MySQL 中的 distinct 和 group by 哪个效率更高?
结论
先说大致的结论(完整结论在文末):
在语义相同,有索引的情况下group by和distinct都能使用索引,效率相同。
在语义相同,无索引的情况下:distinct效率高于group by。原因是distinct 和 group by都会进行分组操作,但group by可能会进行排序,触发filesort,导致sql执行效率低下。
基于这个结论,你可能会问:
为什么在语义相同,有索引的情况下,group by和distinct效率相同?
在什么情况下,group by会进行排序操作?
带着这两个问题找答案。接下来,我们先来看一下distinct和group by的基础使用。
distinct的使用
distinct用法
SELECT DISTINCT columns FROM table_name WHERE where_conditions;例如:
mysql> select distinct age from student;
+------+
| age |
+------+
| 10 |
| 12 |
| 11 |
| NULL |
+------+
4 rows in set (0.01 sec)DISTINCT 关键词用于返回唯一不同的值。放在查询语句中的第一个字段前使用,且作用于主句所有列。
如果列具有NULL值,并且对该列使用DISTINCT子句,MySQL将保留一个NULL值,并删除其它的NULL值,因为DISTINCT子句将所有NULL值视为相同的值。
distinct多列去重
distinct多列的去重,则是根据指定的去重的列信息来进行,即只有所有指定的列信息都相同,才会被认为是重复的信息。
SELECT DISTINCT column1,column2 FROM table_name WHERE where_conditions;
mysql> select distinct sex,age from student;
+--------+------+
| sex | age |
+--------+------+
| male | 10 |
| female | 12 |
| male | 11 |
| male | NULL |
| female | 11 |
+--------+------+
5 rows in set (0.02 sec)group by的使用
对于基础去重来说,group by的使用和distinct类似:
单列去重
语法:
SELECT columns FROM table_name WHERE where_conditions GROUP BY columns;执行:
mysql> select age from student group by age;
+------+
| age |
+------+
| 10 |
| 12 |
| 11 |
| NULL |
+------+
4 rows in set (0.02 sec)多列去重
语法:
SELECT columns FROM table_name WHERE where_conditions GROUP BY columns;执行:
mysql> select sex,age from student group by sex,age;
+--------+------+
| sex | age |
+--------+------+
| male | 10 |
| female | 12 |
| male | 11 |
| male | NULL |
| female | 11 |
+--------+------+
5 rows in set (0.03 sec)区别示例
两者的语法区别在于,group by可以进行单列去重,group by的原理是先对结果进行分组排序,然后返回每组中的第一条数据。且是根据group by的后接字段进行去重的。
例如:
mysql> select sex,age from student group by sex;
+--------+-----+
| sex | age |
+--------+-----+
| male | 10 |
| female | 12 |
+--------+-----+
2 rows in set (0.03 sec)distinct和group by原理
在大多数例子中,DISTINCT可以被看作是特殊的GROUP BY,它们的实现都基于分组操作,且都可以通过松散索引扫描、紧凑索引扫描(关于索引扫描的内容会在其他文章中详细介绍,就不在此细致介绍了)来实现。
DISTINCT和GROUP BY都是可以使用索引进行扫描搜索的。例如以下两条sql(只单单看表格最后extra的内容),我们对这两条sql进行分析,可以看到,在extra中,这两条sql都使用了紧凑索引扫描Using index for group-by。
所以,在一般情况下,对于相同语义的DISTINCT和GROUP BY语句,我们可以对其使用相同的索引优化手段来进行优化。
mysql> explain select int1_index from test_distinct_groupby group by int1_index;
+----+-------------+-----------------------+------------+-------+---------------+---------+---------+------+------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------------------+------------+-------+---------------+---------+---------+------+------+----------+--------------------------+
| 1 | SIMPLE | test_distinct_groupby | NULL | range | index_1 | index_1 | 5 | NULL | 955 | 100.00 | Using index for group-by |
+----+-------------+-----------------------+------------+-------+---------------+---------+---------+------+------+----------+--------------------------+
1 row in set (0.05 sec)
mysql> explain select distinct int1_index from test_distinct_groupby;
+----+-------------+-----------------------+------------+-------+---------------+---------+---------+------+------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------------------+------------+-------+---------------+---------+---------+------+------+----------+--------------------------+
| 1 | SIMPLE | test_distinct_groupby | NULL | range | index_1 | index_1 | 5 | NULL | 955 | 100.00 | Using index for group-by |
+----+-------------+-----------------------+------------+-------+---------------+---------+---------+------+------+----------+--------------------------+
1 row in set (0.05 sec)但对于GROUP BY来说,在MYSQL8.0之前,GROUP Y默认会依据字段进行隐式排序。
可以看到,下面这条sql语句在使用了临时表的同时,还进行了filesort。
mysql> explain select int6_bigger_random from test_distinct_groupby GROUP BY int6_bigger_random;
+----+-------------+-----------------------+------------+------+---------------+------+---------+------+-------+----------+---------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------------------+------------+------+---------------+------+---------+------+-------+----------+---------------------------------+
| 1 | SIMPLE | test_distinct_groupby | NULL | ALL | NULL | NULL | NULL | NULL | 97402 | 100.00 | Using temporary; Using filesort |
+----+-------------+-----------------------+------------+------+---------------+------+---------+------+-------+----------+---------------------------------+
1 row in set (0.04 sec)隐式排序
对于隐式排序,我们可以参考Mysql官方的解释:
MySQL :: MySQL 5.7 Reference Manual :: 8.2.1.14 ORDER BY Optimization
GROUP BY implicitly sorts by default (that is, in the absence of ASC or DESC designators for GROUP BY columns). However, relying on implicit GROUP BY sorting (that is, sorting in the absence of ASC or DESC designators) or explicit sorting for GROUP BY (that is, by using explicit ASC or DESC designators for GROUP BY columns) is deprecated. To produce a given sort order, provide an ORDER BY clause.
大致解释一下:
GROUP BY 默认隐式排序(指在 GROUP BY 列没有 ASC 或 DESC 指示符的情况下也会进行排序)。然而,GROUP BY进行显式或隐式排序已经过时(deprecated)了,要生成给定的排序顺序,请提供 ORDER BY 子句。
所以,在Mysql8.0之前,Group by会默认根据作用字段(Group by的后接字段)对结果进行排序。在能利用索引的情况下,Group by不需要额外进行排序操作;但当无法利用索引排序时,Mysql优化器就不得不选择通过使用临时表然后再排序的方式来实现GROUP BY了。
且当结果集的大小超出系统设置临时表大小时,Mysql会将临时表数据copy到磁盘上面再进行操作,语句的执行效率会变得极低。这也是Mysql选择将此操作(隐式排序)弃用的原因。
基于上述原因,Mysql在8.0时,对此进行了优化更新:
MySQL :: MySQL 8.0 Reference Manual :: 8.2.1.16 ORDER BY Optimization
Previously (MySQL 5.7 and lower), GROUP BY sorted implicitly under certain conditions. In MySQL 8.0, that no longer occurs, so specifying ORDER BY NULL at the end to suppress implicit sorting (as was done previously) is no longer necessary. However, query results may differ from previous MySQL versions. To produce a given sort order, provide an ORDER BY clause.
大致解释一下:
从前(Mysql5.7版本之前),Group by会根据确定的条件进行隐式排序。在mysql 8.0中,已经移除了这个功能,所以不再需要通过添加order by null 来禁止隐式排序了,但是,查询结果可能与以前的 MySQL 版本不同。要生成给定顺序的结果,请按通过ORDER BY指定需要进行排序的字段。
因此,我们的结论也出来了:
在语义相同,有索引的情况下:
group by和distinct都能使用索引,效率相同。因为group by和distinct近乎等价,distinct可以被看做是特殊的group by。
在语义相同,无索引的情况下:
distinct效率高于group by。原因是distinct 和 group by都会进行分组操作,但group by在Mysql8.0之前会进行隐式排序,导致触发filesort,sql执行效率低下。但从Mysql8.0开始,Mysql就删除了隐式排序,所以,此时在语义相同,无索引的情况下,group by和distinct的执行效率也是近乎等价的。
推荐group by的原因
1.group by语义更为清晰
2.group by可对数据进行更为复杂的一些处理
相比于distinct来说,group by的语义明确。且由于distinct关键字会对所有字段生效,在进行复合业务处理时,group by的使用灵活性更高,group by能根据分组情况,对数据进行更为复杂的处理,例如通过having对数据进行过滤,或通过聚合函数对数据进行运算。
相关文章:

MySQL 中的 distinct 和 group by 哪个效率更高?
结论先说大致的结论(完整结论在文末):在语义相同,有索引的情况下group by和distinct都能使用索引,效率相同。在语义相同,无索引的情况下:distinct效率高于group by。原因是distinct 和 group by…...

Spring 框架源码(六) Bean的生命周期全流程源码解析
Spring框架作为Java王国的地基,我觉得它包含了很多精妙的设计,例如Bean工厂设计、Bean的生命周期、tx、aop、web、mvc等,最核心基本的Bean设计是Spring 的框架的灵魂,本文就Bean的生命周期全流程做源码程度上的解析,欢…...

运维服务商低成本提升服务质量解决方案
在信息化高速发展的今天,网络建设的重要性不言而喻,更多客户选择将运维服务外包或托管给运维服务商,市场需求愈大竞争压力愈大,想要脱颖而出势必要优化自身提高服务质量,最好是低成本、大提升,nVisual助力渠…...

Raft 一致性算法
Raft Raft提供了一种在计算系统集群中分布状态机的通用方法,确保集群中的每个节点都同意一系列相同的状态转换。 一个Raft集群包含若干个服务器节点,通常为5个,这允许整个系统容忍2个节点的失效。每个节点处于以下三种状态之一: …...
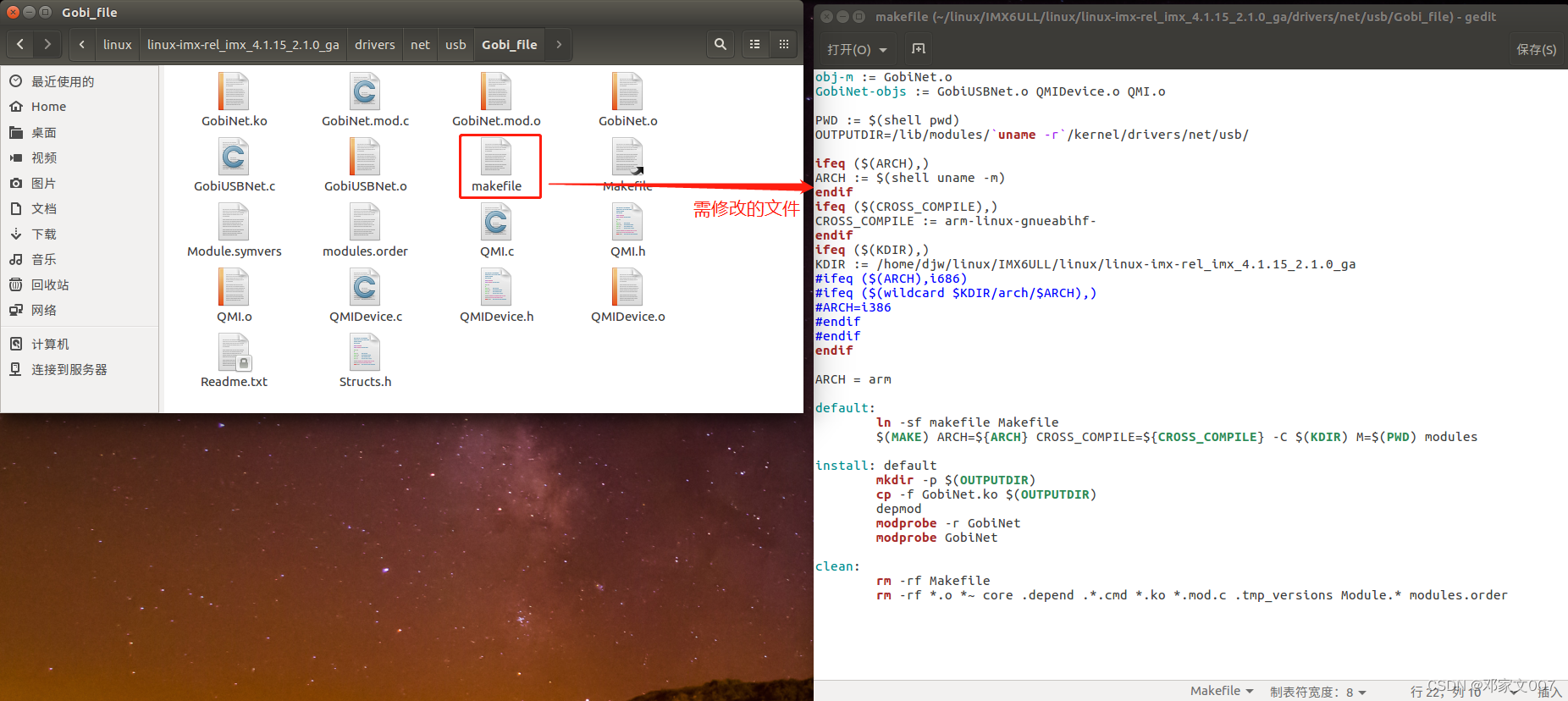
驱动程序开发:基于EC20 4G模块自动拨号联网的两种方式(GobiNet工具拨号和PPP工具拨号)
目录一、EC20 4G模块简介二、根据移远官方文档修改EC20 4G模组驱动 1、因为EC20 4G模组min-pice接口其实就是usb接口,因此需要修改Linux内核源码drivers/usb/serial/option.c文件,如下图: 2、根据USB协议的要求,需要在drive…...

Web自动化测试——常见问题篇
文章目录一、什么是自动化测试二、为啥进行自动化测试(优点)三、Webdriver 的工作原理四、显示等待和隐式等待的区别五、什么样的项目适合做自动化六、自动化测试的流程七、如何分析生成的自动化测试报告一、什么是自动化测试 所谓的自动化测试就是使用…...
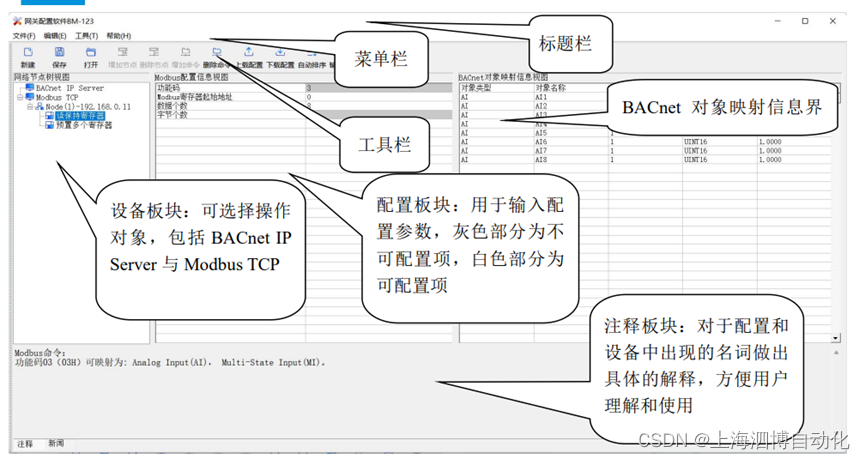
快速实现Modbus TCP转BACnet IP协议的方案
一、需求背景 BACnet是用于智能楼宇自控系统的主流通信协议,可用在暖通空调系统(HVAC,包括暖气、通风、空气调节),也可以用在照明控制、门禁系统、火警侦测系统及其相关的设备。楼宇中的受控设备都通过BACnet协议连接到…...
Unity CircleLayoutGroup 如何实现一个圆形自动布局组件
文章目录简介实现原理Editor 编辑器简介 Unity中提供了三种类型的自动布局组件,分别是Grid Layou Group、Horizontal Layout Group、Vertical Layout Group,本文自定义了一个圆形的自动布局组件Circle Layout Group,如图所示: Ra…...
springcloud+nacos+gateway案例
一、先搭建好springcloudnacos项目地址:https://javazhong.blog.csdn.net/article/details/128899999二、spring cloud gateway简述Spring Cloud Gateway 是Spring Cloud家族中的一款API网关。Gateway 建立在 Spring Webflux上,目标是提供一个简洁、高效的API网关&a…...

实习这么久,你知道Maven是如何从代码仓库中找到需要的依赖吗?
目录 碎碎念 Maven是如何找到代码仓库里需要的依赖的? 如何根据坐标在本地仓库中寻找所需要的依赖? 如何根据坐标在远程仓库中寻找所需要的依赖? Maven 如何使用 HTTP 或 HTTPS 协议从远程仓库中获取依赖项,请详细解释其原理…...
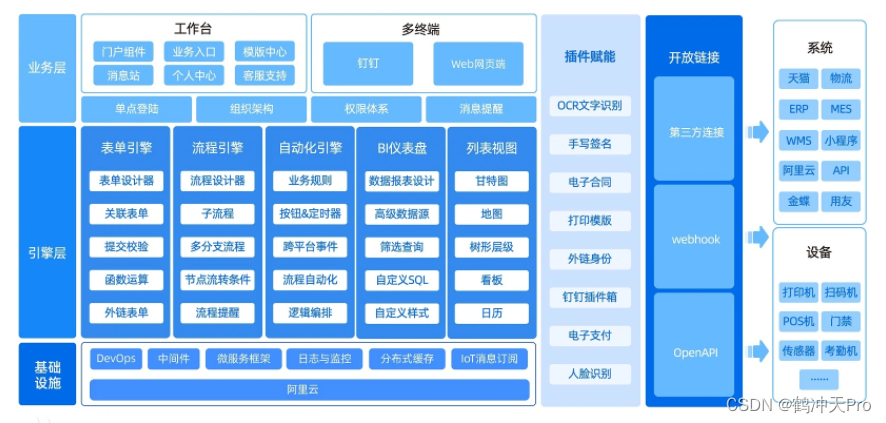
低代码/零代码的快速开发框架
目前国内主流的低代码开发平台有:宜搭、简道云、明道云、云程、氚云、伙伴云、道一云、JEPaaS、华炎魔方、搭搭云、JeecgBoot 、RuoYi等。这些平台各有优劣势,定位也不同,用户可以根据自己需求选择。 一、阿里云宜搭 宜搭是阿里巴巴集团在20…...

C# 中常见的设计模式
设计模式是一套被广泛应用于软件设计的最佳实践,它们可以帮助开发者解决特定的问题,提高代码的可重用性、可读性和可维护性。本文将介绍 C# 中常见的几种设计模式,并提供相应的示例代码。 工厂模式 工厂模式是一种创建型设计模式,…...

promethues/servicemonitor
目录 1.promethues 能保证源源不断地采集/metrics 信息吗?每次都是最新的吗 2.部署servicemonitor 的作用是什么? 3.pod 部署采集数据直接上报promthues ,不通过servicemonitor 可以吗? 4.你说的"此外,如果部署…...

postman使用简介
1、介绍 postman是一款功能强大的网页调试和模拟发送HTTP请求的Chrome插件,支持几乎所有类型的HTTP请求 2、下载及安装 官方文档:https://www.getpostman.com/docs/v6/ chrome插件:chrome浏览器应用商店直接搜索添加即可(需墙&…...

@DS注解在事务中实现数据源的切换@DS在事务中失效【已解决】
在Springboot的application.yml中的配置: spring:datasource:url: jdbc:mysql://localhost:3306/test2?serverTimezoneUTC&useUnicodetrue&characterEncodingutf8driver-class-name: com.mysql.cj.jdbc.Driverusername: rootpassword: rootdynamic:primar…...

Java I/O之文件系统
一、全文概览 在学习文件系统之前,需要了解下Java在I/O上的发展史:在Java7之前,打开和读取文件需要编写特别笨拙的代码,涉及到很多的InputStream、OutputStream等组合起来使用,每次在使用时或许都需要查一下文档才能记…...

Mysql元数据获取方法(information_schema绕过方法)
前提:如果waf或其它过滤了information_schema关键字,那我们该如何获取元数据呢?能够代替information_schema的有:sys.schema_auto_increment_columnssys.schema_table_statistics_with_bufferx$schema_table_statistics_with_buff…...

Eclipse快捷键
* 1.补全代码的声明:alt /* 2.快速修复: ctrl 1 * 3.批量导包:ctrl shift o* 4.使用单行注释:ctrl /* 5.使用多行注释: ctrl shift / * 6.取消多行注释:ctrl shift \* 7.复制指定行的代码:ctrl a…...
java ssm自习室选座预约系统开发springmvc
人工管理显然已无法应对时代的变化,而自习室选座预约系统开发能很好地解决这一问题,既能提高人力物力,又能提高预约选座的知名度,取代人工管理是必然趋势。 本自习室选座预约系统开发以SSM作为框架,JSP技术,…...
分享我从功能测试转型到测试开发的真实故事
由于这段时间我面试了很多家公司,也经历了之前公司的不愉快。所以我想写一篇文章来分享一下自己的面试体会。希望能对我在之后的工作或者面试中有一些帮助,也希望能帮助到正在找工作的你。 找工作 我们总是草率地进入一个自己不了解的公司工作…...

Avalon-MM接口实战解析:从信号握手到高效传输
1. Avalon-MM接口核心信号解析 第一次接触Avalon-MM接口时,我被那一堆带"_n"后缀的信号名绕得头晕。直到在FPGA项目里实际调试数据采集系统时,才真正理解每个信号的作用。这个内存映射接口最妙的地方在于它的灵活性——你可以像搭积木一样&…...
)
从CI/CD到AI/CD:SITS2026定义的下一代测试流水线(附头部大厂内部迁移路径图)
更多请点击: https://intelliparadigm.com 第一章:AI研发自动化测试:SITS2026专题 AI研发流程中,测试环节正从人工验证转向模型感知驱动的闭环自动化。SITS2026(Semantic Intelligence Testing Suite 2026)…...

MultiBreak:大模型多轮越狱成功率飙升54%,我们正在失去对话安全的最后防线
2026年5月3日,来自全球顶尖AI安全实验室的联合研究团队发布了MultiBreak——迄今为止规模最大、多样性最高的大模型多轮越狱攻击基准。实验结果令人震惊:在DeepSeek-R1-7B上,MultiBreak的攻击成功率(ASR)比此前最优数据…...
5分钟掌握Translumo:Windows平台终极屏幕实时翻译神器
5分钟掌握Translumo:Windows平台终极屏幕实时翻译神器 【免费下载链接】Translumo Advanced real-time screen translator for games, hardcoded subtitles in videos, static text and etc. 项目地址: https://gitcode.com/gh_mirrors/tr/Translumo 想要瞬间…...

API中转站统一管理工具:基于Electron的自动化运维实践
1. 项目概述:一个桌面端API中转站管理工具如果你正在使用或管理多个AI模型的API中转服务,比如OpenAI、Claude、Anthropic、Gemini等,那么你大概率会遇到一个非常头疼的问题:管理混乱。不同的中转站有不同的后台地址、不同的账号密…...

对比直接使用官方API通过Taotoken聚合调用在多模型选型上的便利性
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接使用官方API与通过Taotoken聚合调用在多模型选型上的便利性 在实际项目开发中,我们尝试了同时接入多个主流模型…...

ImageGlass:如何构建高效开源图像查看器,90+格式支持与模块化架构深度解析
ImageGlass:如何构建高效开源图像查看器,90格式支持与模块化架构深度解析 【免费下载链接】ImageGlass 🏞 A lightweight, versatile image viewer 项目地址: https://gitcode.com/gh_mirrors/im/ImageGlass 在数字图像处理日益复杂的…...

工业意识:01 SCADA 到底是什么?为什么说它是工厂的“监控大脑”?
01 SCADA 到底是什么?为什么说它是工厂的“监控大脑”? 新系列开张啦!《工业意识:SCADA与MES》第一弹,直接上干货!口号喊起来:“让机器看清世界,让质量无处遁形。” 哈哈,这话多接地气!以前工厂监控靠人眼盯、粉笔写,现在系统自己长了“千里眼”和“顺风耳”,质量问…...
)
SITS2026摄影服务背后的数据真相:单日处理17.8TB视觉流、327台终端协同、端到端延迟压至≤83ms(附完整时序拓扑图)
更多请点击: https://intelliparadigm.com 第一章:SITS2026摄影服务背后的数据真相:单日处理17.8TB视觉流、327台终端协同、端到端延迟压至≤83ms(附完整时序拓扑图) SITS2026并非传统影楼系统,而是一套面…...

3分钟完成Windows和Office激活的终极指南:KMS_VL_ALL_AIO智能脚本
3分钟完成Windows和Office激活的终极指南:KMS_VL_ALL_AIO智能脚本 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows系统激活而烦恼吗?KMS_VL_ALL_AIO是一款开…...