什么现在LLM都在搞Decoder-only,知乎上有相关讨论(为什么现在的LLM都是Decoder only的架构? - 知乎),但没有明确结论。基于讨论内容,个人倾向于判断,各种架构在结果上其实是没有太大差异的,纯粹是因为现在大家都追求高效&通用,所以更适合Decoder-only来进行处理。
进一步展开,BERT和GPT的核心差异,我认为在于这个中间结果,Embedding。
 当大家都在讨论GPT随着参数量的扩增,出现智能的“涌现”时,我尝试去思考了一个问题:为什么没人去扩增BERT的参数量?搜索良久不得答案后,我想到了一个可能:“够用了”。
当大家都在讨论GPT随着参数量的扩增,出现智能的“涌现”时,我尝试去思考了一个问题:为什么没人去扩增BERT的参数量?搜索良久不得答案后,我想到了一个可能:“够用了”。
Embedding是为了具体任务而生的,不同场景下,同一个词会展现为不同的词性,因此需要通过fine-tuning来让BERT迁移到不同的领域中去。而当模型只是为了完成某个特定领域的任务,扩增参数就变得完全没有必要了。而反过来,Embedding也限制了BERT只能成为特定领域的专家工具,具备较高的使用门槛,因此很难得到普及。
GPT的优势
OpenAI最大的功劳,应该是设计出了对话模式,大幅度降低了AI的“体验”门槛(注意,是体验,不是应用),从而让各行各业都开始关注AI的变化和可能。
那么,冷静下来思考,GPT的强大之处到底是什么呢。是GPT能够处理非结构化的文本信息吗?是GPT所拥有的庞大知识储备吗?我认为,这都不是GPT的独有能力,BERT增加参数量和训练量后应该同样能够做到。

而人们真正感到兴奋的,应该是GPT展现出来的创造能力。在这之前,机器无法取代人类的场景,基本都是多领域融合的问题。比如写文档、编程,不是仅仅会打字和懂语法就够了,你还得理解背后的业务逻辑,才能够完成。(类比于翻译,虽然也会涉及一定的专业背景,但即使啥都不懂,依靠词典和例句,也能翻译个大概。所以过往机器能够完成翻译任务。)而这种多领域融合的创造能力,是GPT在结合“Transformer的知识储备”和“生成式的通用解题范式”,所带来的独有能力。
- BERT虽然也有强大的知识储备,但完成任务的模式相对固定。如果要处理复杂任务,还得训练同等量级的Decoder,反倒不如GPT的Decoder-only来得直接。
- RNN虽然是生成式的,但串型结构带来的效率瓶颈和遗忘问题,限制其了知识储备。
因此,GPT的这种创造力,可以大幅度扩展AI的应用场景,使得更多的人类工作被替代。
GPT的劣势
既然GPT拥有更好的通用性,那我们应该万物皆GPT嘛?我倒觉得大可不必。
ROI考量
任何能力的扩增,其实都会带来运算成本的增长,因此,我们需要在ROI上进行考量。
举个简单的例子,你要完成一个数学运算,是使用计算器合适,还是问GPT更合适呢?答案显然是前者,哪怕GPT增加插件模式,可以准确完成数学运算,但它的计算开销是远高于计算器本身的。同理,在流水线工作中,使用单一功能的机器,ROI也远高于雇一个人。

所以,越是固定的任务,其所需要的模型能力越低。明明有固定的输入输出模式,非得转成对话模式去做处理,多少有点“杀鸡用牛刀”的感觉了。
数据量限制
目前GPT(或者NLP领域)能够处理的输入长度都是有限制的。相比于其内部计算的百亿级参数,几千个token的输入长度,多少显得有点不够看了。
语言是一种非结构化信息,它的信息传输效率是远低于结构化的特征的。过去在进行推荐、分类等各种任务时,我们可以人工运算出十万维度的特征来,交由模型去进行处理。但在GPT模式下,如何把这十万维的特征以文本的形态输入GPT进去呢?又或者,可以在GPT之前增加一个Encoder来负责处理。但这样一来,通用性无法得到保障,很可能需要自己训练一个GPT,而不是直接使用大公司预训练好的模型。
 因此,GPT目前更擅长的,其实是引经据典,回答各种知识点性质的问题。而对于基于庞大输入完成的综合决策过程,并不适合使用GPT来解决。
因此,GPT目前更擅长的,其实是引经据典,回答各种知识点性质的问题。而对于基于庞大输入完成的综合决策过程,并不适合使用GPT来解决。
总结
本篇一定程度上是因面对GPT的过度吹捧,有感而发。个人认为,目前火热的不是GPT,而是ChatGPT把AI重新带回大众视野,引发了更多的AI应用尝试。
而这波热潮带给我的最大收益,是引发了NLP对于非结构化数据的处理能力的研究思考,应当能够解决过往很多数据处理的难题。
 至于GPT本身,因为接收输入的不足,我认为不足以作为一个线上功能去使用。(所以现在的产品形态基本都是Copilot,相当于更高阶版的搜索引擎。)但其展现的创造性潜力,确实值得我们保持关注和探索。
至于GPT本身,因为接收输入的不足,我认为不足以作为一个线上功能去使用。(所以现在的产品形态基本都是Copilot,相当于更高阶版的搜索引擎。)但其展现的创造性潜力,确实值得我们保持关注和探索。
相关文章:
为什么是ChatGPT引发了AI浪潮?
目录 BERT和GPT简介 BERT和GPT核心差异 GPT的优势 GPT的劣势 总结 随着近期ChatGPT的火热,引发各行各业都开始讨论AI,以及AI可以如何应用到各个细分场景。为了不被时代“抛弃”,我也投入了相当的精力用于研究和探索。但在试验的过程中&…...
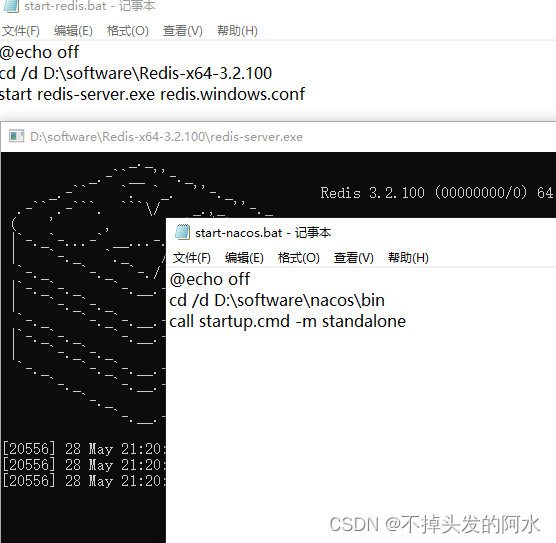
批处理文件(.bat)启动redis及任何软件(同理)
批处理文件 每次从文件根目录用配置文件格式来启动redis太麻烦了 可以在桌面上使用批处理文件(.bat)启动Redis,请按照以下步骤进行操作: 打开文本编辑器,如记事本。 在编辑器中输入以下内容: 将文件保存…...

深度学习求解稀疏最优控制问题的并行化算法
稀疏最优控制问题 问题改编自论文An FE-Inexact Heterogeneous ADMM for Elliptic Optimal Control Problems with L1-Control Cost { min y ( μ ) , u ( μ )...

牛客网项目—开发社区首页
视频连接:开发社区首页_哔哩哔哩_bilibili 代码地址:Community: msf begin 仿牛客论坛项目 (gitee.com) 本文是对仿牛客论坛项目的学习,学习本文之前需要了解Java开发的常用框架,例如SpringBoot、Mybatis等等。如果你也在学习牛…...

uniapp水文【uniapp】
文章目录 1、前言2、历史3、发展4、功能5、优缺点6、总结7、附录7.1、高频使用7.2、使用注意 1、前言 Uniapp是一种跨平台的移动应用开发框架,它允许开发者使用一套代码库,同时生成iOS、Android等多个平台的应用程序。这种技术方案可以大大降低开发成本…...

Java函数式接口
3 函数式接口 3.1 函数式接口概述 函数式接口:有且仅有一个抽象方法的接口 Java中的函数式编程体现就是Lambda表达式,所以函数式接口就是可以适用于Lambda使用的接口只有确保接口中有且仅有一个抽象方法, Java中的Lambda才能顺利地进行推导…...

安装libevent库
安装libevent库 yum install libevent libevent-devel 自动安装Memcached yum install memcached 源码安装 下载1.6.19版本 wget https://www.memcached.org/files/memcached-1.6.19.tar.gz (若证书过期yum install -y ca-certificates) 解压源码 tar -zxvf…...

vue 截取字符串的方法
vue中的字符串方法,我目前使用最多的是下面两种方法,因为 vue的字符串方法支持断言操作。 1、 vue中截取字符串的方法如下: 2、 vue中截取字符串的方法,这个方法也是需要依赖于 vue库提供的支持。 3、 vue中截取字符串的方法&…...

可数集和不可数集
有限集和无限集 后继集 设 S S S是任一集合,称 S S ∪ { S } S^ S\cup \left\{ S\right\} SS∪{S}为 S S S的后继集 自然数集 自然数集 N \mathbb{N} N的归纳定义是: (1) ∅ ∈ N \empty \in \mathbb{N} ∅∈N (…...
》)
<Linux>《Linux 之 ps 命令详解大全(含实用命令)》
《Linux 之 ps 命令详解大全(含实用命令)》 1 常用命令1.1 显示所有当前进程1.2 显示所有当前进程1.3 显示所有当前进程1.4 根据用户过滤进程1.5 根据 CPU 使用来升序排序1.6 根据用户过滤进程1.7 查询全10个使用cpu和内存最高的应用1.8 通过进程名和PID…...

华为OD机试真题 Java 实现【寻找关键钥匙】【2023Q1 100分】
一、题目描述 小强正在参加《密室逃生》游戏,当前关卡要求找到符合给定 密码K(升序的不重复小写字母组成)的箱子,并给出箱子编号,箱子编号为1~N。 每个箱子中都有一个字符串s,字符串由大写字母,小写字母,数字,标点符号,空格组成,需要在这些字符串中找出所有的字母…...
)
项目中遇到的一些问题总结(十三)
extension-configs 和 shared-configs 的区别 在 Nacos 配置管理中,extension-configs 和 shared-configs 分别是两种不同类型的配置,它们的主要区别在于它们的使用场景和作用。 extension-configs 是一种应用程序向 Nacos 注册的扩展配置。它主要用于给…...
)
药品存销信息管理系统数据设计与实现(包括需求分析,数据库设计,数据表、视图、存储过程等)
前言 可前往链接直接下载: https://download.csdn.net/download/c1007857613/87776664 或者阅读本博文的详细介绍,本博文也包含所有详细内容。 一、需求分析 a.“药品存销信息管理系统”只是对数据库应用技术的一个样本数据库的实例,重在对数据库一些方法的熟悉与掌握,…...
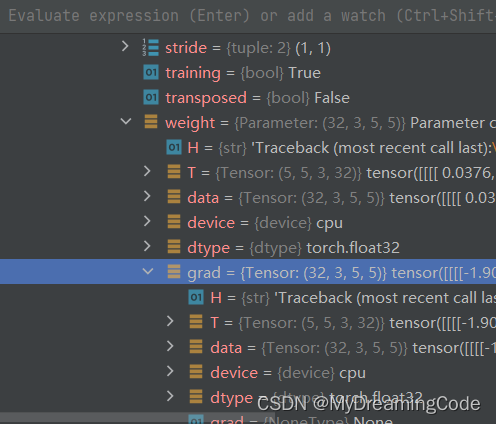
PyTorch-Loss Function and BP
目录 1. Loss Function 1.1 L1Loss 1.2 MSELoss 1.3 CrossEntropyLoss 2. 交叉熵与神经网络模型的结合 2.1 反向传播 1. Loss Function 目的: a. 计算预测值与真实值之间的差距; b. 可通过此条件,进行反向传播。 1.1 L1Loss import torch from …...

centos docker安装mysql8
1、创建挂载文件夹 mkdir -p /mydata/mysql/log mkdir -p /mydata/mysql/data mkdir -p /mydata/mysql/conf 2、拉取镜像最新版本,如果写 mysql:8.0.26可以指定版本 docker pull mysql 3、启动命令 docker run -p 3306:3306 --restartalways -v /mydata/mysql/log:…...
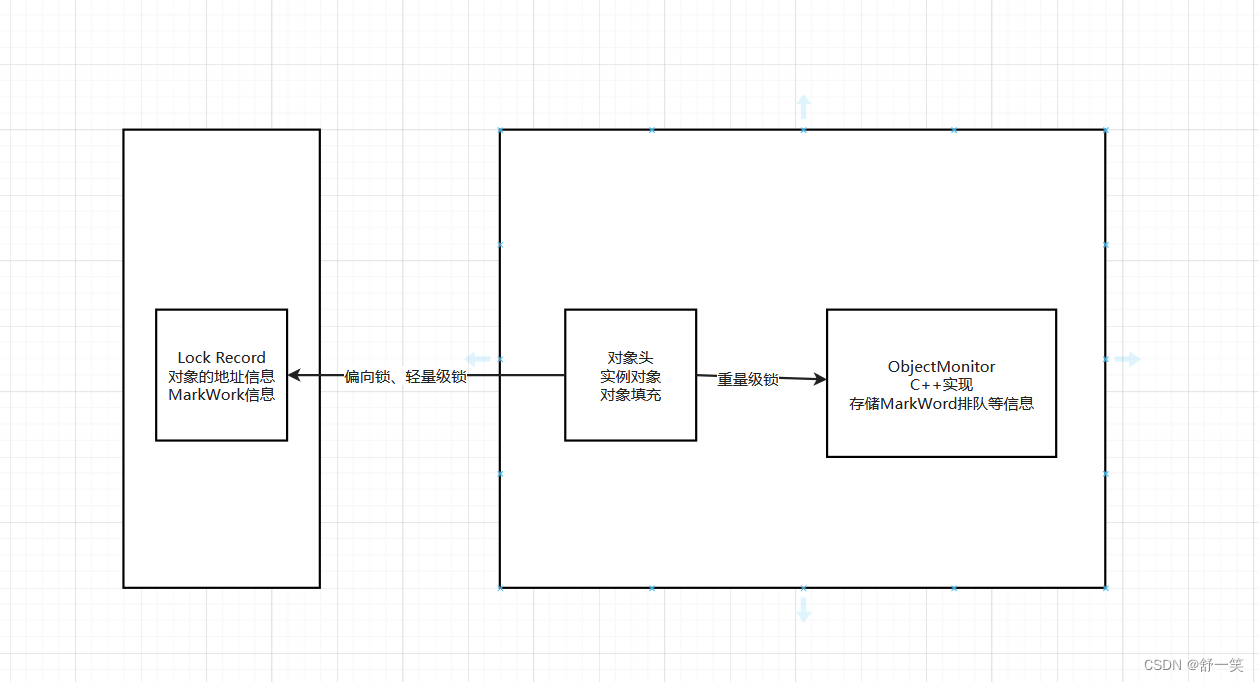
Java中synchronized锁的深入理解
使用范围 synchronized使用上用于同步方法或者同步代码块在锁实现上是基于对象去实现使用中用于对static修饰的便是class类锁使用中用于对非static修饰的便是当前对象锁 synchronized的优化 在jdk1.6中对synchronized做了相关的优化 锁消除 在synchronized修饰的代码块中…...

Find My资讯|iOS17将重点改进钱包、Find My、SharePlay和AirPlay等功能
彭博社的马克・古尔曼(Mark Gurman)在最新一期 Power On 时事通讯中表示,苹果即将推出的 iOS 17 系统将改进 Wallet、Find My、SharePlay 和 AirPlay 等多项功能。 古尔曼在博文中还表示苹果会增强 Find My 的位置服务,同样也没…...

什么是webSocket?
什么是webSocket WebSockets是一种协议,它允许在Web应用程序中建立持久连接。这意味着当客户端与服务器建立连接后,它们可以始终保持连接状态,直到其中一个终止连接。相比于传统的HTTP协议,WebSockets提供了更高效的方式来处理实…...

黑马Redis视频教程高级篇(一:分布式缓存)
目录 分布式缓存 一、Redis持久化 1.1、RDB持久化 1.1.1、执行时机 1.1.2、RDB原理 1.1.3、小结 1.2、OF持久化 1.2.1、AOF原理 1.2.2、OF配置 1.2.3、AOF文件重写 1.3、RDB与AOF对比 二、Redis主从 2.1、搭建主从架构 2.1.1、集群结构 2.1.2、准备实例和配置 …...
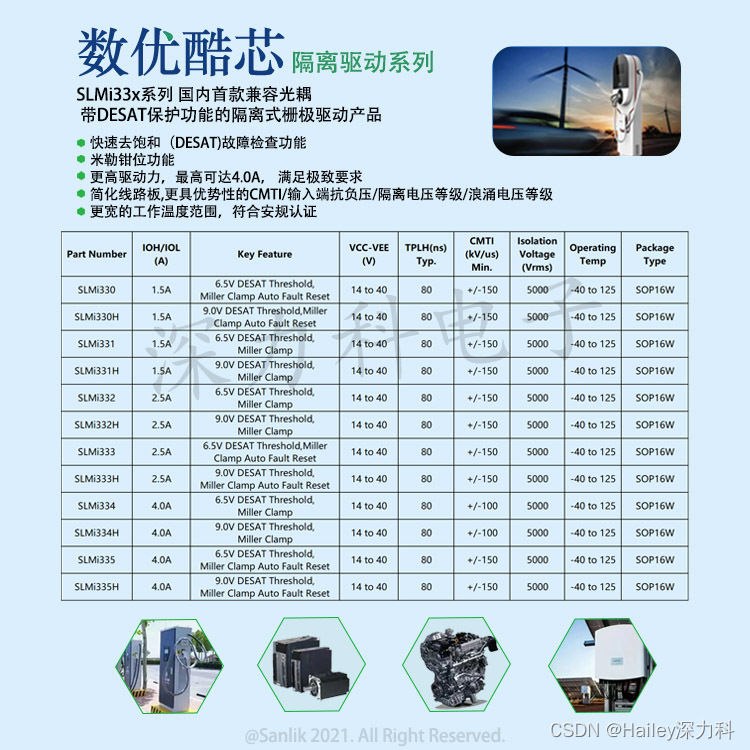
SLMi331数明深力科带DESAT保护功能隔离驱动应用笔记
SLMi33X系列SLMi331数明深力科首款单通道带DESAT保护功能的IGBT/SiC隔离驱动器。内置快速去饱和(DESAT) 故障检测功能、米勒钳位功能、漏极开路故障反馈、软关断功能以及可选择的自恢复模式,兼容光耦隔离驱动器。 SLMi331的DESAT阈值为6.5V,其最大驱动电…...

全域流量矩阵系统的运筹学解法:用线性规划模型,算出你100个账号的最优流量分配
手里有100个账号,抖音30个、小红书25个、视频号20个、B站15个、快手10个——然后呢?大多数人的做法是:每个平台平均发,每个账号随便发,发完看天吃饭。这不叫矩阵运营,这叫资源浪费。今天换个完全不同的视角…...

手把手教你把Windows虚拟内存文件pagefile.sys从C盘挪走,给SSD系统盘腾出几十G空间
彻底解放C盘空间:Windows虚拟内存文件迁移全指南 你是否遇到过这样的场景:刚装完系统时C盘还剩下大半空间,用着用着却突然弹出"磁盘空间不足"的警告?打开资源管理器一看,一个名为pagefile.sys的"巨无霸…...

CMSIS-DSP库更新指南与性能优化实践
1. CMSIS-DSP库更新需求解析在嵌入式开发领域,CMSIS-DSP库是ARM Cortex-M处理器上信号处理的核心支撑。作为专为微控制器优化的数字信号处理库,它包含了滤波器、矩阵运算、FFT等常用算法,其性能直接影响实时信号处理系统的表现。随着编译器版…...

航空航班延误预测:可解释性模型与四源融合实战
1. 项目概述:这不是一个“预测准不准”的问题,而是一个“预测有没有用”的问题我做航班延误预测项目,不是为了在Kaggle排行榜上刷个0.89的AUC就收工。真正让我在凌晨三点改完第17版特征工程脚本、盯着滚动的日志等模型收敛的,是去…...
Transformer核心机制深度解析:从公式到CUDA核的工程真相
1. 这不是又一篇“Transformer原理复述”,而是一次工程师视角的机制解剖你点开这篇文章,大概率不是为了再听一遍“Self-Attention就是计算相似度”这种教科书定义。我干了十多年AI系统架构和模型部署,从2017年Transformer论文刚出来那会儿就在…...

Arm编译器与64位inode文件系统兼容性问题解析
1. 64位inode文件系统与Arm编译器的兼容性问题解析在嵌入式开发领域,Arm编译器工具链是构建可靠、高效嵌入式系统的核心工具。然而,当开发者使用现代网络文件系统(如NFSv3)或分布式文件系统(如Ceph、CXFS)时…...

CLIP原理与实战:零样本图文理解的范式革命
1. 项目概述:为什么CLIP不是又一个“多模态模型”,而是彻底改写图文理解游戏规则的底层工具你可能已经见过太多标榜“图文理解”“跨模态检索”的模型,但真正让从业者在2021年集体停下手头工作、反复刷新arXiv页面的,只有CLIP。它…...
)
手把手教你用Mosquitto + PowerShell玩转MQTT消息订阅与发布(实战测试篇)
手把手教你用Mosquitto PowerShell玩转MQTT消息订阅与发布(实战测试篇) MQTT协议作为物联网领域的核心通信标准,其轻量级和发布/订阅模式为设备互联提供了高效解决方案。本文将带您通过Windows PowerShell与Mosquitto搭建完整的MQTT测试环境…...

2026年南京Geo公司将有何新动态?一起探寻其发展新方向!
在数字化浪潮汹涌澎湃的当下,AI智能营销领域正经历着前所未有的变革。顺炫科技作为该领域的深耕者,一直致力于为全球客户提供高效、智能的数字化推广解决方案。随着2026年的到来,顺炫科技又将有哪些新动态,其发展新方向又将指向何…...

成都制造企业电费越来越高,AI能耗异常预警该先接哪些数据?
一、电费上涨,先别只看总表对成都不少制造企业来说,电费已经不只是后勤费用,而是影响订单毛利、交付节奏和产线管理的一项经营变量。问题在于,许多企业发现电费升高时,第一反应仍然停留在“今年产量多了”“设备老了”…...